モデル管理
モデルセットの新規作成
管理者は以下の手順で新しいモデルセットを作成できます:
-
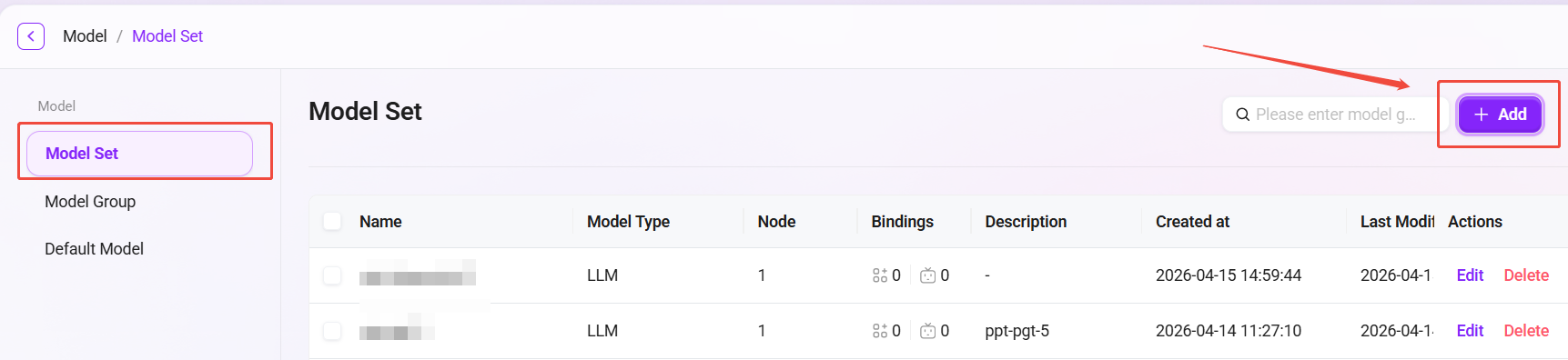
モデルセット管理ページへ移動:モデル管理に入り、その後「モデルセット」をクリックします。
-
「新規作成」をクリック:ページ右側の「新規作成」ボタンをクリックし、新しいモデルセットの作成を開始します。
-
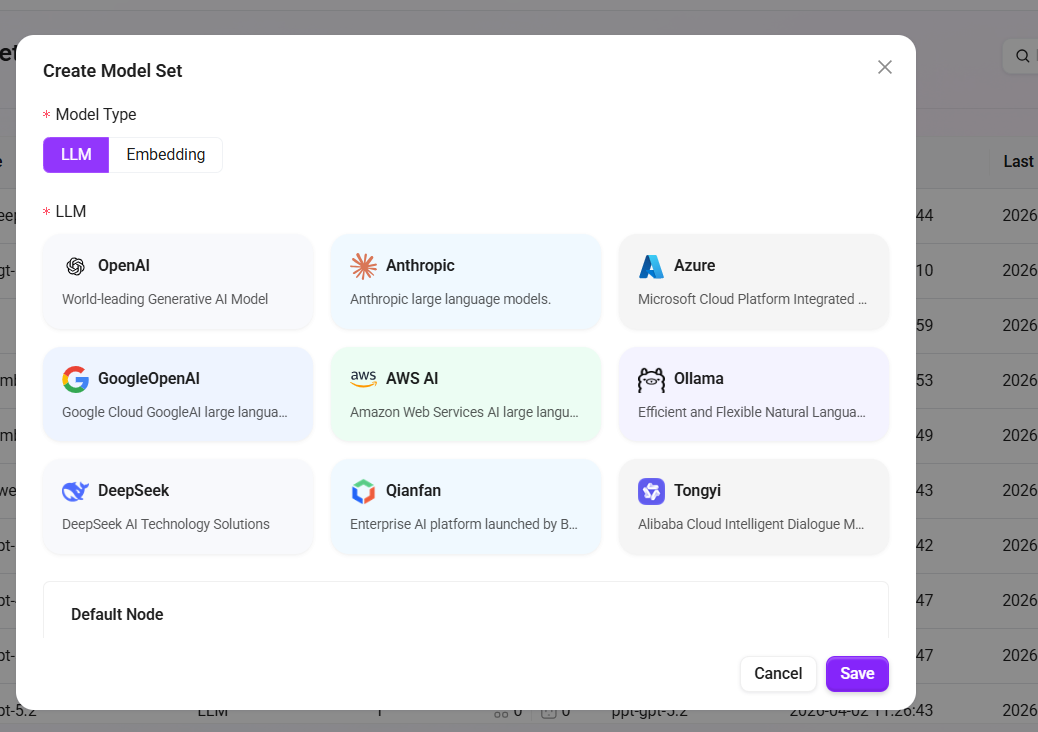
モデルタイプを選択:ポップアップウィンドウで、モデルのタイプを選択します。選択可能なタイプは以下のとおりです:
- LLM(大規模言語モデル)
- Embedding(埋め込みモデル)
⚠️ ヒント:V4.2バージョンでは複数のEmbeddingモデルの接続をサポートしています。
-
言語モデルを選択:要件に応じて、適切な言語モデルを選択します。現在サポートされている言語モデルは以下のとおりです:
- LLM言語モデル:OpenAI、Deepseek、Azure、Ollama、Tongyi、Qianfan、Anthropic、VertexAl、AWS AI;
- Embedding言語モデル:OpenA Embeddings、Azure Embeddings、AliEmbeddings、Ollama Embeddings、Amazon Bedrock Embeddings、VertexAlEmbeddings;
- モデルセット情報を入力:モデルセットの名称と説明を入力し、情報が明確かつ正確であることを確認してください(名称は50文字以内、説明は200文字以内)。
- 追加設定を選択:要件に応じて、画像Q&Aをサポートするか、および推論モデルとするかを選択します。
- 作成を確認:入力完了後、「確認」ボタンをクリックして、モデルセットの作成を完了します。
これらの手順により、管理者は新しいモデルセットを正常に作成し、対応する設定を構成できます。

Embeddingモデルを使用する際は、ベクトル次元の制限にご注意ください:
- PgSQL のベクトルフィールドは最大 2000 次元まで対応;
- Embedding モデルを購入する際は、その出力ベクトル次元が 2000 未満であることを確認してください(モデルによっては設定で調整可能です);
- システムでベクトルモデルを追加する際は、2000 未満のベクトル次元値を入力してください。そうしないと、保存異常やインデックス作成失敗の原因となる可能性があります。
- Tokenコンテキスト制限は 8192 を推奨します。
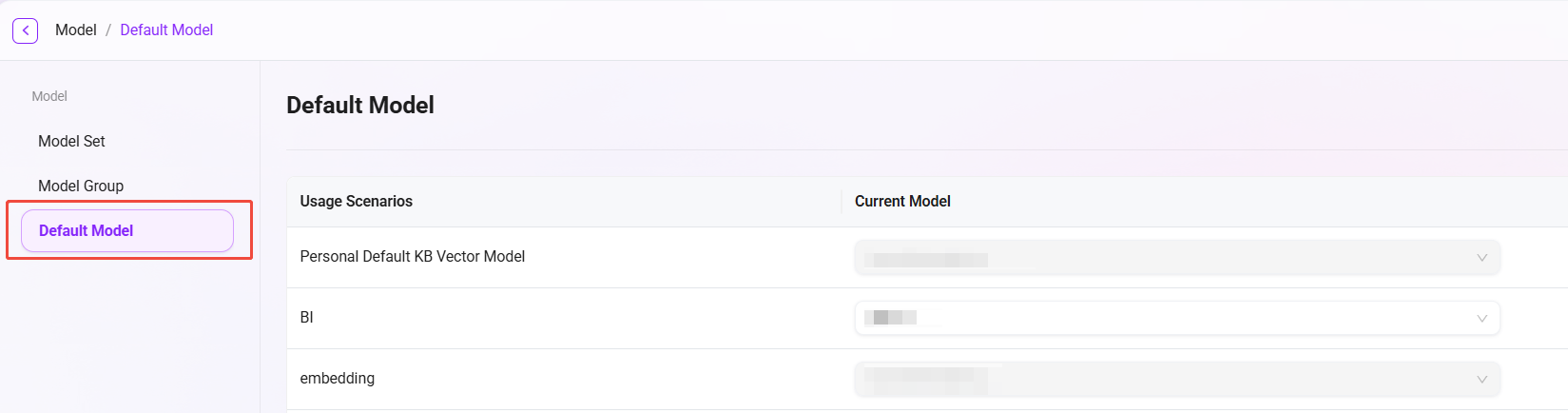
デフォルトモデル設定
モデル管理では、管理者はデフォルトモデルを設定でき、異なる利用シーンごとに適切なモデルを指定できます。たとえば、BI(ビジネスインテリジェンス)、翻訳(Translate)などのシーンでは、デフォルトモデルを Azure-4o モデルに設定できます。この方法により、システムは対応するシーンで事前設定されたデフォルトモデルを自動的に使用し、作業効率と一貫性を向上させます。
設定手順はモデルセットの作成と類似しており、管理者は実際の要件に応じて、シーンのデフォルトモデルとして適切なモデルを選択できます。
利用シーン
| 機能名 | 役割説明 | 典型的なシーン例 |
|---|---|---|
| RAG | ナレッジベースと組み合わせて検索拡張を行い、大規模モデルの回答精度と信頼性を向上 | 企業ナレッジベースQ&A、インテリジェントカスタマーサポート |
| i18n translation | 多言語翻訳とUIの国際化を実現し、グローバル展開をサポート | 海外ユーザー向けAI製品、国際運営プラットフォーム |
| gallery ssn writing | ユーザーの各インタラクションやコンテンツ生成プロセスを記録し、閲覧や再編集を容易にする | 会話履歴のアーカイブ、コンテンツ制作の保存、バージョン追跡 |
| gallery rednote | ユーザーが重要情報のマークや注釈を追加でき、振り返りやコンテンツレビューを支援 | AI生成コンテンツのレビュー、ユーザー共同制作、重要箇所のハイライト |
| gallery mindmap | テキスト内容を構造化されたマインドマップに変換し、情報理解を強化 | プロジェクト整理、ナレッジグラフ生成 |
| optimize prompt | ユーザー入力のPromptを最適化し、モデルの理解と出力品質を向上 | ユーザー入力が不明確な場合の書き換え支援、低ハードルな質問最適化 |
| recommend question | 次に関心を持つ可能性のある、または関連する質問を自動推薦し、対話体験を向上 | チャットボットの会話継続、推薦ガイド |
| gallery chat lead | 会話ガイドテンプレートや「書き出し」を提供し、より明確な質問や作成依頼の開始を支援 | チャットテンプレートライブラリ、作成プロンプト |
| recommend config | タスクに応じて大規模モデルのパラメータ設定(温度、RAG使用有無など)を自動推薦 | Agent設定パネル、ローコード/ノーコードのインテリジェント推薦 |
| pdf_markdown | PDFファイルをMarkdownの構造化形式に解析し、読み取りや後続処理を容易にする | ドキュメントのナレッジベース取り込み、要約生成 |
| translate | ユーザー入力またはモデル出力を自動翻訳し、言語をまたいだコミュニケーションを実現 | 多言語対話、多言語カスタマーサポート |
| BI | 大規模モデルを用いて構造化データを処理し、可視化分析や業務インサイトを生成 | 自然言語によるレポート分析、グラフ生成、BI Q&Aエージェント |
| llm_ocr | 画像内の文字を構造化テキストとして抽出し、大規模モデルと組み合わせて意味を理解 | 画像Q&A、帳票認識、PDFスクリーンショット解釈、画像ドキュメント検索など |
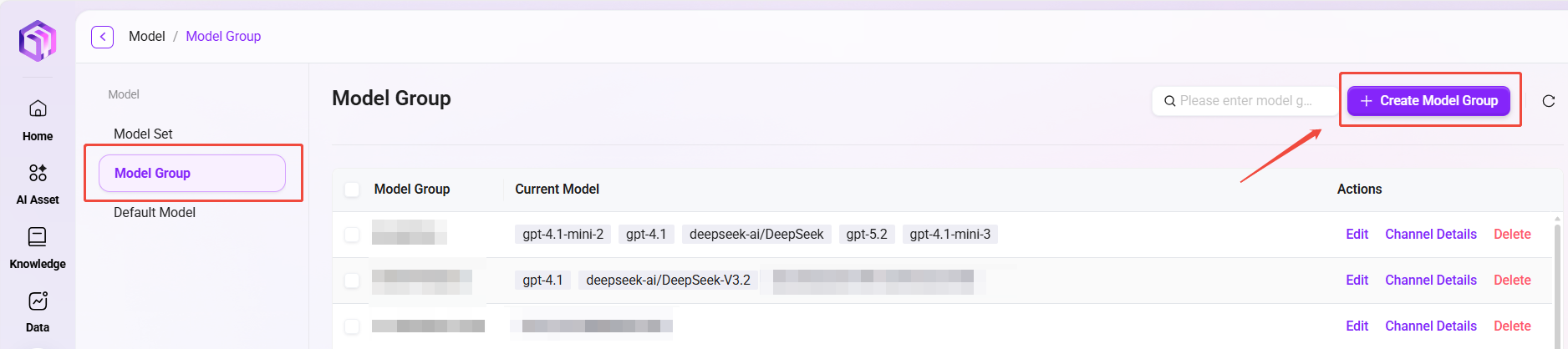
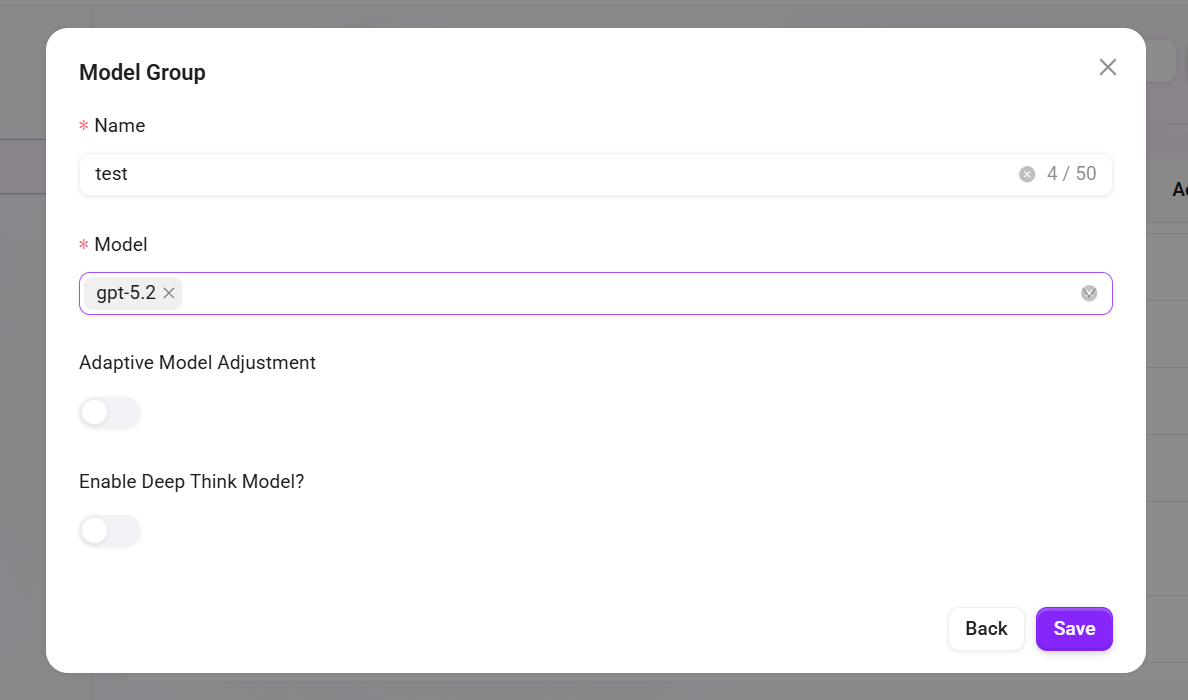
モデルグループの作成
管理者はモデル管理でモデルグループを作成できます。作成したモデルグループは、Agent作成時に適切なモデルグループを設定するために使用できます。
以下はモデルグループ作成の手順です:
- モデルグループ管理ページへ移動:管理に入り、「モデル管理」を選択し、その後「モデルグループ」をクリックします。
- 「新規モデルグループ」をクリック:ページ右側の「新規モデルグループ」ボタンをクリックし、新しいモデルグループの作成を開始します。
- モデルグループ名を入力:モデルグループに一意の名称を指定し、識別しやすいようにします(50文字以内)。
- モデルを選択:利用可能なモデル一覧から、このモデルグループに含めるモデルを選択します。複数選択に対応しています。
- 適応型モデルデプロイとするかを選択:要件に応じて、適応型モデルデプロイ機能を有効にするかを選択し、モデルの柔軟性と適応性を向上させます。
- 深度思考モデルを有効にするかを選択:必要に応じて、深度思考モデルを有効にするかを選択し、モデルのインテリジェント処理能力を強化します。
- 「保存」をクリック:すべての設定に誤りがないことを確認した後、「保存」ボタンをクリックすると、モデルグループを正常に作成できます。
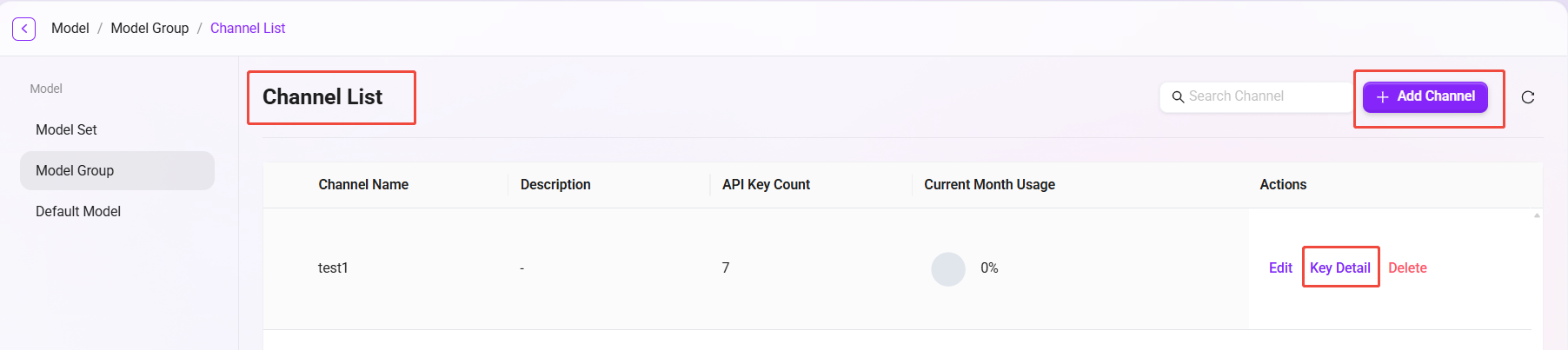
モデルグループのチャネル詳細
新しいモデルグループを作成した後、**「チャネル詳細」**ページに入り、設定済みのすべてのチャネルを確認できます。要件に応じて、以下の操作が可能です:
- チャネルを新規作成:モデルグループ用の新しい呼び出しチャネルを作成します。
- キーを管理:右側の "Key 详情" をクリックすると、そのチャネル配下のすべてのキー情報を確認でき、新しいキーの作成にも対応しています。
このページにより、各チャネルおよび対応する API Key を一元管理しやすくなります。

API Keyの特性説明
当社プラットフォームが提供する API Key は、高い独立性と認可効力を備えています。各 API Key は独立した「通行証」に相当し、完全なアクセスおよび呼び出し権限を持ちます。詳細は以下のとおりです:
-
プラットフォームのユーザー体系から独立
API Key を保持する呼び出し元は、プラットフォームの登録ユーザーである必要はなく、特定のユーザー権限も不要です。リクエストに有効な API Key が含まれていれば、正当な認可済みリクエストと見なされ、システムは通常どおり処理および応答を行います。 -
License の制限を受けない
API Key による呼び出しは、プラットフォームのユーザー License 枠を消費しません。そのため、企業における実際の登録ユーザー数が限られていても、API Key を通じてより多くのサービス接続や業務シーンを柔軟にサポートでき、追加認可や拡張なしで大規模利用を実現できます。 -
必要に応じた柔軟な設定
異なる API Key ごとに、有効期限、権限範囲(アクセス可能なモジュール、データ範囲など)を個別に設定でき、異なる接続システムや業務担当者に適応できます。後続の管理や利用状況の追跡を容易にするため、接続先ごとに独立した API Key を個別発行することを推奨します。
⚠️ セキュリティに関する注意: API Key は適切に管理し、漏洩を防いでください。外部に悪用された場合、その Key を通じて発行されたすべてのリクエストは完全な権限を持つものとして扱われ、データおよびシステムの安全性にリスクをもたらす可能性があります。
Agent対話インターフェースのアップグレード
従来のAPI Key呼び出し方式に加え、ユーザーTokenでAgent APIにアクセスするSSE(Server-Sent Events)セッション管理方式が新たに追加されました。
- ユーザー認証の強化:従来のAPI Key方式では特定ユーザーの識別ができない問題を解決し、サードパーティアプリケーションがユーザーTokenを通じて呼び出せるようになり、異なるユーザーのリクエスト元を明確に区別できます。
- コンテキスト管理の最適化:サードパーティアプリケーションが会話コンテキストを"能動的に"制御でき、新しいセッションの作成や前回の会話の継続を柔軟に行えるため、会話の一貫性と管理の柔軟性が向上します。
- 互換性の向上:新しい呼び出し方式はApifoxなどのAPIテストツールでデバッグおよび呼び出しが可能であり、開発や統合テストに便利です。
このアップグレードは、特に正確なユーザー識別が必要なサードパーティアプリケーション統合シーンに適しており、マルチユーザー環境におけるAgent呼び出しに対して、より精緻な制御能力を提供します。
モデル設定の説明
本製品は以下の拡張機能の統合をサポートしており、いずれも Azure または外部プラットフォームが提供するサービスに依存します。必要に応じて関連プラットフォームで必要なアクセス資格情報(API Key、Endpoint など)を選択・取得してください:
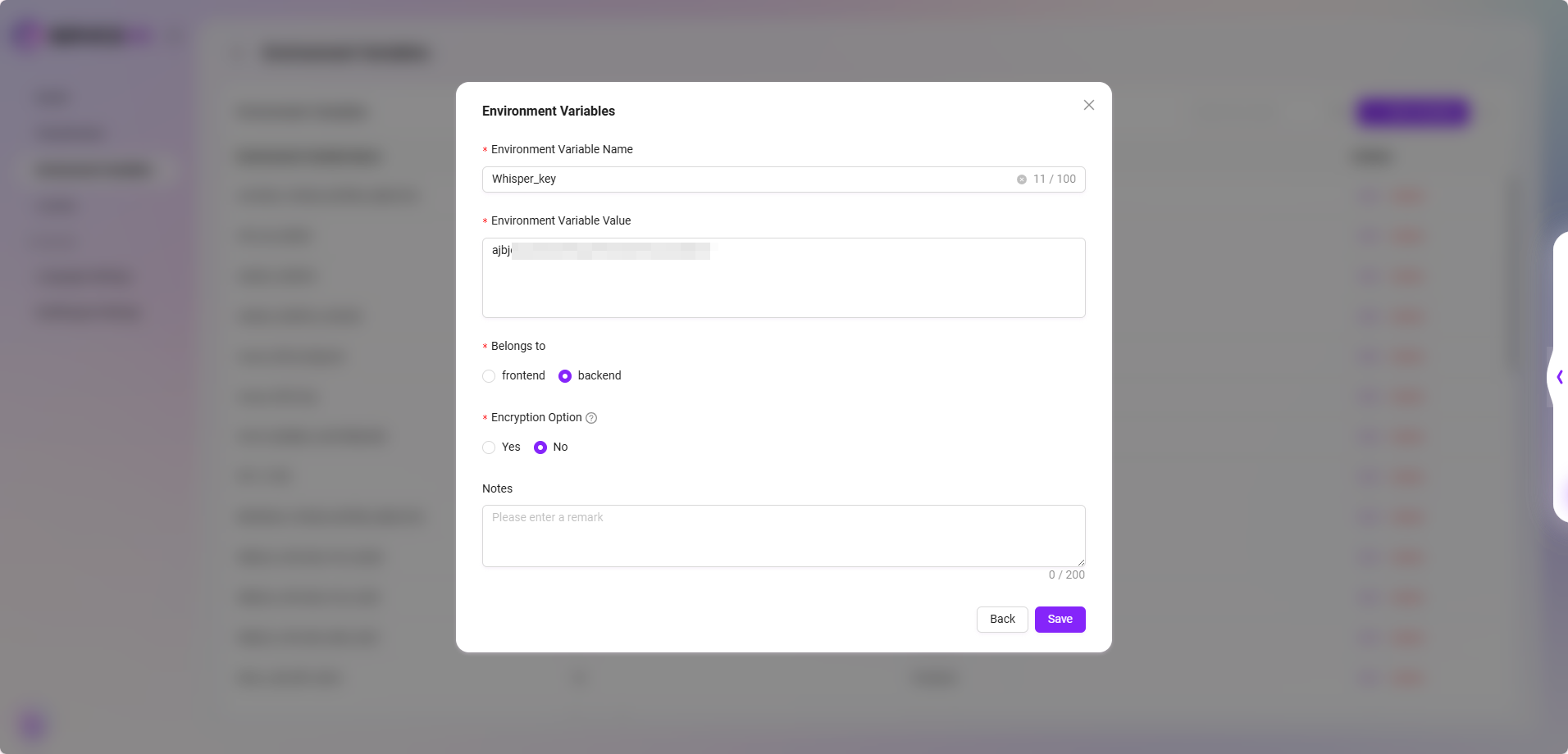
- 音声入力機能(Whisper サービス)
- サービス説明:Azure 上で購入・デプロイした Whisper サービスにより、音声からテキストへの変換機能を実現します。
- 設定方法:環境変数を通じて複数の Whisper Key を設定できます。変数名には "Whisper" の文字列を明示的に含める必要があります。設定されていない場合、音声入力ボタンは表示されません。
- 互換性説明:初期化 SQL による Whisper サービス設定にも対応しており、設定内容は自動的に環境変数へ書き込まれ、後からの変更も可能です。
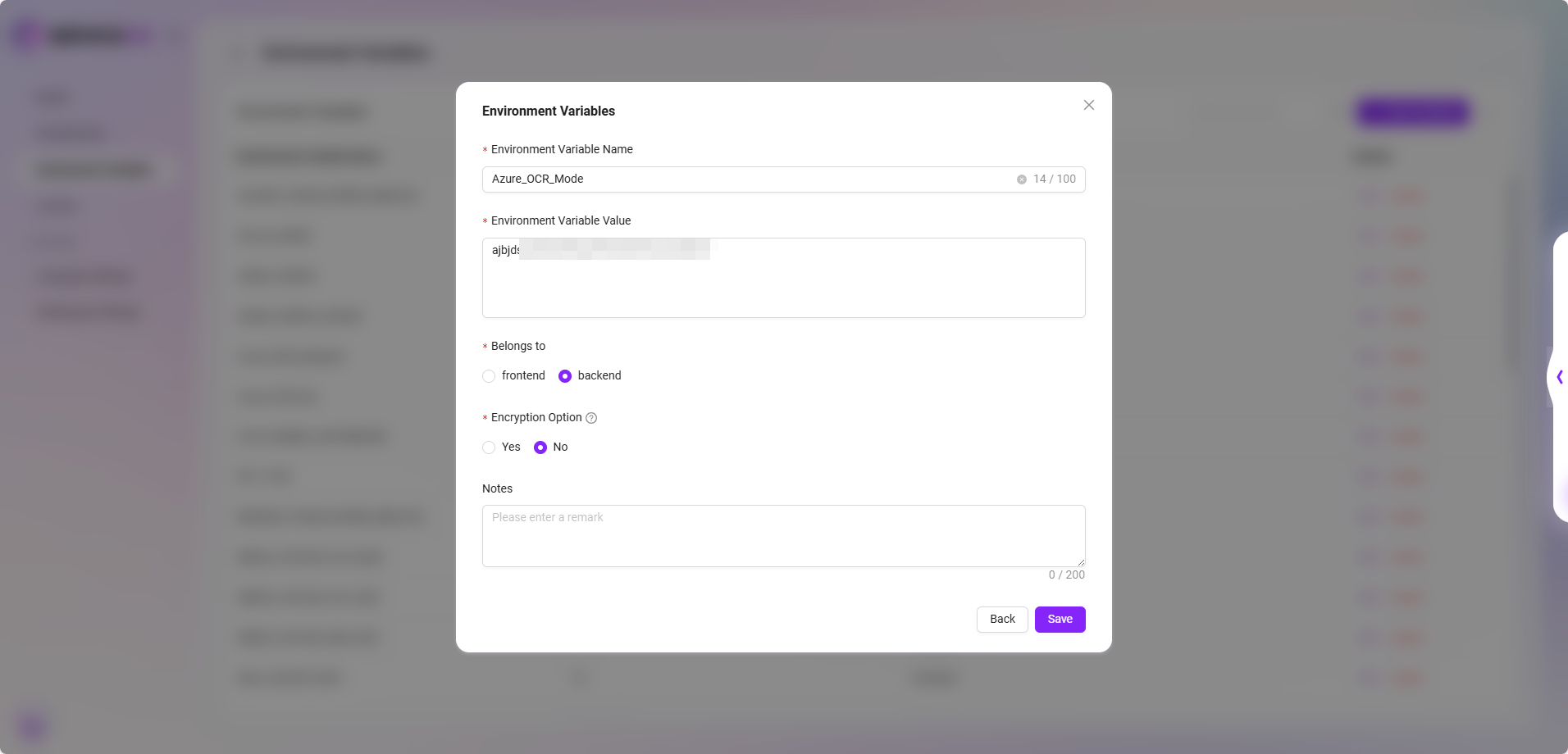
- Azure OCR モード(Azure Document Intelligence)
- サービス説明:Azure Document Intelligence に基づいて OCR 機能を実現し、「Basic」と「Advanced」の2種類の認識モードをサポートします。
- 設定方法:環境変数に Azure OCR モードの KEY と Endpoint を設定する必要があります。未設定の場合、この OCR モードは選択できません。
- UI上のヒント:画面は設定状態に応じて選択可能なモードを自動表示し、無効なオプションの選択を制限します。
- サービスの購入、API Key および Endpoint の取得が必要な場合は、Microsoft Azure 公式サイトまたは関連サービスプロバイダーのページにアクセスし、要件に応じて適切な料金プランを選択してください。
- 当社では、設定前にデータセキュリティ、応答速度、価格要因を優先的に評価することを推奨しています。デプロイ支援が必要な場合は、技術サポートチームまでお問い合わせください。