検索
検索 Pipeline は、RAG(検索拡張生成)フローの重要な構成要素です。主にユーザーが質問したときに、ナレッジベースから関連する内容を探し、適切な断片を呼び出して、その後の回答生成に渡す役割を担います。異なる Agent や業務シナリオごとに独立した検索 Pipeline を設定することで、ユーザーは「どのように検索するか」「何を呼び出すか」「どのルールで結果を返すか」をより柔軟に制御でき、さらにテストやリリースの仕組みを通じて継続的に最適化することで、最終回答の正確性と制御性を向上させることができます。
検索 Pipeline の種類
システムは「基本オーケストレーション」と「高度なオーケストレーション」の 2 つのモードを提供します。シンプルなキーワード検索から、複雑なマルチチャネル再呼び出し、再ランキング、変数集約などの高度なフローまで対応し、開発者が検索と生成のチェーンを柔軟にカスタマイズできるよう支援します。
この 2 つのモードに対応して、システムにはそれぞれ default basic pipeline(基本オーケストレーション)と default advanced pipeline(高度なオーケストレーション)が組み込まれています。組み込み Pipeline は 変更不可・削除不可 ですが、コピーしてから変更 することができるため、初心者ユーザーでも公式テンプレートをベースに、自身の業務に合った検索フローを素早くカスタマイズできます。
| 比較項目 | 基本オーケストレーション | 高度なオーケストレーション |
|---|---|---|
| フローの影響範囲 | 開始ノードのより多くの属性を継承し、オーケストレーション全体が最終的な回答生成に直接影響します。 | フローは検索段階にのみ作用し、最終回答の出力には直接影響しません。 |
| 出力内容 | 回答 + 関連スニペット(ベクトルなどの詳細情報を含む) | 回答のみを出力(ベクトルなどの追加情報は含まない) |
| 適用シナリオ | 検索ロジックを深く制御し、フローが最終回答に影響することを望むシナリオ。 | 検索の再呼び出し品質のみを最適化し、回答生成は他のノードが独立して担当するシナリオ。 |
デフォルトの組み込み Pipeline は、機能面ですでに従来の RAG 検索機能を完全にカバーしており、そのまま使用することも、コピーして必要に応じてカスタマイズすることもできます。たとえば、質問の書き換えをカスタマイズしたり、フィルタリングルールを追加したりできます。
継承メカニズム
検索Pipelineは単独では使用できず、必ず特定の Agent にバインドする必要があります。バインド後、検索Pipelineはその Agent の基本設定を継承し、これらの属性を Pipeline 開始ノードの入力に渡します。
継承される属性:ユーザー入力、会話履歴、モデル選択、外部設定パラメータ
この仕組みにより、検索 Pipeline は Agent のコンテキストをシームレスに認識でき、重複設定を回避できます。
実行メカニズム
検索Pipeline の実行トリガー方式は、その種類によって異なります。
基本オーケストレーション
retrieval tool の実行時にトリガーされます。Agent 設定で対応するスイッチを有効にする必要があります。
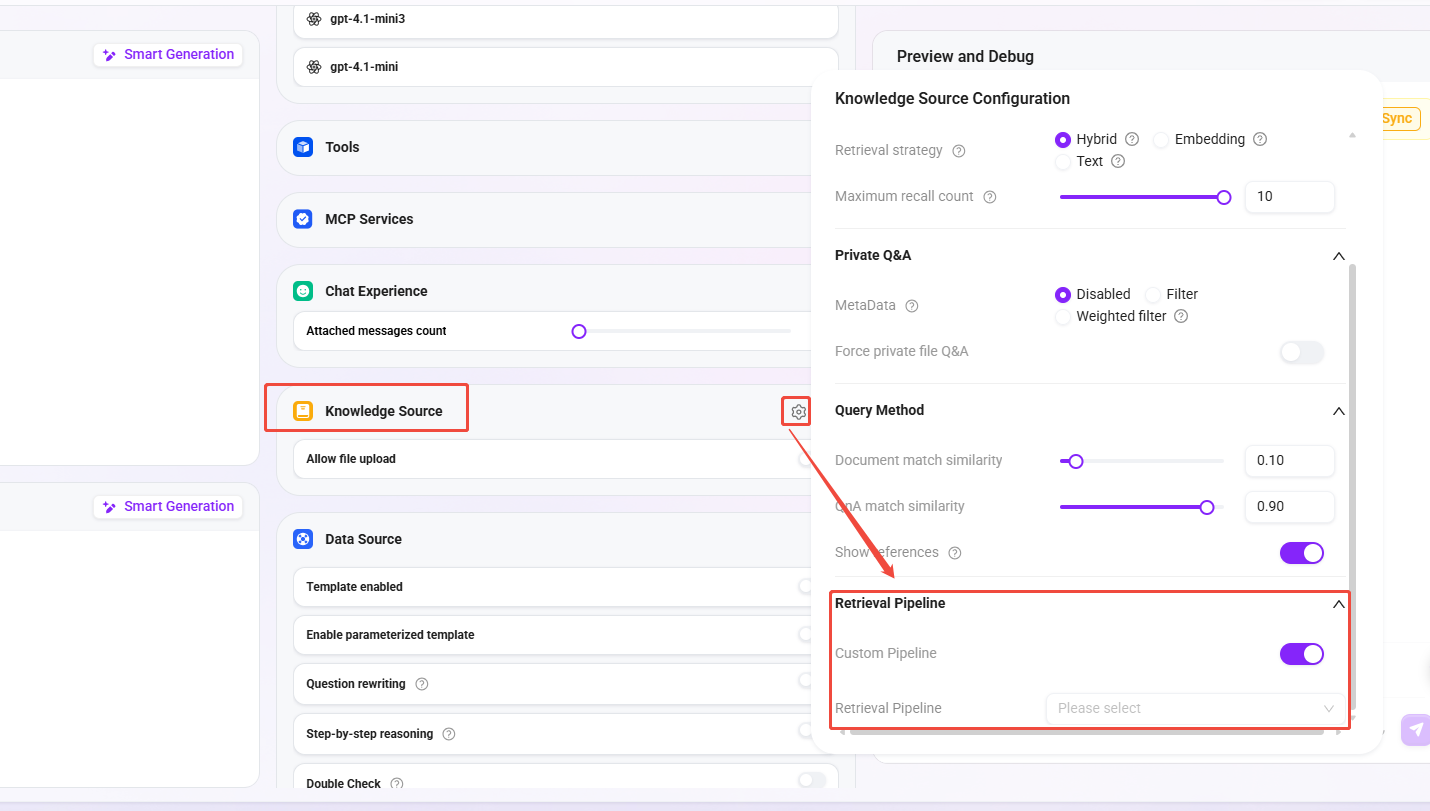
高度なオーケストレーション
対応する retrieval node の実行時にトリガーされます。ナレッジベースノード設定で対応するスイッチを有効にする必要があります。
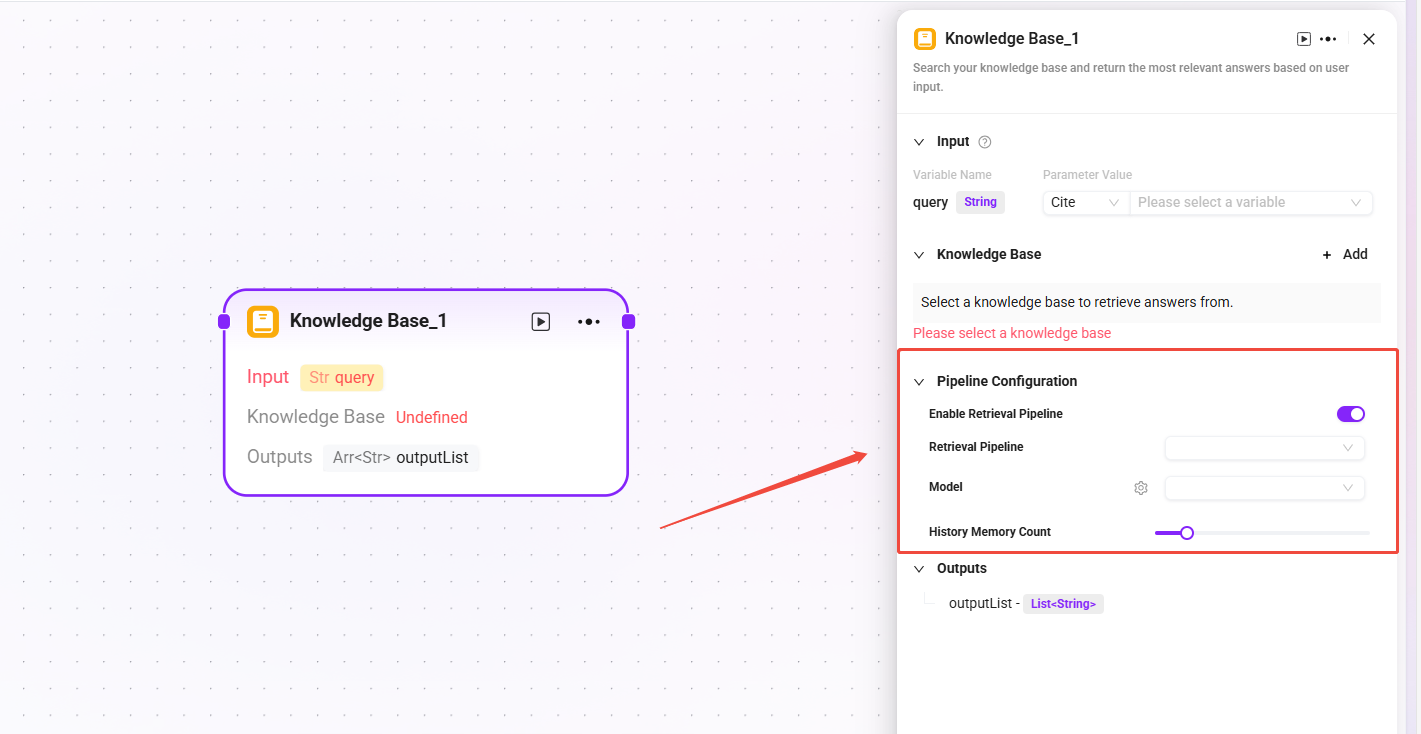
作成と設定
検索Pipelineの作成
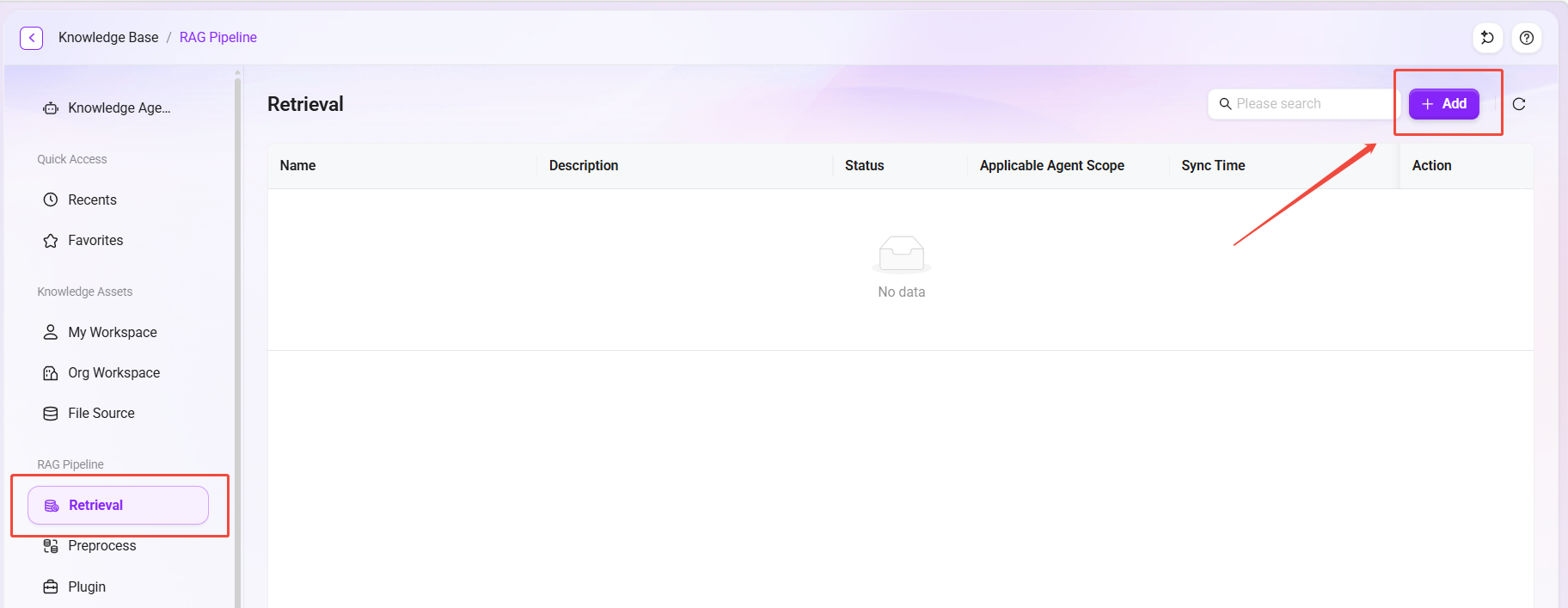
組み込み Pipeline を使用しない場合、ユーザーは以下の手順でカスタム検索Pipelineを一から作成することもできます。
- 検索ページ右上の 「新規追加」 ボタンをクリックして、作成ページに入ります。
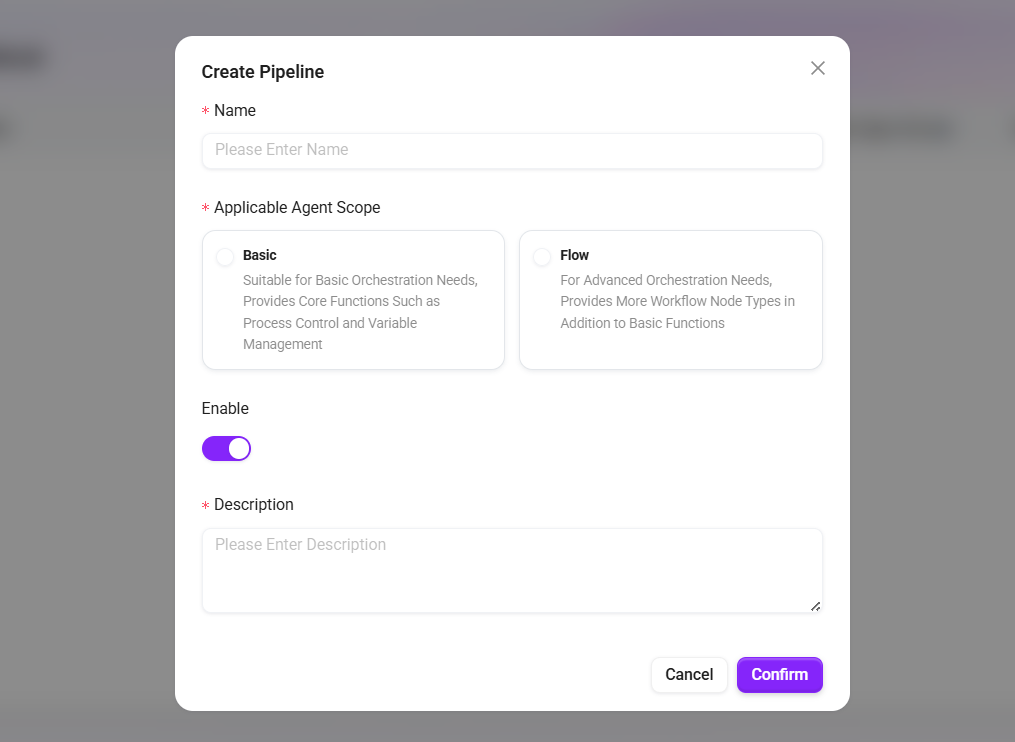
- 基本情報を入力します。
- 名称:検索の名称。
- 適用 Agent 範囲:
- 基本オーケストレーション:基本オーケストレーションの要件に適しており、フロー制御、変数管理などの中核機能を提供します。
- 高度なオーケストレーション:高度なオーケストレーションの要件に適しており、基本機能に加えて、より多くのフローノードタイプを提供します。
- 有効化:検索を有効にするかどうかを制御します。
- 説明:適用シナリオや設定のポイントを補足説明します。
- 「保存」 をクリックして作成を完了します。
検索Pipelineの設定
作成完了後、検索 Pipeline の「 」編集アイコンをクリックして設定画面に入ります。ユーザーは必要に応じてノードライブラリからノードを追加し、接続線によってカスタム検索フローを構成できます。
」編集アイコンをクリックして設定画面に入ります。ユーザーは必要に応じてノードライブラリからノードを追加し、接続線によってカスタム検索フローを構成できます。
ノードタイプ詳細
ノードライブラリには豊富な機能ノードが用意されており、検索フロー内の各処理段階を構築するために使用されます。
ヒント:ノードに関するより詳細な説明については、任意のノードの設定ページ右上にある「
」をクリックして説明ドキュメントをご確認ください。
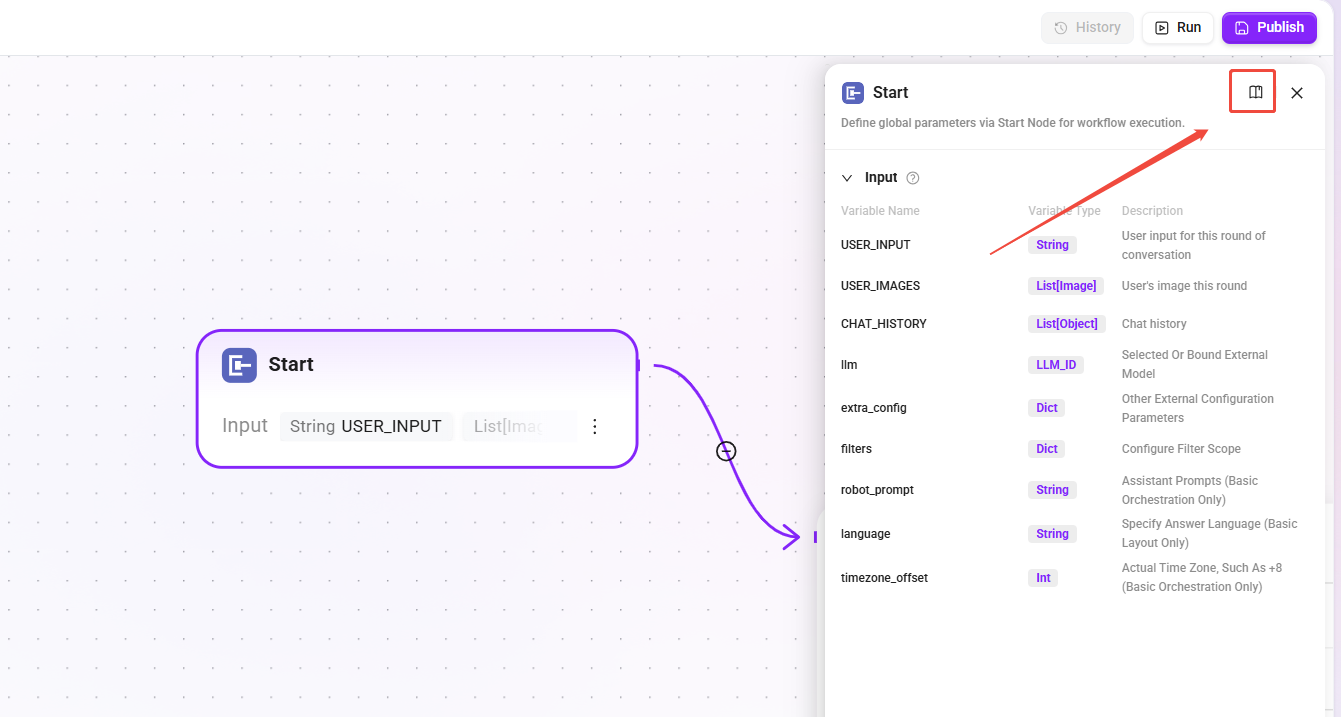
開始
- 機能:RAG Pipeline の入口ノードであり、ユーザー入力および関連設定属性を渡します。
- タイプの違い:
- 基本オーケストレーション:追加パラメータ(
robot_prompt、language、timezone_offset)を含みます。 - 高度なオーケストレーション:標準パラメータセットです。
- 基本オーケストレーション:追加パラメータ(
- 役割:Pipeline が Agent 設定を継承するための入口として機能します。
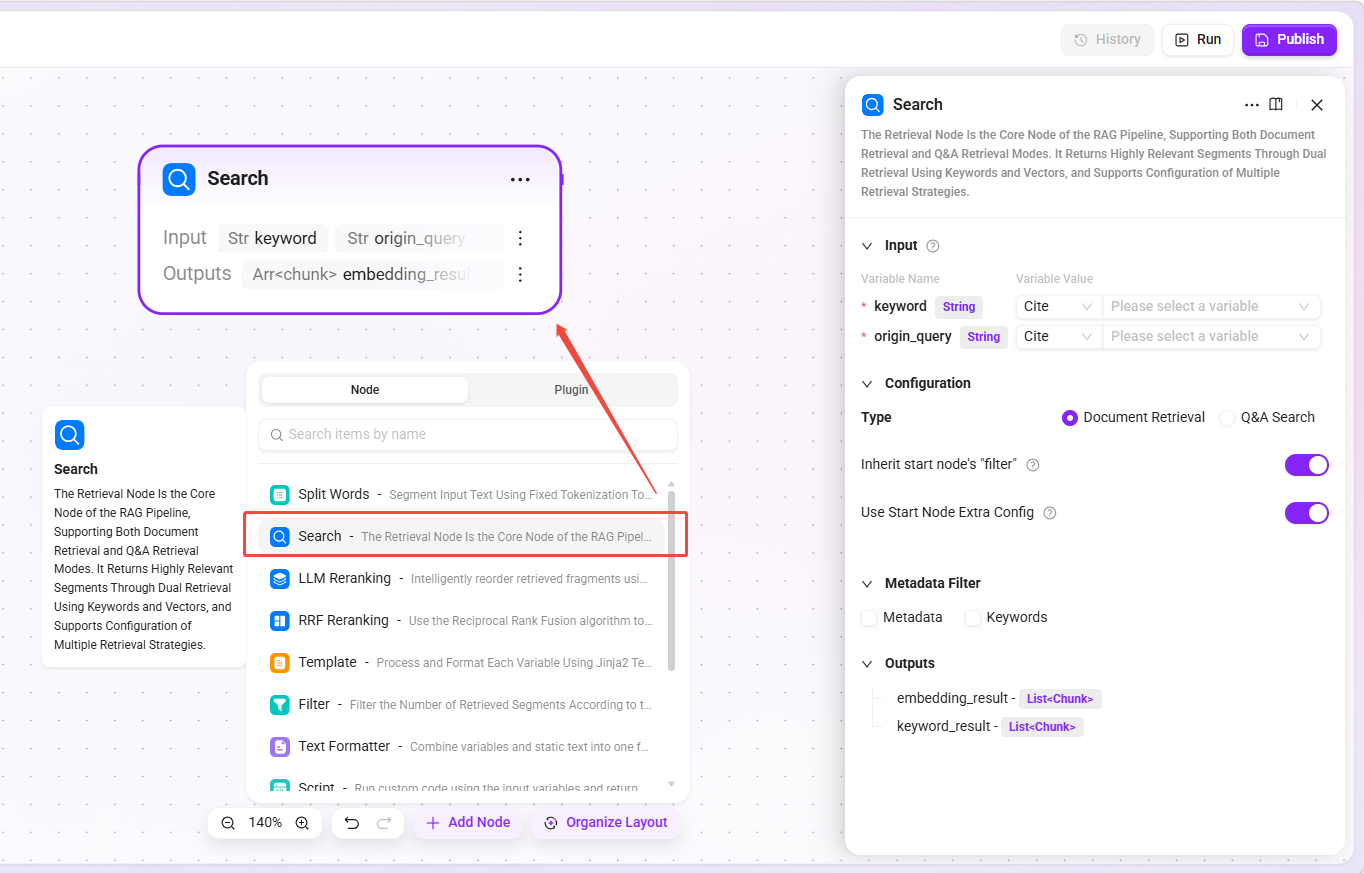
検索
- 機能:中核となる検索ノードで、ドキュメント検索 と Q&A 検索 の 2 つのモードをサポートし、キーワードとベクトルの二重検索によって類似度の高いスニペットを返します。
- 検索タイプ:
- ドキュメント検索:ユーザーがアップロードしたドキュメント空間。
- Q&A 検索:管理されている質問回答ペア。
- 適用シナリオ:ナレッジベース Q&A、ドキュメント内容検索、FAQ マッチング。
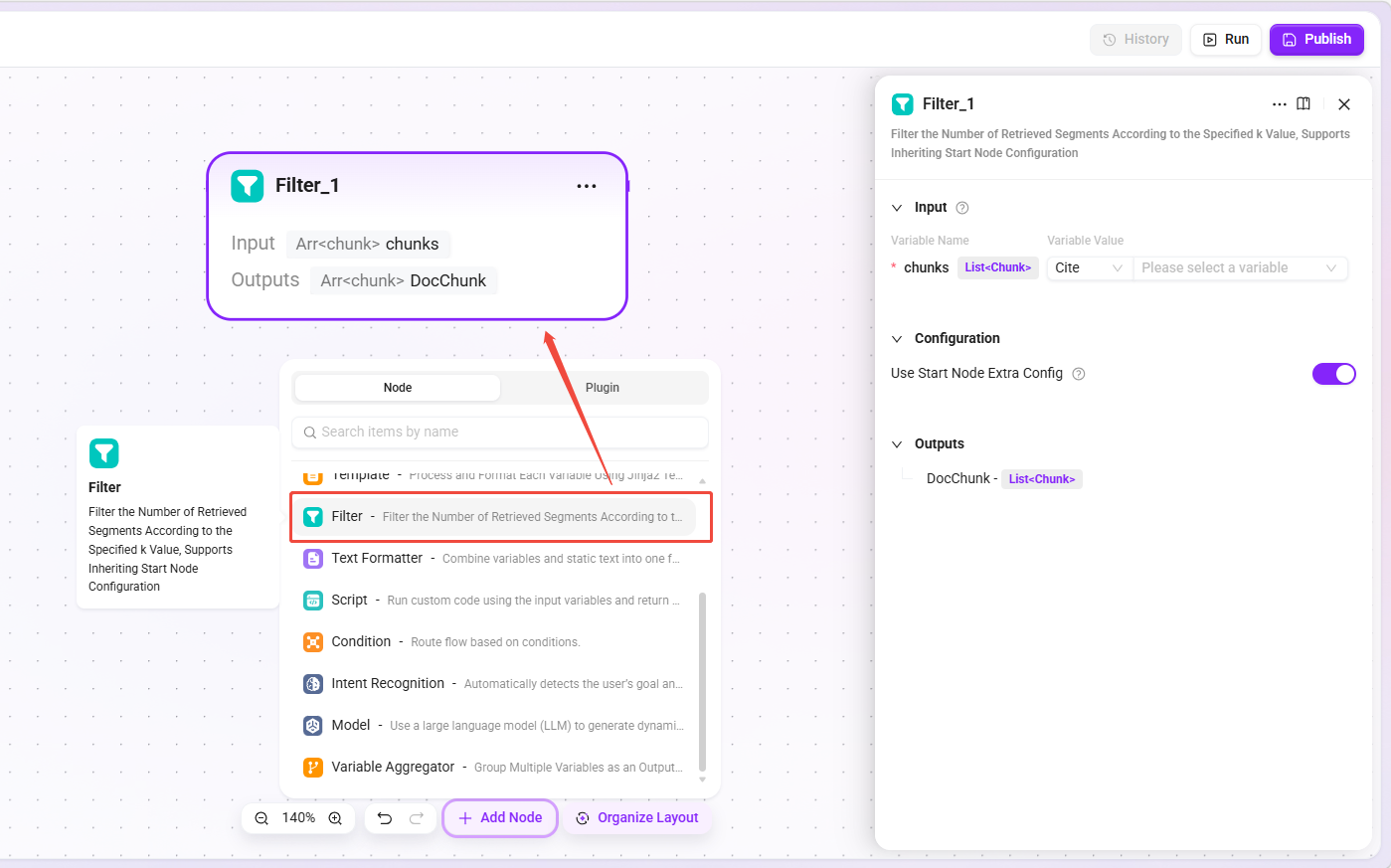
フィルタノード
- 機能:指定した
k値に基づいて検索で返されたスニペット数を絞り込み、検索結果数を制御します。 - 継承設定:開始ノードからの継承を選択した場合、基本オーケストレーションでは Agent 検索戦略の「最大再呼び出し数」を継承し、高度なオーケストレーションでは検索ノードの「Top K」を継承します。
- 適用シナリオ:無関係なスニペットが多すぎて生成結果に干渉するのを防ぎつつ、十分な関連情報を確保します。
LLM 再ランキングノード
- 機能:大規模言語モデルを使用して検索スニペットをインテリジェントに再ランキングし、組み込みの固定プロンプトによってスニペットと質問の関連性を評価します。
- モデル選択:開始ノードのモデル設定を継承することも、個別に指定することもできます。
- 適用シナリオ:高精度なランキングが必要な Q&A シナリオ、複数ソースの検索結果を統合した後の精密ランキング。
- 推奨:コストを抑えるため、まず他の方法で粗いランキングを行い、その後に LLM で精密ランキングを行ってください。
RRF 再ランキングノード
- 機能:Reciprocal Rank Fusion(逆順位融合)アルゴリズムを使用して、異なる検索ソースからのスニペットを重み付きで再ランキングします。
- 入力:複数ソースのスニペットリストと対応する重み。
- 適用シナリオ:ベクトル検索とキーワード検索結果の統合、複数ナレッジベース検索結果の統合、異なる検索戦略結果の統合。
変数アグリゲーター
- 機能:複数の変数をグループ化して出力変数に集約し、「最初の非空値を取得」と「リストとして結合」の 2 つの戦略を提供します。
- 適用シナリオ:マルチチャネル検索結果の合流、条件分岐後のデータ統合、代替案の優先順位選択。
分かち書きノード
- 機能:入力テキストを固定の分かち書きツールで処理し、
|区切りのキーワード文字列を出力します。 - 適用シナリオ:検索ノードに
keyword入力を提供する、ユーザーの質問からキーワードを抽出する。
テンプレートノード
- 機能:Jinja2 テンプレート構文を使用して各変数をフォーマット処理し、文字列連結、条件分岐、ループなどをサポートし、タイムゾーン処理メソッドも組み込まれています。
- 適用シナリオ:モデルに送信するプロンプトの構築、検索結果のフォーマット、返信内容の動的生成。
モデルノード(RAG LLM Node)
- 機能:大規模言語モデルにメッセージを送信して応答を取得し、開始ノードのモデル設定を継承するか、モデルを個別に指定することをサポートします。
- 高度なオーケストレーションのモデルノードとの違い:開始ノードのモデル設定を継承することを選択できるため、Pipeline 内で使用されるモデルをユーザーとの対話と一致させることができます。また、個別指定も可能です。
- 基本オーケストレーションの特別設定:
Streaming Outputスイッチ。オンにすると、モデル応答が会話内でストリーミング出力され、体験が向上します。
プラグインノード
- 機能:システム内で設定済みのプラグインを呼び出し、上流ノードのパラメータをプラグインに渡して実行し、返却結果を取得します。
- 適用シナリオ:外部 API の呼び出し、カスタム業務ロジックの実行、データ形式変換、サードパーティサービスの呼び出し。
ヒント:詳細については、プラグインの関連概念セクションを参照し、プラグインの使用方法をご確認ください。
終了ノード
- 機能:RAG Pipeline の終了ノードであり、上流ノードから渡された入力パラメータを収集し、最終出力として返します。
- 適用シナリオ:処理済みスニペットリストの出力、モデル生成回答の返却(基本オーケストレーション専用)。
ベストプラクティスの提案
- 初心者向け:まずは “default basic pipeline” または “default advanced pipeline” をそのまま使用し、デフォルトの動作を理解してください。
- 必要に応じたカスタマイズ:組み込み Pipeline をコピーし、検索戦略、フィルタ条件、または質問書き換えロジックを変更して、特定の業務要件を満たしてください。
- テストと検証:変更後の Pipeline を独立環境でテストし、再呼び出し効果を確認してから本番 Agent にバインドしてください。
- 継承に注意:Pipeline は Agent の多くの属性を継承するため、Agent 設定時にはこれらの属性が期待どおりであることを確認してください。
- コスト管理:LLM 再ランキングを使用する際は、まずフィルタリングや粗いランキングで入力スニペット数を減らし、リソース消費を抑えてください。