Workflowを活用した複雑な業務Agentアシスタントの構築
SERVICEME NEXT では、基本的な方法で作成されたAgentはシンプルなQ&Aシーンにより適しており、機能は比較的限定的です。より複雑な業務ロジックや複数ステップの操作を実現したい場合は、Workflow(ワークフロー) を利用して高度なAgentを構築し、より多様な業務ニーズに対応できます。
本章では、具体的な事例を通じて、Workflowを使って複雑なプロセスを構築する方法を紹介します。
シナリオ例:契約書内容のセンシティブワード抽出
実際の業務では、契約書のテキストは通常長文で内容も複雑です。もし人手で一つ一つ照合し、センシティブワードが含まれているかを確認する場合、時間も労力もかかり、特にセンシティブワードの数が多い場合は見落としも発生しやすく、正確性の確保が難しくなります。
Workflowの機能を活用することで、ファイルアップロード、内容解析、センシティブワードの識別とマーキングをサポートするインテリジェントなAgentを構築し、以下の操作を自動で完了できます:
- ユーザーがアップロードした契約書ファイルを受け取る
- テキスト内容を自動解析する
- センシティブワードを検出・抽出する
- センシティブワードとその位置を含む結果を返す
このプロセスにより、ユーザーは手動で内容を確認する必要がなく、契約書内のセンシティブ情報を迅速に把握でき、審査の効率と正確性が大幅に向上します。
