データの使い方
概念
データモジュールは、企業がデータ資産を効率的に管理・活用・共有できるように設計されています。柔軟なデータインターフェース、メタデータ管理、データソース設定、データインポート機能を通じて、ユーザーはデータフロー全体を把握し最適化できます。製品は直感的な操作画面を提供し、データのクエリ、プレビュー、操作が容易で、データのサブスクリプションやプッシュ機能もサポートし、データのリアルタイム性と正確性を確保します。
全体アーキテクチャ
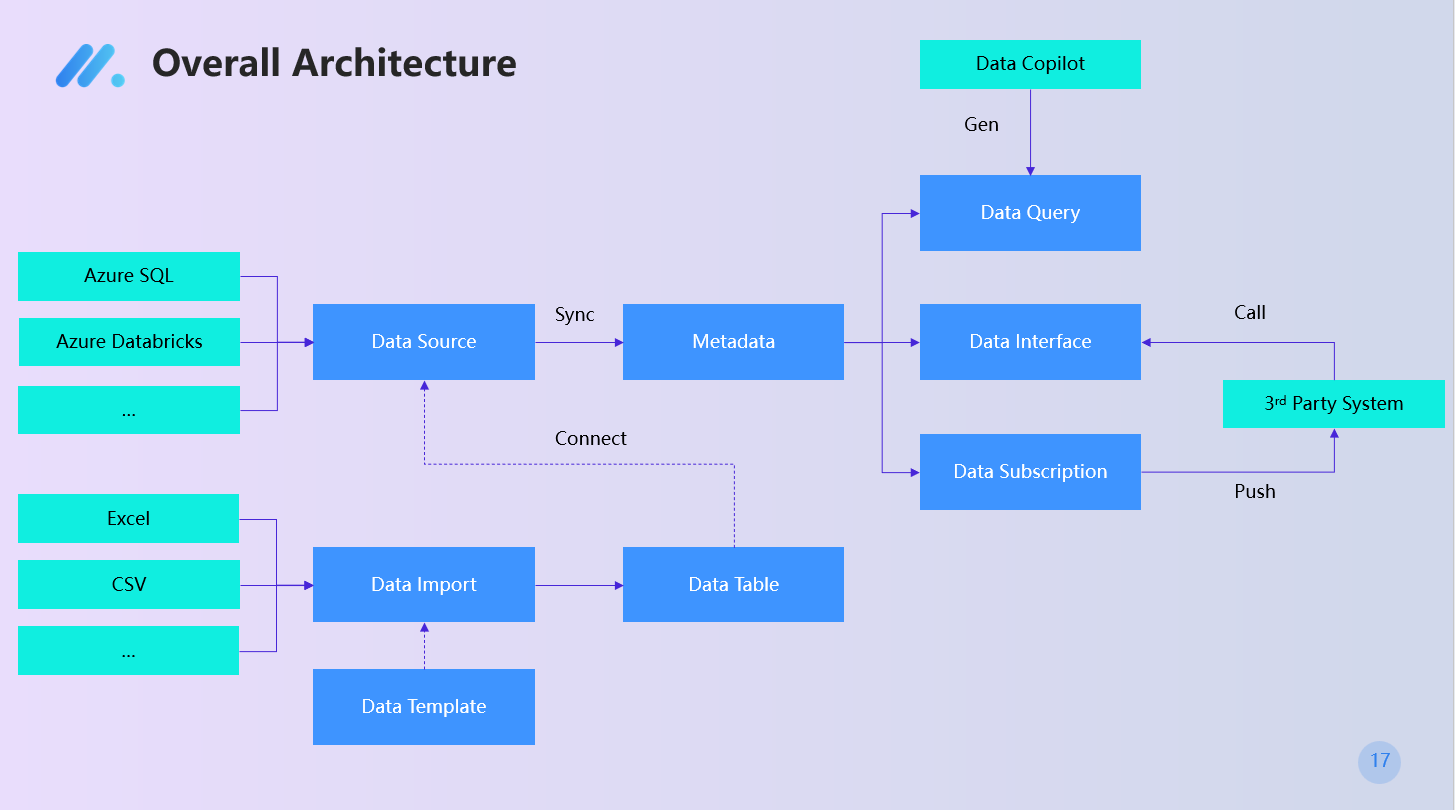
データ資産
データモジュールのエントリーポイントとして、データ資産モジュールは全体ビューを提供し、企業ユーザーがシステム内の各種データ資産の数や詳細情報を直感的に把握でき、現在のデータの全体像や分布状況を理解するのに役立ちます。
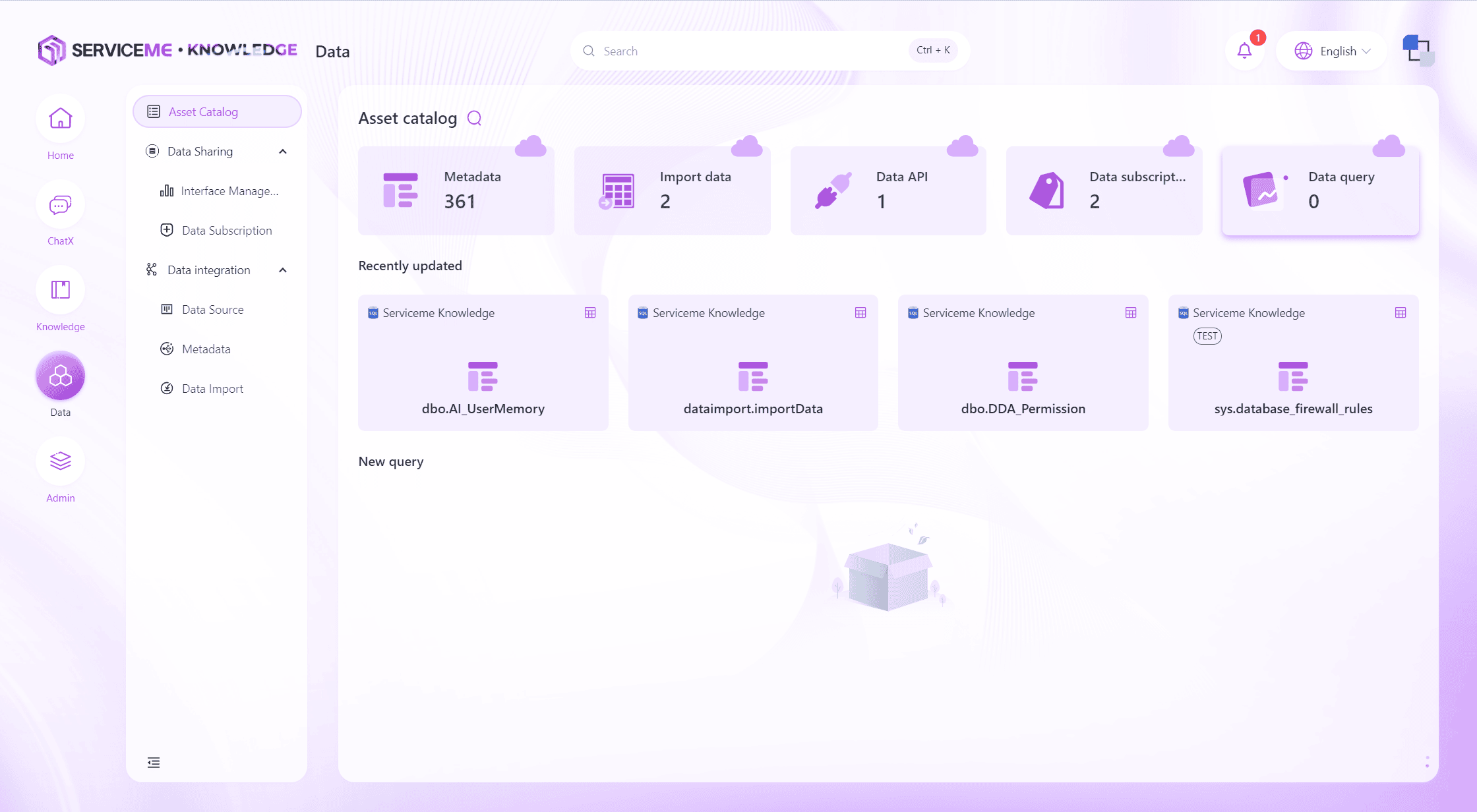
データ資産の検索
検索機能(虫眼鏡)を利用して、キーワードやデータ資産のカテゴリなどでデータ資産を素早く特定できます。
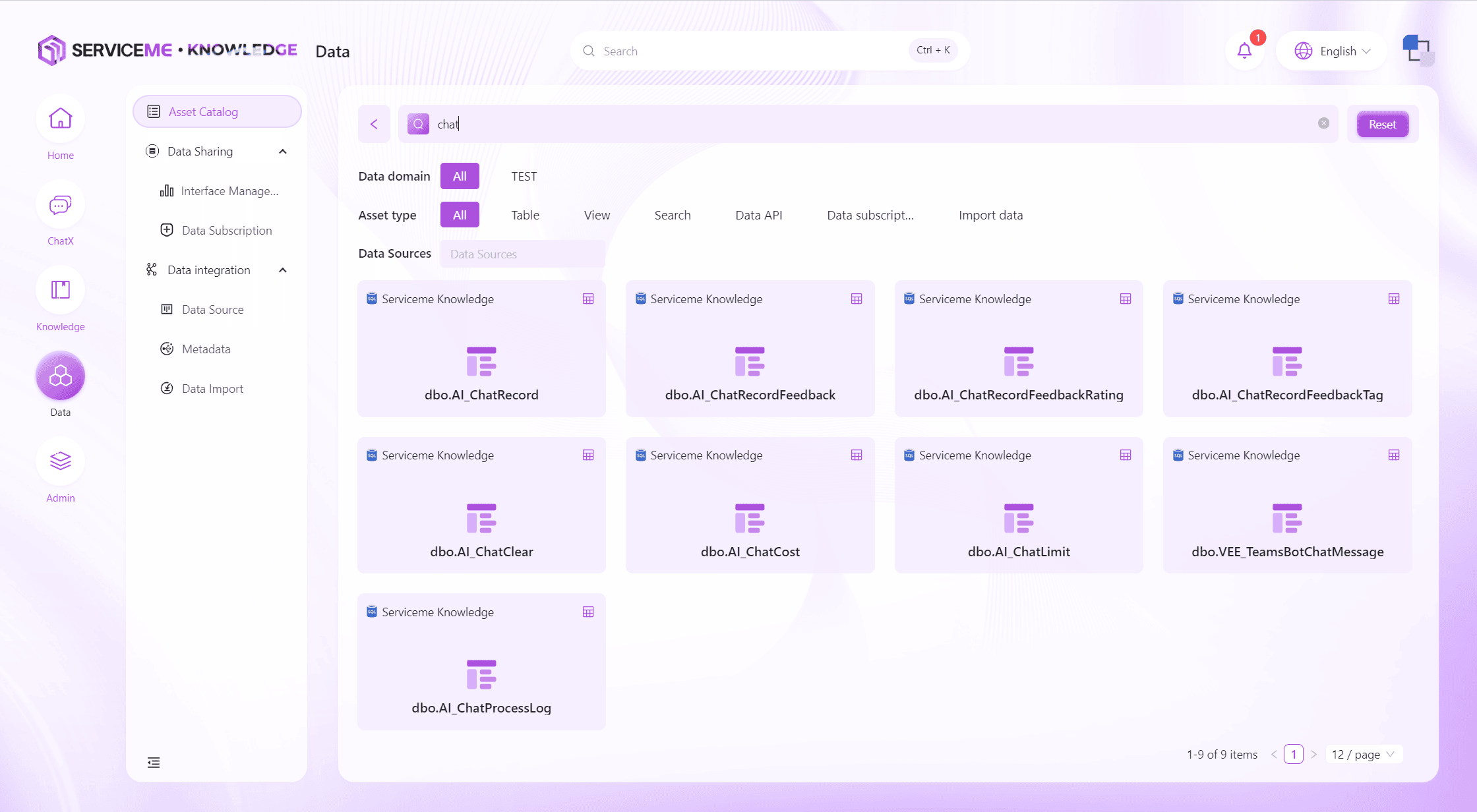
資産データとメタデータの閲覧
各データ資産のカードには、データプレビューやメタデータ閲覧へのクイックリンクが用意されています。

カード中央部分をクリックするとデータプレビュー画面に入り、該当データテーブルの一部データを確認でき、下にスクロールすることでさらに多くのデータを読み込めます。
ChatXモジュールが有効な場合、右側にAgent対話画面が表示され、ユーザーは自然言語で現在のデータをクエリし、システムからインサイトを得ることができます。
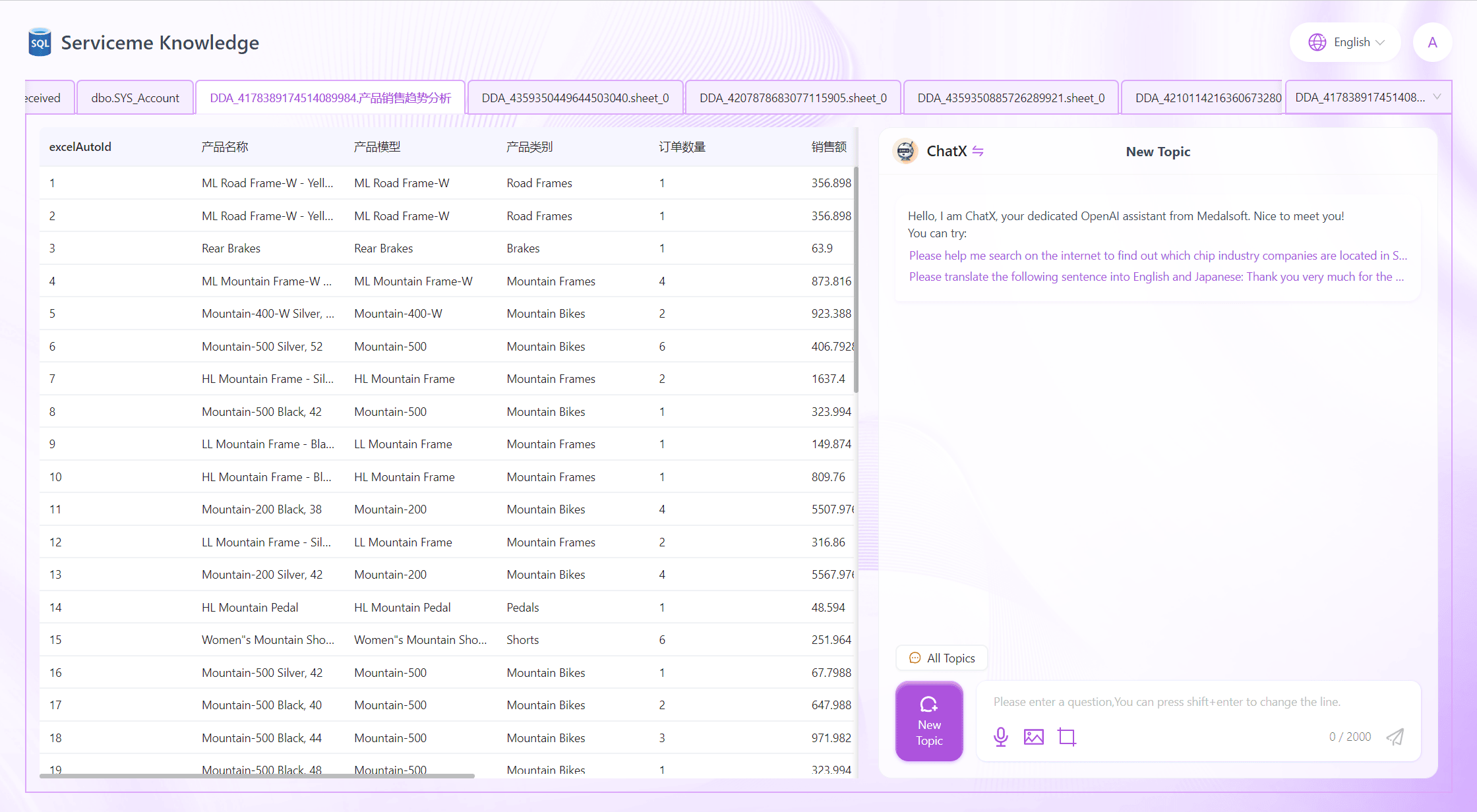
カード右上の[メタデータを見る]をクリックすると、メタデータ閲覧画面に入ります。ここではメタデータのテーブル名、コメント、備考などが表示され、テーブル内の全フィールドのフィールド名、コメント、型情報も含まれます。
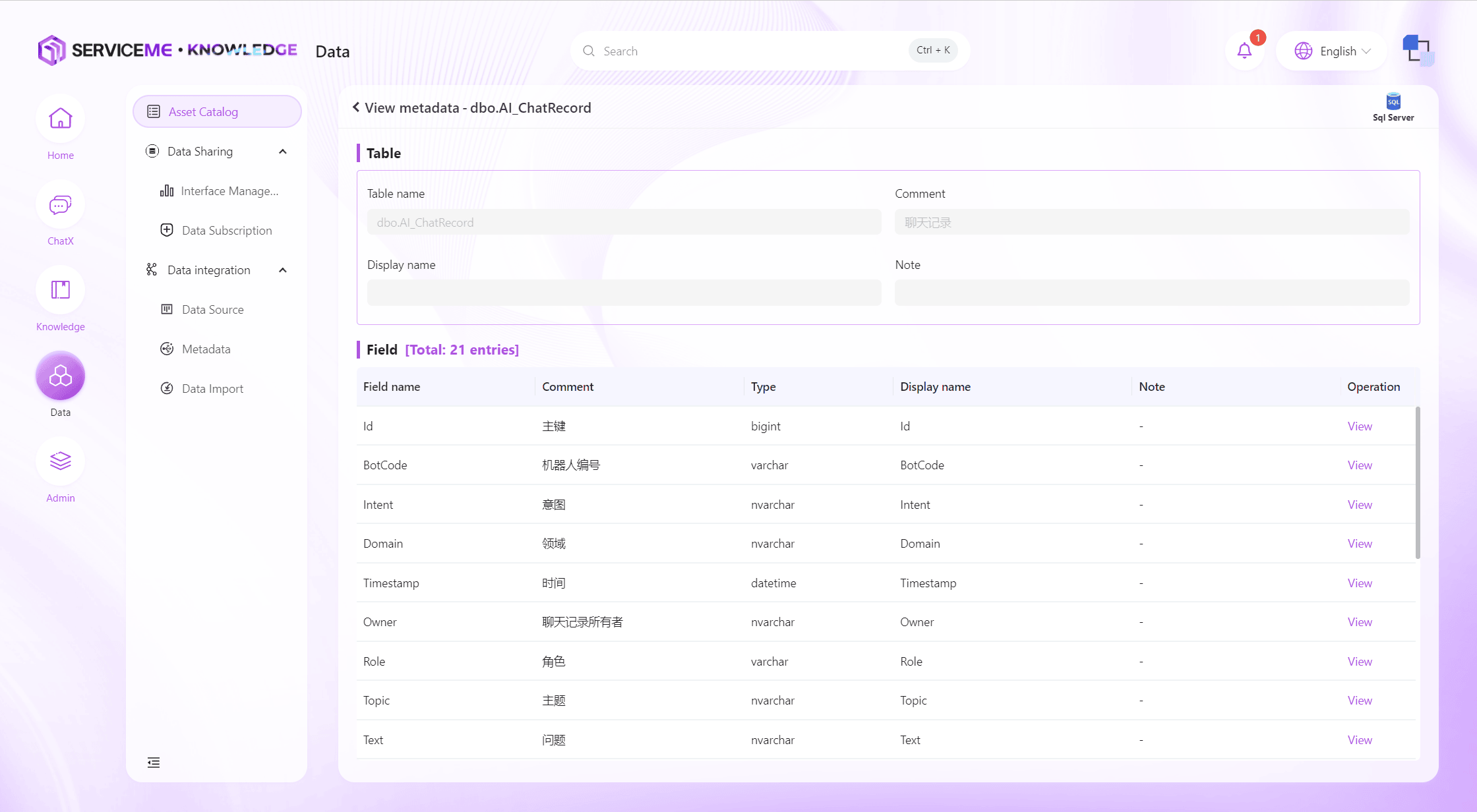
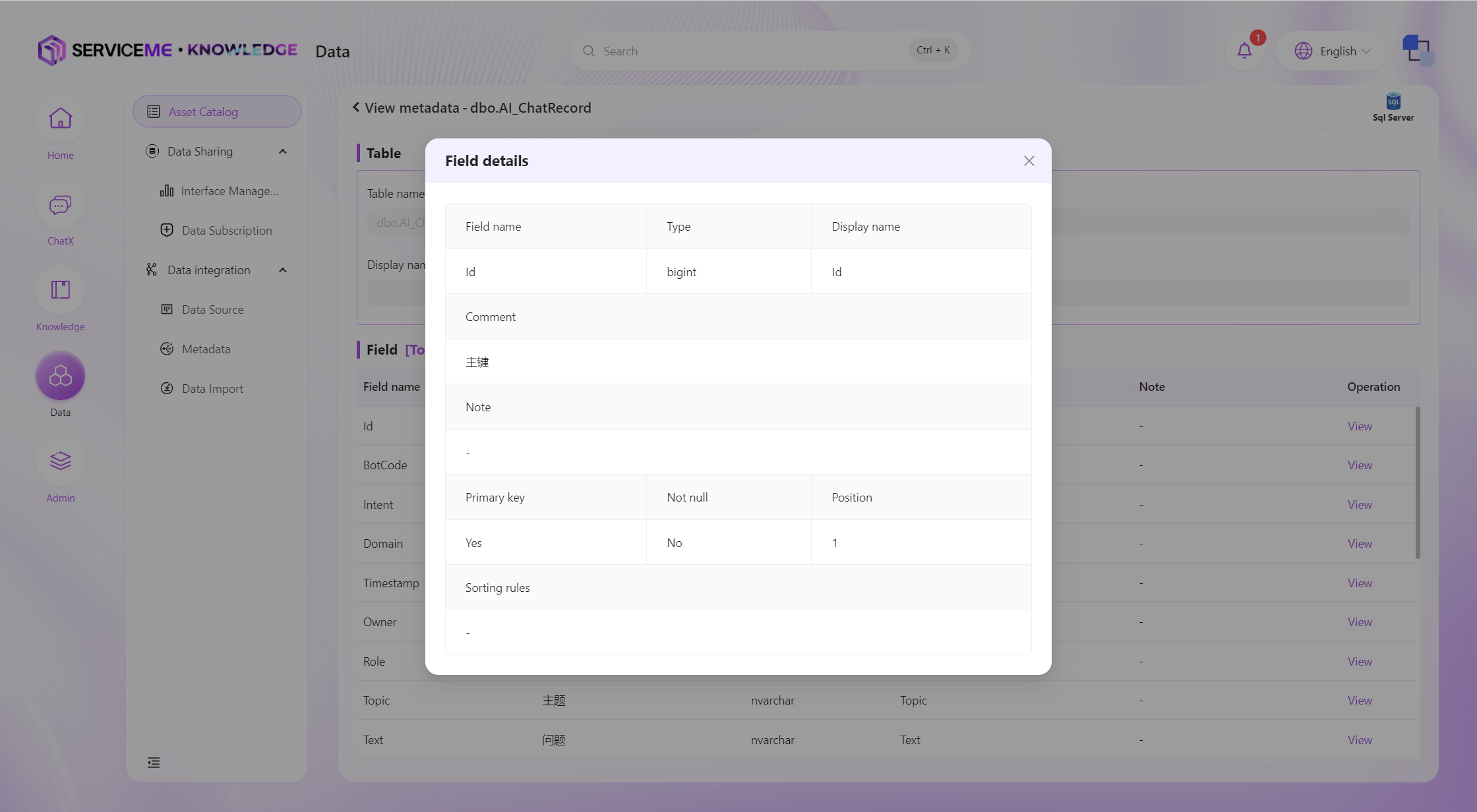
[見る]ボタンをクリックすると、フィールドの詳細ページに入ります。
データインターフェース
簡単なデータインターフェースの作成、編集、テスト機能を提供し、ユーザーは効率的にデータインターフェースを開発・保守できます。また、インターフェースログのクエリもサポートし、インターフェースの安定稼働とトレーサビリティを確保します。
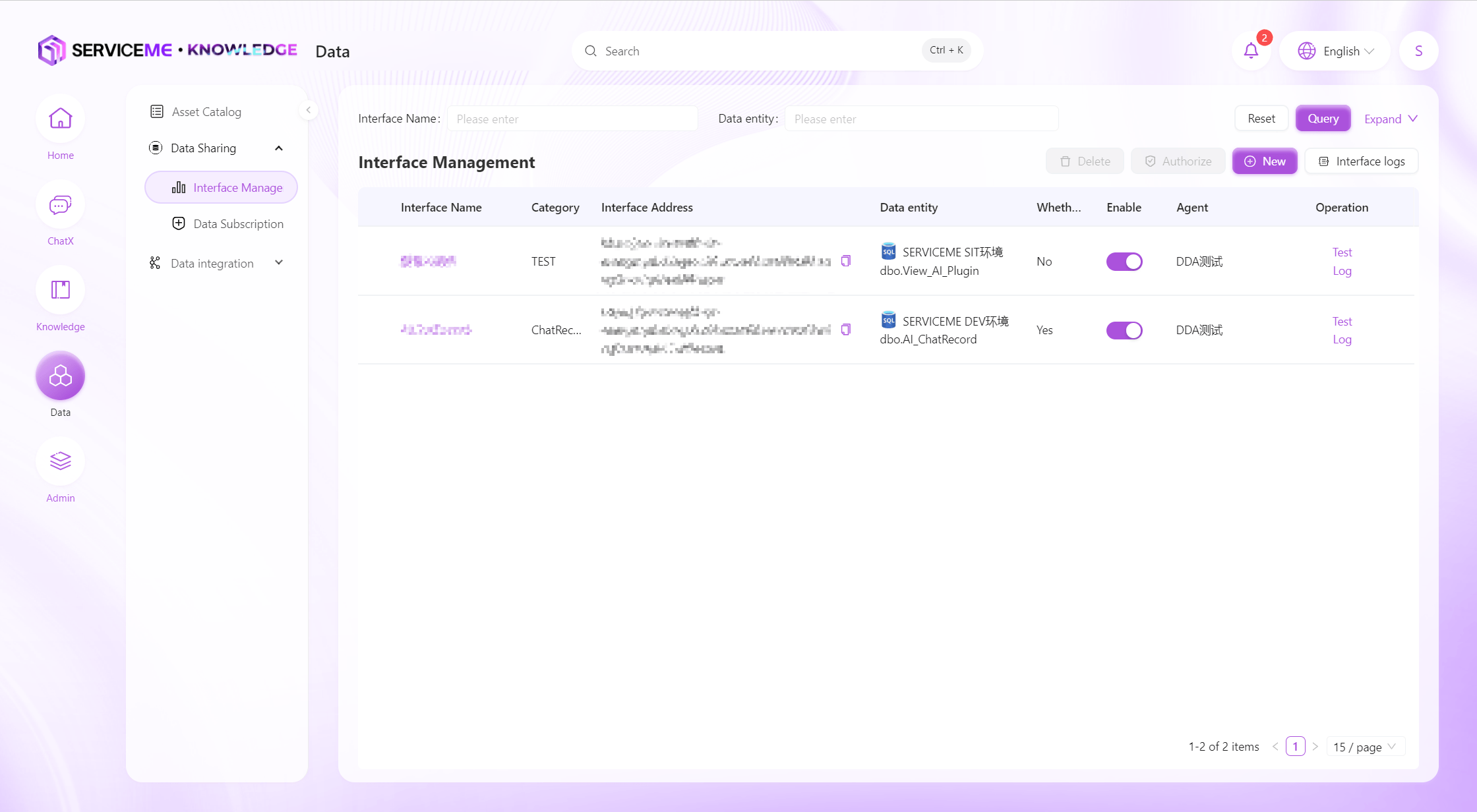
操作説明
- 検索:インターフェース名、データエンティティ名でフィルタリング
- 新規作成:クリックで新しいデータインターフェース定義のポップアップ
- インターフェースログ:データインターフェースログ閲覧ページへ
- 認可:指定クライアントにインターフェースアクセス権限を付与。クライアントがバインドされていない場合、インターフェースはアクセス不可
- 行操作
- 詳細:インターフェースの詳細情報を表示
- 編集:作成済みインターフェースの編集
- ログ:該当インターフェース関連のログのみ表示
- 有効/無効:無効化されたインターフェースは呼び出せなくなりますが、インターフェース自体は削除されず、いつでも有効化可能
- 削除:インターフェースの削除
インターフェース詳細
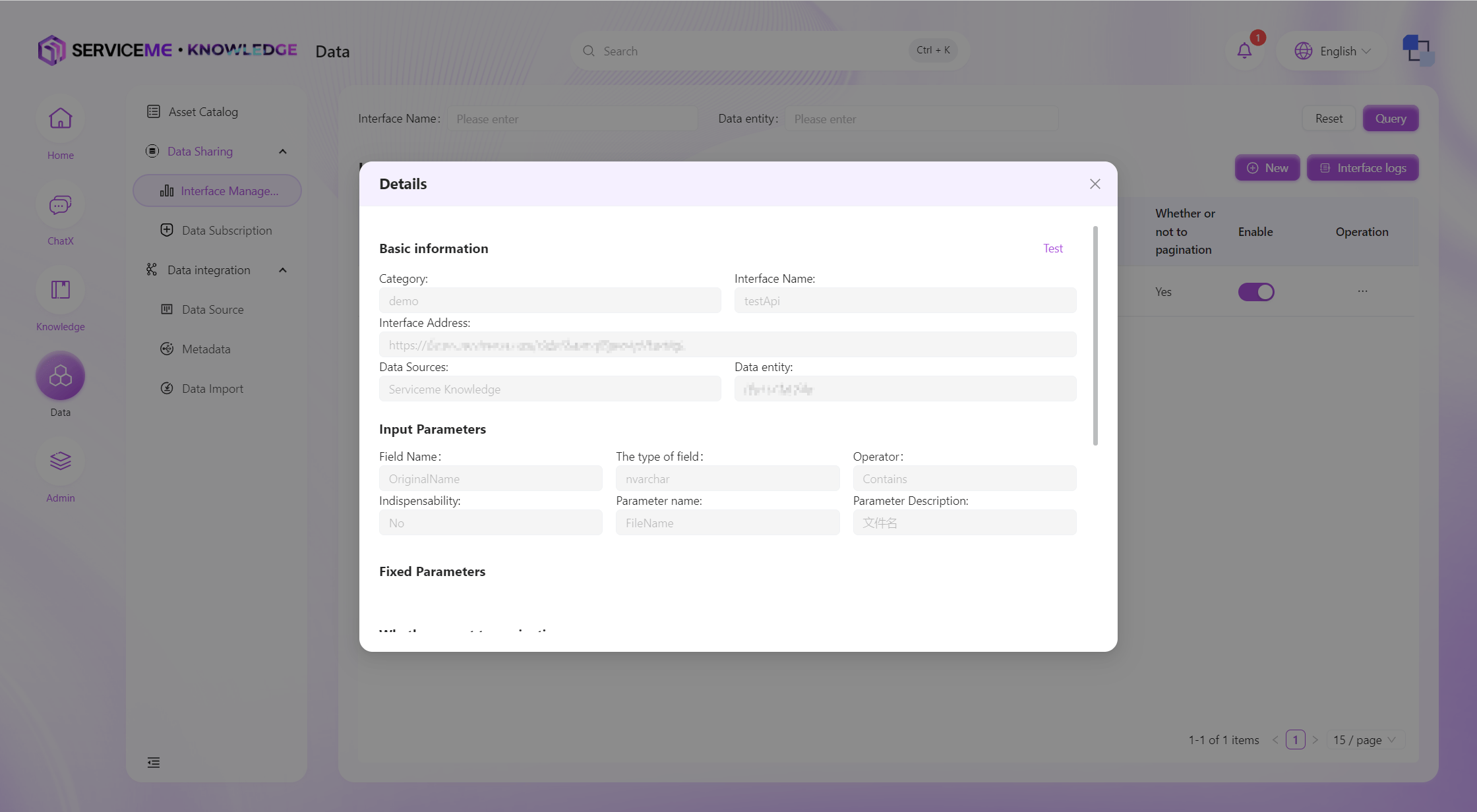
データインターフェースの作成
インターフェース作成により、新しいデータインターフェースをシステムに追加できます。ユーザーは異なるデータエンティティ、条件、フィールドで様々なデータインターフェースを追加できます。 現在は単一データエンティティのクエリインターフェース定義のみサポートしています。複数エンティティの結合クエリが必要な場合は、上流プラットフォームでビューを作成し、データインターフェースで条件を追加してクエリしてください。
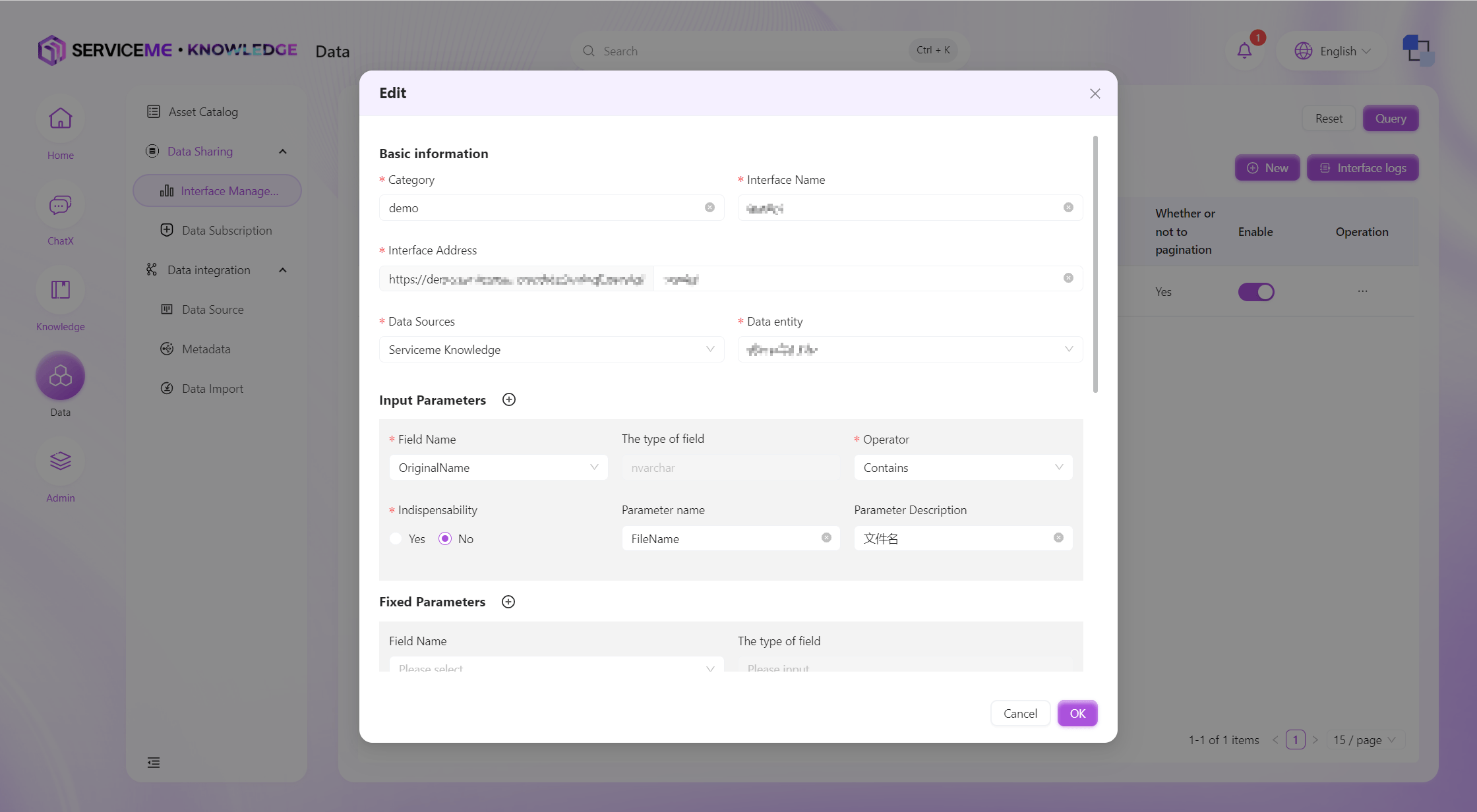
フィールド説明
- カテゴリ:インターフェースのカテゴリ。データインターフェースが多い場合、グループ分けの識別子として利用
- インターフェース名:インターフェースの一意識別子
- インターフェースアドレス:インターフェース公開後のアクセスアドレス。他のインターフェースと同じアドレスは使用不可
- データソース:インターフェースのデータ元。事前にデータドメインをシステムに登録しておく必要あり
- データエンティティ:インターフェースがどのデータエンティティからデータをクエリするか
- 入力パラメータ:インターフェースに1つ以上の入力パラメータを定義し、データのフィルタリングを行う。
等しい、含む、より大きいなどの演算子を提供。入力パラメータはインターフェース呼び出し側が渡す - 固定パラメータ:呼び出し側が渡す必要のない固定パラメータ/条件。例:中国地域の省のみを常にクエリする場合、中国地域を固定パラメータとして設定
- ページング有無:いいえの場合、条件に合致する全レコードを返す。はいの場合、呼び出し側の
pageSizeで1ページの件数、pageIndexでページ番号を指定。総件数と総ページ数は返却パラメータのtotalCount、totalPageに対応 - ソート条件:ソートフィールドと方向(昇順/降順)を指定してクエリ結果の並び順を制御
- 返却パラメータ:どのフィールドをインターフェースで返すかを制御。チェックされていないフィールドはクエリ結果に含まれない(機密情報の制御などに利用)
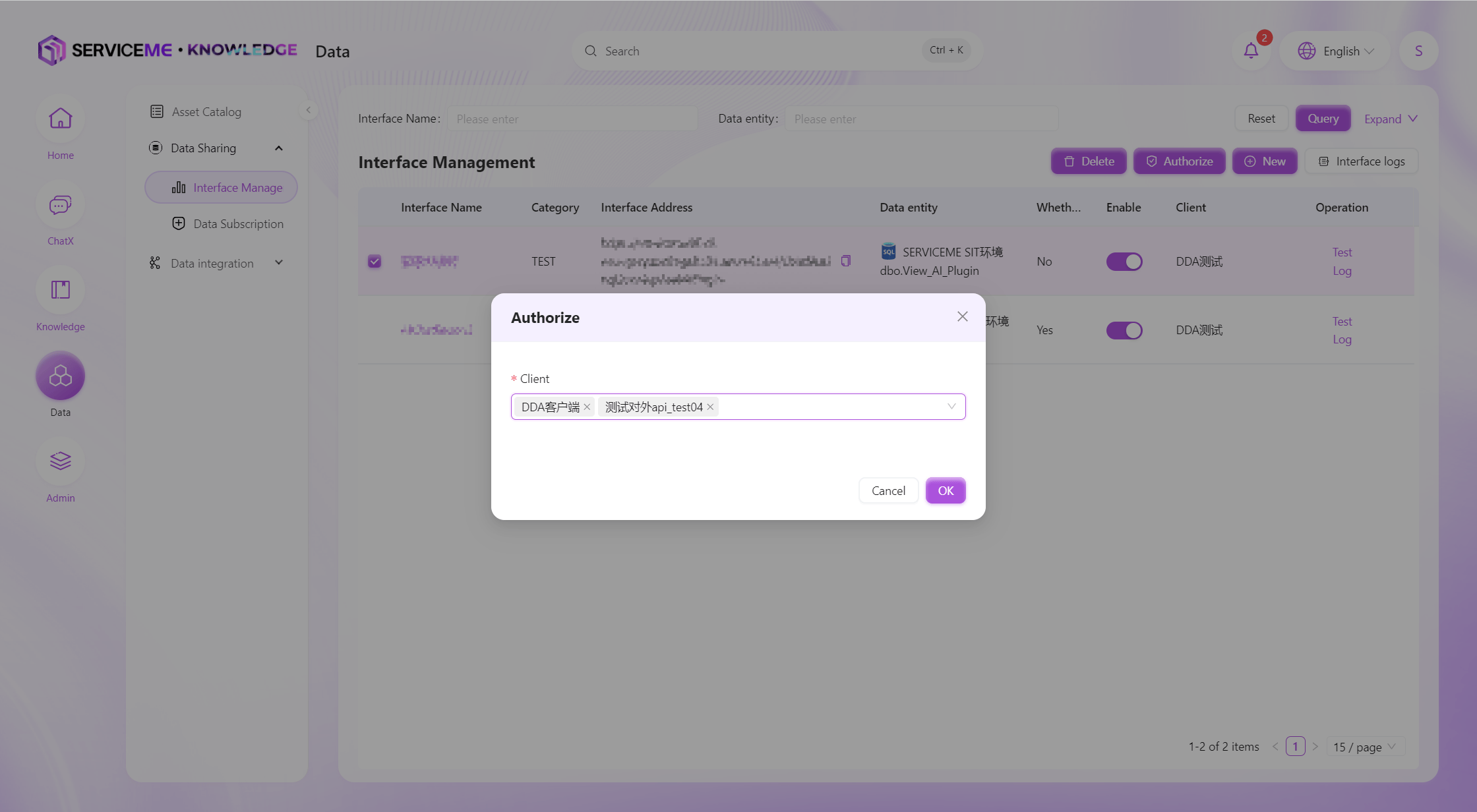
データインターフェースの認可
全てのデータインターフェースは認可後に外部システムから呼び出し可能となります。クライアントは外部システムの識別子で、通常1クライアント=1外部システムです。 認可前に、SERVICEME管理者がクライアントをシステムに追加しておく必要があり、ここで該当クライアントを選択して認可します。
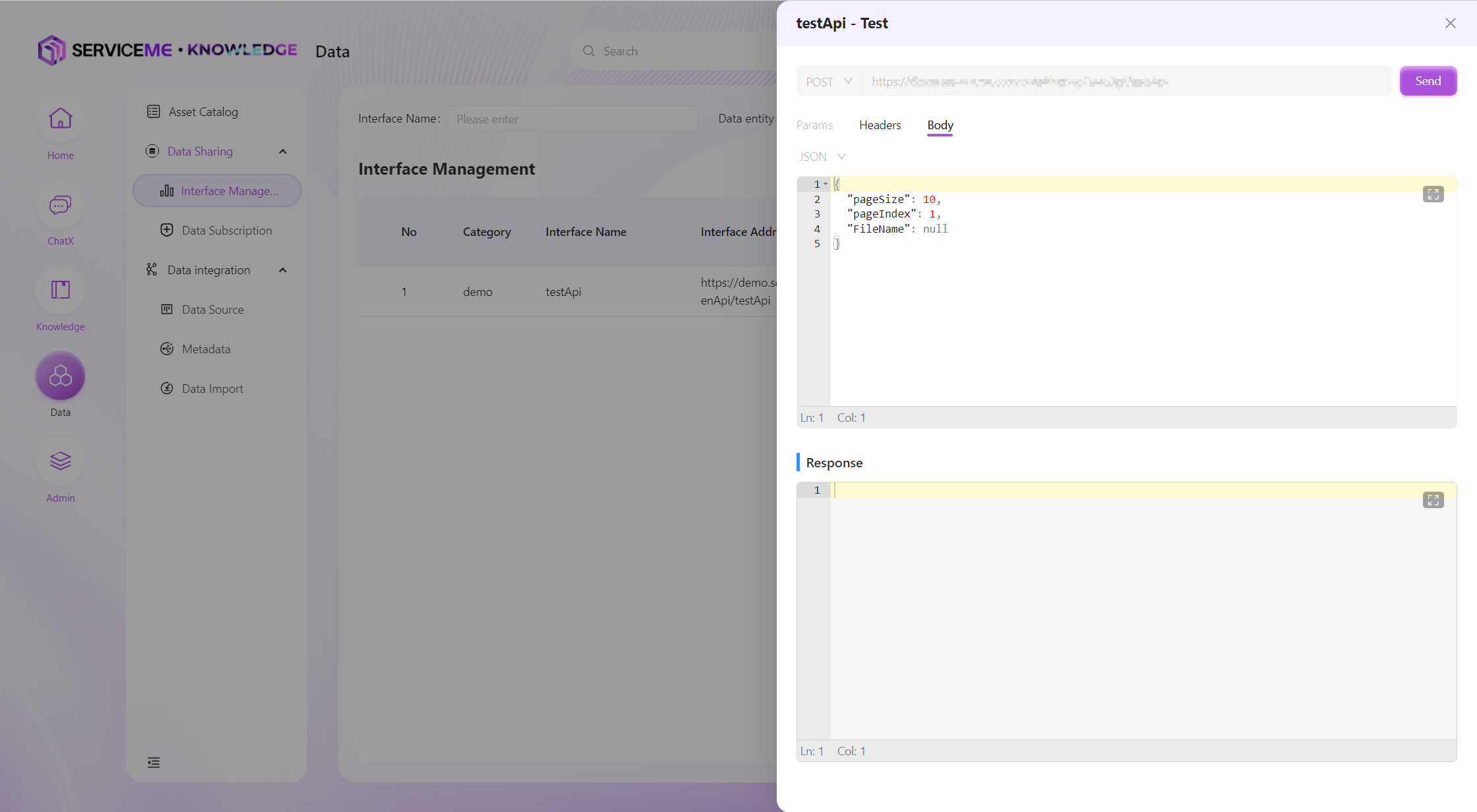
インターフェーステスト(プレビュー)
作成済みデータインターフェースに対してテストを行い、詳細な入出力メッセージでインターフェースが期待通りか確認します。
注:テスト前にクライアント認可を完了し、計算済みのAuthorizationをHeaderに入力する必要があります。そうでない場合、リクエストは拒否されます。Authorizationアルゴリズムは[技術ガイド/DATA 開発連携]を参照してください。
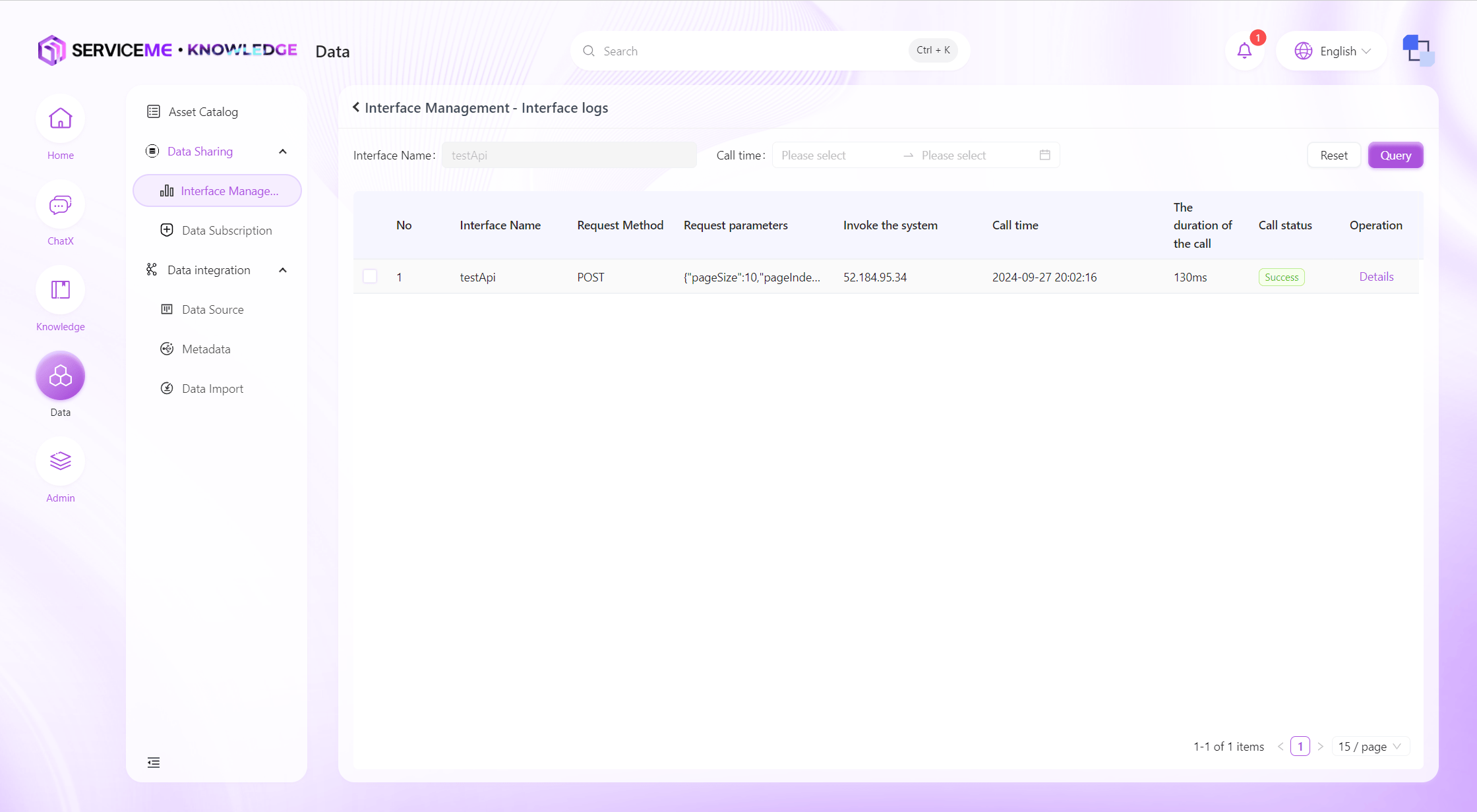
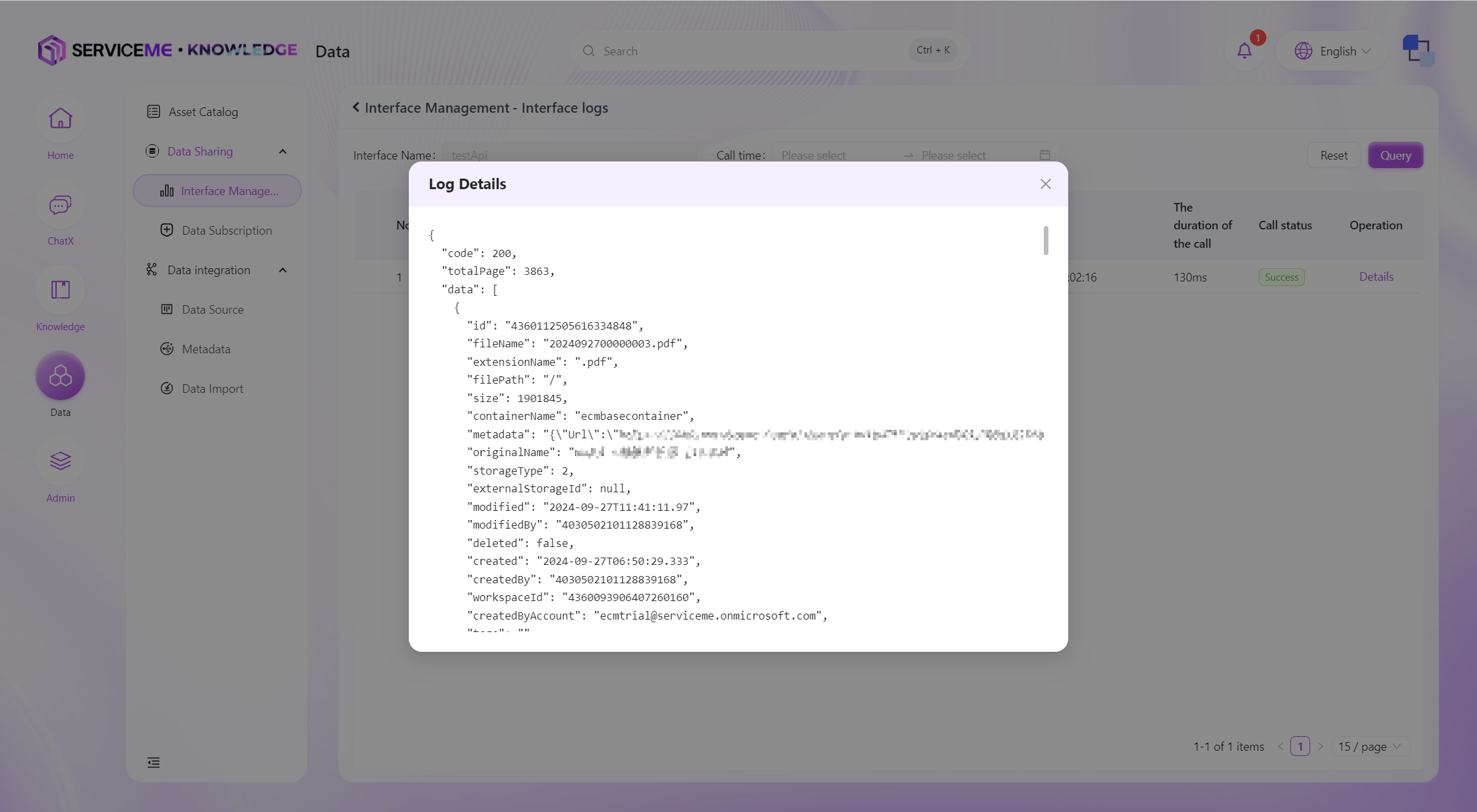
インターフェースログの閲覧
システムの直近の全データインターフェースクエリログを検索できます。システムは呼び出し元のIPアドレスや返却メッセージなどを記録します。
データサブスクリプション
データインターフェースとは逆方向で、データサブスクリプションはSERVICEMEプラットフォームが外部システムにデータを能動的にプッシュします。ここでデータサブスクリプションの条件と頻度を設定でき、トリガー時刻になると条件に合致するデータがあるかを確認し、あれば指定インターフェースにデータをプッシュします。
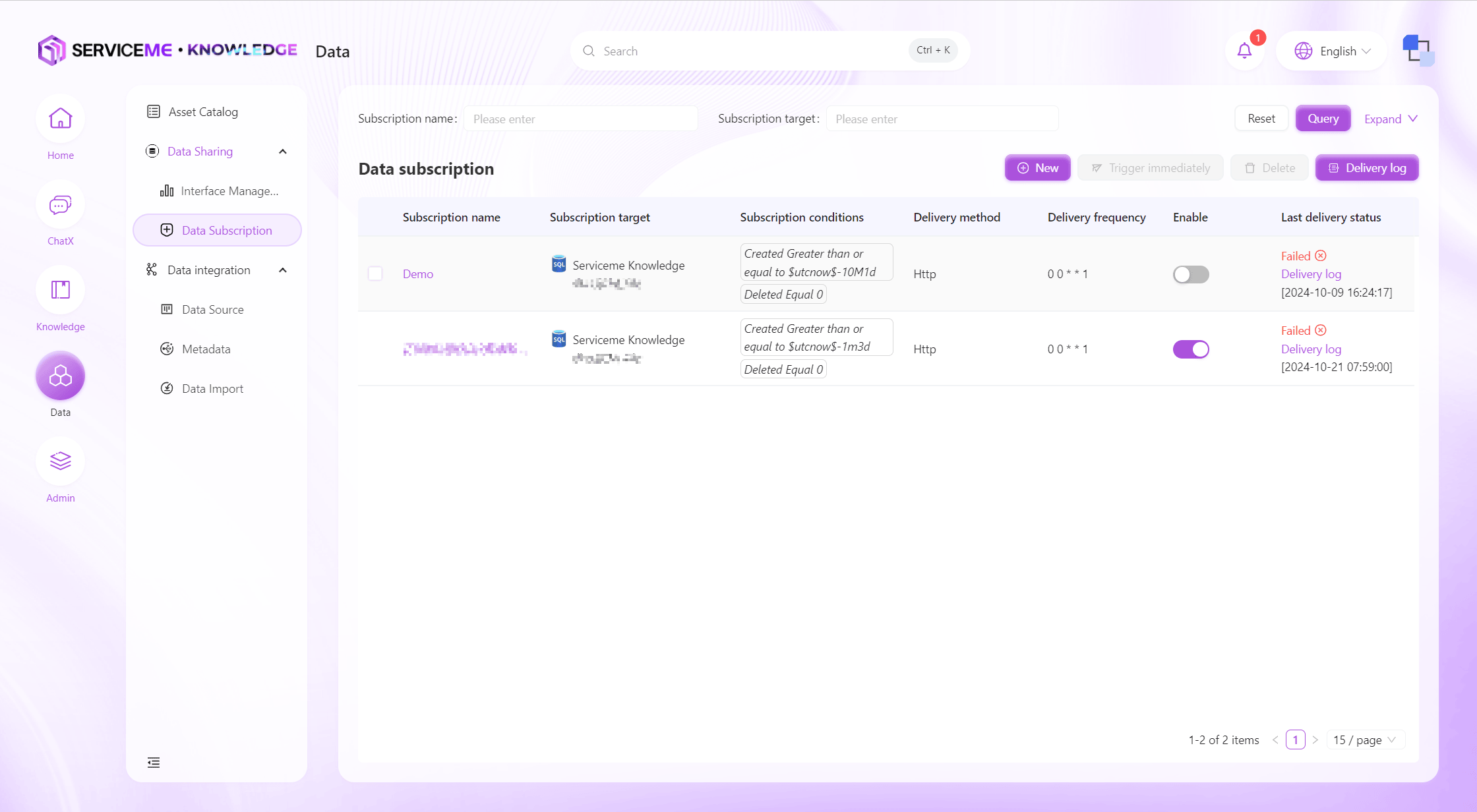
操作説明
- 検索:サブスクリプション名などでデータサブスクリプションを検索
- 新規作成:データ定義パラメータを入力して作成
- 即時トリガー:クリックで即座に条件に合致するデータがあるか確認し、あれば即時プッシュ
- 削除:データサブスクリプションを削除し、以降トリガーやデータプッシュは行われない
- プッシュログ:全データサブスクリプションのプッシュログを横断検索
- 行操作
- 有効/無効:サブスクリプションを無効化するとトリガーやデータプッシュは行われない
- プッシュログ閲覧:現在のサブスクリプション関連のログのみ表示
データサブスクリプションの作成・編集
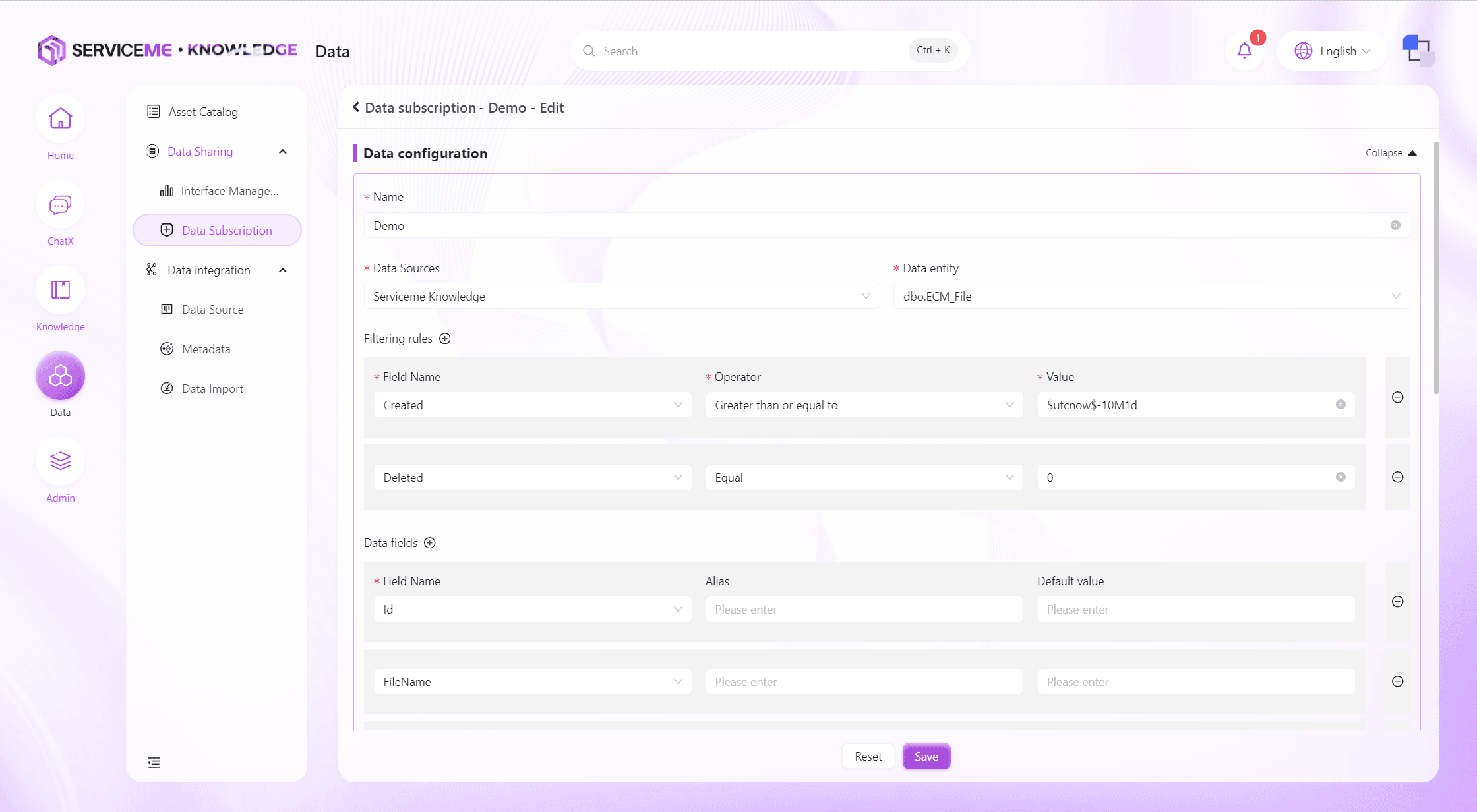
フィールド説明
- データ設定
- 名称:データサブスクリプションの一意識別子
- データソース:データサブスクリプションのデータ元
- データエンティティ:データサブスクリプションがクエリするデータエンティティ(テーブルまたはビュー)
- フィルタールール:条件に合致するデータがあるか判定するためのルール。複数条件の組み合わせ可
- データフィールド:データサブスクリプションが最終的にプッシュするデータフィールド。ここでエイリアスやデフォルト値も設定可能
- サブスクリプション設定
- プッシュ方式:プッシュのプロトコル。現在はHTTPメッセージ方式をサポート
- 頻度:プッシュ頻度。
CRONS(5桁)式をサポート - バッチ数:条件に合致するデータがバッチ数を超える場合、複数回に分けてプッシュし、1回あたりのデータ量を制御
- API:データ受信側のAPIアドレス。ドメインとインターフェースパスを含む完全なアドレスを入力(例:
https://www.baidu.com/api/sendData) - HTTP Method:
POSTとPUTの2種類をサポート - Headers:受信側に渡す
HTTP Header。認証用の固定api_keyなどに利用 - Body:受信側が受け取るメッセージ形式。調整しない場合、全データはJSONの
data属性配下の配列として送信
特殊ルール
- 日付型フィールドの場合、
値入力欄で日付変数を利用でき、特定期間内のデータを簡単にクエリ可能
日付変数例
$utcnow-1m$ 直近1分間
$utcnow-1h$ 直近1時間
$utcnow-1d$ 直近1日
$utcnow-1w$ 直近1週間
$utcnow-1M$ 直近1ヶ月
$utcnow-1y$ 直近1年
組み合わせ
$utcnow-1h20m$ 直近1時間20分
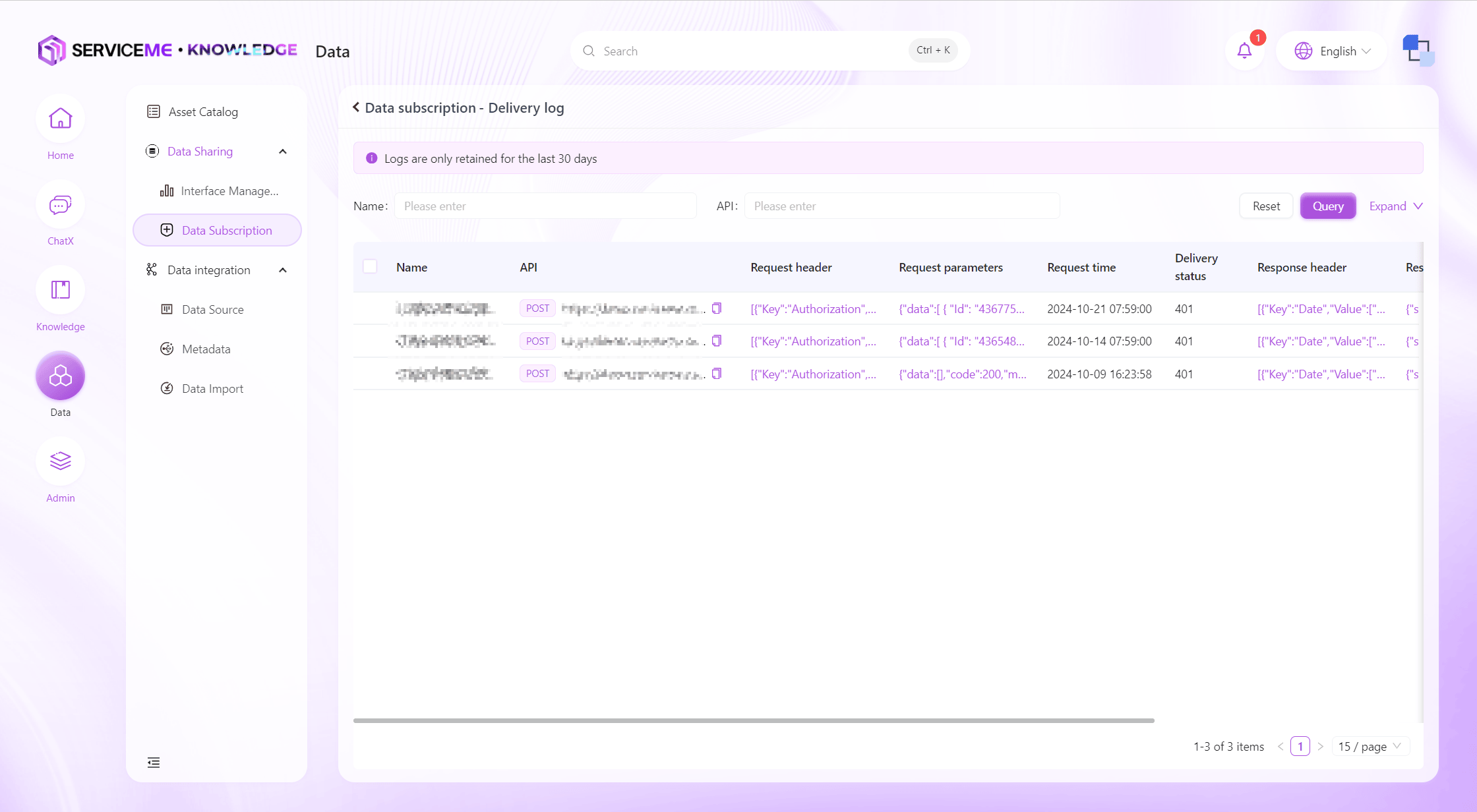
プッシュログの検索
システムの直近の全プッシュログを検索でき、データサブスクリプションの稼働状況を把握できます。データ受信側からデータ未受信のフィードバックがあった場合、プッシュログと合わせて調査できます。
データソース
多様なタイプのデータソース接続・管理をサポートし、ユーザーは新規作成や設定が容易で、データ入力の信頼性と柔軟性を確保できます。
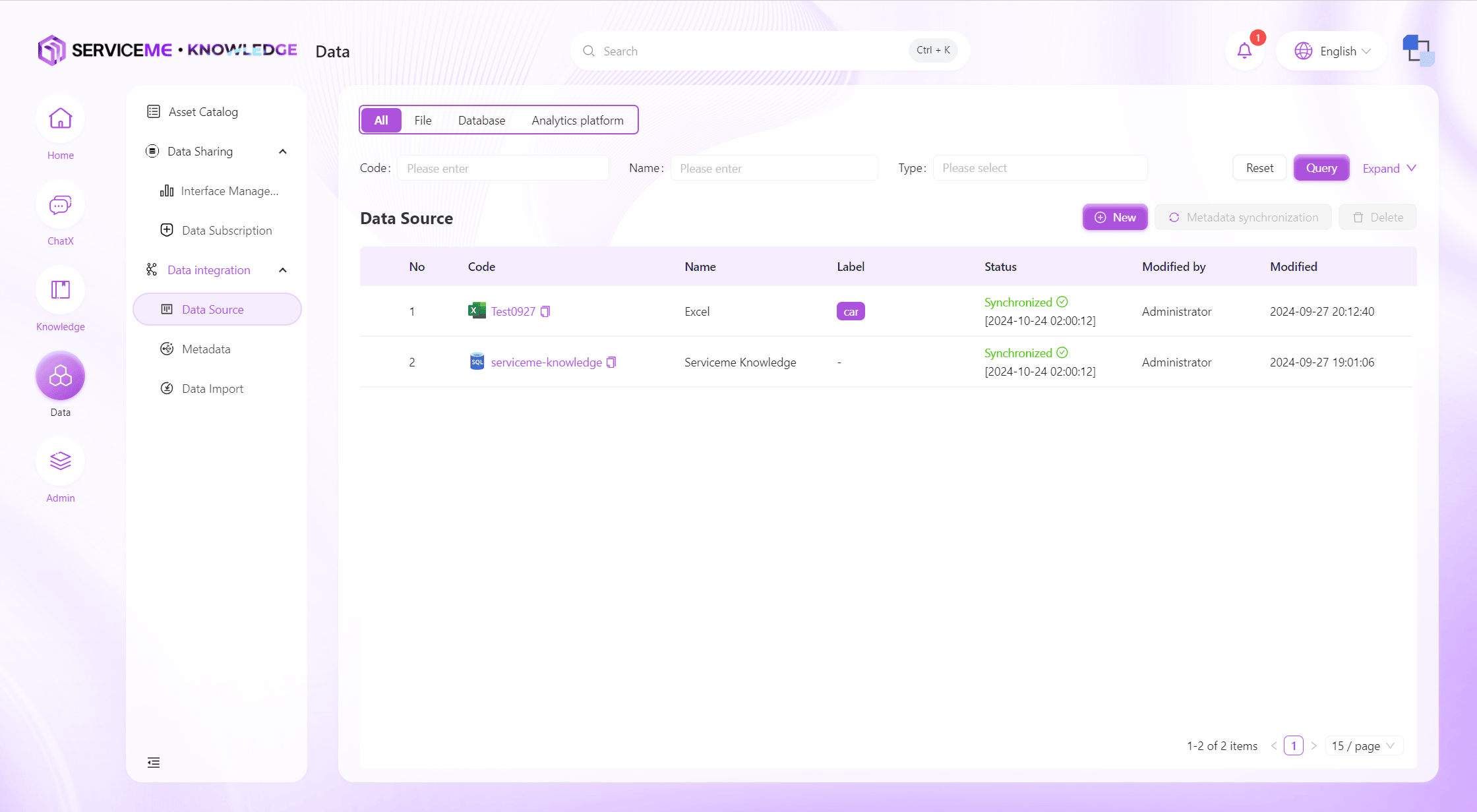
操作説明
- 検索:番号/名称/タイプなどでデータソースを検索
- 新規作成:クリックでデータソース作成フォームを表示
- メタデータ同期:このデータソース内の全メタデータを即時同期
- 削除:データソースを削除し、利用不可・関連メタデータの同期も停止
- 行操作
- リンクをクリック:データソース情報を表示。セキュリティ上、DB接続は編集のみ可能で閲覧不可
データソースの作成
まずデータソースタイプを選択します。現在、プラットフォームはExcel、Azure SQL、Azure Databricksの3種類をサポートしています。
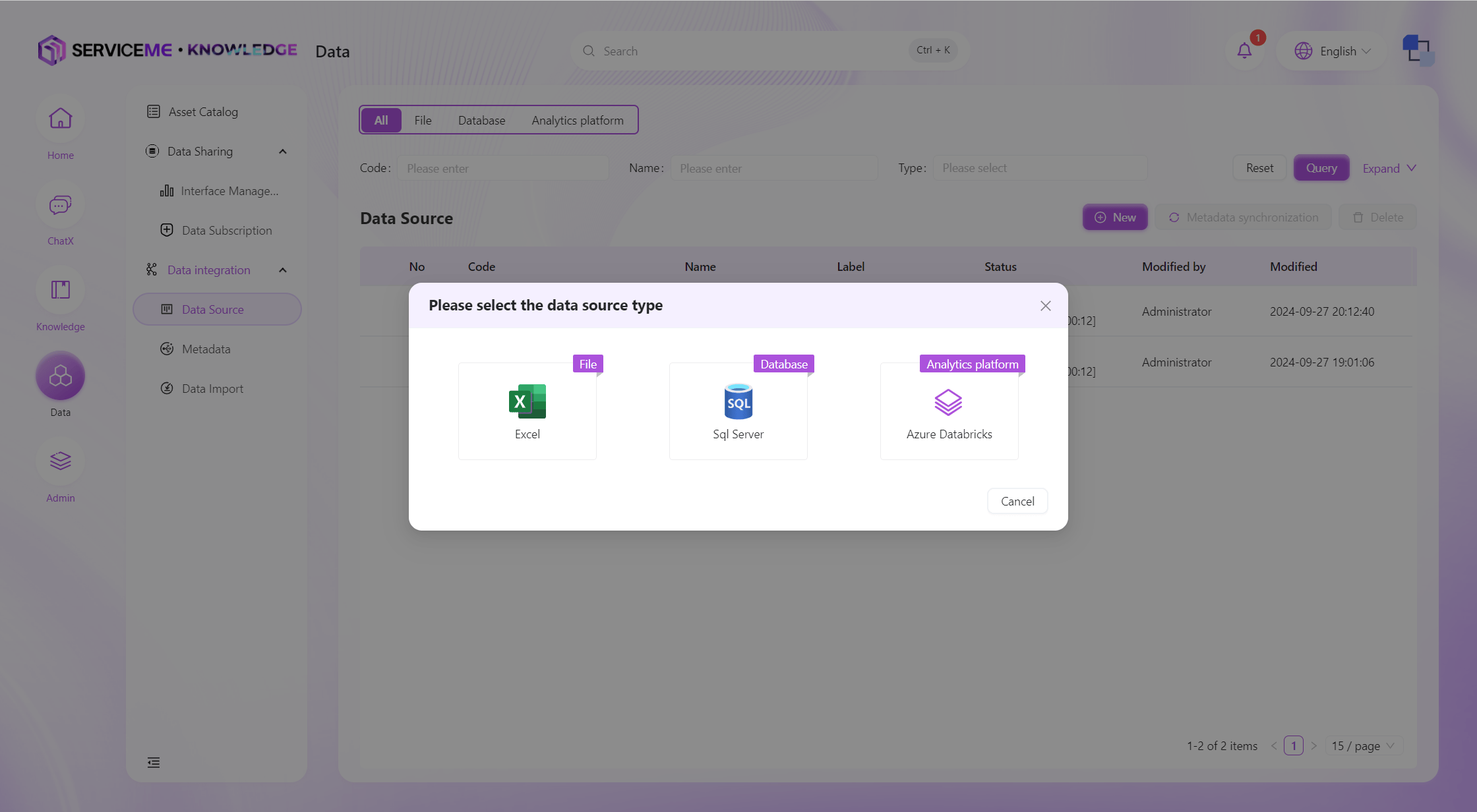
Azure SQLを例に、作成手順は以下の通りです。
まずデータソースの基本情報と接続文字列を入力します。
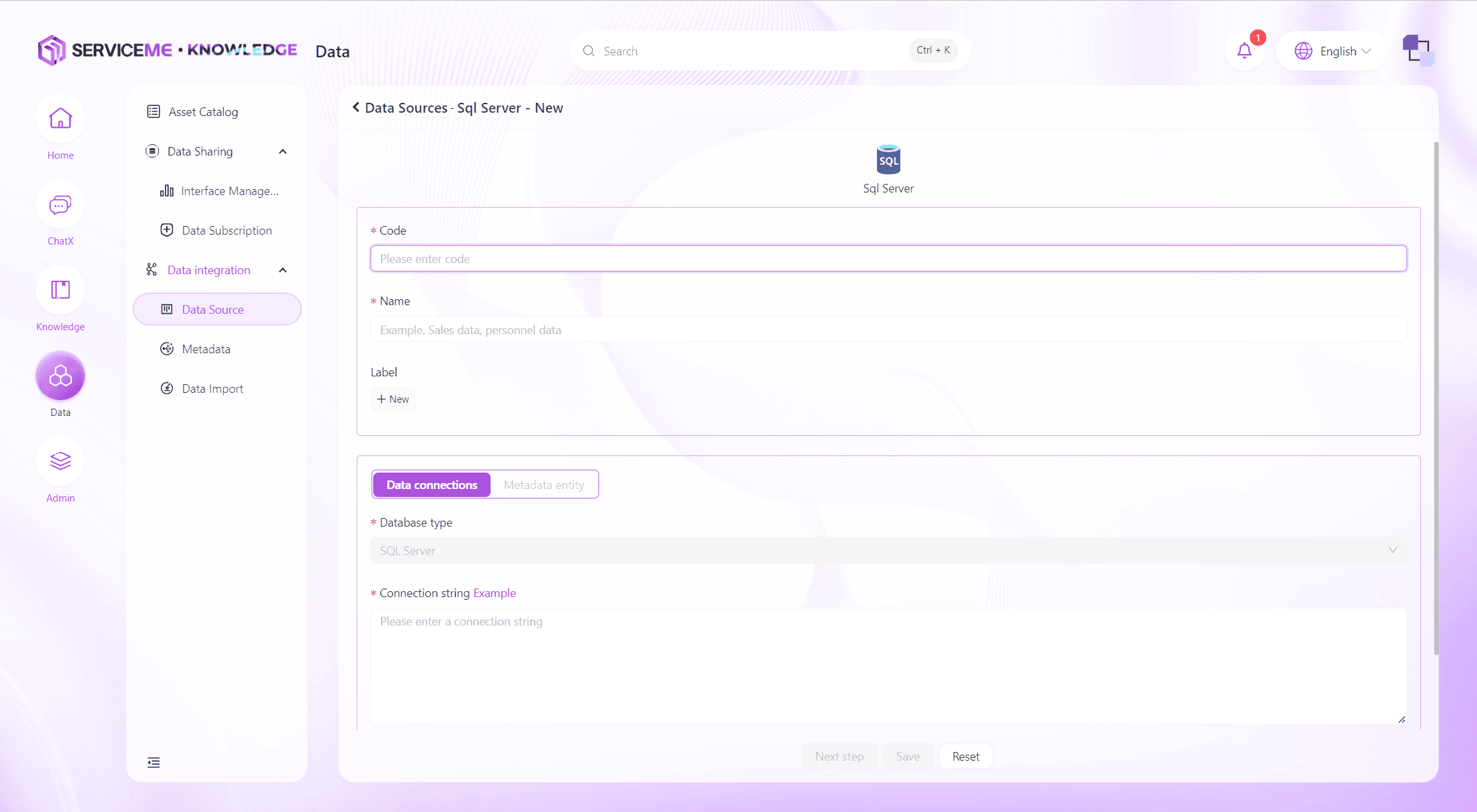
フィールド説明
- 番号:データソースの一意識別子
- 名称:データソースの表示名
- タグ:データソースの分類に利用
- 接続文字列:該当データソースの接続文字列を入力。入力後、
接続テストボタンで検証
接続文字列のテストが通ったら、次へ進みメタデータ選択画面へ。
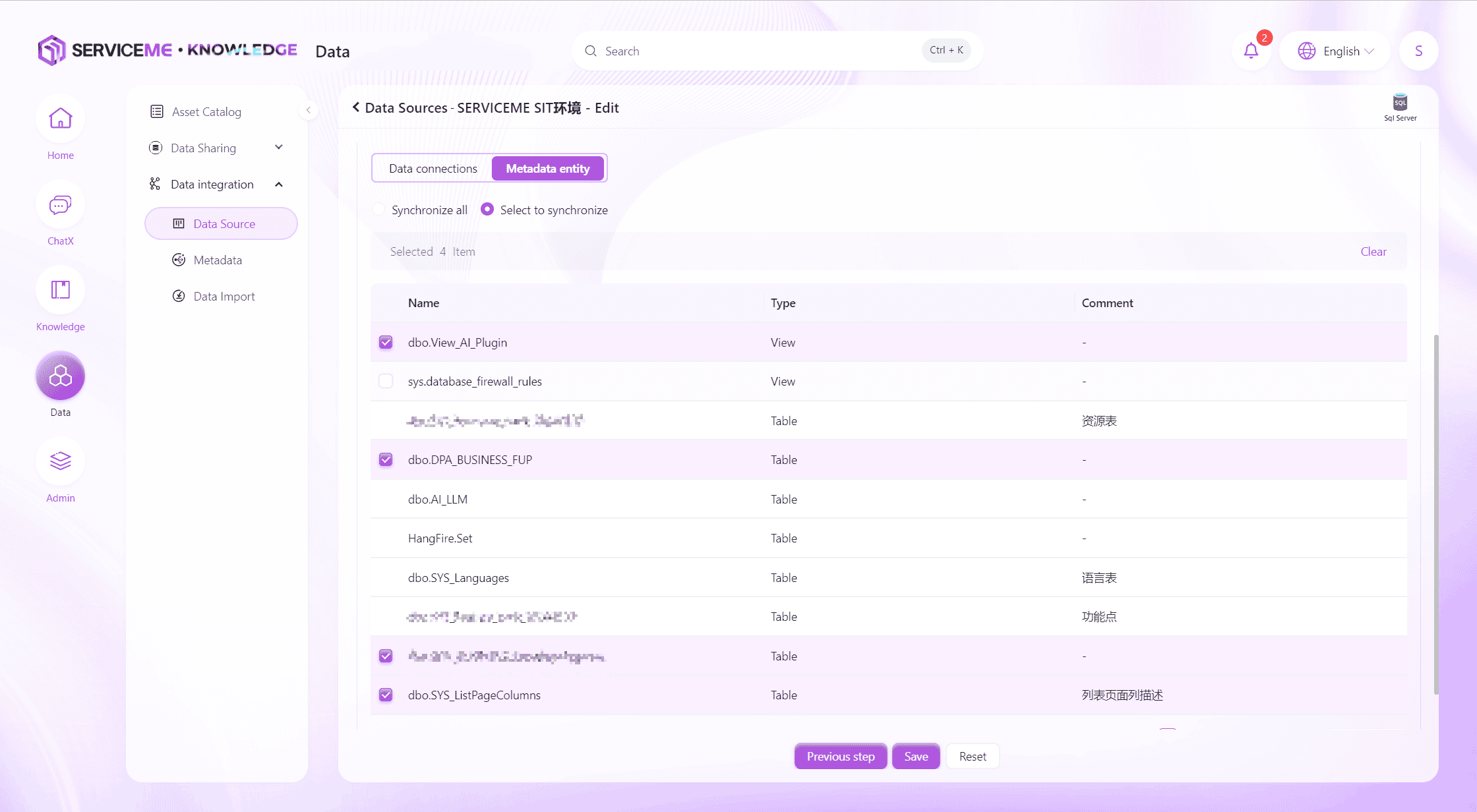
操作説明
- 全て同期:このデータソースの全メタデータを同期。将来新規作成分も含む
- 選択同期:選択したメタデータのみ同期
保存をクリックして、データソース作成完了。
メタデータ
製品内蔵のメタデータ管理機能は、データドメインの作成・編集・管理をサポートし、企業の明確なデータ体系構築を支援します。
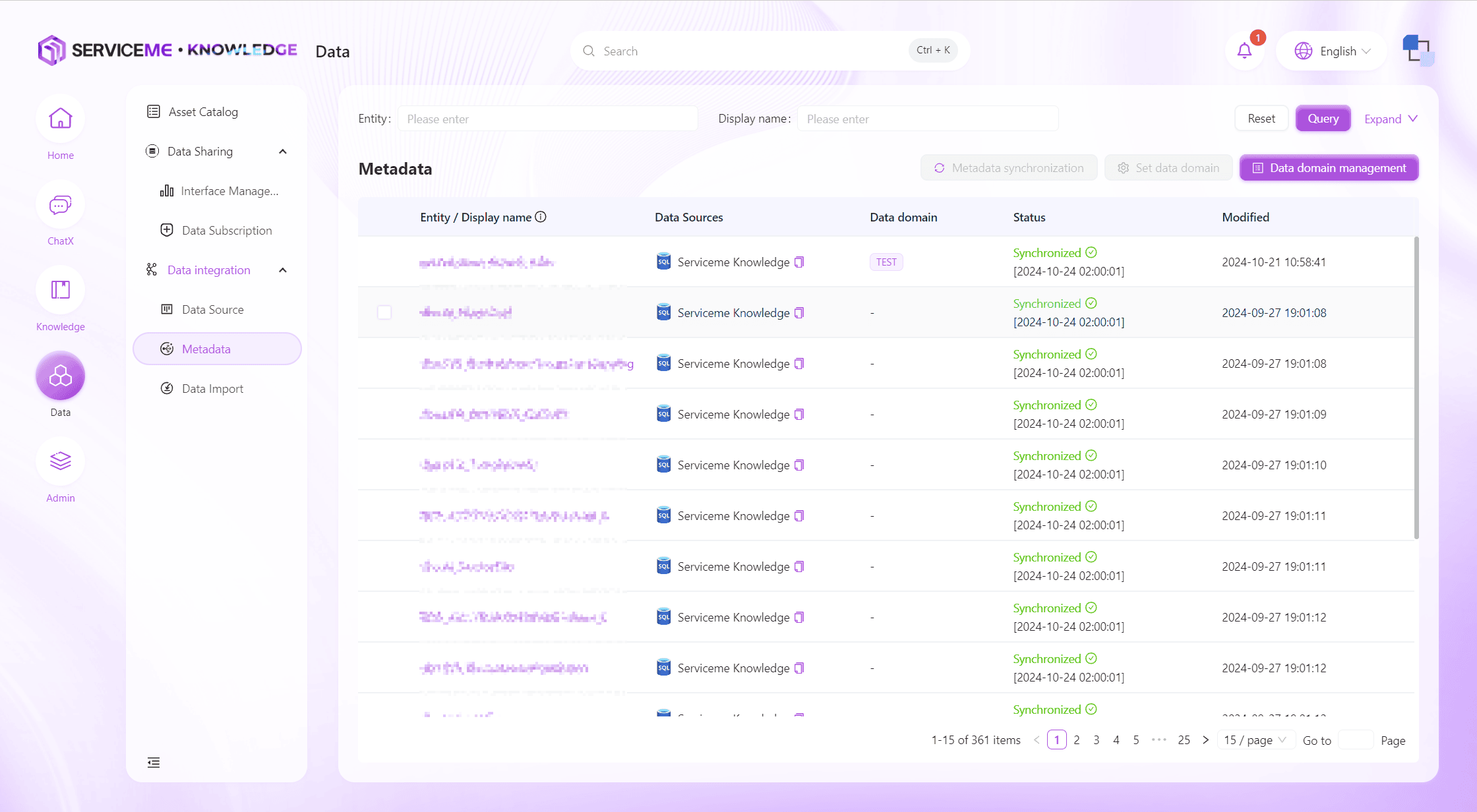
操作説明
- 検索:エンティティ名/表示名/データソースなどでメタデータをフィルタリング
- メタデータ同期:該当メタデータエンティティとフィールドを即時同期
- データドメイン設定:メタデータを該当データドメインに割り当て
- データドメイン管理:データドメインの保守
- 行操作
- エンティティ名ハイパーリンク:クリックでメタデータ詳細ページへ
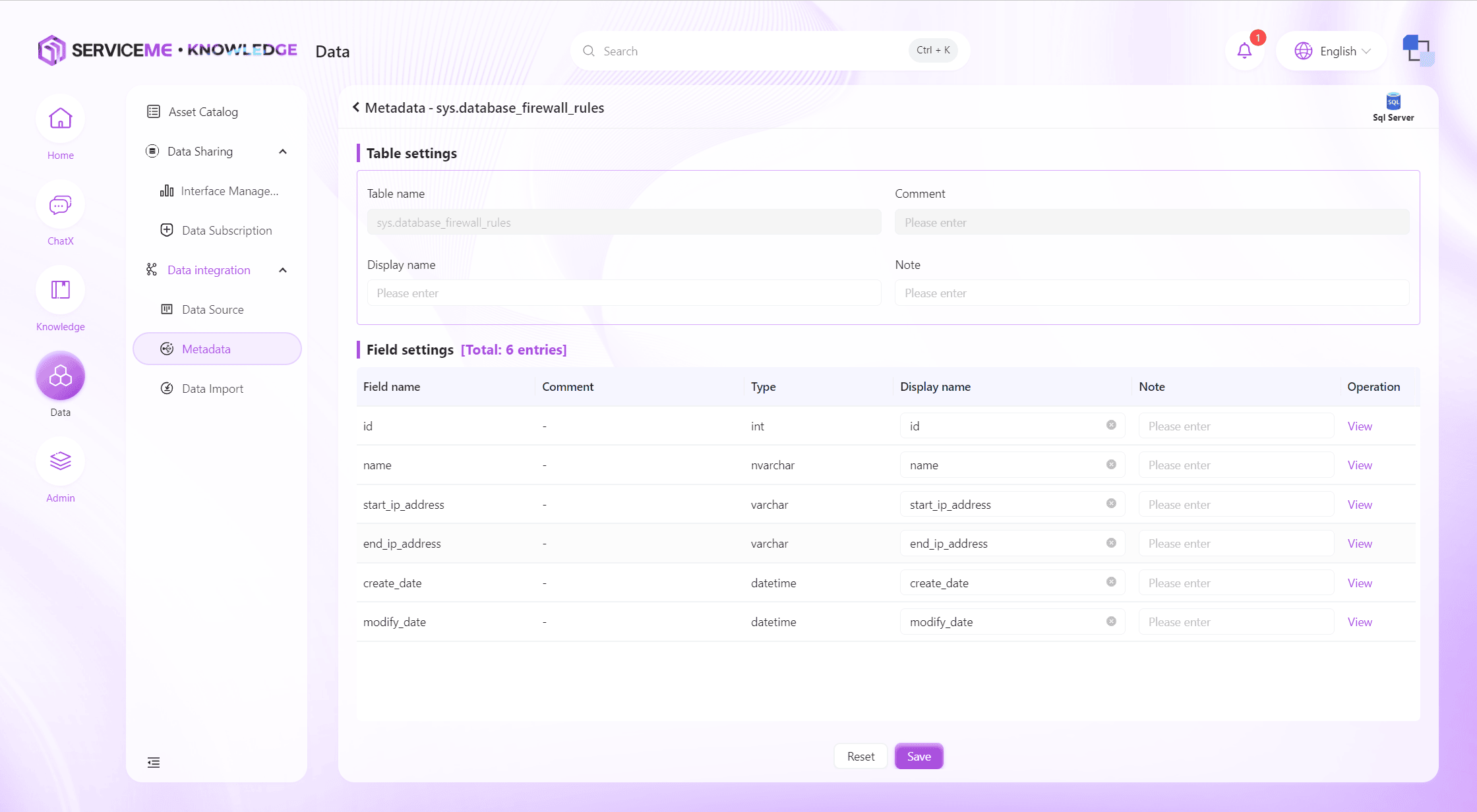
メタデータの編集
メタデータ編集では、テーブルやフィールドに意味のある名称や説明を追加できます。これらの情報はシステムがメタデータをより良く理解するのに役立ち、特にAIによるクエリ生成時に、正確かつ完全なメタデータ記述が安定性向上に寄与します。
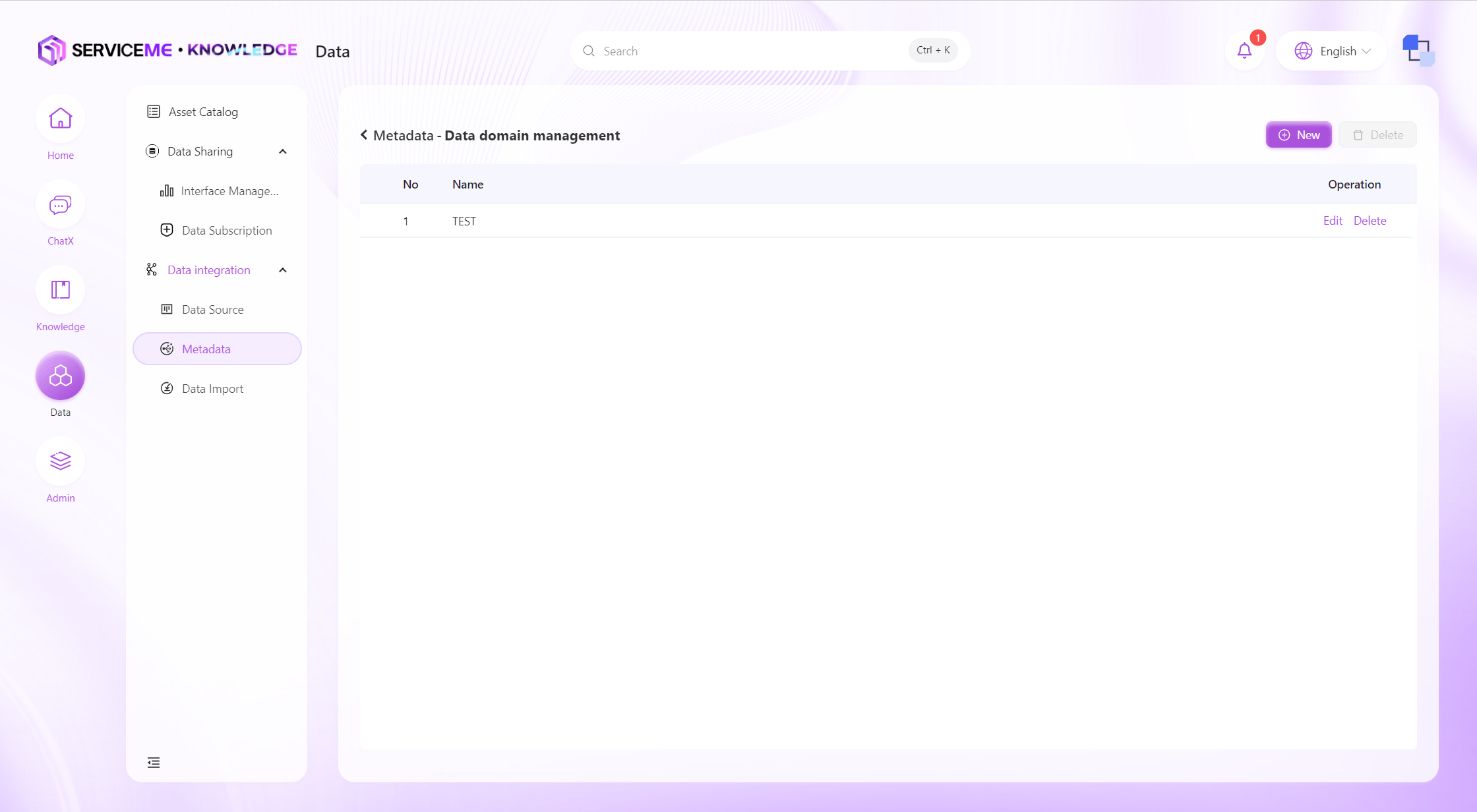
データドメインの管理
データドメイン管理では、異なる分野のデータドメインを作成し、プラットフォーム内のデータ資産を分類管理できます。
データインポート
ファイルまたは手動でデータテンプレートを作成し、データ検証ルールを定義して効率的なデータインポートを実現します。新規データテーブルのインポートや既存データの上書きもサポートし、データ処理の柔軟性と正確性を確保します。
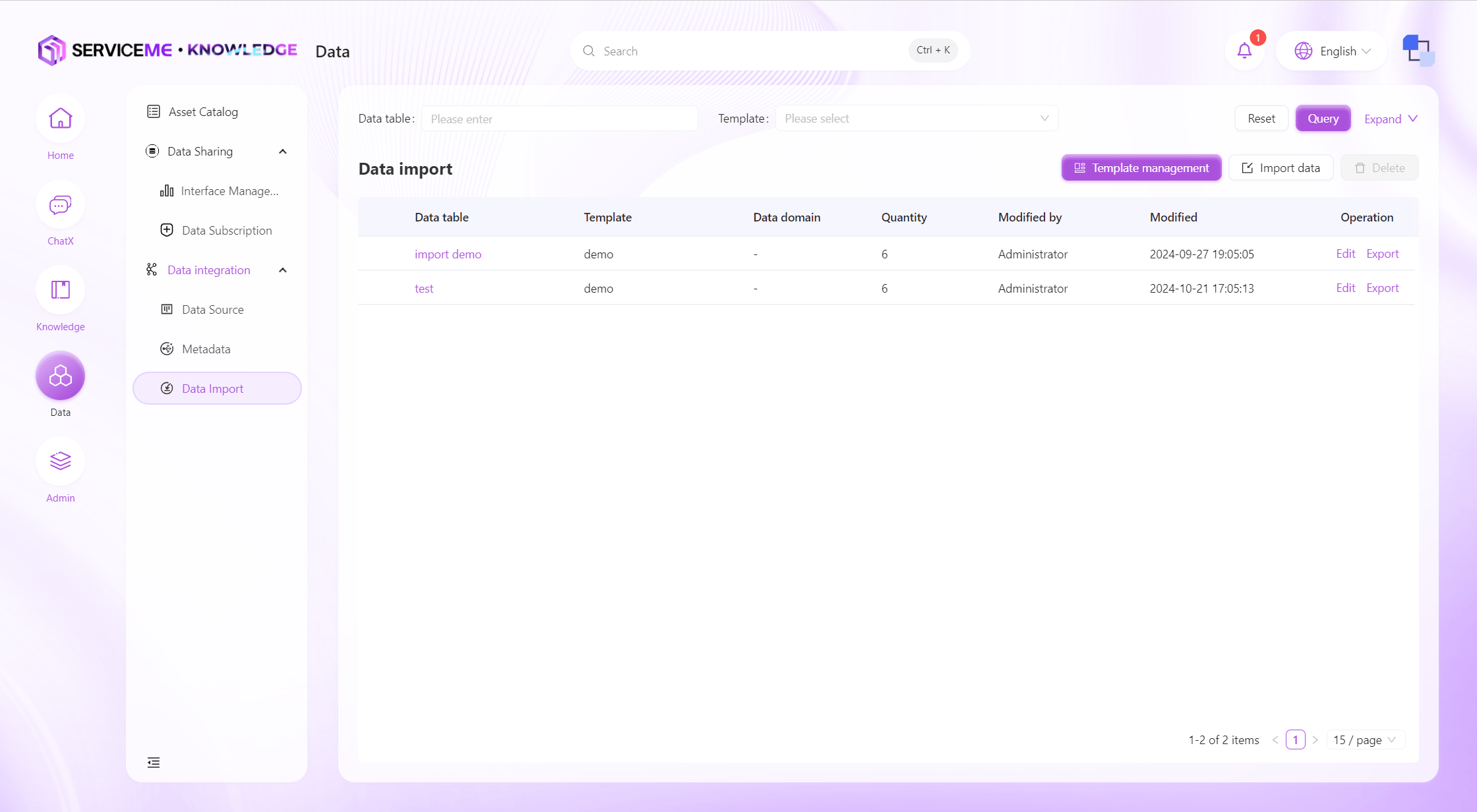
操作説明
- 検索:データテーブル名でフィルタリング
- テンプレート管理:インポートテンプレートの作成/編集。データインポート前に該当テンプレートを作成しておく必要あり
- データインポート:データのインポート操作
- 削除:インポート済みデータテーブルの削除
- 列操作
- 列名ハイパーリンクをクリック:データテーブルの詳細データを表示
- 編集:データテーブルのデータドメインを編集
- エクスポート:データテーブル全体をエクスポート
データテンプレートの作成
データテンプレート作成機能は、手動作成とファイル作成の2通りでデータテンプレートを作成できます。
-
手動作成:
- ユーザーは画面上で直接データテンプレートの構造を定義できます。
- フィールドの追加、編集、削除、型やその他属性の設定が可能です。
-
ファイル作成:
- データ構造を含むExcelファイルをアップロードできます。
- システムがファイル内のデータ構造を自動認識し、対応するテンプレートを生成します。
- 特定のシート(Sheet)をテンプレートのベースとして選択可能です。
テンプレート作成中、ユーザーは以下が可能です:
- フィールド名、型、説明の定義
- 必須フィールドの設定
- データ検証ルールの追加(データ形式、値範囲など)
テンプレート作成完了後、ユーザーはこのテンプレートを使ってデータインポートを行い、インポートデータが事前定義の構造・ルールに合致することを保証します。この方法でデータ品質とインポート効率を大幅に向上できます。
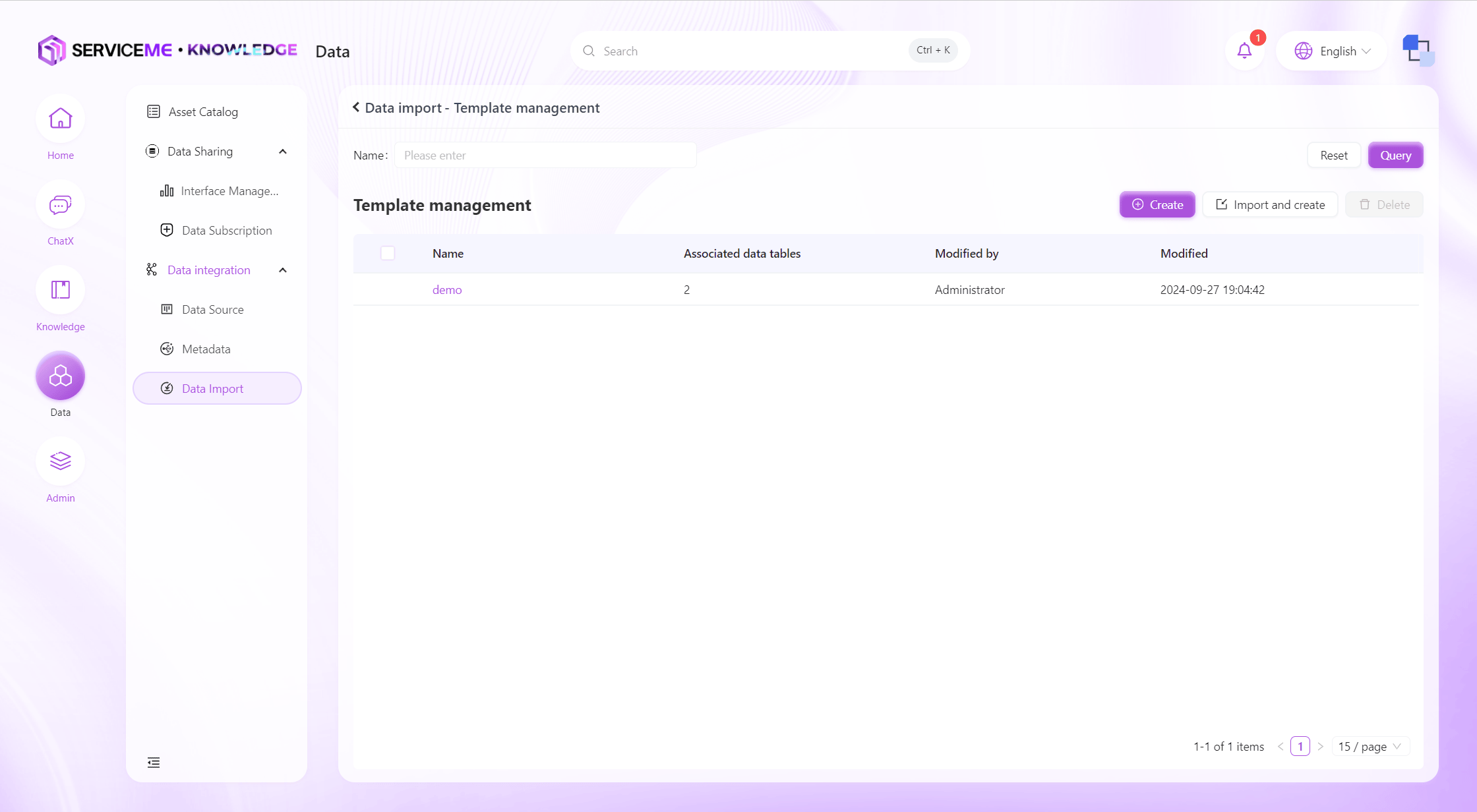
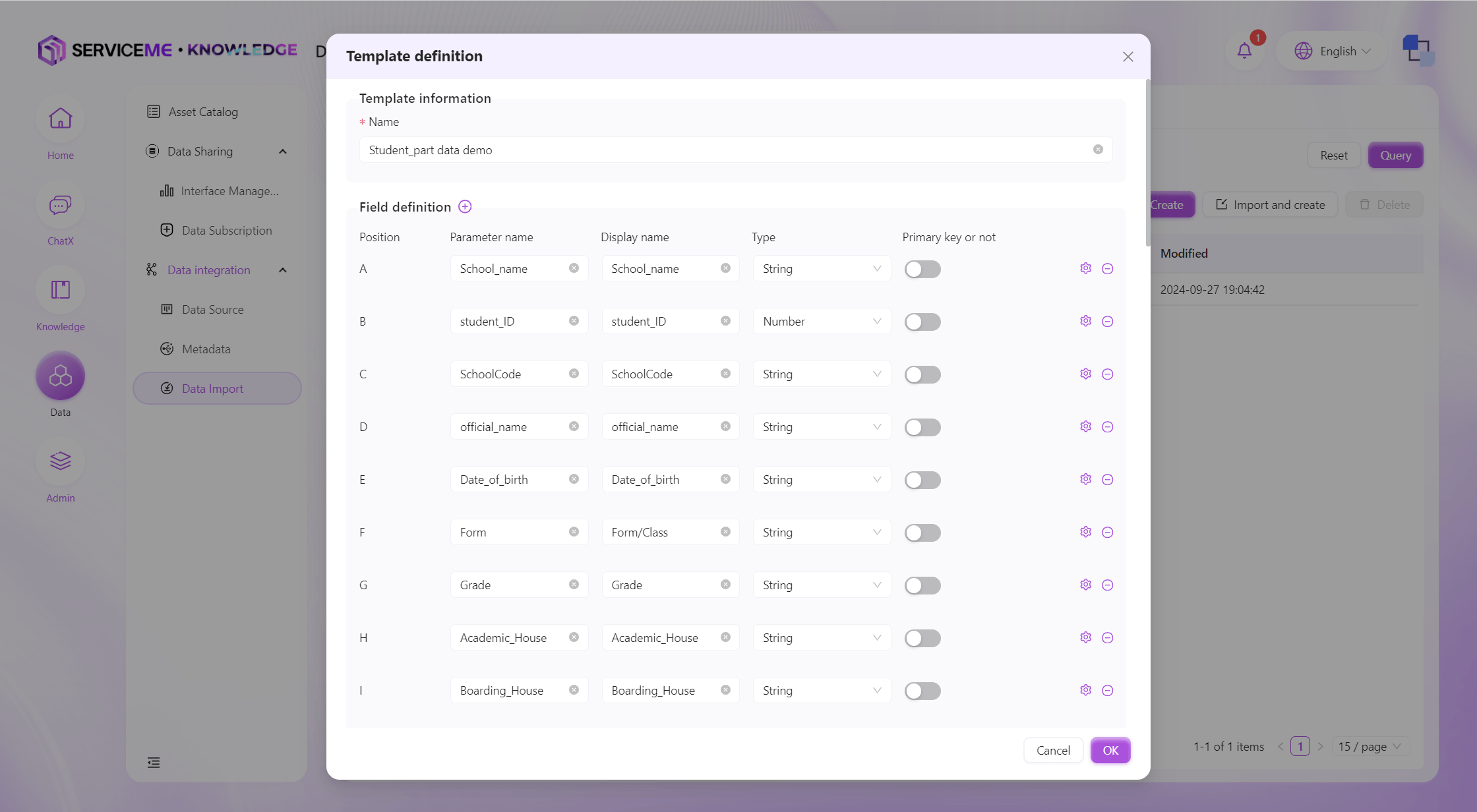
手動でインポートテンプレートを作成
操作説明
- テンプレート名:テンプレートの一意識別子
- フィールド追加(プラスボタン):クリックでテンプレート列を追加
- フィールド操作
- パラメータ名:データテーブル用
- 表示名:データインポート後の表示用
- 型:インポートデータの型を指定(String-テキスト、Number-数値、Boolean-ブール、DateTime-日付時刻)
- 主キーかどうか:主キー列は一意でなければならない。2回目以降のインポート時、既存データを更新したい場合は主キー列を指定
- 設定:列の検証ルール設定画面へ
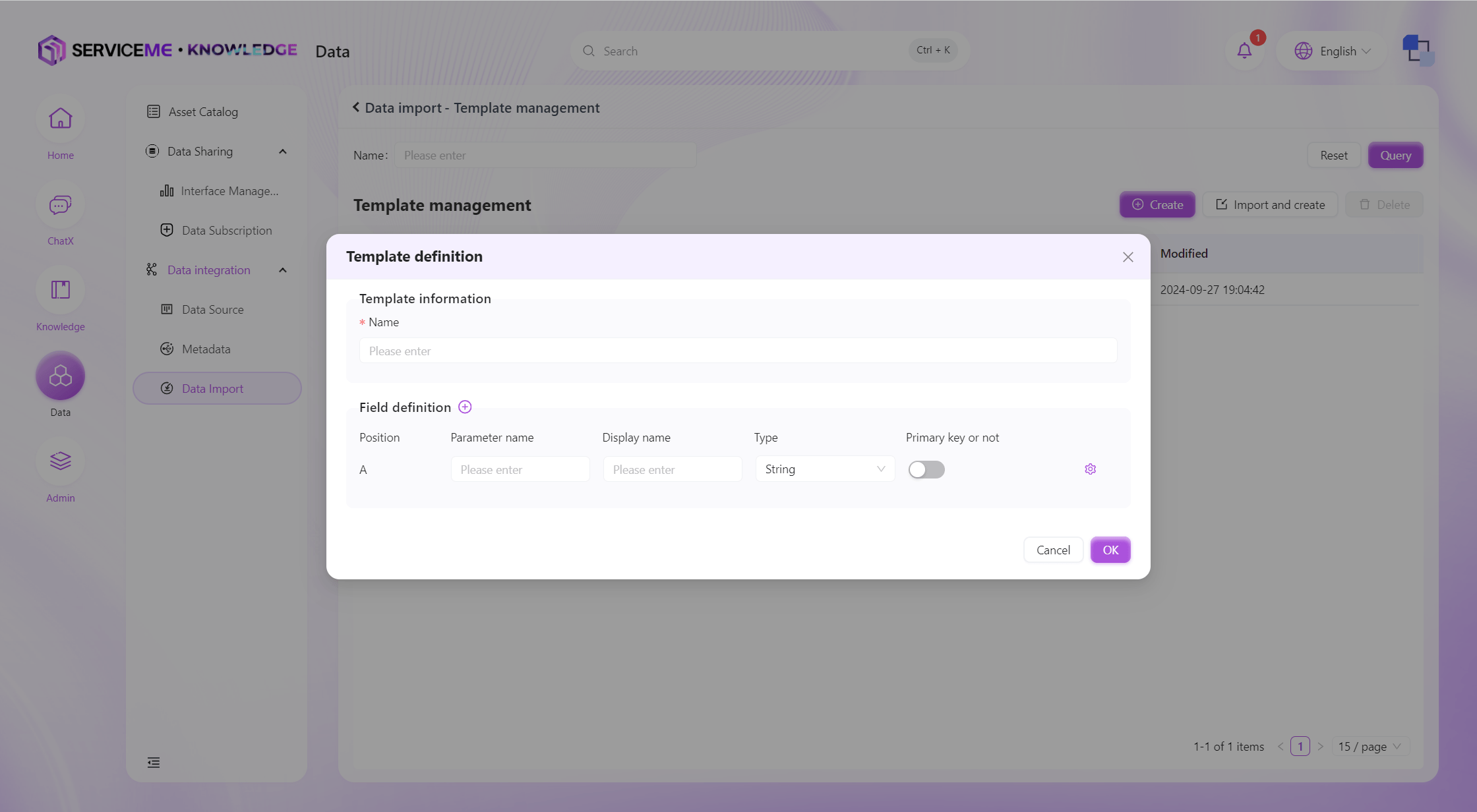
検証ルール定義
操作説明
- 数値範囲:値が特定範囲内であることを制約(例:試験点数は0-100の範囲)
- 値範囲:列挙値定義(例:性別:男/女、リスク:高/中/低)
- 一意かどうか:この列の値が重複しないようにしたい場合は一意検証を有効化
- 外部キー制約:データの存在性検証用。例:学校テーブルの学校コード列で存在性検証。アップロードデータの学校コードが学校テーブルに存在しない場合はエラー
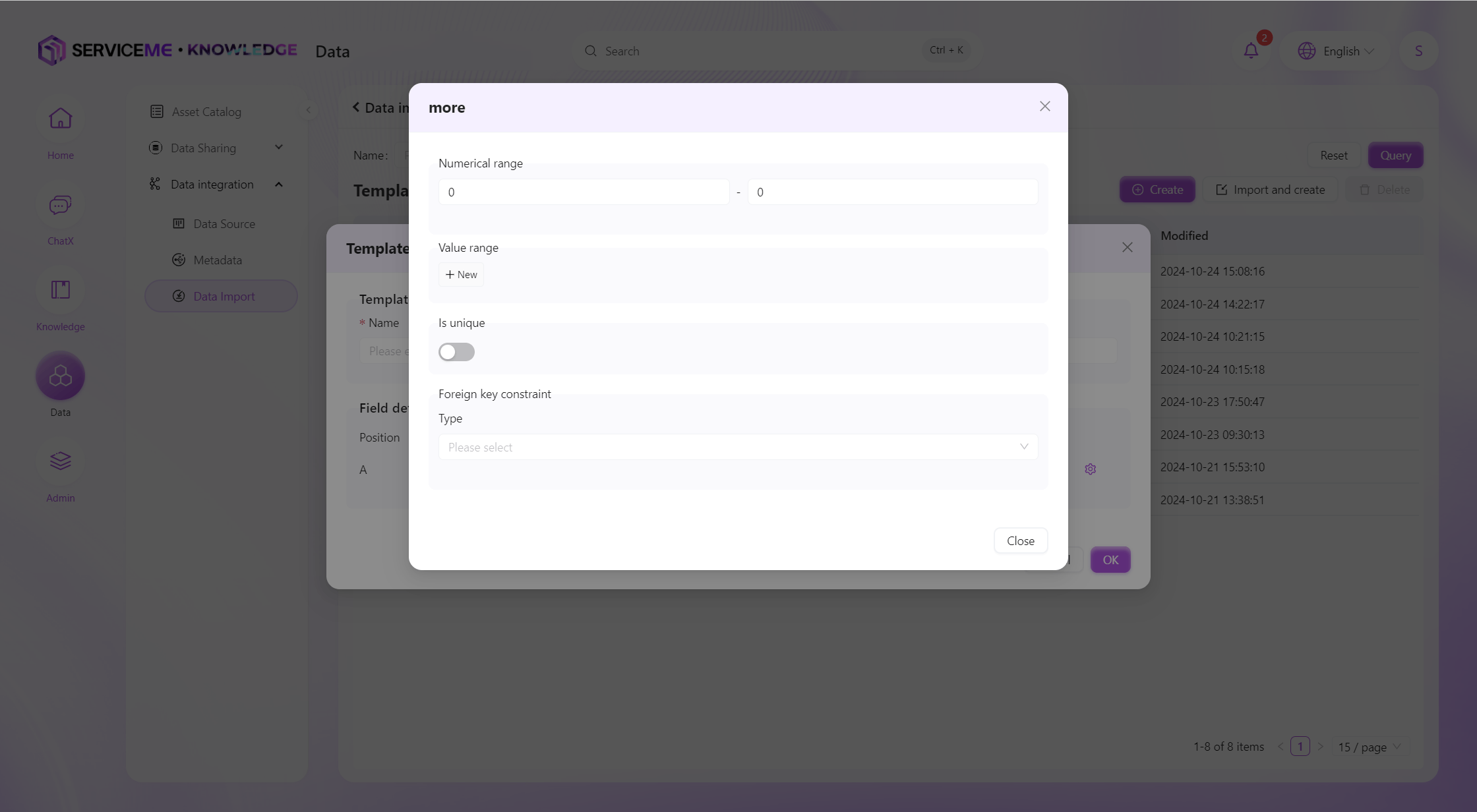
ファイルでインポートテンプレートを作成
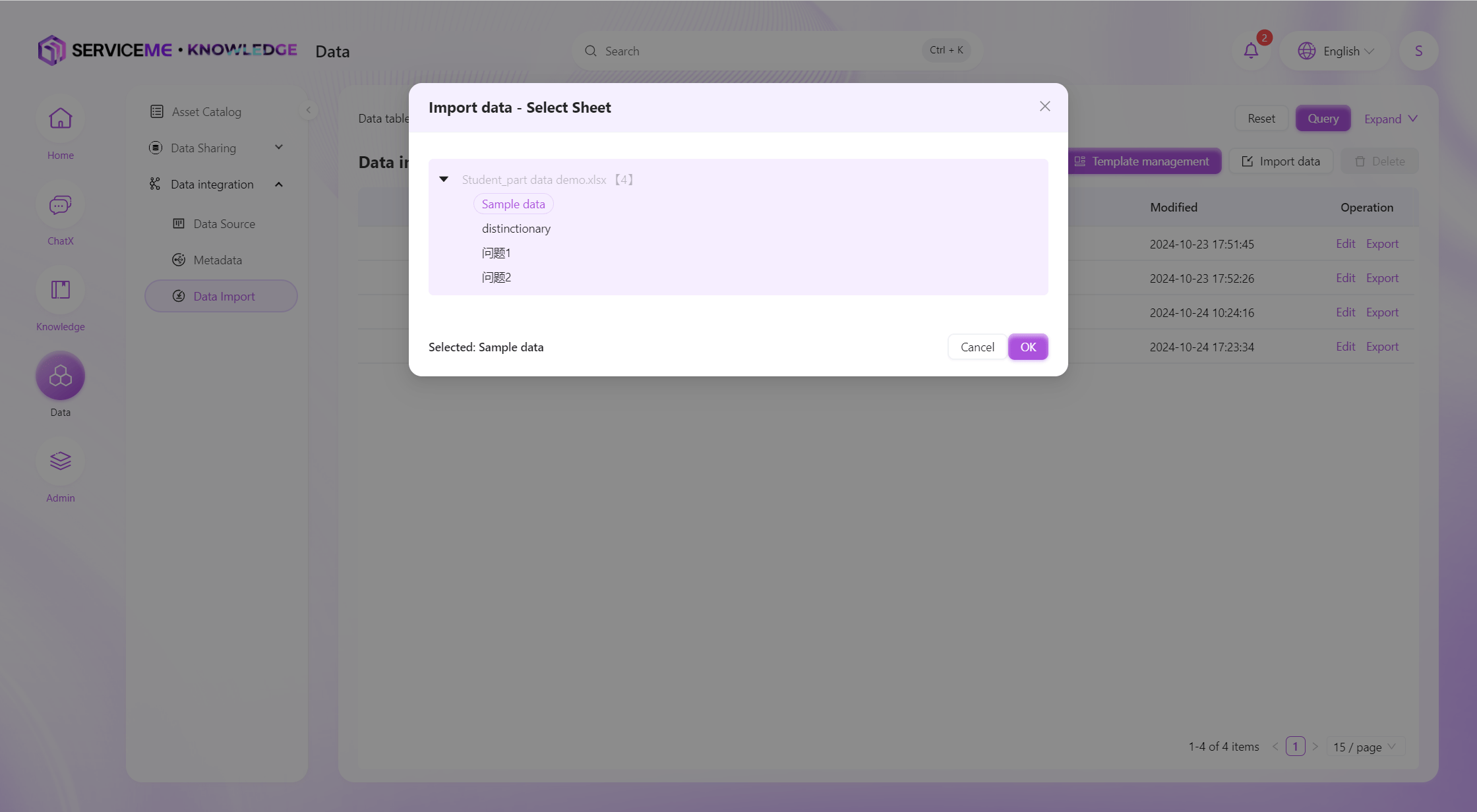
シート選択
システムはシートの1行目をもとにテンプレートのフィールド情報を決定し、各列の型を推定します。インポート後の操作は手動作成と同様です。
データインポート
データインポート機能により、準備したデータファイルをシステムにインポートできます。主な手順は以下の通りです。
-
データファイルの選択:
- ユーザーはインポートするデータを含むExcelまたはCSVファイルをアップロードし、インポートしたいシートを選択します。
-
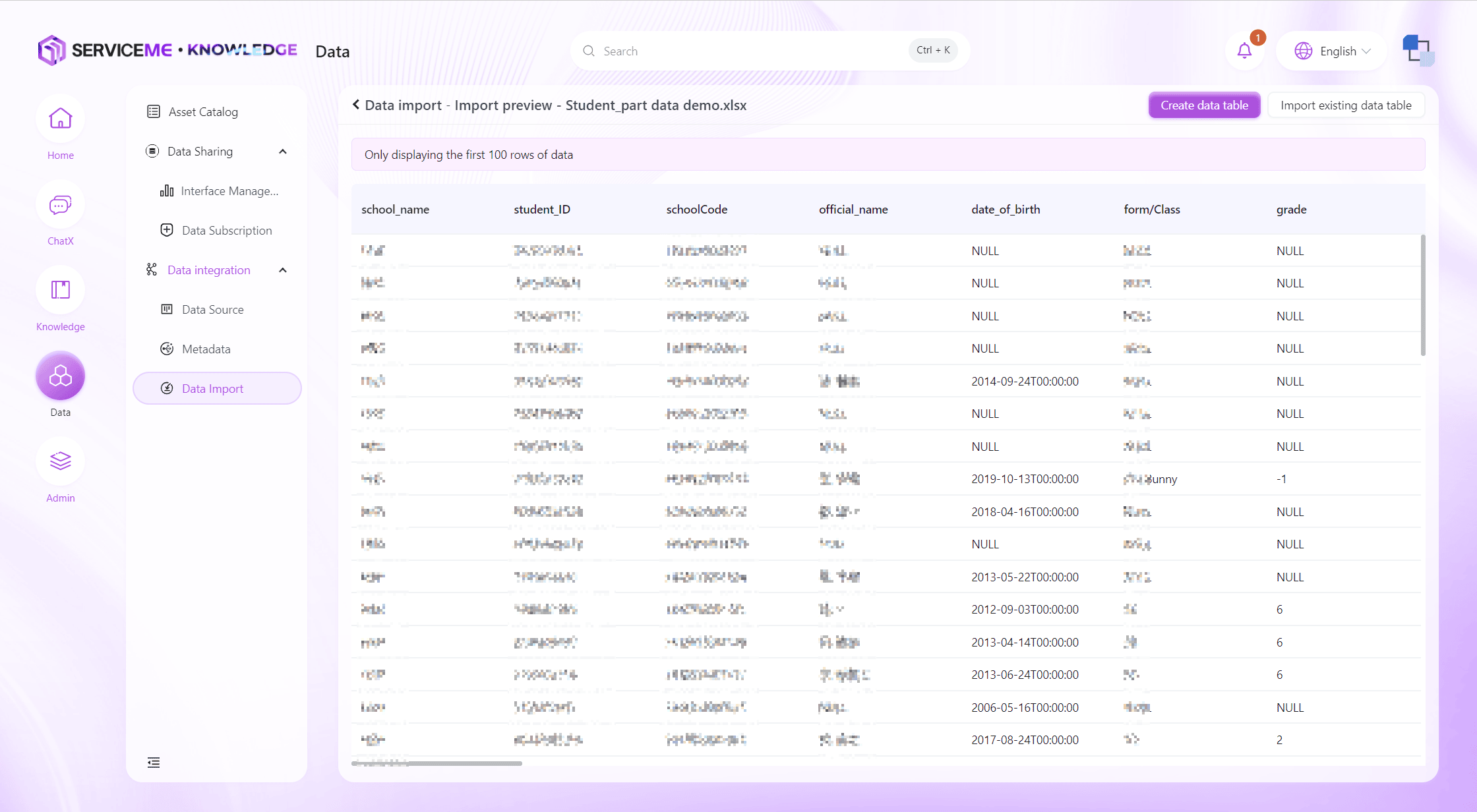
データプレビューと検証:
- 本番インポート前に、システムがデータプレビューを表示し、ユーザーがデータの正確性を確認できます。
-
インポート方式の選択:
- 新規テーブル作成:データを新しいデータテーブルにインポート
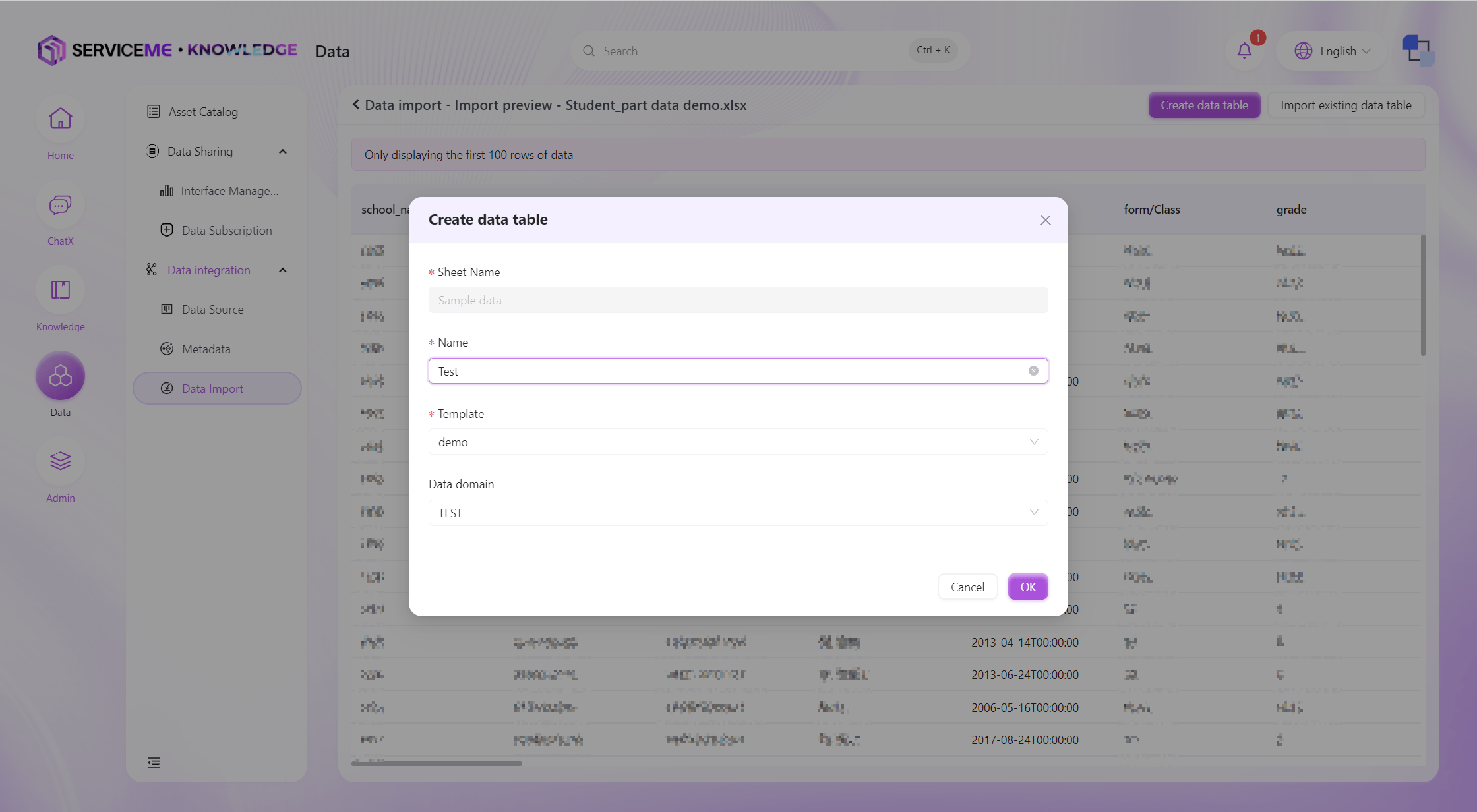
- 既存データへのインポート:既存データテーブルにデータを追加または更新
- 新規追加:常に新規データを追加
- 更新または新規追加:主キーでデータの有無を判定し、存在すれば更新、なければ新規追加
- 上書き:アップロードデータで対象データテーブル全体を上書き
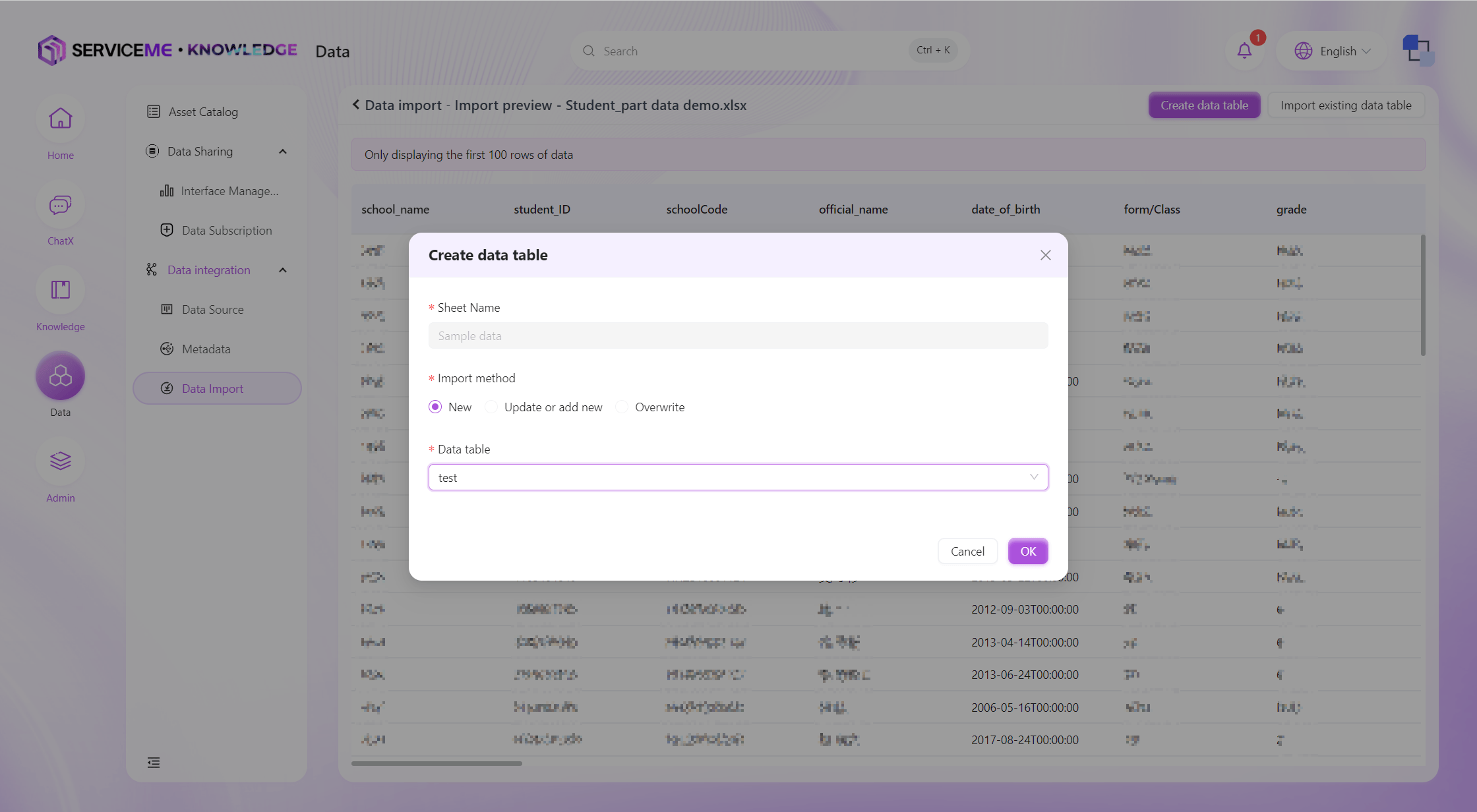
-
インポートの実行:
- システムはアップロードファイルの列と事前定義テンプレートのフィールドを(A-Z順で)マッチング
- ユーザーが確認後、データインポート処理を開始
-
エラー処理:
- インポート中にエラーが発生した場合、システムは詳細なエラーログを提供
- ユーザーはエラー情報に基づきデータを修正し、再度インポートを試行可能