検索 Pipeline と Agent Q&A の設定
本チュートリアルは、「企業技術ドキュメント向けインテリジェントQ&Aシステム」シリーズの第2回です。前回の 前処理 Pipeline とナレッジベース登録の設定 を引き継ぎます。
前回までに、以下を完了しています:
- ✅ 前処理 Pipeline のオーケストレーション(テキスト抽出 → インテリジェント分割 → 多次元サマリー強化 → ベクトル化保存)
- ✅ ナレッジベースの作成と前処理 RAG Pipeline のバインド
- ✅ 技術ドキュメントのアップロードと登録検証
本記事では、これを基に検索 Pipeline を設定し、Agent に関連付けて、エンドツーエンドのインテリジェントQ&A機能を実現します。
💡 前提条件:前回のチュートリアルを完了し、ナレッジベース内に処理済みのドキュメントデータが存在することを確認してください。
ステップ1:検索 Pipeline の設定
検索 Pipeline は、ユーザーが質問した際に、ナレッジベースから最も関連性の高い内容をどのように再取得するかを決定します。前処理段階で多次元強化データ(段落要約、画像説明、表要約)が生成されているため、検索時にこれらのデータを活用して再取得品質を向上できます。
検索 Pipeline の作成
- ナレッジベース ページで、「検索 Pipeline」 タブに切り替えます。
- 「+ Pipeline を作成」 をクリックし、以下を入力します:
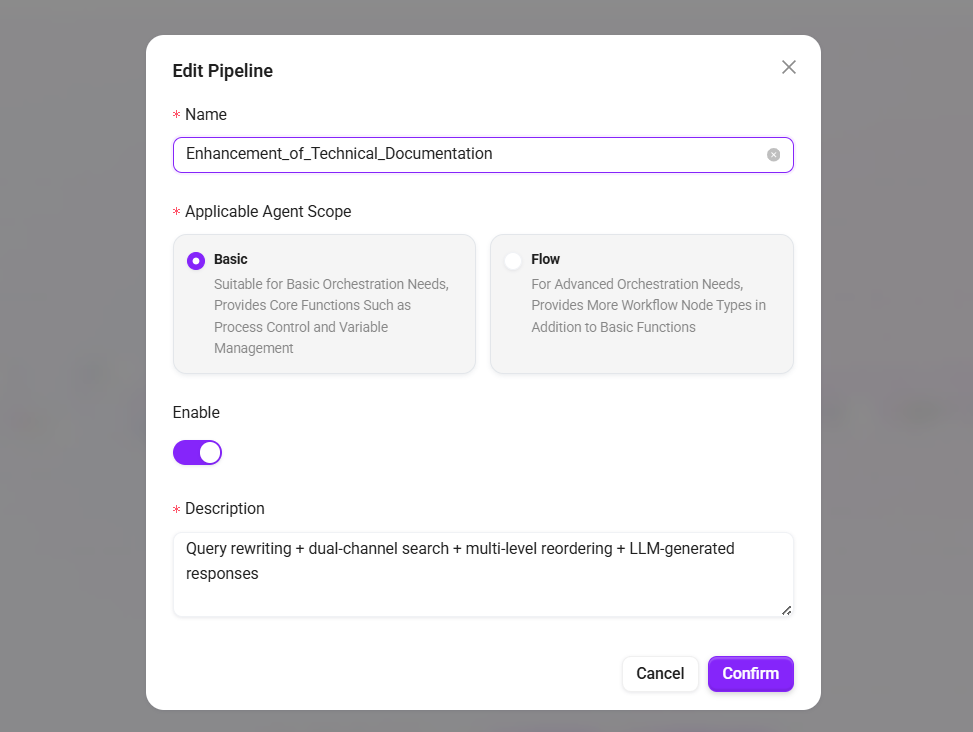
- 名称:
技術ドキュメント強化検索 - 適用Agent範囲:
基礎オーケストレーションを選択 - 説明:
クエリ書き換え + デュアルチャネル検索 + 多段階リランキング + LLM による回答生成
- 名称:
- 「確認」 をクリックしてオーケストレーション画面に入ります。
検索ノードの設定
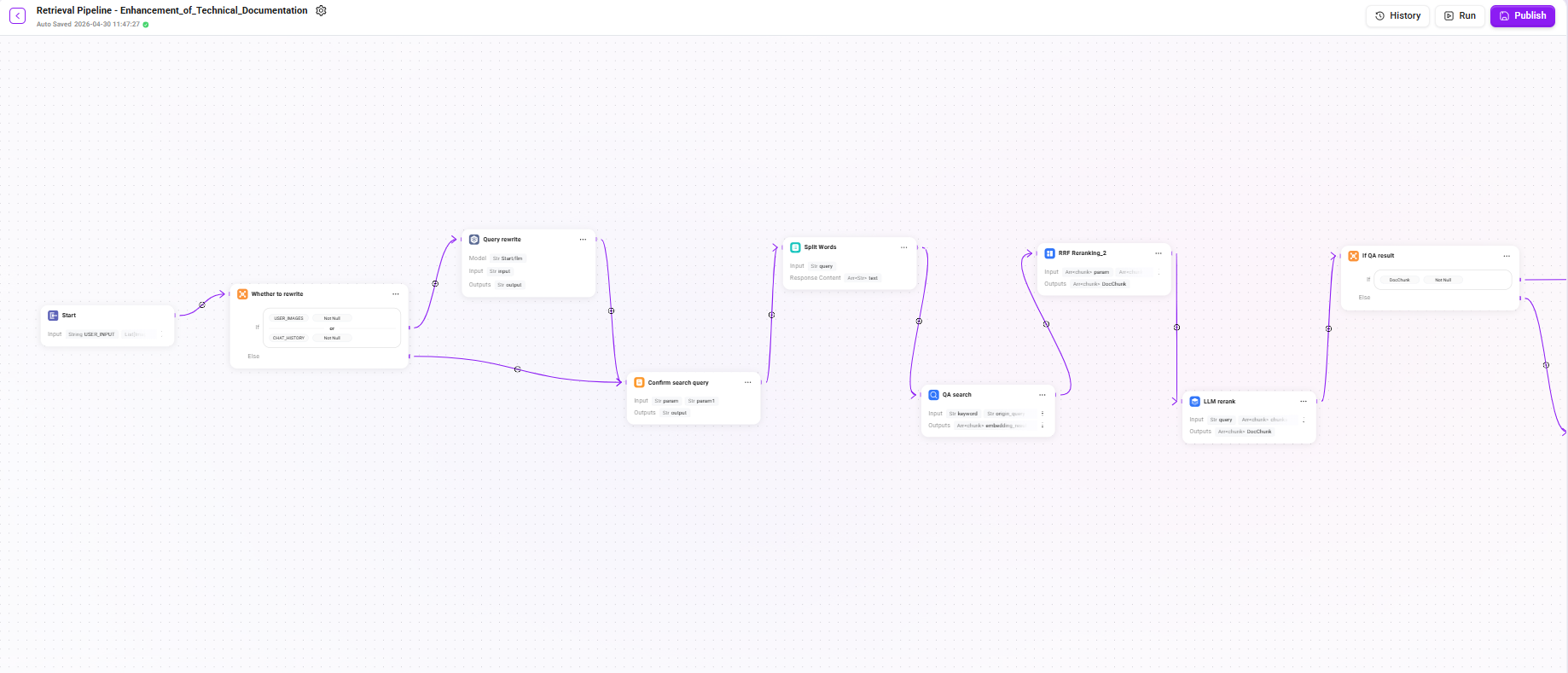
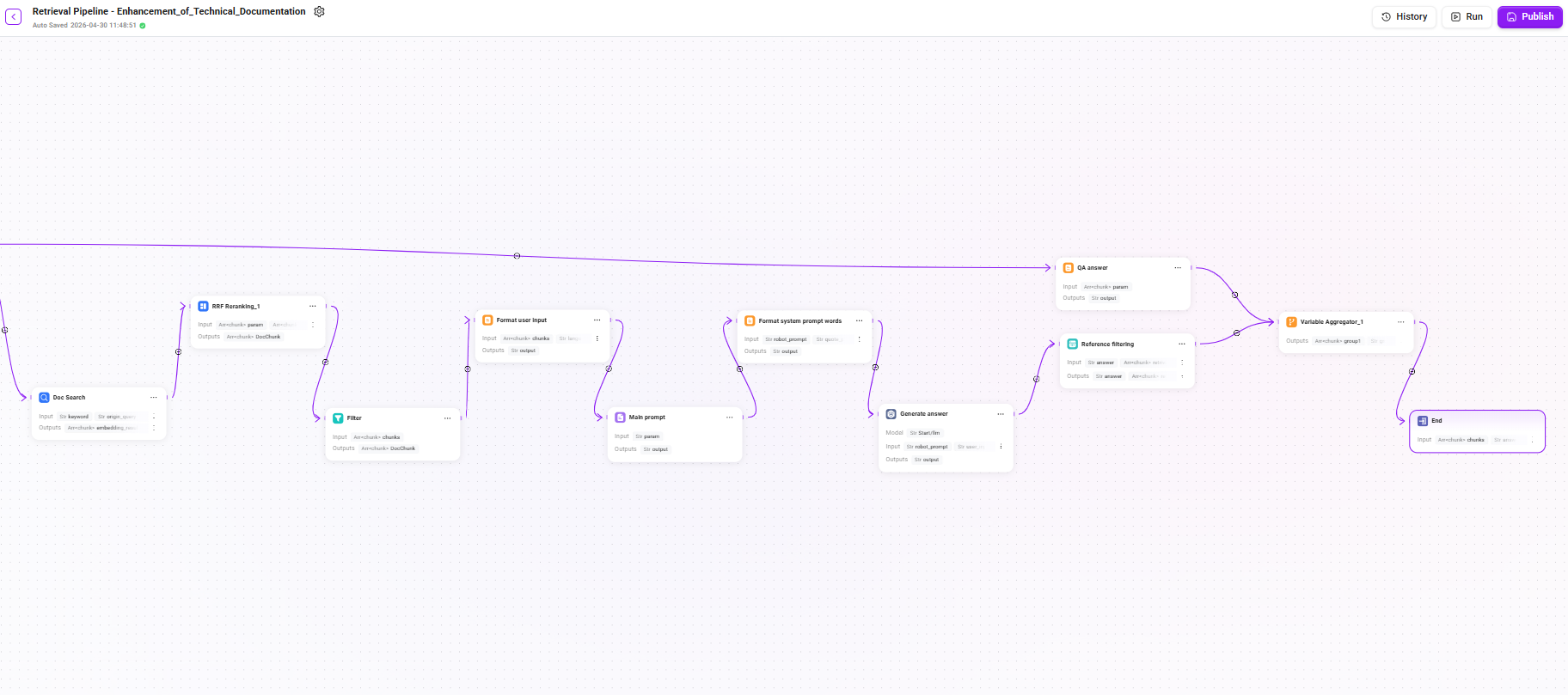
この検索 Pipeline は、多段階の漸進型アーキテクチャを採用しており、クエリ書き換え、デュアルチャネル検索、多段階リランキング、条件付きフォールバック、LLM による回答生成などの工程を含みます。チェーンが長いため、以下では3つの段階に分けて詳しく説明します。
フェーズ1:クエリ理解と検索
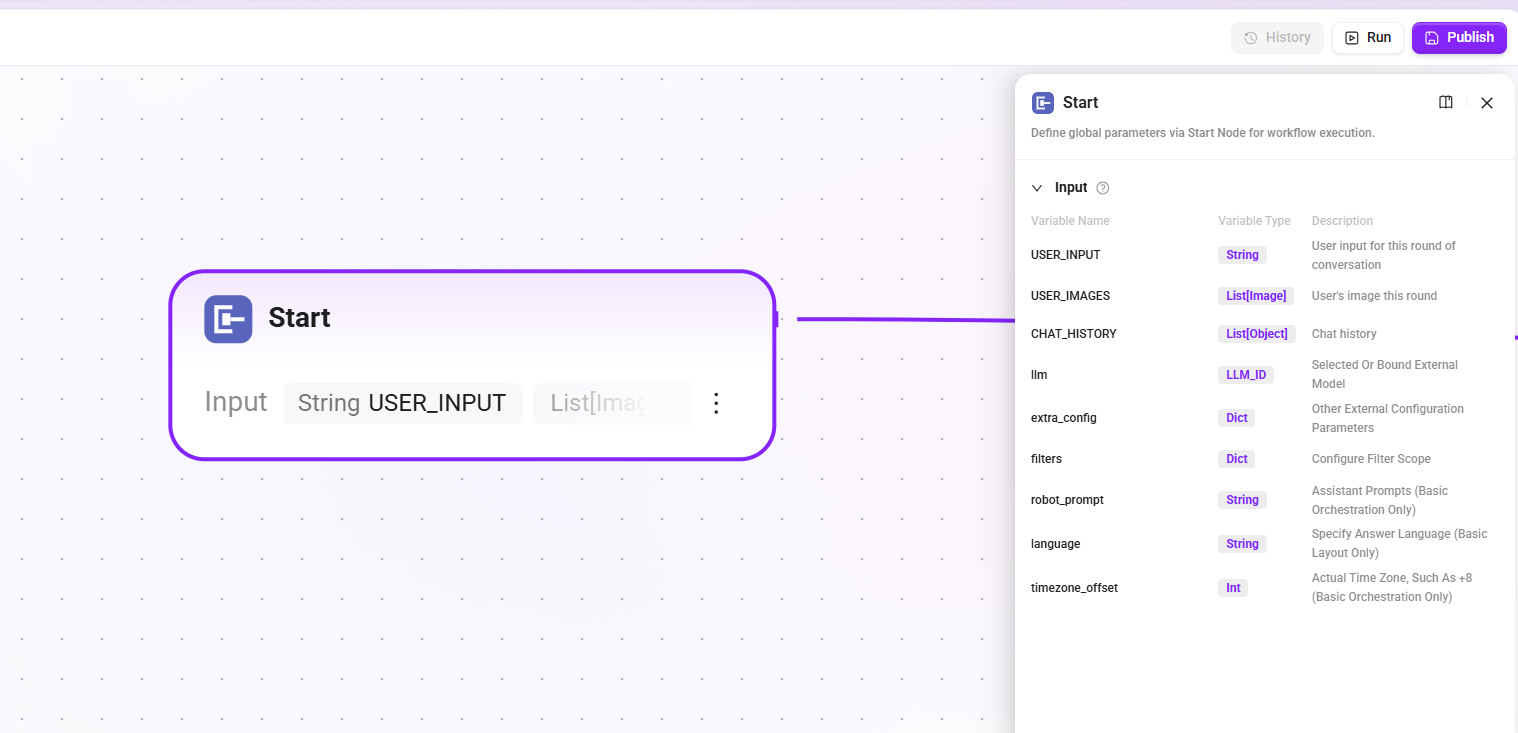
1. Start ノード
ワークフロー起動に必要な入力パラメータを定義します。これらの内容はアシスタントとの対話中にLLMによって読み取られ、適切なタイミングでワークフローを起動し、正しい情報を入力できるようになります。
- 入力:
USER_INPUT(ユーザーの今回の対話入力内容)、CHAT_HISTORY(チャット履歴)、USER_IMAGES(ユーザーが今回入力した画像)など
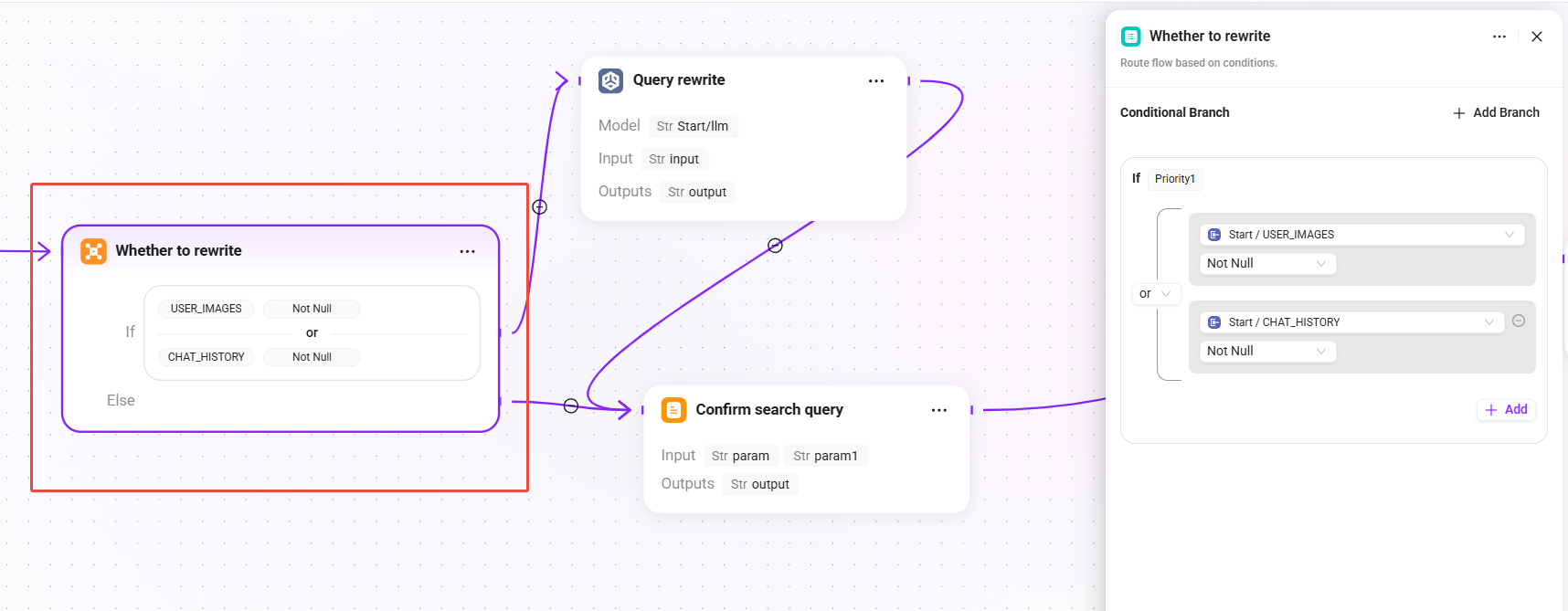
2. Whether to rewrite(条件判定)
現在のセッションコンテキストに基づいて、ユーザークエリを書き換える必要があるかを判断します:
- 条件:
USER_IMAGESが空でないまたはCHAT_HISTORYが空でない場合、「クエリ書き換え」分岐に入ります。 - else:書き換えフローをスキップし、直接「検索クエリ確認」ノードに進み、元の質問を最終クエリとして使用します。
💡 複数ターンの対話履歴が存在する場合、ユーザーの最新の質問は指示語を含む表現(例:「そのパラメータは何ですか?」)である可能性があります。この場合、完全なクエリに書き換えることで検索効果を高められます。
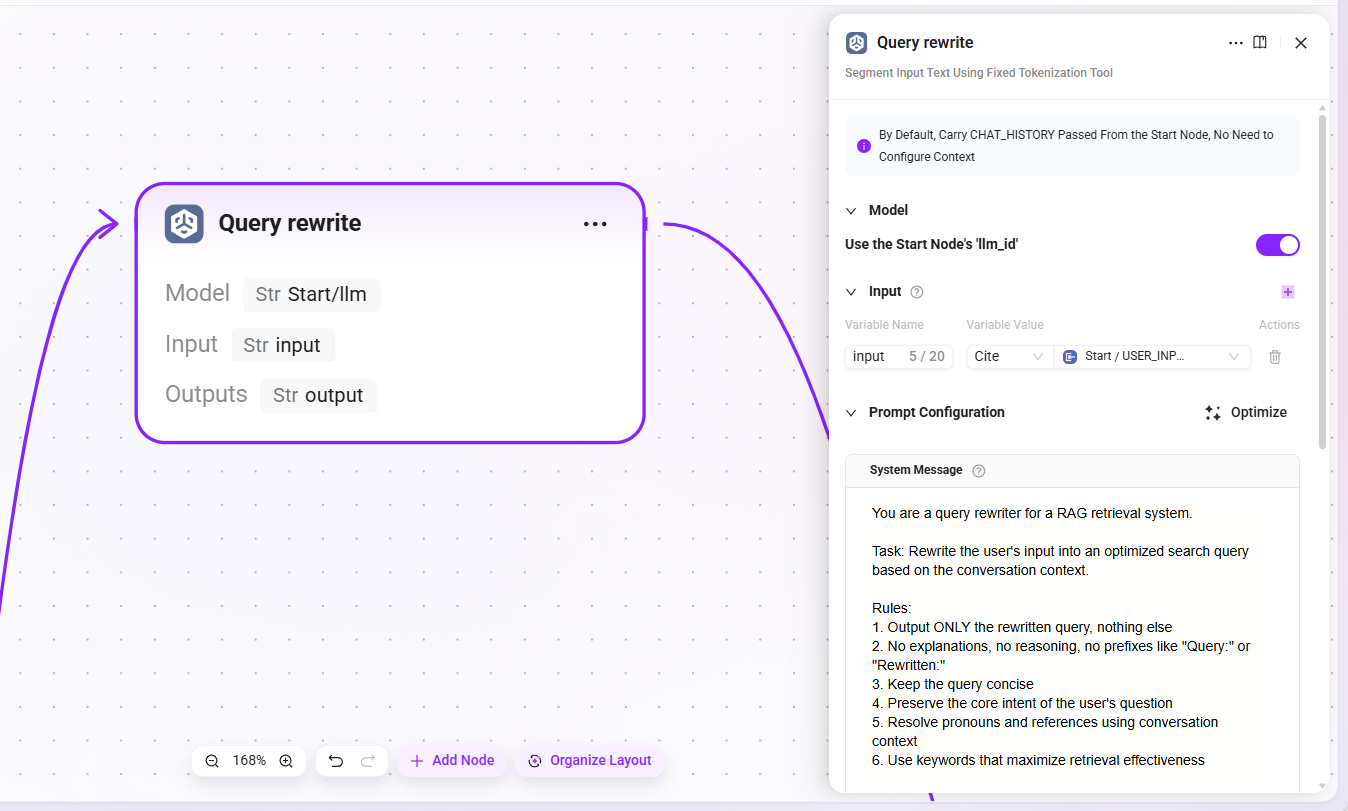
3. Query rewrite(クエリ書き換え)
- モデル:開始ノードで設定した LLM(
llm_id)をそのまま使用 - 入力:
USER_INPUT(ユーザー入力の元の質問テキスト) - 出力:
output(書き換え後の完全なクエリ文)
LLM はコンテキストを踏まえて曖昧な指示表現を明確な表現に置き換えます。たとえば、「それはどう設定しますか?」を「ナレッジベースの検索 Pipeline はどのように設定しますか?」に書き換えます。
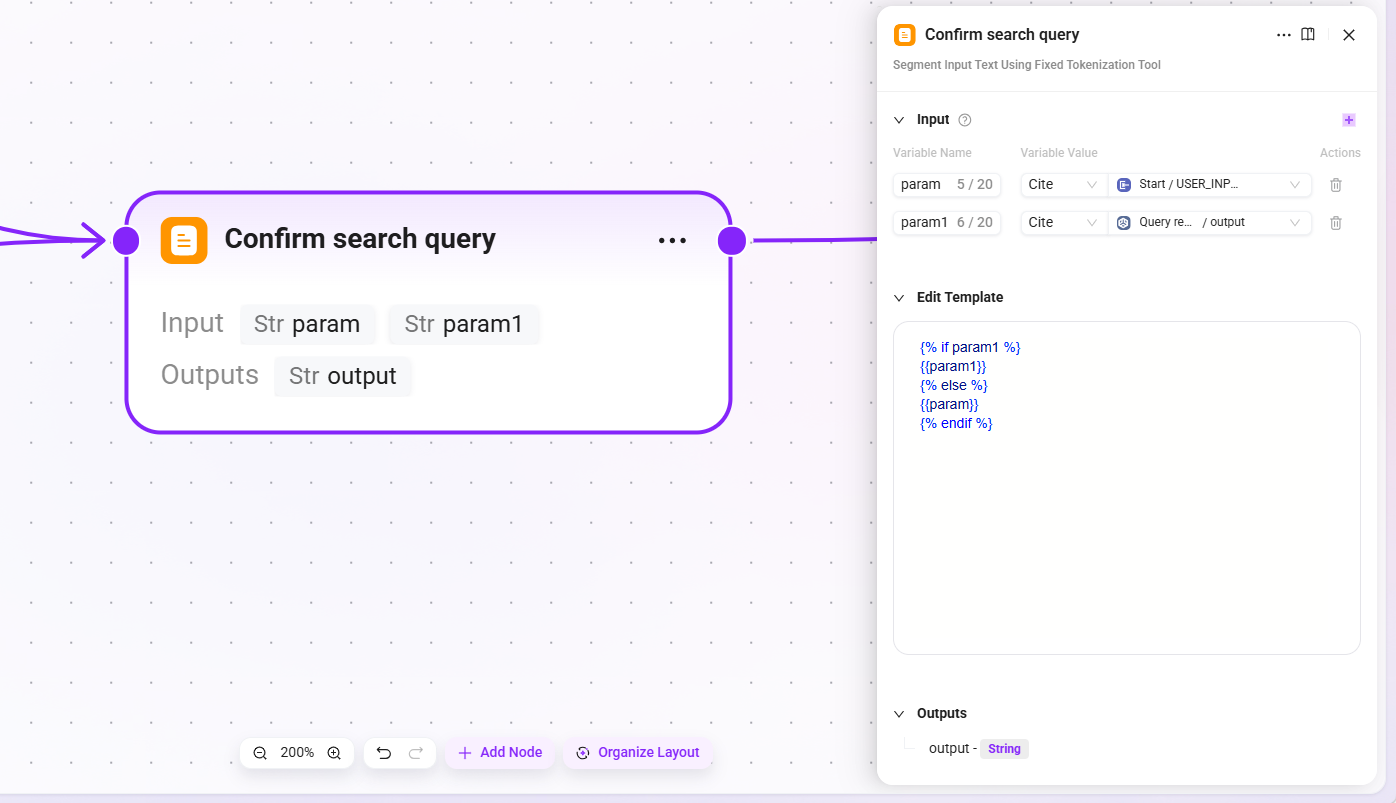
4. Confirm search query(検索クエリ確認)
- 入力::
param(元のユーザー入力)、param1(クエリ書き換え後の結果) - 出力:
output(最終的に確定した検索クエリ)
このノードにより、書き換えの有無にかかわらず、確定したクエリ文が下流の検索ノードへ渡されることが保証されます。
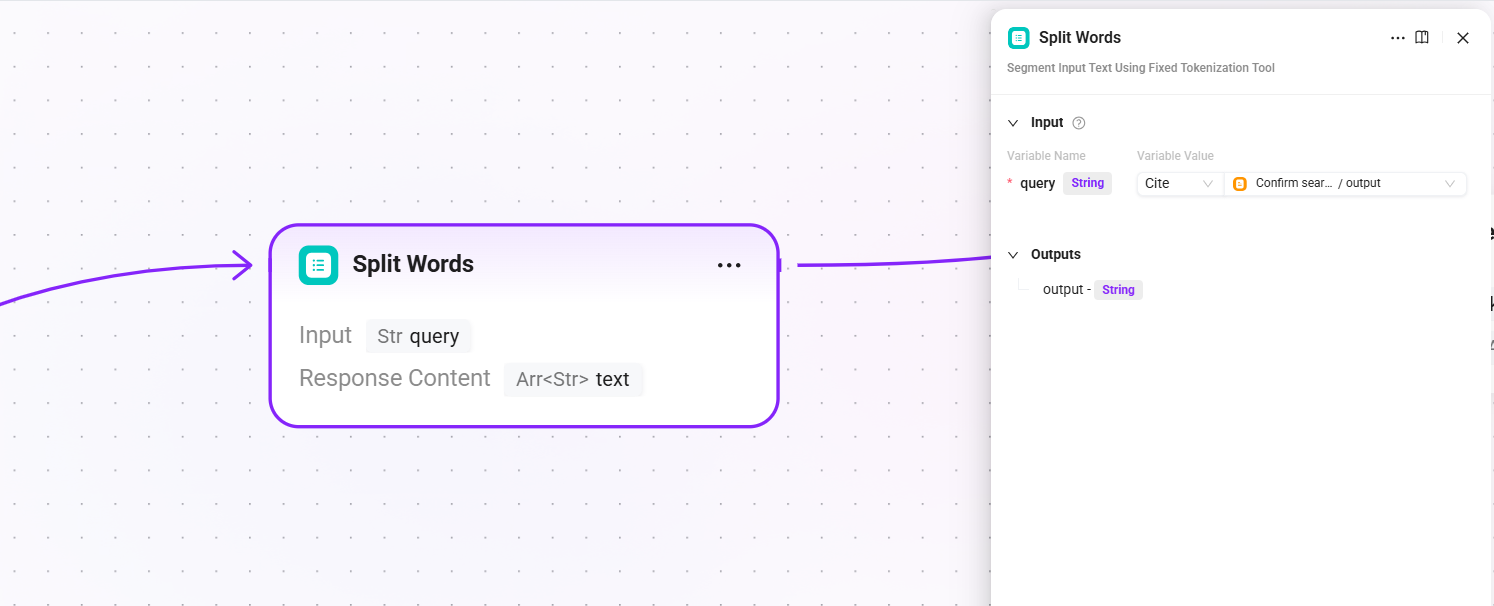
