前処理
前処理 Pipeline は、主にドキュメントがナレッジベースに登録される際の処理フローを定義するために使用され、ドキュメントのアップロードおよび取り込み時に自動で有効になります。これには、ドキュメント解析、テキスト分割、ベクトル化などの工程が含まれます。
ユーザーは、ドキュメントタイプや業務要件に応じて処理戦略をカスタマイズでき、複数ソースのドキュメント取り込みにおける差異化処理要件を満たし、ナレッジコンテンツが取り込み段階で正しく解析・分割・インデックス化されることを保証することで、その後の検索における再現率を向上させます。
使用方法
1 つのナレッジベースには複数の前処理 Pipeline を関連付けることができ、異なるファイルタイプの処理要件に対応できます。ファイルアップロード時、システムは順番に適用可能な前処理ルールを照合し、いずれにも一致しない場合はデフォルト Pipelineにフォールバックします。
- プラットフォーム内蔵のデフォルトルール:システムはすぐに使えるデフォルト前処理 Pipeline を提供しており、そのまま使用することも、インポートして参照することもできます。
- カスタマイズと上書き:新しいカスタム Pipeline の作成をサポートし、デフォルト Pipeline をコピーして修正することもできます。デフォルト Pipeline は削除操作をサポートします。
- ルールマッチング機構:優先順位に従って前処理ルールを照合し、一致した場合は対応するフローを実行し、一致しない場合はデフォルト処理を実行します。
推奨:前処理設定を調整した後は、テストファイルをアップロードして処理結果を検証してください。
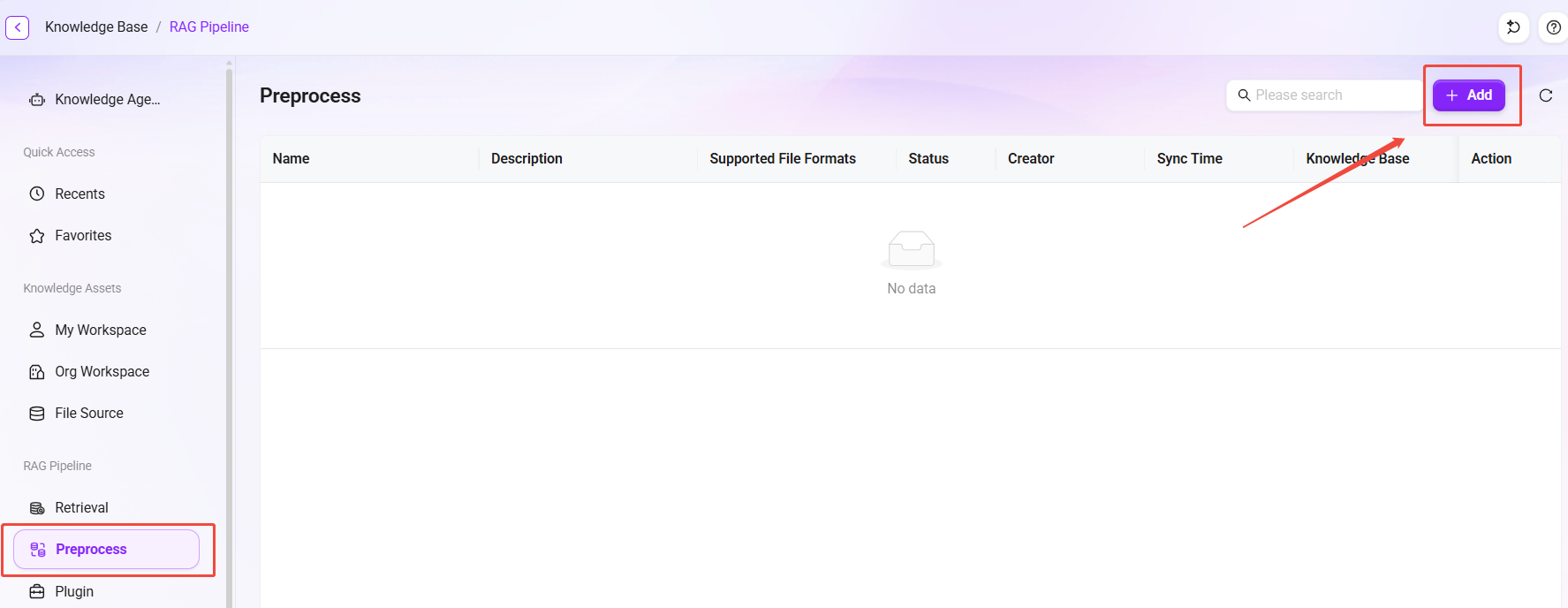
前処理 Pipeline の作成
