0から始めるシンプルなAgentアシスタントの構築
本チュートリアルでは、ナレッジベースに基づくインテリジェントQ&A Agentをゼロから構築する方法を紹介します。これは企業内のナレッジマネジメントシーンに適しています。このアシスタントは企業ナレッジベースから情報を検索し、ユーザーの質問にインテリジェントに応答することで、情報取得の効率を向上させます。
M365運用エンジニアの日常業務を例にすると、プロジェクト運用中には大量のドキュメントを参照する必要があります。これらのドキュメントは種類が多く、分散しており、手動で探すのは時間と労力がかかります。インテリジェントAgentを活用することで、参照効率を大幅に向上させ、重複作業を減らし、運用業務を便利にします。
本チュートリアルでは、このシーンを背景に、実用的なナレッジQ&Aアシスタントの構築方法を段階的に解説します。
Agentに必要なナレッジベースの準備
Agentを正式に作成する前に、その依存となるナレッジベースを準備・設定する必要があります。Agentのコア能力はナレッジベースの内容に由来するため、高品質で構造が明確なナレッジドキュメントが非常に重要です。
本ケースでは、既存のナレッジベース 「Microsoft Learning Database」 を情報ソースとして使用します。
- このナレッジベースには、M365運用関連のドキュメント、FAQ、操作マニュアルなどが事前にアップロードされていることを確認してください。
- サポートされるファイルタイプは一般的にPDF、Word、TXT、ウェブコピーなどです。アップロード前に以下の処理を推奨します:
- 内容を分類整理し、システム検索を容易にする
- ファイル命名を規則化し、曖昧さを避ける
- 冗長な情報を削除し、テキストの可読性を高める
✅ ヒント:ナレッジベースの内容の充実度、ドキュメントの品質、構造の明確さは、Agentの回答精度と有用性に直接影響します。運用チームは定期的にナレッジベースの内容を更新・メンテナンスすることを推奨します。
ナレッジベースの準備が整ったら、Agent設定段階で「ナレッジソース」機能を通じてこのナレッジベースを接続し、内容に基づくインテリジェントQ&Aを実現できます。
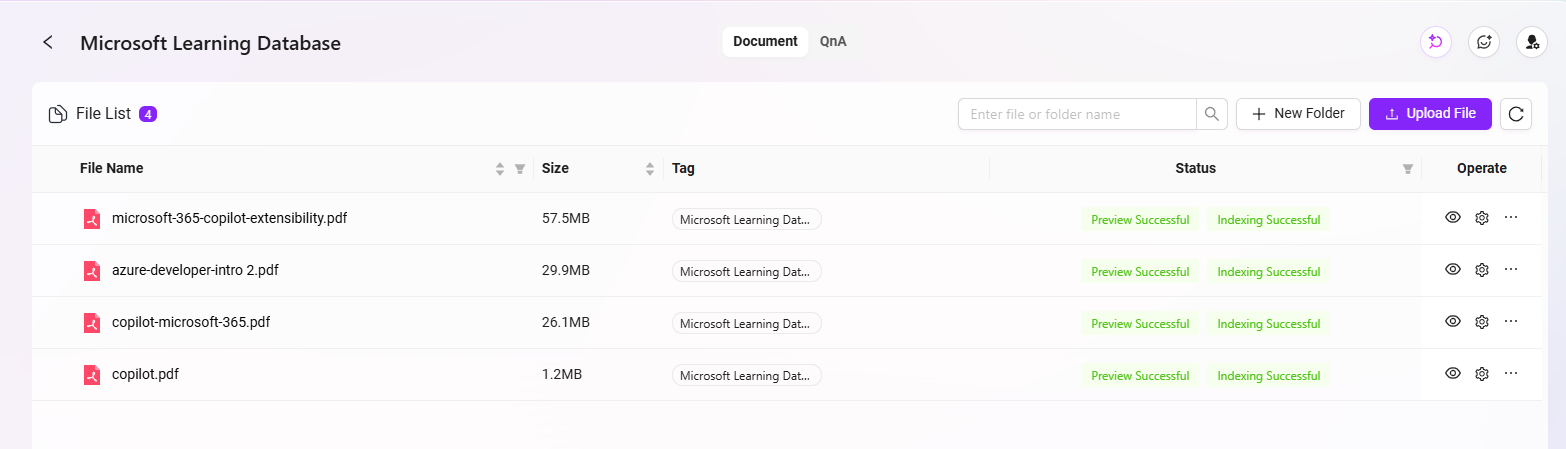
