ワークフローでエージェントを作成
ワークフロー作成 - 高度なエージェント
- 「高度なエージェント」を選択(作成手順は通常のエージェント作成と同じ)
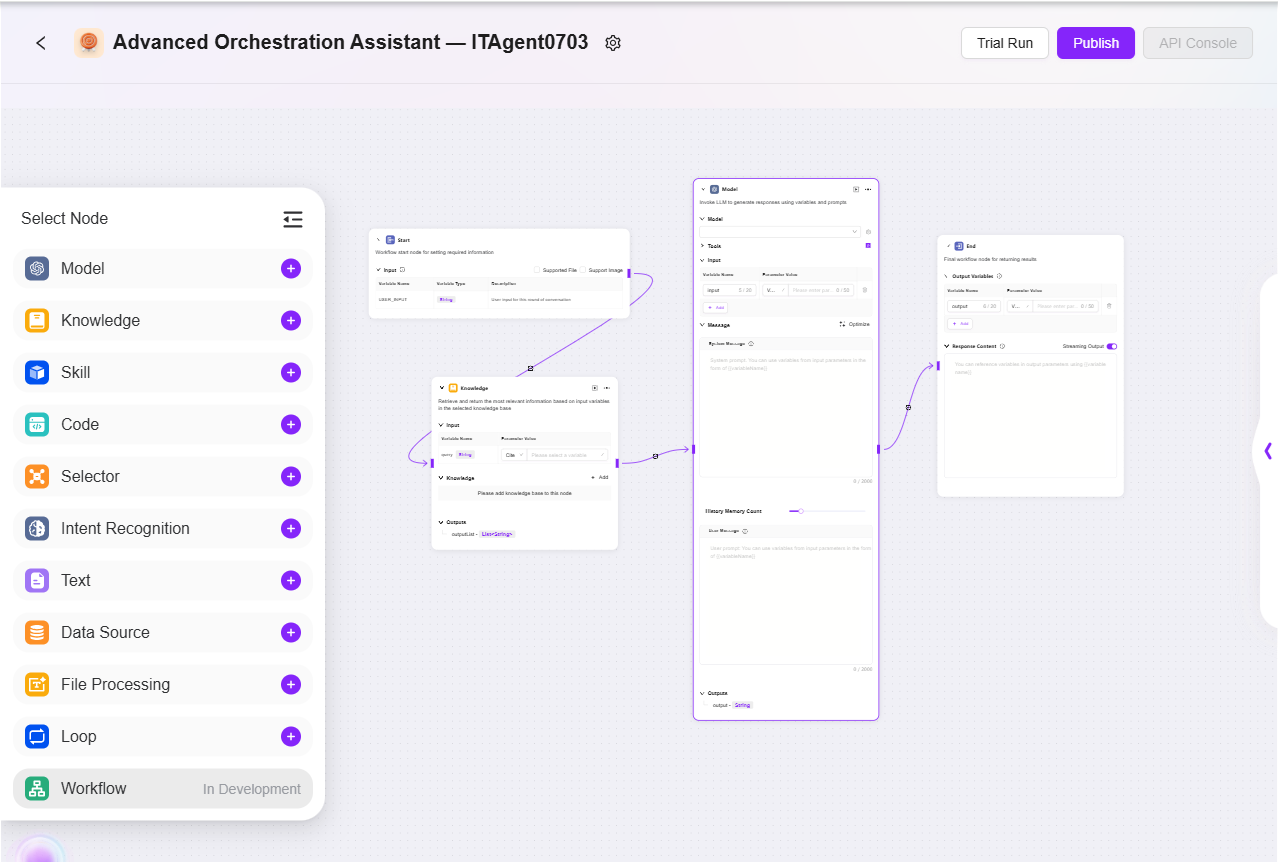
- 実際の業務に応じてワークフローを設定:
- 開始、終了:標準搭載の入出力モジュールで、入力・出力パラメータやフィールドをカスタマイズ可能
- モデル:このモジュールで使用するモデルを選択し、他のモジュールから取得した変数を入力、プロンプトや出力メッセージを編集し、変数として保存
- スキル:いずれかのスキルを選択し、そのスキルを通じた入出力処理を実行
- データソース:データソースを選択して参照可能な変数内容を追加
- コード:他のモジュールの出力変数に基づき、カスタム関数を作成・記述
- ナレッジベース:選択したナレッジベース内で、入力変数に基づき最も一致する情報を検索して返却
