ワークフロー作成Agent
エージェントタイプを選択
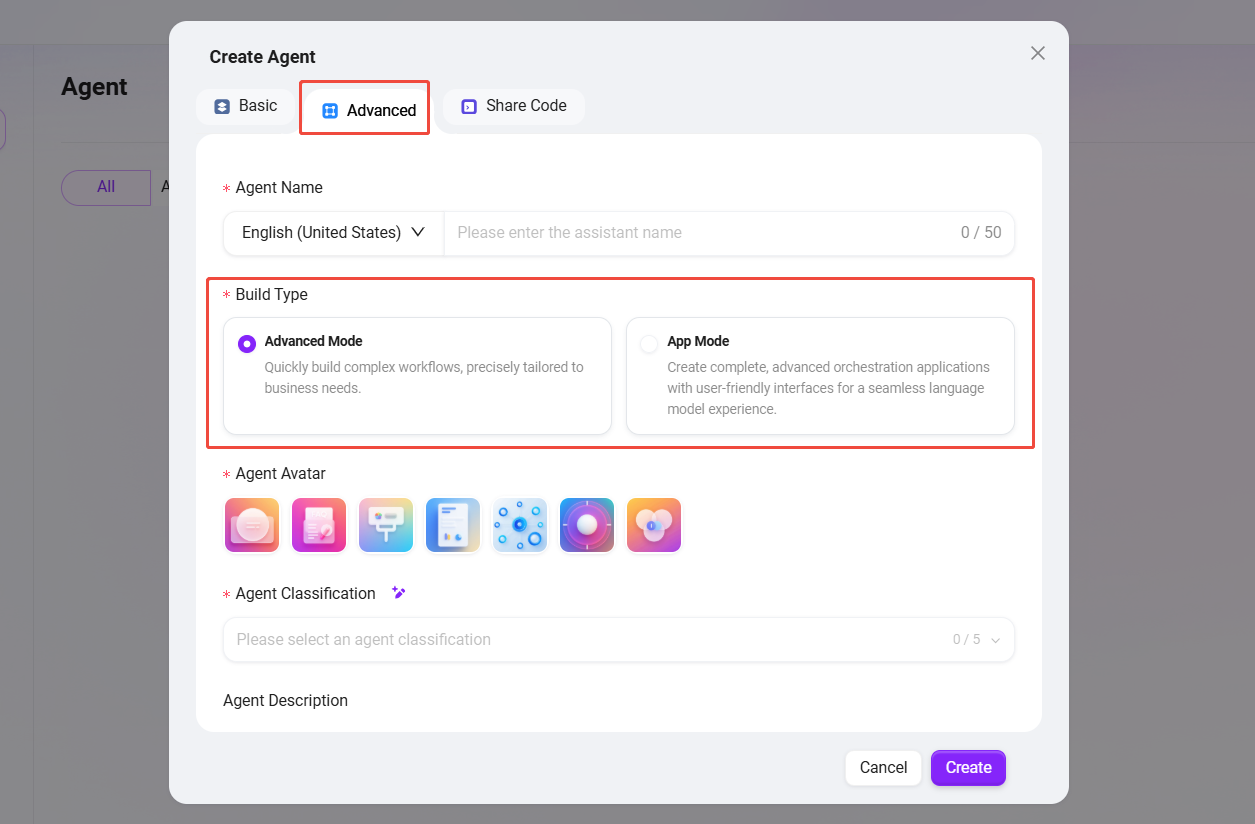
エージェントを作成する際は、**「高度オーケストレーション」**を選択します(初期作成手順は通常のエージェントと同じです)。
- 適用可能なAgentの範囲:異なる複雑さの業務要件を満たすために、2つのコアモードを提供します。
- 上級モード:対話ベースの複雑なワークフローを迅速に構築します。
- アプリモード:完全で高度なオーケストレーションアプリケーションを作成し、ユーザーフレンドリーなインターフェースとスムーズな大規模言語モデルとの対話体験を提供します。
上級モード
基本エージェントを拡張したQ&A型エージェントで、コア機能はマルチターン対話とナレッジQ&Aに集中しています。
特徴:
- 自然言語による対話を主なインタラクション方式とします。
- 柔軟でオープンな対話インタラクションが必要な業務シナリオに適しています。
典型的なシナリオ:
- 社内ナレッジQ&Aエージェント
- 製品FAQおよび技術サポートアシスタント
- チケット処理相談エージェント
アプリモード
UI付きのAgentオーケストレーションアプリを構築するために使用され、特定の入力構造を持ち、特定のタスクを完了するためのもので、自由対話を主とせず、既定のタスクフローの実行に特化したエージェントです。
特徴:
- 固定かつカスタマイズ可能な入力インターフェースを備えています(例:ファイルアップロード、フォーム項目入力)。
- 特定の自動化または半自動化タスクフローの実行に重点を置いています。
- ファイルや構造化データ(Structured Data)などの複雑な入力タイプをサポートし、厳格な入出力形式が必要な業務シナリオに適しています。
典型的なシナリオ:
- 契約審査 App(契約書をアップロード → リスクを自動マーキング)
- 文書分析 App(文書をアップロード → 重要内容を自動生成)
- データクレンジング App(Excel をアップロード → データを自動処理)
ワークフローを設定
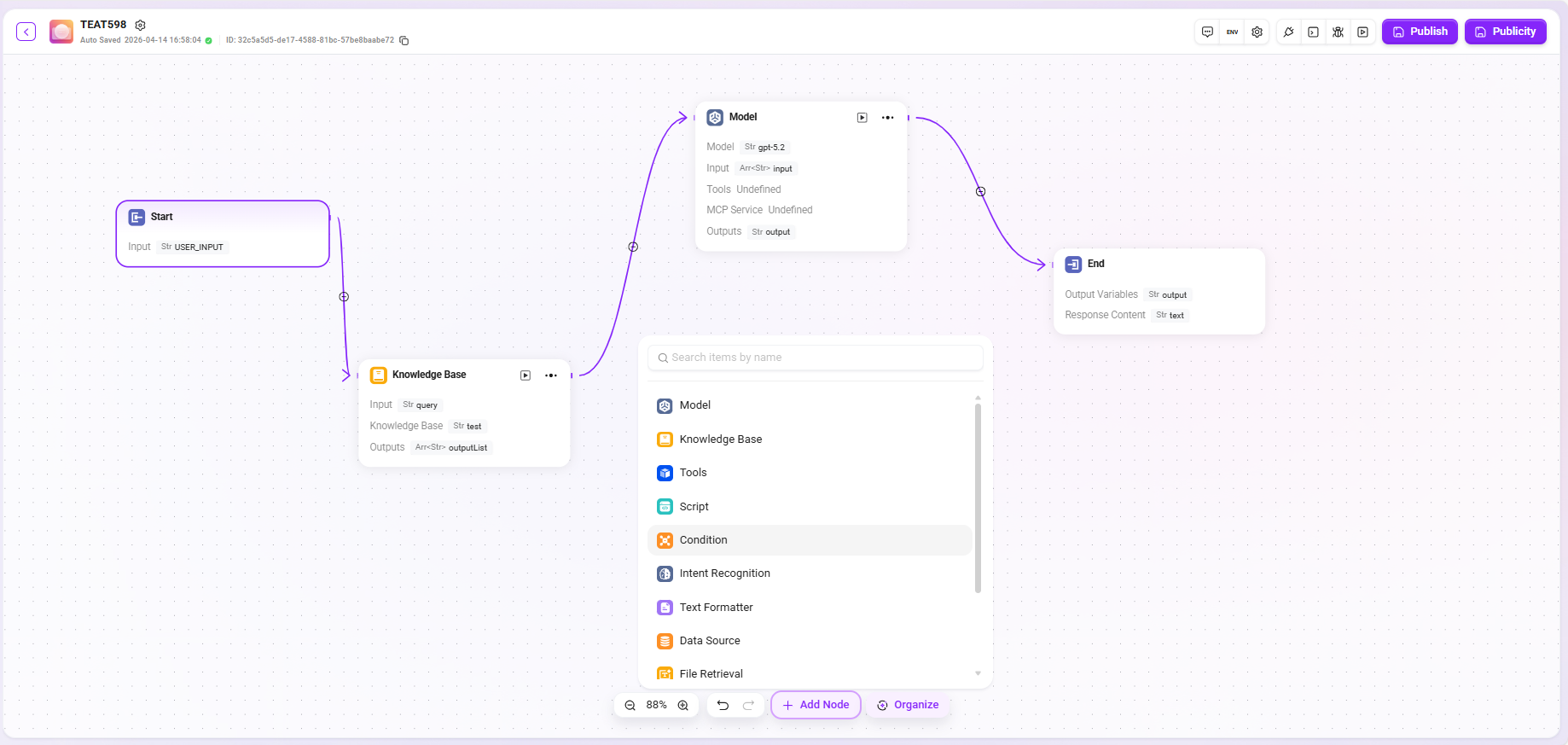
ユーザーの実際の業務ロジックに基づき、以下のノードをドラッグ&ドロップして接続し、ワークフローを設定します:
- 開始、終了:ワークフローのデフォルト入力・出力モジュールで、入力パラメータおよび出力フィールドのカスタマイズをサポートします;
- モデル必要な大規模言語モデルを選択し、他モジュールから渡された変数を受け取り、プロンプトを編集して出力メッセージを定義し、変数形式で保存します;
- ナレッジベース検索:選択したナレッジベース内で、入力変数に基づいて最も一致する情報を検索して返します;
- ツール:内蔵ツールのいずれかを選択し、そのツールを通じた入力および出力操作を行います;
- スクリプト:他モジュールの出力変数に基づいて、コード関数をカスタム作成します;
- セレクター:設定条件に基づいてフロー分岐先を判断し、ロジック判定を実現します;