- 前処理一覧ページで 「新規追加」 ボタンをクリックすると、作成ウィンドウが表示されます。
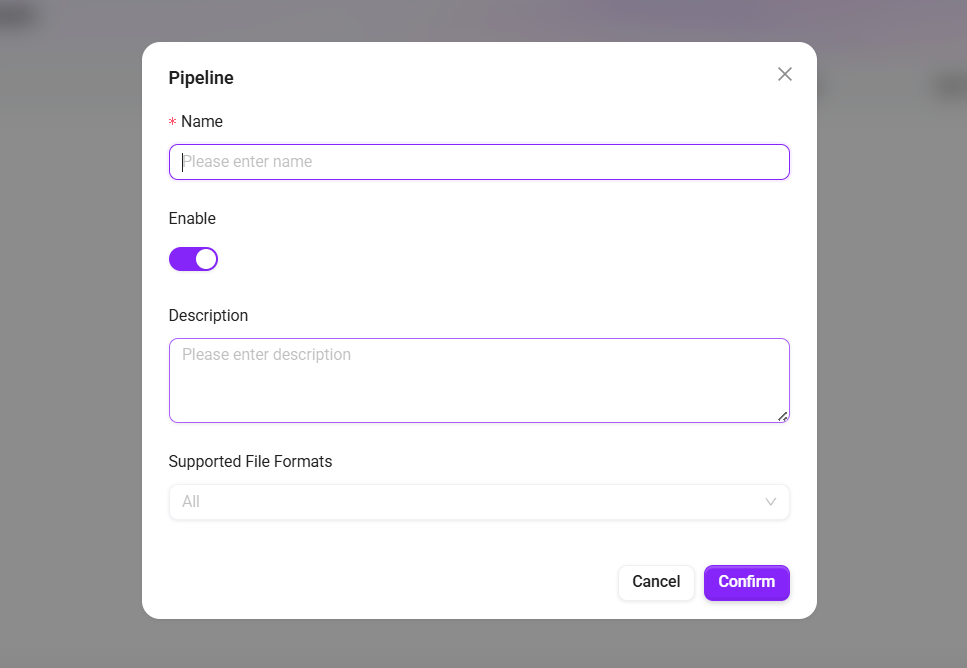
- 基本情報を入力します。
- 名称:前処理 Pipeline 名。
- 有効化:チェックを入れると前処理が有効になり、ナレッジベースに関連付けて使用できます。
- 説明:この前処理の適用シナリオや設定上のポイントを補足説明します。
- 「確認」 をクリックして作成を完了すると、システムは自動的に前処理編集キャンバス画面へ遷移します。
ノード機能の詳細説明
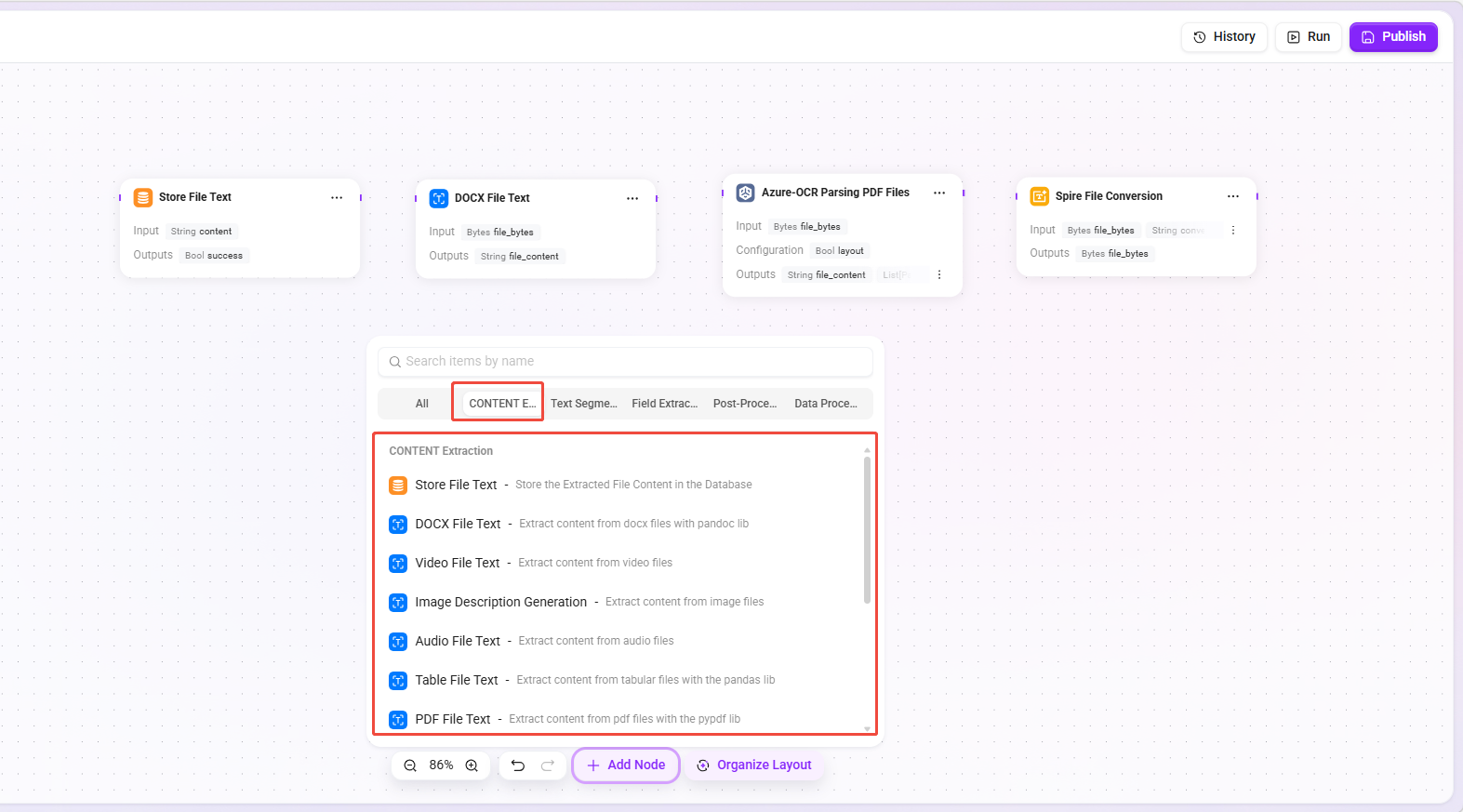
キャンバス編集画面に入ると、ノードライブラリから必要なノードをキャンバスへドラッグし、接続線によって完全なファイル前処理フローを構成できます。
ノードライブラリは機能ごとに以下のカテゴリに分かれています:テキスト抽出、テキスト分割、フィールド抽出、後処理、プラグイン、データ処理。
ヒント:
- 各前処理フローの末尾には、各段階の処理結果が正しくデータベースへ永続化されるよう、対応する保存ノードを追加する必要があります。
- 各ノードの詳細説明については、任意のノードの設定ページ右上の "
" をクリックして説明ドキュメントをご確認ください。
テキスト抽出ノード
各種ファイル形式から元のテキスト内容を抽出し、後続処理の基礎とします。
| ノード名 | 機能説明 |
|---|---|
| ファイルテキストを保存 | ファイルから抽出した内容をデータベースに保存します。 |
| DOCX ファイルテキスト | pandoc ライブラリを使用して docx ファイルから内容を抽出します。 |
| 動画ファイルテキスト | 動画ファイルから内容を抽出します。 |
| 画像説明生成 | 画像ファイルから内容を抽出します。 |
| 音声ファイルテキスト | 音声ファイルから内容を抽出します。 |
| 表形式ファイルテキスト | pandas ライブラリを使用して表形式ファイルから内容を抽出します。 |
| PDF ファイルテキスト | pypdf ライブラリを使用して PDF ファイルから内容を抽出します。 |
| Markdown ファイルテキスト | markdown ファイルから内容を抽出します。 |
| TXT ファイルテキスト | txt ファイルから内容を抽出します。 |
| Azure-OCR による PDF ファイル解析 | Azure Document Intelligence のレイアウト/読み取りモードを使用して内容を抽出します。.pdf 形式のみ対応し、ノイズデータを自動的にクリーンアップできます。 |
| マルチモーダル LLM による PDF ファイル解析 | LLM OCR モデルを使用して内容を抽出します。 |
| Spire ファイル変換 | Spire ライブラリを使用してファイル形式を変換します。 |
| LibreOffice ファイル変換 | LibreOffice ライブラリを使用してファイル形式を変換します。 |
テキスト分割ノード
抽出した長文テキストを指定した戦略に従って複数の段落または断片に分割し、後続のインデックス化と検索を容易にします。
| ノード名 | 機能説明 |
|---|---|
| 固定文字数分割 | 固定サイズでドキュメントを分割します。 |
| 固定文字数分割(ページ番号情報付き) | 固定サイズでドキュメントを分割し、同時にページ開始位置情報を保持します。 |
| 表形式ファイル分割 | 表形式ドキュメントを段落に分割します。 |
| ページ単位分割 | ドキュメントをページごとに段落へ分割します。 |
| 見出し単位分割 | 見出しに基づいてドキュメントを段落に分割します。 |
