工作流创建Agent
选择智能体类型
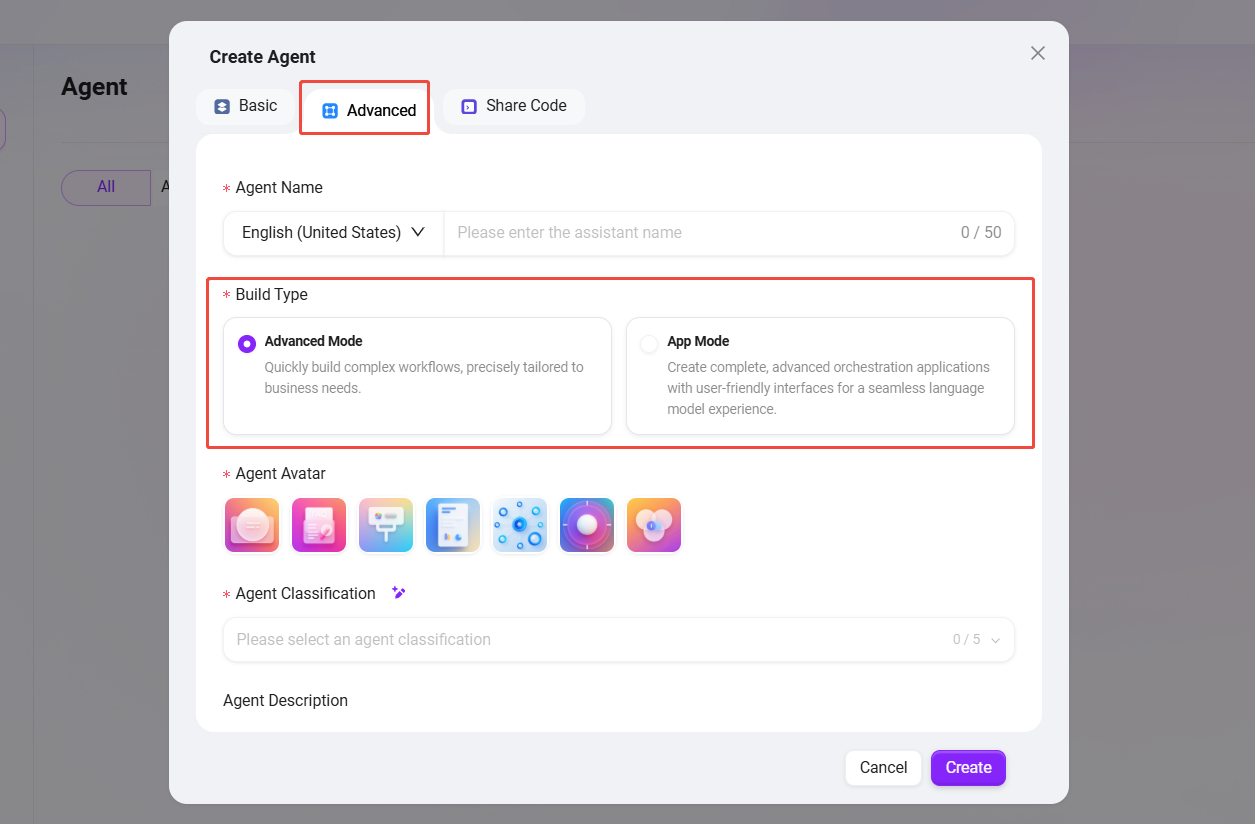
在创建智能体时,选择 “高级编排”(初始创建步骤与普通智能体相同)。
- 适用Agent范围:提供两种核心模式,以满足不同复杂度的业务需求。
- 进阶模式:快速构建基于对话的复杂工作流程。
- 应用模式:创建完整、先进的编排应用程序,提供用户友好的界面,带来流畅的大语言模型交互体验。
进阶模式
在基础智能体之上增强的问答型智能体,核心能力集中于多轮对话与知识问答。
特点:
- 以自然语言对话为主要交互方式。
- 适合需要灵活、开放式对话交互的业务场景。
典型场景:
- 企业内部知识问答智能体
- 产品FAQ与技术支持助理
- 工单处理咨询智能体
应用模式
用于构建带有带UI的Agent编排应用,具有特定输入结构、用于完成特定任务,不以自由对话为主,而是专注于执行既定任务流程的智能体。
特点:
- 具有固定、可定制的输入界面(如上传文件、填写表单字段)。
- 重点是执行某个自动化或半自动化的任务流程。
- 支持复杂的输入类型,如文件、结构化数据(Structured Data),适用于需要严格输入输出格式的业务场景。
典型场景:
- 合同审查 App(上传合同 → 自动标记风险)
- 文档分析 App(上传文档 → 自动生成关键内容)
- 数据清洗 App(上传 Excel → 自动处理数据)
配置工作流
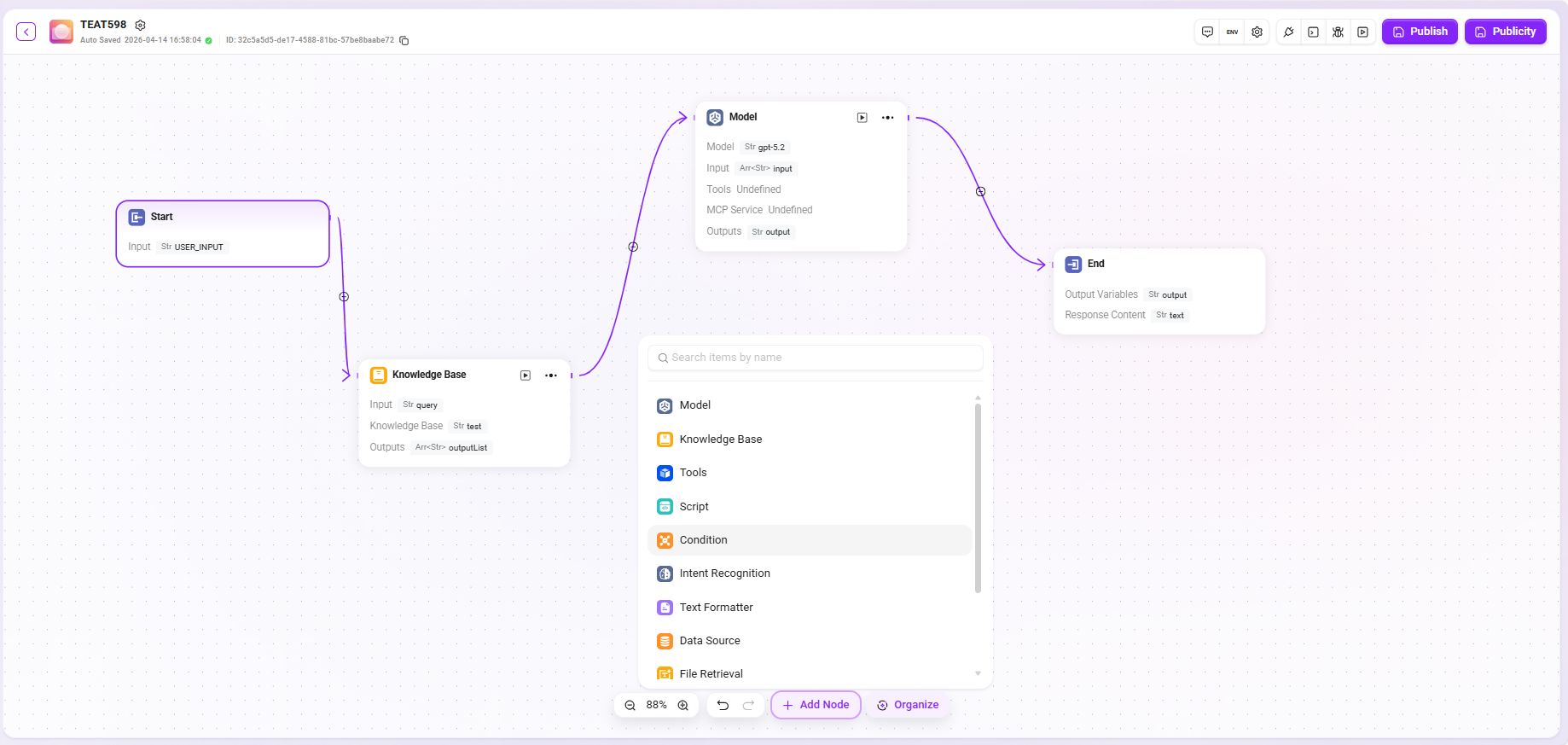
根据用户的实际业务逻辑,通过拖拽和连接以下节点来配置工作流:
- 开始、结束:工作流的默认输入与输出模块,支持自定义输入参数及输出字段;
- 模型选择所需的大语言模型,接收其他模块传递的变量,编辑提示词并定义输出消息,以变量形式保存;
- 知识库检索:在选定的知识库中,根据输入变量召回最匹配的信息,加以返回;
- 工具:选择其中一个内置工具,进行经过该工具的输入与输出操作;
- 脚本:根据其他模块中的输出变量,进行代码函数的自定义编写与创建;
- 选择器:根据设定条件判断流程分支走向,实现逻辑判断;
- 意图识别:用于用户输入的意图识别,并将其与预设意图选项进行匹配;
- 文本格式器:用于处理多个字符型变量的格式;
- 数据来源:指定数据来源,以扩展流程中可引用的变量内容范围;
- 文件检索:在上传的文件中搜索,根据输入的问题查找相关答案;
- 循环:对列表中的每一项重复执行一组任务,并可选择并行处理;
- 变量赋值:对已定义的变量进行赋值或更新,用于在工作流节点间传递和修改数据。
- 工作流:引用并调用其他已配置的工作流,实现模块化嵌套与复用。
节点详细介绍
- 节点数量限制:单个工作流中节点总数上限为 100 个,循环节点内部节点数量上限为 1000 个。
- 全局注意:需先连接上前置节点,才能选择其他节点的变量作为当前节点的输入。此规则适用于所有需要引用前置节点输出的节点。
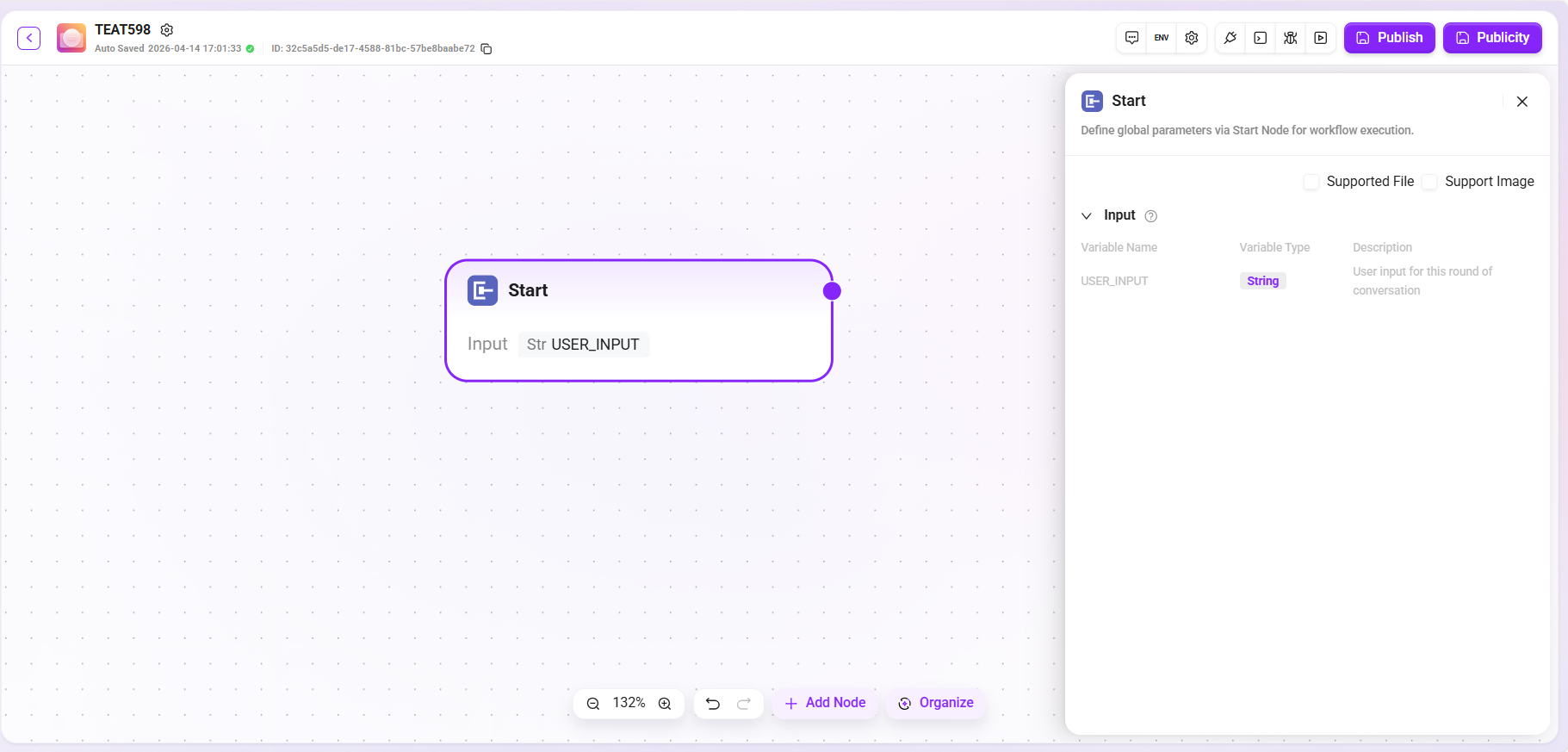
开始
开始节点是工作流的起始节点,用于配置工作流运行的全局参数,支持自定义选择输入图片和文件。
- 功能:预设完成任务所需的基本信息(输入参数)。当满足触发条件时,系统自动收集并传递这些参数以启动流程。
- 处理逻辑:直通传递,将输入内容原样传递给后续节点。
- 输出:所有输入内容。
- 特别说明(应用模式):在此模式下,开始节点支持定义多种复杂的入参类型,包括文本、数字、选择等字段,为构建专业化应用提供了高度定制化的输入界面。
提示:在开始节点中定义的输入参数,将在智能体对话过程中被 LLM 读取,使其能够在适当时机启动工作流并准确填入所需信息。
进阶模式:
应用模式:
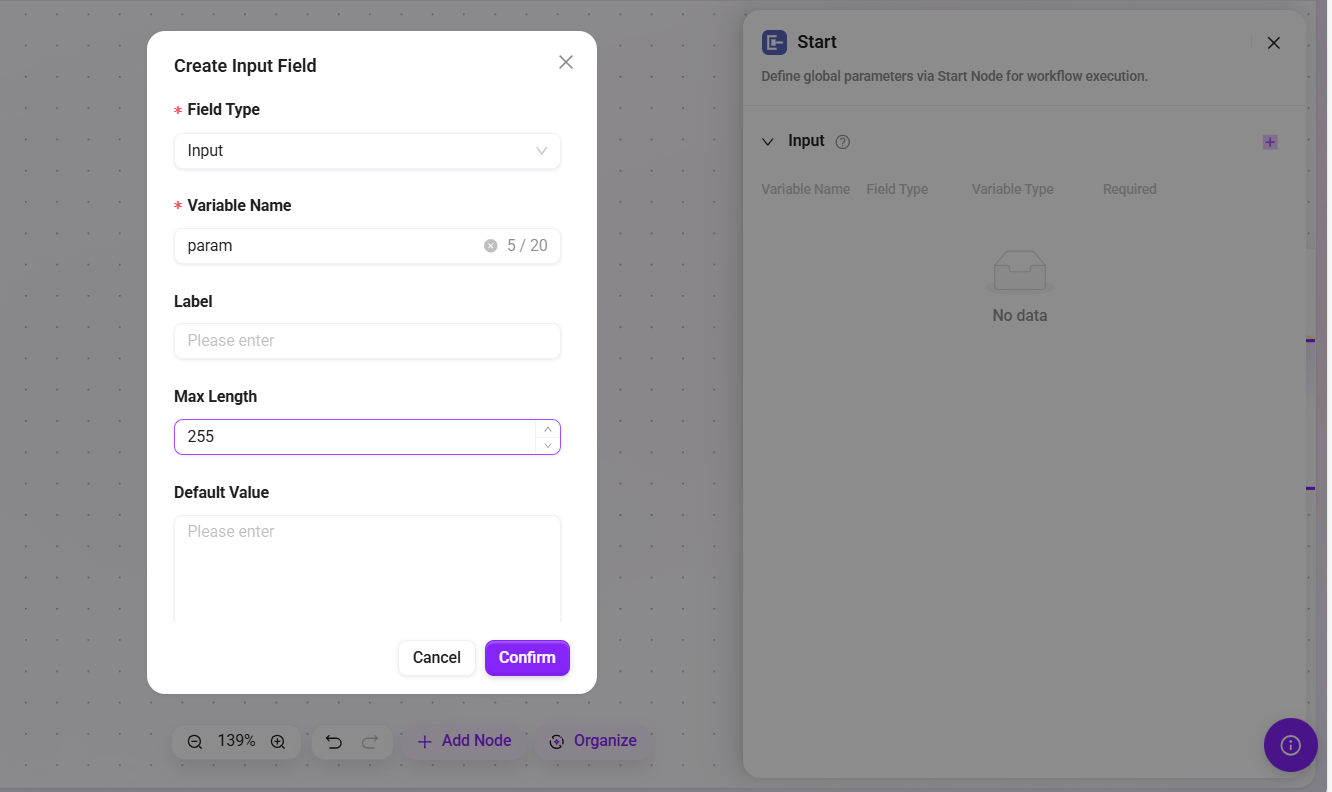
模型
使用大语言模型(LLM)根据输入变量和自定义提示词生成动态回应。
- 模型:下拉选择已配置的可用模型。
- MCP服务:可选配置项,用于接入 MCP 服务以扩展模型能力
- 工具:可选配置项,用于为模型添加内置工具调用能力
- 输入:定义输入变量并为其分配值,用于提示词或流程中。每个变量可以引用固定值或其他变量的输出变量。
- 提示词配置
- 系统消息:为对话提供高层级的角色或行为指导,支持通过
{{变量名}}格式引用输入参数中的变量(提示词内容上限 5000 字符)。 - 历史记忆条数:取值范围 0–20,控制模型处理时携带的历史对话轮次数量。
- 用户消息:向模型传递具体指令、查询或文本输入。同样支持
{{变量名}}格式引用变量。
- 系统消息:为对话提供高层级的角色或行为指导,支持通过
- 处理逻辑:将输入内容提交至大语言模型(LLM)进行处理,模型根据配置的提示词与上下文生成对应回答。
- 输出:模型生成的文本内容。
💡 提示:需先连接上前置节点,才能选择其他节点的变量作为当前节点的输入。
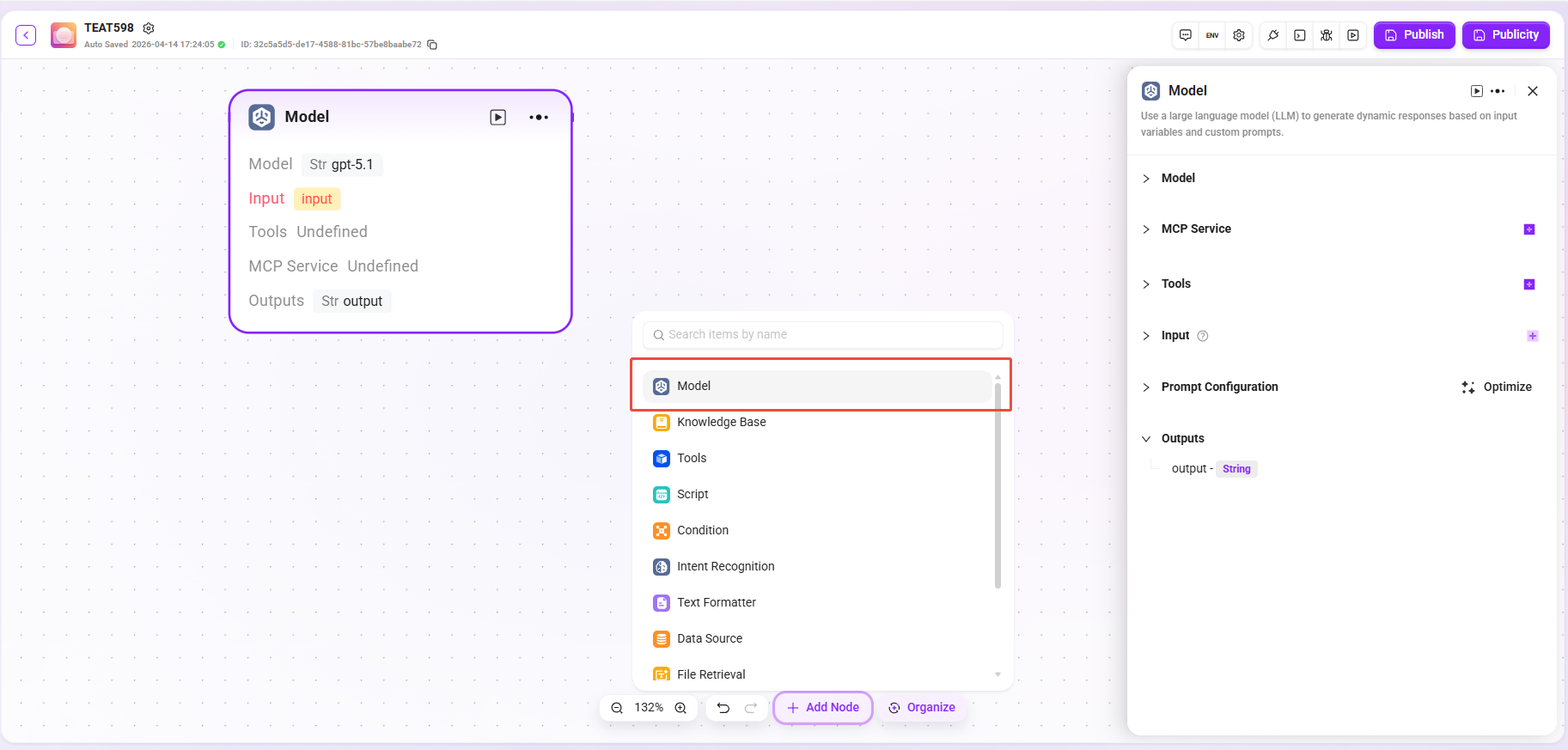
知识库检索
在知识库中搜索,并根据用户输入返回最相关的答案。
- 输入:通过定义变量名及设置参数值,为知识库检索提供检索关键词等原始数据。
- 处理逻辑:根据输入和参数检索知识库,返回片段或FAQ。
- 知识库检索:选定特定的知识库作为检索范围,系统将在这个范围内查找匹配信息。
- 检索策略:知识检索是从知识库获取信息的方式,采用不同的检索策略能够更有效地定位正确信息,从而提升生成答案的准确性和可用性。
- 元数据过滤(预览):文档检索过程中对召回片段进行过滤,减少噪声,提升数据质量和处理效率。
- 最大召回数量:用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整分段数量。
- 文档匹配近似度:取值范围 0–1,用于控制召回文档与查询的相似度阈值。
- 问答对匹配近似度:取值范围 0–1,用于控制召回的问答对与查询的相似度阈值。
提示:设置过高可能导致召回段落超过Token限制,超过Token部分的低匹配段落将不会传输到大模型。
- Pipeline 配置:选择是否开启Pipeline搜索。
- 输出:将从知识库中检索到的匹配信息,以指定变量的形式输出,供后续流程使用。
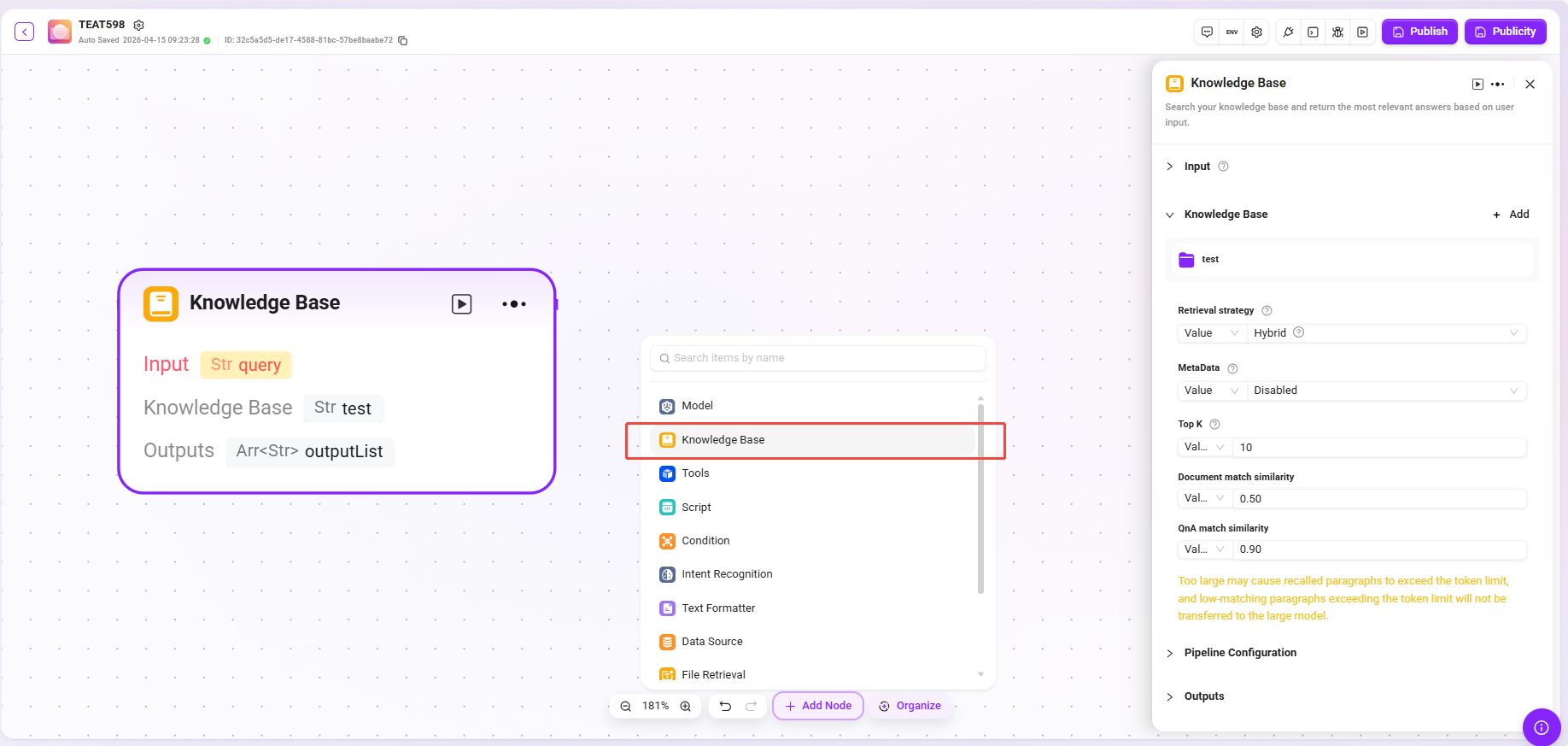
工具(示例)
- 处理逻辑:根据所选工具类型,执行对应的输入输出动作,并将处理结果传递给后续节点。
- 网站读取:能读取网页上的静态文字(无法获取动态加载的内容)。
- 文本生成图片:根据描述性文本生成图像,并返回图片地址。
- 谷歌搜索:调用搜索引擎返回搜索结果。
💡 提示:高级编排模式下添加工具只允许添加内置工具,无法添加自定义工具。
脚本
编写代码,处理输入变量来生成返回值。
- 输入:用于接收外部传入的变量,是代码运行所需数据的入口,为后续代码处理提供原始数据。
- 配置参数:对代码运行相关参数进行设置。
- 最大运行时长(Maximum Runtime):设置代码执行的时间上限(最长 600 秒),防止程序陷入长时间运行。
- 代码输入(Code Input):参考代码示例编写一个函数的结构,你可以直接使用输入参数中的变量,并通过return一个对象来输出处理结果。此功能不支持编写多个函数,即使仅有一个输出值,也务必保持以对象的形式return
- 处理逻辑:
- 在安全的沙箱环境中运行代码(基于 RestrictedPython 或指定平台)。
- 限制运行时长和访问权限,避免安全风险。
- 输出结果:代码运行处理完输入数据后,将结果以指定变量形式输出,是代码处理结果的出口。需要自己设定输出变量
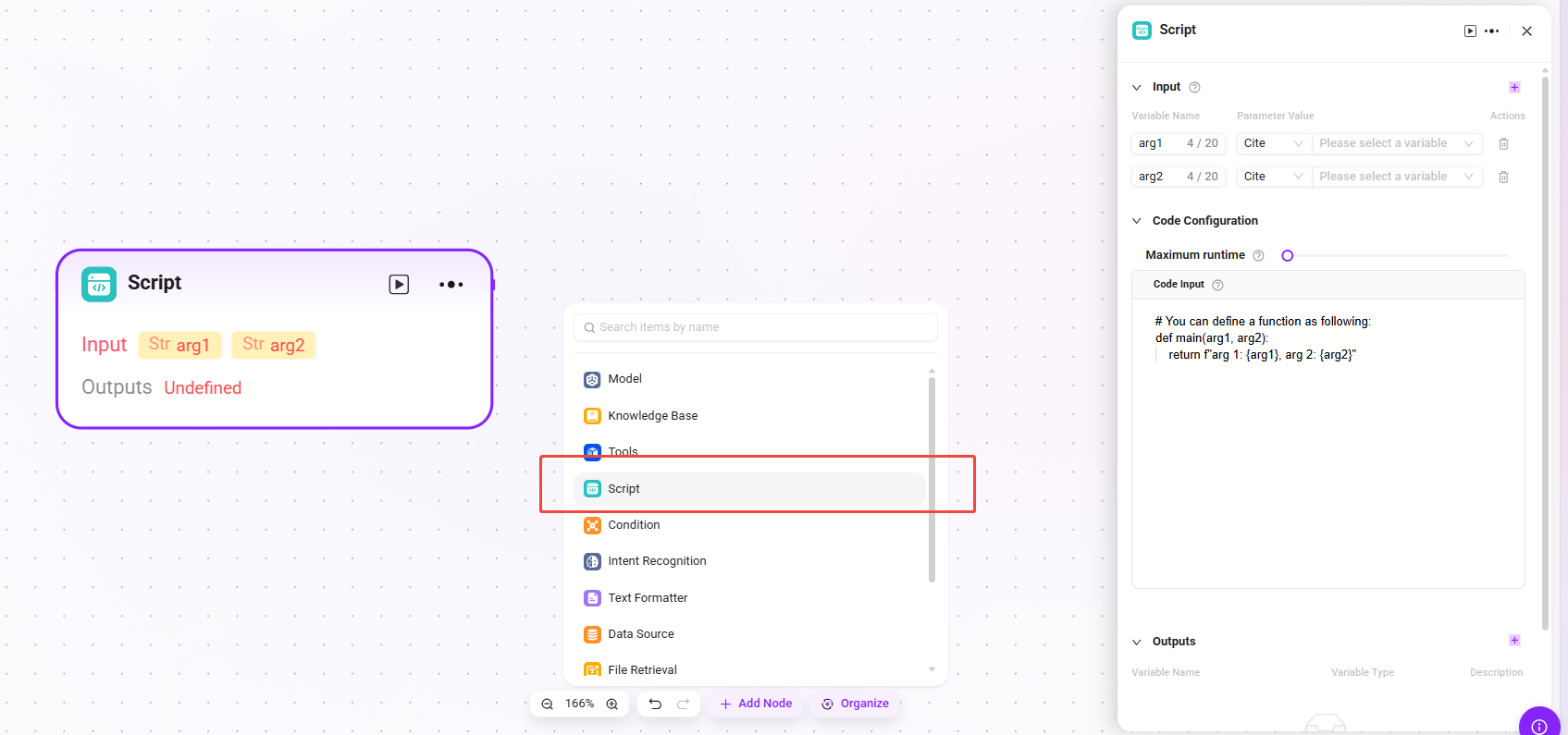
选择器
在流程编排中起条件判断作用。它连接多个下游分支,通过设定的条件来决定执行路径。
- 条件分支:
- 可设置多个条件,如 “if - 优先级 1”。分支数量无限制,但条件总数上限为 20 个。
- 通过配置引用变量、选择条件(如等于、大于等比较逻辑)、比较值,来判断条件是否成立。若成立,则运行对应的分支流程。
- 处理逻辑:根据不同条件走不同路径(如果没有满足条件的,就走 Else)。
- 输出结果:没有直接输出,只决定下一个节点的走向。
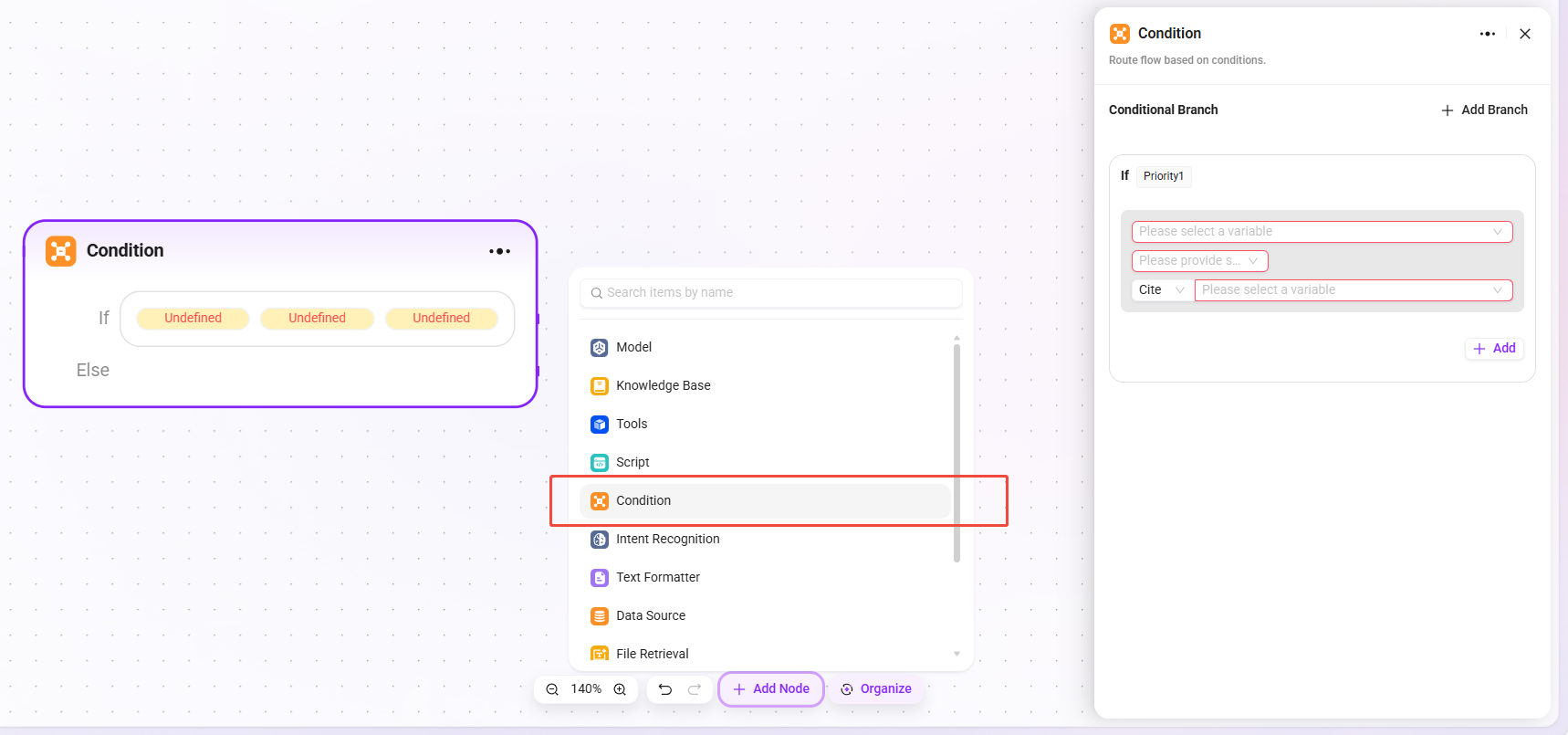
意图识别
意图识别是自然语言处理中的关键环节,该模块作用是分析用户输入内容,确定其真实意图并匹配预设置选项。
- 模型:选择用于意图识别的模型,模型决定了意图识别的能力和效果。
- 意图匹配:可预先输入用户意图描述作为匹配标准,也能新增其他意图,系统据此判断用户输入符合哪种预设意图。
- 高级设置:
- 系统提示:可自定义提示内容,支持引用输入变量以优化提示效果(提示词内容上限 5000 字符)。
- 历史记忆条数:设置参考的历史对话轮次,使模型结合上下文信息提升识别准确性。
- 处理逻辑:判断用户的真实意图,把输入分类到对应类别。
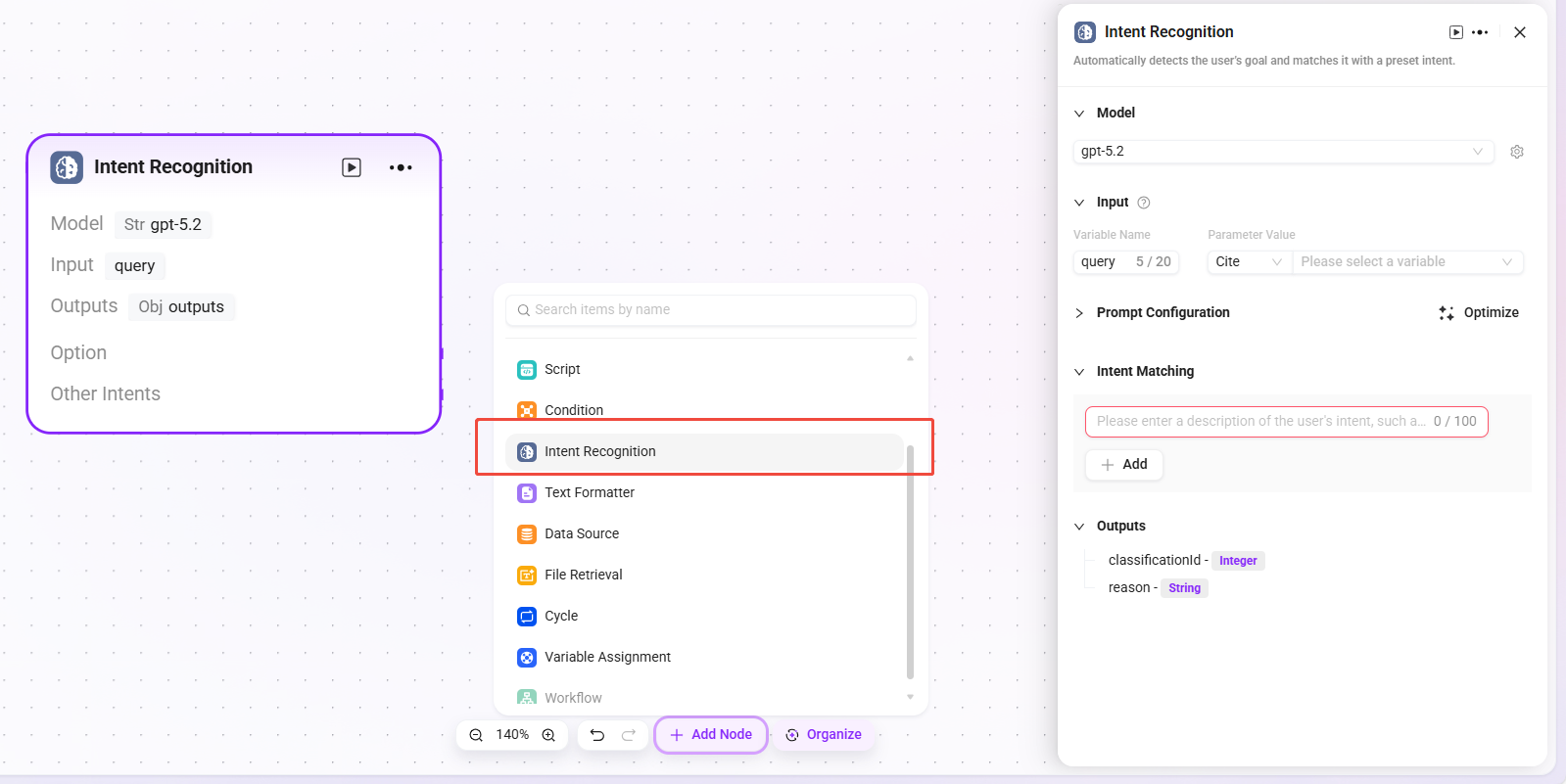
文本格式器
用于将变量和固定文本组合成一个格式化的字符串。
- 输入:可定义变量名,并通过引用方式获取参数值,为后续文本处理提供原始字符串数据。
- 处理逻辑:把文本做简单加工。
- 字符串拼接
- 字符串分割
- 分割符:可自定义或选择分隔符
- 字符串拼接:提供文本编辑区域,可按需求使用变量名方式引用输入变量,对多个字符串进行拼接等格式处理。
- 使用限制:单个工作流中,文本格式器节点的数量上限为 20 个。
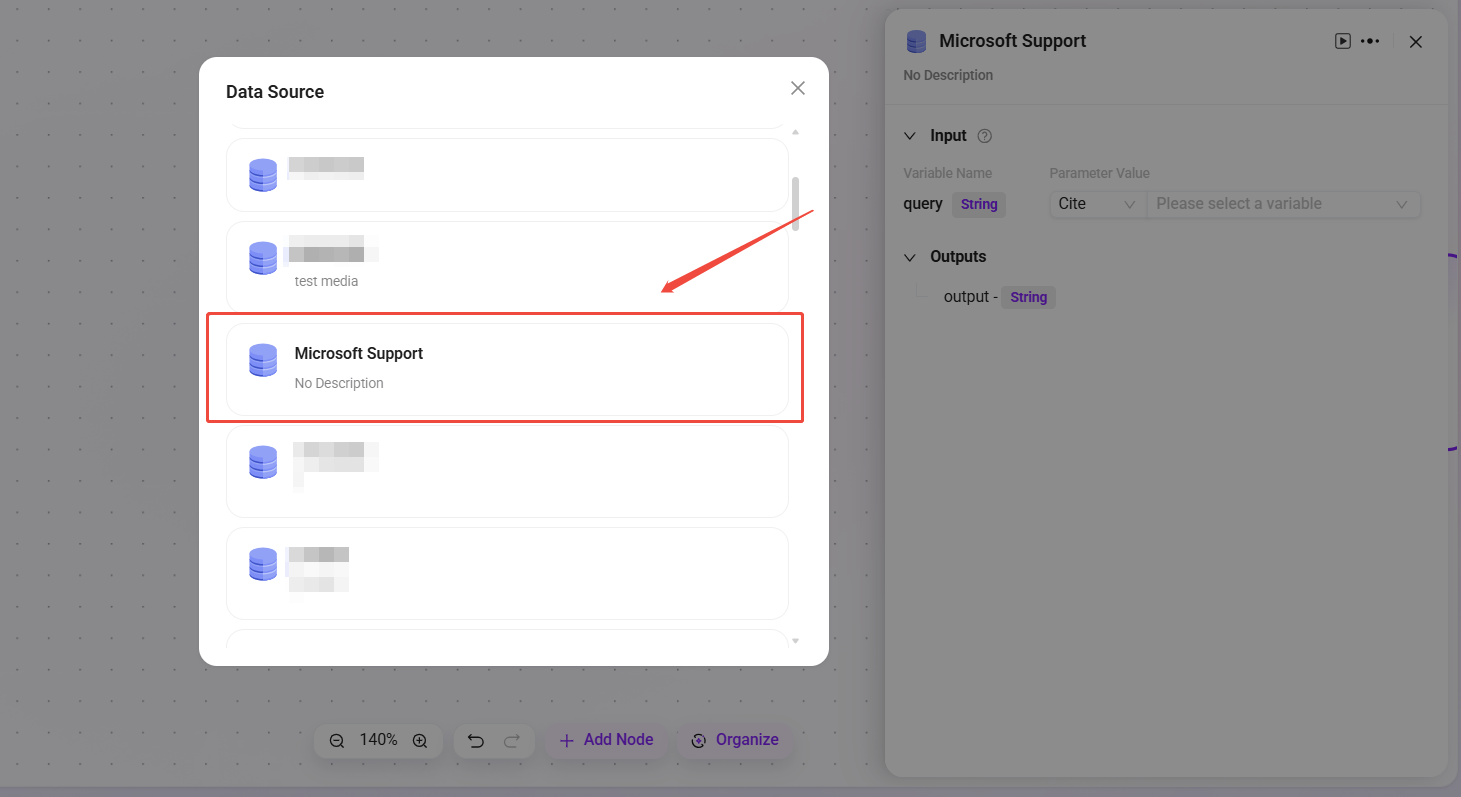
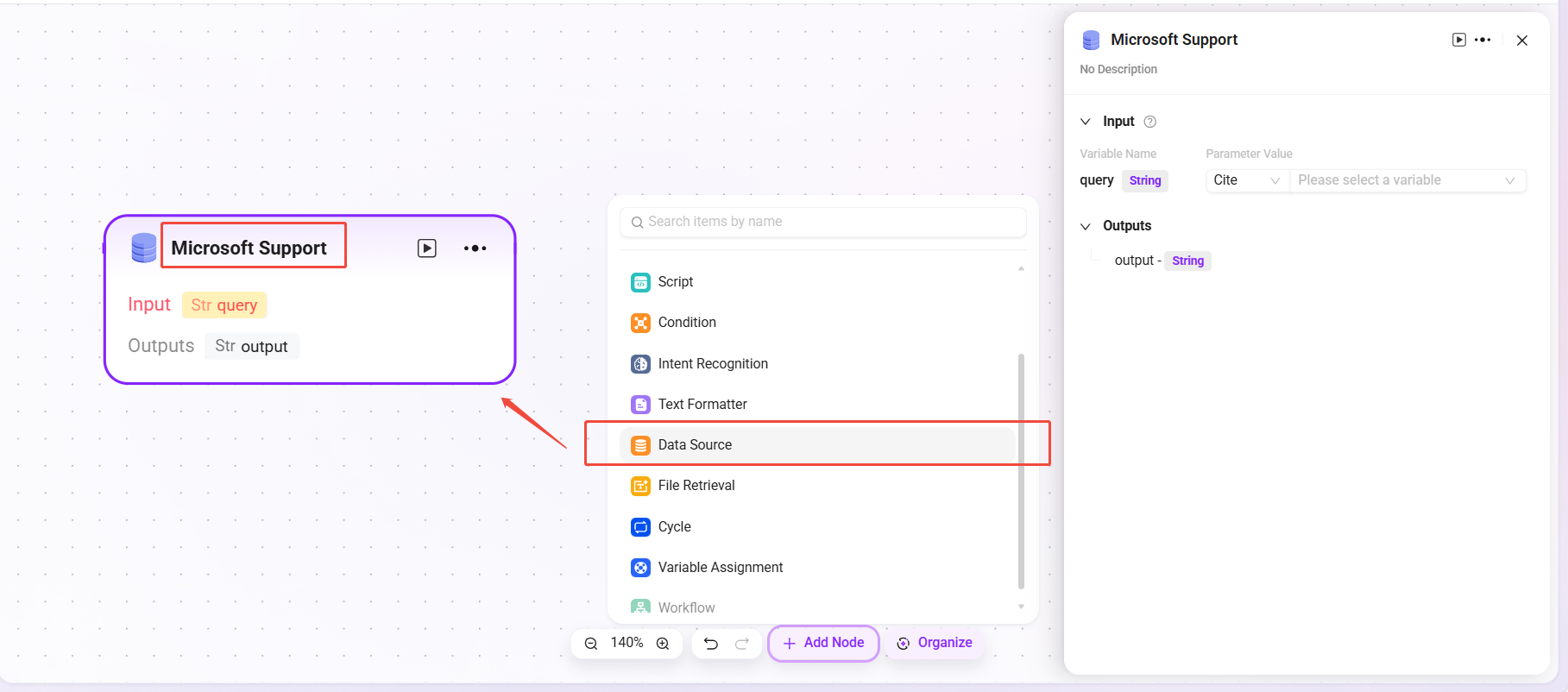
数据来源
- 数据来源:选择要接入的数据源。
- 处理逻辑:把自然语言转成SQL查询数据库,返回结果。
- 输出:将数据源的数据进行输出,输出给下一个节点。
文件检索
文件检索是对文件内容进行检索等操作的功能模块。
- 输入:通过定义变量名并引用参数值来提供检索关键词等输入信息,为文件内容查找提供依据。
- 文件:可添加需要处理的文件到该节点,确定检索的文件范围。
- 处理逻辑:根据输入的检索关键词,在指定的文件范围内进行内容匹配与搜索,定位相关片段或信息。
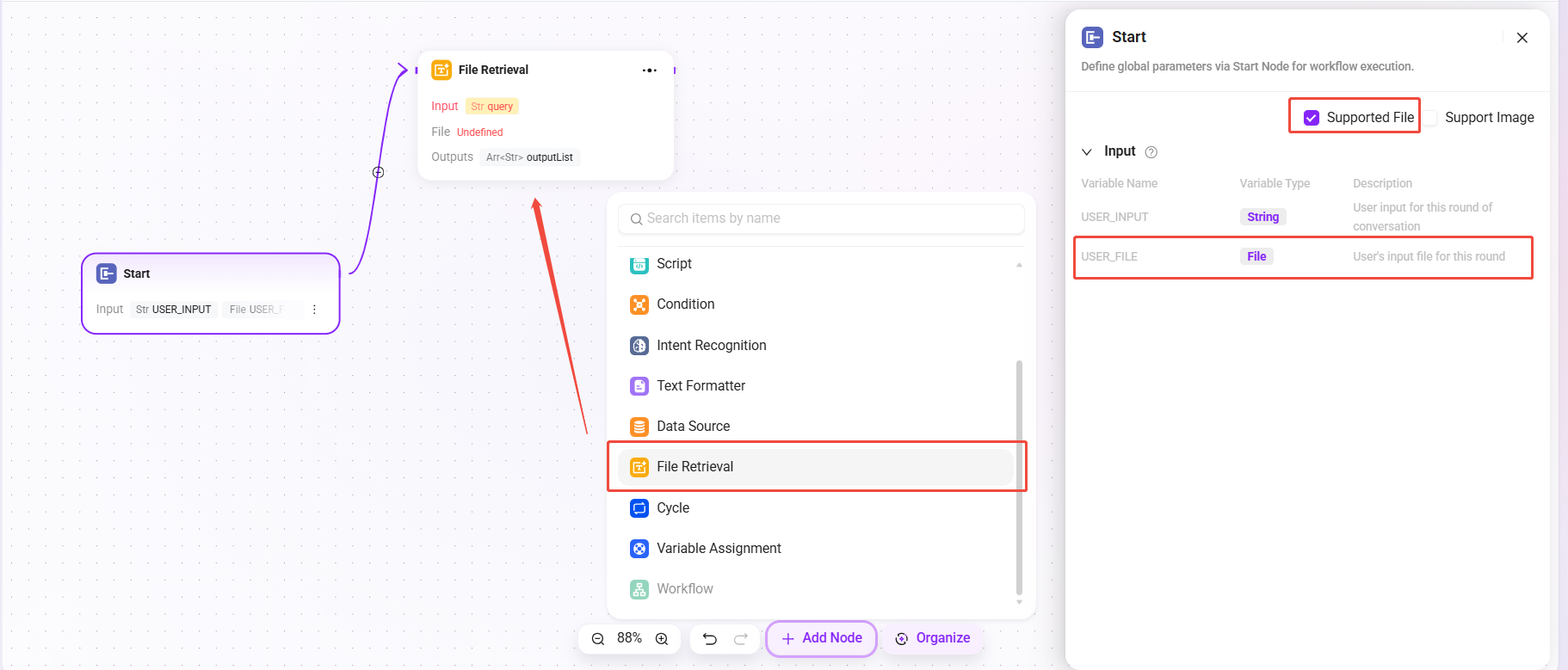
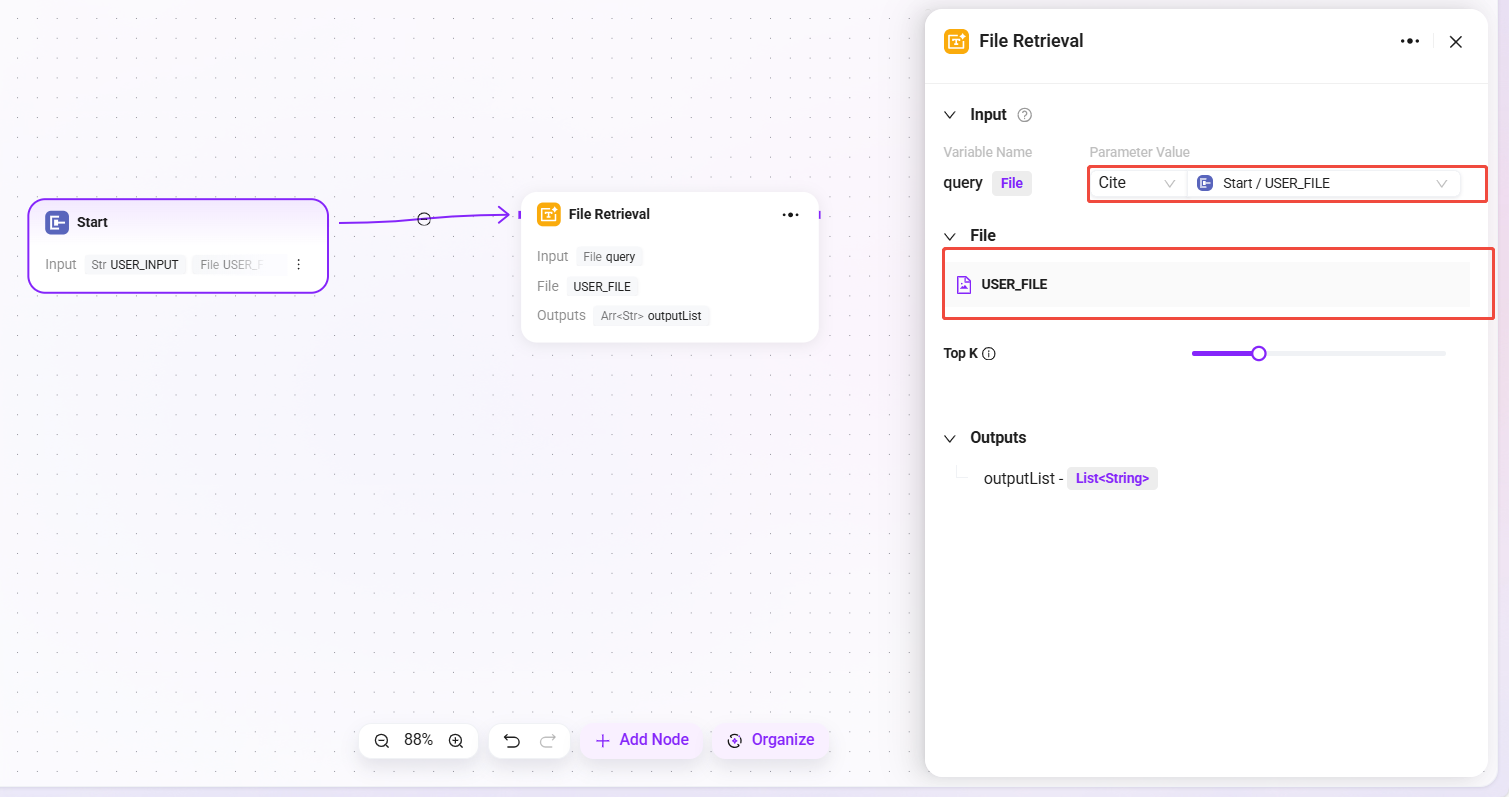
配置文件检索
- 首先需要在“开始”节点中勾选“支持文件”
- 勾选后开始节点出现变量“USER_FILE”,指的是用户本轮输入的文件
- 再连接“开始”节点和“文件检索”节点
- 连接后,文件检索节点可添加“USER_FILE”为被检索的文件。
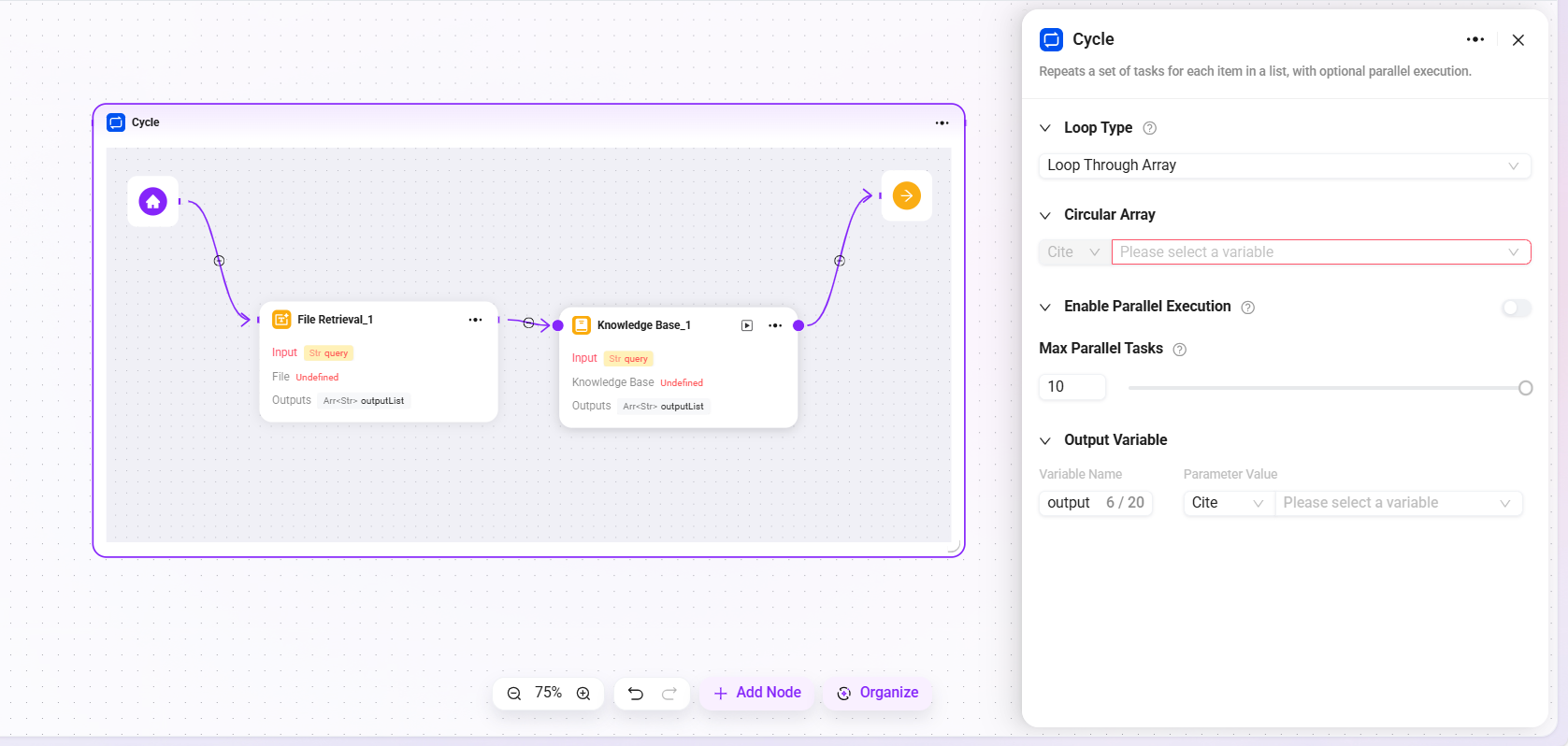
循环
用于按指定的次数或指定的数据集合,重复执行一组任务。通过配置不同的循环模式,可以灵活实现批量处理或重复操作。
- 循环类型:支持两种模式
- 使用数组循环:根据输入的数组,对数组中的每个元素依次执行任务。
- 使用数值循环:按照设定的次数,循环执行任务。
- 循环数值/数组:
- 当选择“数值循环”时,需输入一个具体的数字,例如
2,则表示任务将被执行 2 次。 - 当选择“数组循环”时,需要提供一个数组变量,系统会逐一取出数组中的元素作为输入执行任务。
- 当选择“数值循环”时,需输入一个具体的数字,例如
- 并行执行:可选功能。开启后,系统会同时处理多个循环任务,提升效率。用户可设置最大并行数以控制资源占用。
工作流
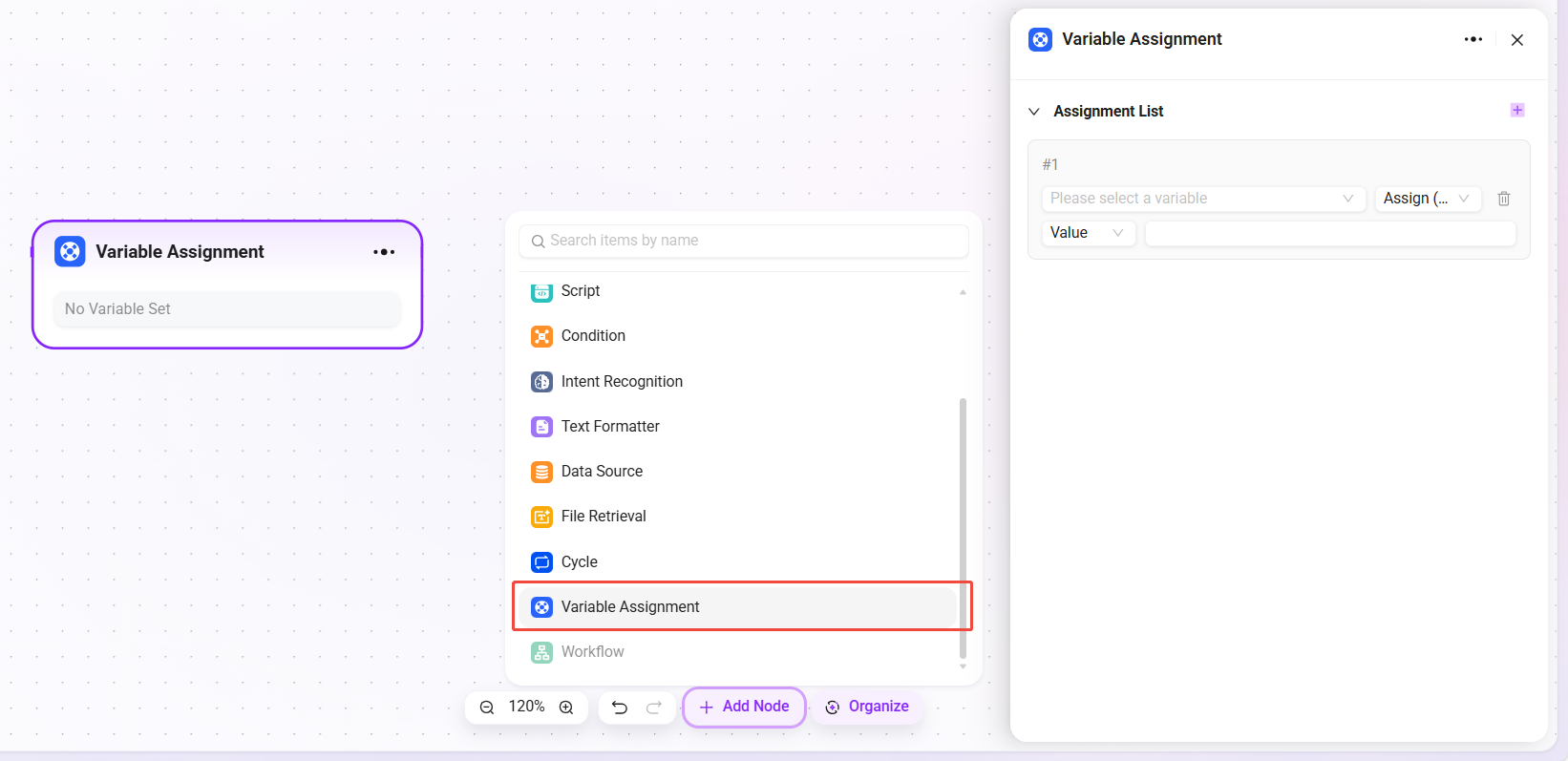
用于引用并调用其他已配置的工作流,实现模块化嵌套与流程复用。
- 工作流选择:从现有工作流列表中选择需要调用的子工作流。
- 输入映射:将当前流程中的变量映射至子工作流的输入参数。
- 输出映射:将子工作流的输出结果映射回当前流程的变量,供后续节点使用。
- 处理逻辑:执行所引用的子工作流,并等待其运行完成后返回结果。
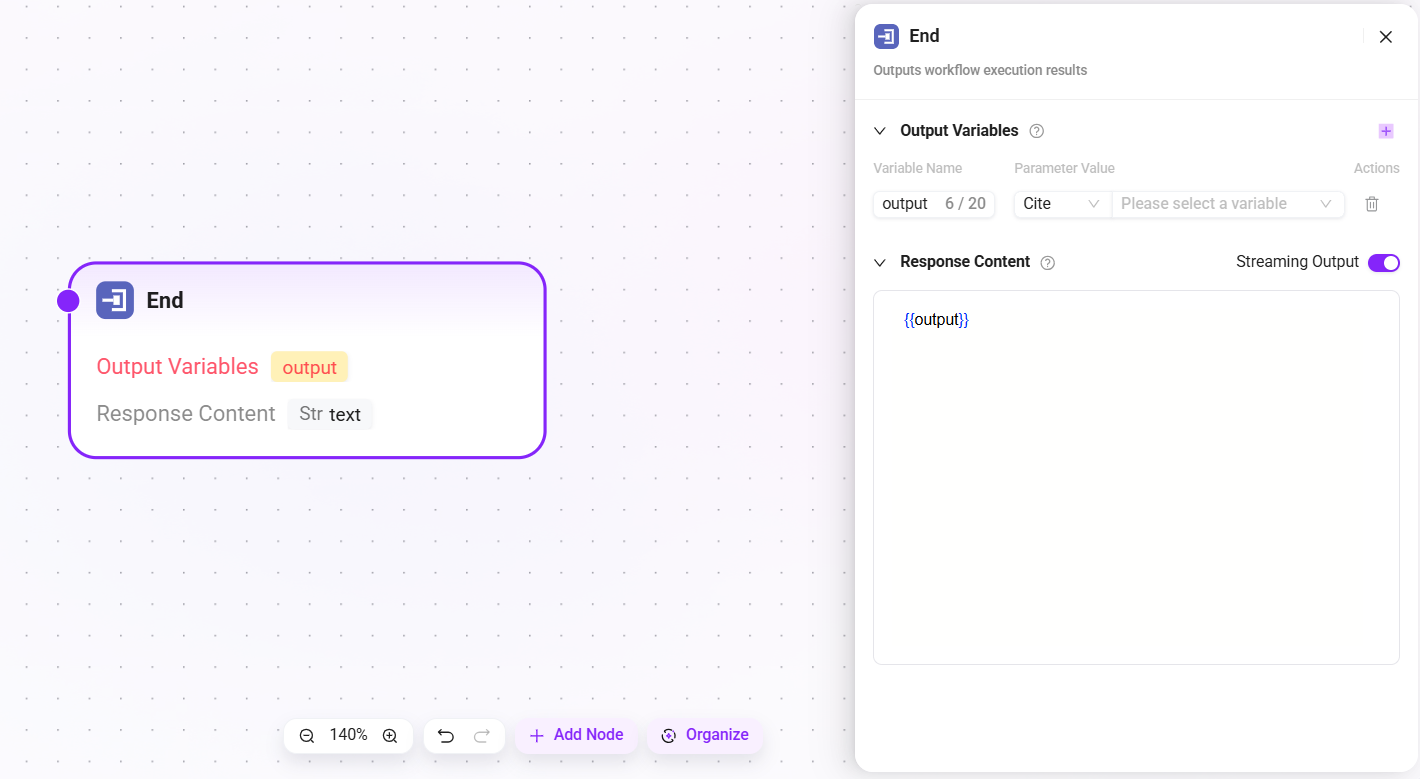
结束
工作流的最终节点,用于返回工作流运行后的结果信息。
- 输出变量:在智能体调用工作流完成后,这些变量将被输出。
- 回答内容:编辑智能体的回复文本。工作流运行结束后,智能体中的 LLM 将不再自行组织语言,而是直接使用此处编辑的原文进行回复。支持通过
{{变量名}}格式引用输出变量。 - 流式输出:可选择是否启用流式输出方式。
工作流示例
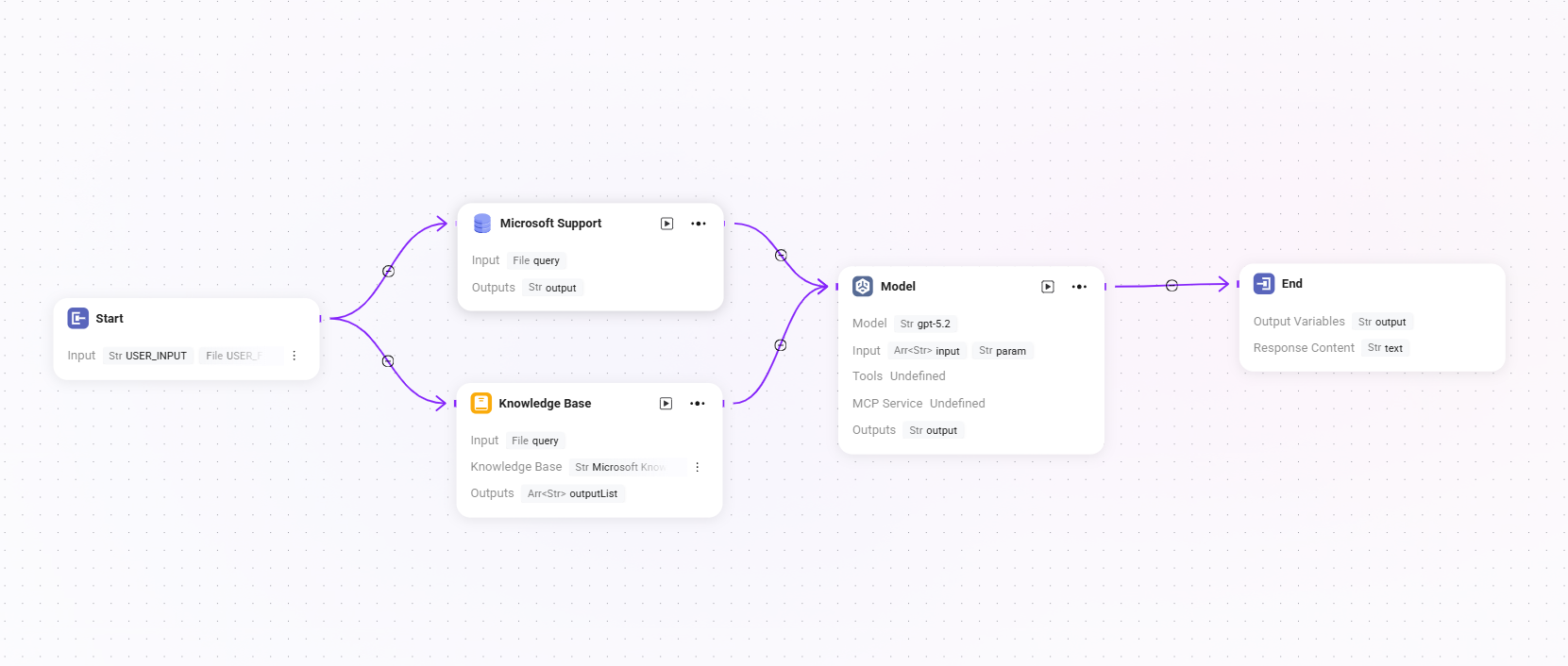
在本场景中,使用工作流功能构建一个完整的 “Microsoft Support Ticket Issue Analytics” 流程,具体流程如下:
- 开始节点
流程的起点,系统默认包含。 - 数据源节点
用于接入工单分析所需的原始数据。 - 知识库节点
接入包含分析参考资料的知识文档,作为AI分析的理论支撑。 - 模型节点
基于AI模型,将数据源与知识库内容结合,进行综合分析,生成工单问题分析结果。 - 结束节点
流程的终点,输出模型节点的分析结果。此节点系统默认包含。
数据源节点与知识库节点并列配置,模型节点则汇总处理前两者的信息,确保输出结果具备数据依据和理论支撑。
最后效果如下:
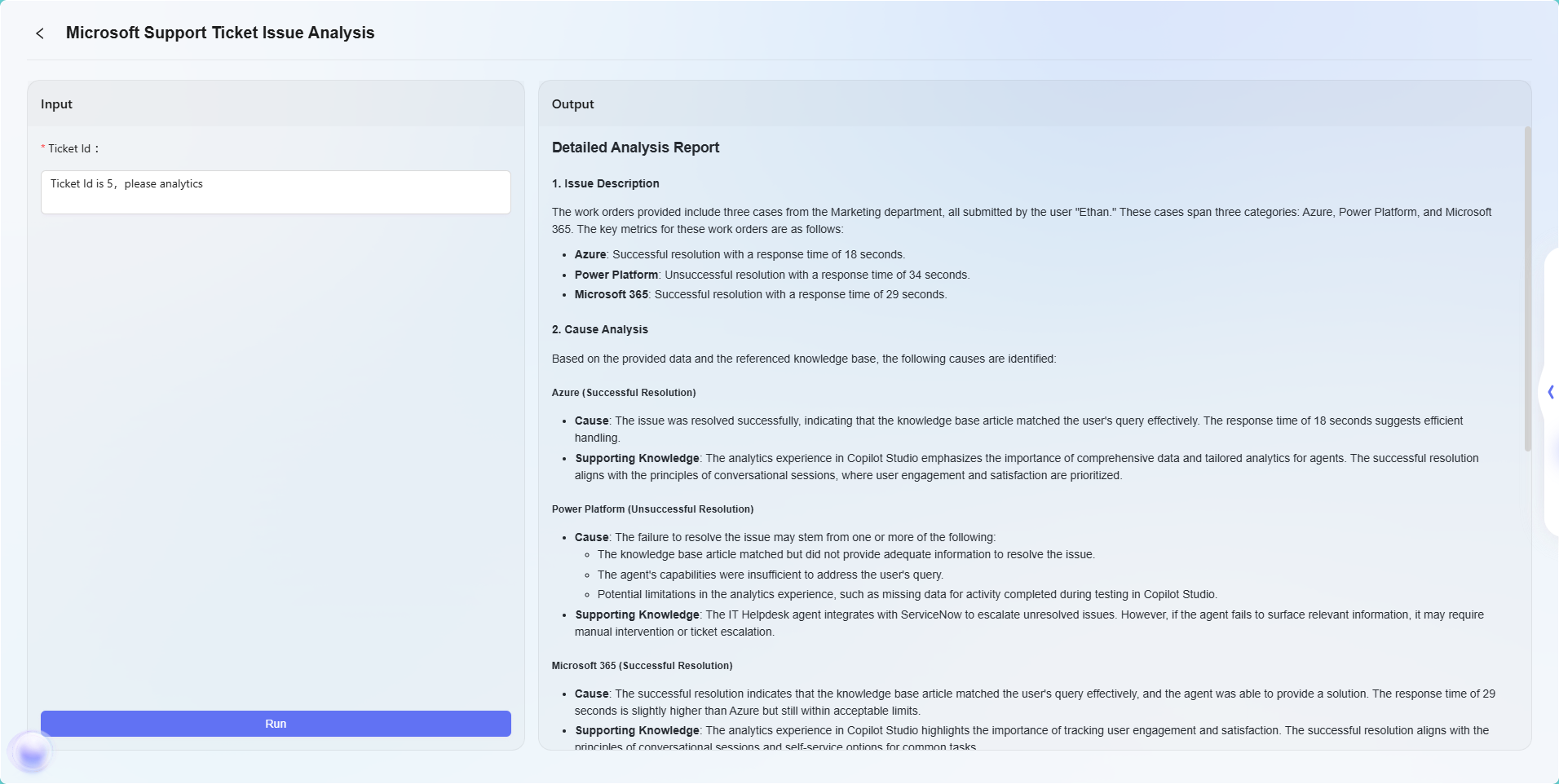
注:本示例仅为工作流功能的基础应用演示。工作流编排具备高度的灵活性与可扩展性,通过组合各类节点,能够实现极其复杂的业务逻辑与自动化流程,可适应广泛的业务场景需求。
变量管理
为了增强编排灵活性、减少节点间的显式耦合,工作流支持环境变量与会话变量两种机制,分别用于存储配置类参数与运行时中间状态。所有变量均可通过节点配置项中的输入变量直接调用。
- 配置入口:变量管理面板位于画布右上角,点击对应图标即可展开。

聊天变量
聊天变量用于存储工作流运行过程中的中间状态、上下文结果或用户临时输入(如上次分析结论、执行标志位、用户偏好等)。其作用域为 Workflow 运行实例级,同一实例内的所有节点共享,不同实例或用户上下文之间严格隔离。
- 读写权限:可读写,支持在节点中动态赋值、覆盖或清空。
- 支持类型:支持
String、Number、Boolean、Integer、Object、List<String>、List<Number>、List<Boolean>、List<Integer>、List<Object>。 - 应用范围:同一运行实例内所有节点共享。
清理机制:
- 手动清理:若某个 Agent 使用了会话变量,其图标上会出现扫把标识。点击后弹出二次确认弹窗,支持多选清理项,默认选中“清空上下文”与“会话变量”。
- 接口清理:提供单独的清理会话变量接口,方便在交付场景中由外部系统调用,实现自动化的会话状态重置。
环境变量
环境变量用于存储配置类、系统级参数,如 API 密钥、全局开关、模型名称等。其作用域为 Workflow 定义级,同一工作流的所有运行实例共享该配置。
- 读写权限:只读。变量值在定义时固定,运行时不可修改。
- 支持类型:
String、Number、Secret(加密字符串,用于存储敏感信息如 API Key)。 - 应用范围:工作流内所有节点均可引用。
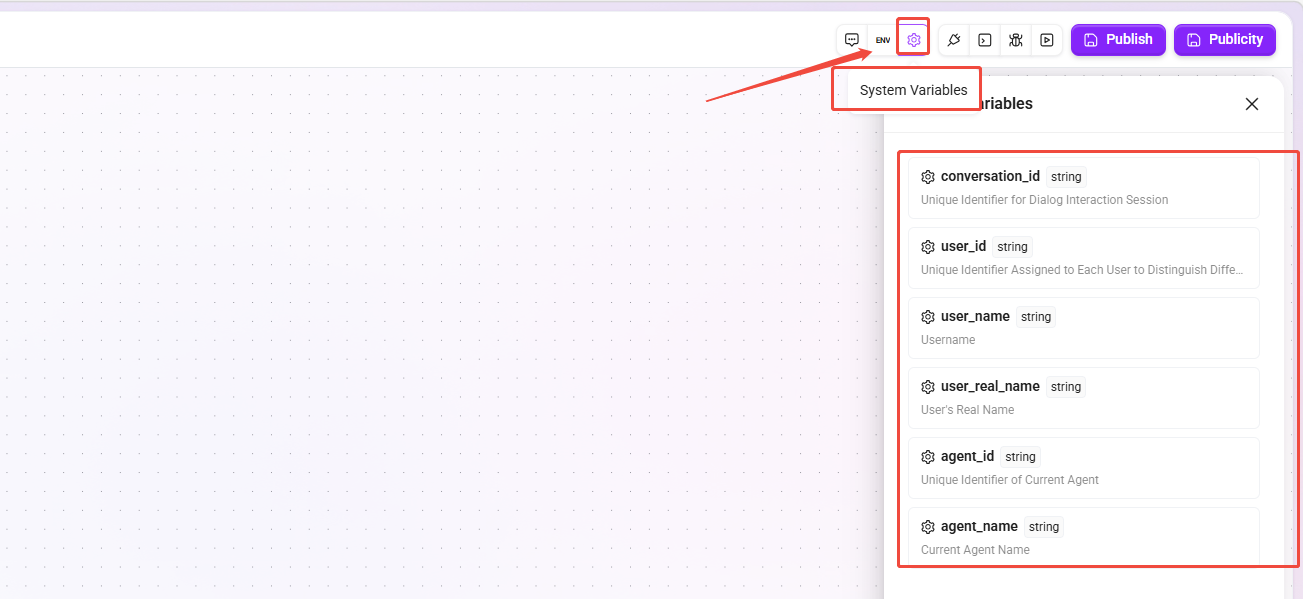
系统变量
系统预置的只读变量,用于获取当前会话或智能体的元数据信息,无需手动创建,可直接在节点中引用。
| 变量名 | 类型 | 说明 |
|---|---|---|
conversation_id | string | 当前对话框交互会话的唯一标识符。 |
user_id | string | 当前对话用户的唯一标识符。 |
user_name | string | 用户名。 |
user_real_name | string | 用户真实姓名。 |
agent_id | string | 当前智能体的唯一标识符。 |
agent_name | string | 当前智能体的名称。 |
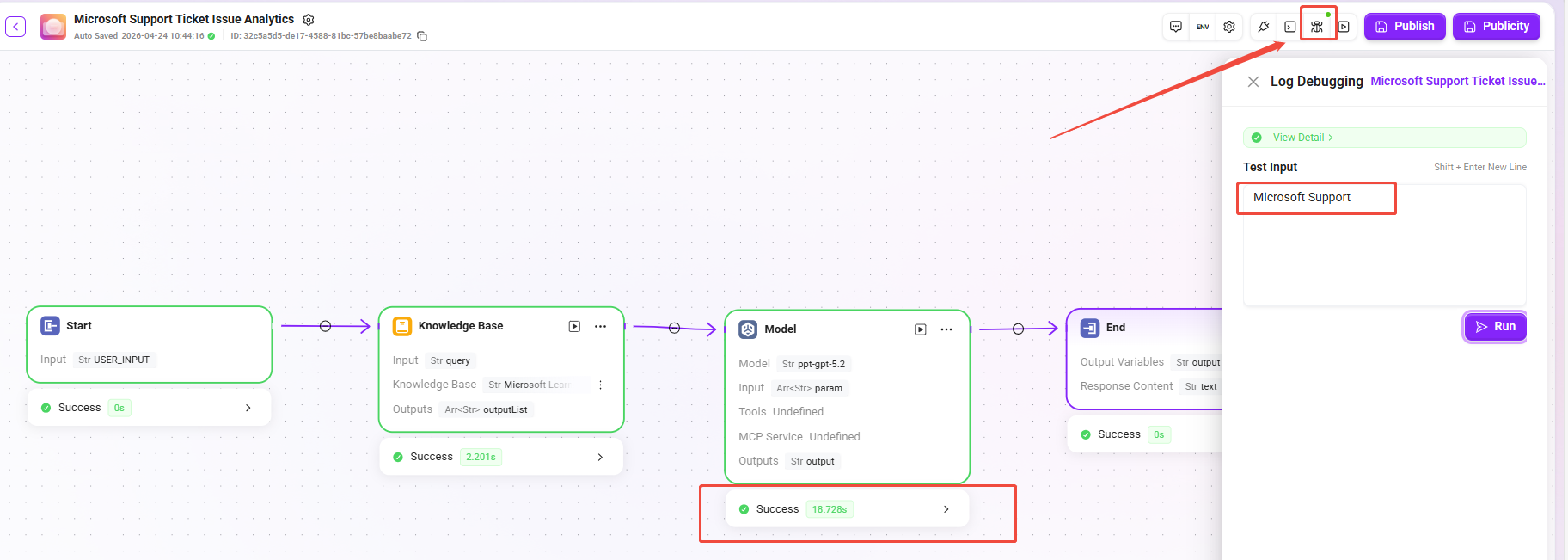
日志调试
日志调试用于在编排阶段定位流程问题。用户输入具体问题后,可逐节点查看输入与输出变量,快速排查数据传递是否符合预期。
- 启动方式:点击画布右上角 “日志调试” 按钮,在测试输入框中输入问题(如
Microsoft Support)点击运行,系统将自动执行当前工作流。 - 执行过程:运行过程中,成功执行的节点会变为绿色标识,节点下方显示运行状态与耗时。点击节点可查看该节点的输入与输出变量详情。
- 查看详情:
- 测试输入框上方设有 “查看详情” 按钮。
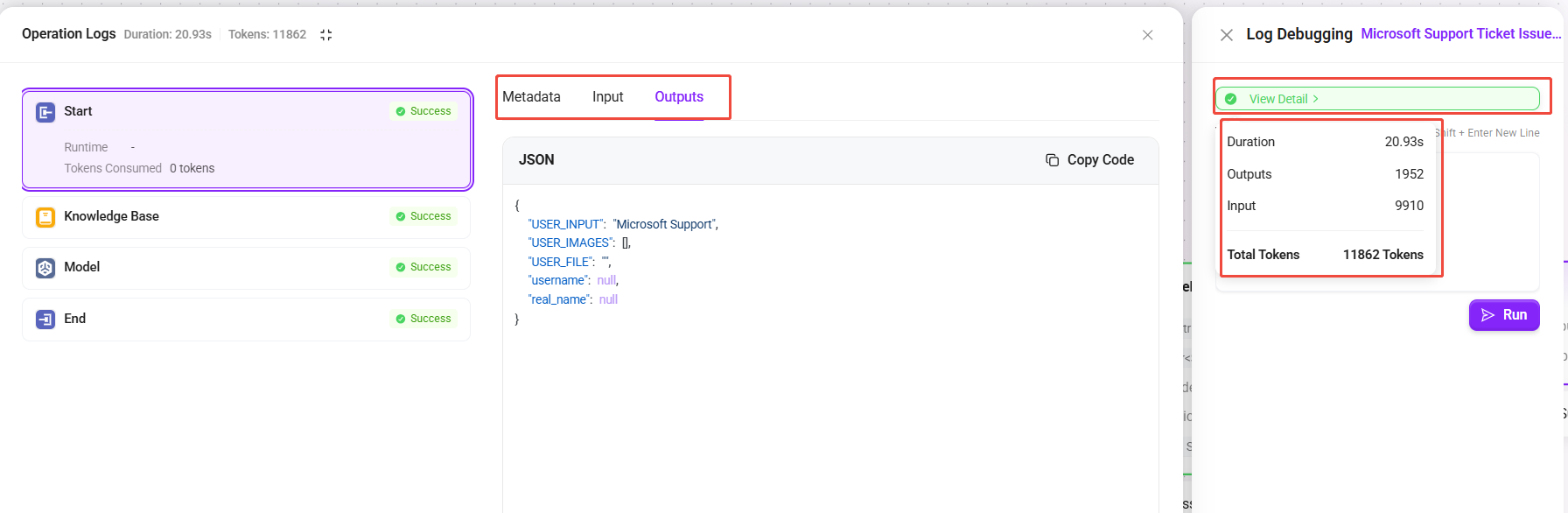
- 悬浮鼠标于按钮上,可快速预览本次运行的总时长、输入输出消耗的 Token 及总 Token 数。
- 点击按钮进入详情面板,可查看每个节点的完整输入与输出内容(JSON 格式),以及元数据(包括开始时间、运行时间与 Token 消耗明细)
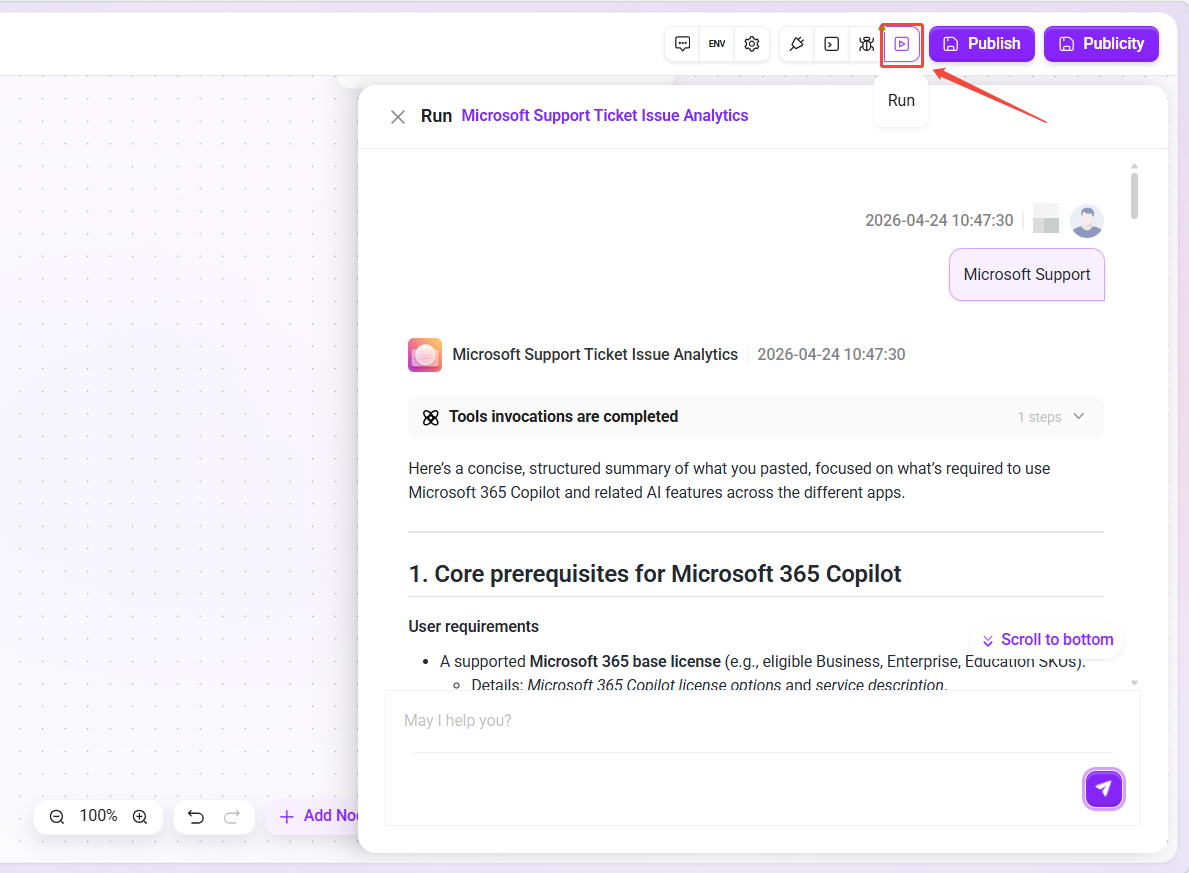
试运行
试运行用于模拟真实问答场景,验证工作流的整体编排效果与助手最终回复质量。
- 启动方式:点击画布右上角 “试运行” 按钮,在对话面板中输入测试问题,工作流将按发布后的逻辑完整执行。
- 效果预览:运行结束后,面板展示助手的最终回答内容,可直观判断回复是否满足业务预期。
- 即时调整:若回复效果不理想,可直接在试运行界面修改节点配置(如提示词、参数等),无需反复跳转至画布配置页,提升调试效率。
注意:试运行不会影响线上智能体的真实会话记录,所有测试数据仅在当前调试会话中有效。