- 意図認識:ユーザー入力の意図を認識し、事前設定された意図オプションとマッチングします;
- テキストフォーマッター:複数の文字列型変数のフォーマット処理に使用します;
- データソース:データソースを指定し、フロー内で参照可能な変数内容の範囲を拡張します;
- ファイル検索:アップロードされたファイル内を検索し、入力された質問に基づいて関連する回答を探します;
- ループ:リスト内の各項目に対して一連のタスクを繰り返し実行し、並列処理も選択できます;
- 変数代入:定義済み変数に値を代入または更新し、ワークフローノード間でデータを受け渡し・変更するために使用します。
- ワークフロー:他の設定済みワークフローを参照・呼び出し、モジュール化されたネストと再利用を実現します。
ノード詳細紹介
- ノード数制限:単一ワークフロー内のノード総数の上限は 100 個、ループノード内部のノード数上限は 1000 個です。
- 全体的な注意事項:先に前段ノードを接続してからでないと、他ノードの変数を現在ノードの入力として選択できません。このルールは、前段ノードの出力を参照する必要があるすべてのノードに適用されます。
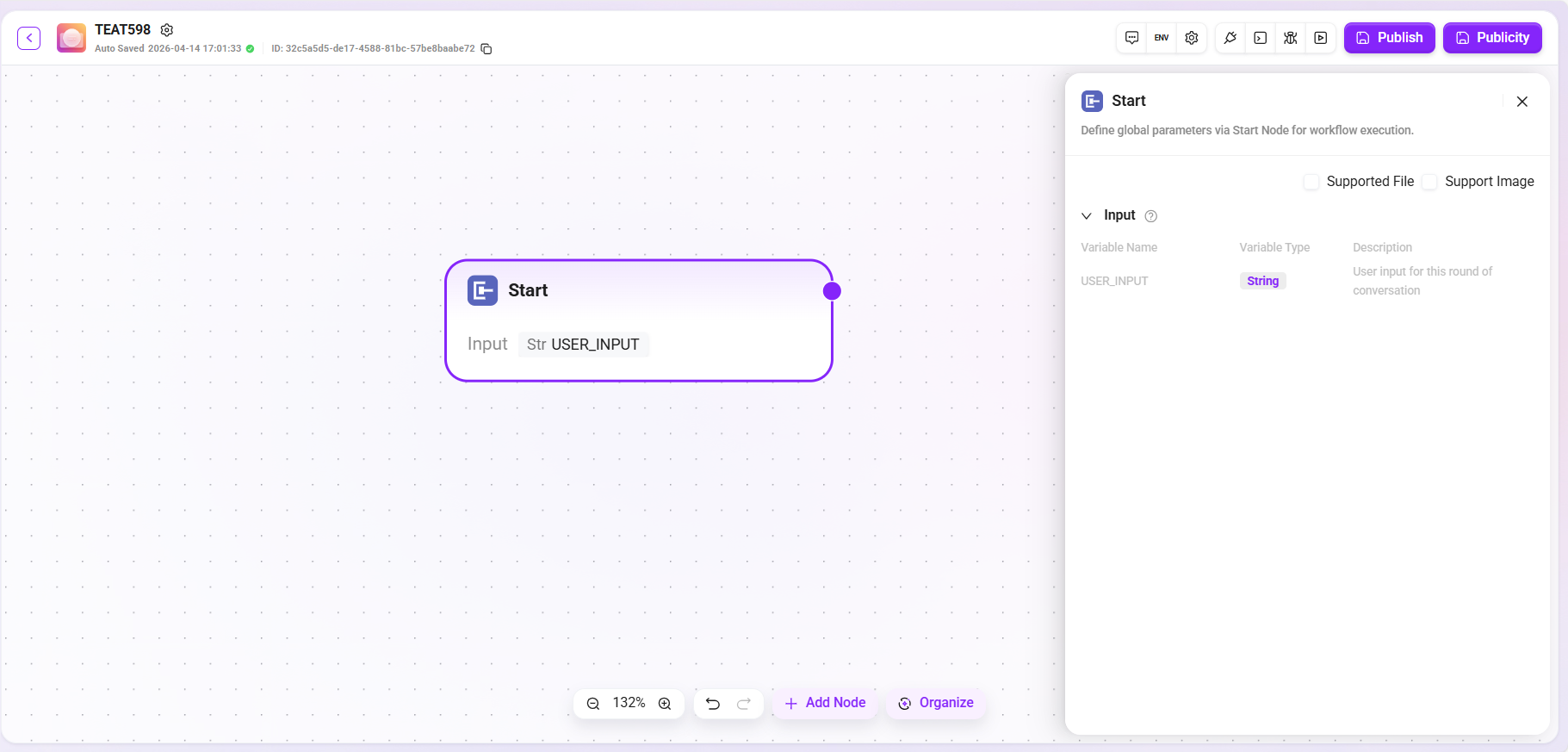
開始
開始ノードはワークフローの開始ノードであり、ワークフロー実行のグローバルパラメータを設定するために使用され、入力画像およびファイルのカスタム選択をサポートします。
- 機能:タスク完了に必要な基本情報(入力パラメータ)を事前設定します。トリガー条件を満たすと、システムはこれらのパラメータを自動収集して渡し、フローを開始します。
- 処理ロジック:そのまま通過させ、入力内容を後続ノードへそのまま渡します。
- 出力:すべての入力内容。
- 特記事項(アプリモード):このモードでは、開始ノードはテキスト、数値、選択など複数の複雑な入力パラメータ型の定義をサポートし、専門的なアプリ構築のために高度にカスタマイズ可能な入力インターフェースを提供します。
ヒント:開始ノードで定義した入力パラメータは、エージェント対話中に LLM によって読み取られ、適切なタイミングでワークフローを開始し、必要情報を正確に入力できるようになります。
上級モード:
アプリモード:
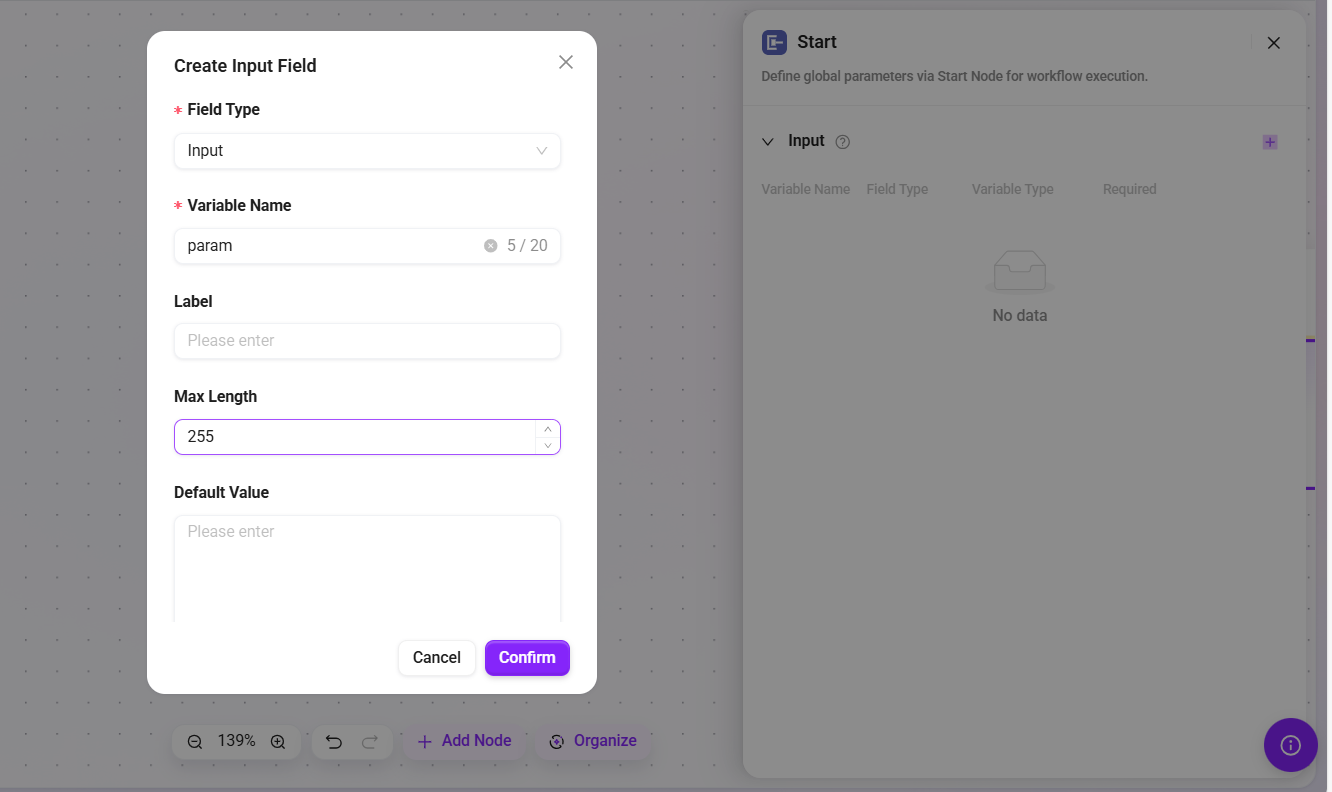
モデル
大規模言語モデル(LLM)を使用して、入力変数とカスタムプロンプトに基づく動的な応答を生成します。
- モデル:設定済みの利用可能なモデルをドロップダウンから選択します。
- MCPサービス:任意の設定項目で、MCP サービスに接続してモデル能力を拡張するために使用します
- ツール:任意の設定項目で、モデルに内蔵ツール呼び出し機能を追加するために使用します
- 入力:入力変数を定義し、それに値を割り当てて、プロンプトまたはフロー内で使用します。各変数は固定値または他の変数の出力変数を参照できます。
- プロンプト設定
- システムメッセージ:対話に高レベルの役割または行動指針を提供し、
{{变量名}}形式で入力パラメータ内の変数を参照できます(プロンプト内容の上限は 5000 文字)。 - 履歴記憶件数:値の範囲は 0–20 で、モデル処理時に持ち込む対話履歴ターン数を制御します。
- ユーザーメッセージ:具体的な指示、問い合わせ、またはテキスト入力をモデルに渡します。同様に
{{变量名}}形式で変数参照をサポートします。
- システムメッセージ:対話に高レベルの役割または行動指針を提供し、
- 処理ロジック:入力内容を大規模言語モデル(LLM)に送信して処理し、モデルは設定されたプロンプトとコンテキストに基づいて対応する回答を生成します。
- 出力:モデルが生成したテキスト内容。
💡 ヒント:先に前段ノードを接続してからでないと、他ノードの変数を現在ノードの入力として選択できません。
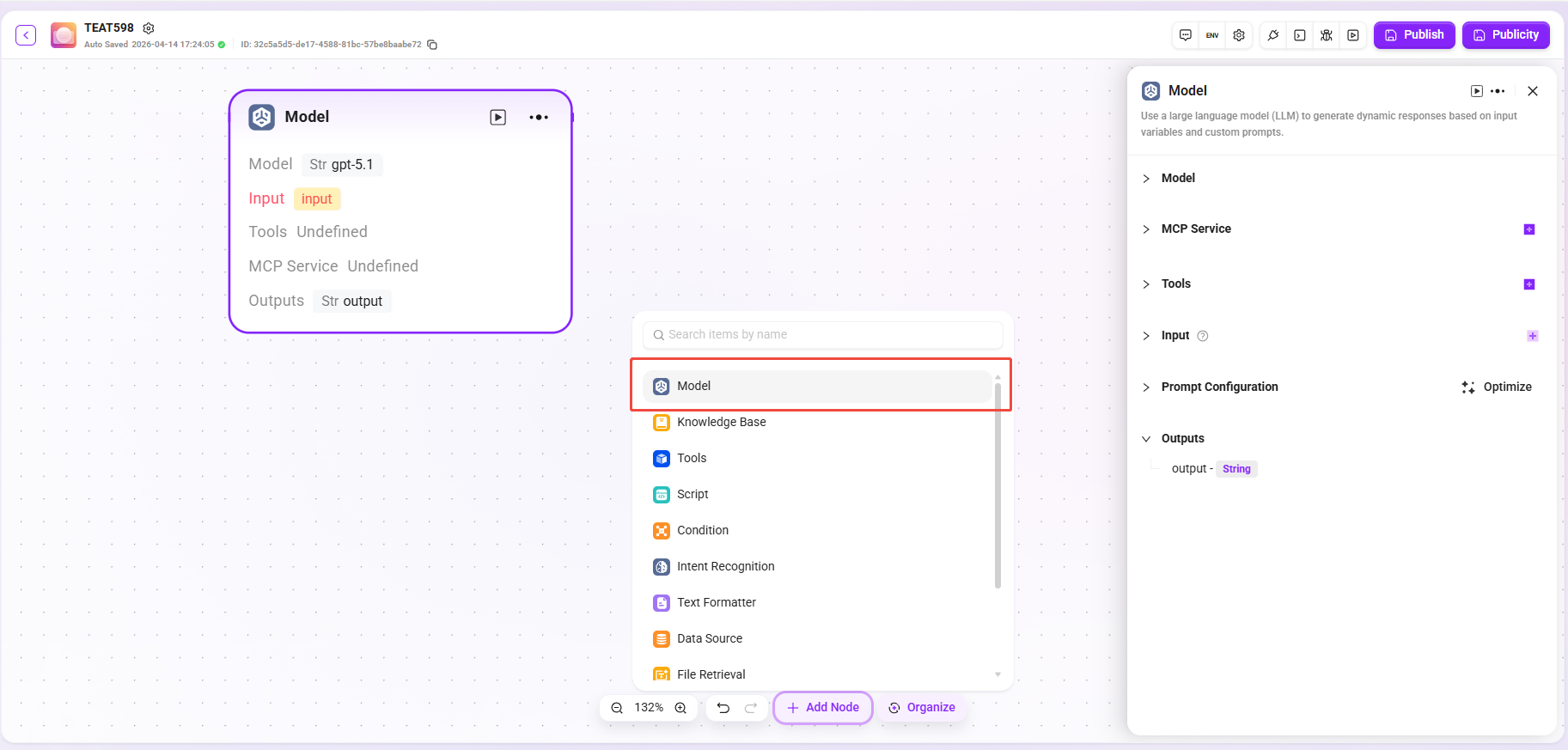
ナレッジベース検索
ナレッジベース内を検索し、ユーザー入力に基づいて最も関連性の高い回答を返します。
- 入力:変数名の定義およびパラメータ値の設定により、ナレッジベース検索に検索キーワードなどの元データを提供します。
- 処理ロジック:入力とパラメータに基づいてナレッジベースを検索し、断片またはFAQを返します。
- ナレッジベース検索:特定のナレッジベースを検索範囲として選択し、システムはこの範囲内で一致情報を検索します。
- 検索戦略:ナレッジ検索はナレッジベースから情報を取得する方法であり、異なる検索戦略を採用することで正しい情報をより効果的に特定し、生成される回答の正確性と有用性を向上できます。
- メタデータフィルタ(プレビュー):文書検索プロセス中に再取得された断片をフィルタリングし、ノイズを減らしてデータ品質と処理効率を向上させます。
- 最大再取得数:ユーザーの質問との類似度が最も高いテキスト断片を選別するために使用します。システムは同時に、選択したモデルのコンテキストウィンドウサイズに基づいてセグメント数を動的に調整します。
- 文書マッチング類似度:値の範囲は 0–1 で、再取得文書とクエリの類似度しきい値を制御するために使用します。
- Q&Aペアマッチング類似度:値の範囲は 0–1 で、再取得されたQ&Aペアとクエリの類似度しきい値を制御するために使用します。
ヒント:高く設定しすぎると、再取得段落が Token 制限を超える可能性があり、Token を超えた部分の低一致段落は大規模モデルに送信されません。
- Pipeline 設定:Pipeline 検索を有効にするかどうかを選択します。
- 出力:ナレッジベースから検索された一致情報を、指定した変数の形式で出力し、後続フローで使用できるようにします。
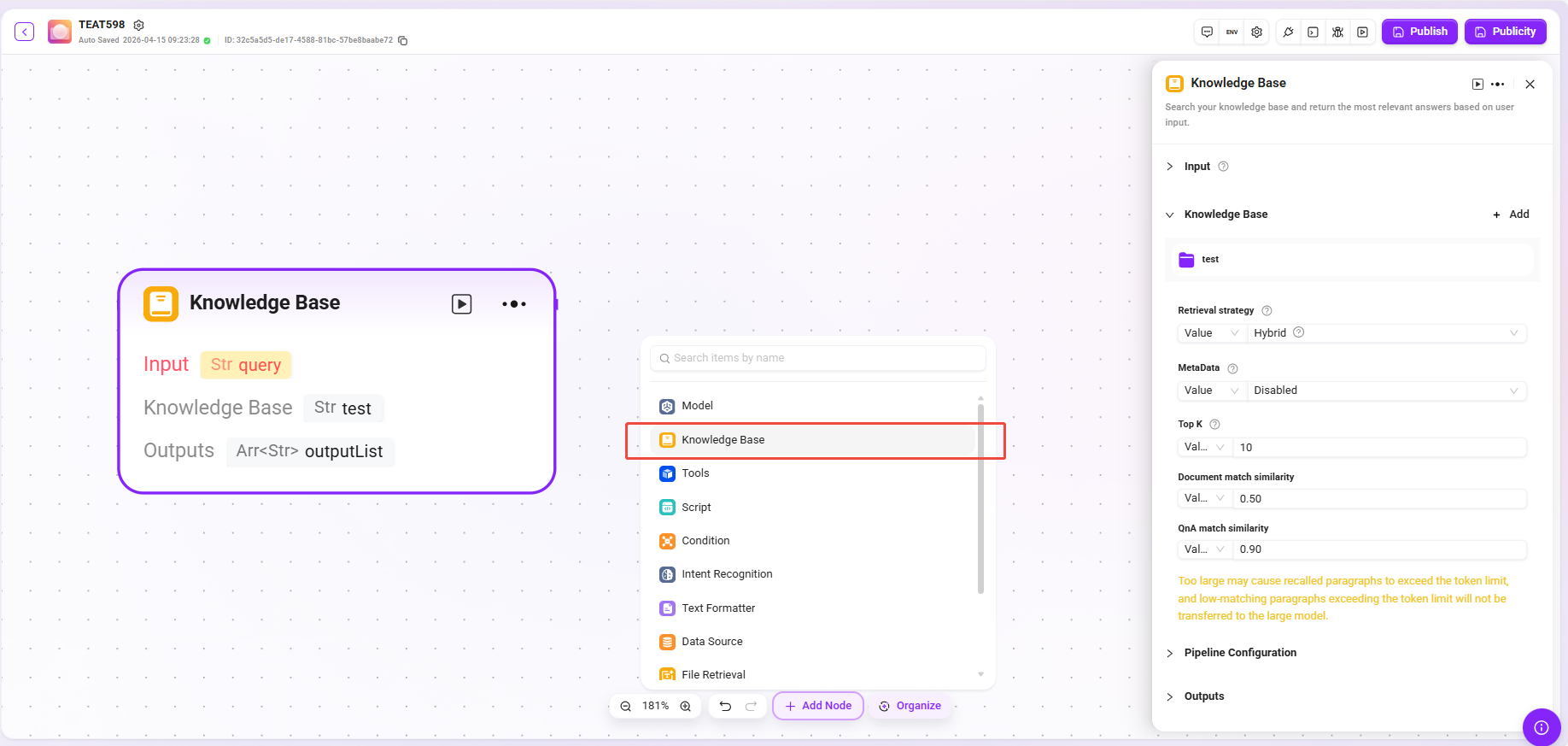
ツール(例)
- 処理ロジック:選択したツールタイプに応じて対応する入出力アクションを実行し、処理結果を後続ノードに渡します。
- Webサイト読み取り:Webページ上の静的テキストを読み取れます(動的に読み込まれる内容は取得できません)。
- テキストから画像生成:説明テキストに基づいて画像を生成し、画像URLを返します。
- Google検索:検索エンジンを呼び出して検索結果を返します。
💡 ヒント:高度オーケストレーションモードで追加できるツールは内蔵ツールのみであり、カスタムツールは追加できません。
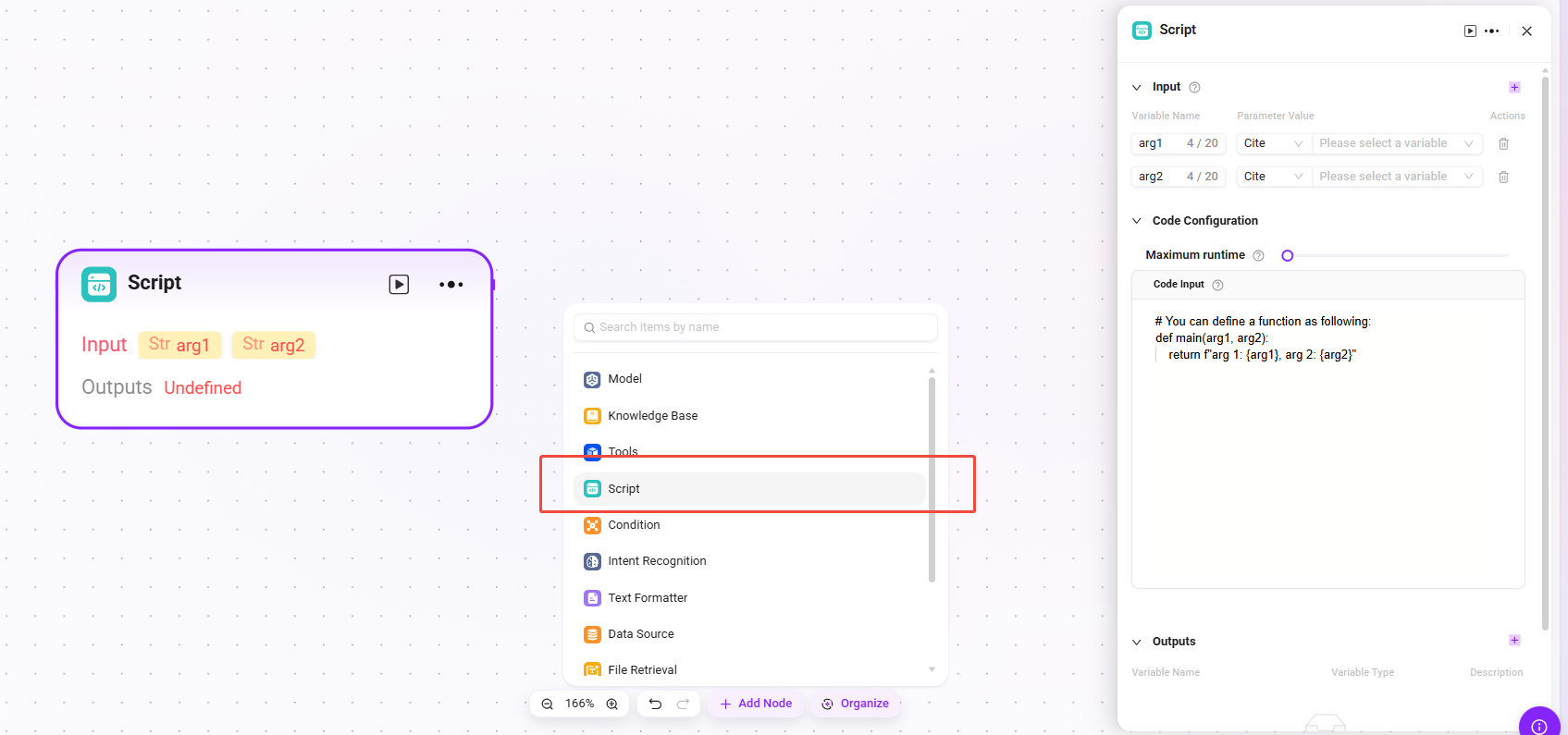
スクリプト
コードを記述し、入力変数を処理して戻り値を生成します。
- 入力:外部から渡された変数を受け取るために使用され、コード実行に必要なデータの入口として、後続のコード処理に元データを提供します。
- 設定パラメータ:コード実行に関連するパラメータを設定します。
- 最大実行時間(Maximum Runtime):コード実行の時間上限を設定します(最長 600 秒)。プログラムが長時間実行状態に陥るのを防ぎます。
- コード入力(Code Input):コード例を参考に関数構造を記述します。入力パラメータ内の変数を直接使用でき、
returnでオブジェクトを返すことで処理結果を出力します。この機能では複数関数の記述はサポートされません。出力値が1つだけの場合でも、必ずオブジェクト形式でreturnしてください
- 処理ロジック:
- 安全なサンドボックス環境でコードを実行します(RestrictedPython または指定プラットフォームに基づく)。
- 実行時間とアクセス権限を制限し、セキュリティリスクを回避します。
- 出力結果:コードが入力データの処理を完了した後、結果を指定変数形式で出力します。これはコード処理結果の出口です。出力変数は自分で設定する必要があります
セレクター
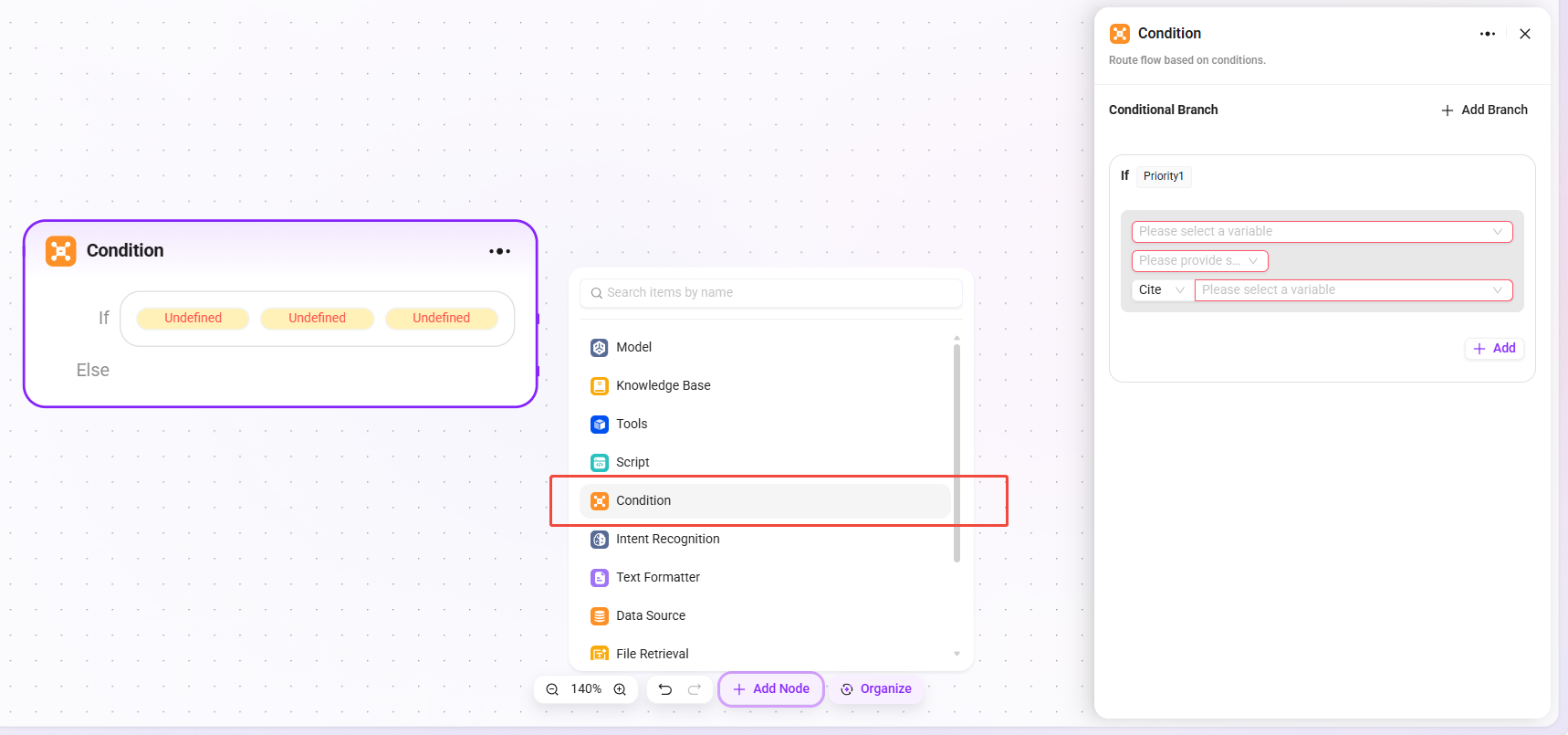
フローオーケストレーションにおいて条件判定の役割を果たします。複数の下流分岐を接続し、設定された条件によって実行パスを決定します。
- 条件分岐:
- 「if - 優先度 1」のように複数条件を設定できます。分岐数に制限はありませんが、条件総数の上限は 20 個です。
- 参照変数、条件(等しい、大きいなどの比較ロジック)、比較値を設定することで、条件が成立するかを判定します。成立した場合、対応する分岐フローを実行します。
- 処理ロジック:異なる条件に応じて異なるパスを進みます(条件を満たすものがない場合は Else に進みます)。
- 出力結果:直接的な出力はなく、次のノードへの進行方向のみを決定します。
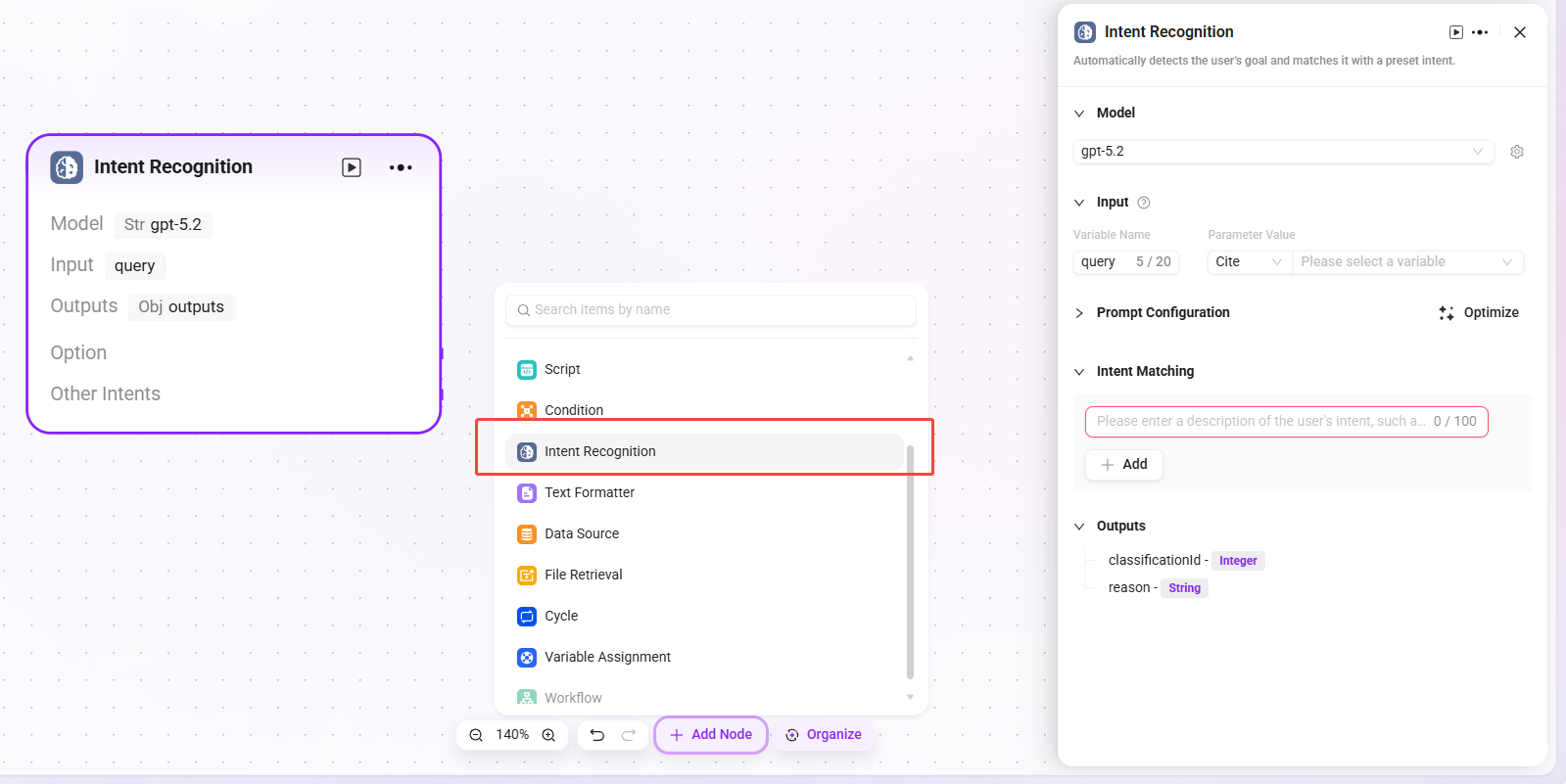
意図認識
意図認識は自然言語処理における重要な工程であり、このモジュールの役割はユーザー入力内容を分析し、その真の意図を特定して事前設定されたオプションにマッチングすることです。
- モデル:意図認識に使用するモデルを選択します。モデルは意図認識の能力と効果を決定します。
- 意図マッチング:ユーザー意図の説明を事前に入力してマッチング基準とすることができ、他の意図を追加することもできます。システムはこれに基づいて、ユーザー入力がどの事前設定意図に該当するかを判断します。
- 詳細設定:
- システムプロンプト:プロンプト内容をカスタマイズでき、入力変数の参照をサポートしてプロンプト効果を最適化します(プロンプト内容の上限は 5000 文字)。
- 履歴記憶件数:参照する対話履歴ターン数を設定し、モデルがコンテキスト情報を組み合わせて認識精度を向上できるようにします。
- 処理ロジック:ユーザーの真の意図を判断し、入力を対応するカテゴリに分類します。
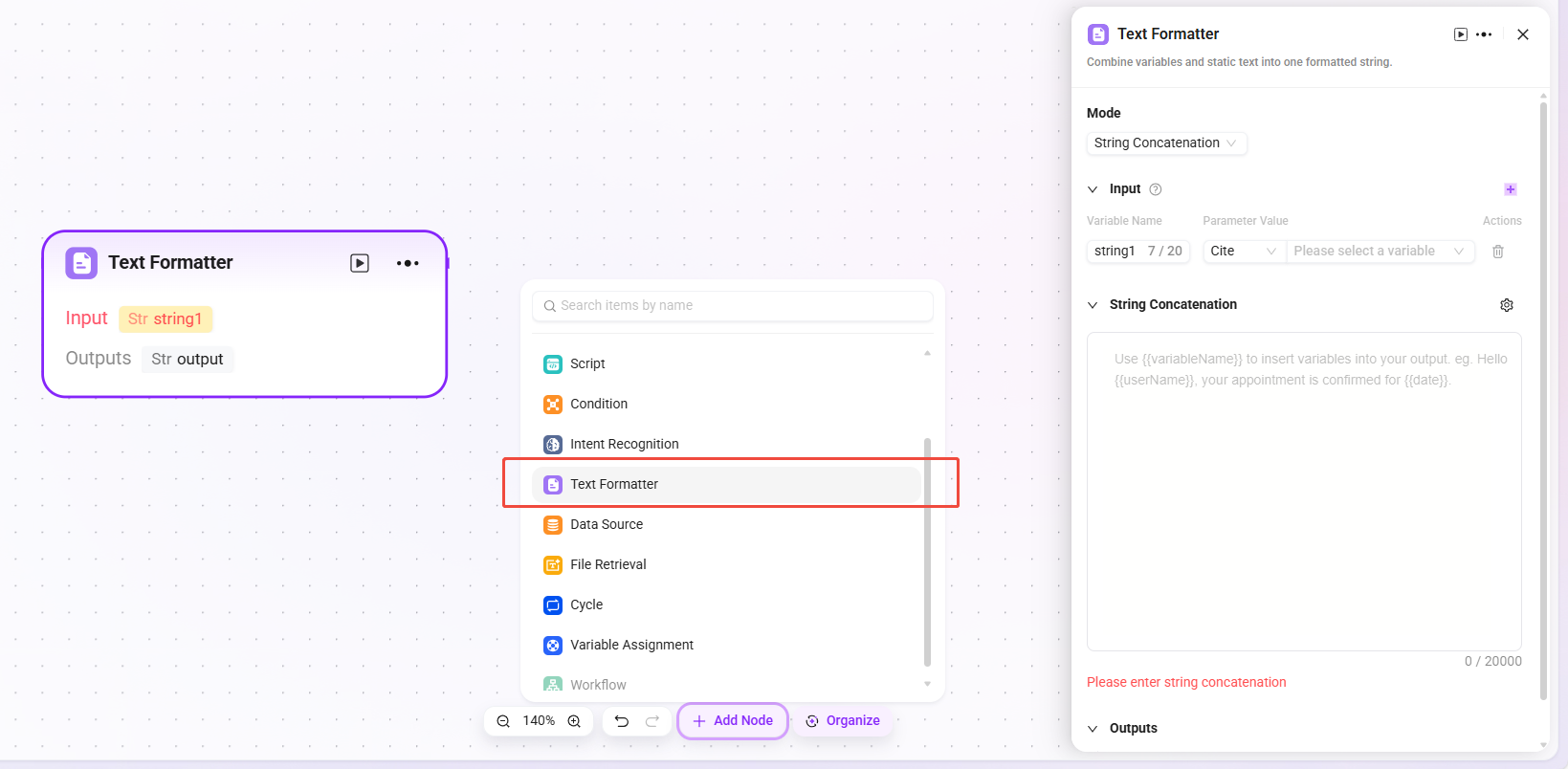
テキストフォーマッター
変数と固定テキストを組み合わせて、フォーマット済み文字列を作成するために使用します。
- 入力:変数名を定義し、参照方式でパラメータ値を取得して、後続のテキスト処理に元の文字列データを提供できます。
- 処理ロジック:テキストに簡単な加工を行います。
- 文字列連結
- 文字列分割
- 区切り文字:区切り文字をカスタマイズまたは選択できます
- 文字列連結:テキスト編集エリアを提供し、必要に応じて変数名方式で入力変数を参照し、複数文字列の連結などのフォーマット処理を行えます。
- 使用制限:単一ワークフロー内で、テキストフォーマッターノード数の上限は 20 個です。
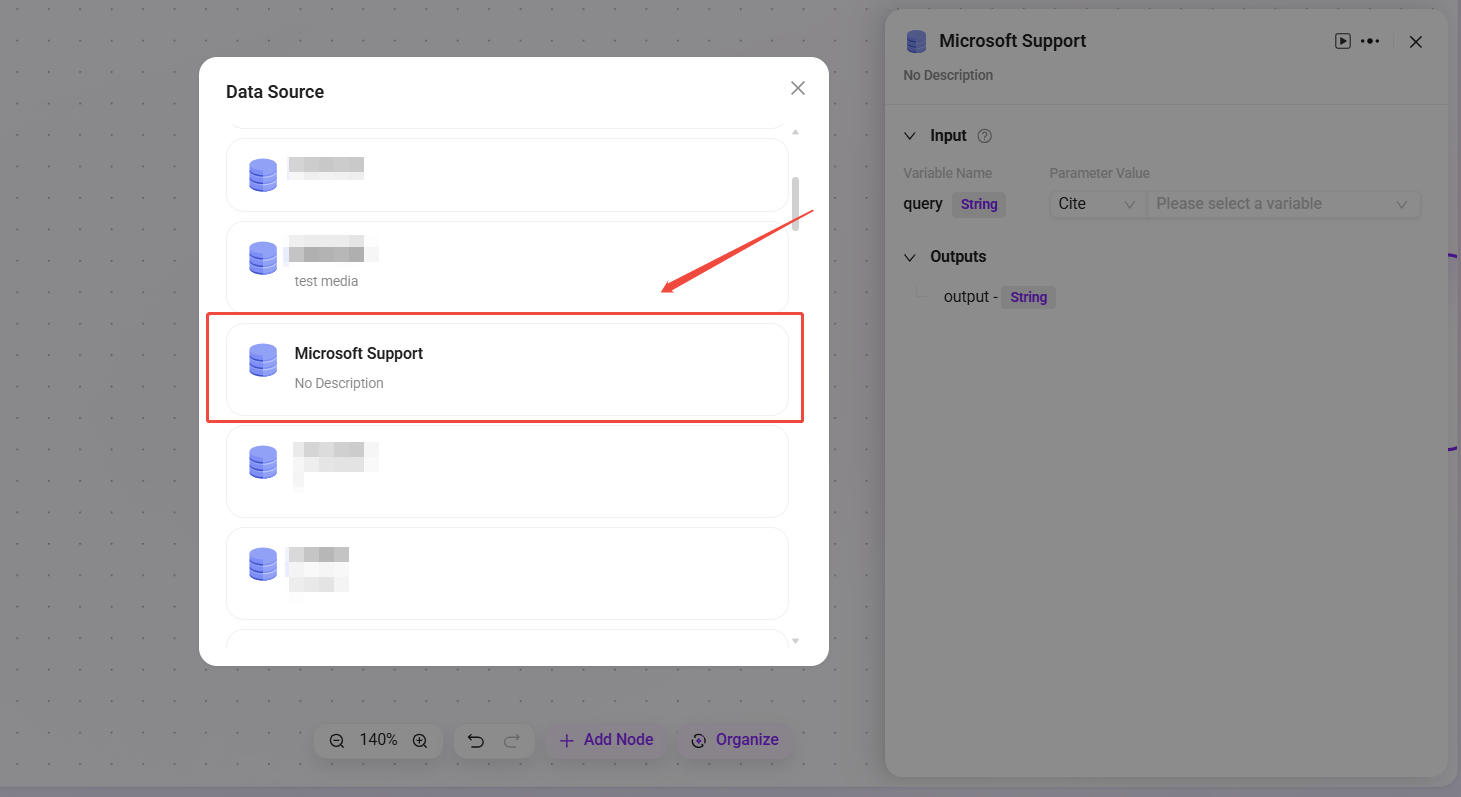
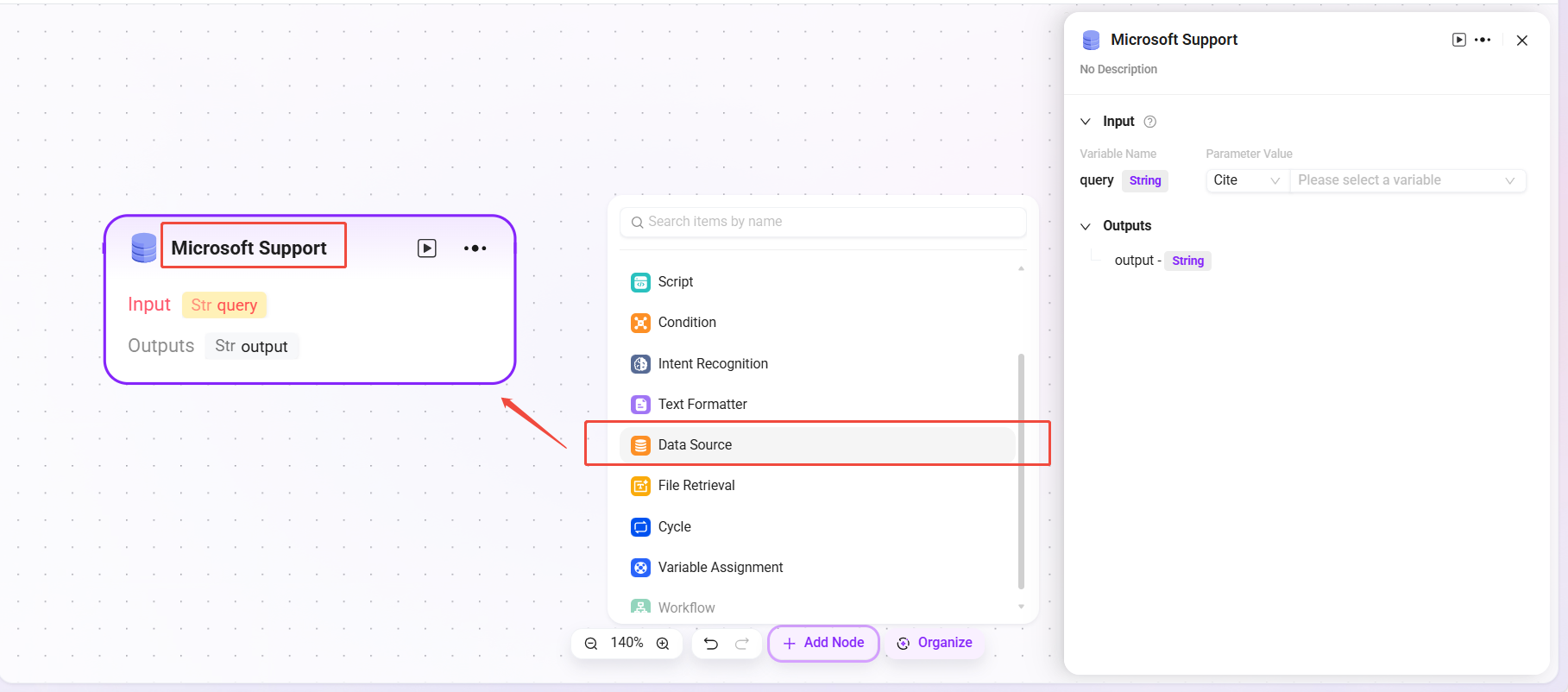
データソース
- データソース:接続するデータソースを選択します。
- 処理ロジック:自然言語をSQLに変換してデータベースを照会し、結果を返します。
- 出力:データソースのデータを出力し、次のノードに渡します。
ファイル検索
ファイル検索は、ファイル内容の検索などを行う機能モジュールです。
- 入力:変数名を定義し、パラメータ値を参照して検索キーワードなどの入力情報を提供し、ファイル内容検索の根拠とします。
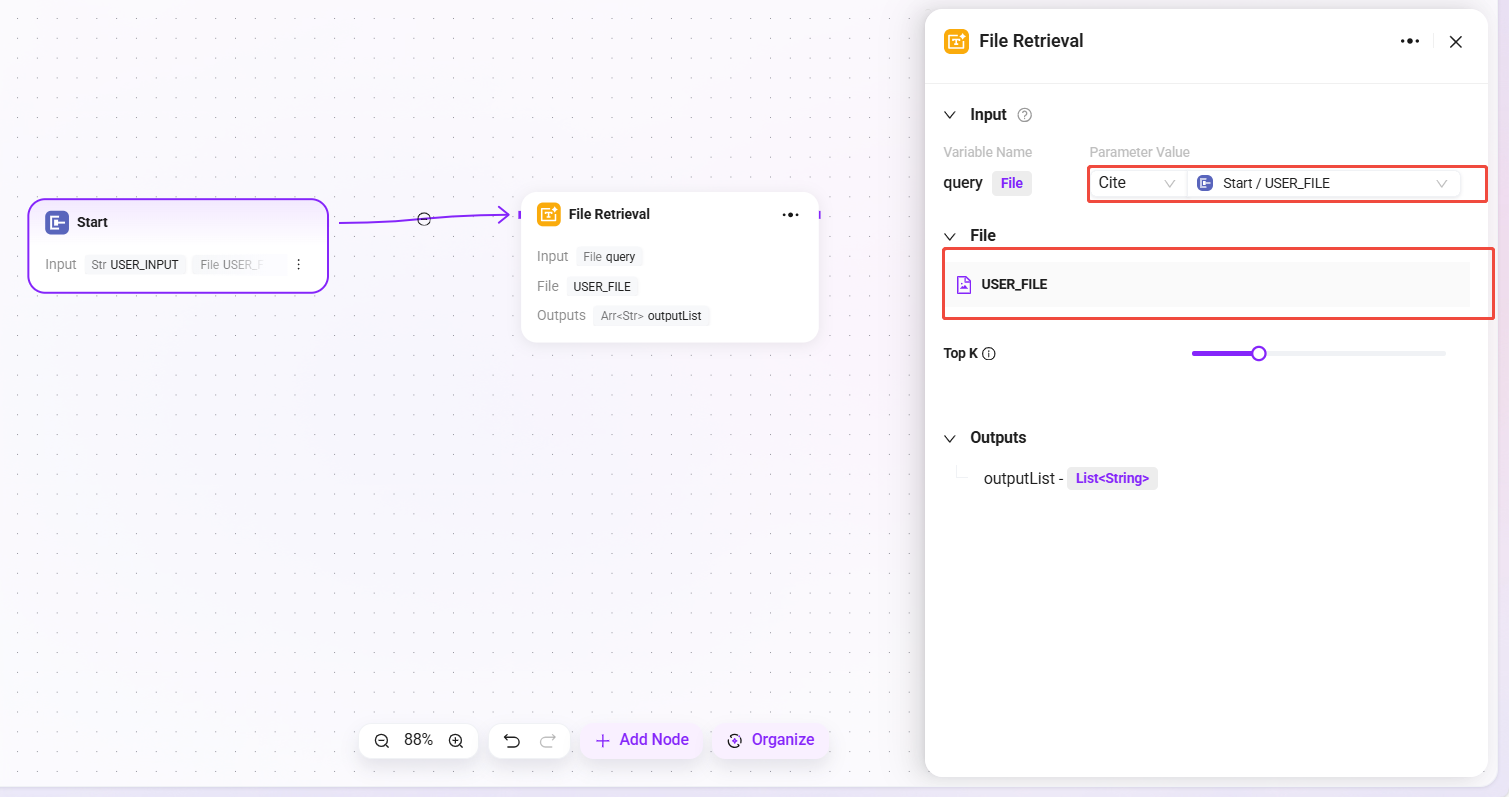
- ファイル:処理対象のファイルをこのノードに追加し、検索対象ファイルの範囲を確定できます。
- 処理ロジック:入力された検索キーワードに基づき、指定されたファイル範囲内で内容のマッチングと検索を行い、関連する断片または情報を特定します。
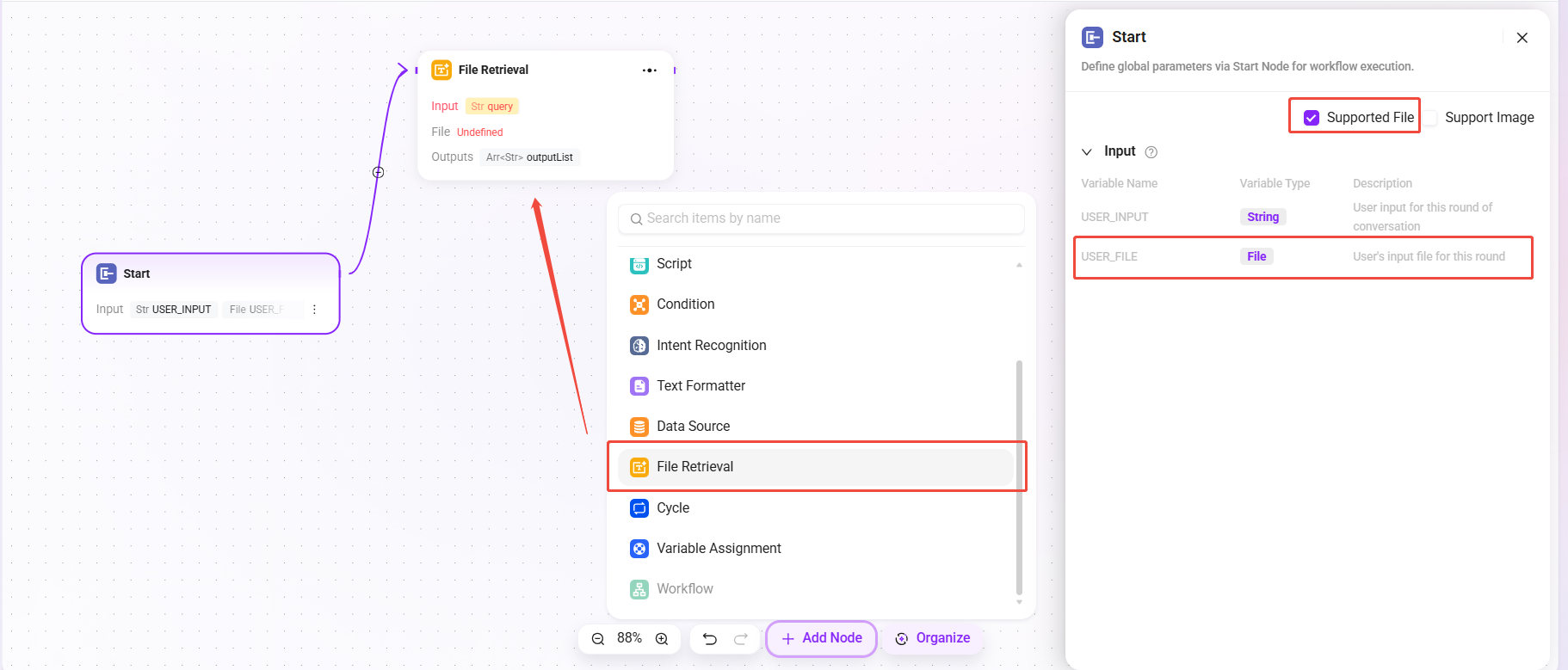
ファイル検索を設定
- まず「開始」ノードで「ファイルをサポート」にチェックを入れる必要があります
- チェック後、開始ノードに変数「USER_FILE」が表示され、これはユーザーの今回入力したファイルを指します
- 次に「開始」ノードと「ファイル検索」ノードを接続します
- 接続後、ファイル検索ノードで「USER_FILE」を検索対象ファイルとして追加できます。
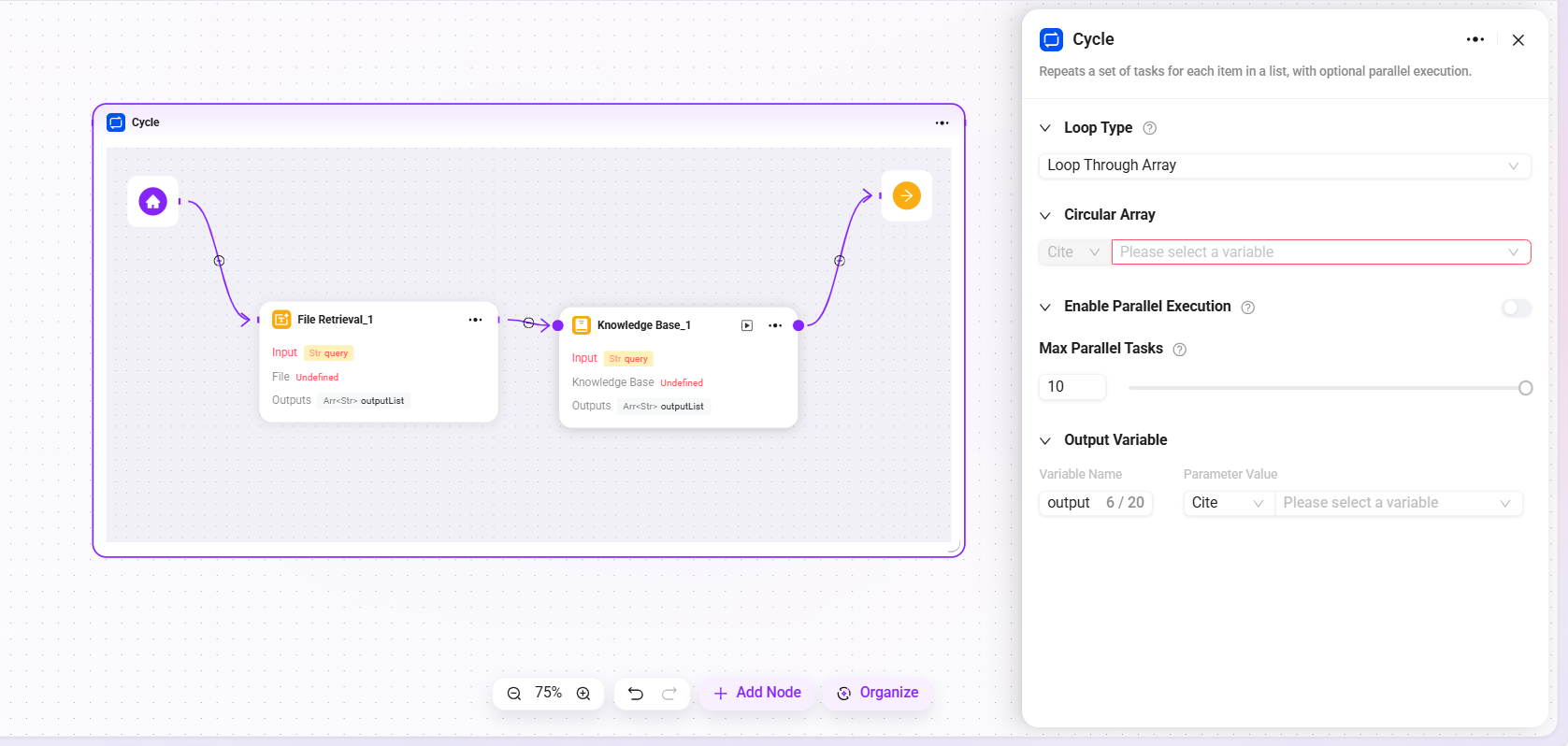
ループ
指定回数または指定データ集合に従って、一連のタスクを繰り返し実行するために使用します。異なるループモードを設定することで、バッチ処理や繰り返し操作を柔軟に実現できます。
- ループタイプ:2つのモードをサポートします
- 配列ループを使用:入力配列に基づき、配列内の各要素に対して順番にタスクを実行します。
- 数値ループを使用:設定した回数に従って、タスクを繰り返し実行します。
- ループ数値/配列:
- 「数値ループ」を選択した場合、具体的な数値(例:
2)を入力する必要があり、これはタスクが 2 回実行されることを意味します。 - 「配列ループ」を選択した場合、配列変数を提供する必要があり、システムは配列内の要素を1つずつ取り出して入力としてタスクを実行します。
- 「数値ループ」を選択した場合、具体的な数値(例:
- 並列実行:任意機能です。有効にすると、システムは複数のループタスクを同時に処理し、効率を向上させます。ユーザーは最大並列数を設定してリソース使用量を制御できます。
ワークフロー
他の設定済みワークフローを参照・呼び出し、モジュール化されたネストとフロー再利用を実現するために使用します。
- ワークフロー選択:既存のワークフロー一覧から、呼び出したい子ワークフローを選択します。
- 入力マッピング:現在のフロー内の変数を子ワークフローの入力パラメータにマッピングします。
- 出力マッピング:子ワークフローの出力結果を現在のフローの変数にマッピングし、後続ノードで使用できるようにします。
- 処理ロジック:参照した子ワークフローを実行し、その実行完了を待って結果を返します。
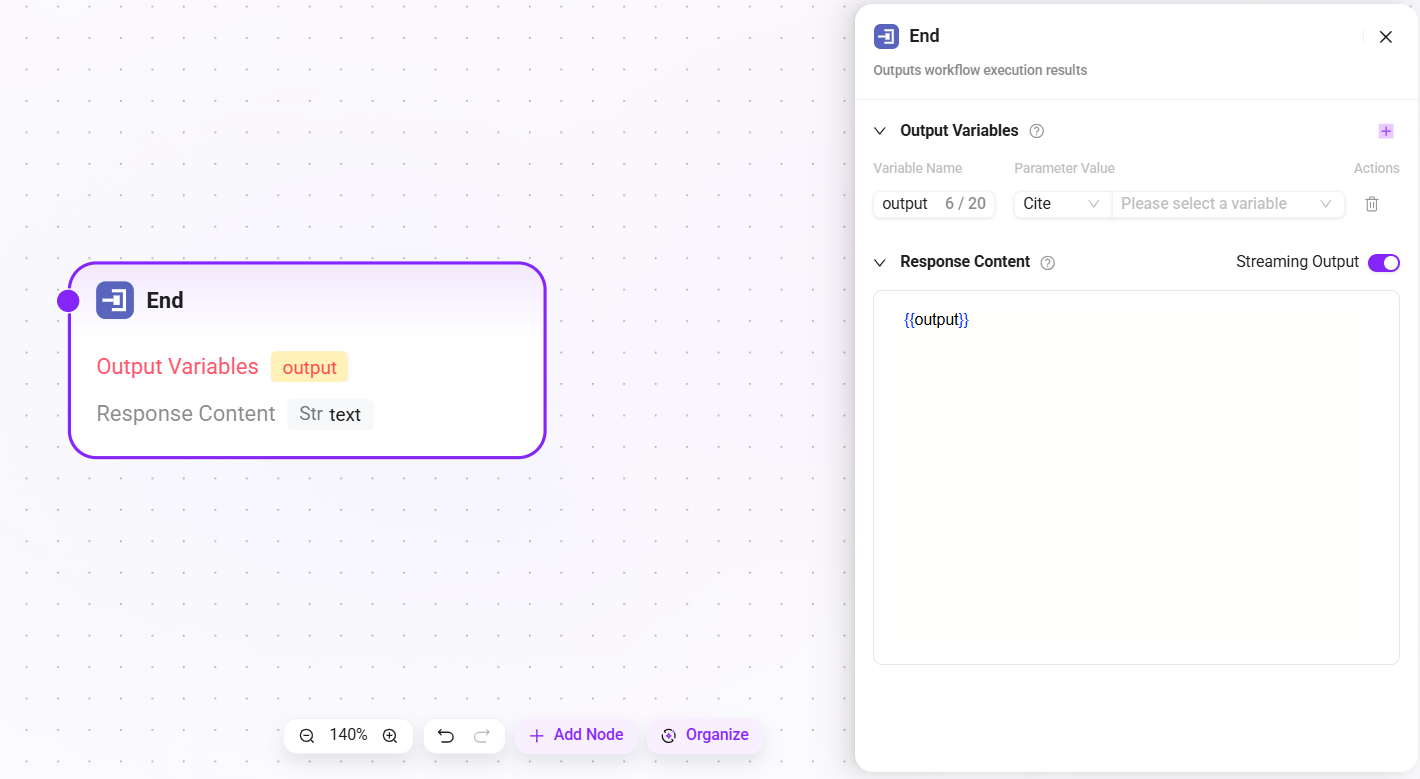
終了
ワークフローの最終ノードであり、ワークフロー実行後の結果情報を返すために使用します。
- 出力変数:エージェントがワークフローを呼び出して完了した後、これらの変数が出力されます。
- 回答内容:エージェントの返信テキストを編集します。ワークフロー実行終了後、エージェント内の LLM は自動で文章を組み立てず、ここで編集した原文を直接使用して返信します。
{{变量名}}形式で出力変数を参照できます。 - ストリーミング出力:ストリーミング出力方式を有効にするかどうかを選択できます。
ワークフロー例
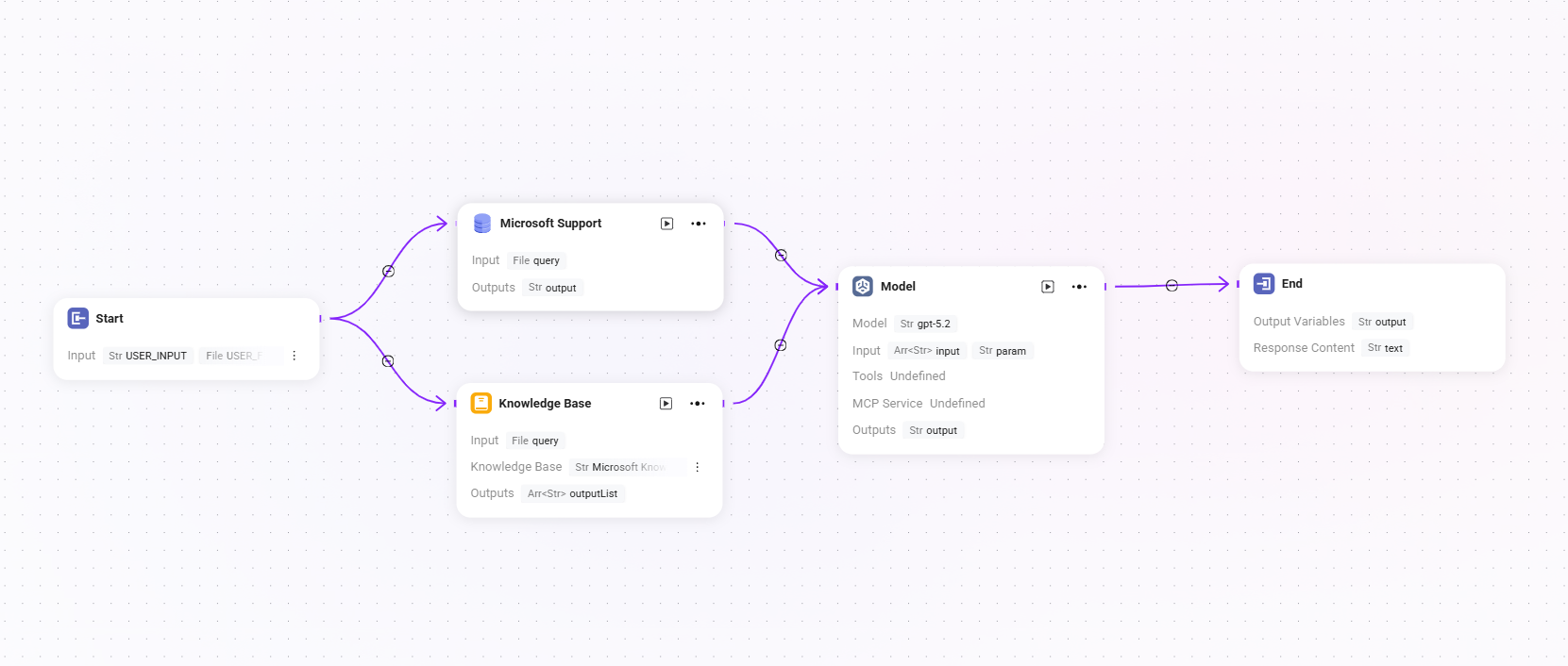
このシナリオでは、ワークフロー機能を使用して完全な「Microsoft Support Ticket Issue Analytics」フローを構築します。具体的な流れは以下のとおりです:
- 開始ノード
フローの開始点であり、システムにデフォルトで含まれています。 - データソースノード
チケット分析に必要な元データを接続するために使用します。 - ナレッジベースノード
分析参考資料を含むナレッジ文書を接続し、AI分析の理論的支援とします。 - モデルノード
AIモデルに基づき、データソースとナレッジベースの内容を組み合わせて総合分析を行い、チケット問題分析結果を生成します。 - 終了ノード
フローの終点であり、モデルノードの分析結果を出力します。このノードはシステムにデフォルトで含まれています。
データソースノードとナレッジベースノードは並列に設定され、モデルノードが前者2つの情報を集約して処理することで、出力結果にデータ根拠と理論的支援が備わるようにします。
最終的な効果は以下のとおりです:
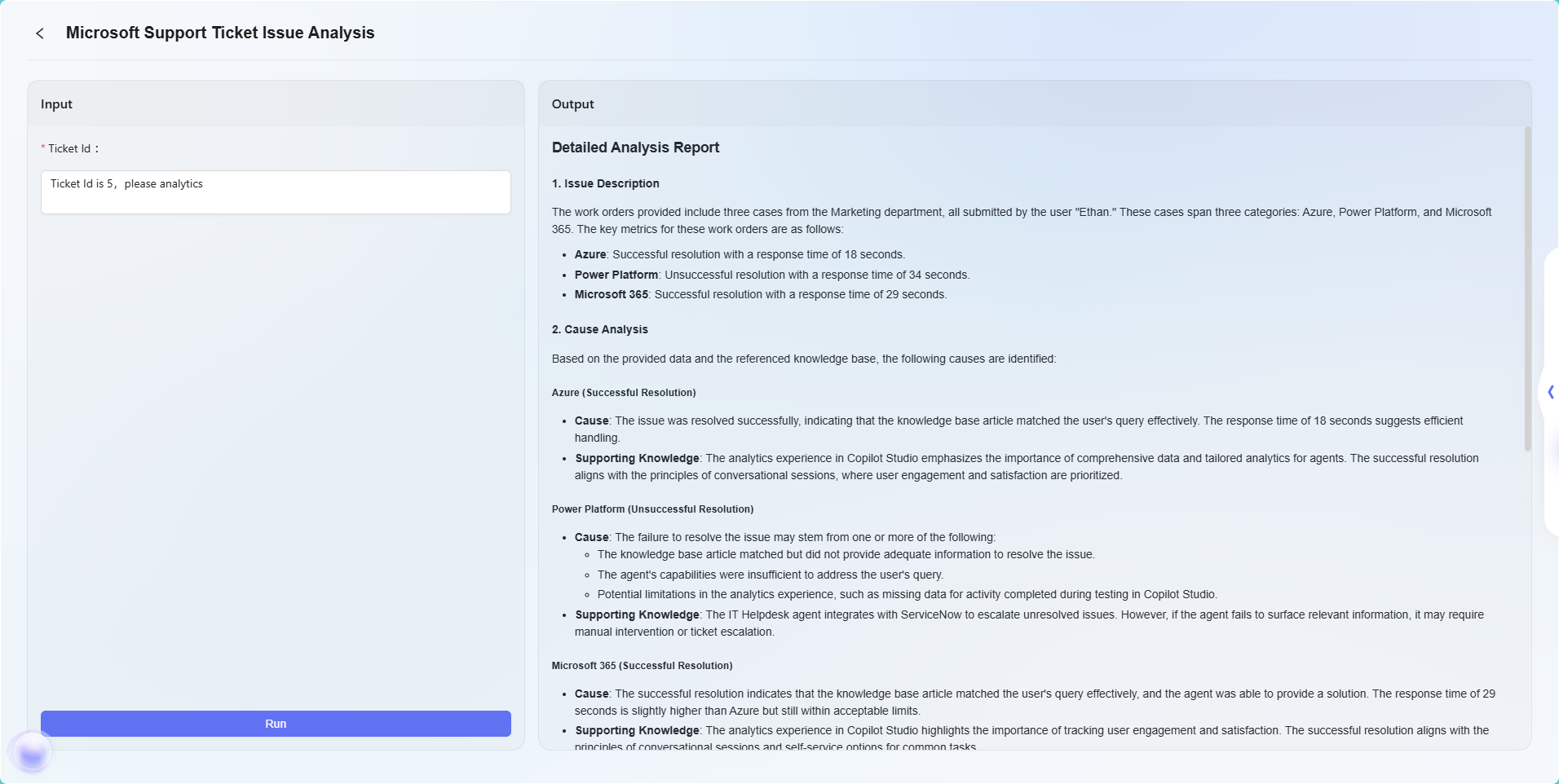
注:本例はワークフロー機能の基本的な利用デモにすぎません。ワークフローオーケストレーションは高い柔軟性と拡張性を備えており、各種ノードを組み合わせることで、極めて複雑な業務ロジックと自動化フローを実現でき、幅広い業務シナリオ要件に対応できます。
変数管理
オーケストレーションの柔軟性を高め、ノード間の明示的な結合を減らすために、ワークフローは環境変数とセッション変数の2つの仕組みをサポートしています。それぞれ設定系パラメータと実行時の中間状態を保存するために使用されます。すべての変数はノード設定項目内の入力変数から直接呼び出すことができます。
- 設定入口:変数管理パネルはキャンバス右上にあり、対応するアイコンをクリックすると展開できます。

チャット変数
チャット変数は、ワークフロー実行中の中間状態、コンテキスト結果、またはユーザーの一時入力(例:前回の分析結論、実行フラグ、ユーザー設定など)を保存するために使用されます。そのスコープは Workflow 実行インスタンスレベル であり、同一インスタンス内のすべてのノードで共有され、異なるインスタンスまたはユーザーコンテキスト間では厳密に分離されます。
- 読み書き権限:読み書き可能で、ノード内での動的代入、上書き、クリアをサポートします。
- 対応型:
String、Number、Boolean、Integer、Object、List<String>、List<Number>、List<Boolean>、List<Integer>、List<Object>をサポートします。 - 適用範囲:同一実行インスタンス内のすべてのノードで共有されます。
クリーンアップ機構:
- 手動クリーンアップ:ある Agent がセッション変数を使用している場合、そのアイコン上にほうきマークが表示されます。クリックすると二次確認ダイアログが表示され、複数のクリーンアップ項目を選択できます。**デフォルトでは「コンテキストをクリア」と「セッション変数」**が選択されています。
- APIクリーンアップ:個別のセッション変数クリアAPIを提供しており、納品シナリオで外部システムから呼び出して、自動化されたセッション状態リセットを実現できます。
環境変数
環境変数は、API キー、グローバルスイッチ、モデル名などの設定系・システムレベルのパラメータを保存するために使用されます。そのスコープは Workflow 定義レベル であり、同一ワークフローのすべての実行インスタンスでこの設定が共有されます。
- 読み書き権限:読み取り専用。変数値は定義時に固定され、実行時には変更できません。
- 対応型:
String、Number、Secret(暗号化文字列。API Key などの機密情報保存に使用)。 - 適用範囲:ワークフロー内のすべてのノードで参照できます。
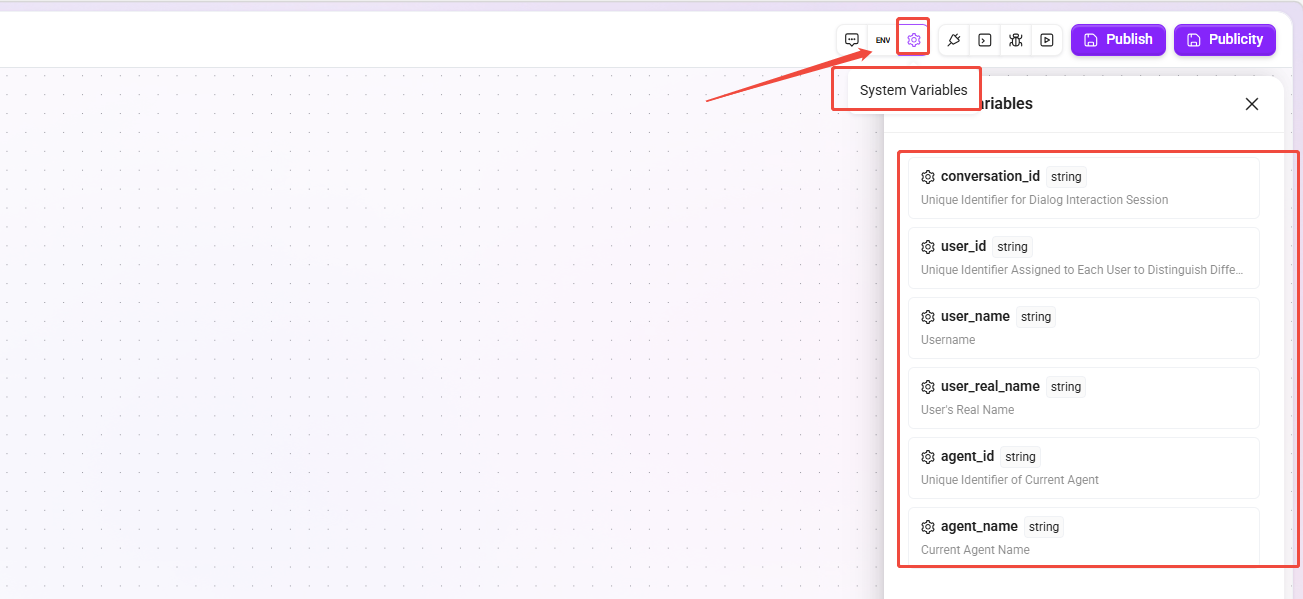
システム変数
現在のセッションまたはエージェントのメタデータ情報を取得するための、システムにあらかじめ用意された読み取り専用変数です。手動作成は不要で、ノード内で直接参照できます。
| 变量名 | 类型 | 说明 |
|---|---|---|
conversation_id | string | 現在の対話ボックス対話セッションの一意識別子。 |
user_id | string | 現在の対話ユーザーの一意識別子。 |
user_name | string | ユーザー名。 |
user_real_name | string | ユーザーの実名。 |
agent_id | string | 現在のエージェントの一意識別子。 |
agent_name | string | 現在のエージェント名。 |
ログデバッグ
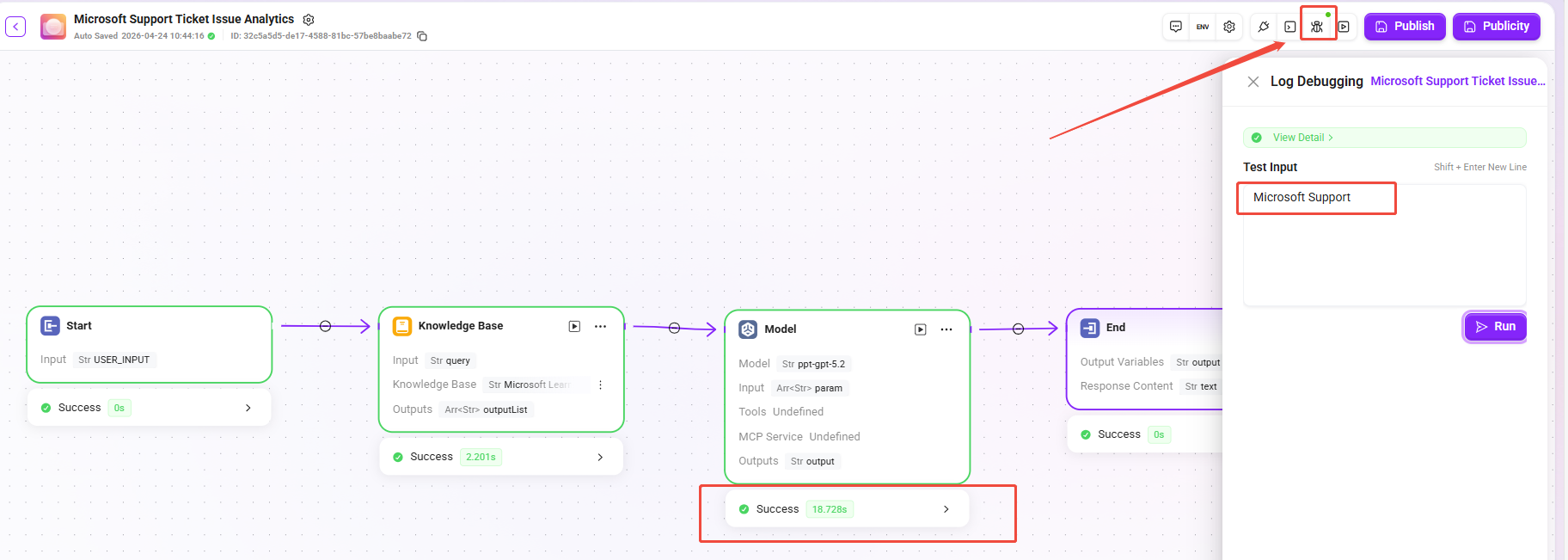
ログデバッグは、オーケストレーション段階でフローの問題を特定するために使用します。ユーザーが具体的な問題を入力すると、ノードごとに入力変数と出力変数を確認でき、データ受け渡しが期待どおりかを迅速に確認できます。
- 起動方法:キャンバス右上の 「ログデバッグ」 ボタンをクリックし、テスト入力欄に問題(例:
Microsoft Support)を入力して実行をクリックすると、システムが現在のワークフローを自動実行します。 - 実行過程:実行中、正常に実行されたノードは緑色表示になり、ノード下部に実行状態と所要時間が表示されます。ノードをクリックすると、そのノードの入力変数と出力変数の詳細を確認できます。
- 詳細確認:
- テスト入力欄の上部に 「詳細を見る」 ボタンがあります。
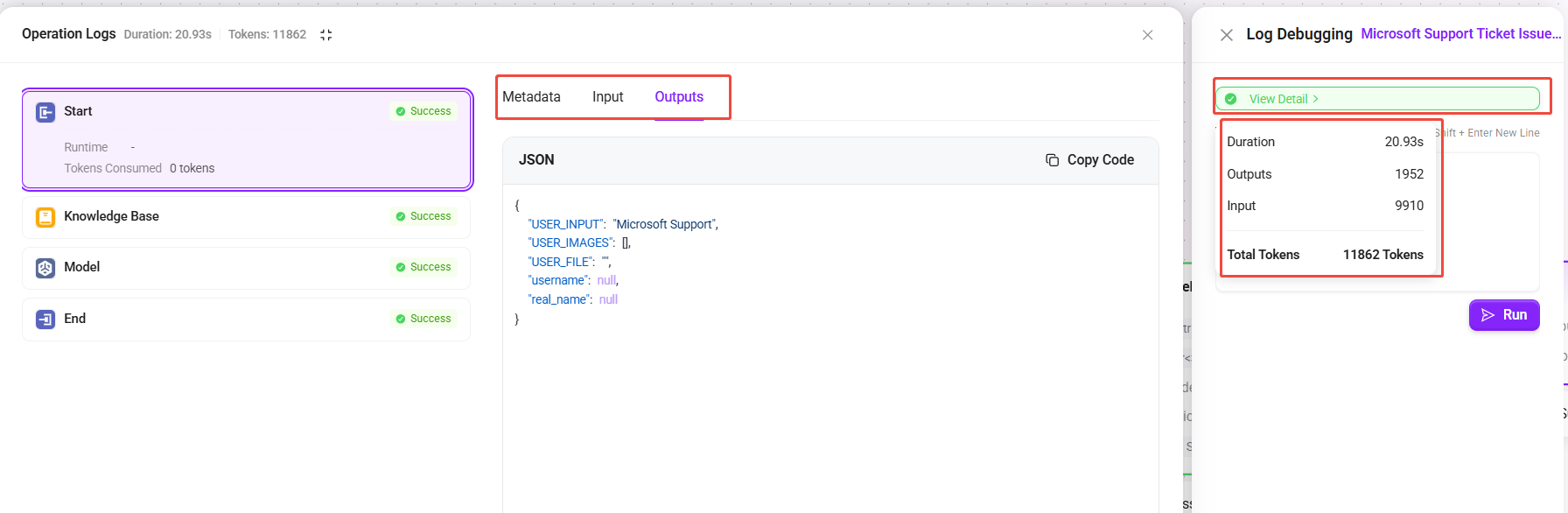
- ボタンにマウスをホバーすると、今回の実行の総所要時間、入出力で消費した Token、および総 Token 数をすばやくプレビューできます。
- ボタンをクリックして詳細パネルに入ると、各ノードの完全な入力内容と出力内容(JSON 形式)、およびメタデータ(開始時刻、実行時間、Token 消費明細を含む)を確認できます
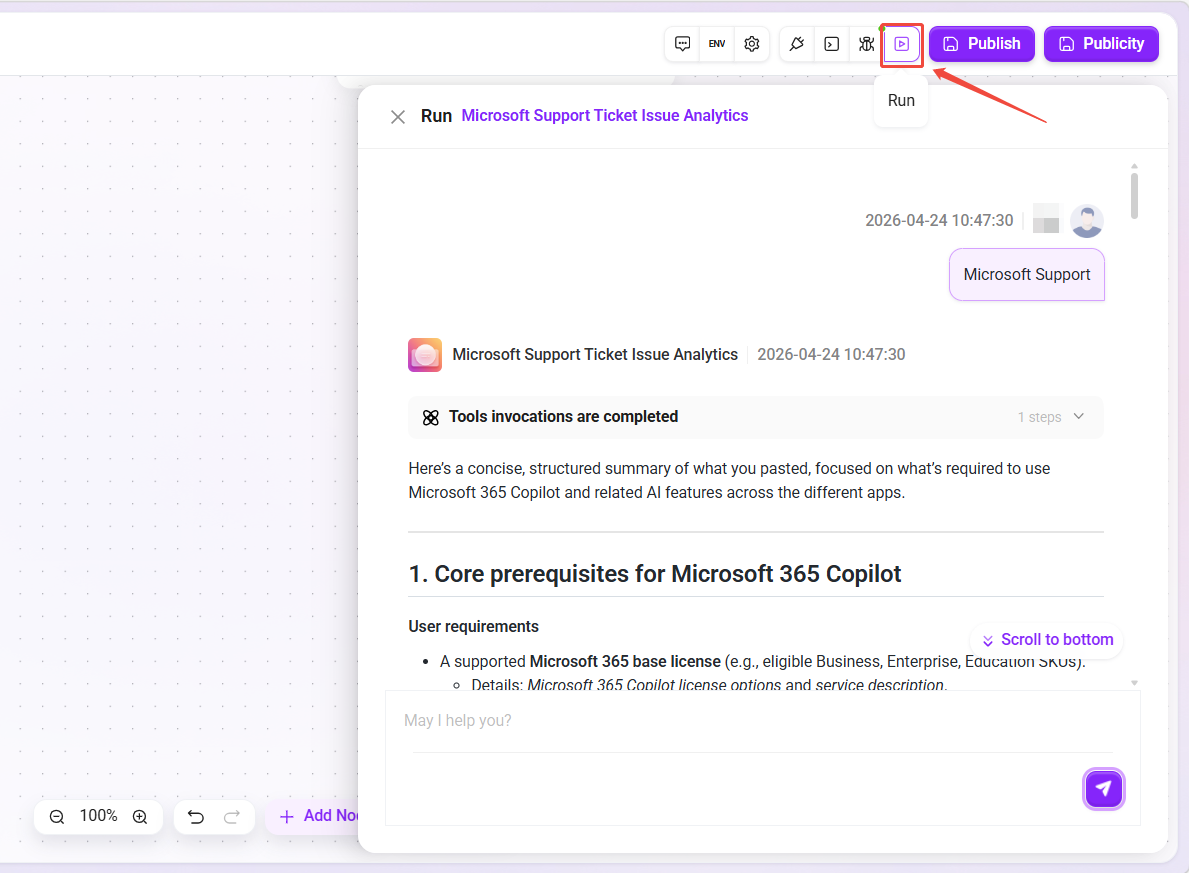
試運転
試運転は、実際のQ&Aシナリオをシミュレートし、ワークフロー全体のオーケストレーション効果とアシスタント最終応答品質を検証するために使用します。
- 起動方法:キャンバス右上の 「試運転」 ボタンをクリックし、対話パネルにテスト問題を入力すると、ワークフローは公開後のロジックに従って完全に実行されます。
- 効果プレビュー:実行終了後、パネルにアシスタントの最終回答内容が表示され、応答が業務期待を満たしているかを直感的に判断できます。
- 即時調整:応答結果が理想的でない場合、試運転画面で直接ノード設定(プロンプト、パラメータなど)を修正でき、何度もキャンバス設定ページへ移動する必要がなく、デバッグ効率が向上します。
注意:試運転は本番エージェントの実際の会話記録には影響せず、すべてのテストデータは現在のデバッグセッション内でのみ有効です。