检索
检索 Pipeline 是 RAG(检索增强生成)流程中的关键环节,主要负责在用户提问时,从知识库中查找相关内容并召回合适的片段,供后续生成答案使用。通过为不同 Agent 或业务场景配置独立的检索 Pipeline,用户可以更灵活地控制“怎么检索、召回哪些内容、按什么规则返回结果”,并结合测试与发布机制持续优化效果,从而提升最终答案的准确性与可控性。
检索 Pipeline 的类型
系统提供 “基础编排” 与 “高级编排” 两种模式。支持从简单的关键词检索到复杂的多路召回、重排序、变量聚合等高级流程,帮助开发者灵活定制检索与生成链路。
对应两种模式,系统分别内置了 default basic pipeline(基础编排)与 default advanced pipeline(高级编排)。内置 Pipeline 不可修改、不可删除,但支持复制后修改,便于新手用户在官方模板基础上快速定制符合自身业务的检索流程。
| 对比维度 | 基础编排 | 高级编排 |
|---|---|---|
| 流程影响范围 | 继承开始节点的更多属性,整个编排流程直接影响最终的答案生成。 | 流程仅作用于检索阶段,不直接影响最终答案的输出。 |
| 输出内容 | 答案 + 相关片段(包含向量等详细信息) | 仅输出答案(不包含向量等额外信息) |
| 适用场景 | 需要深度控制检索逻辑并希望流程影响最终回答的场景。 | 只需优化检索召回质量,而答案生成由其他节点独立负责的场景。 |
默认内置 Pipeline 在功能上已完全覆盖原有 RAG 检索能力,可以直接使用,也可以复制后按需定制,例如自定义问题改写、添加过滤规则等。
继承机制
检索Pipeline不能独立使用,必须绑定到具体的 Agent 上。绑定后,检索Pipeline会继承该 Agent 的基础配置,并将这些属性传递到 Pipeline 开始节点的输入中。
继承的属性:用户输入、对话历史、模型选择、外部配置参数
该机制使检索 Pipeline 能够无缝感知 Agent 上下文,避免重复配置。
运行机制
检索Pipeline 的执行触发方式取决于其类型:
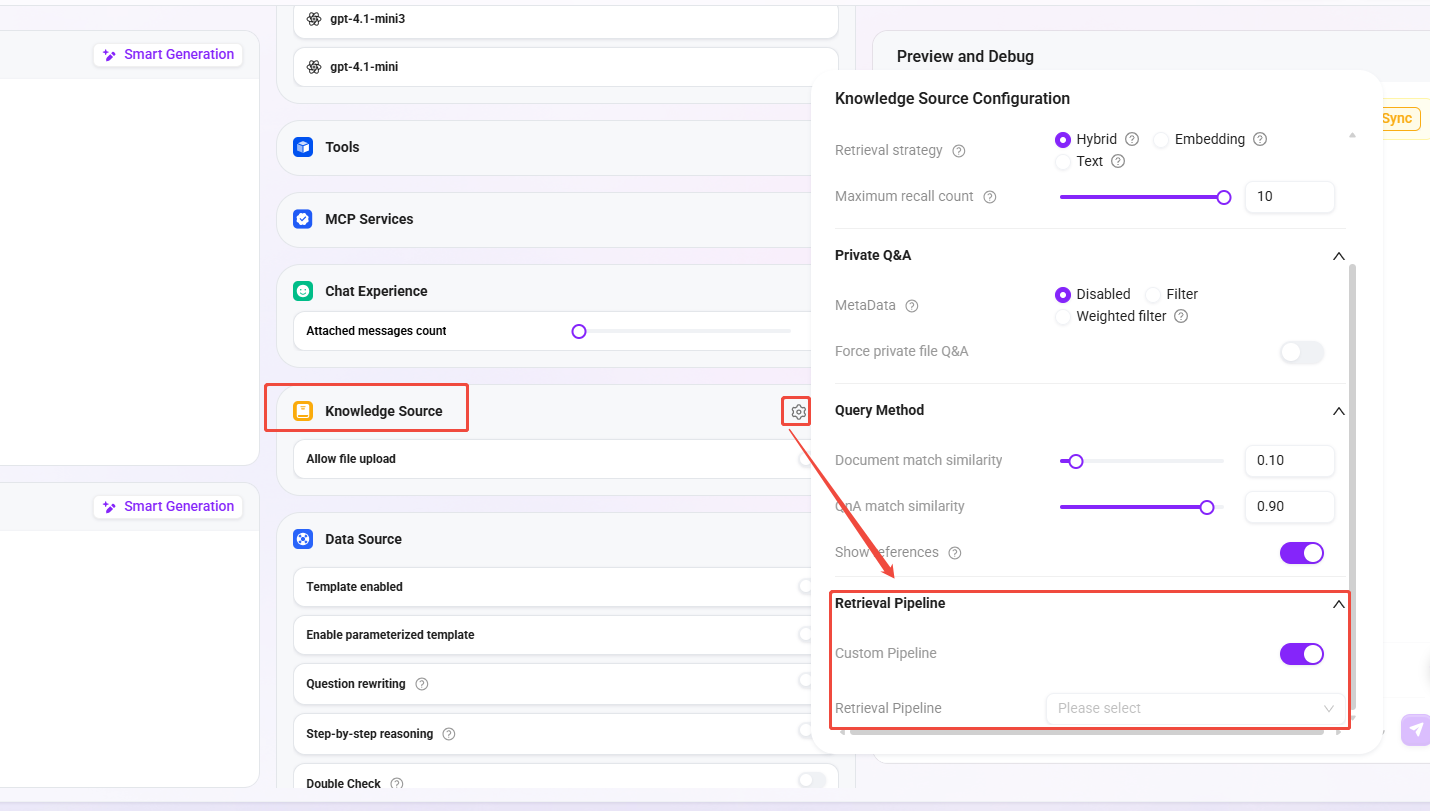
基础编排
在执行 retrieval tool 时触发。需要在 Agent 配置中打开对应的开关。
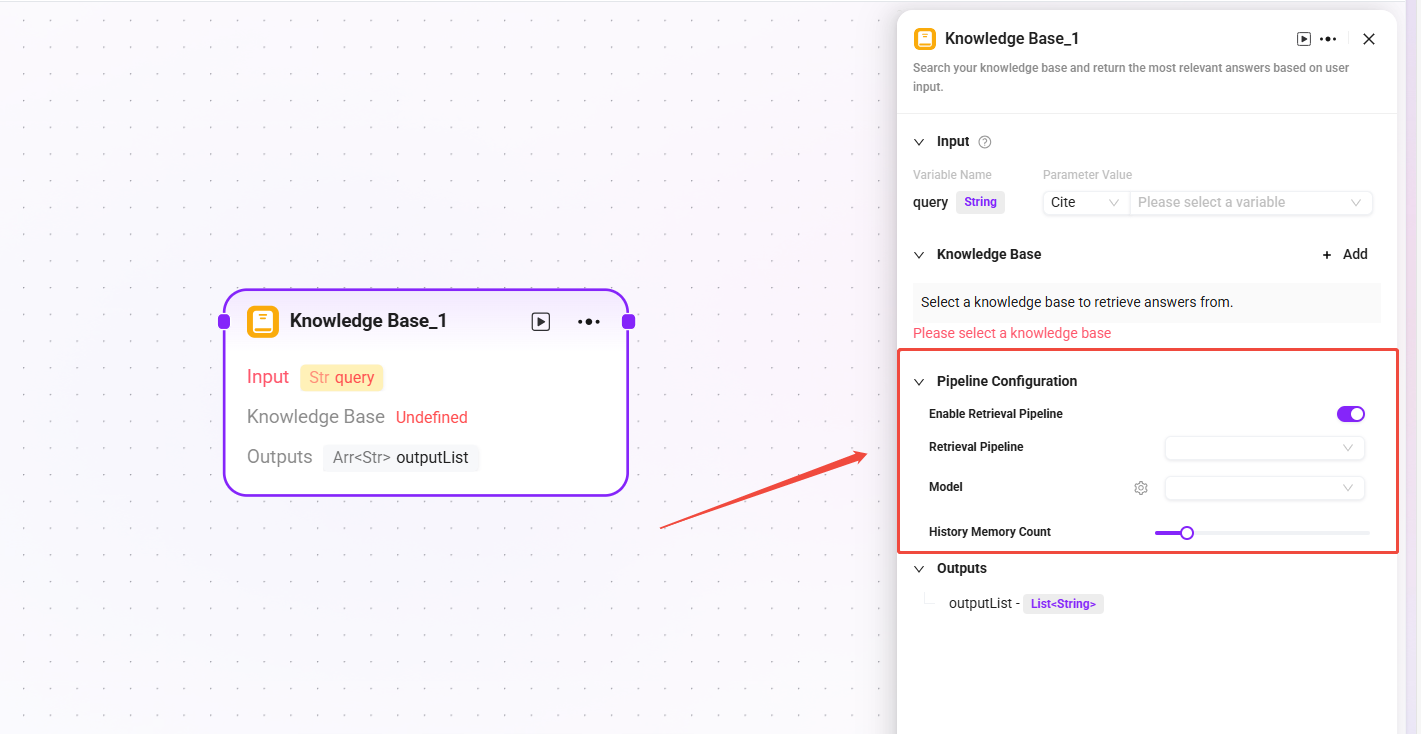
高级编排
在执行到对应的 retrieval node 时触发。需要在知识库节点配置中打开对应的开关。
创建与配置
创建检索Pipeline
如果不使用内置 Pipeline,用户也可以按以下步骤从头创建自定义的检索Pipeline。
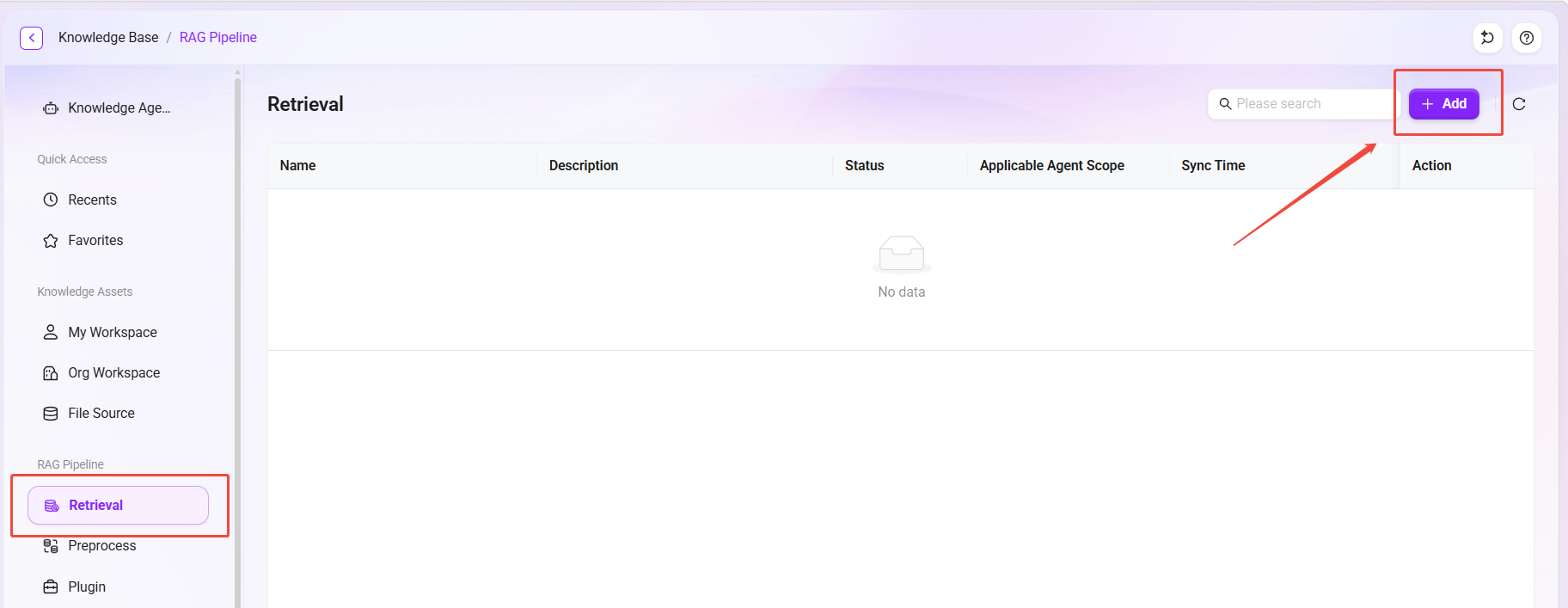
- 在检索页面右上角点击 “新增” 按钮,进入创建页面。
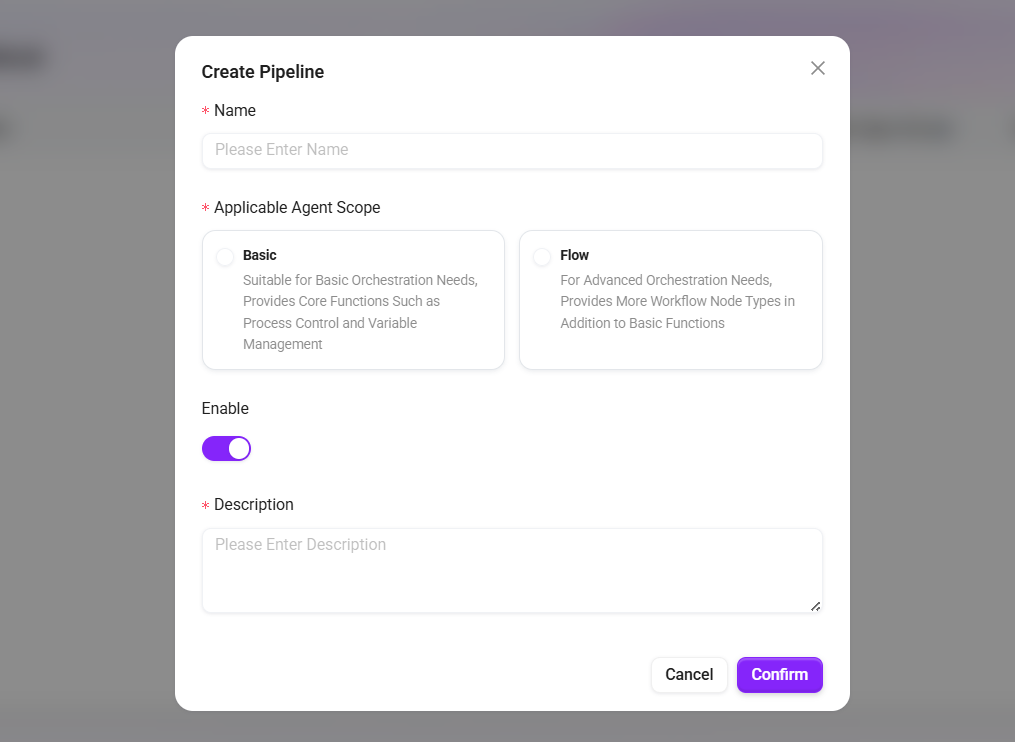
- 填写基本信息:
- 名称:检索的名称。
- 适用 Agent 范围:
- 基础编排:适用于基础编排需求,提供流程控制、变量管理等核心功能。
- 高级编排:适用于高级编排需求,除基础功能外,提供更多流程节点类型。
- 启用:控制检索是否生效。
- 描述:补充说明适用场景或配置要点。
- 点击 “保存” 完成创建。
配置检索Pipeline
创建完成后,点击检索 Pipeline 的 “ ” 编辑图标进入配置界面。用户可以按需从节点库添加节点,并通过连线组合出自定义检索流程。
” 编辑图标进入配置界面。用户可以按需从节点库添加节点,并通过连线组合出自定义检索流程。
节点类型详解
节点库提供了丰富的功能节点,用于构建检索流程中的各个处理环节。
提示:关于节点更多的详细说明,请点击任一节点的配置页面的右上角的 “
”进入说明文档查看。
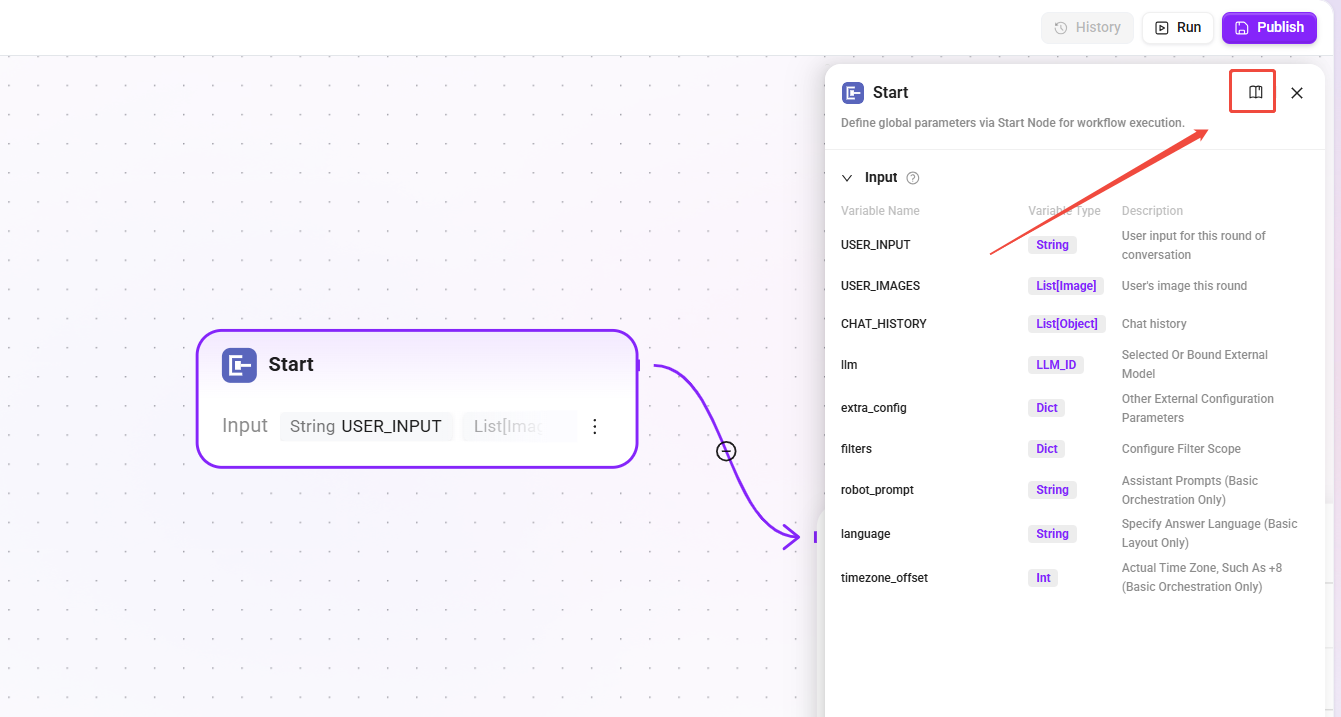
开始
- 功能:RAG Pipeline 的入口节点,负责传递用户输入和相关配置属性。
- 类型差异:
- 基础编排:包含额外参数(
robot_prompt、language、timezone_offset)。 - 高级编排:标准参数集。
- 基础编排:包含额外参数(
- 作用:作为 Pipeline 继承 Agent 配置的入口。
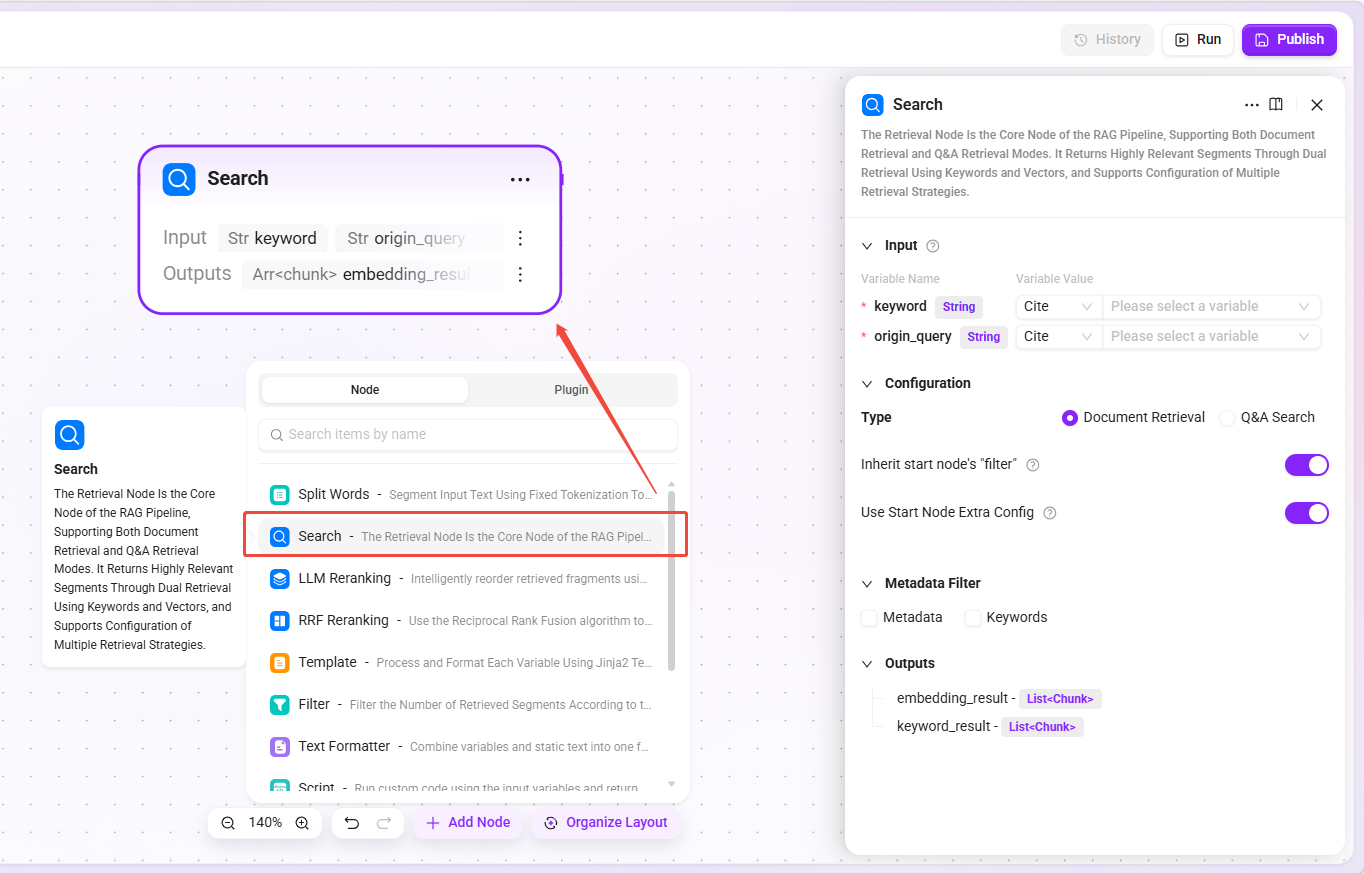
检索
- 功能:核心检索节点,支持文档检索和 Q&A 检索两种模式,通过关键词和向量双路检索返回相似度高的片段。
- 检索类型:
- 文档检索:用户上传的文档空间。
- Q&A 检索:维护的问答对。
- 适用场景:知识库问答、文档内容搜索、FAQ 匹配。
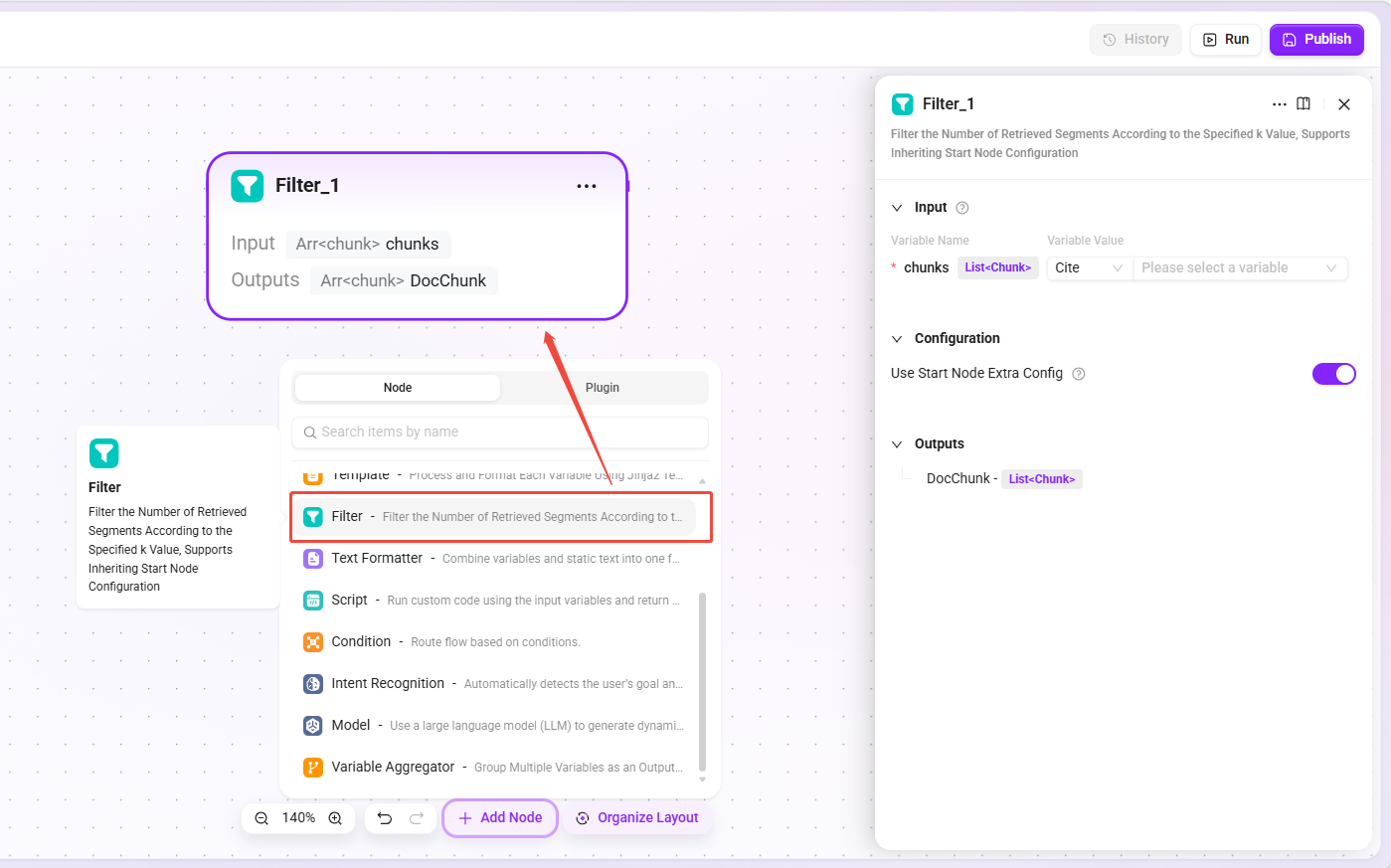
过滤节点
- 功能:根据指定的
k值对检索返回的片段数量进行筛选,控制检索结果数量。 - 继承配置:若选择继承开始节点,基础编排继承 Agent 检索策略的“最大召回数量”;高级编排继承检索节点的“Top K”。
- 适用场景:避免过多无关片段干扰生成结果,同时保证足够的相关信息。
LLM 重排节点
- 功能:使用大语言模型对检索片段进行智能重排序,通过内置固定提示词评估片段与问题的相关性。
- 模型选择:可继承开始节点的模型配置,也可单独指定。
- 适用场景:需要高精度排序的问答场景、多源检索结果融合后的精排。
- 建议:先用其他方式粗排,再使用 LLM 精排,以控制成本。
RRF 重排节点
- 功能:使用 Reciprocal Rank Fusion(倒数排名融合)算法,对来自不同检索源的片段进行加权重排序。
- 输入:多个来源的片段列表和对应权重。
- 适用场景:向量检索与关键词检索结果融合、多知识库检索结果融合、不同检索策略结果融合。
变量聚合器
- 功能:将多个变量分组聚合为输出变量,提供“取首个非空值”和“合并为列表”两种策略。
- 适用场景:多路检索结果汇合、条件分支后的数据合并、备选方案的优先级选择。
分词节点
- 功能:将输入文本通过固定分词工具进行分词处理,输出以
|分隔的关键词字符串。 - 适用场景:为检索节点提供
keyword输入、提取用户问题中的关键词。
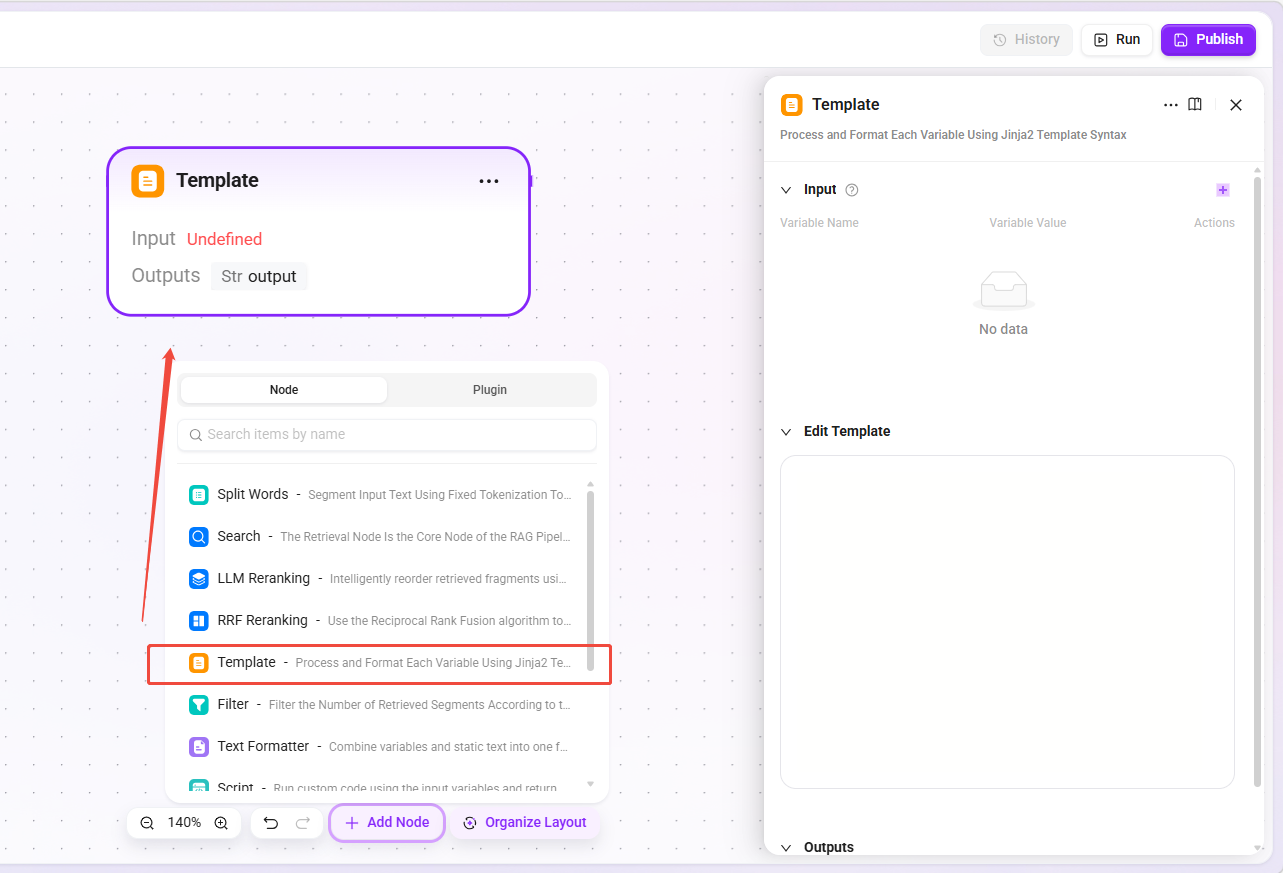
模板节点
- 功能:使用 Jinja2 模板语法对各变量进行格式化处理,支持字符串拼接、条件判断、循环等,并内置时区处理方法。
- 适用场景:构建发送给模型的提示词、格式化检索结果、动态生成回复内容。
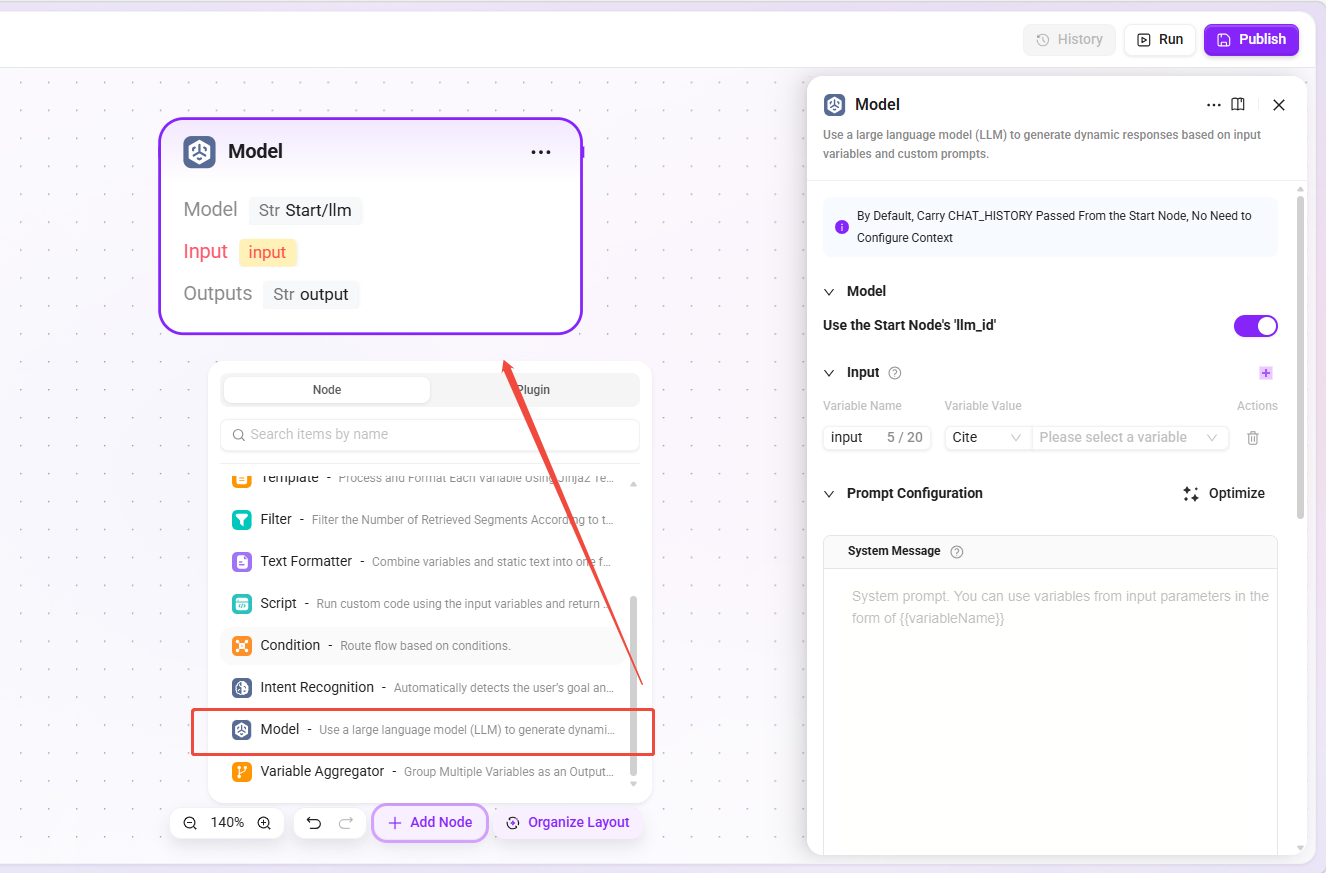
模型节点(RAG LLM Node)
- 功能:向大语言模型发送消息并获取响应,支持继承开始节点的模型配置或单独指定模型。
- 与高级编排模型节点的区别:可选择继承开始节点的模型配置,保证 Pipeline 内使用的模型与用户对话一致;也可单独指定。
- 基础编排特殊配置:
Streaming Output开关,开启后模型响应会在对话中流式输出,提升体验。
插件节点
- 功能:调用系统中已配置的插件,将上游节点的参数传递给插件执行,并获取返回结果。
- 适用场景:调用外部 API、执行自定义业务逻辑、数据格式转换、调用第三方服务。
提示:详情请参考插件的相关概念部分,了解插件如何使用。
结束节点
- 功能:RAG Pipeline 的终止节点,收集上游节点传递的输入参数并作为最终输出返回。
- 适用场景:输出经过处理的片段列表、返回模型生成的回答(基础编排专属)。
最佳实践建议
- 新手入门:先直接使用 “default basic pipeline” 或 “default advanced pipeline”,理解其默认行为。
- 按需定制:复制内置 Pipeline,修改检索策略、过滤条件或问题改写逻辑,以满足特定业务需求。
- 测试验证:在独立环境中测试修改后的 Pipeline,确认召回效果后再绑定到生产 Agent 上。
- 注意继承:Pipeline 会继承 Agent 的诸多属性,配置 Agent 时请确保这些属性符合预期。
- 成本控制:在使用 LLM 重排时,先通过过滤或粗排减少输入片段数量,以降低资源消耗。