モデル管理
新しいモデルセットの作成
管理者は以下の手順で新しいモデルセットを作成できます:
- モデルセット管理ページに移動:モデル管理に移動し、「モデルセット」をクリックします。
- 「新規」をクリック:ページ右側の「新規」ボタンをクリックして、新しいモデルセットの作成を開始します。
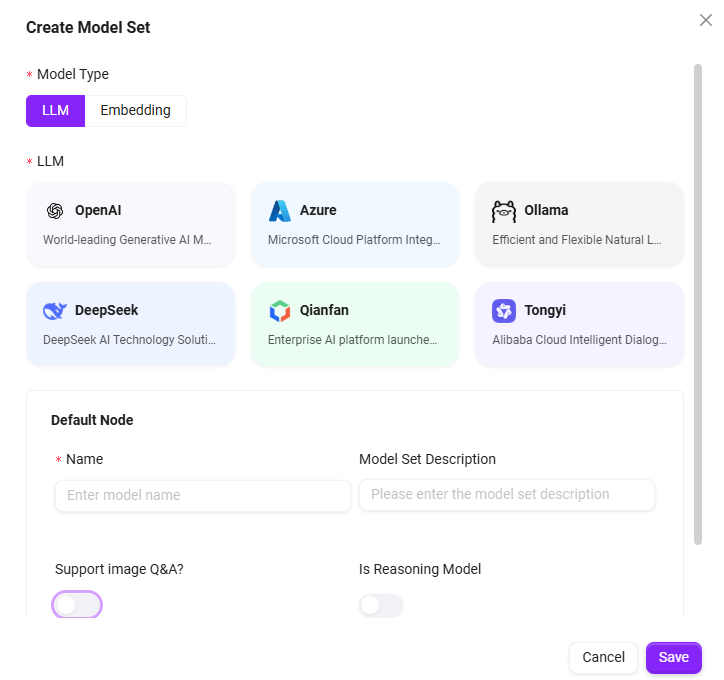
- モデルタイプを選択:ポップアップウィンドウで、モデルのタイプを選択します。選択可能なタイプは:
- LLM(大規模言語モデル)
- Embedding(埋め込みモデル)
💡 ヒント:システムは1つのEmbeddingモデルのみ追加をサポートしています。
- 言語モデルを選択:必要に応じて、適切な言語モデルを選択します。現在サポートされている言語モデルは:
- LLM言語モデル:OpenAI、Deepseek、Azure、Ollama、Tongyi、Qianfan、Anthropic、VertexAl、AWS AI;
- Embedding言語モデル:OpenA Embeddings、Azure Embeddings、AliEmbeddings、Ollama Embeddings、Amazon Bedrock Embeddings、VertexAlEmbeddings;
- モデルセット情報を入力:モデルセットの名称と説明を入力し、情報が明確で正確であることを確認します(名称50文字以内、説明200文字以内)。
- 追加設定を選択:必要に応じて、画像Q&Aをサポートするかどうか、および推論モデルかどうかを選択します。
- 作成を確認:記入後、「確認」ボタンをクリックして、モデルセットの作成を完了します。
これらの手順により、管理者は新しいモデルセットを正常に作成し、対応する設定を構成できます。

Embeddingモデルを追加する際は、ベクトル次元制限に注意してください:
- PgSQLベクトルフィールドは最大2000次元をサポートします。
- Embeddingモデルを購入する際は、その出力ベクトル次元が2000未満であることを確認してください(一部のモデルは設定で調整可能)。
- システムでベクトルモデルを追加する際は、2000未満のベクトル次元値を入力してください。そうしないと、ストレージ異常やインデックス失敗の原因となる可能性があります。
- 推奨Tokenコンテキスト制限:8192。
デフォルトモデル設定
モデル管理では、管理者はデフォルトモデルの設定を行い、異なる使用シナリオに適用可能なモデルを指定できます。例えば、BI(ビジネスインテリジェンス)や翻訳(Translate)などのシナリオでは、デフォルトモデルをAzure-4oモデルに設定できます。このように、システムは対応するシナリオで自動的に事前設定されたデフォルトモデルを使用し、作業効率と一貫性を向上させます。
設定手順はモデルセット作成と類似しています。管理者は実際のニーズに基づいて、シナリオのデフォルトモデルとして適切なモデルを選択できます。
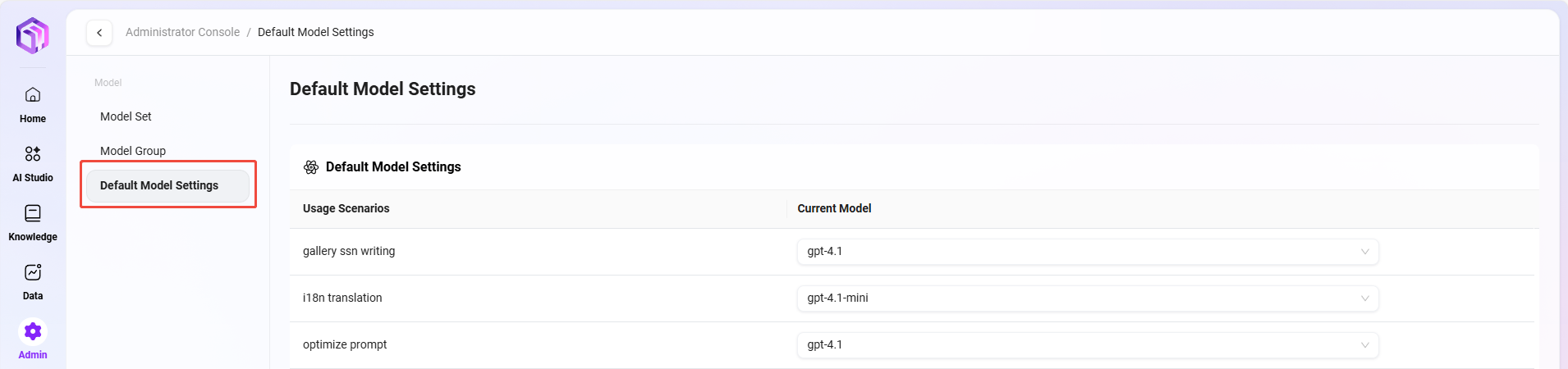
使用シナリオ
| 機能名称 | 説明 | 代表的なシナリオ例 |
|---|---|---|
| RAG | 知識ベースと組み合わせて検索拡張生成を行い、大規模モデル回答の正確性と信頼性を向上 | 企業ナレッジベースQ&A、インテリジェントカスタマーサービス |
| i18n translation | 多言語翻訳とインターフェース国際化を実現し、グローバル展開をサポート | 海外ユーザー向けAI製品、国際化運用プラットフォーム |
| gallery ssn writing | ユーザー毎のインタラクションやコンテンツ生成プロセスを記録し、レビューと二次編集を容易に | 対話履歴アーカイブ、コンテンツ作成記録、バージョン遡及 |
| gallery rednote | ユーザーが重要な情報をマークしたり注釈を書いたりでき、レビューやコンテンツ審査を補助 | AI生成コンテンツの審査、ユーザー共同創作、重要なセグメントのハイライト |
| gallery mindmap | テキストコンテンツを構造化マインドマップに変換し、情報理解を強化 | プロジェクト整理、ナレッジグラフ生成 |
| optimize prompt | ユーザー入力のプロンプトを最適化し、モデルの理解と出力品質を向上 | ユーザー入力が不明確な場合の書き換え支援、低い敷居の質問最適化 |
| recommend question | 次に興味を持つ可能性のある関連質問を自動的に推奨し、インタラクション体験を向上 | チャットボット対話継続、推奨ガイダンス |
| gallery chat lead | 対話ガイダンステンプレートや「開始語」を提供し、ユーザーがより明確な質問や作成リクエストを開始するのを支援 | チャットテンプレートライブラリ、創作プロンプト |
| recommend config | タスクに基づいて大規模モデルパラメータ設定(温度、RAG使用有無など)を自動的に推奨 | エージェント設定パネル、ローコード/ノーコードインテリジェント推奨 |
| pdf_markdown | PDFファイルをMarkdown構造化形式に解析し、読み取りと後続処理を容易に | ドキュメント知識ベースへのインポート、要約生成 |
| translate | ユーザー入力やモデル出力を自動的に翻訳し、言語横断コミュニケーションを実現 | 多言語対話、多言語カスタマーサービス |
| BI | 大規模モデルを使用して構造化データを処理し、視覚的分析やビジネスインサイトを生成 | 自然言語分析レポート、チャート生成、BI Q&Aアシスタント |
| llm_ocr | 画像中の文字を構造化テキストに抽出し、大規模モデルと組み合わせて意味理解を行う | 画像Q&A、フォーム認識、PDFスクリーンショット解釈、画像ドキュメント検索など |
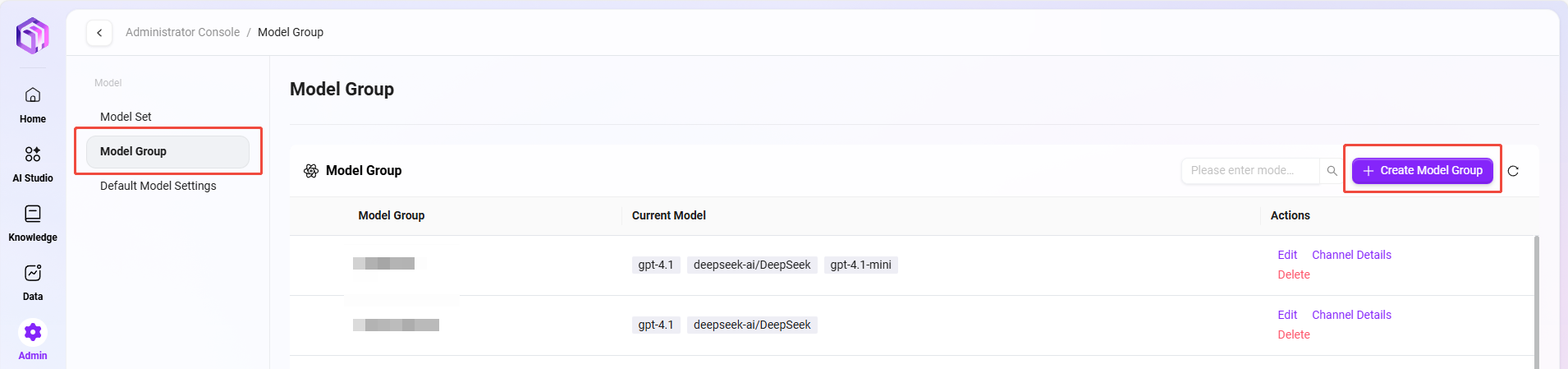
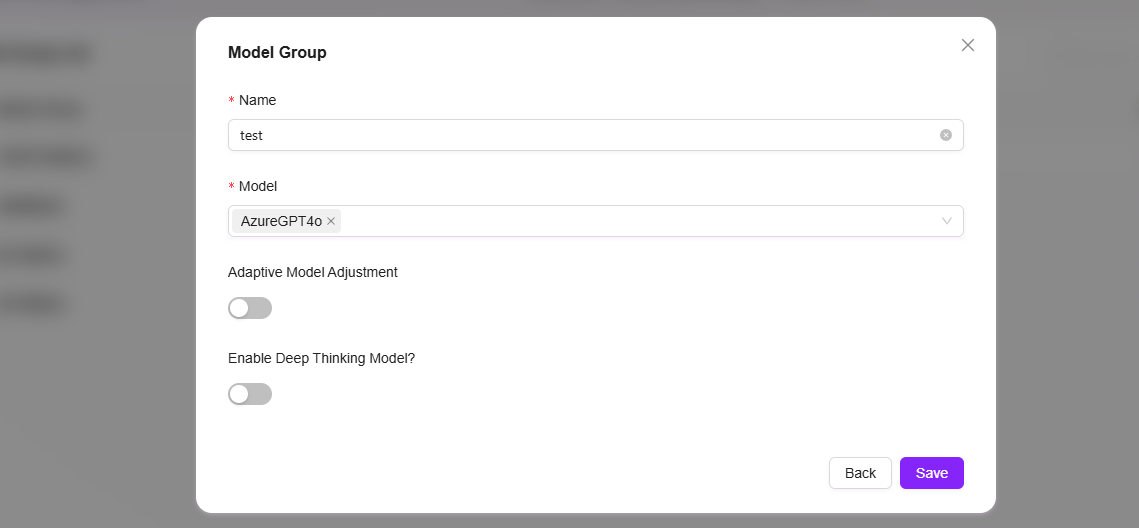
モデルグループの作成
管理者はモデル管理でモデルグループを作成できます。作成されたモデルグループは、助手作成時に適切なモデルグループとして構成できます。
モデルグループ作成の手順は以下の通りです:
- モデルグループ管理ページに移動:管理に移動し、「モデル管理」を選択してから「モデルグループ」をクリックします。
- 「新規モデルグループ」をクリック:ページ右側の「新規モデルグループ」ボタンをクリックして、新しいモデルグループの作成を開始します。
- モデルグループ名を入力:モデルグループに一意の名前を指定し、容易に識別できるようにします(50文字以内)。
- モデルを選択:利用可能なモデルリストからこのモデルグループに含めるモデルを選択します。複数選択をサポートします。
- 適応型モデルデプロイかどうかを選択:必要に応じて、適応型モデルデプロイ機能を有効にするかどうかを選択し、モデルの柔軟性と適応性を向上させます。
- 深度思考モデルを有効にするかどうかを選択:必要に応じて、深度思考モデルを有効にするかどうかを選択し、モデルの知的処理能力を強化します。
- 「保存」をクリック:すべての設定が正しいことを確認したら、「保存」ボタンをクリックしてモデルグループを正常に作成します。
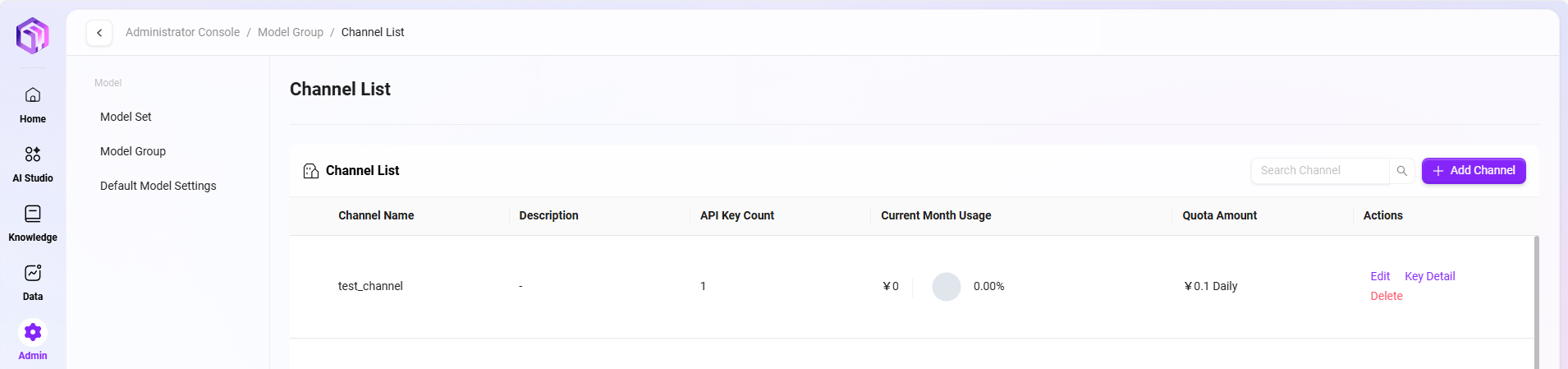
モデルグループチャネル詳細
新しいモデルグループを作成した後、**「チャネル詳細」**ページに入ると、設定済みのすべてのチャネルを表示できます。ニーズに応じて:
- 新しいチャネルを作成:モデルグループの新しい呼び出しチャネルを作成します。
- キーを管理:右側の「Key 詳細」をクリックして、そのチャネル下のすべてのキー情報を表示し、新しいキーの作成をサポートします。
このページを通じて、各チャネルとその対応するAPI Keyを統一管理しやすくなります。
API Key特性説明
当社プラットフォームが提供するAPI Keyは、高い独立性と認可効力を有しています。各API Keyは独立した「通行証」に相当し、完全なアクセスおよび呼び出し権限を備えています。具体的な説明は以下の通りです:
-
プラットフォームユーザーシステムからの独立性 API Keyを保持する呼び出し側は、プラットフォームの登録ユーザーである必要も、特定のユーザー権限を有する必要もありません。有効なAPI Keyをリクエストに含めるだけで、合法的に認可されたリクエストと見なされ、システムは正常に処理と応答を行います。
-
License制限を受けない API Keyを通じて開始された呼び出しは、プラットフォームのユーザーLicenseクォータを消費しません。したがって、企業のプラットフォーム上の実際の登録ユーザー数が限られていても、API Keyを通じて柔軟により多くのサービスアクセスとビジネスシナリオをサポートでき、追加の認可や容量拡張を必要とせずに大規模な使用を実現できます。
-
必要に応じた柔軟な構成 異なるAPI Keyは、必要に応じて異なる有効期間、権限範囲(アクセスモジュール、データ範囲など)を構成でき、異なる接続システムやビジネスパートナーに適合させることができます。各接続先に対して独立したAPI Keyを生成することを推奨し、後続の管理と使用状況追跡を容易にします。
⚠️ セキュリティ警告:API Keyを適切に管理し、漏洩を避けてください。一度外部に悪用されると、そのKeyを通じて開始されたすべてのリクエストはデフォルトで完全な権限を持ち、データとシステムセキュリティにリスクをもたらす可能性があります。
エージェント対話インターフェースのアップグレード
💡 ヒント:この機能はV4.1.2以降のバージョンのみサポートしています
元のAPI Key呼び出し方式に基づき、ユーザートークンによるAgent APIへのアクセス SSE(Server-Sent Events)セッション管理方式が新たに追加されました。
- ユーザー認証のアップグレード:従来のAPI Key方式では特定のユーザーIDを識別できない問題を解決し、サードパーティアプリケーションがユーザーレベルトークン(統一API Keyの代替)を通じて呼び出すことをサポートし、ユーザー要求元の正確な追跡を実現します。
- コンテキスト管理の最適化:サードパーティアプリケーションが「積極的に」対話コンテキストを制御することをサポートし、新しいセッションの作成や前回の対話の継続を柔軟に行え、対話の一貫性と管理の柔軟性を強化します。
- 互換性の強化:新たな呼び出し方式は、ApifoxなどのAPIテストツールを使用したデバッグや呼び出しが可能で、開発と統合テストを容易にします。
このアップグレードは、正確なユーザーID識別を必要とするサードパーティアプリケーション統合シナリオに特に適しており、多ユーザー環境でのAgent呼び出しに対してより細かい制御能力を提供します。
モデル設定説明
本製品は以下の拡張機能の統合をサポートしていますが、これらはいずれもAzureまたは外部プラットフォームが提供するサービスに依存しています。お客様自身で関連プラットフォームにアクセスし、ニーズに応じて必要なアクセス資格情報(API Key、Endpointなど)を取得する必要があります:
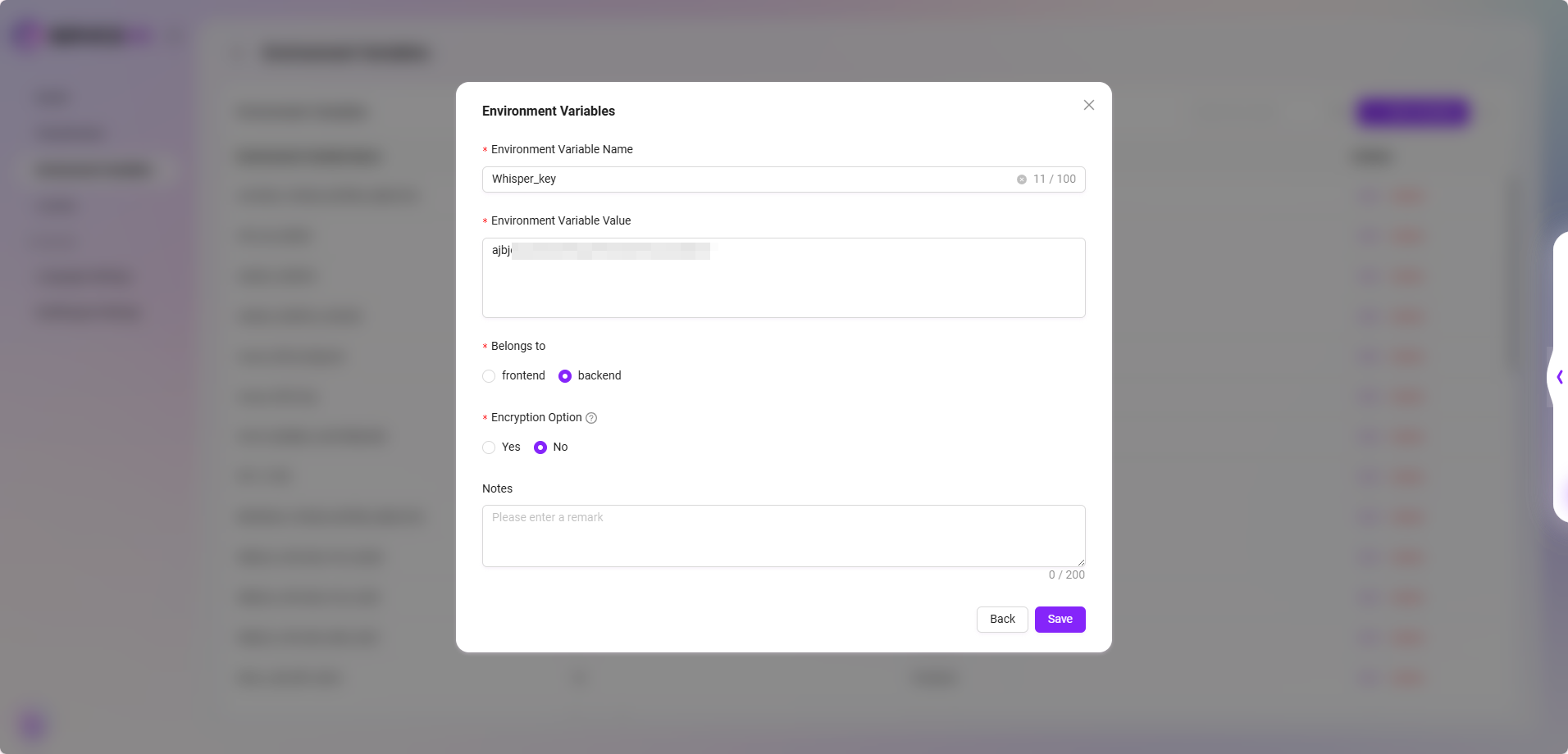
- 音声入力機能(Whisperサービス)
- サービス説明:Azure上でWhisperサービスを購入・デプロイすることで、音声テキスト変換機能を実現します。
- 設定方法:環境変数を通じて複数のWhisper Keyを設定することをサポートします。変数名には明確に「Whisper」の文字を含める必要があります。設定されていない場合、音声入力ボタンは表示されません。
- 互換性説明:初期化SQLを通じてWhisperサービスを設定することもサポートしており、設定内容は自動的に環境変数に書き込まれ、後で変更をサポートします。
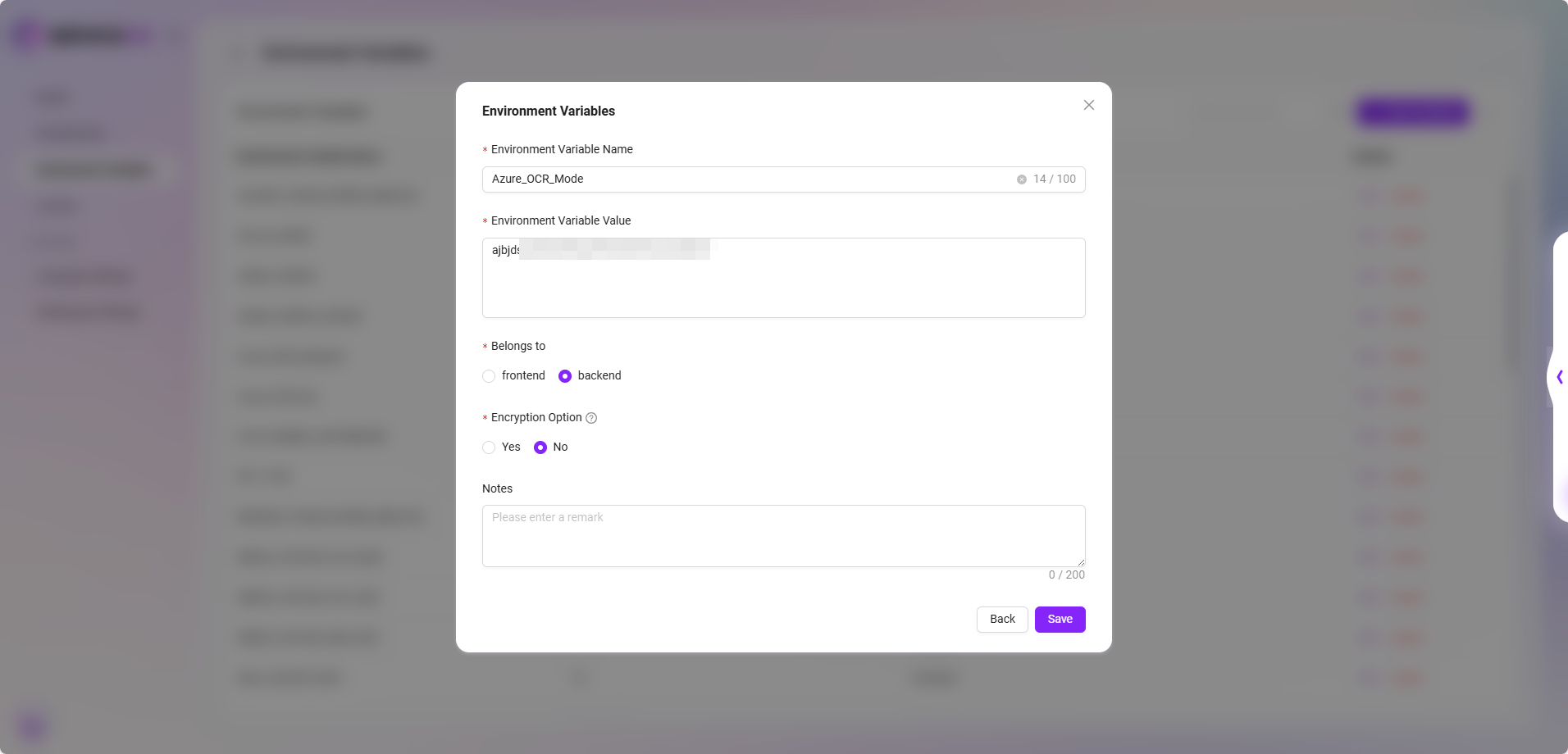
- Azure OCRモード(Azure Document Intelligence)
- サービス説明:Azure Document Intelligenceに基づいてOCR能力を実現し、「Basic」と「Advanced」の2つの認識モードをサポートします。
- 設定方法:環境変数でAzure OCRモードのKEYとEndpointを設定する必要があります。設定されていない場合、このOCRモードを選択することはできません。
- インタラクションプロンプト:インターフェースは設定状態に基づいて自動的に選択可能なモードを表示し、無効なオプションの選択を制限します。
- サービスの購入やAPI KeyおよびEndpointの取得が必要な場合は、Microsoft Azure公式サイトまたは関連サービスプロバイダーページを訪問し、必要に応じて適切な価格プランを選択してください。
- お客様には、まずデータセキュリティ、応答速度、価格要因を評価してから設定することをお勧めします。デプロイサポートが必要な場合は、テクニカルサポートチームにお問い合わせください。