| ファイルセグメントを保存 | 分割データをデータベースに保存します。 |
フィールド抽出ノード
ドキュメント内容またはメタデータから重要情報を抽出し、要約、キーワード、または構造化フィールドを生成します。
| ノード名 | 機能説明 |
|---|---|
| 段落拡張データを保存 | ドキュメント段落の拡張強化データをドキュメントインデックスに保存します。 |
| ドキュメントメタデータを保存 | 抽出したドキュメント情報をドキュメントインデックスに保存します。 |
| メタデータ抽出 | LLM を使用してドキュメントからメタデータを抽出します。 |
| キーワード抽出 | LLM を使用してドキュメントの各段落からキーワードを抽出します。 |
| 段落メタデータ抽出 | LLM を使用して各ドキュメント段落からメタデータを抽出します。 |
| 段落要約生成 | 段落を要約します。 |
| 表高度要約生成 | LLM を使用して表レベルの要約およびグループレベルの叙述要約を生成します。 |
| 画像説明生成 | 画像説明を使用して段落を強化します。 |
| ドキュメント要約生成 | ドキュメント全体を要約します。 |
| 表行レコード要約生成 | 表の説明を使用して段落を強化します。 |
後処理ノード
分割後のテキストに対してトークン化、ベクトル化などの後続処理を行い、インデックス化前の準備作業を完了します。
| ノード名 | 機能説明 |
|---|---|
| 分割トークンを保存 | セグメントのトークンデータをデータベースに保存します。 |
| SpaCy に基づく分割トークン化 | SpaCy トークナイザーを使用してトークン化します。 |
| 分割データをベクトル化して保存 | モデルを使用して段落を埋め込みし、埋め込みベクトルをベクトルデータベースに保存します。 |
データ処理ノード
フロー制御と変数処理機能を提供し、より複雑な前処理ロジックを構築するために使用されます。
| ノード名 | 機能説明 |
|---|---|
| 変数アグリゲーター | 複数の変数をグループ化して出力変数に集約し、「最初の非空値を取得」と「リストに結合」の 2 つの戦略をサポートします。集約動作は set_output_mapping() によって動的に設定されます。 |
| 条件ノード | 条件に基づいてフローを分岐制御します。条件判定ロジックはパイプラインエンジンによって外部で処理され、ノード自体は出力データを生成しません。 |
| テンプレート | Jinja2 テンプレート構文を使用して各変数を処理および整形します。 |
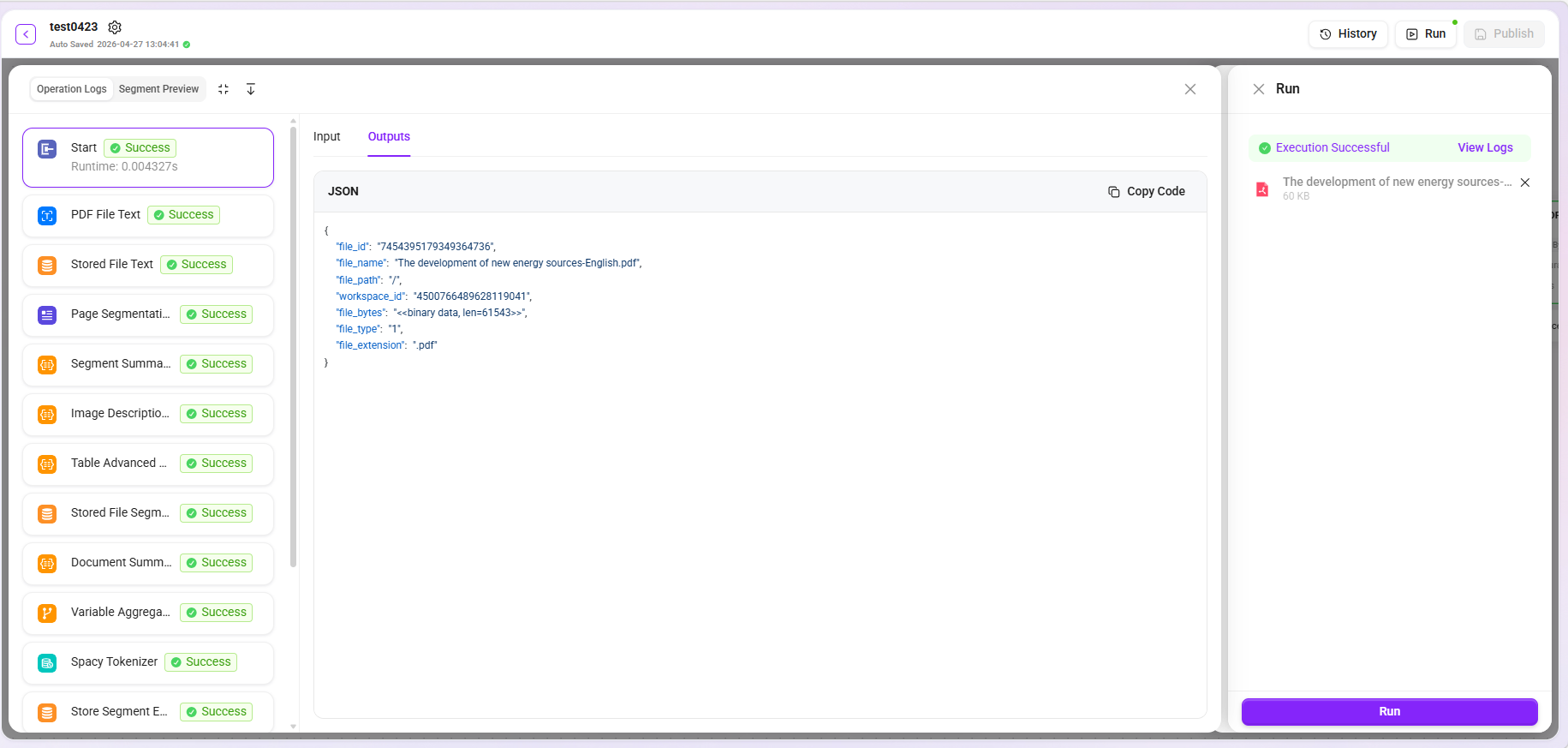
試運転
設定完了後、試運転機能を使用して前処理フローが期待どおりに実行されるかを検証できます。システムはローカルからのアップロード、またはナレッジベースからのファイル選択によるテストをサポートしています。
ヒント:テスト効率を確保するため、アップロードするファイルサイズは 5MB 以下、ページ数は 20 ページ以下を推奨します。
- ログの確認:「ログを確認」をクリックすると、各ノードの詳細な入力内容と出力内容を展開でき、ノードごとに問題を切り分けて、処理異常の具体的な箇所を正確に特定できます。
- 断片プレビュー:処理後のテキスト断片のプレビューをサポートし、分割や抽出など各工程の効果が期待どおりかを直感的に判断できます。
- データダウンロード:表示制限により、プレビュー領域にはデフォルトで先頭 10 件のデータのみが表示されます。完全なデータが必要な場合は、「ダウンロード」 ボタンをクリックしてすべての処理結果を取得できます。