✅ ヒント:この種のAgentは、法務審査、コンテンツ審査、コンプライアンス管理などのシーンに特に適しています。
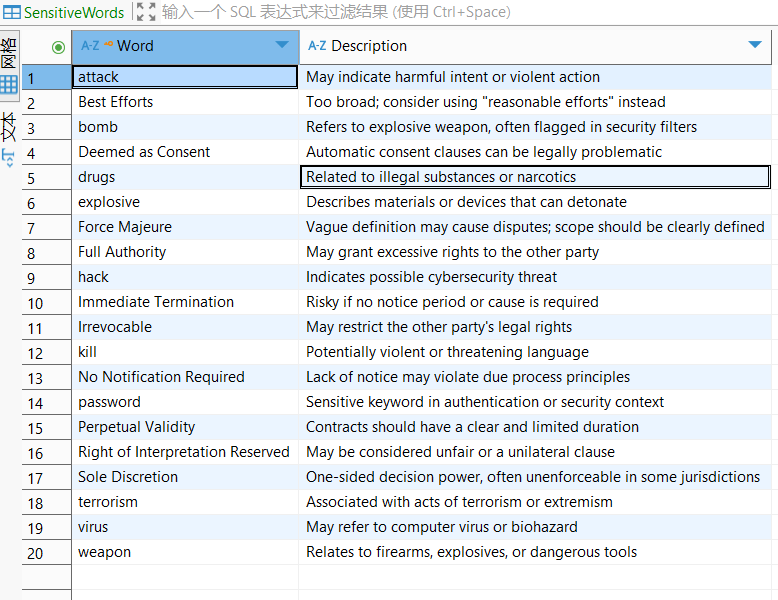
センシティブワードデータソースの準備
ワークフローを構築する前に、センシティブワードのデータを準備する必要があります。本ケースでは、センシティブワードはデータベースに保存されているため、Dataモジュールを通じてデータベースをデータソースとして追加し、データ同期を完了させます。
データ準備の前提条件
- センシティブワードデータがデータベース(テーブル名:
SensitiveWords)に書き込まれている - データベースの種類は
SQLServerで、ネットワーク経由でアクセス可能
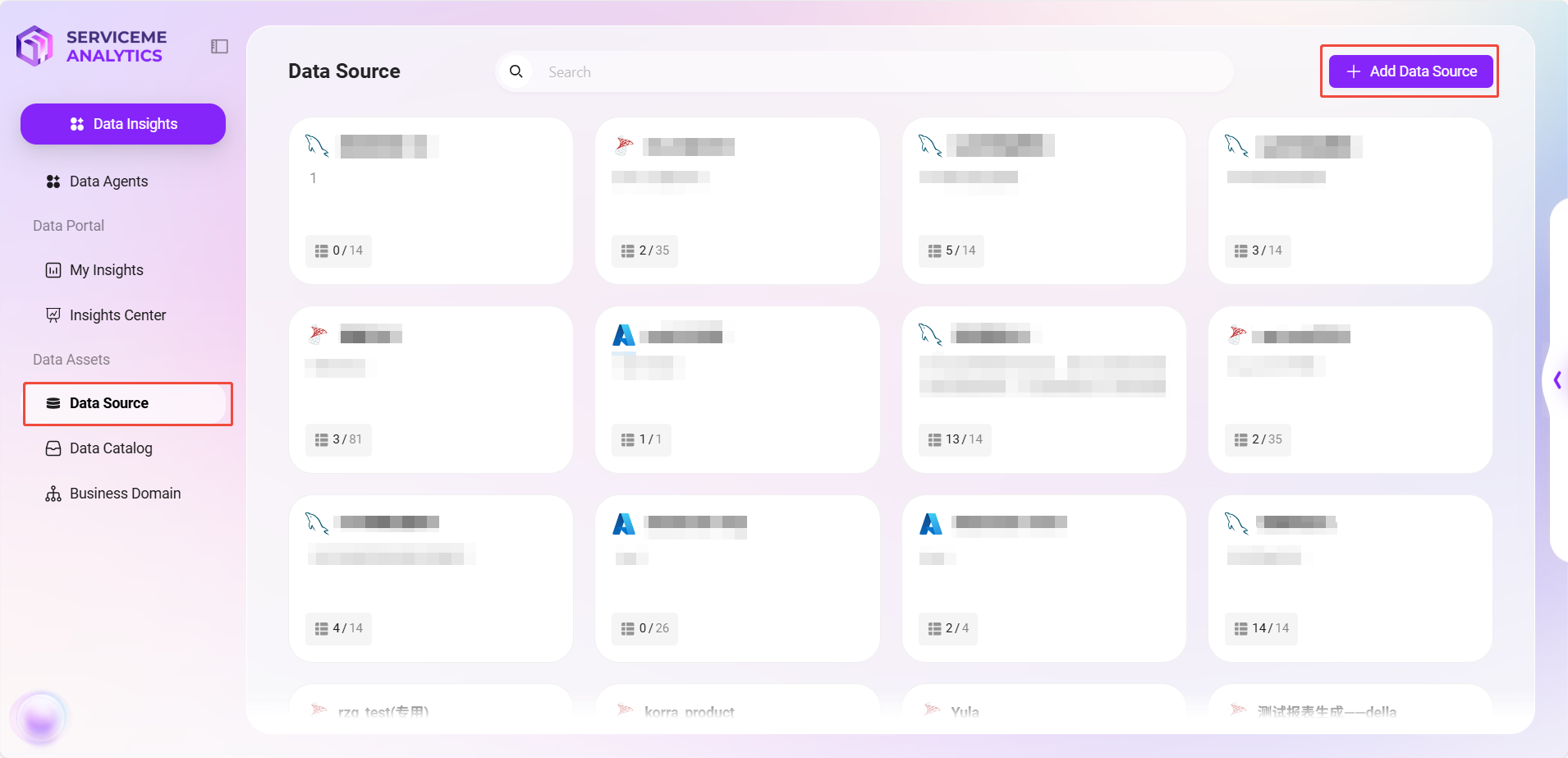
データソース追加手順
- Dataモジュールに入る
- SERVICEMEプラットフォームを開き、右側メニューの 「Data」 をクリックします。
- 左側で 「データソース」 を選択し、データソース管理ページに入ります。
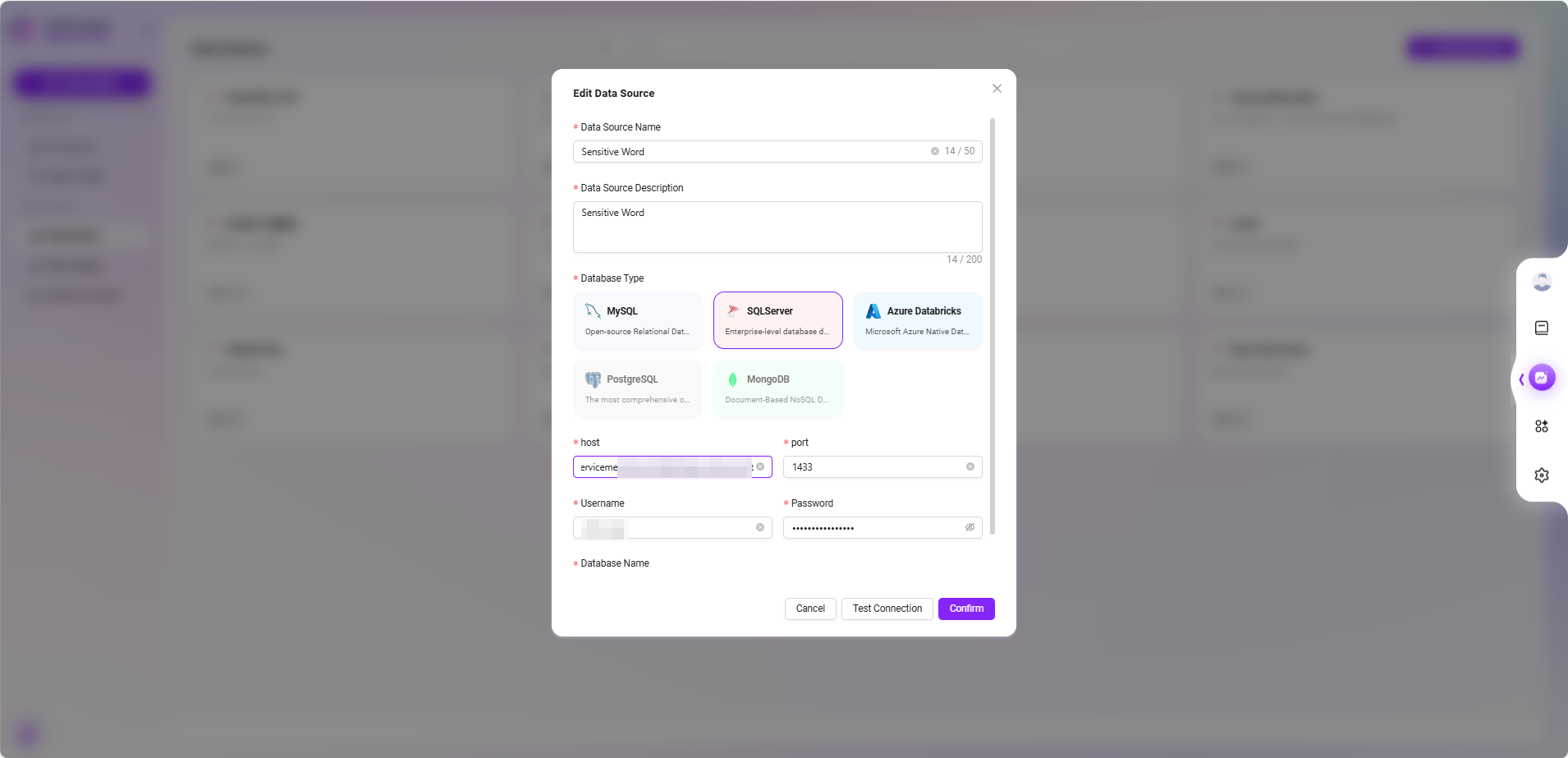
- データソースを追加
- 右上の 「データソース追加」 ボタンをクリックします。
- ポップアップの設定ウィンドウで以下の情報を入力します:
- データソース名:例
Sensitive Word - データベース種類:
SQLServerを選択 - 接続情報:
host、port、ユーザー名、パスワード、データベース名を含む
- データソース名:例
- 「接続テスト」 をクリックし、接続成功を確認したら 「確認」 をクリックして追加を完了します。
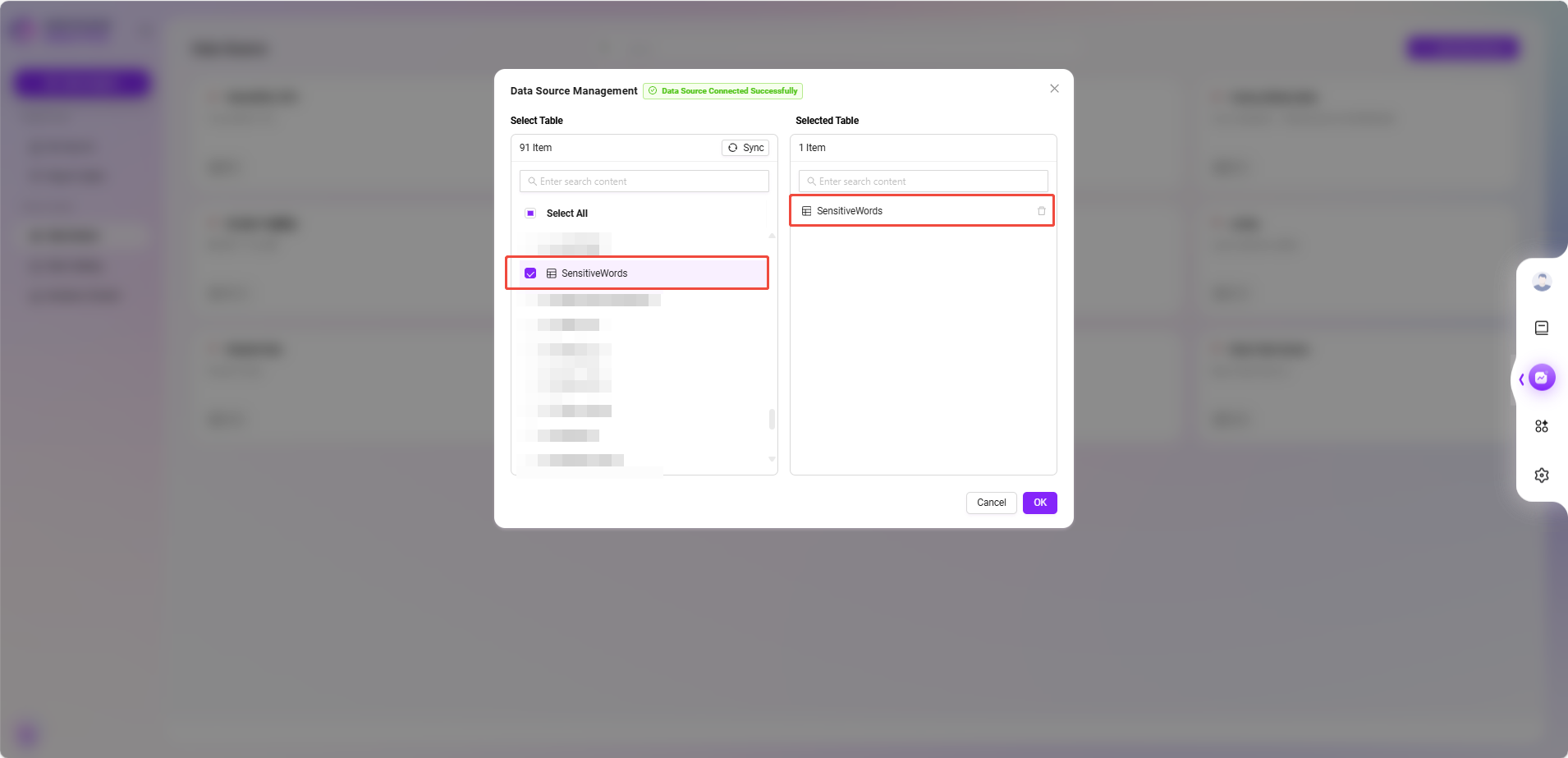
- データテーブルを選択
- データソースリストに戻り、作成したデータソース項目をクリックします。
- システムがデータベース内の利用可能なテーブルを表示するので、センシティブワードを含むテーブル(例:
SensitiveWords)にチェックを入れ、「確認」 をクリックして追加します。
- データディレクトリ同期
- 左側メニューで 「データディレクトリ」 を選択し、
Sensitive Wordデータソースを見つけてクリックします。 - 「同期」 操作を実行し、プラットフォームが最新データを取得できるようにします。
- 左側メニューで 「データディレクトリ」 を選択し、
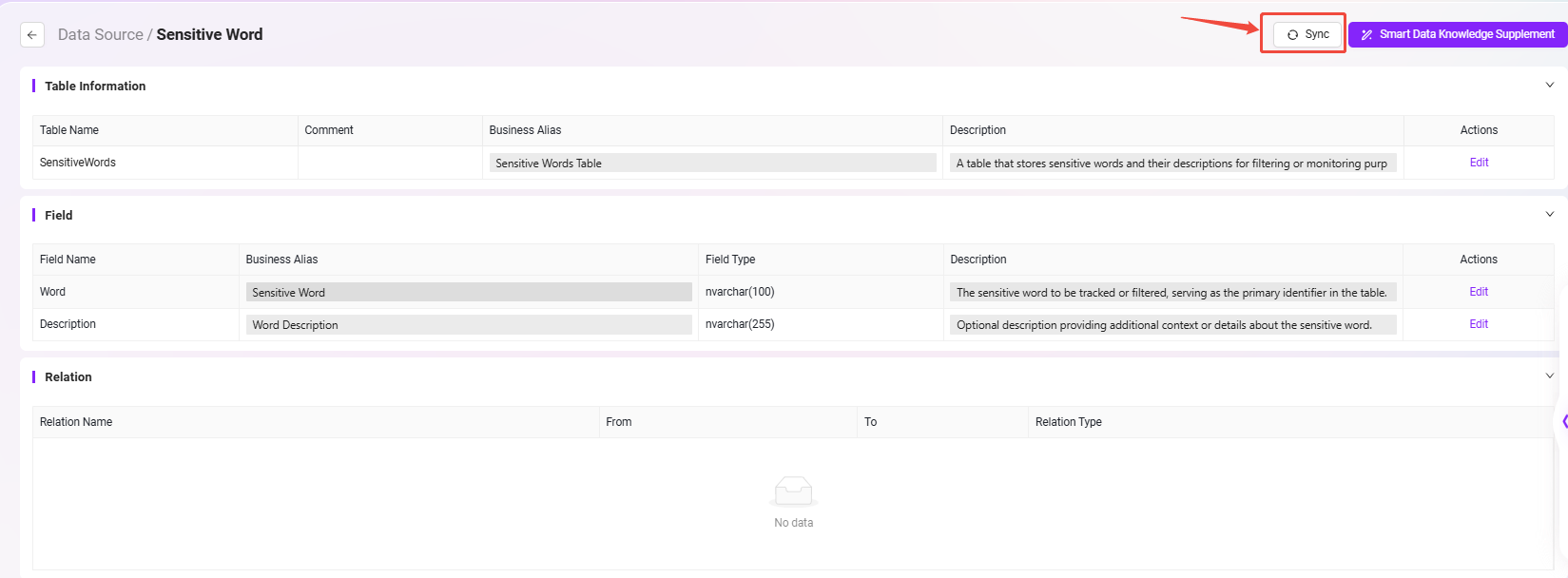
以上の手順を完了すると、センシティブワードのデータソース設定が完了します。今後のワークフローでは、このデータテーブルにノード経由でアクセスし、契約書内容のセンシティブワード抽出と照合を実現できます。
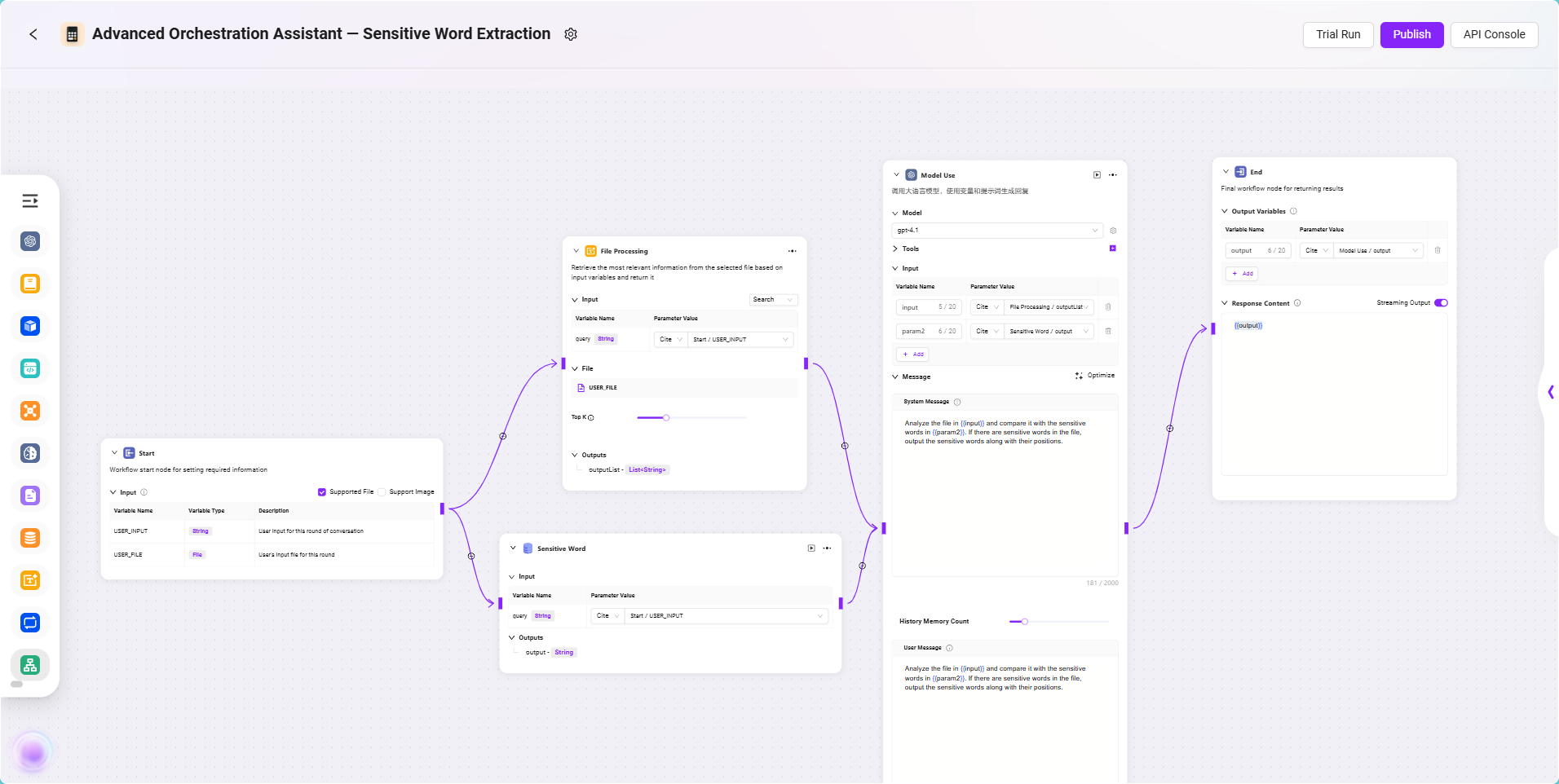
ワークフローで「Sensitive Word Extraction」Agentを作成
- SERVICEME NEXT のホーム画面に入り、左下の円形アイコンをクリックしてAgent Q&A画面に入ります。
- 左側メニューの 「その他のアシスタント」 をクリックし、アシスタント広場に入ります。
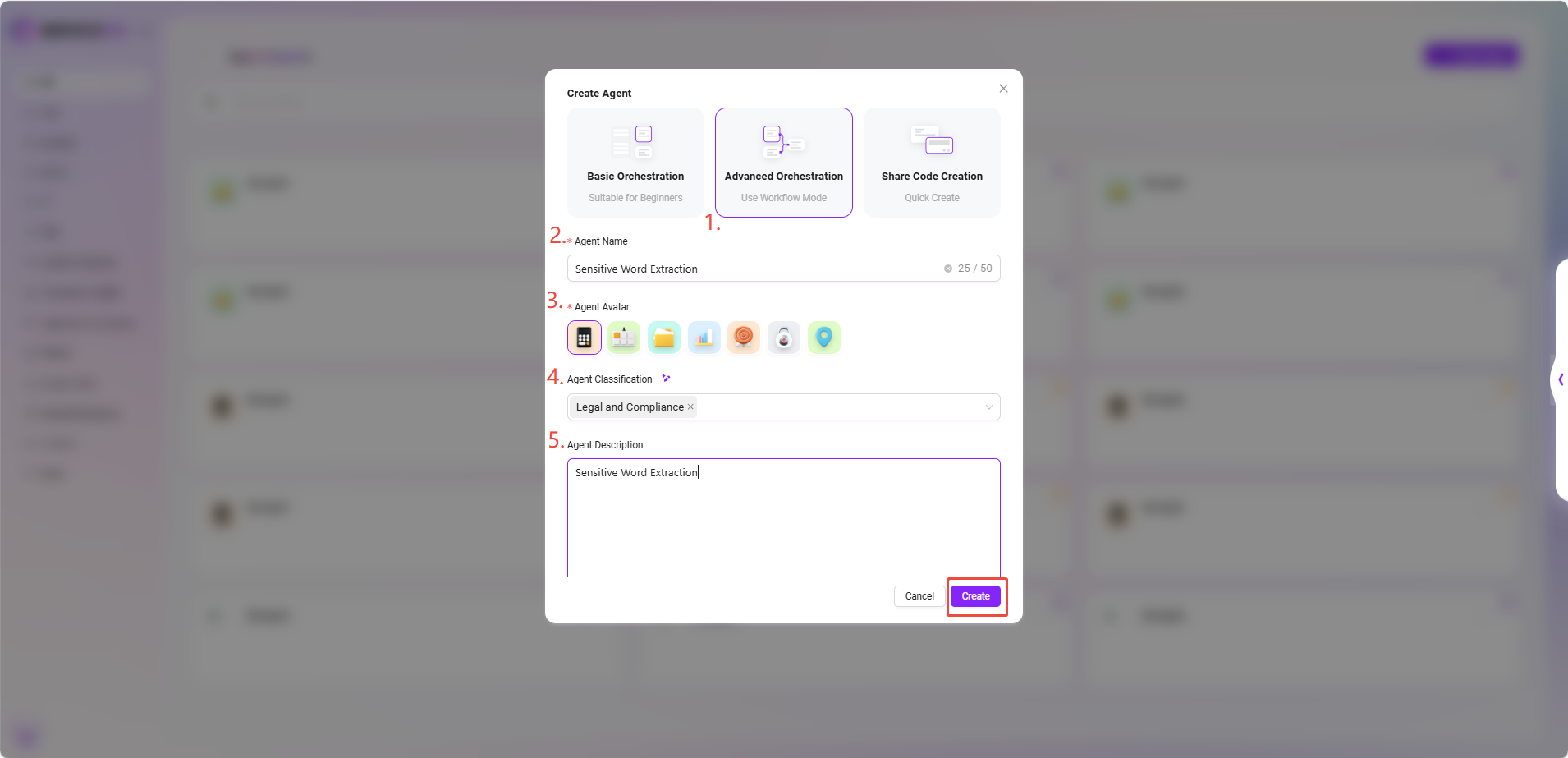
- アシスタント広場の右上で 「アシスタント作成」 をクリックし、「高度なオーケストレーション作成」 を選択します。
- 以下の基本情報を入力します:
- アシスタント名:
Sensitive Word Extractionを入力 - アバター:システム内蔵アバターから選択(現時点ではカスタムアップロード非対応)
- カテゴリ:業務カテゴリを選択、例:
Legal and Compliance - 説明:例
Sensitive Word Extraction
- アシスタント名:
- 入力が完了したら 「作成」 をクリックし、基本Agentが生成されます。
「Sensitive Word Extraction」Agentの設定
📌 オーケストレーション前の思考整理
本ワークフローのコア目標は、Agentがユーザーがアップロードした契約書ファイルから自動でセンシティブワードを識別できるようにすることです。そのため、ユーザーに契約書ファイルをアップロードしてもらい、その内容を処理可能なテキストに解析します。同時に、事前に設定したデータベースからセンシティブワードデータをロードし、モデルで契約書内容とセンシティブワードをインテリジェントに照合、一致項目とその位置を特定します。最終的に、モデルが識別結果を出力し、その結果をユーザーに返します。全体の流れは、ファイル処理、データソース呼び出し、モデル識別、結果出力などの重要なステップを含み、自動化されたテキスト審査業務に適しています。