5. Split Words(分かち書き)
- 入力:
query(検索クエリ確定後の最終クエリテキスト) - 出力:
text(分かち書き結果。全文検索用キーワードとして使用)
クエリに対して分かち書き処理を行い、後続の QA 検索およびドキュメント検索の全文一致チャネルで使用するキーワードを抽出します。
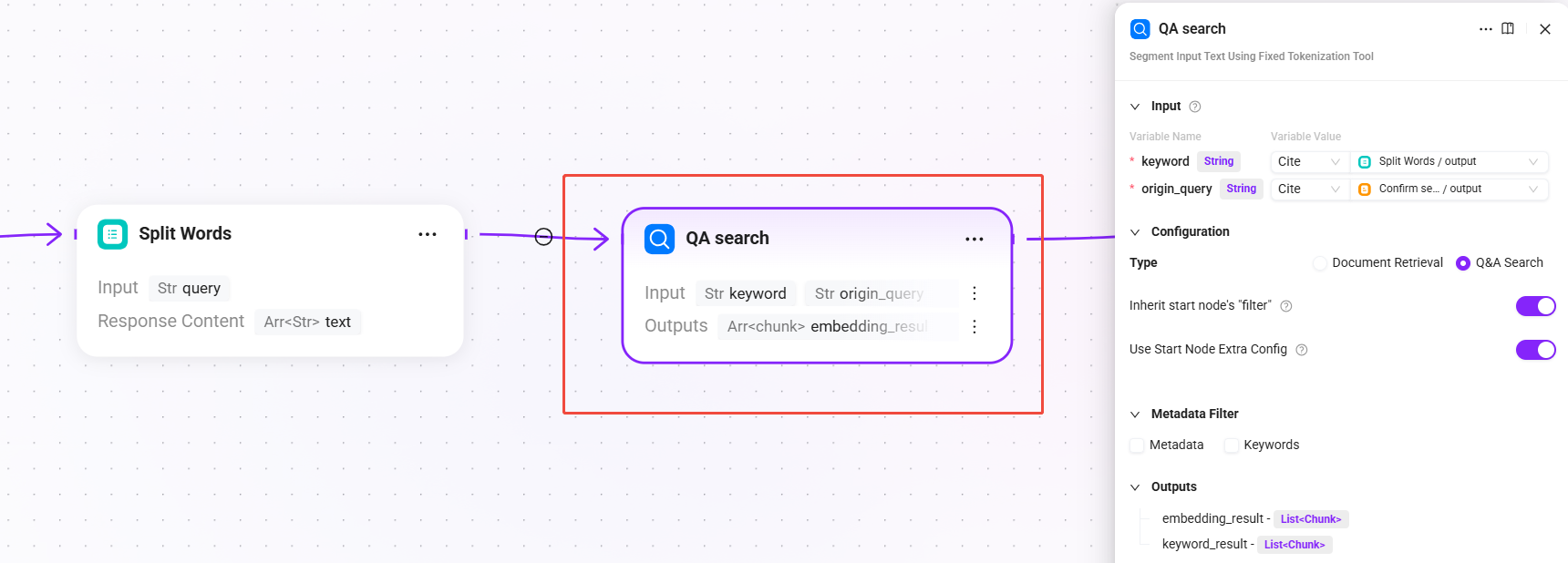
6. QA search(QA ナレッジ検索)
- 入力:
keyword(分かち書き後のキーワード)、origin_query(検索クエリ確定後の最終クエリテキスト) - 設定:
Q&A 検索を選択し、デフォルトで開始ノード filters を継承と開始ノード extra_config を継承を有効化 - 出力:
embedding_result(QA ナレッジベースの検索結果)、keyword_result(キーワードベース全文検索による QA 一致結果)
まず QA 問答ペアのナレッジベースから検索します。QA ナレッジベースには通常、整理済みの標準Q&Aペアが含まれており、ヒット率が高く、回答品質も安定しています。
フェーズ2:多段階リランキングと条件付きフォールバック
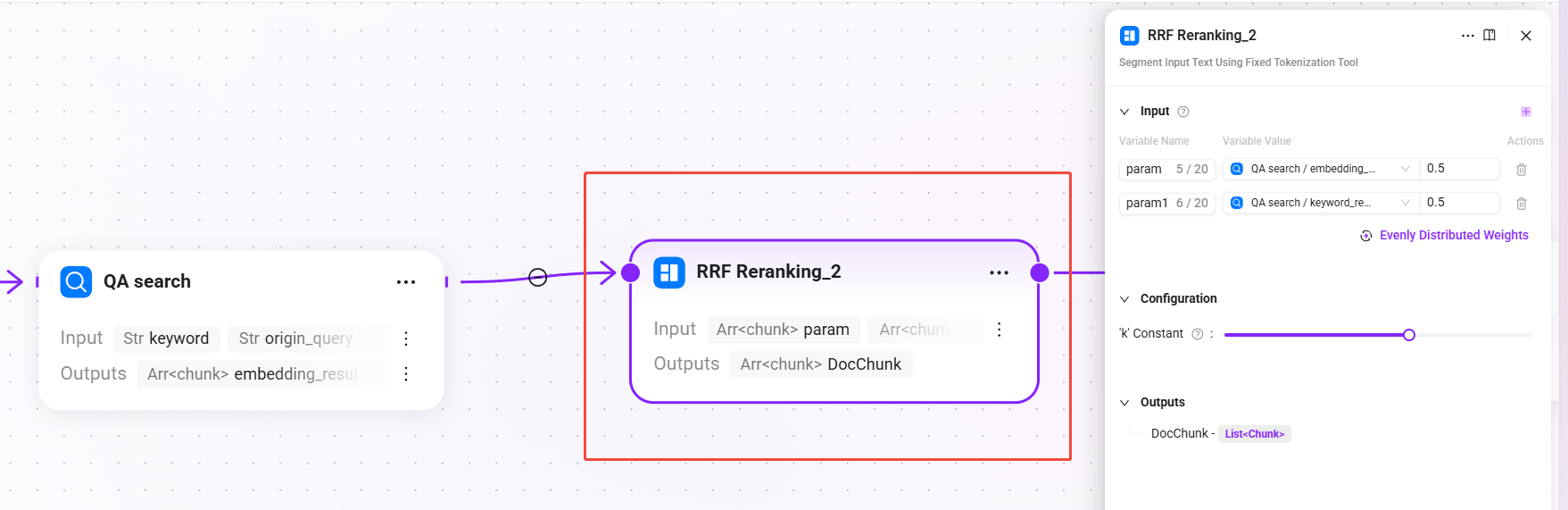
7. RRF Reranking_2(RRF 融合リランキング)
入力テキストを固定の分かち書きツールで分かち書き処理します
- 入力:
param(QA 検索の意味ベクトル再取得結果)、param1(QA 検索のキーワード全文一致再取得結果)- 2系統の入力重みは均等で、それぞれ 0.5
- 設定:
-
- k 定数:
60(0-100、順位が最終スコアに与える減衰速度を制御するために使用。値が大きいほど、下位結果の重み減衰は緩やかになります)
- k 定数:
-
- 出力:
DocChunk(リランキング後のドキュメント断片)
RRF(Reciprocal Rank Fusion)アルゴリズムを使用して QA 検索結果を融合ソートし、複数経路の再取得順位情報を統合して、統一された関連度ランキングを生成します。
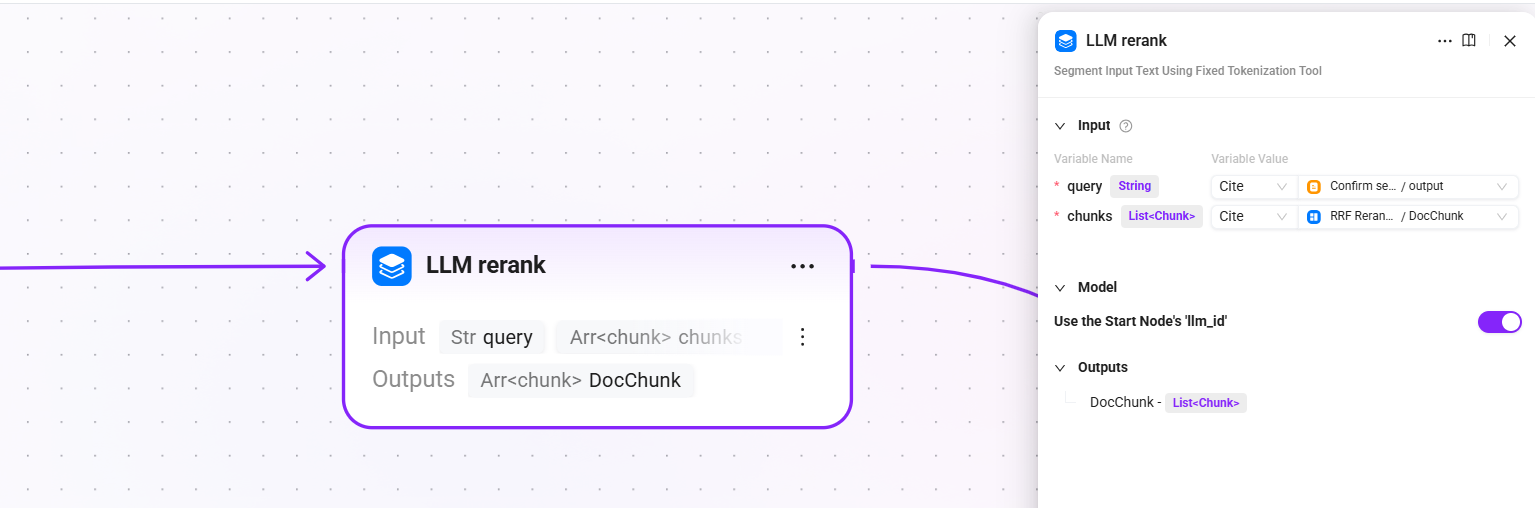
8. LLM rerank(LLM 精密リランキング)
- 入力:
query(検索クエリ確定後の最終クエリテキスト)、chunk(リランキング後のドキュメント断片) - 設定:開始ノードで設定した LLM(
llm_id)を継承 - 出力:
DocChunk(精密リランキング後の断片)
LLM を呼び出して候補断片に対し意味レベルの精密リランキングを行い、各断片とユーザー質問との関連度を個別に判断します。従来の Reranker モデルよりも高い意味理解能力を持ちます。
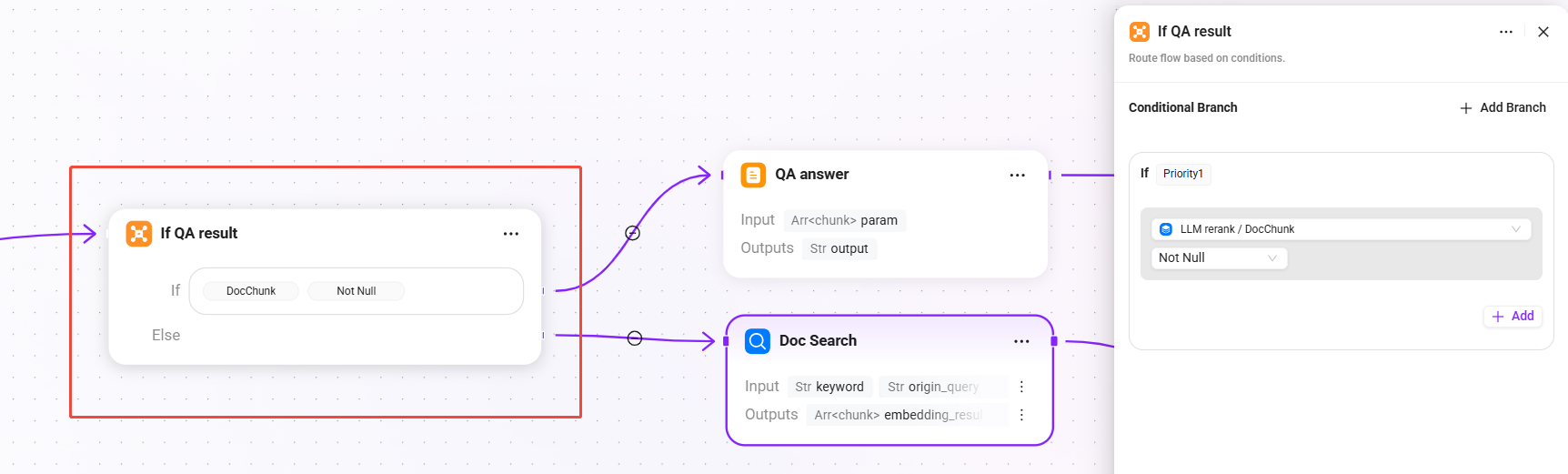
9. If QA result(条件判定 - QA 結果が有効か)
- 条件:
DocChunkが空でない場合、QA 検索 + リランキングの結果を直接使用 - else:QA 結果が空の場合、ドキュメントのフォールバック検索を起動
これは本 Pipeline の重要な設計です。まず QA ナレッジベースの高品質な回答を優先し、QA でヒットしない場合にのみドキュメント断片検索へフォールバックすることで、回答品質と再取得カバレッジを両立します。
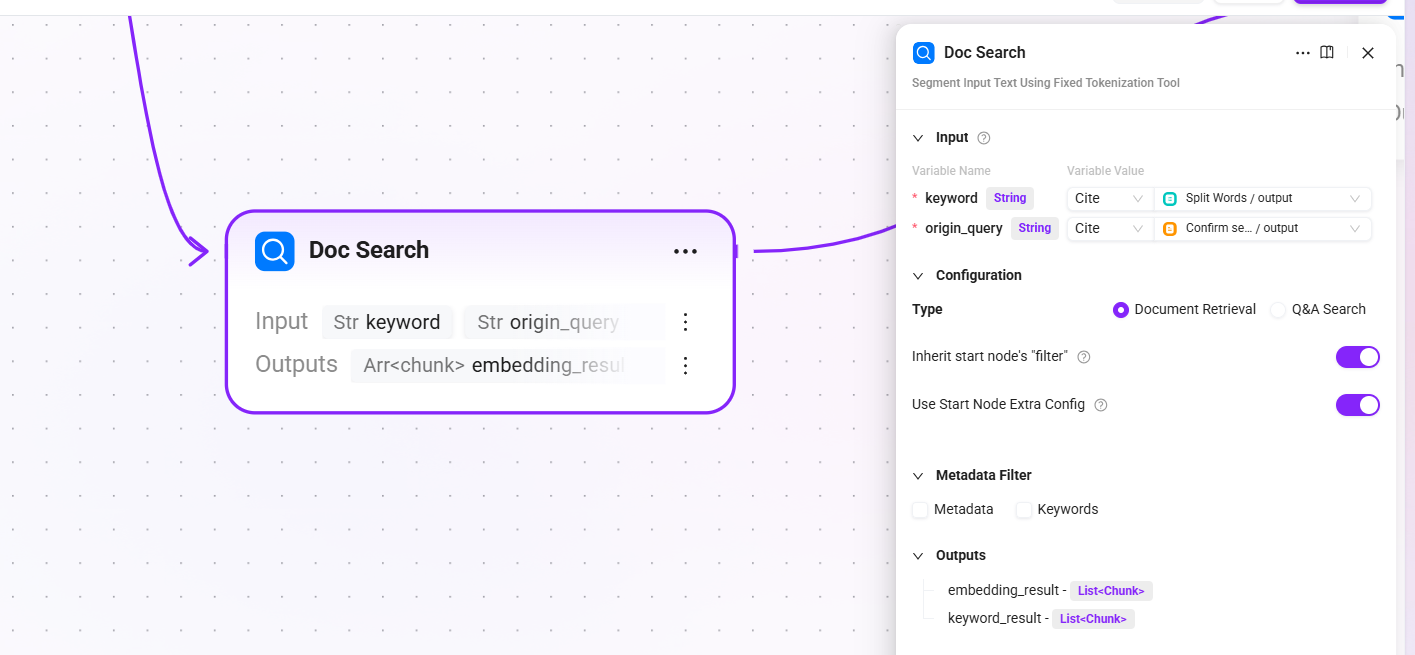
10. Doc Search(ドキュメント検索 - フォールバックチャネル)
- 入力:
keyword(分かち書き後のキーワード)、origin_query(確認後の最終クエリテキスト) - 設定:
ドキュメント検索を選択し、デフォルトで開始ノード filters を継承と開始ノード extra_config を継承を有効化 - 出力:
embedding_result(意味ベクトル検索でヒットしたドキュメント断片リスト)とkeyword_result(キーワード全文一致でヒットしたドキュメント断片リスト)
QA 検索で結果が得られない場合、前処理段階で保存されたドキュメント断片からベクトル + 全文融合検索を行い、ユーザーの質問が無回答にならないようにします。
11. RRF Reranking_1(ドキュメント検索リランキング)
- 入力:
param(ドキュメント検索の意味ベクトル再取得結果)、param1(ドキュメント検索のキーワード全文一致再取得結果) - 設定:
k定数:60(QA 検索リランキングと同じ減衰制御値を使用し、ランキング戦略の一貫性を確保)
- 出力:
DocChunk(リランキング後のドキュメント断片)
ドキュメントのフォールバック検索結果についても同様に RRF 融合リランキングを行い、返却結果の関連度ランキング品質を保証します。
フェーズ3:回答生成と出力
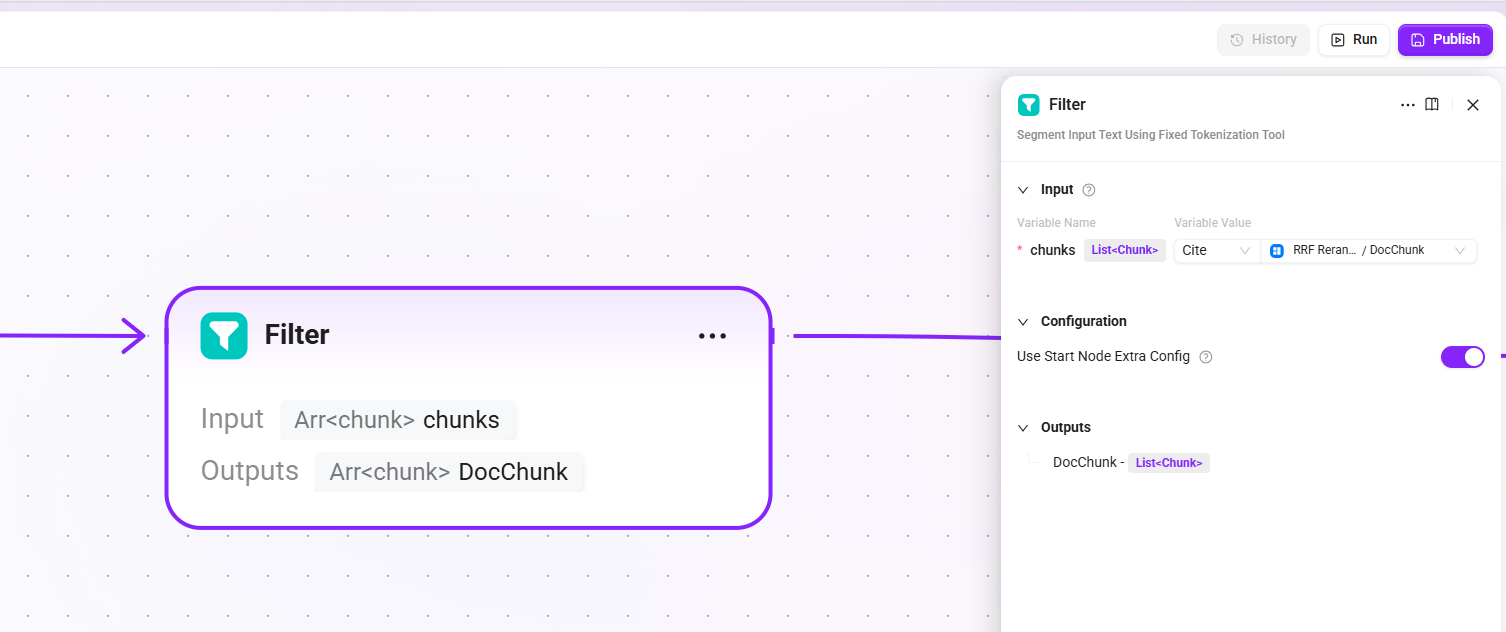
12. Filter(フィルタリング)
- 入力:
chunks(ドキュメント検索リランキング後の候補断片リスト) - モデル:開始ノードで設定した LLM(
llm_id)を継承 - 出力:
DocChunk(LLM による選別後に残された高関連断片。ノイズや低関連内容を除去)
最終的に再取得された断片をフィルタリングし、低関連度または重複断片を除去して、LLM に渡すコンテキストを簡潔かつ有効なものにします。
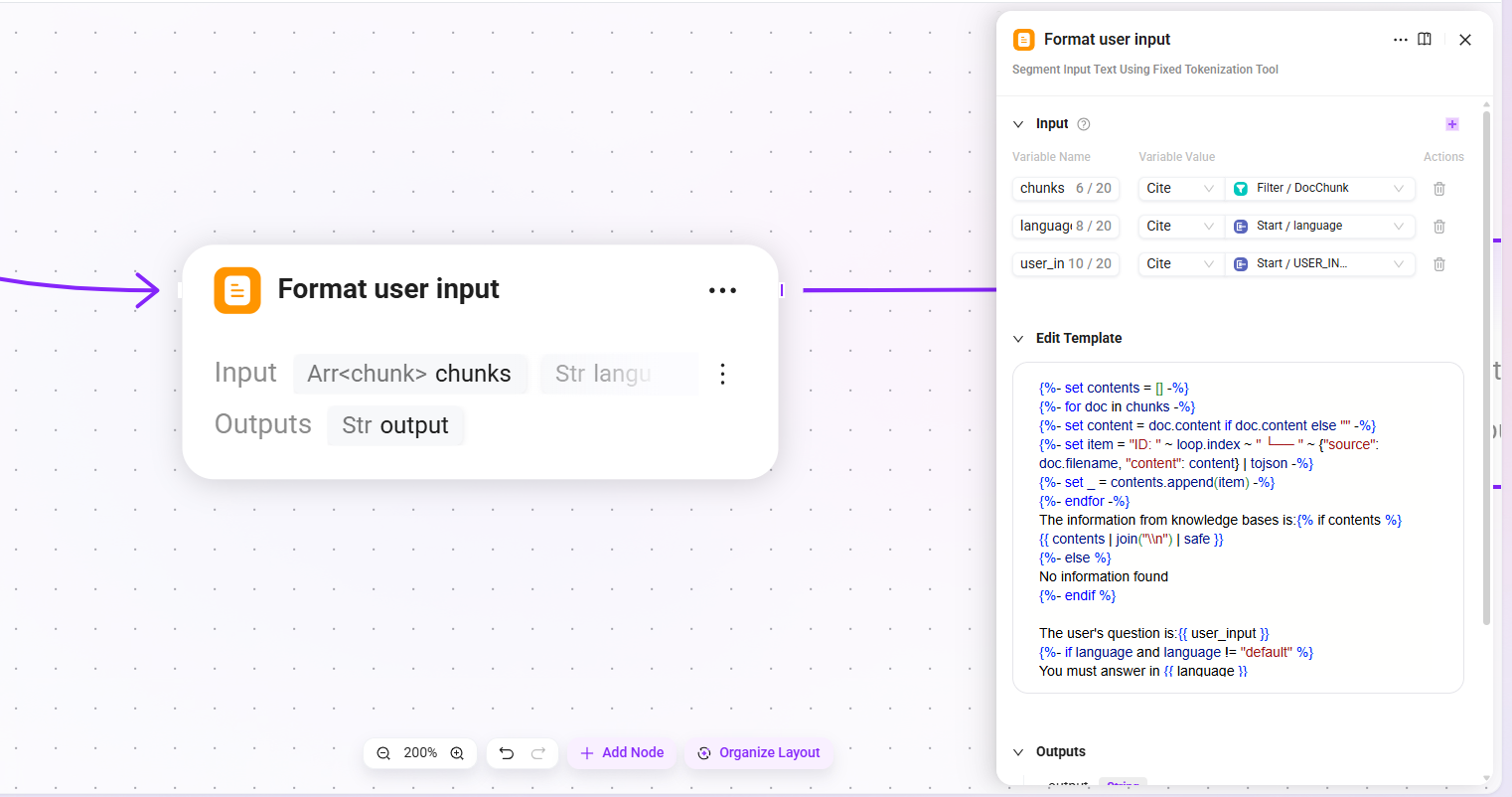
13. Format user input(ユーザー入力の整形)
- 入力:
chunks(フィルタリング後の高関連ドキュメント断片リスト)、language(ユーザー入力の言語)、user_input(ユーザー入力内容) - 出力:
output(整形後のユーザーコンテキスト)
再取得したドキュメント断片とユーザー質問を指定テンプレートに従って連結し、LLM のユーザー側入力を構成します。
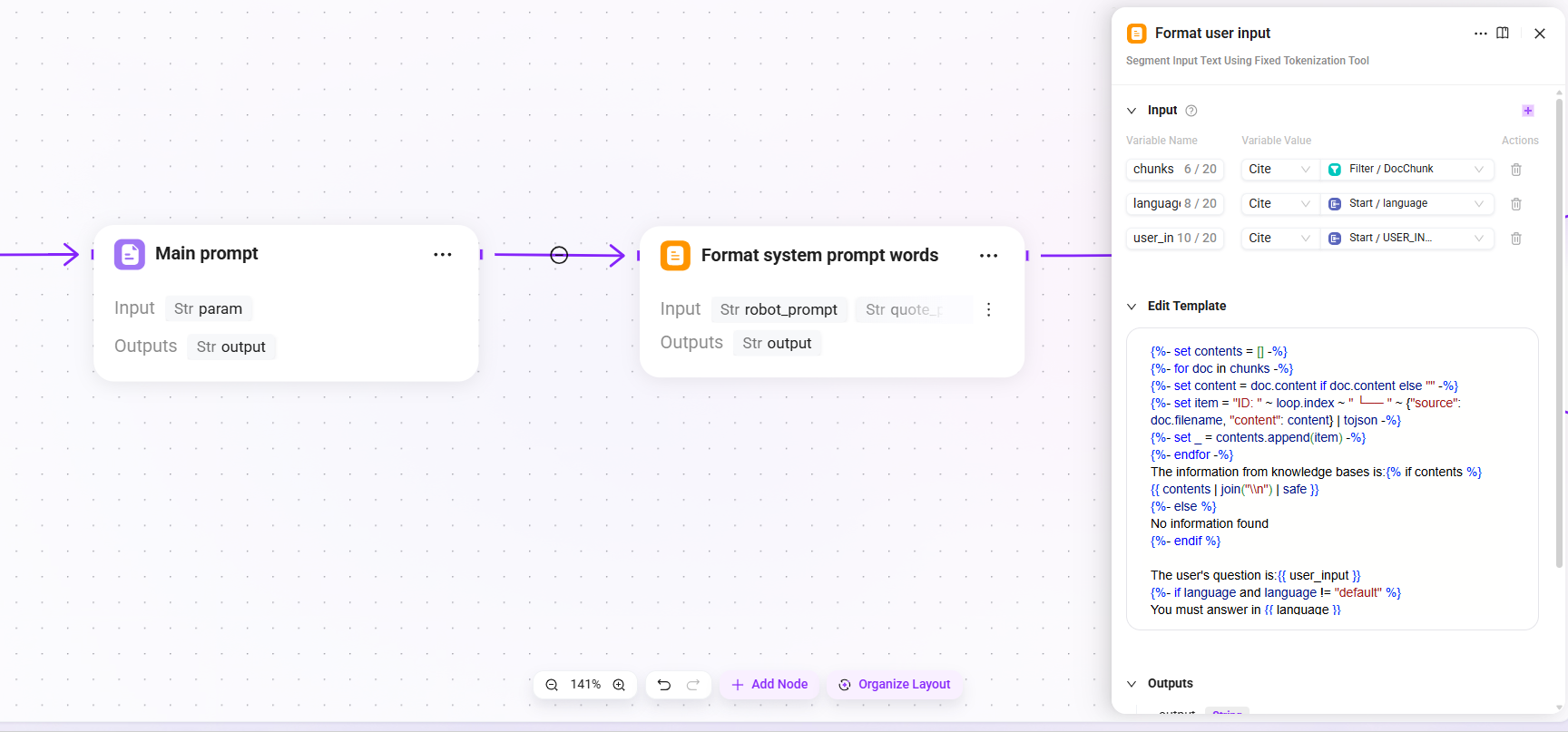
14. Main prompt(メインプロンプト組み立て)
- モード:文字列連結
- 入力:
param(整形後のユーザーコンテキスト) - 出力:
output(組み立て後のメインプロンプト内容)
15. Format system prompt words(システムプロンプト整形)
- 入力:
robot_prompt(アシスタントプロンプト)、quote_prompt(組み立て後のメインプロンプト内容)、time_diff_hour(実際のタイムゾーン) - 出力:
output(完全な System Prompt。LLM のシステムレベル指示として使用)
Agent のペルソナ記述、行動制約、検索コンテキストテンプレートを統合し、完全な System Prompt を構成します。
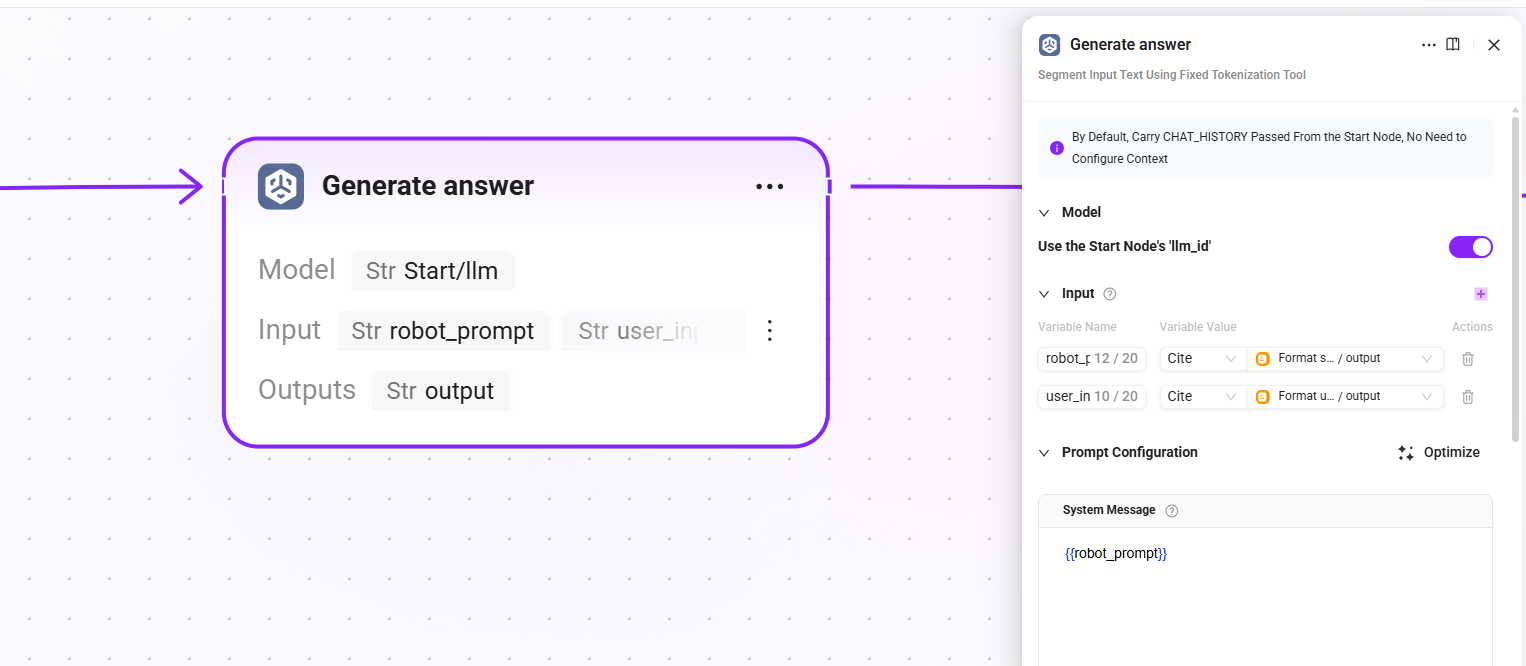
16. Generate answer(回答生成)
- モデル:開始ノードで設定した LLM(
llm_id)を継承 - 入力:
robot_prompt(完全なシステムプロンプト)、user_input(整形後のユーザーコンテキスト) - 出力:
output(LLM が生成した最終回答テキスト)
中核となる生成ノードです。LLM は検索されたドキュメント断片とシステムプロンプトに基づいて、ユーザー向けの最終回答を生成します。
17. Reference filtering(引用フィルタリング)
- 入力:
answer(LLM が生成した最終回答テキスト)、retrival_docs(フィルタリング後の高関連ドキュメント断片リスト) - 出力:
answer(回答)、reference(retrieval_docsから選別された、回答内で実際に引用または根拠として使用された断片リスト)
候補断片の中から、実際に回答で引用された断片を選別し、参考ソースとしてユーザーに表示することで、回答の追跡可能性を高めます。
18. QA answer(QA 回答処理)
- 入力:
param(精密リランキング後の断片) - 出力:
output(処理後の回答構造)
QA チャネルで生成された標準回答を整形処理します。
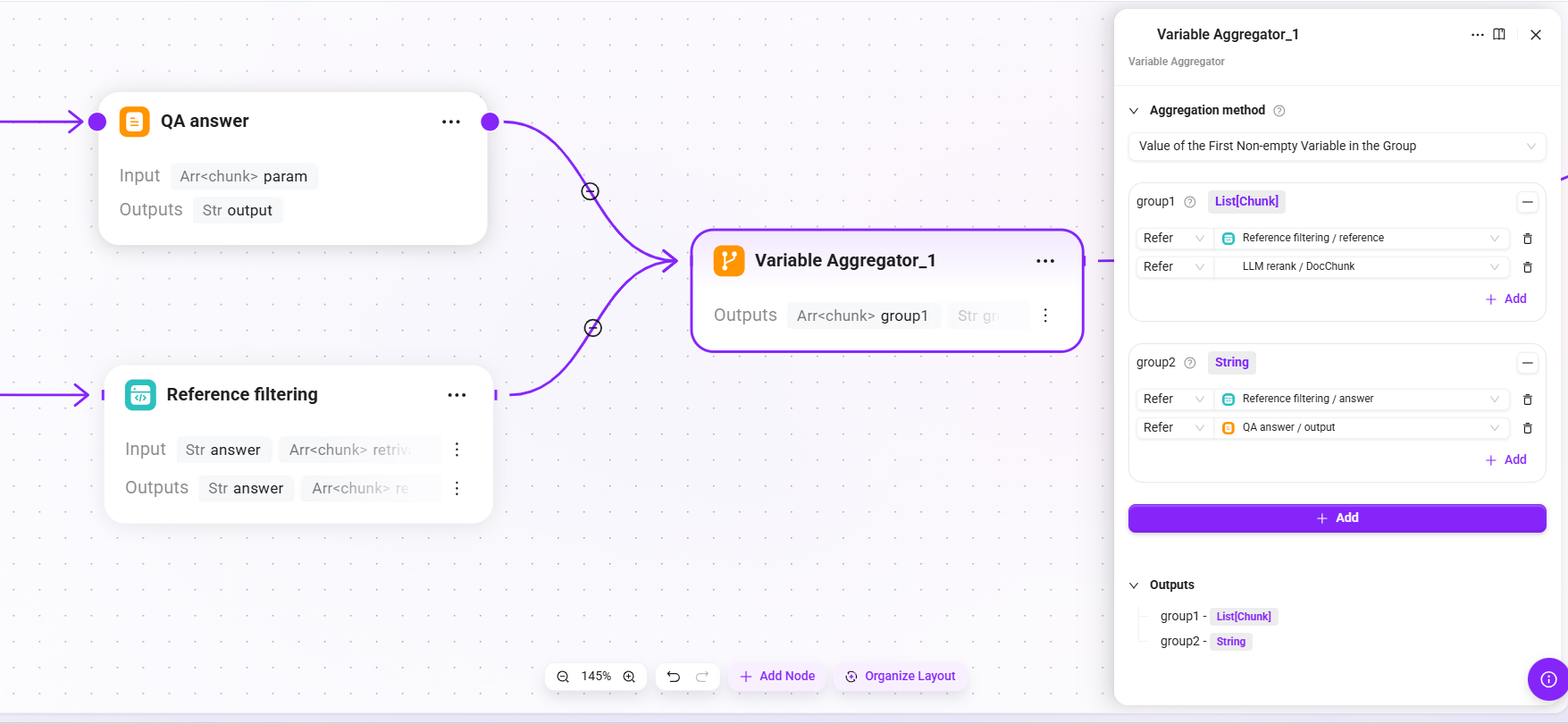
19. Variable Aggregator_1(結果集約)
- 集約戦略:グループ内の最初の非空変数の値
- 入力:
- group1:
- Reference filtering が出力した
referenceリスト。 - LLM Rerank 精密リランキング後の断片
- Reference filtering が出力した
- group2:
- Reference filtering が出力した
answerテキスト。 - QA answer が出力した
output。
- Reference filtering が出力した
- group1:
- 出力:
group1(最終的に使用される引用ソースリスト)、group2(最終的にユーザーへ返す回答テキスト)
QA 回答と引用フィルタリングの出力を統合し、最終返却構造を形成します。
20. End(フロー終了)
- 出力:
chunks(集約後のgroup1、すなわち最終確定した参考引用リスト)、answer(集約後のgroup2、すなわち最終的にユーザーへ返す回答テキスト)
最終結果を呼び出し元(Agent)へ出力します。回答内容と参考引用を含みます。
完全な検索チェーンのまとめ
検索テストと公開
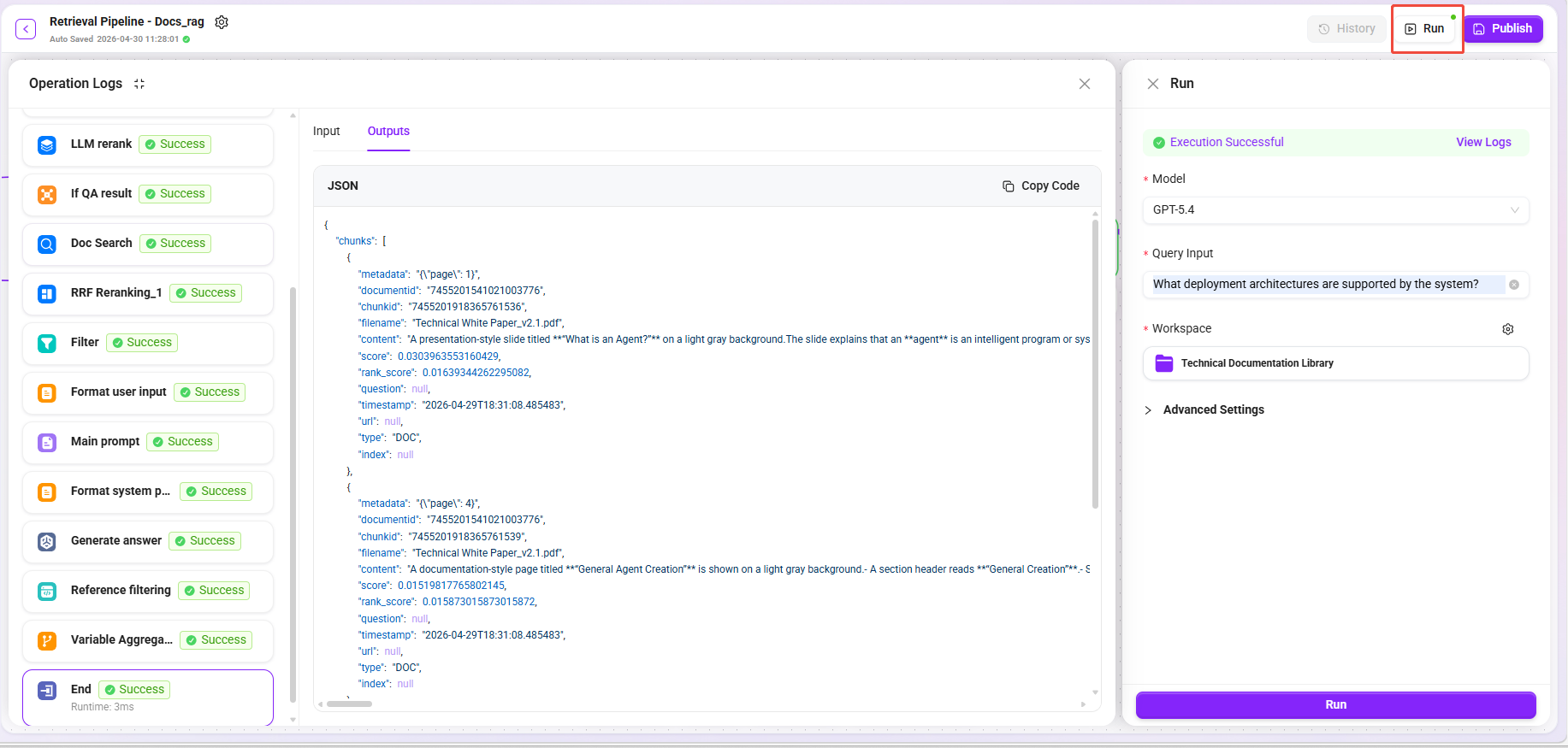
- 「試運転」 ボタンをクリックします。 2,モデルを選択:GPT-5.4
- 異なるタイプの質問を入力します:
| テスト質問 | 期待される再取得タイプ |
|---|---|
システムがサポートするデプロイアーキテクチャには何がありますか? | テキスト段落 + アーキテクチャ図の説明 |
各モジュールの性能指標比較 | 表要約関連の断片 |
データ処理フローはどのようなものですか? | フローチャート説明 + 関連テキスト段落 |
- ナレッジベースを選択:Technical Documentation Library
- 再取得結果が多次元データ(原文 + 要約 + 画像説明 + 表要約)を含んでいることを確認します。
- テスト結果が期待どおりであることを確認したら、「公開」 をクリックします。
ステップ2:Agent を作成し、検索 RAG Pipeline を適用する
設定済みの検索 Pipeline を Agent に関連付け、エンドツーエンドのインテリジェントQ&A検証を完了します。
Agent の作成または設定
- AI Asset モジュール → Agent 管理 に入ります。
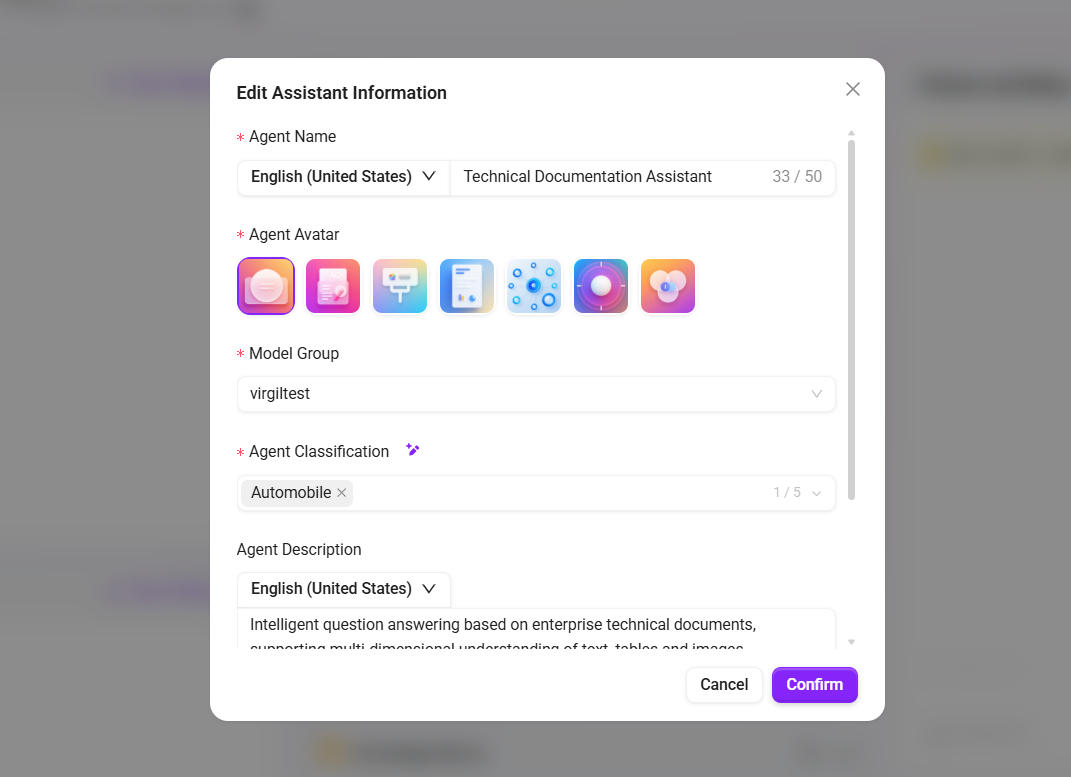
- 基礎Agentを作成するか、既存の Agent を選択し、以下を入力します:
- 名称:
技術ドキュメントアシスタント - 説明:
企業技術ドキュメントに基づくインテリジェントQ&A。テキスト、表、画像の多次元理解をサポート
- 名称:
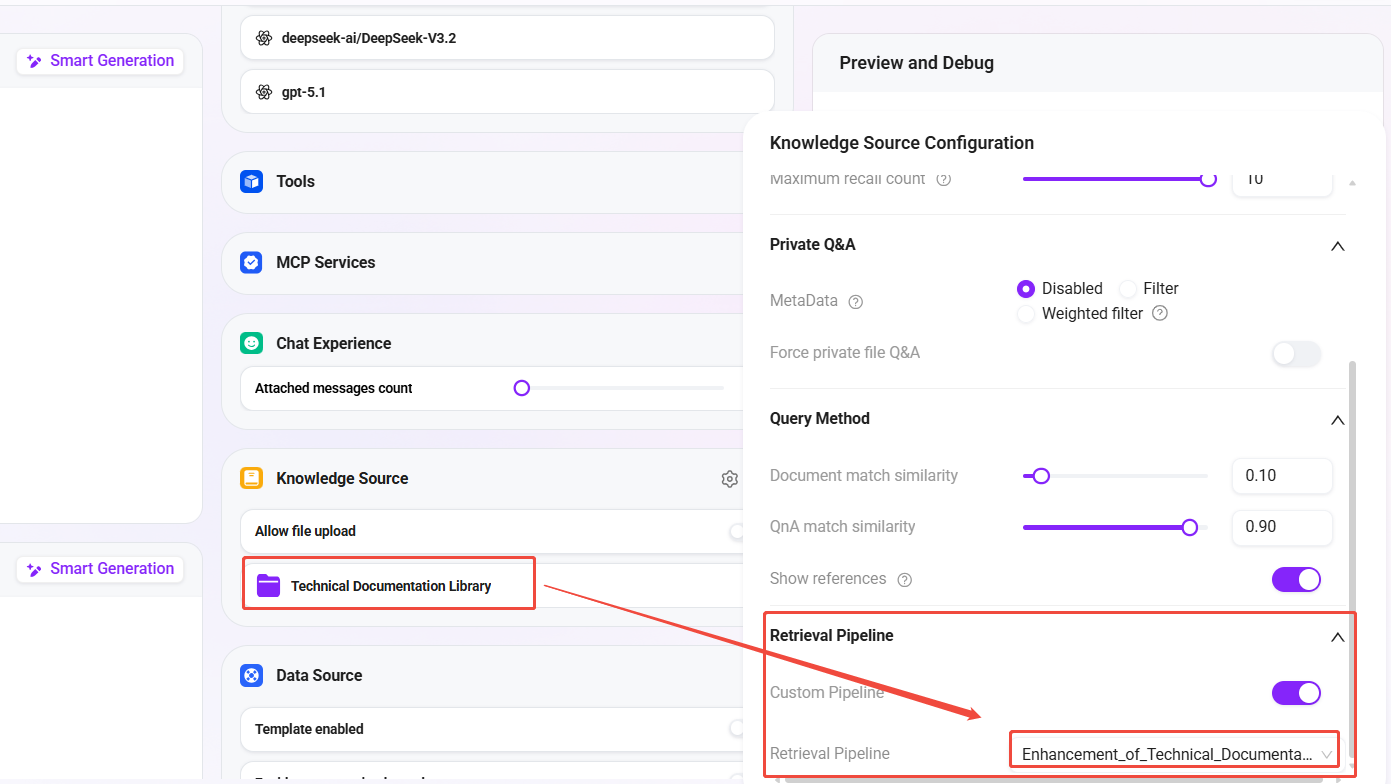
- Agent の ナレッジベース設定 で:
- 関連付けるナレッジベース:
技術ドキュメントライブラリ(前回作成したナレッジベース) - 検索 Pipeline:
技術ドキュメント強化検索を選択
- 関連付けるナレッジベース:
- Agent 設定を保存します。
インテリジェントQ&A効果の検証
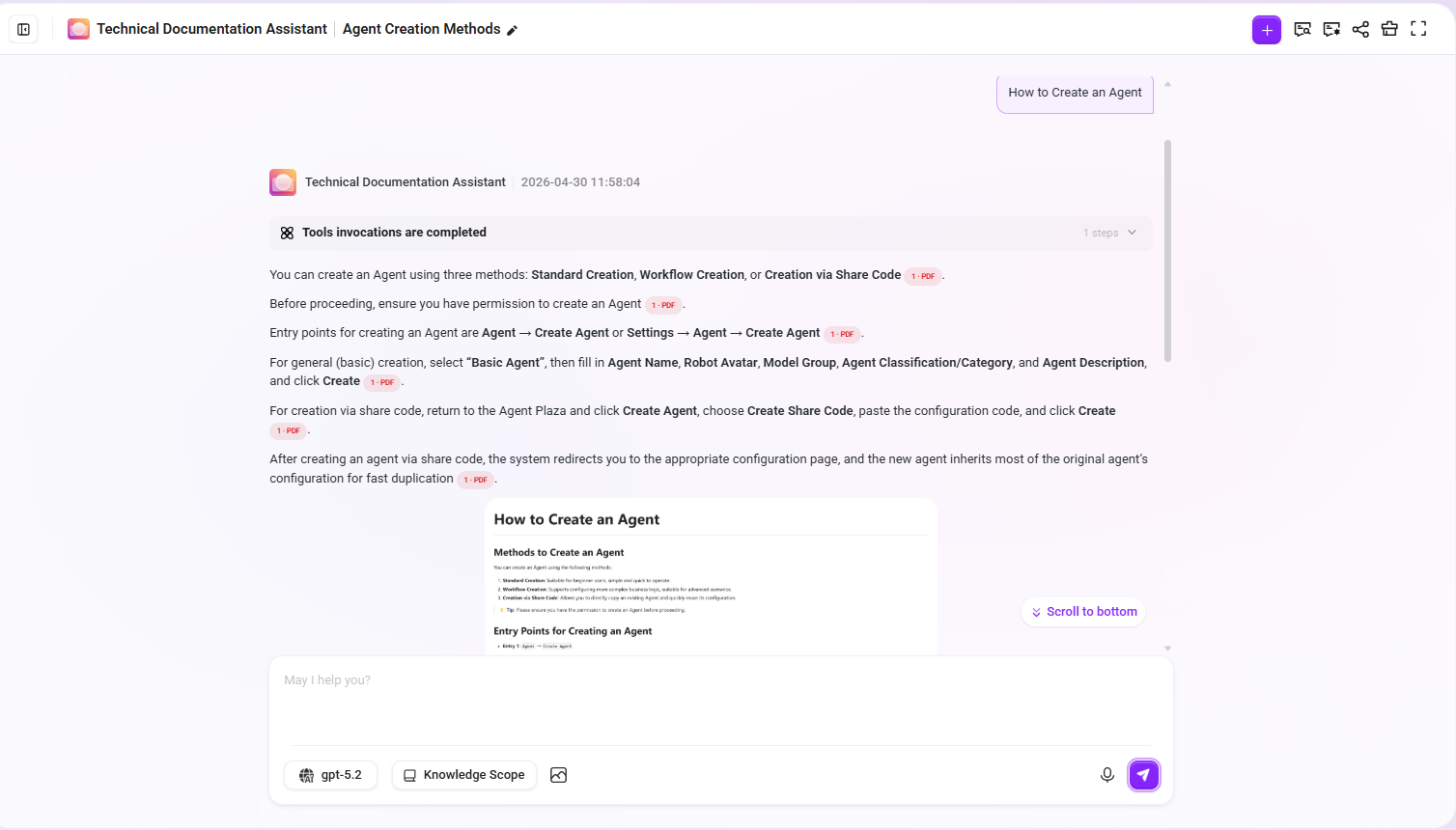
Agent の対話画面に入り、以下のテストを行います:
質問:Agent をどのように作成しますか?
期待される効果:
- 回答内容は、ドキュメント内の Agent 作成に関する段落から取得される
- 引用断片には、段落原文および要約強化情報が含まれる
- ドキュメント内に関連する手順図がある場合、その画像も再取得に参加する
効果まとめ
前回(前処理 Pipeline + ナレッジベース)と本記事(検索 Pipeline + Agent)を組み合わせることで、深いドキュメント理解能力を備えたエンドツーエンドのインテリジェントQ&Aシステムを完成させました:
| 工程 | 設定内容 | 効果 |
|---|---|---|
| 前処理 Pipeline | テキスト抽出 → インテリジェント分割 → 多次元強化 → 保存 | ドキュメントが十分に理解・索引化され、テキスト/画像/表のいずれも検索可能 |
| ナレッジベース RAG Pipeline モード | ナレッジベース作成時に前処理 RAG Pipeline を直接バインド | アップロードと同時に処理され、全チェーン前処理を自動実行 |
| 検索 Pipeline | クエリ書き換え → デュアルチャネル検索 → 多段階リランキング → LLM 生成 | ユーザー意図を理解し、正確に再取得し、インテリジェントに回答を生成 |
| Agent 関連付け | ナレッジベース + 検索 Pipeline のバインド | エンドツーエンドのインテリジェントQ&Aが利用可能 |
検索 Pipeline 設計のハイライト
- クエリ書き換え:対話履歴に基づいて指示語を含む質問を自動補完し、複数ターン対話での検索精度を向上
- QA 優先 + ドキュメントフォールバック:デュアルチャネル戦略により、回答品質とカバレッジを両立
- 多段階リランキング:RRF 融合ソート + LLM 意味精密リランキングにより、Top-K 品質を段階的に向上
- エンドツーエンド生成:検索 Pipeline に LLM 生成工程を内蔵し、検索から回答までを1本のチェーンで完結
- 引用トレーサビリティ:Reference filtering が回答で引用されたドキュメント断片を自動注記
さらなる最適化の提案
- クエリ書き換え Prompt の最適化:業務領域に応じて書き換えプロンプトをカスタマイズし、書き換え品質を向上
- RRF パラメータの調整:実際の再取得効果に応じて RRF の k 値パラメータを調整
- LLM rerank のコスト制御:呼び出し量が多い場合は、軽量な Reranker モデルで LLM 精密リランキングを代替することを検討
- QA ナレッジベースの拡張:高頻度Q&Aペアを継続的に補充し、QA チャネルのヒット率を向上
- 検索ログの監視:Pipeline 実行履歴を通じて、再取得品質の問題や応答時間のボトルネックを特定