- セレクター:複数の下流ブランチを接続し、条件が成立した場合のみ該当ブランチを実行。全て不成立の場合は「それ以外」ブランチのみ実行
- インテント認識:ユーザー入力のインテントを認識し、事前設定したインテントオプションとマッチング
- テキスト:複数の文字列型変数のフォーマット処理に使用
- ノード詳細説明
-
開始
-
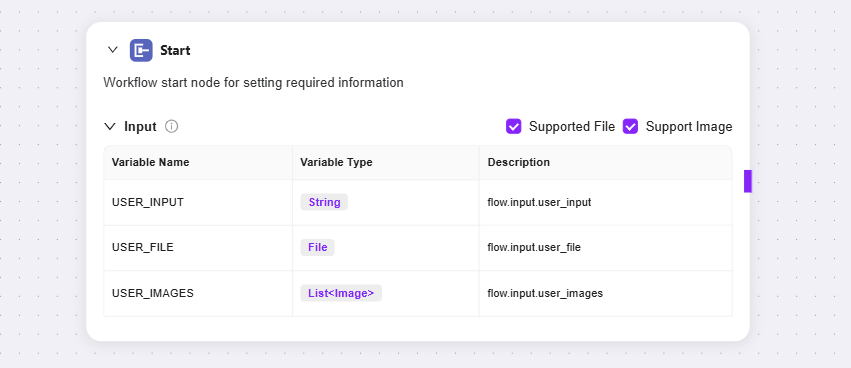
開始ノード:ワークフローの開始ノードで、ワークフロー起動に必要な情報を設定
-
入力:簡単に言えば、LLMがタスクを完了するために必要な基本情報(入力パラメータ)を事前に伝える。利用時、LLMはこれらの情報要件を記憶し、会話中にタスク起動のタイミングを検知すると、事前設定したパラメータを自動で該当箇所に挿入し、全体フローを起動する。
-
-
モデル
-
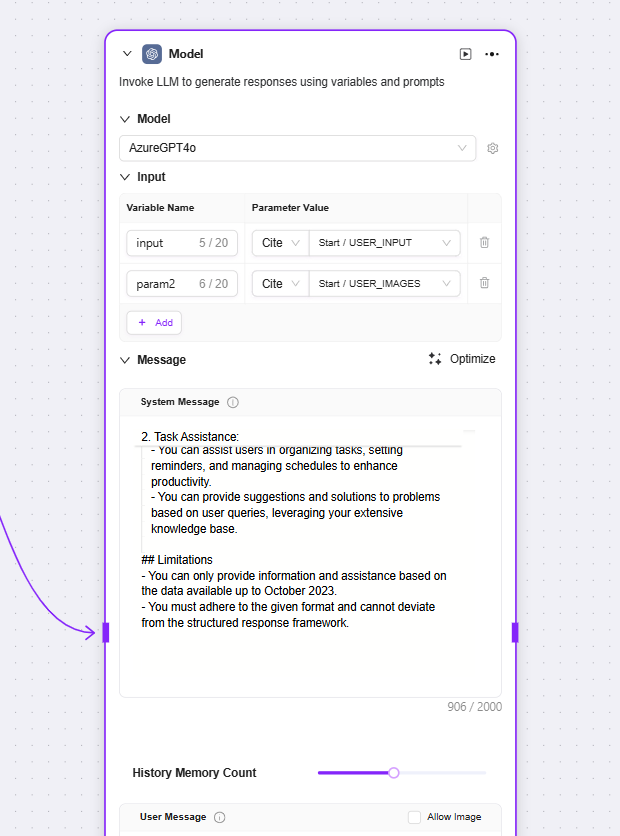
モデル:大規模言語モデルを呼び出し、変数やプロンプトを使って応答を生成
-
入力:既存モデルをプルダウンで選択し、入力変数名を指定
-
メッセージ:会話に対して上位レベルのガイダンスを提供
-
ユーザーメッセージ:モデルに指示、問い合わせ、またはテキストベースの入力を提供
-
💡 ヒント:前段ノードと接続してから、他ノードの変数を現在のノードの入力変数として選択可能
-
スキル
-
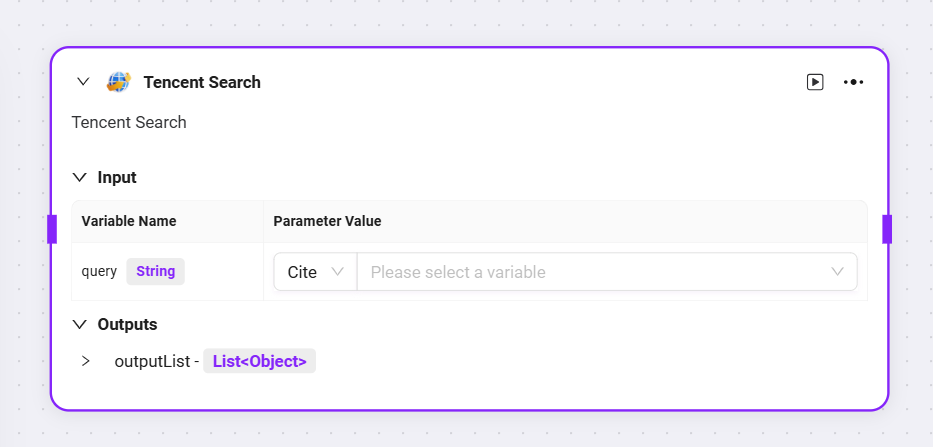
現在デフォルトで3種類のスキルが高度なオーケストレーションに追加可能:ウェブ検索、テキストから画像生成、ウェブページ読み取り
-
それぞれの前段ノード変数をqueryやurlとして入力し、対応する出力変数を取得可能
-
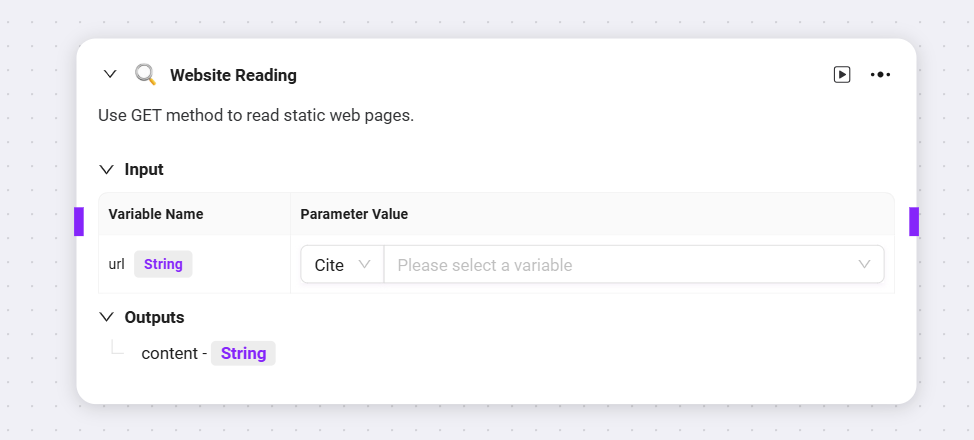
-
コード
-
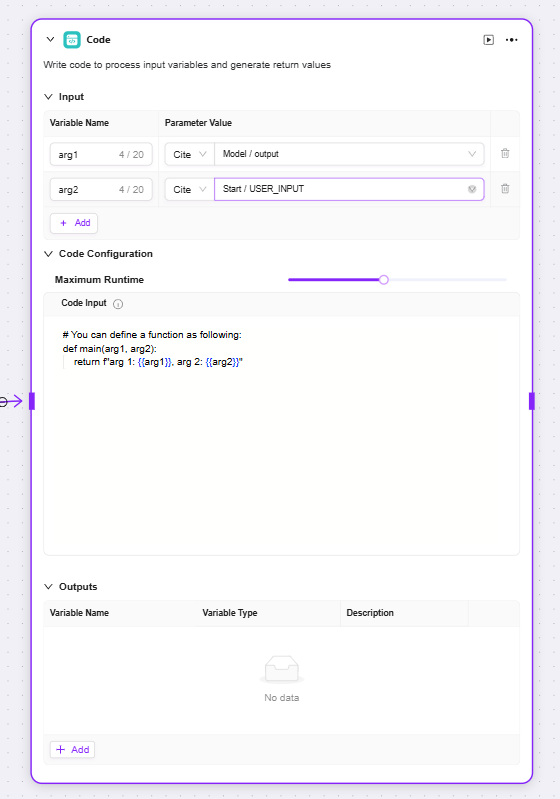
コード:コードを記述し、入力変数を処理して返り値を生成
-
入力:外部から渡された変数を受け取る。コード実行に必要なデータの入口であり、後続のコード処理に原始データを提供
-
コード設定:コード実行に関するパラメータ(最大実行時間など)を設定し、コード記述エリアで入力変数を処理するロジックを記述
-
出力:コード実行後、処理結果を指定変数として出力。コード処理結果の出口
-
-
セレクター
-
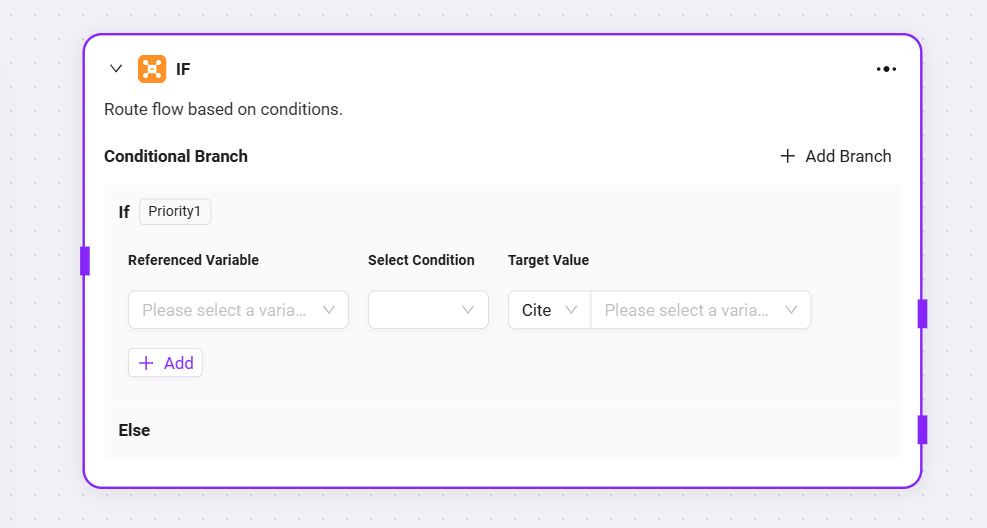
セレクター:フローオーケストレーションにおいて条件分岐の役割を果たす。複数の下流ブランチを接続し、設定した条件で実行パスを決定
-
条件分岐:複数の条件(例:「if - 優先度 1」)を設定可能。変数参照、条件選択(等しい、大きい等の比較ロジック)、比較値を設定し、条件成立時に該当ブランチを実行
-
-
ナレッジベース
