ワークフローによるエージェント作成
インテリジェントエージェントタイプの選択
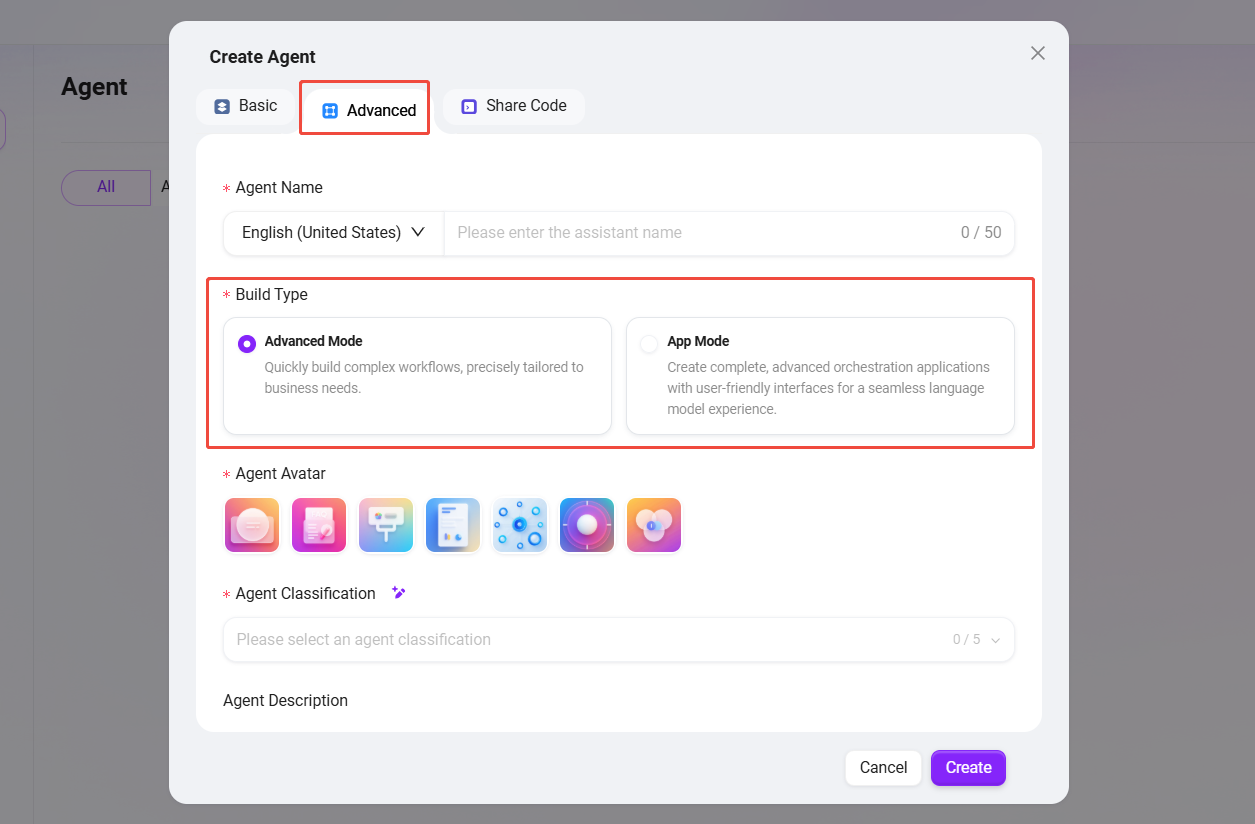
エージェントを作成する際は、「高度なエージェント」 を選択します(初期作成手順は通常のエージェントと同じです)。
- 構築タイプ:異なる複雑さのビジネスニーズに対応するため、2つのコアモードを提供します。
- アドバンスモード:対話ベースの複雑なワークフローを迅速に構築します。
- アプリケーションモード:カスタマイズ可能なユーザーインターフェースと構造化入力フローを持つ、完全なオーケストレーションアプリケーションを作成し、より優れたユーザー体験を提供します。
アドバンスモード
ベーシックエージェントの上に強化されたQ&A型エージェントで、コア機能はマルチターン対話と知識Q&Aに集中しています。
特徴:
- 自然言語による対話を主なインタラクション方式とします。
- 作成後、エージェントリスト に表示されます。
- 柔軟でオープンな対話インタラクションが必要なビジネスシーンに適しています。
典型的なシーン:
- 企業内ナレッジQ&Aアシスタント
- 製品FAQおよび技術サポートアシスタント
- チケット処理コンサルティングアシスタント
アプリケーションモード
UI付きエージェントオーケストレーションアプリ を構築し、特定の入力構造を持ち、特定のタスクを完了するために使用されます。自由対話が主ではなく、定められたタスクフローの実行に特化したエージェントです。
特徴:
- 作成後、APPページ に表示されます。
- 固定かつカスタマイズ可能な入力インターフェース(ファイルアップロード、フォームフィールド入力など)を持ちます。
- 特定の自動化または半自動化タスクフローの実行に重点を置きます。
- ファイルや構造化データ(Structured Data)など、複雑な入力タイプをサポートし、厳格な入出力フォーマットが必要なビジネスシーンに適しています。
典型的なシーン:
- 契約書レビューアプリ(契約書アップロード → 自動リスクマーキング)
- ドキュメント分析アプリ(ドキュメントアップロード → 重要内容自動生成)
- データクレンジングアプリ(Excelアップロード → データ自動処理)
ワークフローの構成
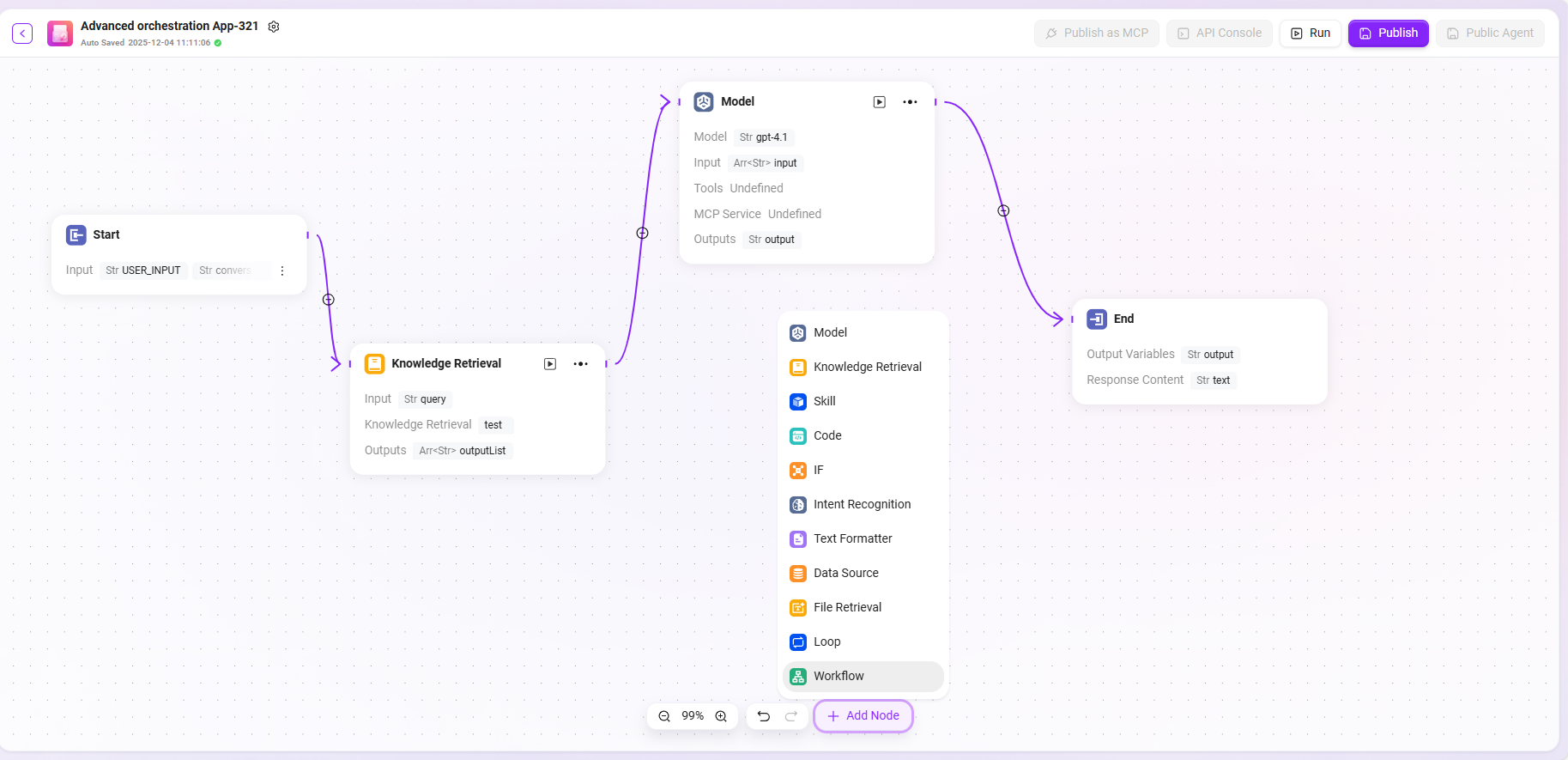
ユーザーの実際のビジネスロジックに基づき、以下のノードをドラッグ&ドロップおよび接続してワークフローを構成します:
- 開始・終了:標準搭載の入出力モジュールで、入出力パラメータやフィールドをカスタマイズ可能です。
- モデル:このモジュールで使用するモデルを選択し、他のモジュールから取得した変数を入力し、プロンプトや出力メッセージを編集し、変数として保存します。
- ナレッジベース検索:選択したナレッジベース内で、入力変数に基づき最も一致する情報を呼び出して返します。
- スキル:いずれかのスキルを選択し、そのスキルを通じて入出力アクションを実行します。
- コード:他のモジュールの出力変数に基づき、カスタムコード関数を作成します。
- セレクター:設定した条件に基づきフロー分岐を判断し、ロジック判定を実現します。
- インテント認識:ユーザー入力のインテントを認識し、事前設定したインテントオプションとマッチングします。
- テキストフォーマッター:複数の文字列型変数のフォーマット処理に使用します。
- データソース:データソースを選択し、参照可能な変数内容を追加します。
- ファイル検索:アップロードされたファイル内を検索し、入力された質問に基づき関連する回答を探します。
- ループ:リスト内の各項目に対して一連のタスクを繰り返し実行し、並列処理も選択可能です。
ノード詳細説明
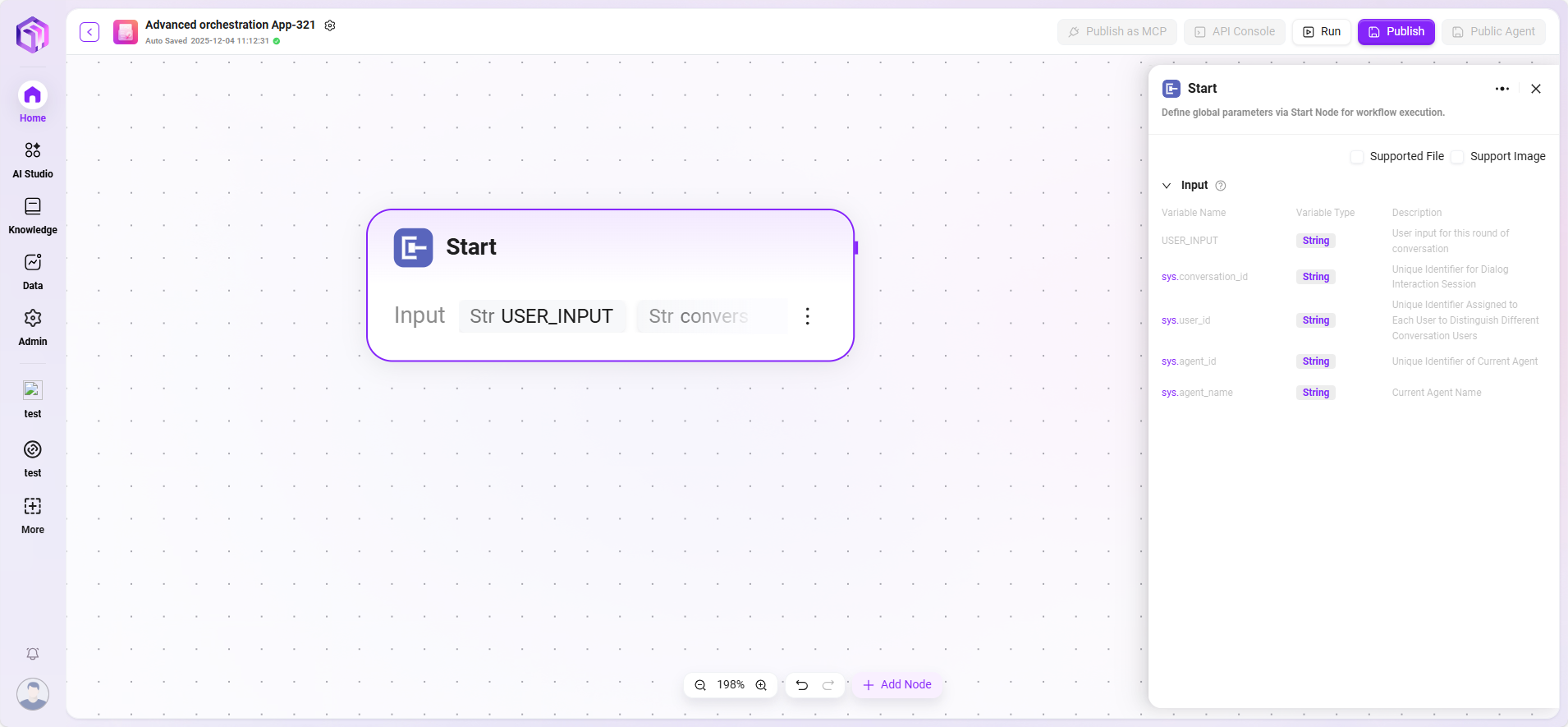
開始
開始ノードはワークフローの起点となり、ワークフロー開始に必要な情報を設定します。
- 機能:タスク完了に必要な基本情報(入力パラメータ)を事前設定します。トリガー条件を満たすと、システムがこれらのパラメータを自動収集し、フローを開始します。
- 処理ロジック:バイパス(By pass)で、入力内容をそのまま後続ノードに渡します。
- 出力:すべての入力内容。
- 特記事項(アプリケーションモード):このモードでは、開始ノードでファイルアップロード(PDF、Excel、画像など)や構造化データフィールドなど、複雑な入力タイプを定義でき、専門的なアプリ構築のために高度にカスタマイズされた入力インターフェースを提供します。
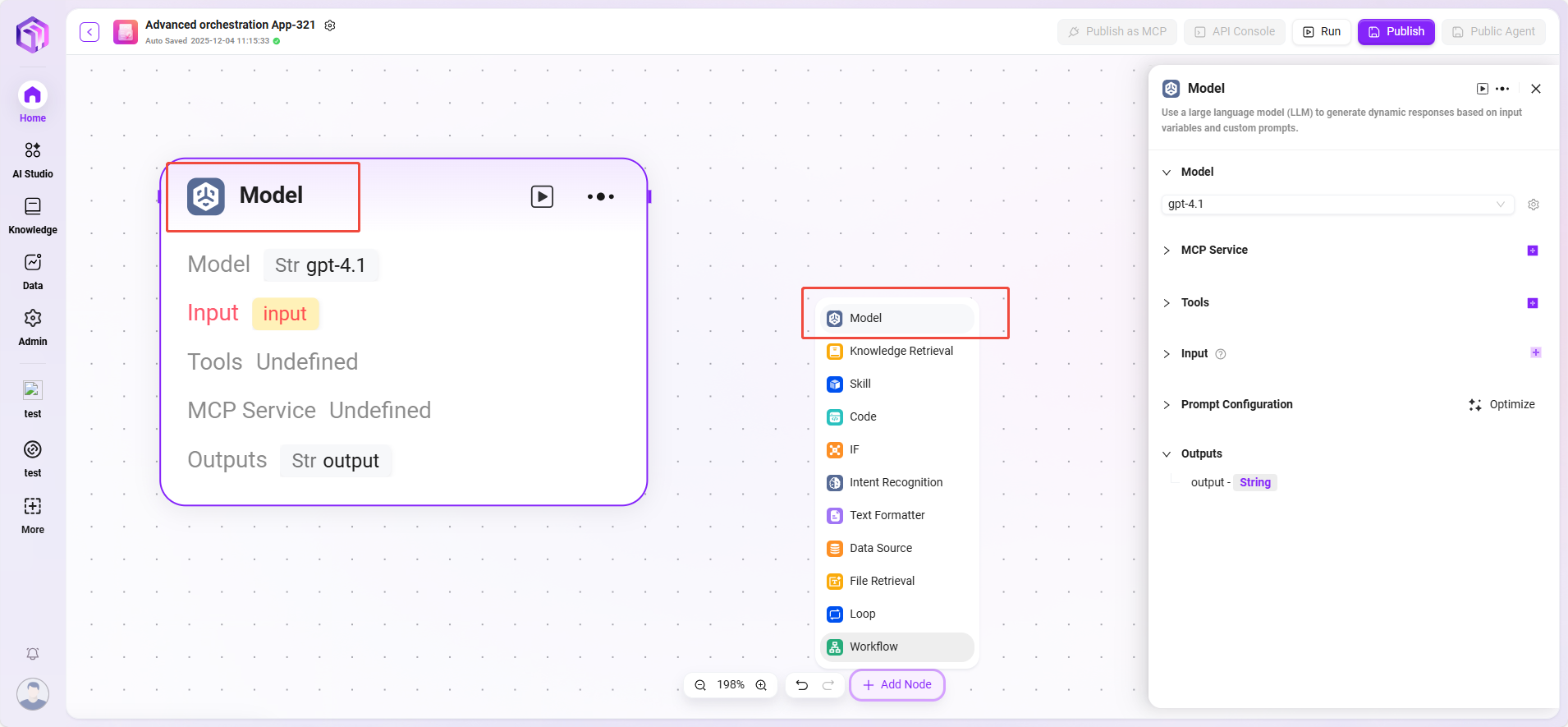
モデル
大規模言語モデルを呼び出し、変数やプロンプトを使って返信を生成します。
入力:既存モデルをプルダウンで選択し、入力変数名を選択します。 入力パラメータ:query(String、上流またはユーザー入力)。 設定パラメータ:
- 1つ以上のTools
- Model
- GPT(GPTまたは他のモデル)
- Temperature:創造性を制御し、値が高いほど回答が創造的かつランダムになります。
- Top P:「確率しきい値」により選択される単語範囲を制限し、回答の多様性を制御します。
- Max Reply Length:AIが一度に返信できる最大文字数を制限します。
- Syatem Prompt:AIへの隠し指示で、全体のスタイルを制御します。
- User Prompt:ユーザーが入力した内容や質問。
- History:過去の対話履歴で、コンテキスト理解を維持します。
- 処理ロジック:入力を大規模言語モデル(LLM)に渡し、設定に基づいて回答を生成します。
- 出力結果:モデルが生成したテキスト内容。
💡 ヒント:前段ノードと接続してから、他ノードの変数を現在ノードの入力として選択できます。
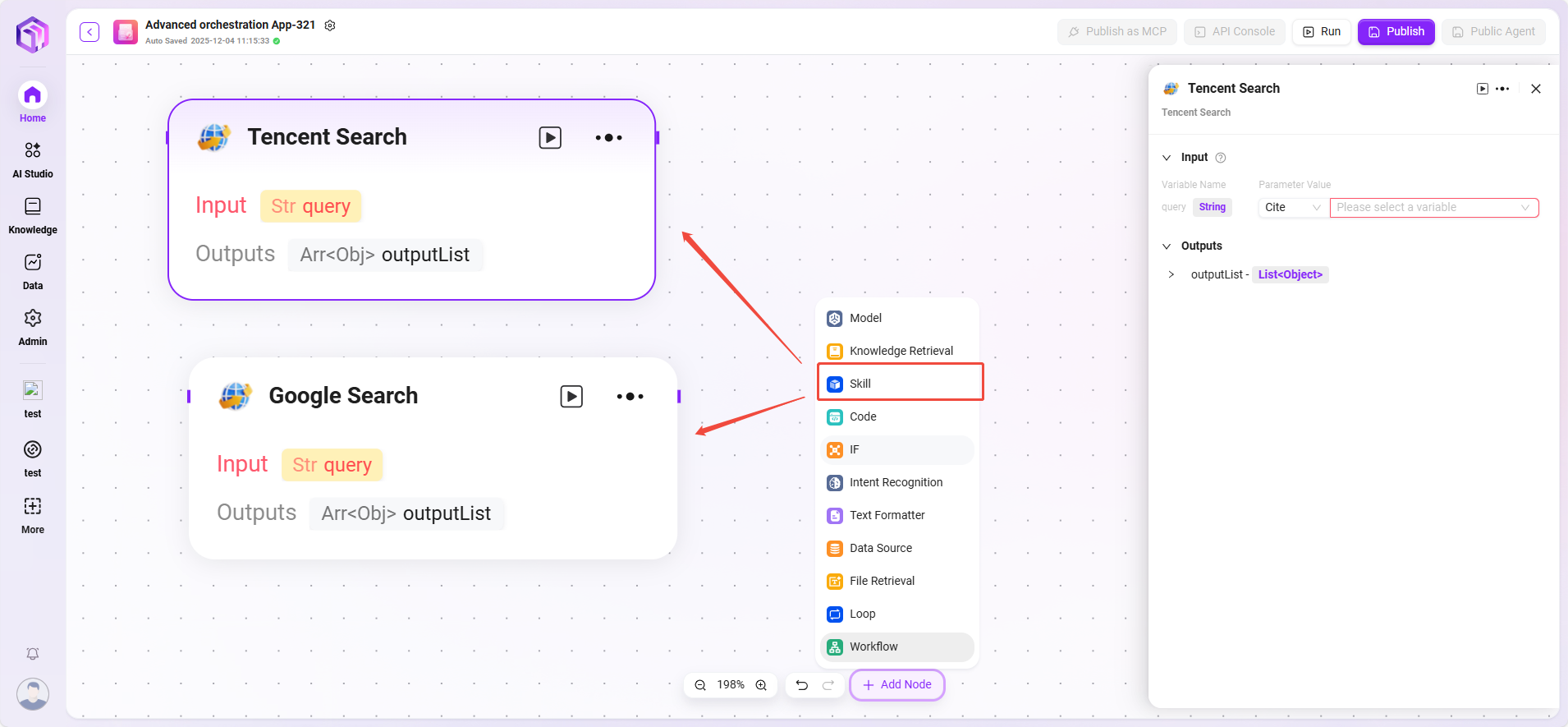
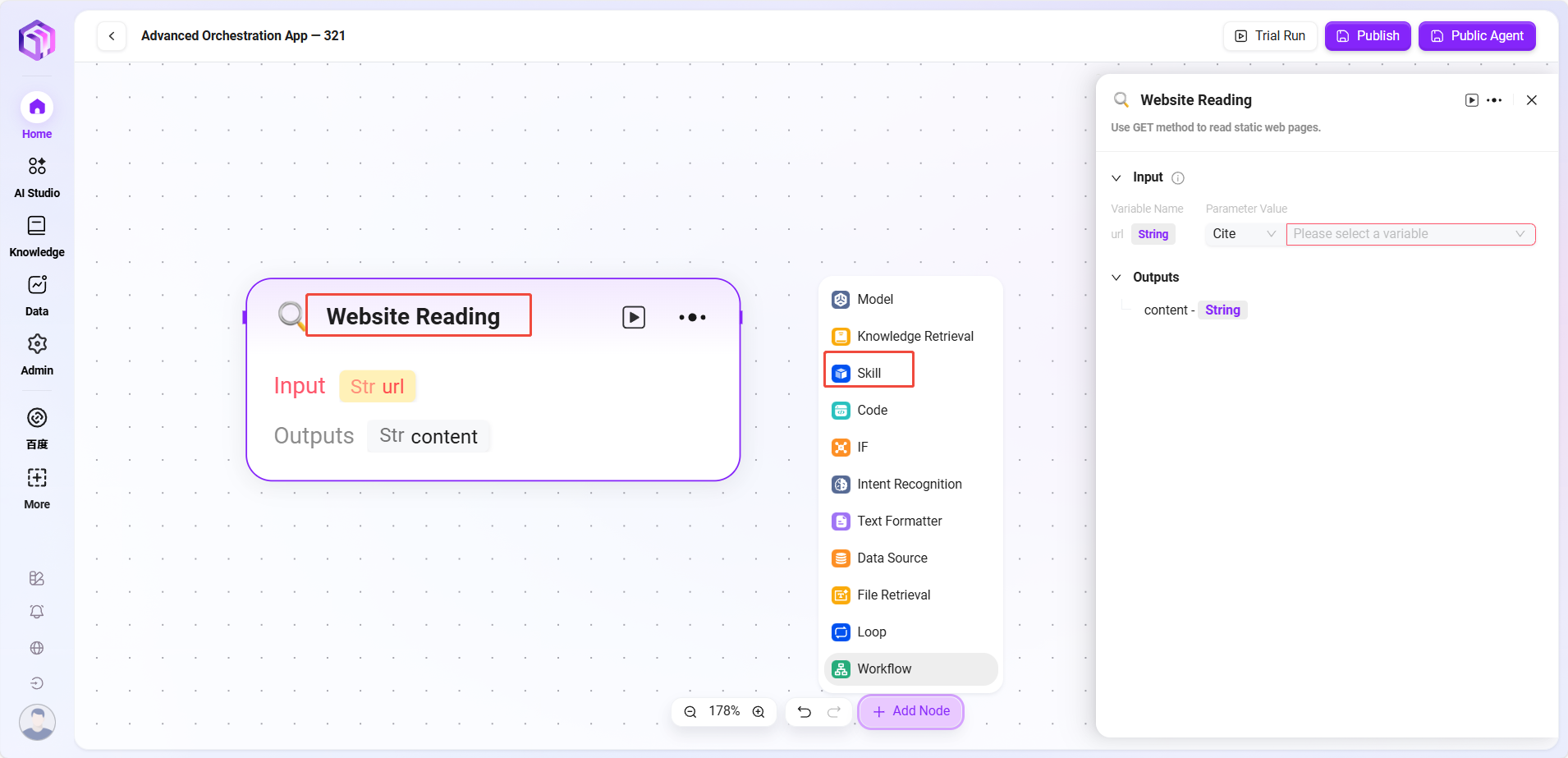
スキル(例)
- ウェブサイトリーディング:ウェブページ上の静的テキストを読み取ることができます(動的ロードされた内容は見えません)。
- テキストから画像生成:記述テキストに基づき画像を生成し、画像アドレスを返します。
- テンセント検索:検索エンジンを呼び出して検索結果を返します。
💡 ヒント:高度なオーケストレーションモードでは、スキルの追加は組み込みスキルのみ可能で、カスタムスキルは追加できません。
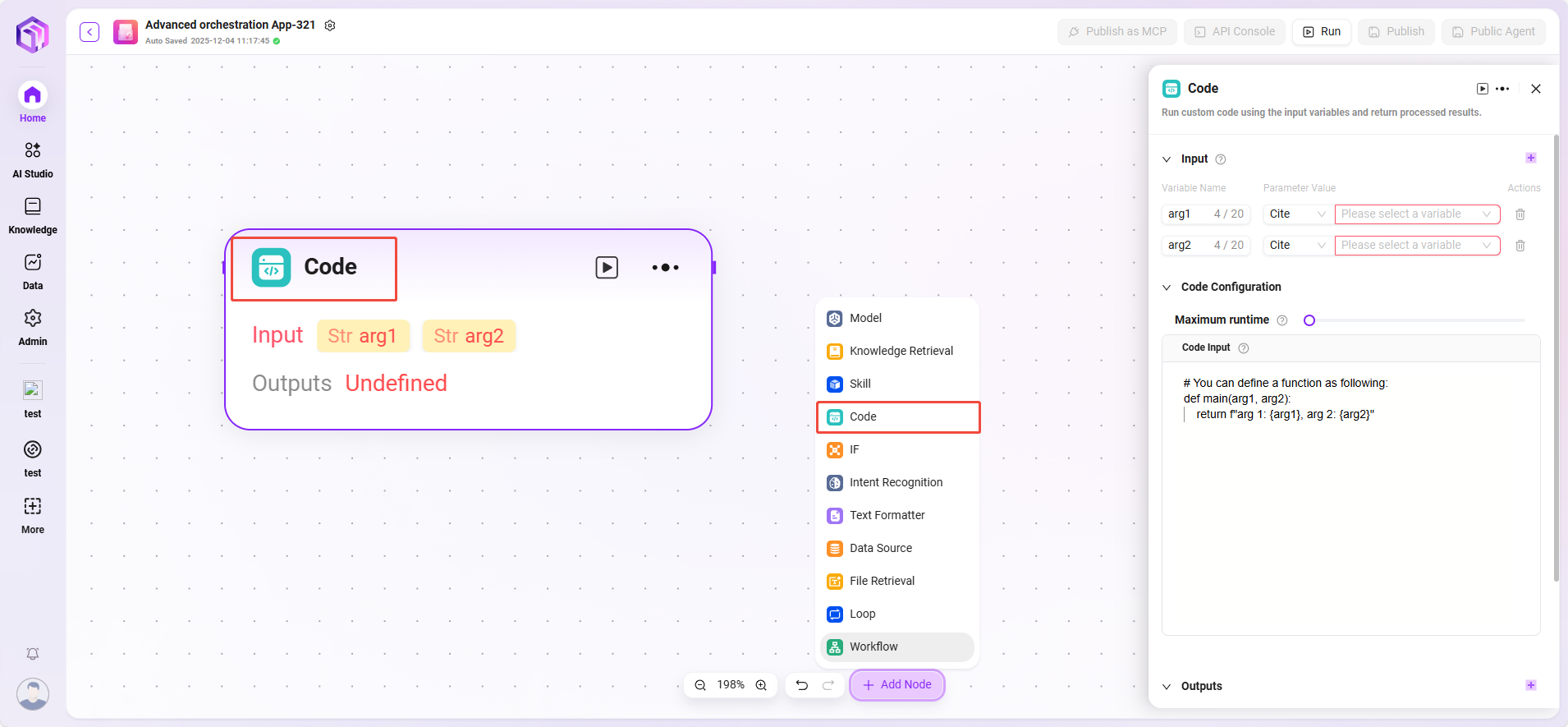
コード
コードを記述し、入力変数を処理して戻り値を生成します。
- 入力:外部から渡された変数を受け取り、コード実行に必要なデータの入口となり、後続のコード処理に原始データを提供します。
- 入力パラメータ:query(string、ユーザーまたは上流から渡されたコードリクエスト)。
- 設定パラメータ:コード実行に関するパラメータを設定します。
- 最大実行時間(Maximum Runtime)
- コード内容(Code Input)
- 処理ロジック:
- セキュアなサンドボックス環境でコードを実行します(RestrictedPythonまたは指定プラットフォームベース)。
- 実行時間とアクセス権限を制限し、セキュリティリスクを回避します。
- 出力結果:コードが入力データを処理した後、結果を指定変数として出力します。これがコード処理結果の出口です。
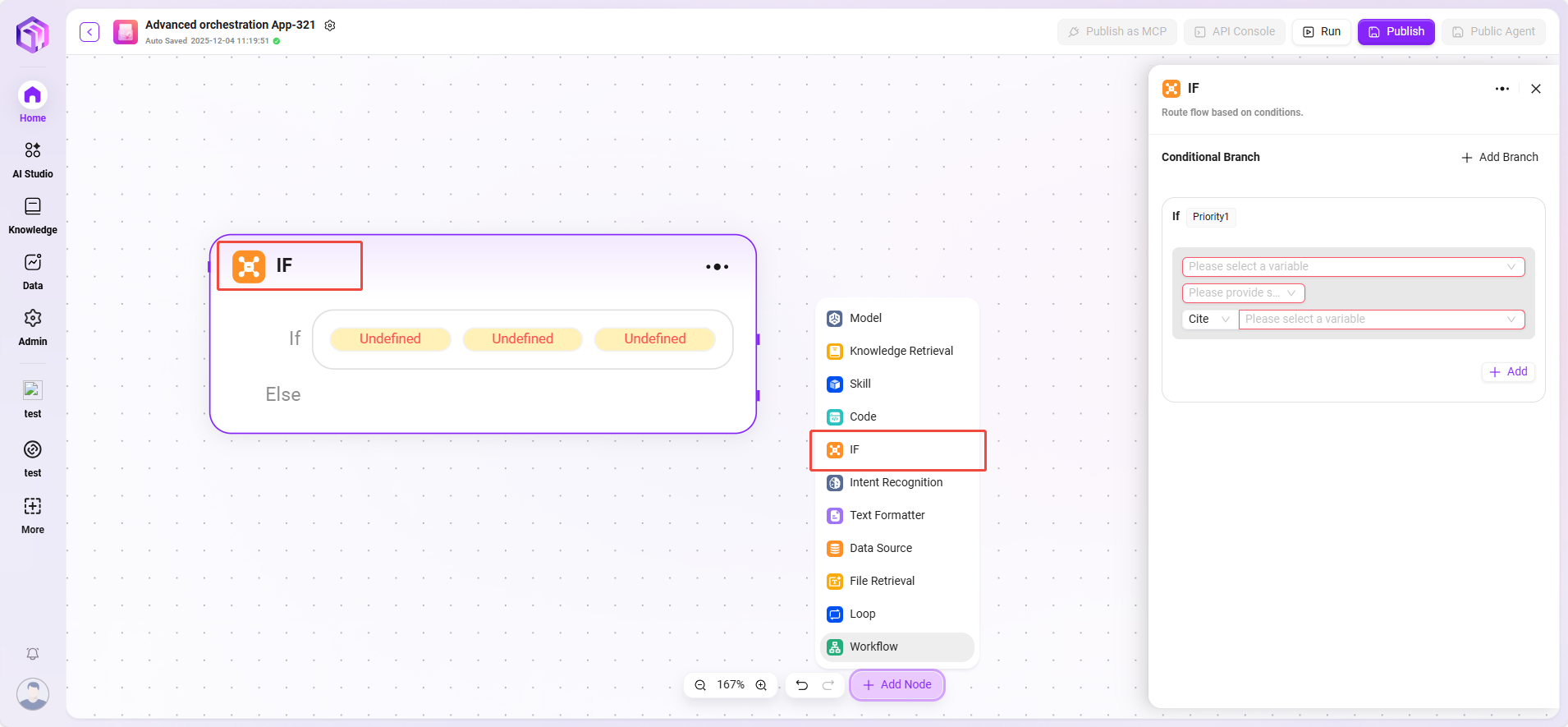
セレクター
フローオーケストレーションで条件分岐の役割を果たします。複数の下流分岐を接続し、設定した条件により実行パスを決定します。
- 条件分岐:複数の条件(例:「if - 優先度1」)を設定可能です。変数参照、条件選択(等しい、大きいなどの比較ロジック)、比較値を設定し、条件成立時に対応する分岐フローを実行します。
- 処理ロジック:異なる条件により異なるパスを進みます(条件を満たさない場合はElseに進みます)。
- 出力結果:直接の出力はなく、次のノードの進行方向のみを決定します。
インテント認識
インテント認識は自然言語処理の重要なステップで、このモジュールはユーザー入力内容を分析し、真の意図を特定し、事前設定したオプションとマッチングします。
- モデル:インテント認識に使用するモデルを選択します。モデルにより認識能力と効果が決まります。
- インテントマッチング:ユーザーインテントの説明を事前に入力してマッチ基準とすることも、他のインテントを追加することもできます。システムはこれに基づき、ユーザー入力がどのプリセットインテントに合致するかを判断します。
- 高度な設定:システムプロンプト内容を設定でき、入力変数を参照してプロンプト効果を最適化できます。また、履歴記憶数を設定し、モデルが過去の対話情報を参照して認識精度を向上させます。
- 処理ロジック:ユーザーの真の意図を判断し、入力を対応するカテゴリに分類します。
ナレッジベース検索
- 入力:変数名を定義し、パラメータ値を設定することで、ナレッジベース検索に検索キーワードなどの原始データを提供します。
- 処理ロジック:入力とパラメータに基づきナレッジベースを検索し、フラグメントやFAQを返します。
- ナレッジベース:特定のナレッジベースを検索範囲として選択し、その範囲内で一致する情報を探します。
- 最大リコール数:ナレッジベースから最大で返す一致結果数を設定でき、データの過剰返却を防ぎます。
- 出力:ナレッジベースから検索した一致情報を指定変数として出力し、後続フローで利用します。
テキストフォーマッター
主に文字列型変数のフォーマット処理に使用します。
- 入力:変数名を定義し、参照方式でパラメータ値を取得し、後続のテキスト処理に原始文字列データを提供します。
- 処理ロジック:テキストを簡単に加工します。
- 文字列の連結
- 文字列の分割
- 文字列連結:テキスト編集エリアを提供し、必要に応じて変数名方式で入力変数を参照し、複数の文字列を連結するなどのフォーマット処理を行います。
ファイル検索
ファイル検索はファイル内容の検索などの操作を行う機能モジュールです。
- 入力:変数名を定義し、パラメータ値を参照して検索キーワードなどの入力情報を提供し、ファイル内容検索の根拠とします。
- ファイル:このノードに処理対象ファイルを追加でき、検索するファイル範囲を決定します。
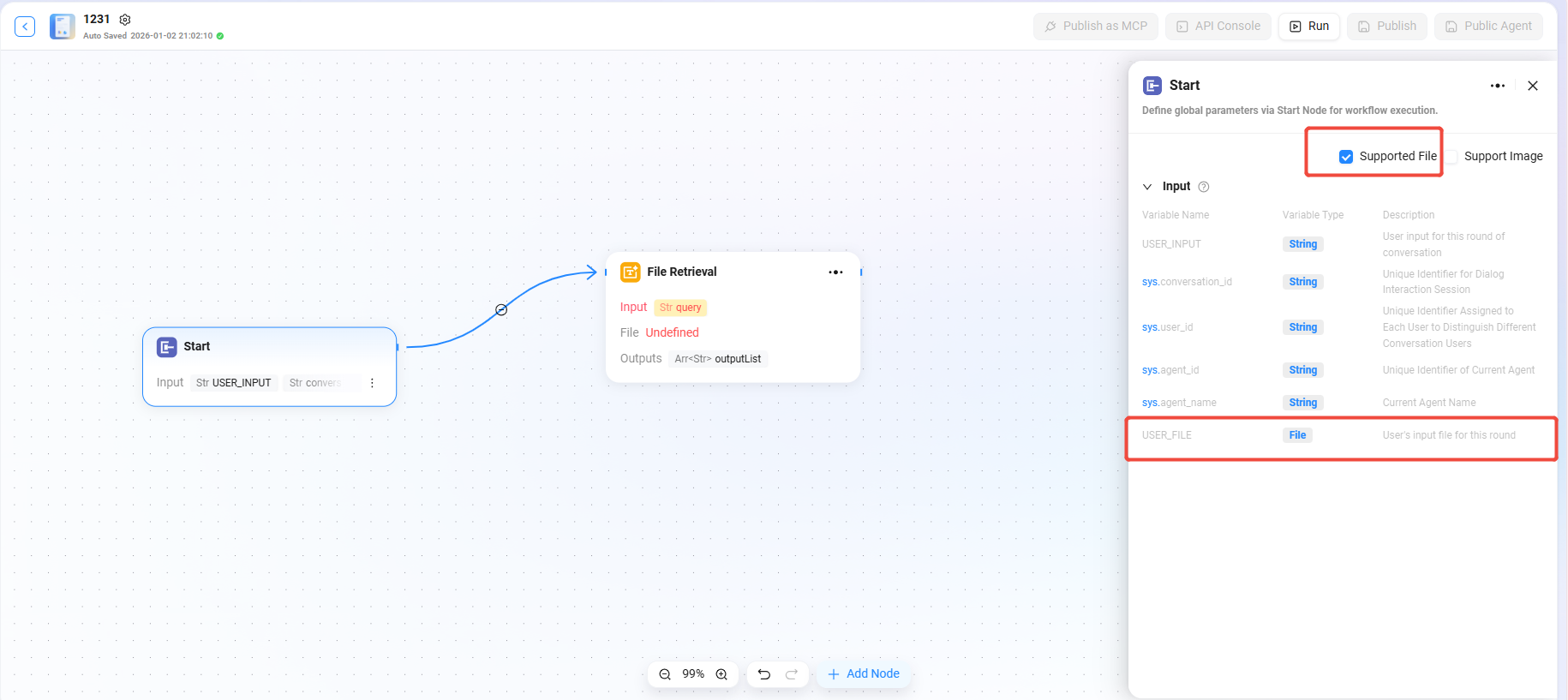
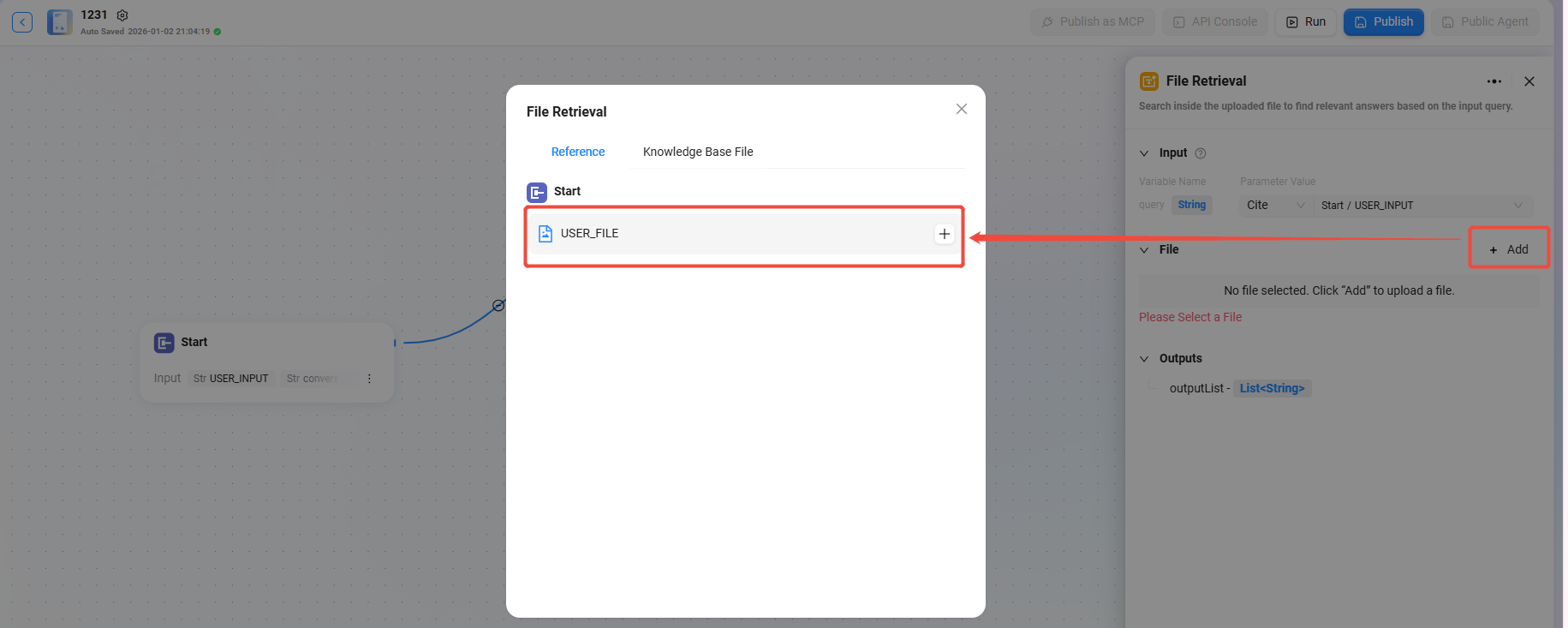
設定ファイルの検索
- まず、「開始」ノードで「ファイルをサポート」にチェックを入れる必要があります
- チェック後、開始ノードに「USER_FILE」という変数が表示されます。これはユーザーがこのターンで入力したファイルを指します
- 次に、「開始」ノードと「ファイル検索」ノードを接続します
- 接続後、ファイル検索ノードで「USER_FILE」を検索対象のファイルとして追加できます
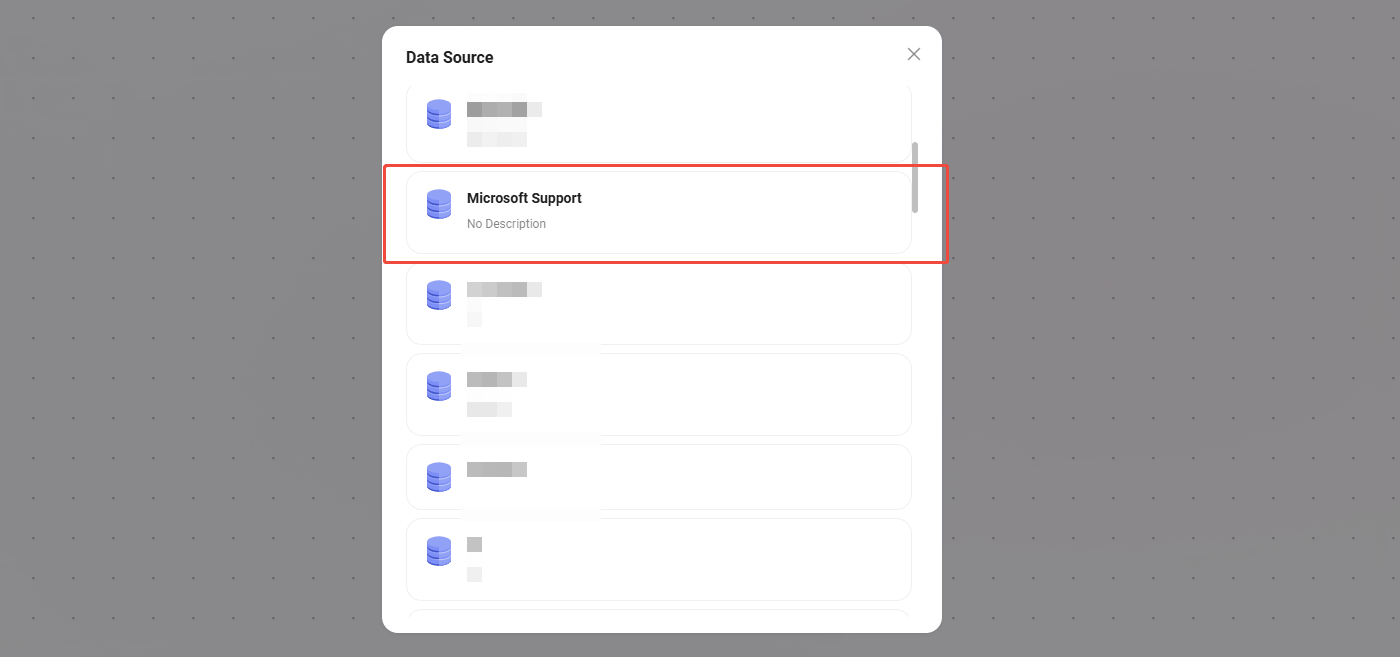
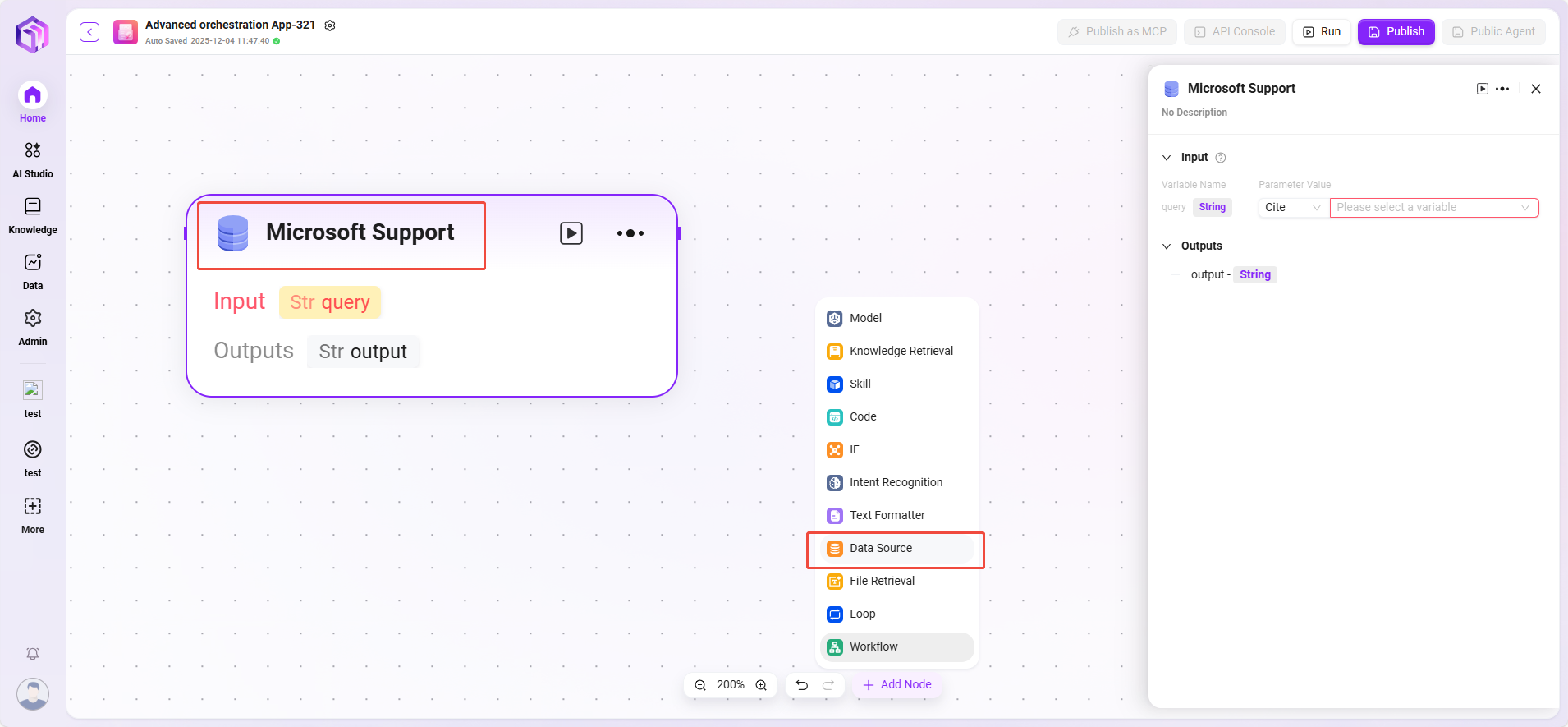
データソース
- データソース:接続するデータソースを選択します。
- 処理ロジック:自然言語をSQLに変換してデータベースを検索し、結果を返します。
- 出力:データソースのデータを出力し、次のノードに渡します。
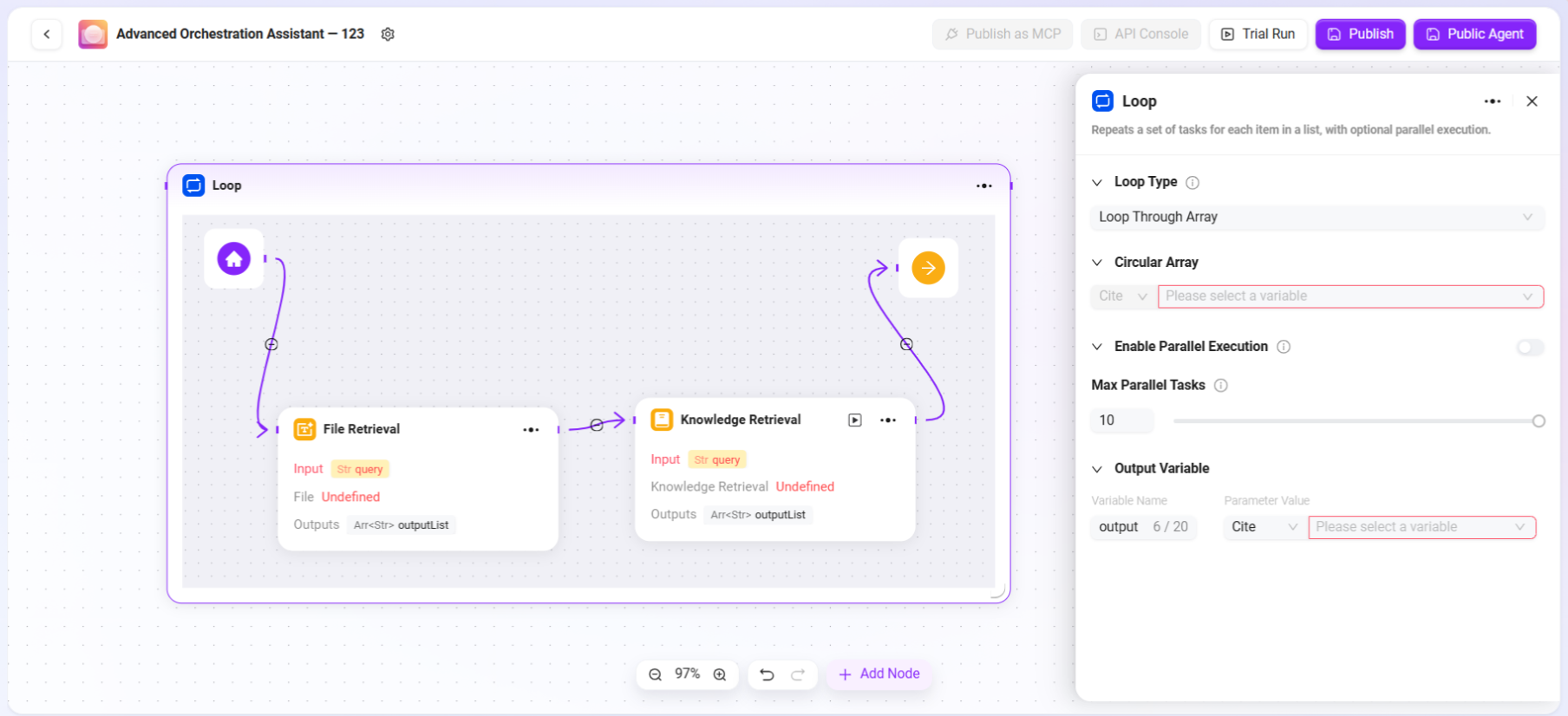
ループ
指定回数または指定データセットに従い、一連のタスクを繰り返し実行します。異なるループモードを設定することで、バッチ処理や繰り返し操作を柔軟に実現できます。
- ループタイプ:2つのモードをサポート
- 配列ループ:入力された配列に基づき、配列内の各要素に対して順次タスクを実行します。
- 数値ループ:設定した回数に従い、タスクをループ実行します。
- ループ数値/配列:
- 「数値ループ」を選択した場合、具体的な数字(例:2)を入力し、タスクが2回実行されることを意味します。
- 「配列ループ」を選択した場合、配列変数を提供し、システムが配列内の各要素を順次取り出してタスクを実行します。
- 並列実行:オプション機能です。有効にすると、システムが複数のループタスクを同時に処理し、効率を向上させます。最大並列数を設定してリソース消費を制御できます。
ワークフロー例
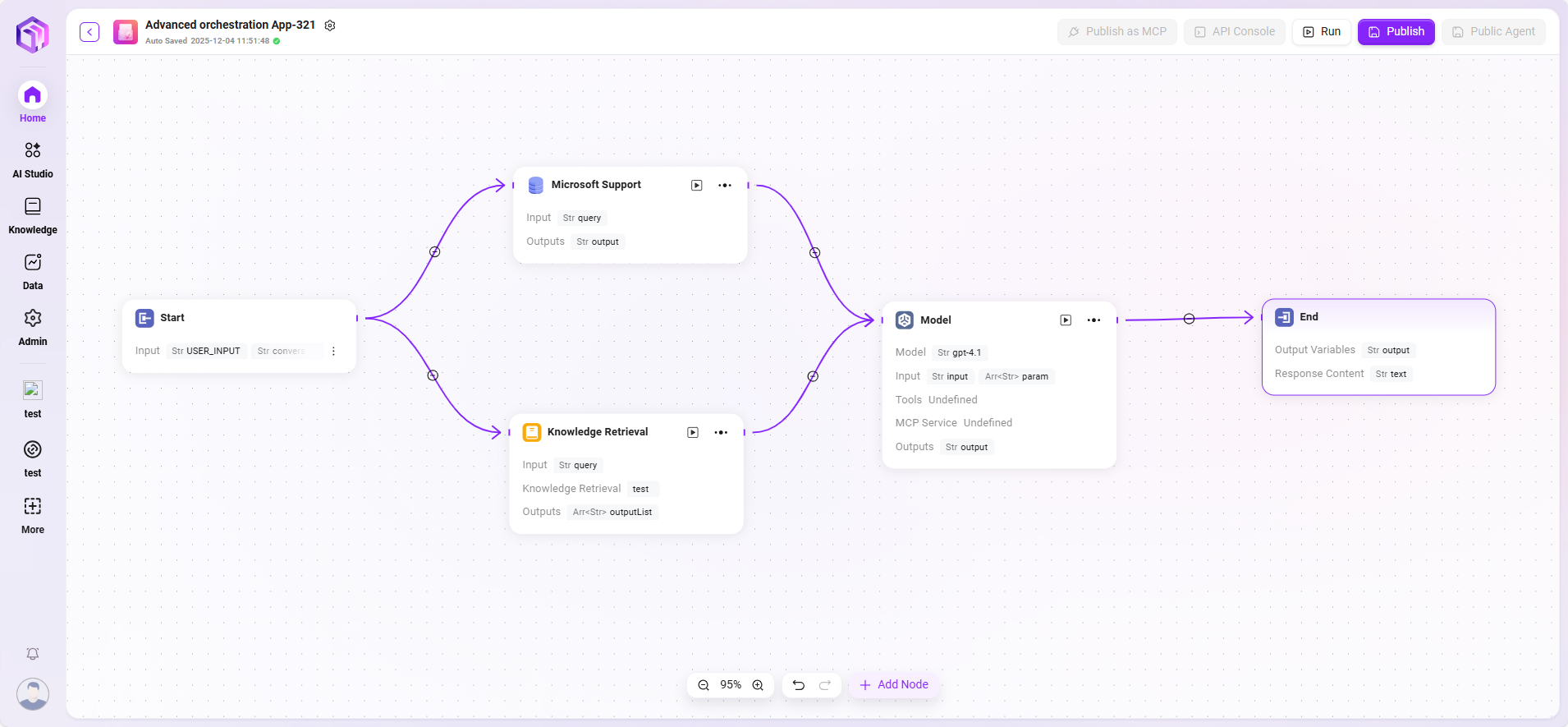
このシナリオでは、ワークフロー機能を使って「Microsoft Support Ticket Issue Analytics」の完全なフローを構築します。具体的なフローは以下の通りです:
- 開始ノード
フローの起点で、システムによりデフォルトで含まれています。 - データソースノード
チケット分析に必要な元データを接続します。 - ナレッジベースノード
分析参考資料を含むナレッジドキュメントを接続し、AI分析の理論的支えとします。 - モデルノード
AIモデルを基に、データソースとナレッジベース内容を組み合わせて総合分析を行い、チケット問題分析結果を生成します。 - 終了ノード
フローの終点で、モデルノードの分析結果を出力します。このノードもシステムによりデフォルトで含まれています。
データソースノードとナレッジベースノードは並列で構成され、モデルノードが両者の情報を集約処理し、出力結果にデータ的根拠と理論的支えを持たせます。
最終的な効果は以下の通りです:
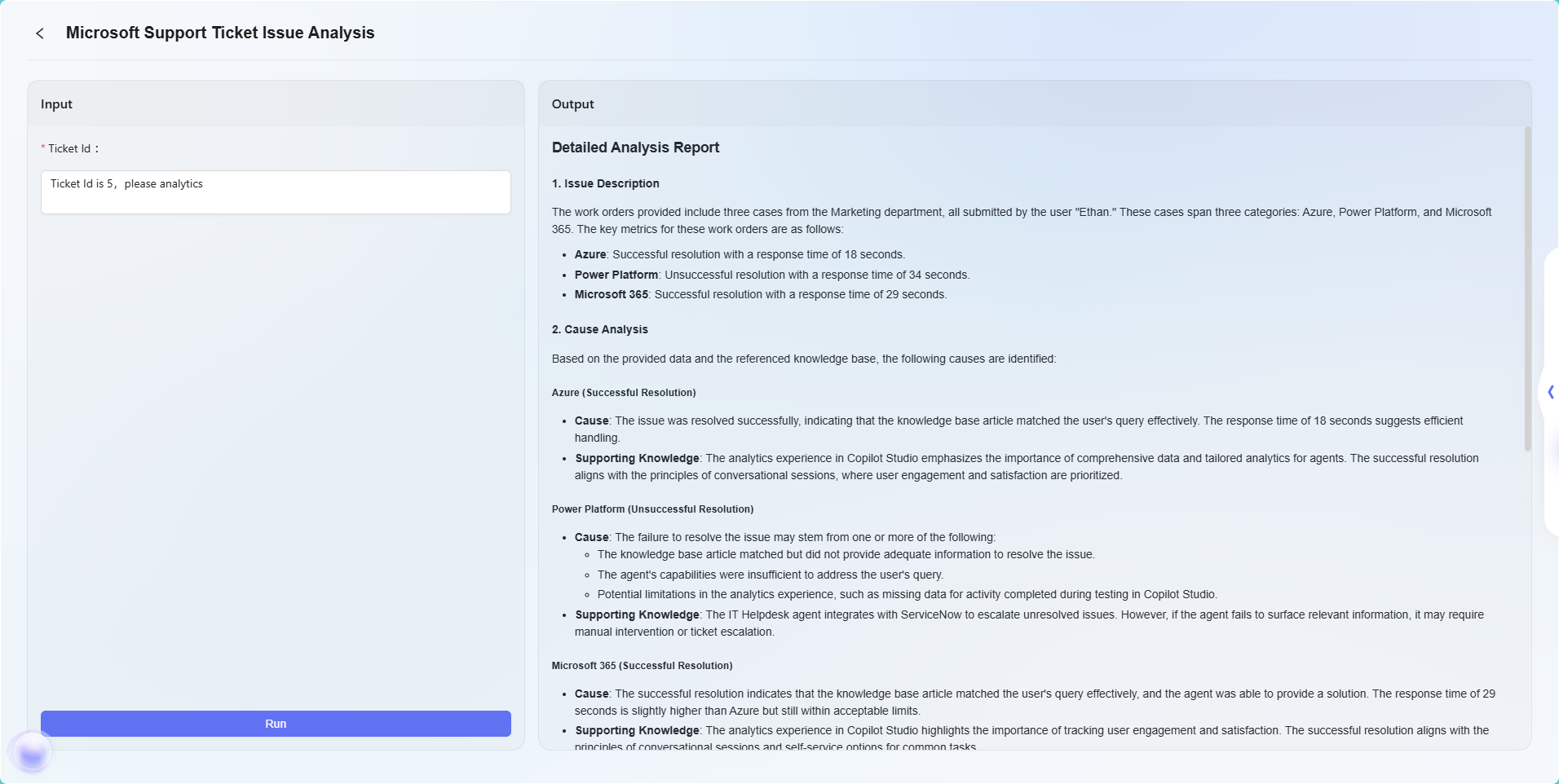
注:この例はワークフロー機能の基本的な応用デモです。ワークフローオーケストレーションは高い柔軟性と拡張性を持ち、各種ノードを組み合わせることで、非常に複雑なビジネスロジックや自動化フローを実現でき、幅広いビジネスシーンのニーズに対応可能です。