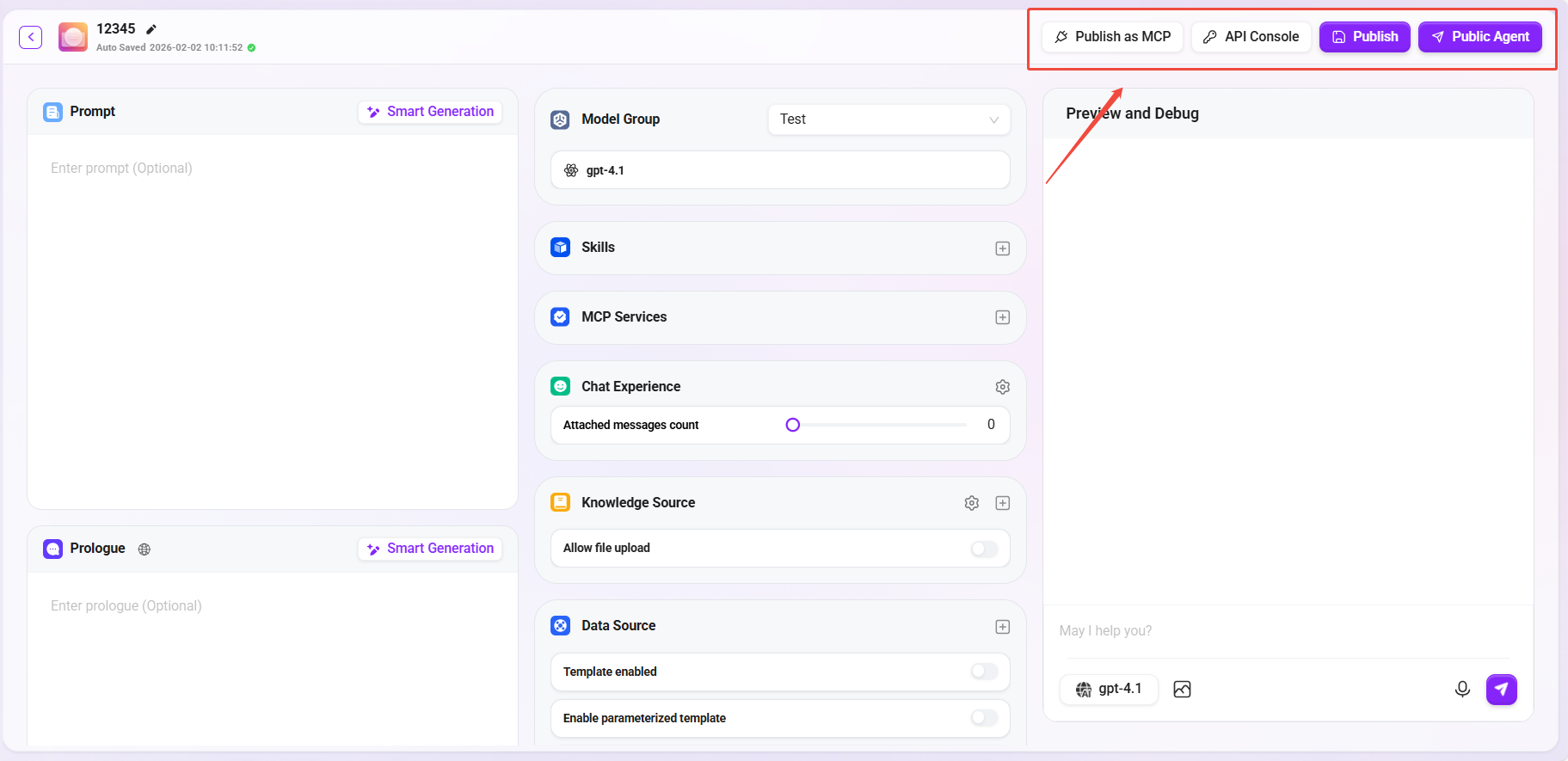
基本的なAgentの作成
助手タイプの選択
AI Studioページの右上にある「作成」をクリックして、ベーシックインテリジェントエージェントを作成します。
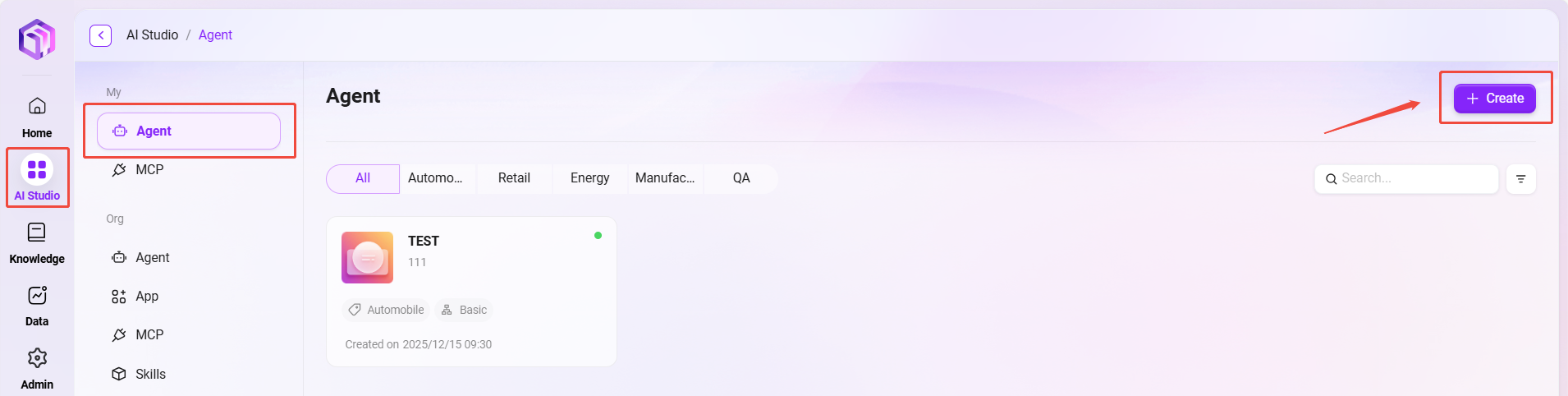
作成手順
作成ポップアップで以下の基本情報を入力します:
① アシスタント名:助手の名前を入力します(50文字以内)。
② エージェントのアバター:システムのデフォルトアイコンから選択します(カスタムアイコンのアップロードは現在サポートされていません)。
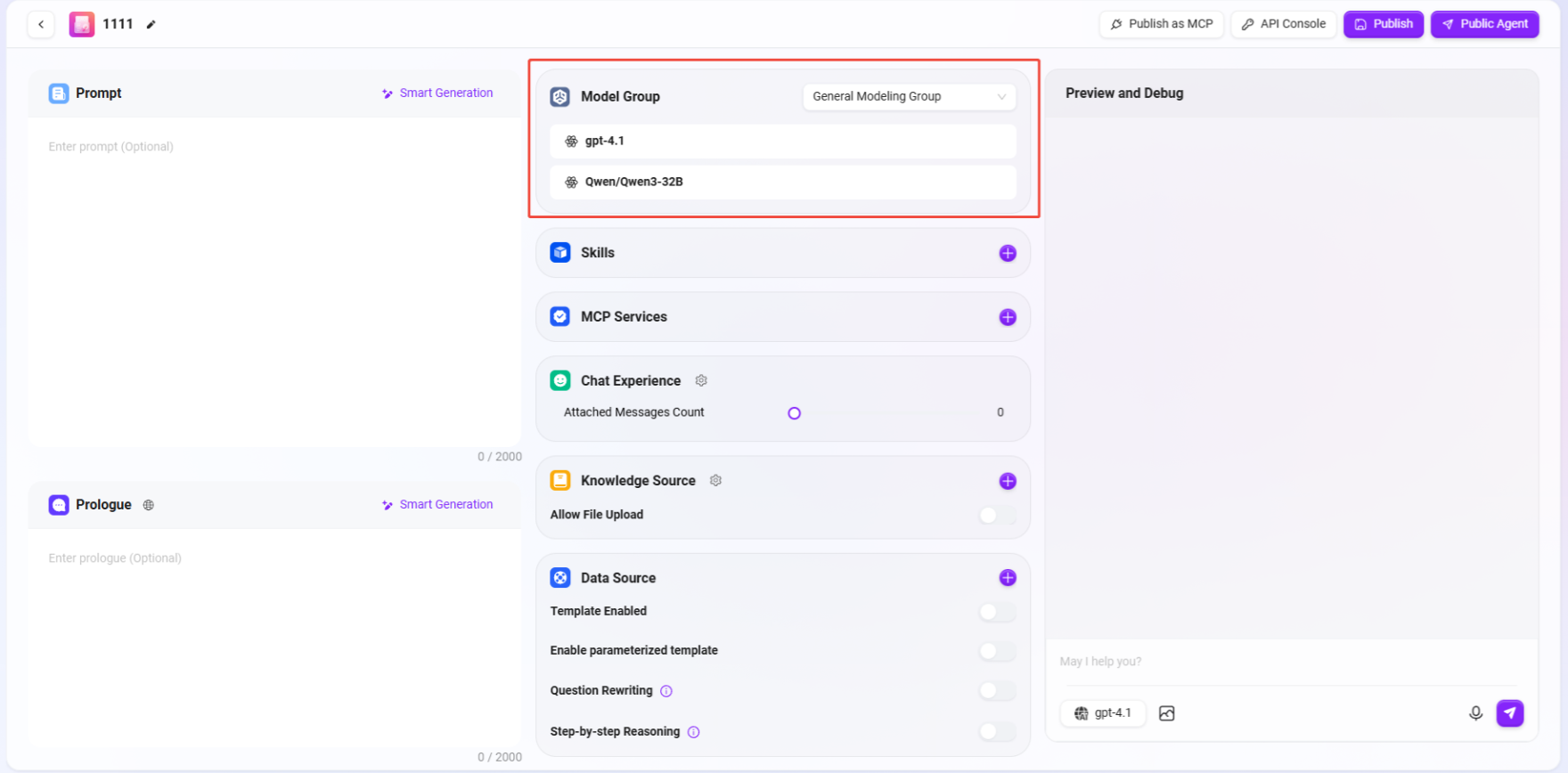
③ モデルグループ:助手に適切なモデルグループを設定します。
④ エージェント分類:新規助手が属するグループを選択します(最大5つまで選択可能)。
⑤ エージェントの説明:助手の機能や用途を説明する簡単な説明を入力します(200文字以内)。
- 「作成」をクリックします。助手が作成された後、ベーシックオーケストレーション助手設定ページに入ります。設定して公開すると使用できます。
💡 ヒント:システムインターフェースは以下の言語をサポートしています:中国語簡体字、中国語繁体字、日本語、英語。
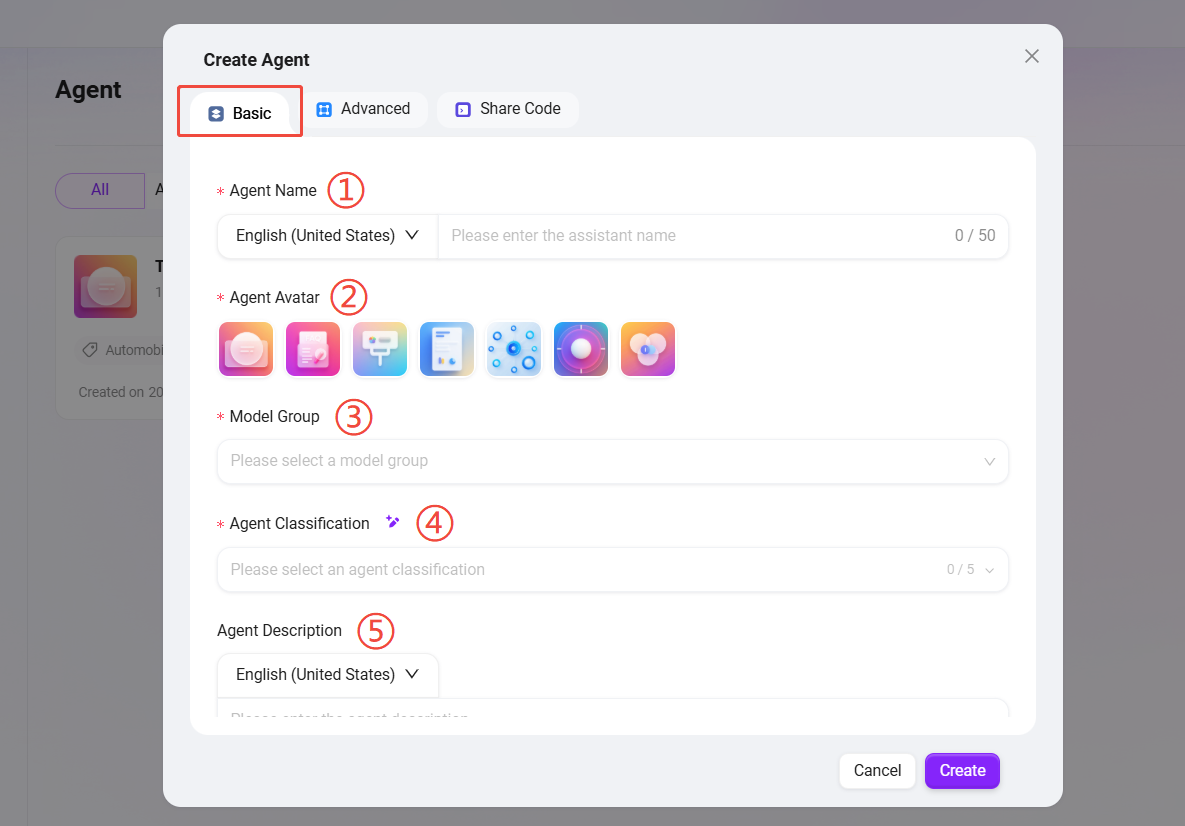
助手の設定
設定ページへのアクセス
インテリジェントエージェントの詳細設定ページには、以下の2つの方法で入ることができます:
- 方法1:AI Studioで新しい助手を作成した後、システムは自動的にその設定ページに入ります。