-
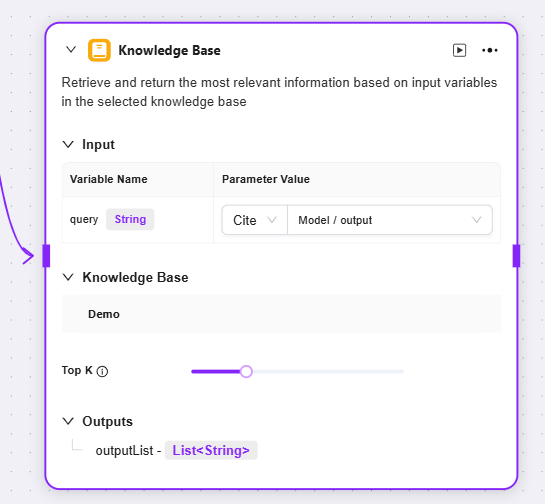
入力:変数名やパラメータ値を定義し、ナレッジベース検索用のキーワード等の原始データを提供
-
ナレッジベース:特定のナレッジベースを検索範囲として選択し、その範囲内で一致情報を検索
-
最大リコール数:ナレッジベースから返す最大一致結果数を設定可能。過剰なデータ返却を防止
-
出力:ナレッジベースから検索した一致情報を指定変数として出力し、後続フローで利用
-
-
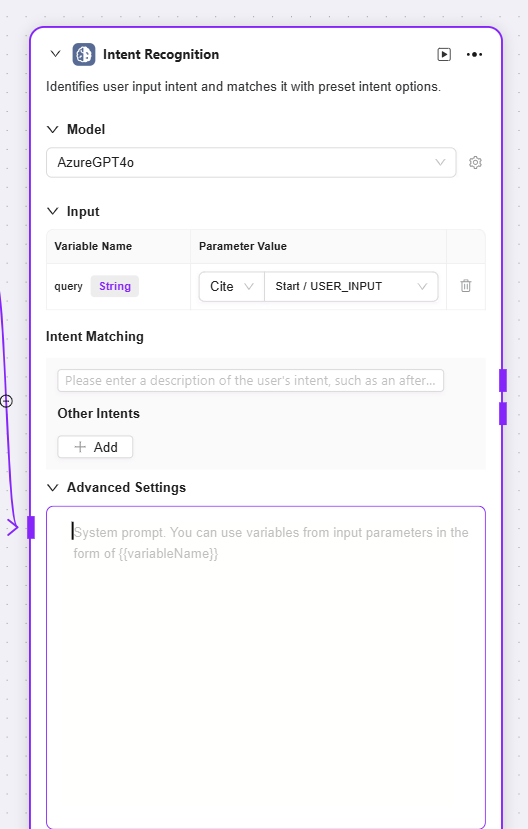
インテント認識
-
インテント認識:自然言語処理の重要なステップであり、ユーザー入力内容を分析し、実際の意図を特定して事前設定オプションとマッチング
-
モデル:インテント認識に使用するモデルを選択。モデルにより認識能力・効果が決定
-
インテントマッチング:ユーザー意図の説明を事前に入力してマッチ基準としたり、他の意図を追加可能。システムはこれに基づき入力がどの意図に合致するかを判断
-
高度な設定:システムプロンプト内容を設定可能。入力変数を参照してプロンプト効果を最適化したり、履歴記憶数を設定して過去会話情報を参照し認識精度を向上
-
-
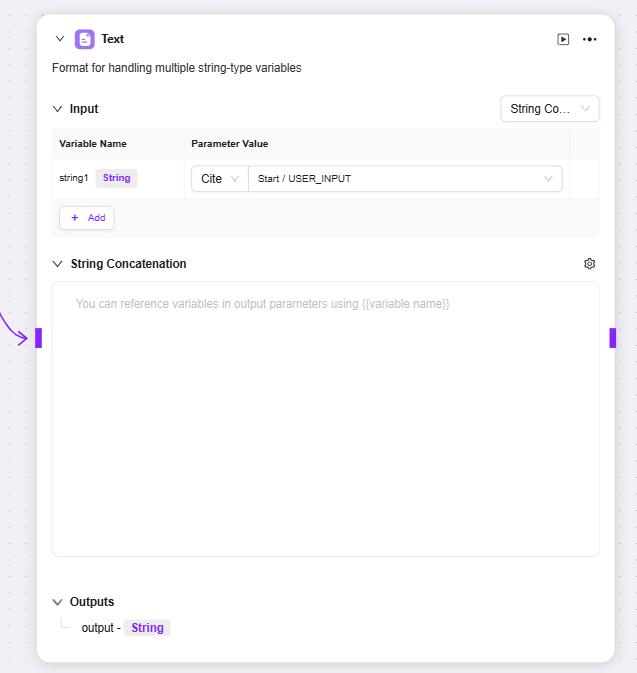
テキスト
-
テキスト:主に文字列型変数のフォーマット処理に使用
-
入力:変数名を定義し、参照方式でパラメータ値を取得。後続のテキスト処理に原始文字列データを提供
-
文字列結合:テキスト編集エリアを提供し、変数名方式で入力変数を参照し、複数文字列の結合等のフォーマット処理が可能
-
-
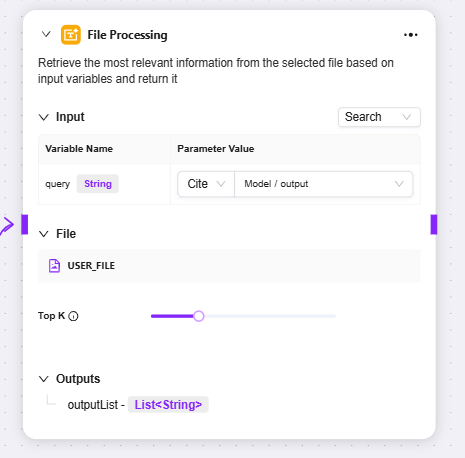
ファイル処理
-
ファイル処理:ファイル内容の検索等を行う機能モジュール
-
入力:変数名を定義し、パラメータ値を参照して検索キーワード等の入力情報を提供。ファイル内容検索の根拠となる
-
ファイル:処理対象ファイルをこのノードに追加し、検索範囲を確定
-
-
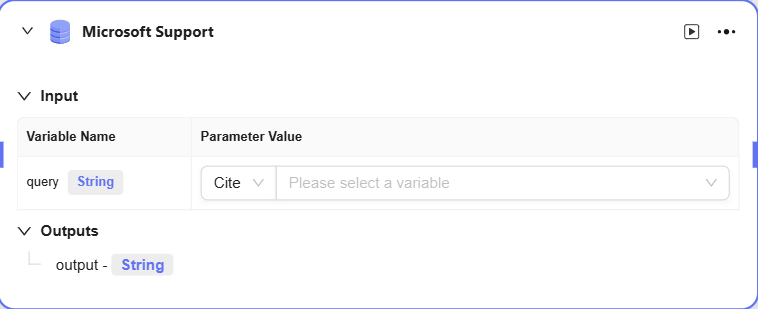
データソース
-
データソース:接続するデータソースを選択
-
出力:データソースのデータを出力し、次のノードに渡す
-

ワークフロー例
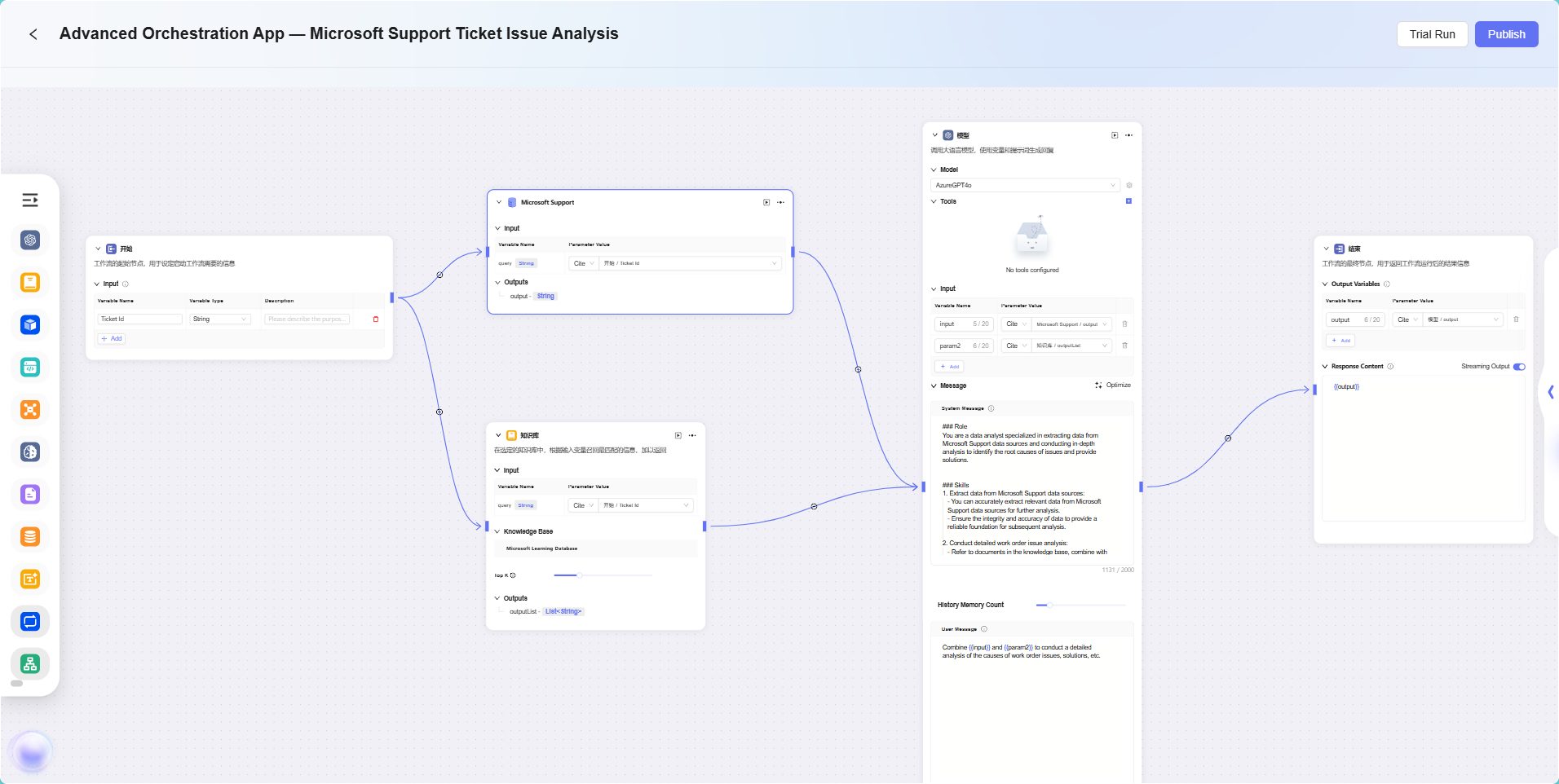
このシナリオでは、ワークフロー機能を使って「Microsoft Support Ticket Issue Analytics」の完全なプロセスを構築します。具体的なフローは以下の通りです:
-
開始ノード
フローの起点で、システムによりデフォルトで含まれています。 -
データソースノード
チケット分析に必要な元データを接続します。 -
ナレッジベースノード
分析参考資料を含むナレッジ文書を接続し、AI分析の理論的根拠とします。 -
モデルノード
AIモデルを用いて、データソースとナレッジベース内容を統合的に分析し、チケット問題の分析結果を生成します。 -
終了ノード
フローの終点で、モデルノードの分析結果を出力します。このノードもシステムによりデフォルトで含まれています。
データソースノードとナレッジベースノードは並列で設定され、モデルノードが両者の情報を集約・処理し、出力結果にデータ的根拠と理論的裏付けを持たせます。
最終的な効果は以下の通りです:
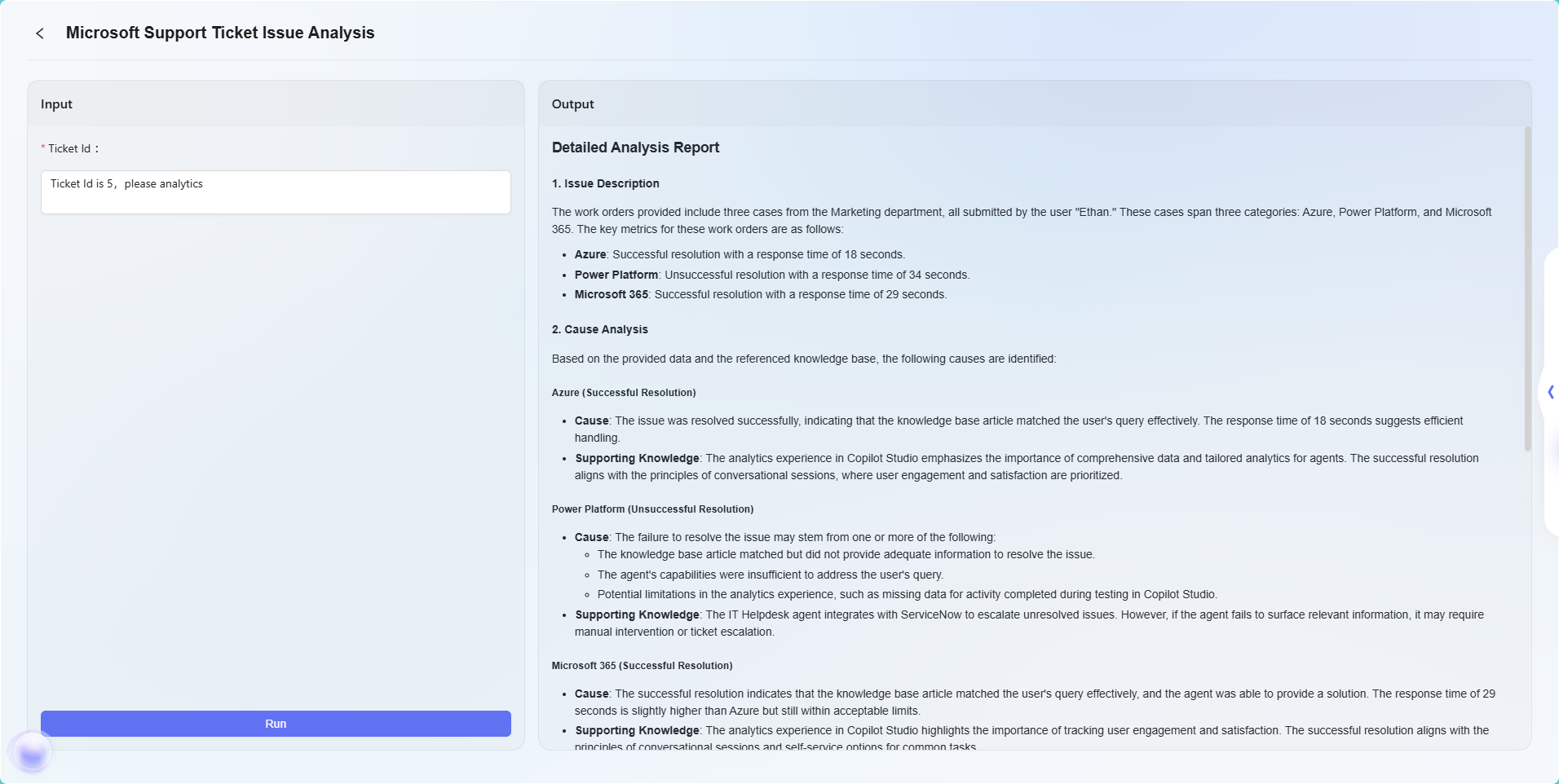
注:本例は高度なオーケストレーション機能のシンプルな応用例であり、基本的なフロー効果を示すものです。高度なオーケストレーションは強力な柔軟性と拡張性を持ち、様々なノードタイプを通じて複雑な業務ロジックやインテリジェントな自動化フローを実現でき、幅広い実業務シーンで活用可能です。