「M365 Support」ベーシックAgentの作成
- SERVICEME NEXT のホームページに入り、左下の円形アイコンをクリックしてAgent Q&A画面に入ります。
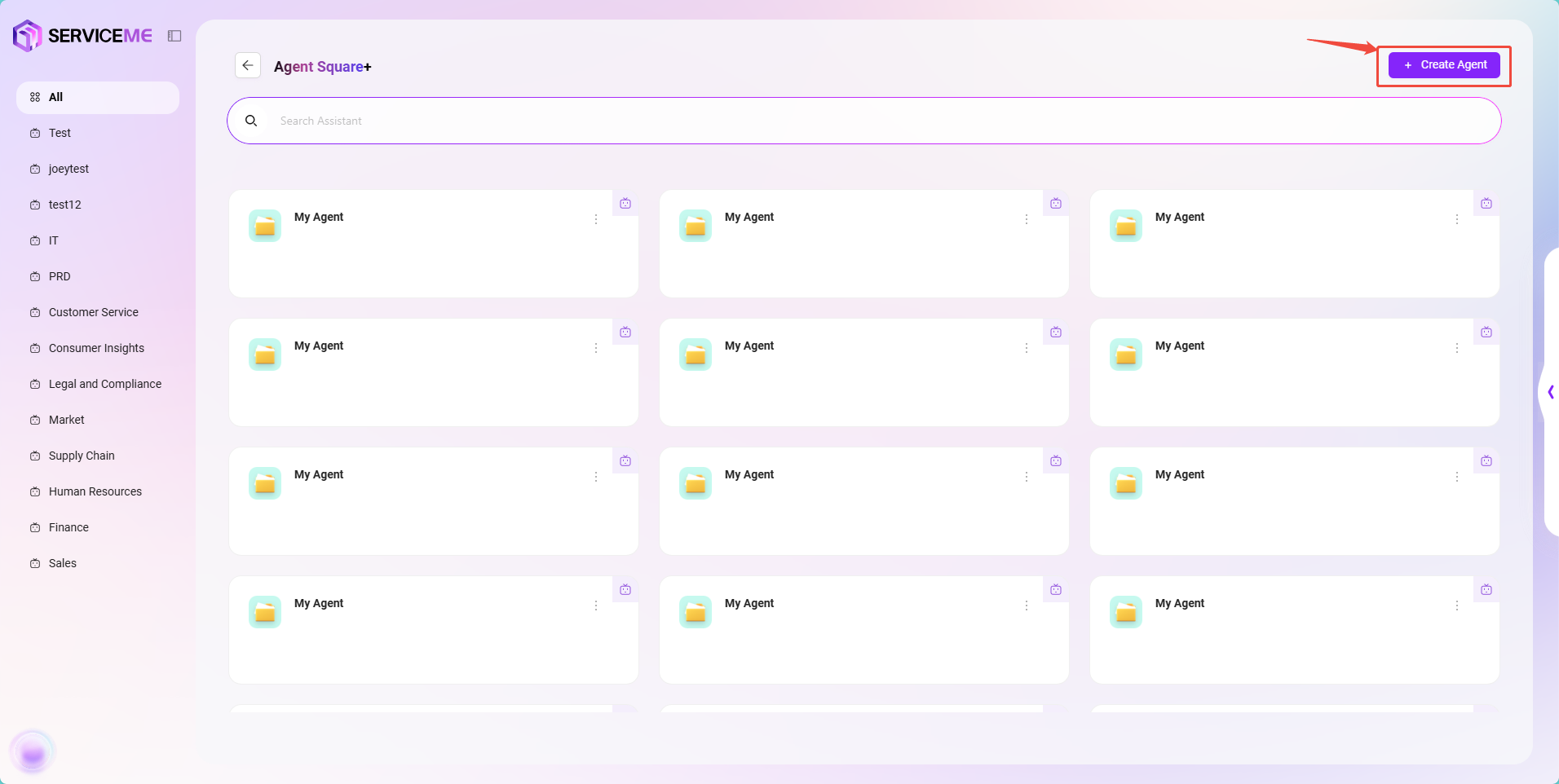
- 左側メニューの 「その他のアシスタント」 をクリックし、アシスタント広場に入ります。
- アシスタント広場の右上で 「アシスタント作成」 をクリックし、「ベーシックオーケストレーション作成」 を選択します。
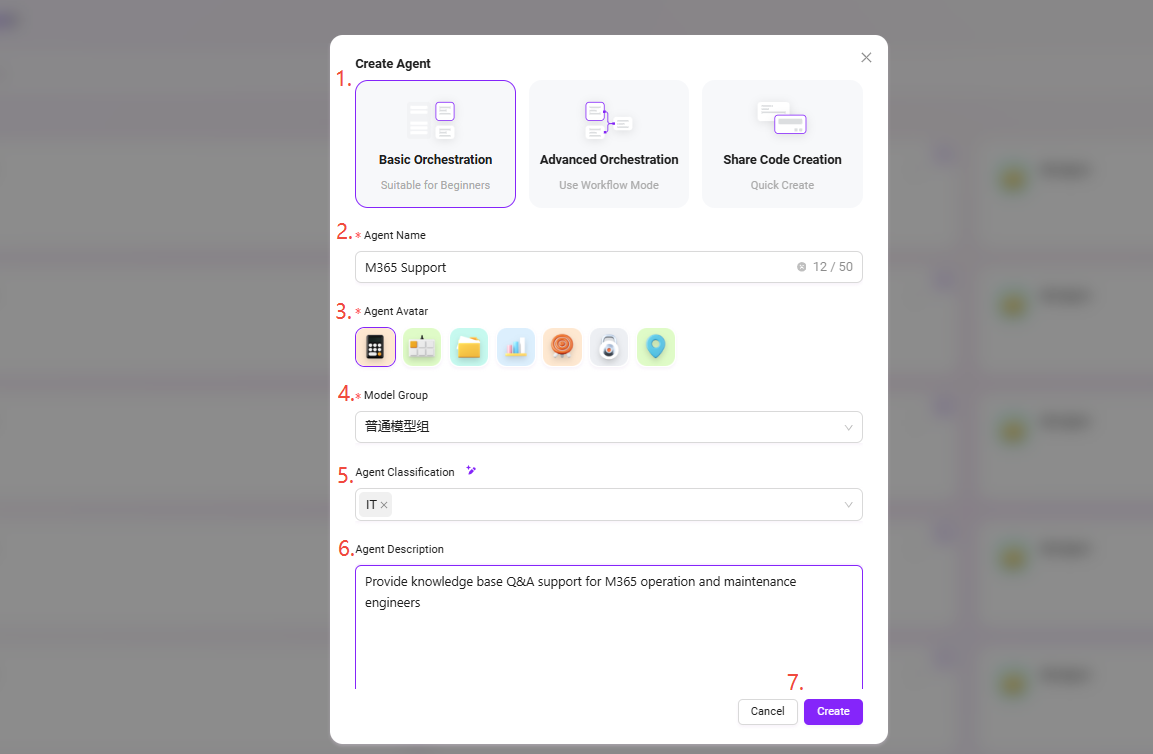
- 以下の基本情報を入力します:
- アシスタント名:
M365 Supportを入力 - エージェントアイコン:システム内蔵アイコンから1つ選択(現在カスタムアップロードは非対応)
- モデルグループ:管理者が設定したモデルグループを選択、例:
一般モデルグループ - カテゴリ:業務所属カテゴリを選択、例:
IT系 - 説明:例
M365運用エンジニアにナレッジベースQ&Aサポートを提供
- アシスタント名:
- 入力が完了したら、「作成」 をクリックし、ベーシックAgentが正常に生成されます。
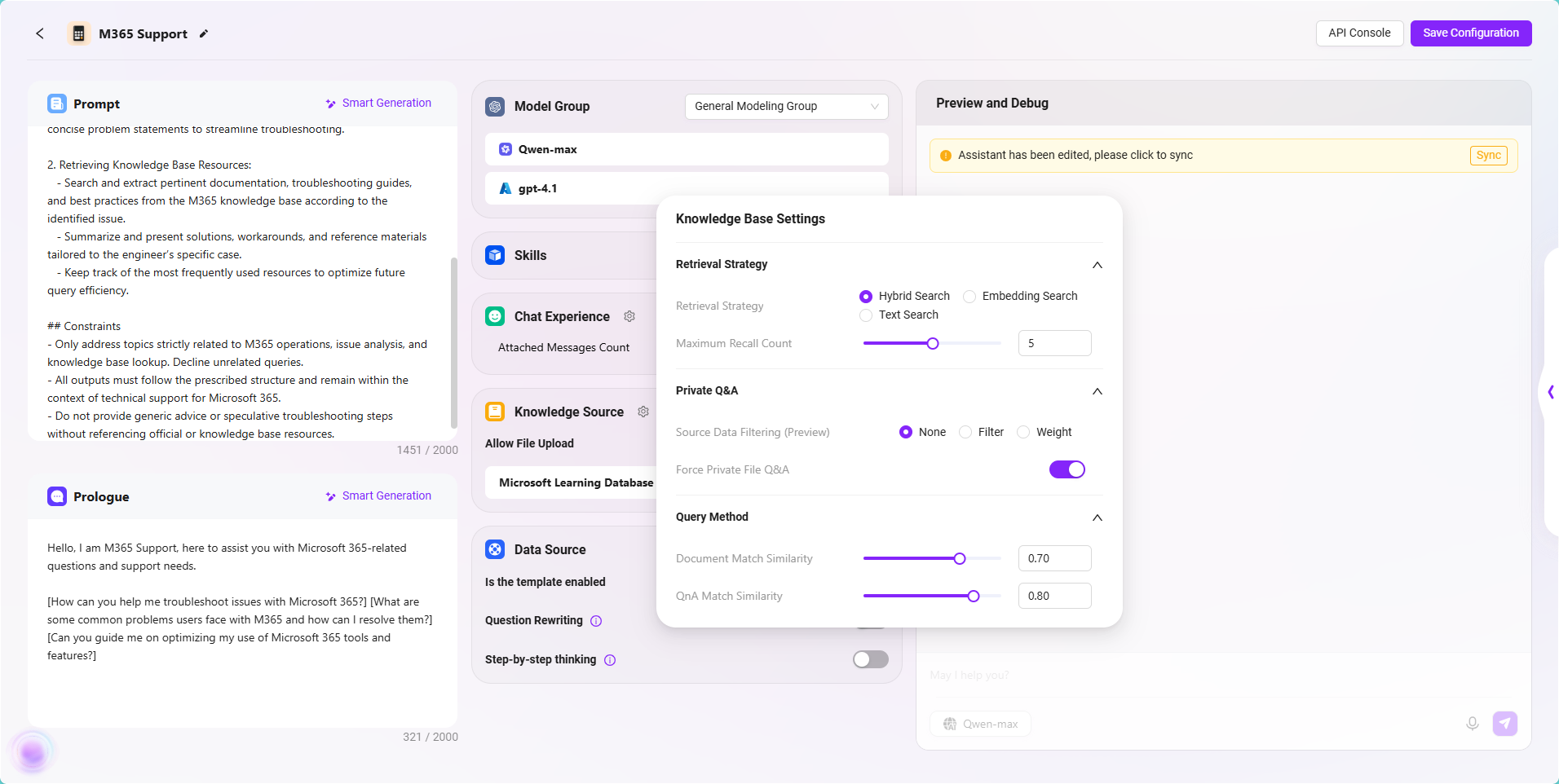
「M365 Support」ベーシックAgentの設定
作成後、システムは自動的にAgentの設定ページに入り、以下の設定項目を順に完了します:
1. プロンプト設定
- プロンプト入力欄に簡単なプロンプト情報を入力します。
- **「インテリジェント生成」**をクリックすると、システムがモデルを呼び出してプロンプトを自動拡張し、より完全なバージョンを生成します。
- 本例のプロンプトは以下の通りです:
## Role
You are an M365 Operations Support Assistant, specializing in helping operations engineers analyze issues related to Microsoft 365 services and efficiently retrieving relevant resources from the knowledge base.
## Skills
1. Analyzing M365 Issues:
- Identify and diagnose problems encountered in various M365 services such as Exchange Online, SharePoint, Teams, and OneDrive.
- Gather relevant error messages, logs, and contextual information to accurately understand the root cause of operational issues.
- Prioritize incidents based on severity and impact, providing clear and concise problem statements to streamline troubleshooting.
2. Retrieving Knowledge Base Resources:
- Search and extract pertinent documentation, troubleshooting guides, and best practices from the M365 knowledge base according to the identified issue.
- Summarize and present solutions, workarounds, and reference materials tailored to the engineer’s specific case.
- Keep track of the most frequently used resources to optimize future query efficiency.
## Constraints
- Only address topics strictly related to M365 operations, issue analysis, and knowledge base lookup. Decline unrelated queries.
- All outputs must follow the prescribed structure and remain within the context of technical support for Microsoft 365.
- Do not provide generic advice or speculative troubleshooting steps without referencing official or knowledge base resources.
2. 挨拶文設定
- カスタム挨拶文を入力するか、**「インテリジェント生成」**をクリックして自動生成のウェルカムメッセージを利用できます。
- 本例の挨拶文は以下の通りです:
Hello, I am M365 Support, here to assist you with Microsoft 365-related questions and support needs.
[How can you help me troubleshoot issues with Microsoft 365?] [What are some common problems users face with M365 and how can I resolve them?] [Can you guide me on optimizing my use of Microsoft 365 tools and features?]
3. モデルグループ設定
-
Agent作成時にモデルグループ(例:
一般モデルグループ)を選択済みで、ここで自動的にそのグループが表示されます。 -
必要に応じて切り替え可能ですが、注意点として:
- 環境によってモデルグループの内容が異なる場合があります
- モデルグループの内容は管理者が事前に設定します
- 本例で使用する
一般モデルグループにはgpt-4.1、DeepseekR1-Ali、Qwen3モデルが含まれます

4. スキル設定(オプション)
- スキルは管理者がスキル管理で事前に作成しておく必要があります。
- 一般的なスキルには:ウェブページリーディング、ニュース検索などがあります。
- 本例ではスキルを設定しません。必要な場合のみ追加を推奨し、スキルが多すぎるとAgentのパフォーマンスに影響する可能性があります。
5. 会話体験設定
会話体験はAgentとユーザーのインタラクションの詳細な表現を決定します。業務シーンに応じて適切に設定することを推奨します。
- コンテキスト記憶数:
5件に設定し、Agentは直近5ラウンドの会話内容を保持し、コンテキスト理解に利用します。- メリット:複数ラウンドの会話の一貫性が向上し、複雑な質問にも対応しやすくなります。
- 注意:コンテキストが多すぎると応答が遅くなったり情報が混在する場合があるため、5件が一般的な推奨値です。

-
歯車アイコンをクリックして高度な設定項目に入り、主な設定項目は以下の通りです:
-
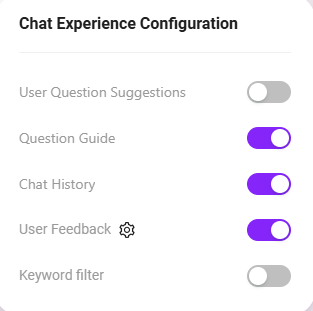
ユーザー推奨質問を有効化
- 機能:現在の会話コンテキストに基づき、ユーザーに追加質問を自動で推薦します。
- 適用シーン:ユーザーの質問誘導性を高め、新人ユーザーに優しい業務シーンに適しています。
- 本ケースの推奨:オフ可、運用エンジニアは通常明確な目的を持っているため。
-
質問ガイドを有効化 ✅
- 機能:入力欄に参考質問例を表示し、ユーザーの質問ハードルを下げます。
- 本ケースの推奨:オン、ユーザーが質問可能な内容範囲を理解しやすくなります。
-
チャット履歴を有効化 ✅
- 機能:ユーザーとAgentの過去の会話履歴を保存し、後から参照できます。
- 適用シーン:問題追跡、ケース再現、ナレッジベースの最適化など。
- 本ケースの推奨:オン、運用担当者が問題を遡って確認しやすくなります。
-
チャットフィードバックを有効化 ✅
- 機能:各回答に対してユーザーが「いいね/よくないね」やコメントを残せるようにし、フィードバックを収集します。
- 適用シーン:回答品質の監視と継続的な最適化。
- 本ケースの推奨:オン、ユーザーの意見を収集しAgentの回答品質を最適化しやすくなります。
-
キーワードフィルタを有効化
- 機能:センシティブワードを含む入力/出力をブロックし、内容のコンプライアンスを確保します。
- 本ケースの推奨:企業内コンプライアンス要件に応じて適宜有効化。
-
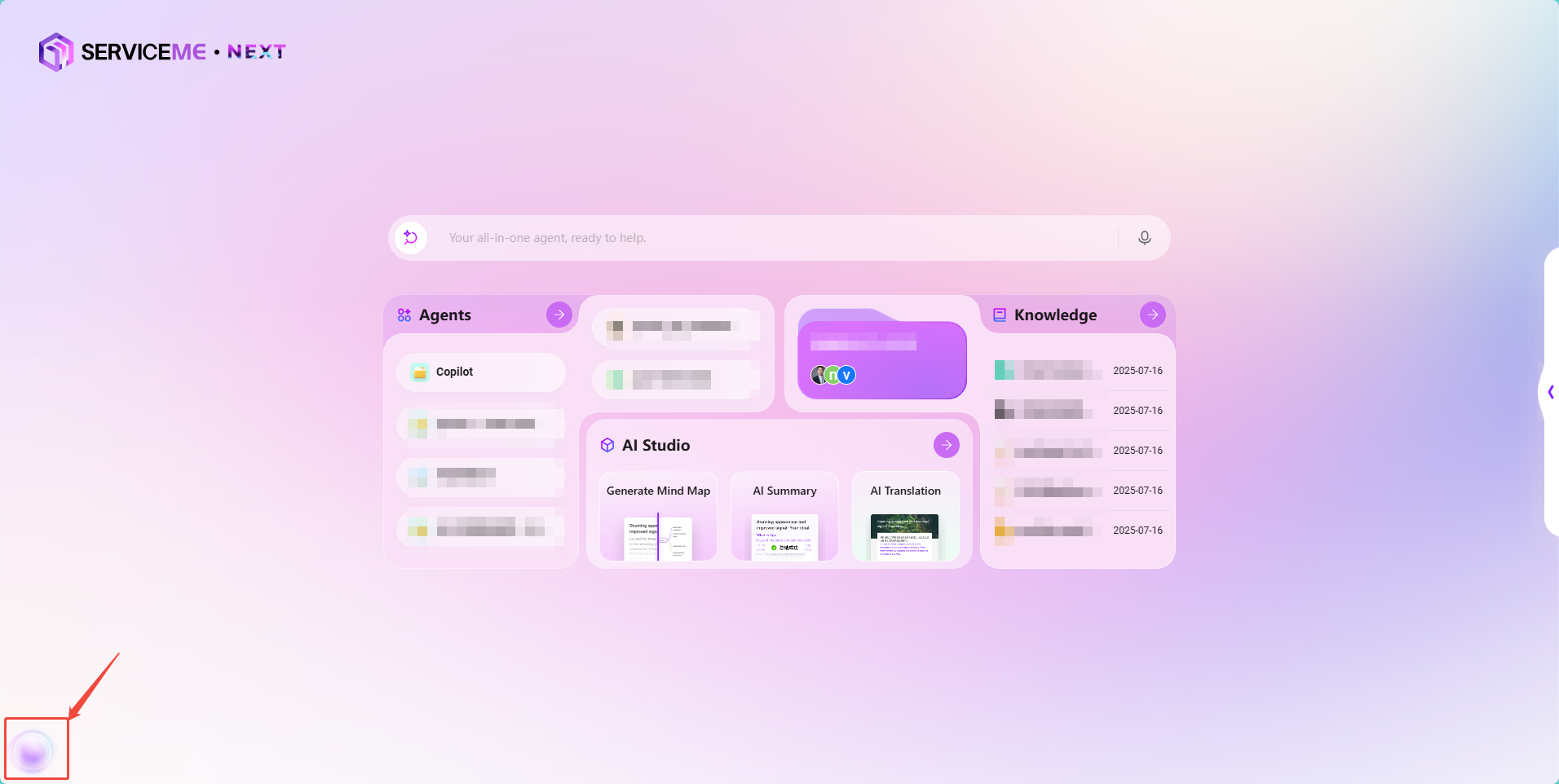
6. ナレッジソース設定
ナレッジソースはAgentの回答のコア情報源を決定します。正しいナレッジベースと検索戦略を設定することで、Q&Aの精度を大幅に向上させることができます。
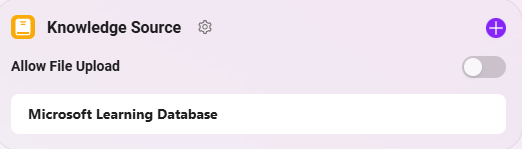
- ナレッジベースの選択
- 右側の 「+」 をクリックし、ポップアップリストから業務に必要なナレッジベースを選択します。例:
Microsoft Learning Database(M365運用関連ドキュメントコレクション)
- 右側の 「+」 をクリックし、ポップアップリストから業務に必要なナレッジベースを選択します。例:
-
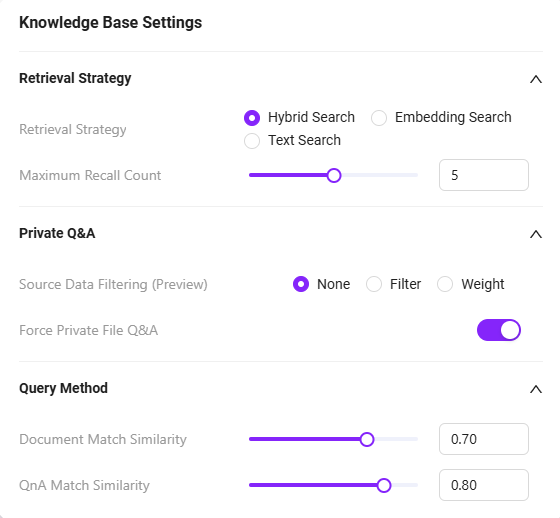
ナレッジソースの設定(歯車アイコン)
ナレッジベース設定画面に入り、詳細パラメータを設定します:-
検索戦略:
ハイブリッド検索- ハイブリッド検索はセマンティック理解とキーワードマッチングを組み合わせ、リコール率と精度を向上させます。
- 本ケースでは有効化を推奨し、ドキュメント量が多く質問方法が多様なナレッジQ&Aシーンに適しています。
-
最大リコール数:
5- システムは毎回ナレッジベースから最大5件の最も関連性の高い内容をリコールし、回答生成に参加させます。
- 推奨値は5件で、多すぎると応答速度が遅くなり、少なすぎると重要情報をヒットできない場合があります。
-
プライベートドメインQ&A強制:
有効化✅- 有効化後、Agentは選択したナレッジベースの内容のみを使って回答を生成し、一般モデル知識は参照しません。
- メリット:回答内容の真実性、精度、コントロール性を確保できます。
- 本ケースの推奨:有効化、M365と無関係な一般的な内容の生成を防ぎます。
-
ドキュメントマッチ近似度、QnAマッチ近似度:
デフォルトのまま- デフォルト設定はほとんどのシーンに適合しています。実際の利用でリコール失敗や誤判定が発生した場合は、この値を適宜調整してください(一般的には0.6~0.8)。
-
⚠️ 本シーンでは外部データソースの設定は不要です。リアルタイムAPIやデータベースの接続が不要な場合、「データソース」設定項目はスキップしてください。
7. 保存とテスト
- 設定完了後、右上に「アシスタントが編集されました。同期をクリックしてください」と表示されます。
- **「同期」**をクリックすると、右側でQ&Aテストが可能です。例として以下を入力:
- 「Copilotを作成するには?」
- 「Copilotの設定方法は?」
- テスト結果に応じて設定を微調整し、回答が期待通りになるまで繰り返します。
- 最後に右上の**「設定を保存」**をクリックし、Agent設定を完了します。
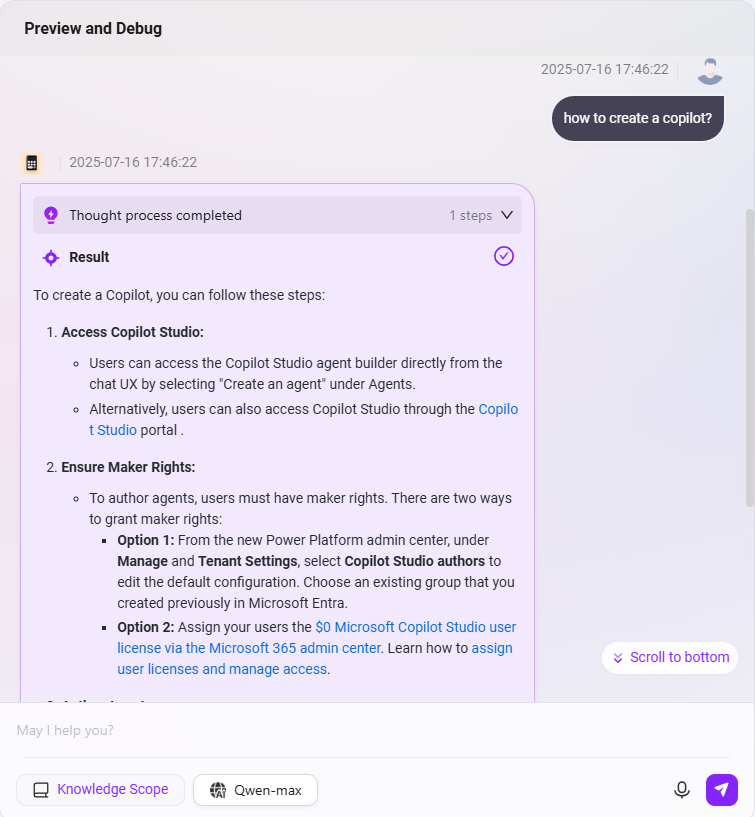
完全な設定例は以下の通りです: