基本的なAgentの作成
エージェントタイプを選択
AI Asset ページの右上にある 「作成」 ボタンをクリックし、エージェントタイプとして 基本エージェント を選択します。
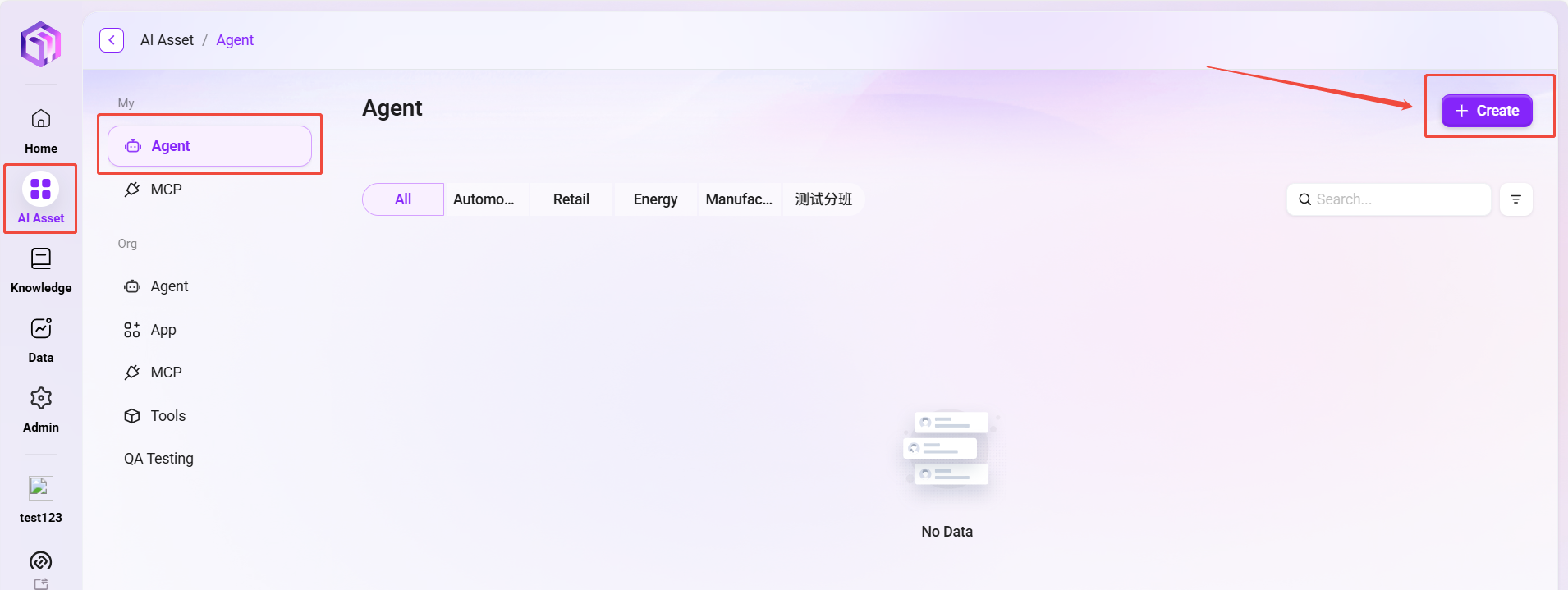
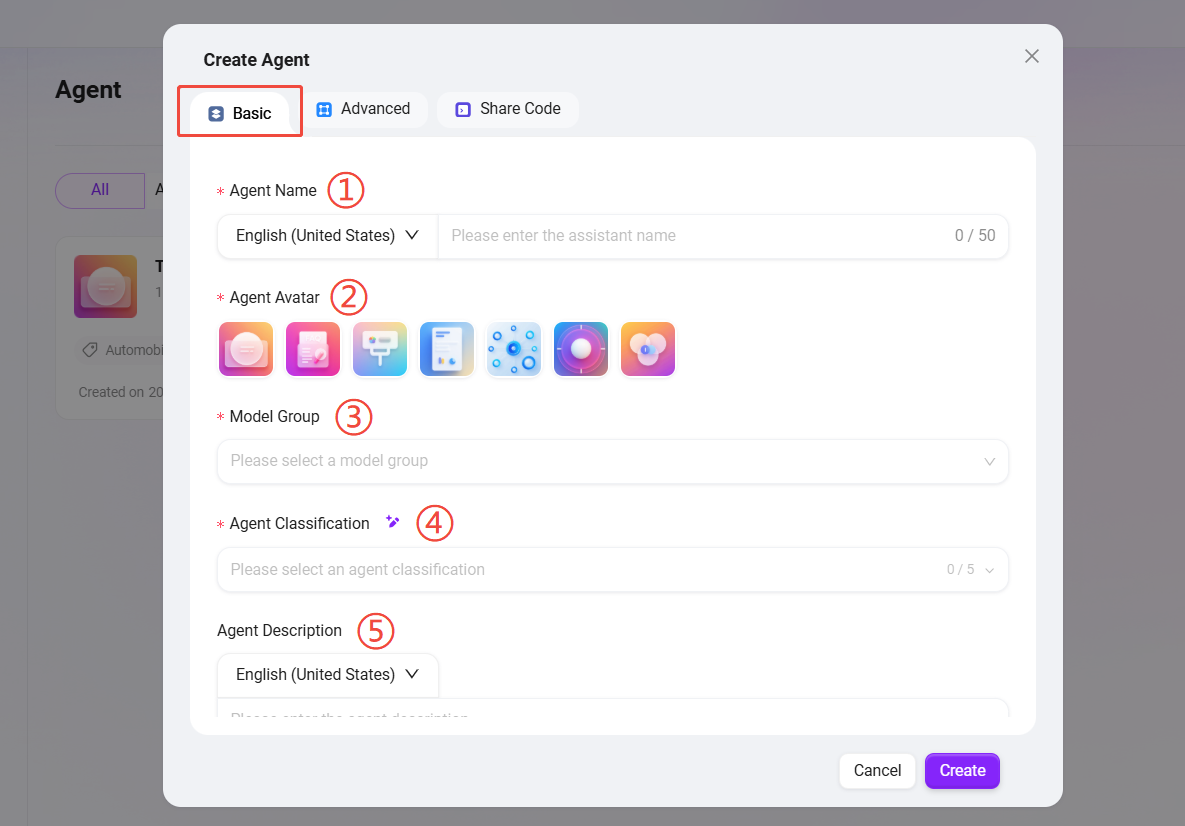
作成手順
作成ポップアップで、以下の基本情報を入力します:
① エージェント名:エージェントの名称を入力し、エージェントの識別子として使用します(50文字以内)。
② エージェントアイコン:システムのデフォルトアイコンから1つ選択します(現時点ではカスタムアイコンのアップロードは未対応)。
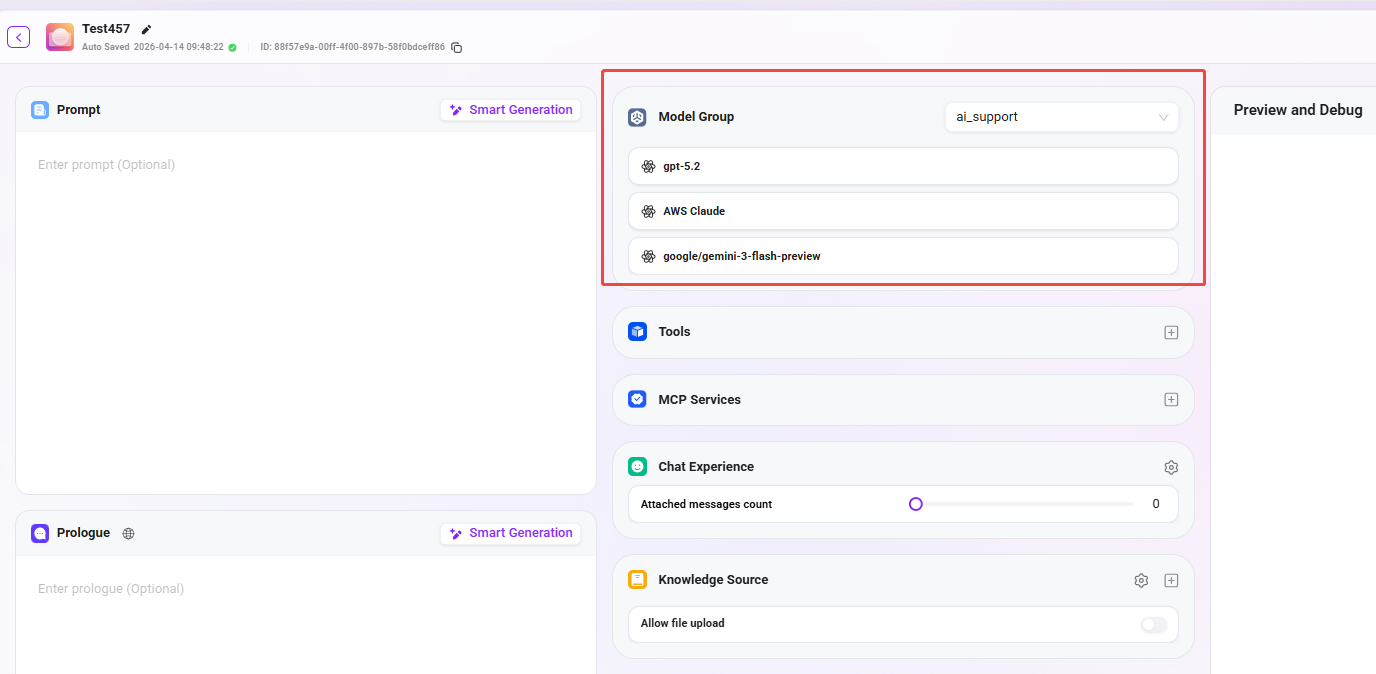
③ モデルグループ:エージェントに適切なモデルグループを設定します。
④ エージェント分類:新規作成するエージェントが属するグループを選択します(最大5つまで選択可能)。
⑤ エージェント説明:簡潔な説明を入力し、エージェントの機能と用途を示します。
「作成」をクリックすると、エージェント作成後に基本オーケストレーションエージェントの設定ページへ進み、設定と公開を完了すると利用可能になります。
💡 ヒント:ここでは国際化コンテンツのワンクリック補完機能を備えており、エージェント関連テキストの多言語翻訳適用をすばやく完了できます。対応言語:簡体字中国語、繁体字中国語、日本語、英語、ドイツ語、韓国語。
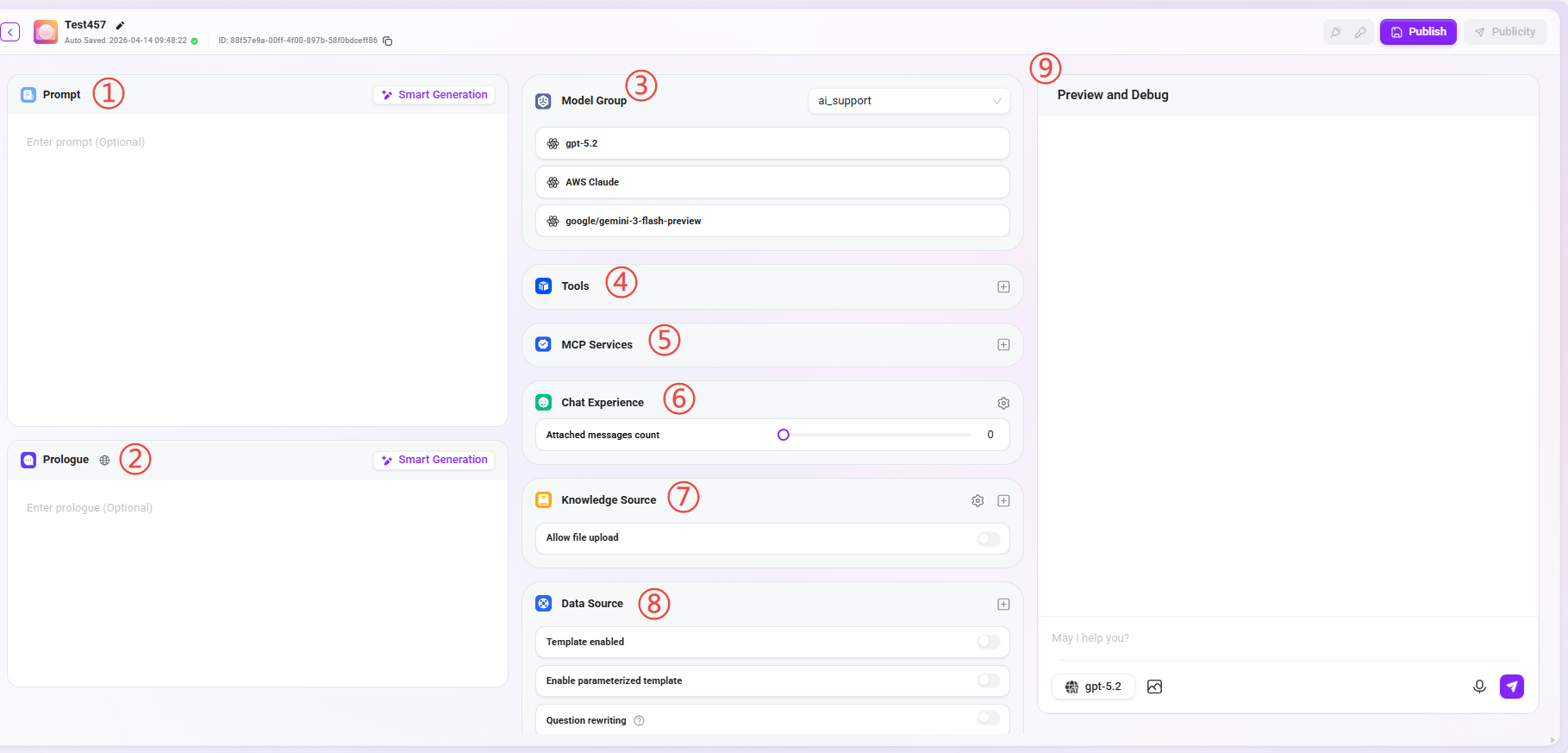
エージェント設定
設定ページに入る
以下の2つの方法でエージェントの詳細設定ページに入ることができます:
- 方法1:AI Asset で新しいエージェントを作成すると、システムが自動的にその設定ページへ移動します。
- 方法2:エージェント一覧で、対象エージェントのカードにマウスを重ね、表示される「✏️」アイコンをクリックすると、設定ページに入れます。
主要設定項目の説明
設定ページには以下の主要モジュールが含まれます:
① プロンプト:エージェントのプロンプトを入力します。既存のプロンプトからインテリジェント生成することも可能です。
② オープニングメッセージ:エージェントのオープニングメッセージを入力します。プロンプトまたは既存のオープニングメッセージに基づいてインテリジェント生成することも可能です。
💡 ヒント:プロンプトとオープニングメッセージの入力が約2000文字を超えると、システムは「入力内容が多すぎるため、効果に影響する可能性があります」と表示しますが、入力の継続は妨げません。最適な性能を確保するため、内容は簡潔に保つことを推奨します。
③ モデルグループ
- 機能:「+」をクリックして、設定済みのモデルグループをエージェントに追加または切り替えます。1つのモデルグループには複数の異なるAIモデルを含めることができます。
- 管理説明:モデルグループは、管理者が 「管理 > モデル管理 > モデルグループ」 で事前に作成・設定し、複数のモデルを同一グループに追加しておく必要があります。その後、ここでエージェントに割り当てて使用できます。
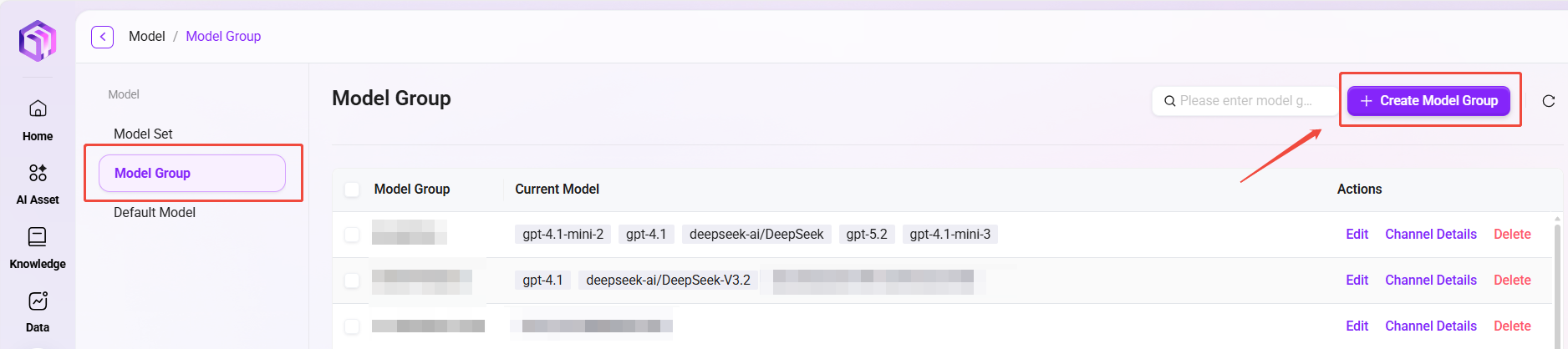
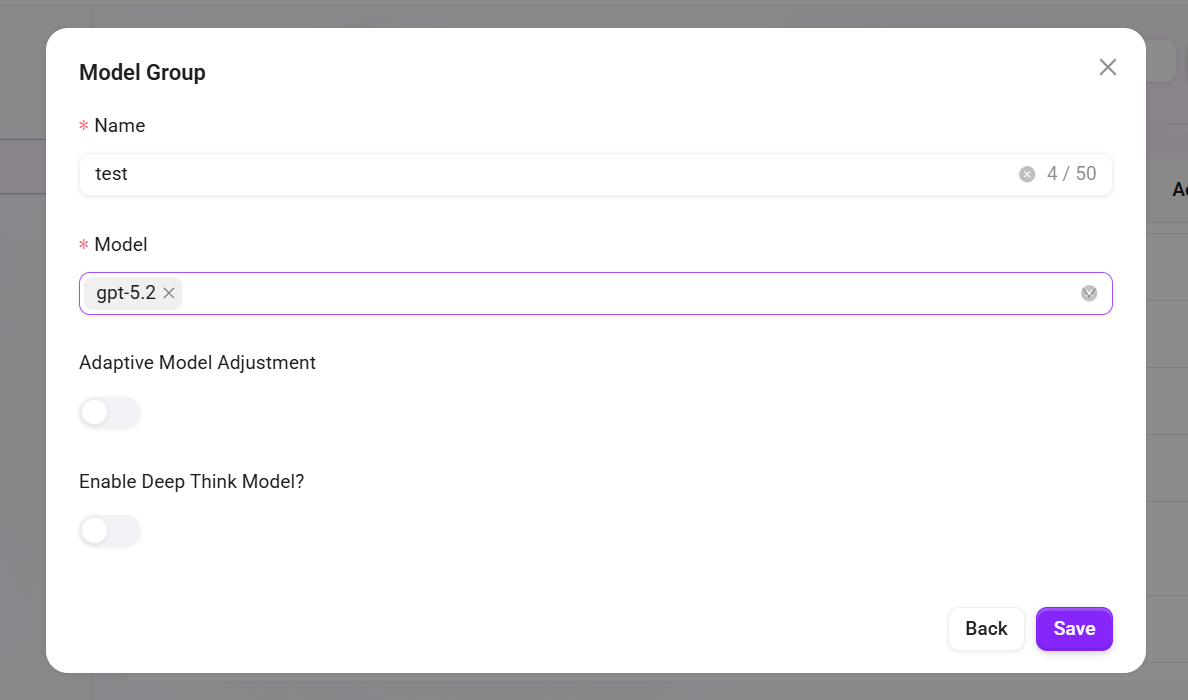
管理者によるモデルグループ追加手順:
- パスに移動:管理 → モデル管理 → モデルグループ。
- 「新規モデルグループ」 をクリックします。
- 以下の設定を完了します:
- モデルグループ名を入力します。
- このグループに追加するモデルをチェックします(複数選択可)。
- 「適応型モデルデプロイ」 を有効にするか選択します:有効化すると、トラフィックに応じて計算リソースを自動調整し、サービスの安定性とスムーズさを確保します。
- 「深い思考モデル」 を有効にするか選択します:有効化すると、複雑な問題に遭遇した際により強力なモデルをインテリジェントに呼び出し、回答品質を大幅に向上させます。
- 「保存」 をクリックします。

④ ツール
「+」をクリックして、1種類または複数のツールを追加します(最大20個まで追加可能)
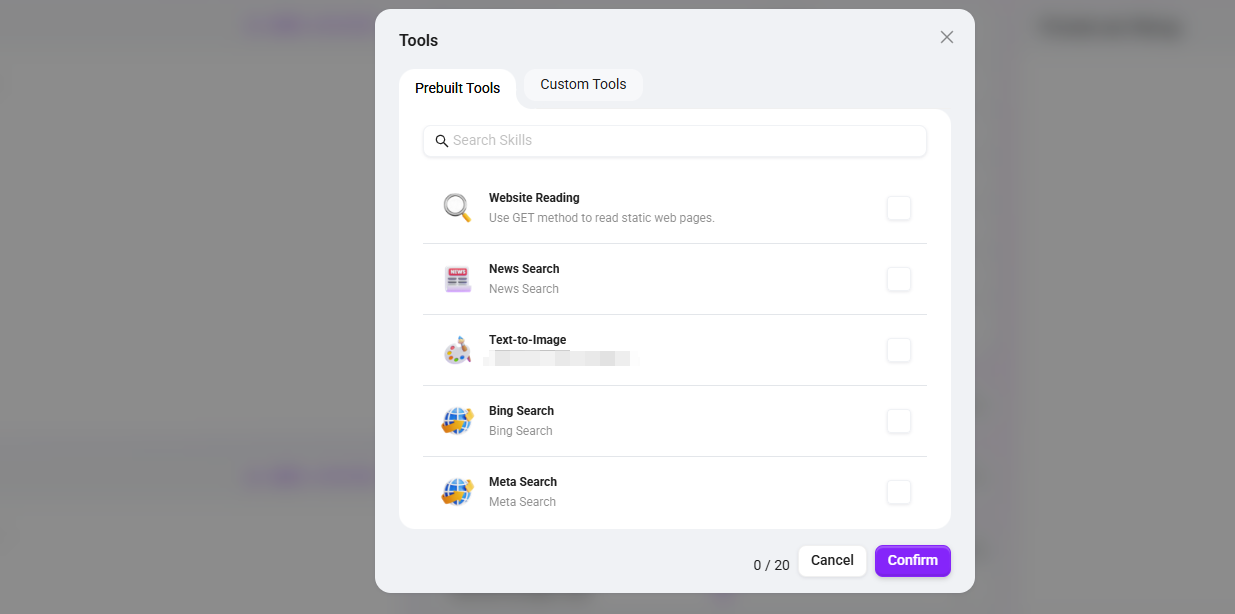
システムには8種類のツールが内蔵されています:Google 検索、G-Bing 検索、Bing 検索、Tencent 検索、Metaso 検索、テキストから画像生成、ニュース検索ツール、Webページ読み取り。
- Google検索:Google検索エンジンを通じてリアルタイムかつ正確なネットワーク情報を取得し、グローバル範囲のWebコンテンツ検索をサポートします。
- G-Bing検索:包括的なWeb検索機能を提供し、検索範囲の広さと結果の精度のバランスを取ります。
- Bing検索:Microsoft Bing検索エンジンを基盤とし、グローバルな多言語Webページ、画像、動画などの総合情報検索をサポートします。
- Tencent検索:Tencentの検索技術に基づき、中国語インターネット環境向けの検索サービスを提供し、特に中国語コンテンツの検索効果を最適化しています。
- 秘塔検索:高効率かつ高精度な検索サービスを提供し、ユーザーが必要とする重要情報をすばやく特定して返します。
- 文生図:テキスト記述に基づいて対応する画像コンテンツを自動生成し、文字によるアイデアを視覚表現へ変換します。
- ニュース検索ツール:各種ニュース情報を検索・取得するための専用ツールです。
- Webページ読み取り:Webページのテキスト、データなどの内容を抽出し、ページ情報を解析する機能です。
備考:その他のツールの追加にも対応しており、管理者がバックエンドで操作・設定します。
⑤ MCPサービス
MCPサービスは、エージェントに外部ツールおよびデータソース機能を接続するために使用されます。
- 機能:MCPサービス モジュールで「+」をクリックすると、サービス選択ページに入ります。
- サービス選択:設定済みの個人MCPまたは組織MCPから、接続したいサービスを選択できます。
- 機能の有効化:追加後、エージェントは対話中に対応するMCP機能を呼び出してタスクを完了できます。
- 設定の推奨:設定済みのMCPツール数が 5 個以上になると、システムが通知を表示します。高頻度かつ必要なサービスを優先的に残し、ツールが多すぎてコンテキストが長くなり、実行性能に影響することを避けることを推奨します。
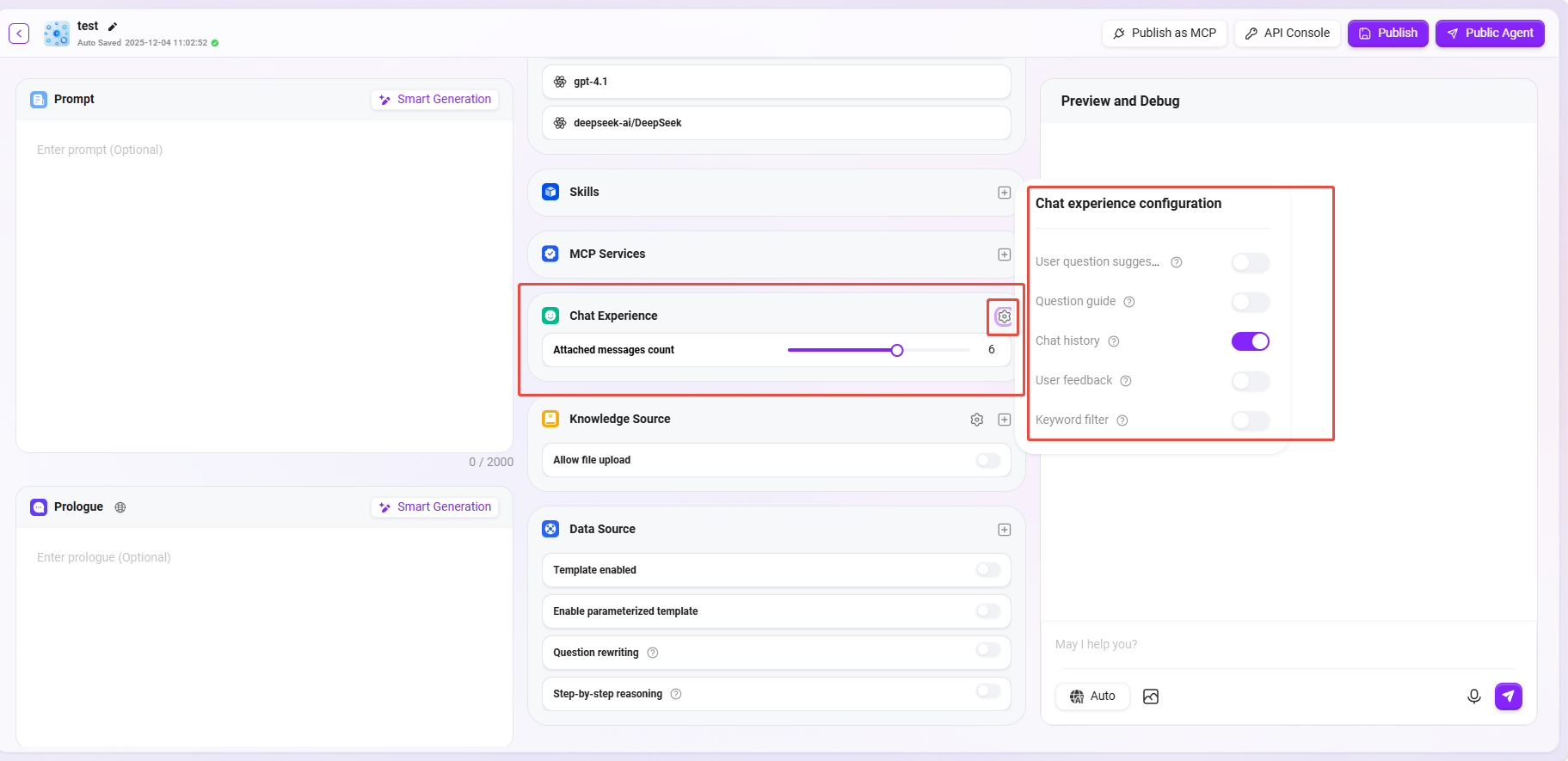
⑥ 対話体験
-
コンテキスト記憶件数: エージェントが記憶できる過去の対話ラウンド数を 1-10 件で設定します。対話の一貫性と性能のバランスを取るため、5件を推奨します。
-
対話設定:「ユーザー質問提案、質問ガイド、チャット履歴、チャットフィードバック、キーワードフィルタリング」などの設定を有効化できます。
- ユーザー質問提案:有効化すると、ユーザーの回答に基づき、コンテキストを組み合わせて提案型の質問ヒントを提示します。
- 質問ガイド:ユーザーがエージェントと対話する際、すでに入力された回答に基づいて、モデル機能を利用してユーザーが質問しそうな内容や質問の補完を推測します。
- チャット履歴:エージェントのチャット履歴を保存するかどうか。無効化すると、エージェントのチャット履歴を確認できなくなります。
- チャットフィードバック:エージェントの回答に対して、いいね・低評価などのインタラクションを行え、エージェント回答の最適化に利用されます。
- キーワードフィルタリング:機密コンテンツを自動的に遮断し、企業コンプライアンスとデータセキュリティを確保します。有効化すると、プロンプトおよび AI の返答結果の両方に対してセンシティブワード検出が行われ、センシティブワード辞書は事前にメンテナンス可能です。
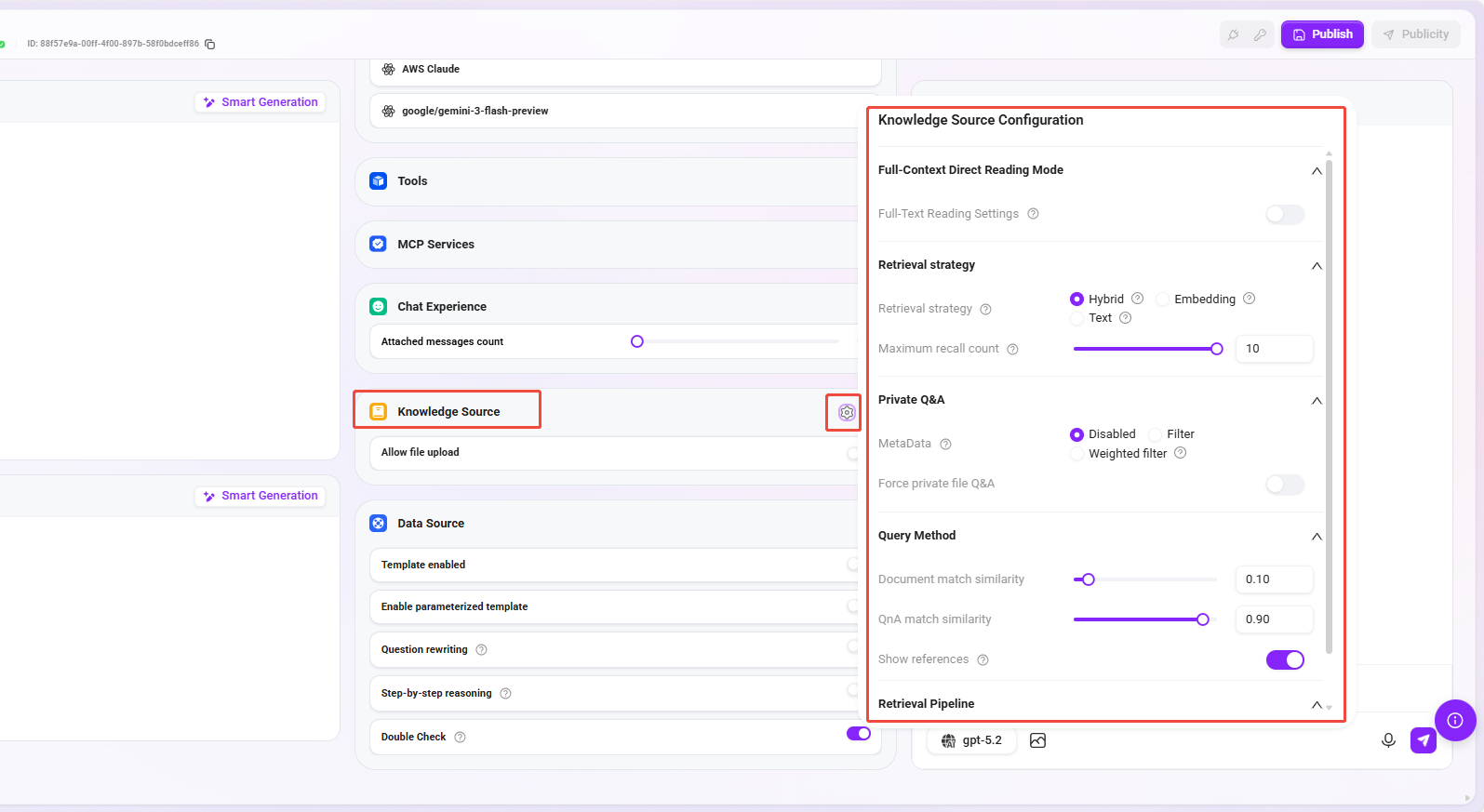
⑦ ナレッジベース
エージェントにナレッジを追加し、回答の正確性と制御性を向上させます。
-
ナレッジベース:「+」 をクリックしてナレッジベースを追加します。ナレッジソースとして最大 5 個まで追加できます。
-
ファイルアップロードを許可するか:
- ファイルアップロードを許可すると、ナレッジソースとしてナレッジベース内容を追加できなくなります。
- ファイルアップロードを許可しない場合、個人スペースまたは企業スペース内のナレッジベースをナレッジソースとして追加できます。
-
ナレッジベース設定:ナレッジベースの「検索戦略、プライベートドメインQ&A、検索方式」などのパラメータを詳細に設定できます。
1)フルコンテキスト直接読取モード:有効化すると、AI は検索された関連断片だけでなく、文書全体を読んで回答します。回答品質は向上しますが、より多くの tokens を消費します。
2)検索戦略:ナレッジ検索は、ナレッジベースから情報を取得する方法です。異なる検索戦略を採用することで、正しい情報をより効果的に特定でき、生成される回答の正確性と有用性を向上できます。
- ハイブリッド検索:全文検索とセマンティック検索の利点を融合し、結果を統合してランキングします。
- 埋め込み検索:ベクトルテキストの関連性に基づいて検索を行い、意味的関連の理解やクロスリンガル検索が必要なシナリオに推奨されます。
- テキスト検索:キーワード検索メカニズムに依存し、特定名称、略語、フレーズ、ID を含む検索シナリオに適しています。
- 最大リコール数:範囲は 1–10。高すぎても低すぎても推奨されず、推奨値は 3–5 です。
3)プライベートドメインQ&A
- メタデータフィルタリング(プレビュー):文書検索の過程でリコールされた断片をフィルタリングし、ノイズを減らしてデータ品質と処理効率を向上させます。
- プライベートドメインファイルQ&Aを強制:有効化すると、オンライン検索などのツールは使用されず、エージェントの回答はナレッジベース内容のみに基づきます。
4)検索方式
- 文書一致類似度:範囲は 0–1。数値が高いほど、リコールされた文書内容がクエリにより近いことを示します。推奨値は約 0.8(つまり 80%)です。
- Q&Aペア一致類似度:範囲は 0–1。文書内容の類似度一致と同様で、推奨値は約 0.9(つまり 90%)です。
- 参考文献を表示:有効化すると、エージェントは回答時に参照した文献を列挙し、回答の信頼性を高めます。この機能を無効化すると、ファイル断片の引用、特定ファイルの引用、およびファイルに基づく再質問などの機能は利用できなくなります。
5)検索 Pipeline
- カスタムPipeline:カスタム検索 Pipeline を追加して選択でき、業務要件に応じて検索フローを柔軟に設定し、より複雑なリコールシナリオに対応できます。
💡 ヒント:最大リコール数、文書一致類似度、QnA 一致類似度のいずれも、高ければ高いほど、または低ければ低いほど良いわけではありません。実際の要件に応じて設定することを推奨します。特別な要件がない場合は、デフォルト値のままで安定した効果が得られます。
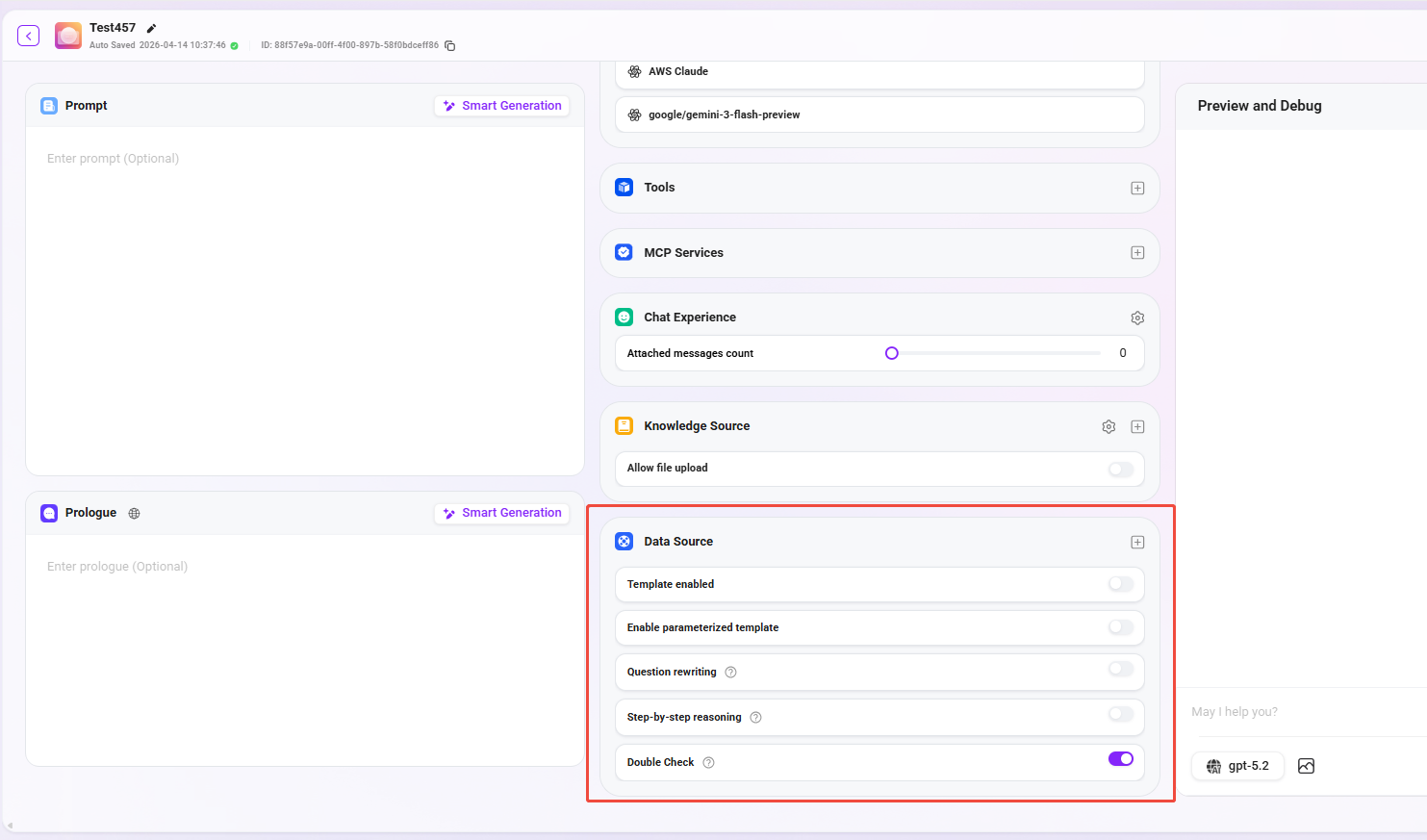
⑧ データソース
- データソース:「+」をクリックしてデータソースを追加し、エージェントのQ&Aデータソースとして使用します(最大5個まで追加可能)。
- テンプレートを有効にするか:自然言語と SQL の間の事前設定済みマッピングテンプレートを有効にするかを制御します。
- ユーザーが自然言語の質問を入力すると(例:「
先月の売上はいくらですか?」)、システムはまず事前設定済みテンプレートとの一致を試みます。 - 一致するテンプレートが見つかった場合(例:「
ある期間の売上を照会する」のような汎用質問)、テンプレート内の既存 SQL 構造 を参考にしつつ、具体的なフィールド名・テーブル名などを組み合わせて最終的なSQL文を生成します。
- ユーザーが自然言語の質問を入力すると(例:「
- パラメータ化テンプレートを有効にするか:有効化すると、テンプレートをベースにパラメータ化クエリを有効にし、クエリの柔軟性と安全性を高めます。
- 質問リライト:有効化すると、ユーザー入力の質問を自動的に最適化し、データ照会の正確性を確保します。
- ユーザーの元の質問:
売上を調べて(情報が不完全)。 - 質問リライト後:
2024年7月の全製品の総売上を照会する(時間と範囲が補完される)。
- ユーザーの元の質問:
- 段階的思考:この機能を有効にすると、最終的なクエリ結果を生成する前に、システムは詳細な思考ステップを出力し、どのように問題を分析してSQLクエリ文を構築したかを説明します。
- ステップ 1:キーワード「
2024年7月」「売上」を識別。 - ステップ 2:データテーブル
Orders、フィールドorder_dateとsales_amountを特定。 - ステップ 3:日付範囲条件
2024-07-01から2024-07-31を構築。 - ステップ 4:SQLを生成。
- ステップ 1:キーワード「
- 二次確認:有効化すると、モデルが生成されたSQLの正確性を検証します。現時点ではclaude系モデルには未対応です。
⑨ プレビューとデバッグ
- 機能:公開前に、ここでエージェントの対話テストを行えます。
- 操作:ユーザーはプレビュー対話ウィンドウに直接質問を入力し、設定中のエージェントとリアルタイムで対話して、プロンプト、ナレッジベース、スキルなどの設定が期待どおりかを検証できます。
- 目的:エージェントの動作が正確であることを確認してから公開し、設定ミスがユーザー体験に影響するのを防ぎます。
公開と利用
設定完了後、以下のオプションでエージェントの公開を完了できます:
- MCPとして公開:
 アイコンをクリックすると、エージェントを MCP サービスとして公開し、他のエージェントが接続・呼び出しできるようになります。
アイコンをクリックすると、エージェントを MCP サービスとして公開し、他のエージェントが接続・呼び出しできるようになります。 - API コンソール:
 アイコンをクリックすると、API コンソール に入り、既存の API チャネル名および API Key 数を確認でき、新規チャネル追加などの管理操作もサポートされます。
アイコンをクリックすると、API コンソール に入り、既存の API チャネル名および API Key 数を確認でき、新規チャネル追加などの管理操作もサポートされます。 - 公開:設定を確認し、プレビューとデバッグを通過した後、「公開」 をクリックして設定を保存すると、エージェントは正式に利用可能になります。
- Agentを公開:エージェントを組織エージェントライブラリに公開し、チームメンバーが共同で利用できるようにします。