- 方法2:エージェントリストで、ターゲットエージェントカードにマウスを乗せ、表示される「✏️」アイコンをクリックして設定ページに入ります。
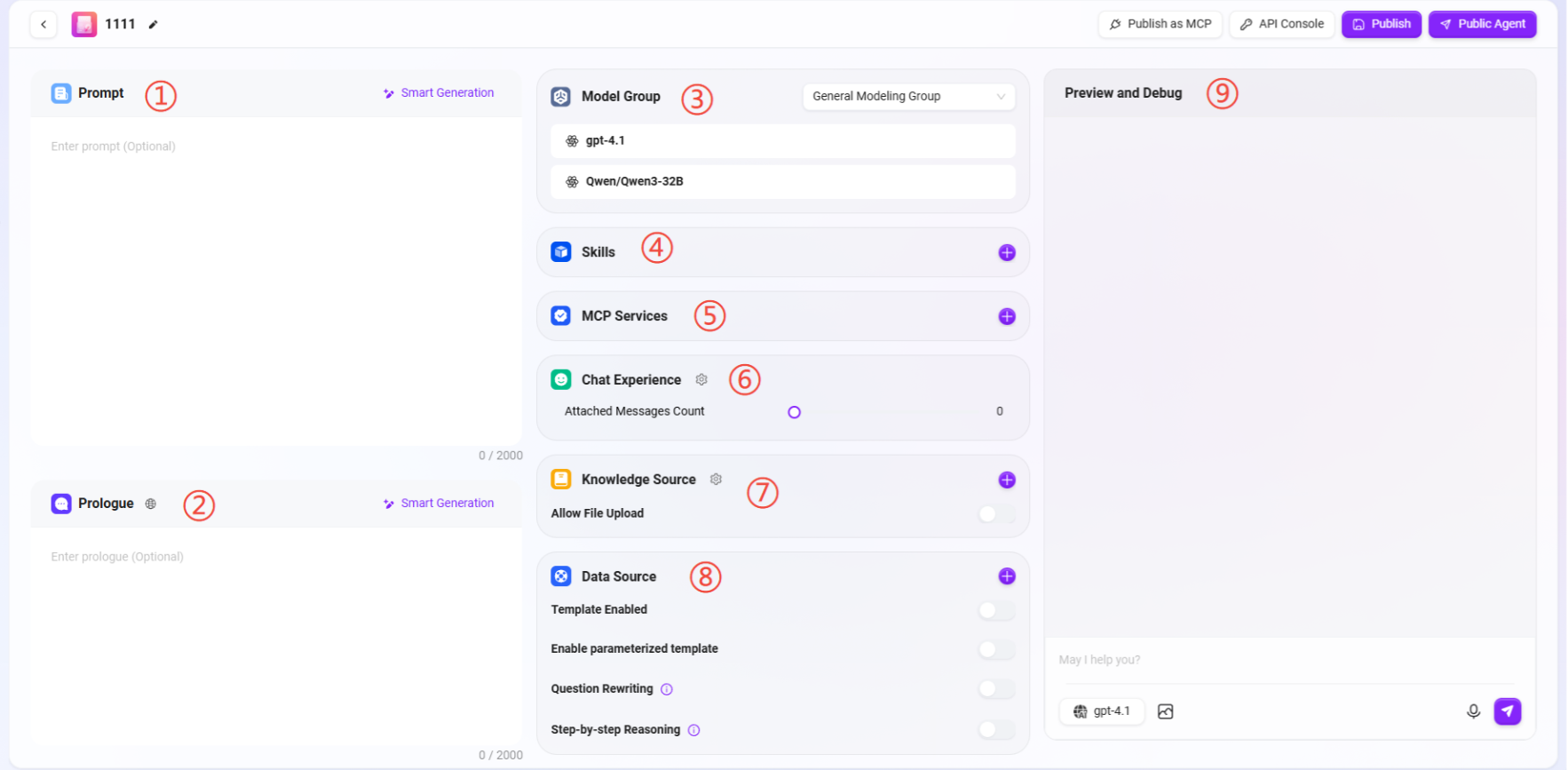
コア設定項目の説明
設定ページには以下のコアモジュールが含まれます:
① プロンプト:エージェントのプロンプトを入力します。既存のプロンプトに基づいてインテリジェントに生成することもサポートします。
② オープニング:エージェントのオープニングメッセージを入力します。プロンプトまたは既存のオープニングメッセージに基づいてインテリジェントに生成することもサポートします。
備考:プロンプトとオープニングメッセージの入力が約2000文字を超えると、システムは「入力内容が多すぎるため、効果に影響する可能性があります」と警告しますが、入力を阻止することはありません。最適なパフォーマンスを得るためには、内容を簡潔に保つことをお勧めします。
③ モデルグループ:「+」をクリックしてモデルグループを追加し、複数のオプションモデルをサポートします。
- 機能:**「+」**をクリックして、エージェントに設定済みのモデルグループを追加または切り替えます。1つのモデルグループには複数の異なるAIモデルを含めることができます。
- 管理説明:モデルグループは、管理者が**「管理 > モデル管理 > モデルグループ」**で事前に作成および設定する必要があります。複数のモデルを同じモデルグループに追加した後、ここでエージェントに割り当てることができます。
管理者がモデルグループを追加する手順:
- アクセスパス:管理 → モデル管理 → モデルグループ。
- **「新規モデルグループ」**をクリックします。
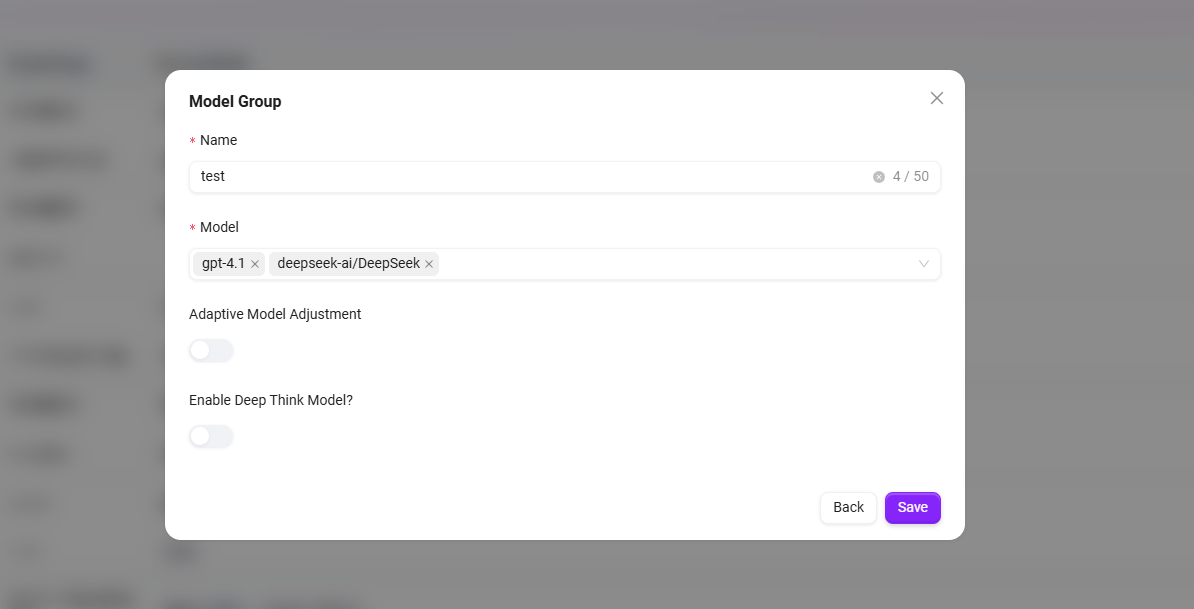
- 以下の設定を完了します:
- モデルグループ名を入力します。
- このグループに追加するモデルをチェックします(複数選択可能)。
- **「適応型モデルデプロイ」**を有効にするかどうかを選択します。トラフィックに基づいて計算リソースを自動調整し、安定したサービスを確保します。
- **「深度思考モデル」**を有効にするかどうかを選択します。複雑な問題に対してより強力なAIをインテリジェントに呼び出し、回答品質を大幅に向上させます。
- **「保存」**をクリックします。

④ スキル
「+」をクリックして1つ以上のスキルを追加するか、推奨スキルを追加します(最大20個のスキルを追加できます)。
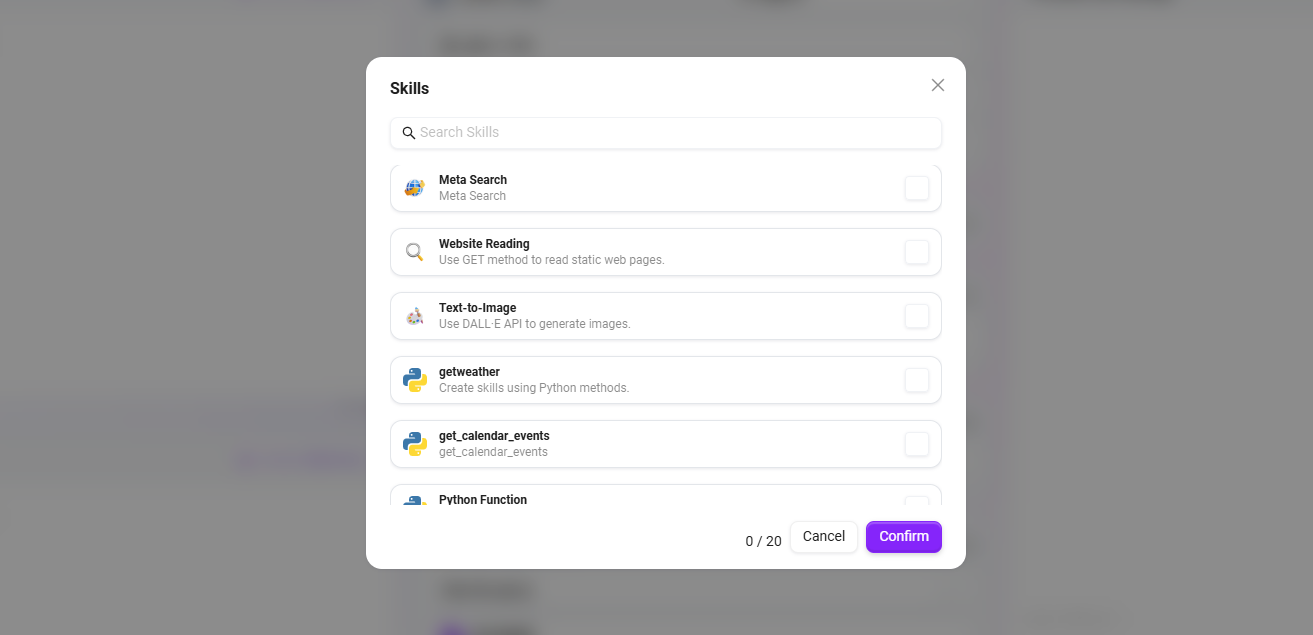
システムは7つのデフォルトスキルを提供します:Google検索、Tencent検索、G-Bing検索、Mita検索、文生図、ニュース検索ツール、ウェブページ読み取り。
- Google検索:Google検索エンジンを通じてリアルタイムで正確なウェブ情報を取得し、グローバルなウェブコンテンツの検索をサポートします。
- Tencent検索:Tencent検索技術に基づき、中国語インターネット環境向けの検索サービスを提供し、特に中国語コンテンツの検索効果を最適化します。
- G-Bing検索:総合的なウェブ検索機能を提供し、検索の広範性と結果の正確性のバランスを取ります。
- Mita検索:効率的で正確な検索サービスを提供し、ユーザーが必要な重要な情報を迅速に特定して返します。
- 文生図:テキスト記述に基づいて対応する画像コンテンツを自動生成し、文字の創造性を視覚的表現に変換します。
- ニュース検索ツール:様々なニュース情報を検索・取得するための専用ツールです。
- ウェブページ読み取り:ウェブページのテキスト、データなどのコンテンツを抽出し、ウェブページ情報を解析する機能です。
備考:他のスキルの追加をサポートしますが、管理者がバックエンドで操作および設定する必要があります。
⑤ MCPサービス
MCPサービスは、システム内のAI助手と外部ツール/データソース間の接続権限を管理します。
- 作用:
- 能力拡張:検索、計算、視覚化などの外部能力をエージェントに付与します。
- エコシステム統合:様々なツールとサービスを継続的に統合し、多様なニーズを満たします。
- 内部統合:個人MCPを通じて内部システムリソースを統合します。
- 設定提案:設定されたMCPツールの数が5つ以上になると、システムは警告を発します。ツールが多すぎるとプロンプトが長くなり、モデルのコンテキスト制限を超え、パフォーマンスに影響する可能性があります。
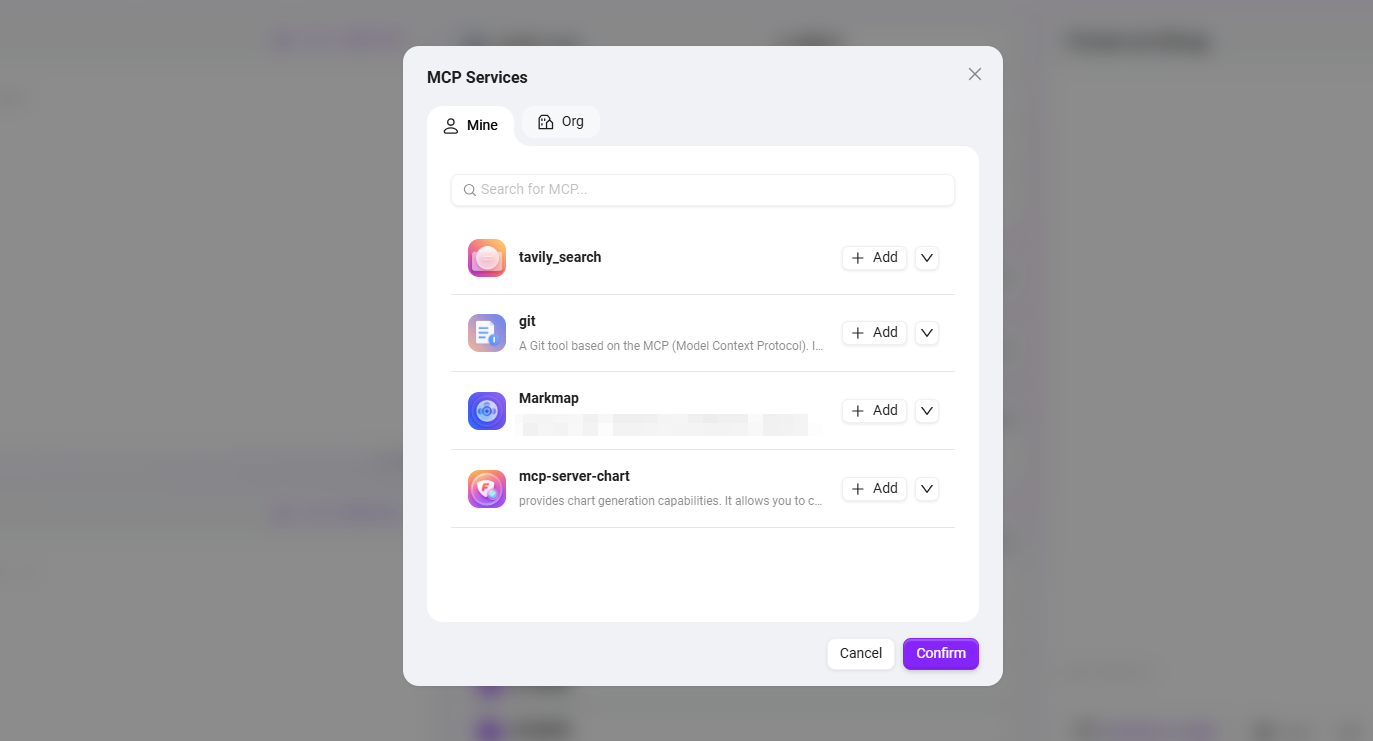
⑥ チャット体験
-
コンテキストメモリの数:エージェントが記憶できる過去のダイアログラウンド数を設定します(1-10ラウンド)。ダイアログの一貫性とパフォーマンスのバランスを取るために、5に設定することをお勧めします。
-
チャット体験設定:「ユーザー質問提案、質問ガイダンス、チャット履歴、ダイアログフィードバック、キーワード審査」などの設定を有効にできます。
- ユーザー質問提案:エージェントが回答した後、前文に基づいてユーザーにいくつかの質問提案を提供します。
- 質問ガイダンス:ユーザーとエージェントのダイアログ時に、関連する質問ガイダンスがあり、モデルの能力を利用してユーザーが質問する可能性のある問題やユーザーの質問を補完します。
- チャット履歴:エージェントのチャット履歴を保持するかどうか。オフにすると、エージェントのチャット履歴を確認できなくなります。
- ダイアログフィードバック:エージェントの回答に対して「いいね」や「嫌い」などのインタラクティブ操作を行い、エージェントの回答を最適化するために使用します。
- キーワードフィルタリング:「入力内容の審査」と「出力内容の審査」の少なくとも1つを有効にする必要があります。有効にすると、プロンプトやAIフィードバック結果に対してセンシティブワード検出が行われます。センシティブワードは事前に維持できます。
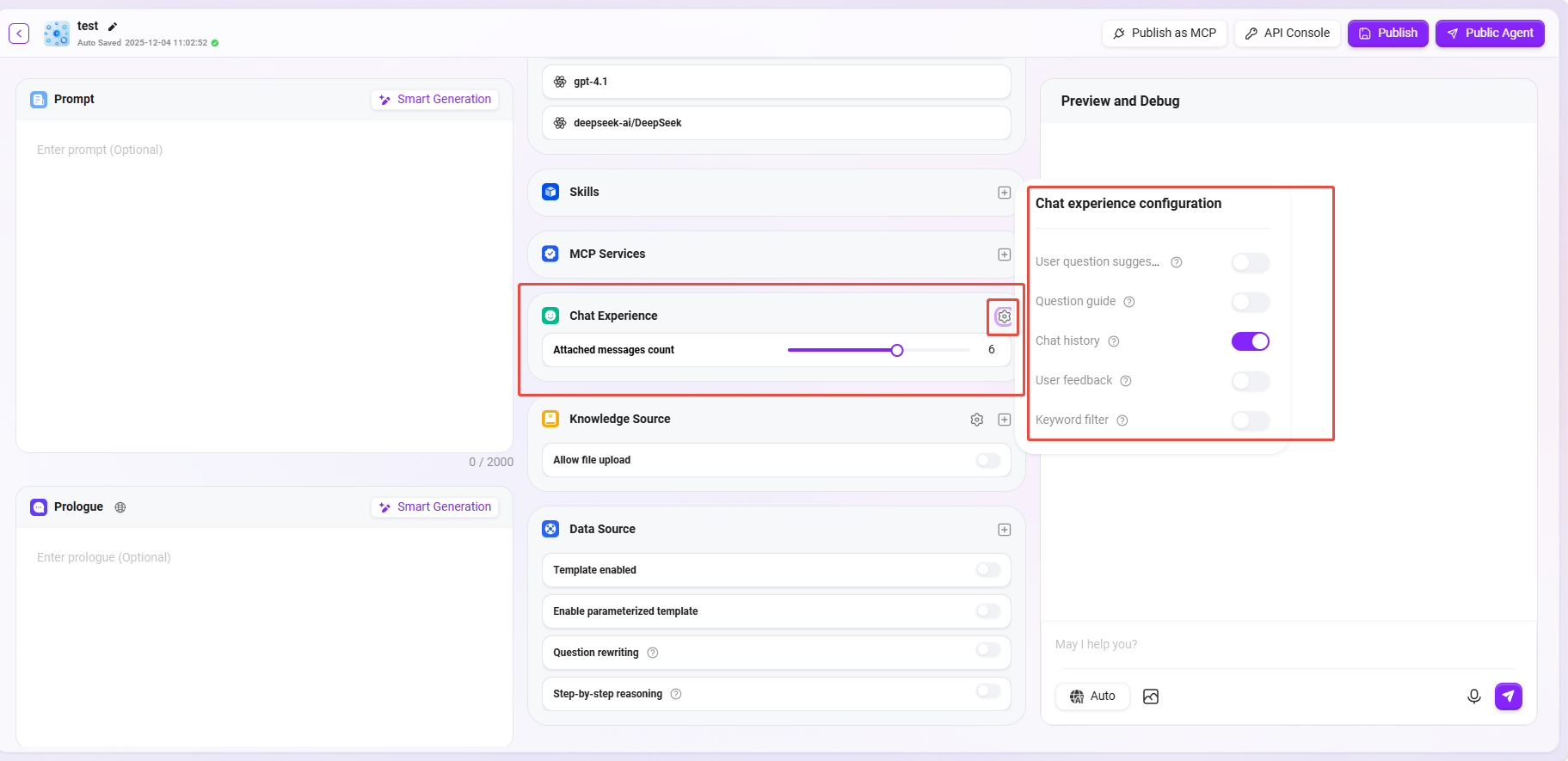
⑦ 知識の出典
-
知識ベース:「+」をクリックして知識ベースを追加します(知識ソースとして最大5つの知識ベースを追加できます)。
-
ファイルアップロードを許可する:
- 「ファイルアップロードを許可する」をオンにすると、知識ベースのコンテンツを知識ソースとして追加することはできません。
- 「ファイルアップロードを許可する」をオフにすると、個人スペースまたはワークスペースの知識ベースを知識ソースとして選択的に追加できます。
-
知識ソースの設定:知識ベースの「検索戦略、プライベートQ&A、検索方法」などの詳細設定を変更できます。
- 検索戦略:混合検索、埋め込み検索、テキスト検索。
- 混合検索:ベクトル検索と全文検索の結果を統合し、再ランク付けされた結果を返します。
- 埋め込み検索:類似性を通じてセグメントを検索し、ある程度の言語横断汎化能力があります。
- テキスト検索:キーワードを通じてセグメントを検索し、特定のキーワードや名詞セグメントを含む検索に適しています。
-
最大リコール数:範囲1〜10。高すぎたり低すぎたりする設定はお勧めしません。推奨値は3〜5です。
-
メタデータフィルタリング:なし、フィルター、重み。
-
プライベートファイルQ&Aを強制実行:オンにすると、ウェブ検索などのスキルは使用せず、エージェントの回答は知識ベースのコンテンツのみに基づきます。
-
ドキュメント一致度:範囲0〜1。類似度が高いほど、リコールされるドキュメントコンテンツが類似していることを示します。推奨値は約0.8(80%)です。
-
QnA一致度:範囲0〜1。ドキュメントコンテンツの類似度マッチングと似ています。推奨値は約0.9(90%)です。
-
参考文献を表示:オンにすると、エージェントは回答時に参照した文献をリストアップし、回答の信頼性を高めます。
💡 ヒント:最大リコール数、ドキュメントマッチング類似度、QnAマッチング類似度のいずれも、高ければ良い、低ければ良いというわけではありません。実際のニーズに応じて設定することをお勧めします。特別な要件がない場合は、デフォルト値を維持することをお勧めします。
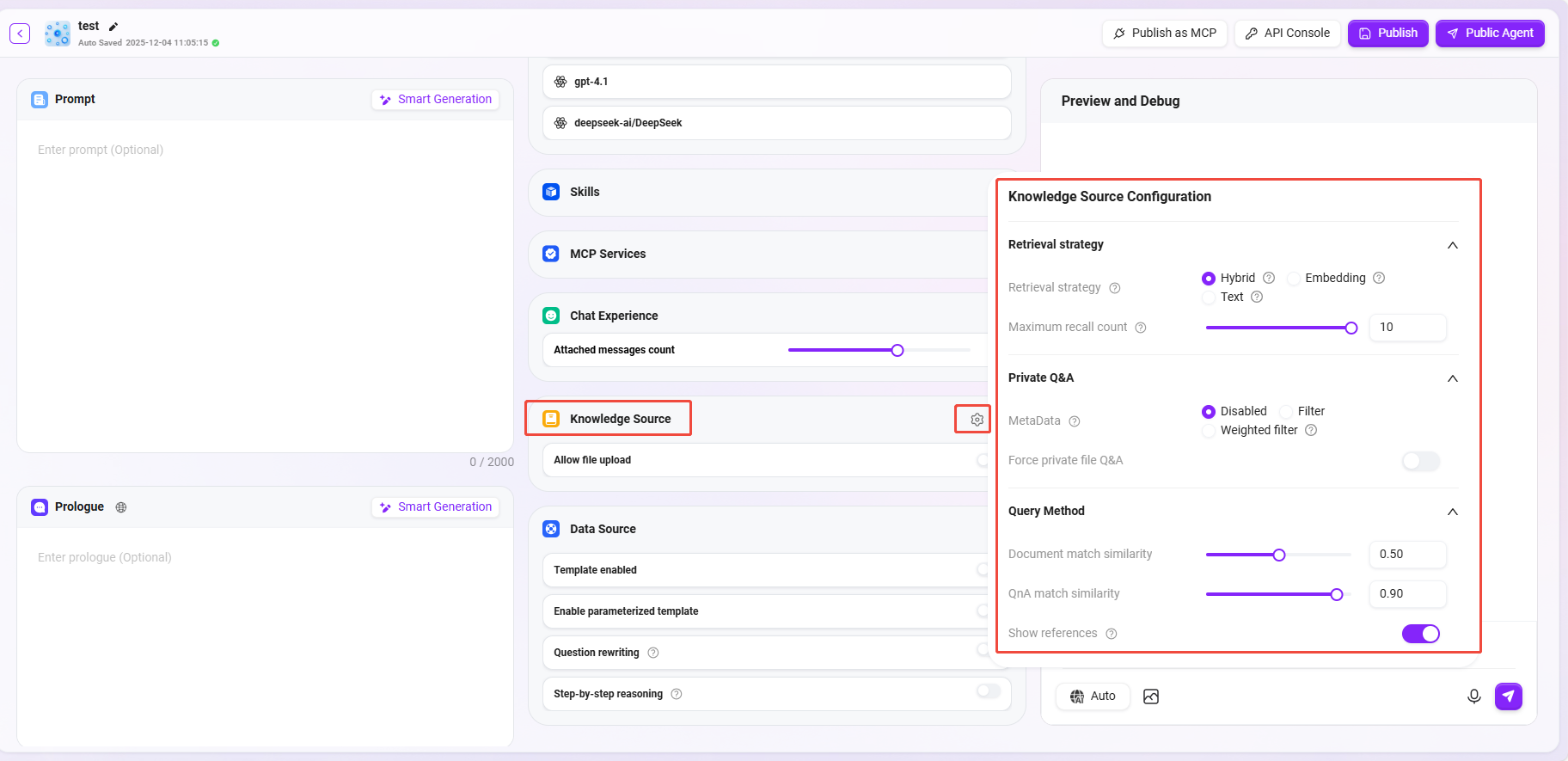
⑧ データソース
-
データソース:「+」をクリックしてデータソースを追加し、エージェントのQ&Aデータソースとします(最大5つのデータソースを追加できます)。
-
テンプレートを有効にする:自然言語とSQLの間の事前設定されたマッピングテンプレートを有効にするかどうか。
- ユーザーが自然言語の質問(例:「
先月の売上はいくらですか?」)を入力すると、システムはまず事前設定されたテンプレートに一致するものを試みます。 - 一致するテンプレート(例:「
特定の期間の売上を照会する」のような一般的な質問)が見つかった場合、テンプレート内の既存のSQL構造を参照として使用し、具体的なフィールド/テーブル名などと組み合わせて最終的なSQLステートメントを生成します。
- ユーザーが自然言語の質問(例:「
-
パラメータ化テンプレートを有効にする:オンにすると、テンプレートの上でパラメータ化クエリが有効になり、クエリの柔軟性とセキュリティが向上します。
-
質問書き換え:オンにすると、ユーザー入力の質問が自動的に最適化され、正確なデータクエリが確保されます。
- ユーザーの元の質問:
売上を確認してください(情報が不完全)。 - 書き換え後:
2024年7月の全製品の総売上を照会してください(時間と範囲を補完)。
- ユーザーの元の質問:
-
ステップバイステップ思考:この機能をオンにすると、最終的なクエリ結果を生成する前に、システムは詳細な思考ステップを出力し、問題をどのように分析し、SQLクエリストテートメントを構築したかを説明します。
- ステップ1:キーワード「
2024年7月」、「売上」を識別します。 - ステップ2:データテーブル
Orders、フィールドorder_dateとsales_amountを決定します。 - ステップ3:日付範囲条件
2024-07-01から2024-07-31を構築します。 - ステップ4:SQLを生成します。
- ステップ1:キーワード「
-
二次確認:オンにすると、生成されたSQLに対してモデルが正確性検査を行います。Claude系モデルには一時的に非対応です。
⑨ プレビューとデバッグ
- 機能:公開前に、ここでエージェントとのダイアログテストを行うことができます。
- 操作:ユーザーはプレビューダイアルグウィンドウに直接問題を入力し、設定中のエージェントとリアルタイムで対話して、そのプロンプト、知識ベース、スキルなどの設定が期待通りかどうかを検証できます。
- 目的:公開前にエージェントの動作が正確であることを確認し、設定エラーによるユーザーエクスペリエンスへの影響を回避します。
公開と使用
設定が完了したら、公開を選択してエージェントの作成を完了できます。「Agentに公開」とは、組織エージェントに公開することを意味します。また、MCPとして公開することも選択でき、別のエージェントにアクセス可能なMCPとして公開します。APIコンソールでは、既存のAPIチャネル名とAPI Keyの数を確認でき、新しいチャネルを追加することもできます。
すべての設定を完了し、プレビューデバッグを通過したら、エージェントを公開できます:
- MCPとして公開:エージェントはMCPサービスとして公開でき、他のエージェントがアクセスして呼び出すことができます。
- APIコンソール:「APIコンソール」では、既存のAPIチャネル名とAPI Keyの数を確認でき、新しいチャネルの追加などの管理操作を行うことができます。
- 公開:設定とプレビューが問題ないことを確認したら、公開をクリックして設定を保存し、エージェントを正式に使用できます。
- 公開エージェント:エージェントを組織のエージェントライブラリに公開し、チームメンバーが使用できるようにします。