📌 ノード設定と接続説明
本例のWorkflowでは、各ノードの入出力は前のノードの結果を参照して設定します。センシティブワード抽出の目的を実現するため、本プロセスは主に以下のノードを含みます:開始ノード、ファイル処理ノード、データソースノード、モデルノード、終了ノード。以下に各ノードの設定と接続方法を順に説明します。
設定プロセス
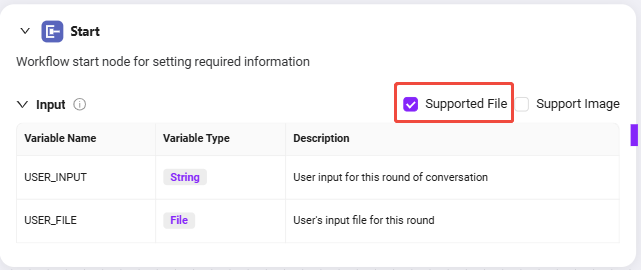
- 開始ノードの入力説明
開始ノードにはデフォルトで2つの入力があります:
USER_INPUT:ユーザーが入力する自然言語指示、例:「契約書のセンシティブワードをチェックしてください。」USER_FILE:ユーザーがアップロードするローカル契約書ファイル
これら2つの入力は、後続ノードの参照元として、ファイル処理やモデル識別に利用されます。
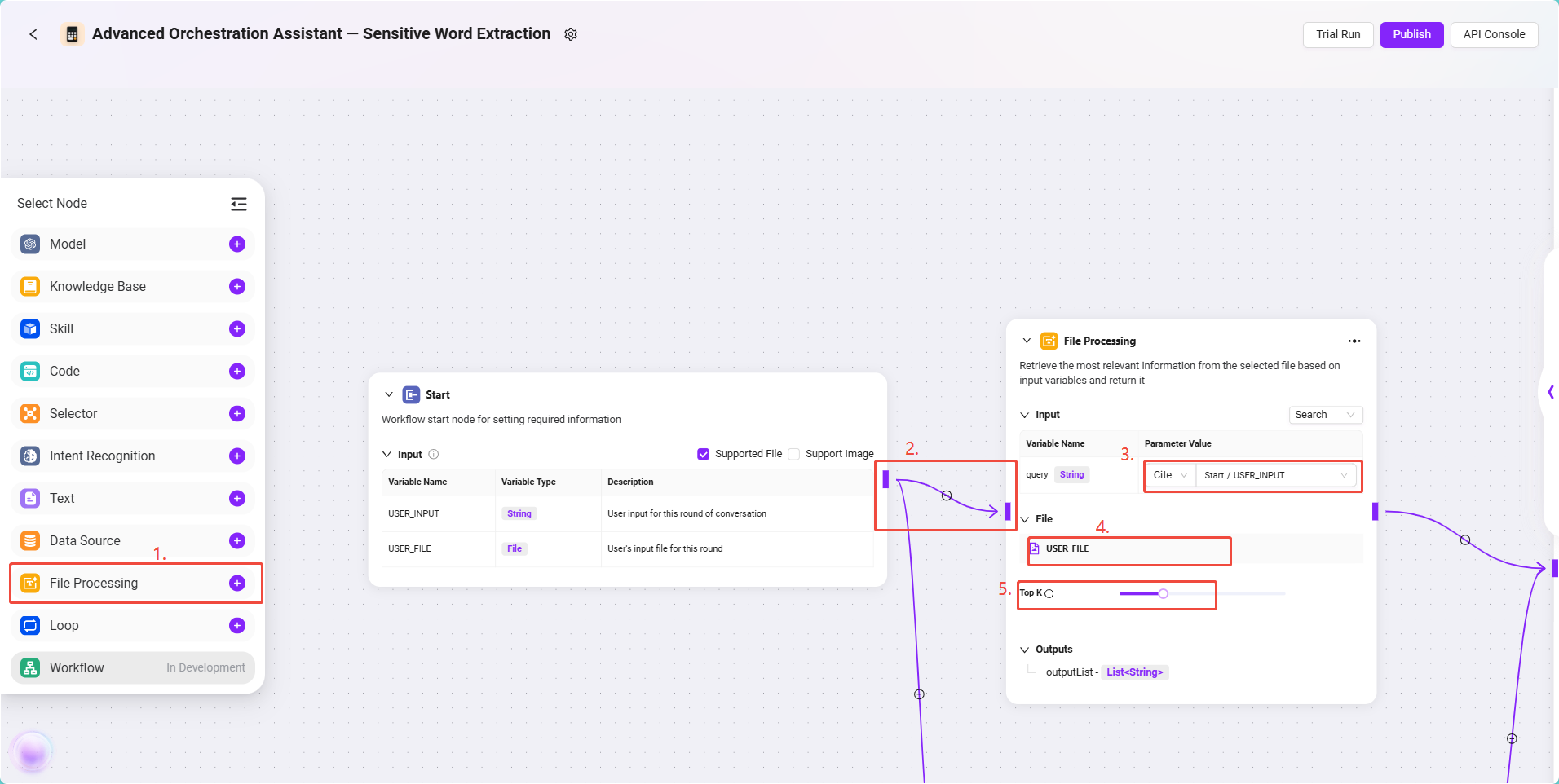
- ファイル処理ノードの設定
このノードは、ユーザーがアップロードした契約書ファイルの処理(テキスト抽出、スライス、ベクトル化処理)を担当します。
設定手順は以下の通りです:
- ファイル処理ノード をキャンバスに追加します。
- 開始ノード と ファイル処理ノード を接続します。
- ファイル処理ノードをクリックし、設定画面で以下を設定します:
- 入力参照:
USER_INPUTを参照として設定、フォーマット:
Start/USER_INPUT - ファイル参照:「ファイル追加」をクリックし、
USER_FILE(ユーザーがアップロードした契約書ファイル)を選択 - TopK設定:適切なTopK(例:3~5)を選択
- TopKは、モデルがテキストベクトルマッチング時に最大で返す文書数を示します。
- 推奨:TopKが低すぎると重要な内容を見逃す可能性があり、高すぎるとモデルの集中力が低下する場合があります。
- 入力参照:
- データソースノードの設定
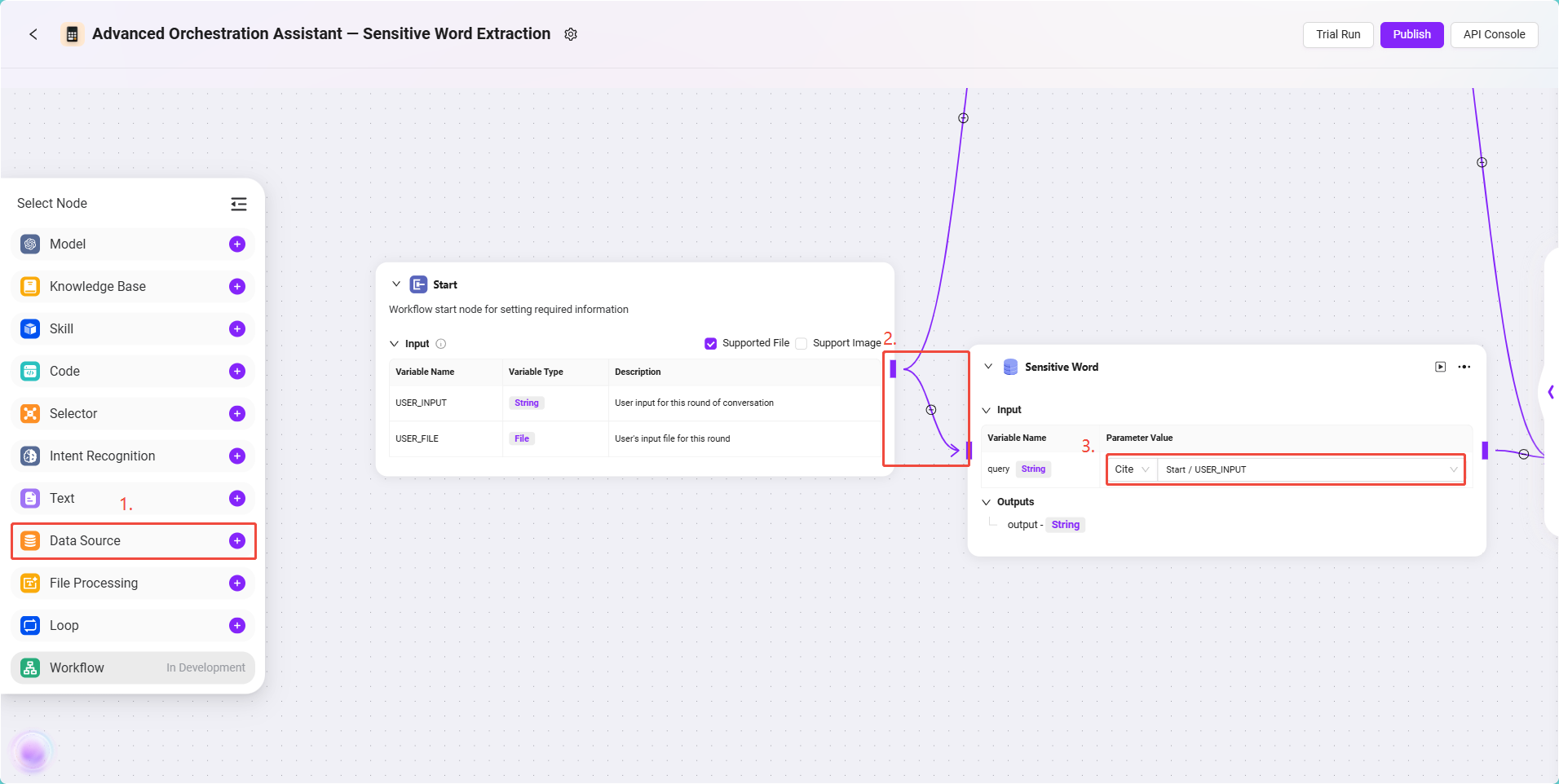
このノードは、先ほど作成したセンシティブワードデータテーブルを導入し、後続の照合に利用します。
設定手順は以下の通りです:
- データソースノード をキャンバスに追加し、開始ノードと接続します。
- ノードをクリックし、データソース情報を設定します:
- データソースを選択:
Sensitive Word - 入力参照設定:
Start/USER_INPUT(ユーザーの入力指示)
- データソースを選択:
このノードの出力が、モデルで使用するセンシティブワードリストとなります。
- モデルノードの設定
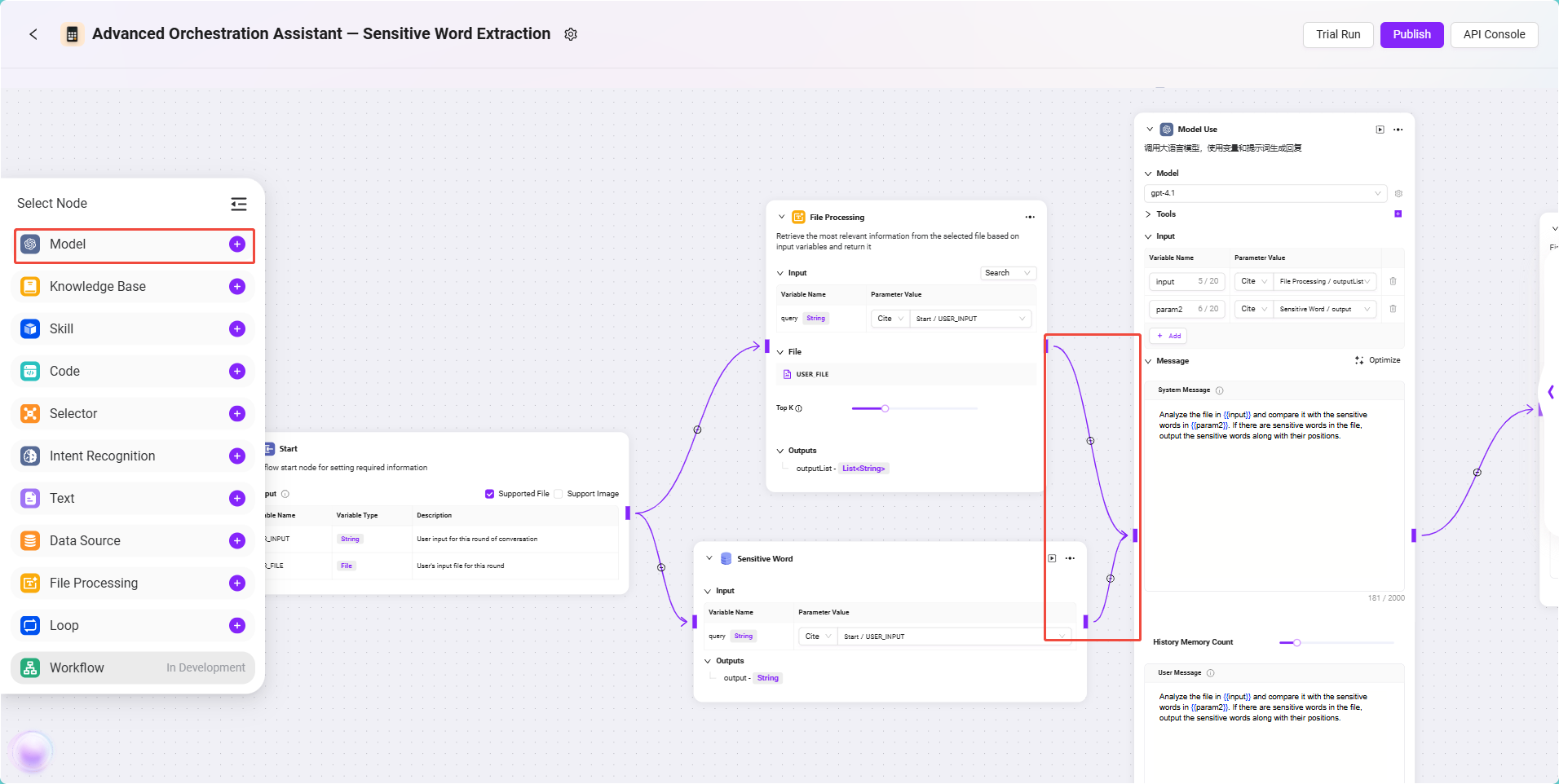
このノードは本プロセスのコア処理モジュールであり、契約書テキストとセンシティブワードをインテリジェントに照合し、結果を返します。
設定手順は以下の通りです:
- モデルノード を追加し、ファイル処理ノードとデータソースノードをそれぞれ接続します。
- モデル選択:
gpt-4.1 - ツール選択:本シナリオでは外部ツールの呼び出しは不要なのでスキップ
- 入力参照:
input:ファイル処理ノードの出力を参照、フォーマット:
FileHandler/outputparam2:データソースノードの出力を参照、フォーマット:
DataSource/output
- プロンプト設定:
- システムメッセージ(System Prompt):
Analyze the file in {{input}} and compare it with the sensitive words in {{param2}}. If there are sensitive words in the file, output the sensitive words along with their positions. - ユーザーメッセージ(User Prompt):
Analyze the file in {{input}} and compare it with the sensitive words in {{param2}}. If there are sensitive words in the file, output the sensitive words along with their positions.
- システムメッセージ(System Prompt):
✅ ヒント:システムメッセージはモデルに行動指示を与え、ユーザーメッセージはユーザーの実際の入力をシミュレートします。ここでは両者の内容を同じにすることで、より安定した効果が得られます。
- 出力ノードの設定
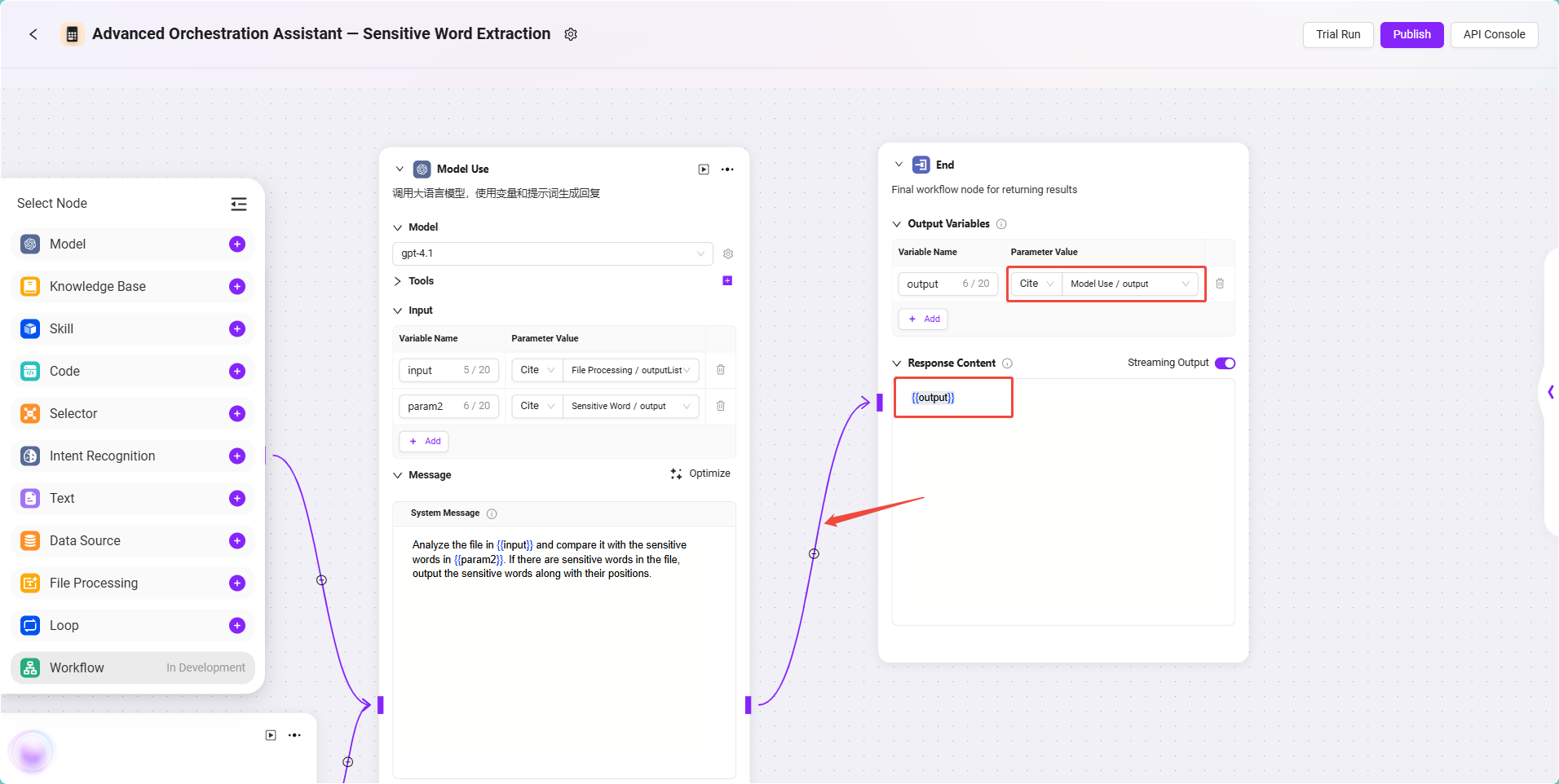
このノードは、モデルの処理結果を最終ユーザーに返す役割を担います。
設定手順は以下の通りです:
- モデルノード と 終了ノード を接続します。
- 終了ノードをクリックし、入力参照を設定:
- 入力内容:モデルノード出力を参照、フォーマット:
Model/output
- 入力内容:モデルノード出力を参照、フォーマット:
- 出力内容設定に以下を記入:
{{output}}
✅ ヒント:最後に
{{output}}のみを出力として記入することで、モデルの出力をより良く保持できます。必要に応じて、特定内容の出力も指定可能です。
全体設定例: