预处理
预处理 Pipeline 主要用于定义文档在放入知识库时的处理流程,会在文档上传并入库时生效,包括文档解析、文本分块、向量化等环节。
用户可以按文档类型或业务需求定制处理策略,满足多来源文档接入下的差异化处理要求,确保知识内容在入库阶段被正确解析、切分与索引,从而提升后续检索的召回质量。
使用方式
一个知识库可关联多个预处理 Pipeline,以适应不同文件类型的处理需求。文件上传时,系统将按顺序匹配适用的预处理规则,若均未命中则回退至默认 Pipeline。
- 平台内置默认规则:系统提供开箱即用的默认预处理 Pipeline,可直接使用或导入参考。
- 自定义与覆盖:支持新建自定义 Pipeline,也可复制默认 Pipeline 进行修改;默认 Pipeline 支持删除操作。
- 规则匹配机制:按优先级顺序匹配预处理规则,匹配到即执行对应流程,未匹配则走默认处理。
建议:调整预处理配置后,可通过上传测试文件验证处理效果。
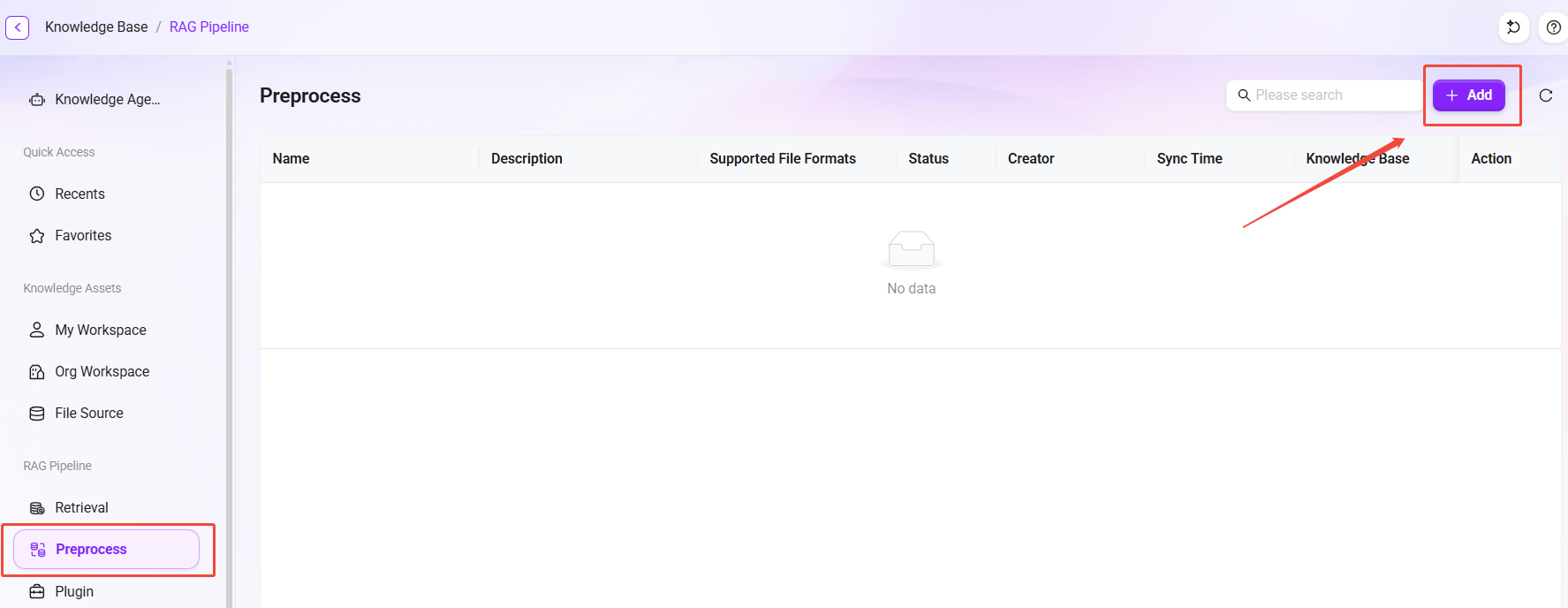
创建预处理 Pipeline
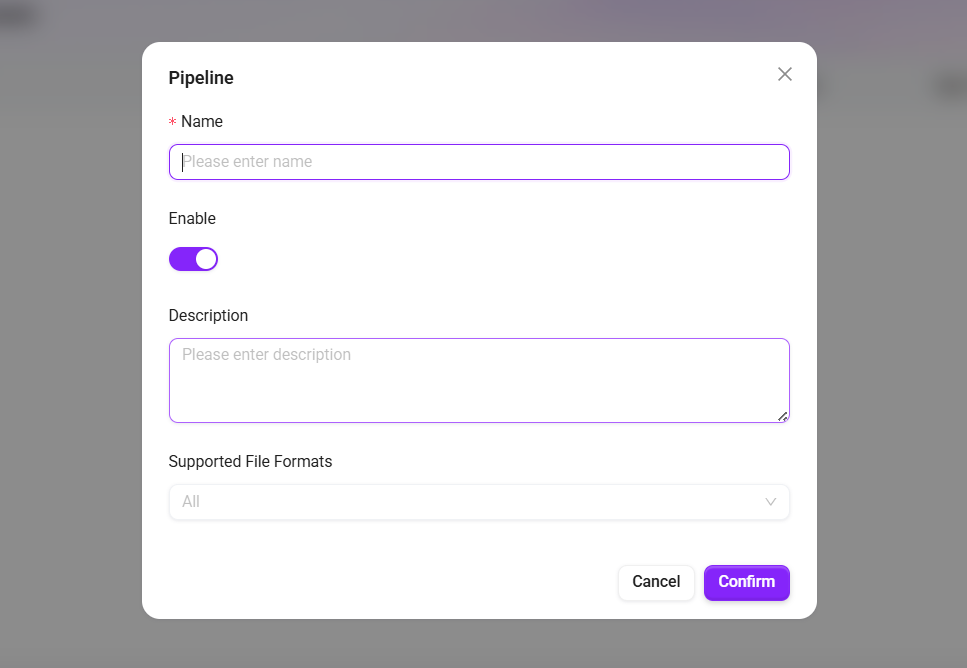
- 在预处理列表页点击 “新增” 按钮,弹出创建窗口。
- 填写基本信息:
- 名称:预处理 Pipeline名称。
- 启用:勾选后预处理生效,可被知识库关联使用。
- 描述:补充说明该预处理的适用场景或配置要点。
- 点击 “确认” 完成创建,系统将自动跳转至预处理编辑画布界面。
节点功能详解
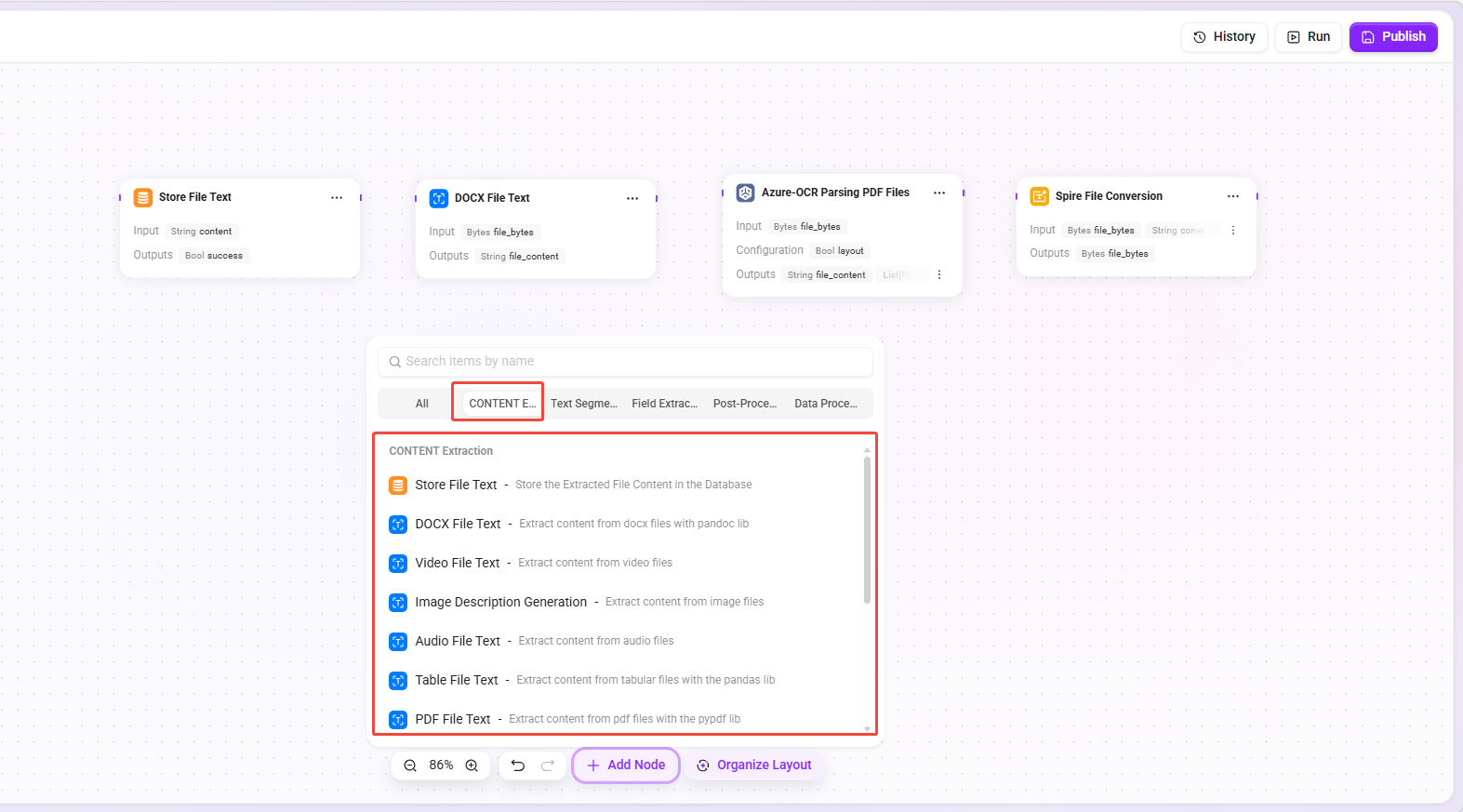
进入画布编辑界面后,可从节点库拖拽所需节点至画布,通过连线组合出完整的文件预处理流程。
节点库按功能分为以下类别:文本提取、文本分块、字段提取、后处理、插件、数据处理。
提示:
- 每个预处理流程的末尾均需添加相应的存储节点,确保各阶段处理结果正确持久化至数据库。
- 关于节点更多的详细说明,请点击任一节点的配置页面的右上角的 “
”进入说明文档查看。
文本提取节点
从各类文件格式中提取原始文本内容,作为后续处理的基础。
| 节点名称 | 功能描述 |
|---|---|
| 存储文件文本 | 将文件提取的内容存储到数据库。 |
| DOCX 文件文本 | 使用 pandoc 库从 docx 文件中提取内容。 |
| 视频文件文本 | 从视频文件中提取内容。 |
| 图像描述生成 | 从图片文件中提取内容。 |
| 音频文件文本 | 从音频文件中提取内容。 |
| 表格文件文本 | 使用 pandas 库从表格文件中提取内容。 |
| PDF 文件文本 | 使用 pypdf 库从 PDF 文件中提取内容。 |
| Markdown 文件文本 | 从 markdown 文件中提取内容。 |
| TXT 文件文本 | 从 txt 文件中提取内容。 |
| Azure-OCR 解析 PDF 文件 | 使用 Azure Document Intelligence 布局/读取模式提取内容。仅支持 .pdf 格式,可自动清理噪音数据。 |
| 多模态 LLM 解析 PDF 文件 | 使用 LLM OCR 模型提取内容。 |
| Spire 文件转换 | 使用 Spire 库进行文件格式转换。 |
| LibreOffice 文件转换 | 使用 LibreOffice 库进行文件格式转换。 |
文本分块节点
将提取的长文本按指定策略切分为多个段落或片段,便于后续索引与检索。
| 节点名称 | 功能描述 |
|---|---|
| 固定字符数分块 | 按固定大小拆分文档。 |
| 固定字符数切分(附带页码信息) | 按固定大小拆分文档,同时携带页面起始位置信息。 |
| 表格类文件分块 | 将表格文档拆分为段落。 |
| 按页分块 | 将文档按页切分为段落。 |
| 按标题分块 | 按标题将文档拆分为段落。 |
| 存储文件分段 | 将分段数据存储到数据库。 |
字段提取节点
从文档内容或元数据中提取关键信息,生成摘要、关键词或结构化字段。
| 节点名称 | 功能描述 |
|---|---|
| 存储段落增强数据 | 将文档段落扩展增强数据存储到文档索引中。 |
| 存储文档元数据 | 将提取的文档信息存储到文档索引中。 |
| 元数据提取 | 使用 LLM 从文档中提取元数据。 |
| 关键词提取 | 使用 LLM 对文档的每个段落进行关键词提取。 |
| 段落元数据提取 | 使用 LLM 从每个文档段落中提取元数据。 |
| 段落总结生成 | 对段落进行摘要。 |
| 表格高级总结生成 | 使用 LLM 生成表级摘要及分组级叙述摘要。 |
| 图片描述生成 | 使用图片描述增强段落。 |
| 文档摘要生成 | 对整个文档进行摘要。 |
| 表格行记录总结生成 | 使用表格描述增强段落。 |
后处理节点
对分块后的文本进行分词、向量化等后续处理,完成索引前的准备工作。
| 节点名称 | 功能描述 |
|---|---|
| 存储分块分词 | 将分段词元数据存储到数据库。 |
| 基于 SpaCy 为分块分词 | 使用 SpaCy 分词器进行分词。 |
| 向量化分块数据并存储 | 使用模型对段落进行嵌入,并将嵌入向量存储到向量数据库。 |
数据处理节点
提供流程控制与变量处理能力,用于构建更复杂的预处理逻辑。
| 节点名称 | 功能描述 |
|---|---|
| 变量聚合器 | 将多个变量分组聚合为输出变量,支持“取首个非空值”和“合并为列表”两种策略。聚合行为通过 set_output_mapping() 动态配置。 |
| 条件节点 | 根据条件对流程进行分支控制。条件判断逻辑由管道引擎在外部处理,节点本身不产生输出数据。 |
| 模板 | 使用 Jinja2 模板语法对各变量进行处理和格式化。 |
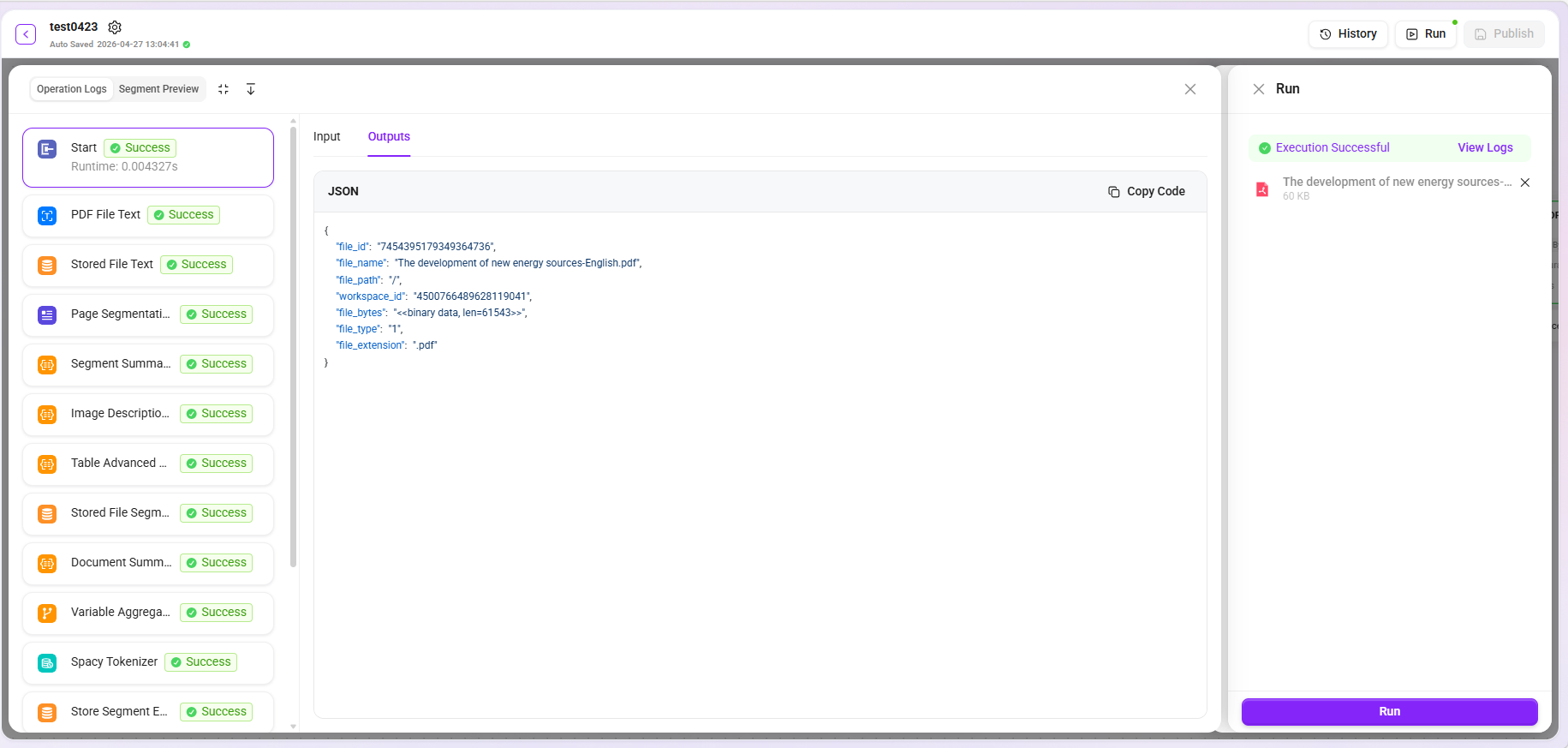
试运行
配置完成后,可通过试运行功能验证预处理流程是否按预期执行。系统支持从本地上传或从知识库中选择文件进行测试。
提示:为确保测试效率,建议上传文件大小不超过 5MB、页数不超过 20 页。
- 查看日志:点击“查看日志”可展开每个节点的详细输入与输出内容,便于逐节点排查问题,精准定位处理异常的具体环节。
- 片段预览:支持预览处理后的文本片段,直观判断分块、提取等环节的效果是否符合预期。
- 数据下载:受展示限制,预览区默认仅显示前 10 条数据。如需完整数据,可点击 “下载” 按钮获取全部处理结果。