個人アプリケーションセンター
Agentとは
エージェント(Agent)とは?
エージェント(Agent)とは、自律的に感知、理解、推論、実行能力を備えたインテリジェントなプログラムまたはシステムを指します。ユーザーが提供する目標に基づき、自主的に計画を立て、ツールを呼び出し、タスクを実行し、タスクの過程でフィードバックに応じて動的に行動を調整し、最終的に効率的に目標を達成します。
従来のソフトウェアプログラムが人手による逐次操作に依存するのとは異なり、エージェントは**ユーザーを「代わって考え行動する」**ことができ、「指示駆動 → 自律的意思決定 → 自動実行」という完全なタスクの閉ループを実現します。
エージェントのコア特性
- 目標指向:ユーザーの指示やコンテキストに基づき、タスクの目標を明確にし、達成戦略を策定する。
- 自律的行動:一定の主体性と自治性を持ち、逐次的な指示なしに複雑なタスクを独立して実行できる。
- 環境認識とフィードバック:外部システム、データソース、ユーザー入力から情報を取得し、それに基づいて実行経路を動的に調整できる。
- ツール呼び出し能力:検索エンジン、データベース、API、自動化ツールなどの外部リソースを柔軟に呼び出し、タスクに必要な操作を完遂する。
- 継続的学習と最適化:一部の高度なエージェントは継続的な学習と最適化能力を備え、長期使用によりパフォーマンスを向上させる。
例え話
- 従来のソフトウェアは「ツールボックス」のようなもので、各機能は手動でクリック・操作する必要があります。
- 一方、エージェントは「熟練のアシスタント」のようなもので、「何を達成したいか」を伝えるだけで、どのツールを使い、どの順序で、どのように突発事態に対応するかを自ら判断し、最終的に目標を達成します。
利用シーン
インテリジェントアシスタントは多くの業務分野で広く活用されており、代表的なシーンは以下の通りです:
-
企業の自動化オフィス業務
- 日報、週報、会議録、メールなどの自動作成
- スケジュール自動管理と会議調整
- データの自動分析およびグラフ・結論レポートの生成
-
金融サービスとリスク管理
- コンプライアンスや監査レポートの自動生成
- リスクの世論監視と異常事象の検知
- 顧客リスク評価と信用スコアの自動化
個人AI Studioの作成方法
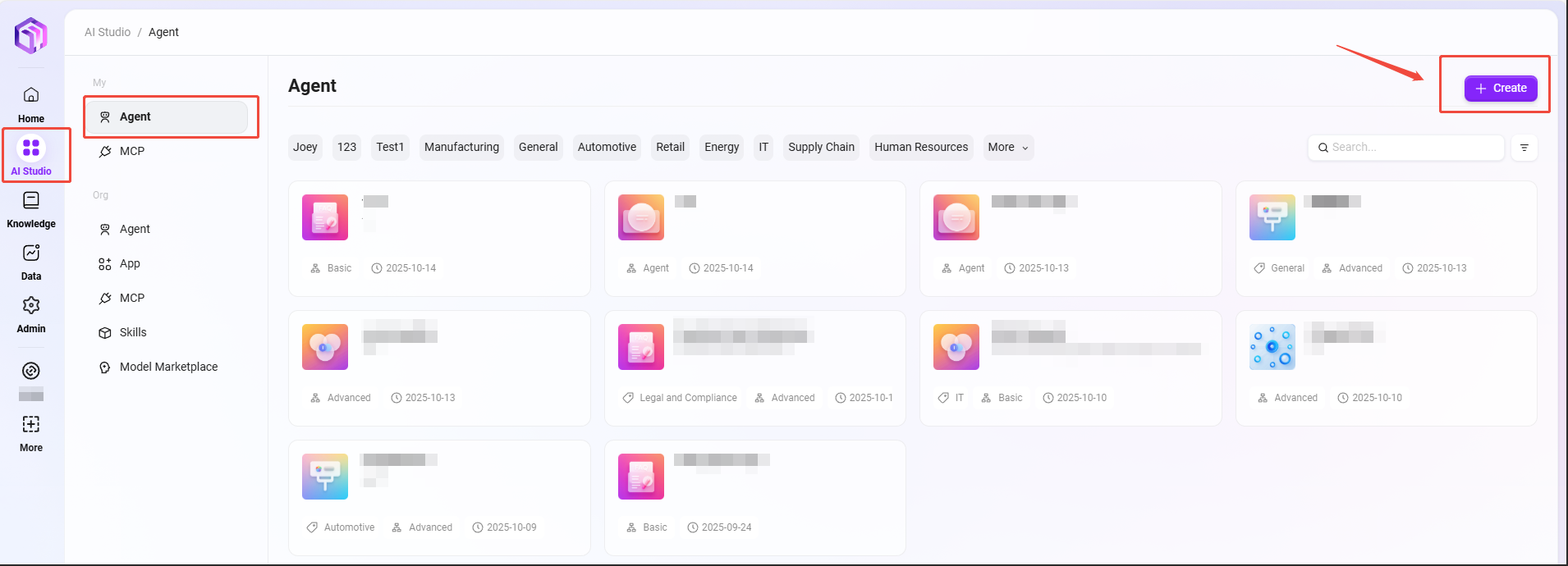
基本的なAgentの作成
-
AI Studioページ右上の「作成」をクリックし、基本エージェントを作成します。
-
作成手順
-
アシスタント名の入力、アシスタントアイコンの選択、モデルグループの選択、アシスタント分類の選択、アシスタント説明の追加:
① アシスタント名:アシスタントの識別名として入力します。
② アシスタントアイコン:アシスタントのデフォルトアイコンを選択します。現在はアップロード不可。
③ モデルグループ:アシスタントに適したモデルグループを設定します。
④ アシスタント分類:新規作成アシスタントの所属グループを選択(複数選択可)。
⑤ アシスタント説明:簡潔な説明を入力し、アシスタントの機能や用途を明示します。 -
「作成」をクリックすると、アシスタント作成後に基本編成の設定ページに遷移し、設定・公開後に利用可能となります。
-
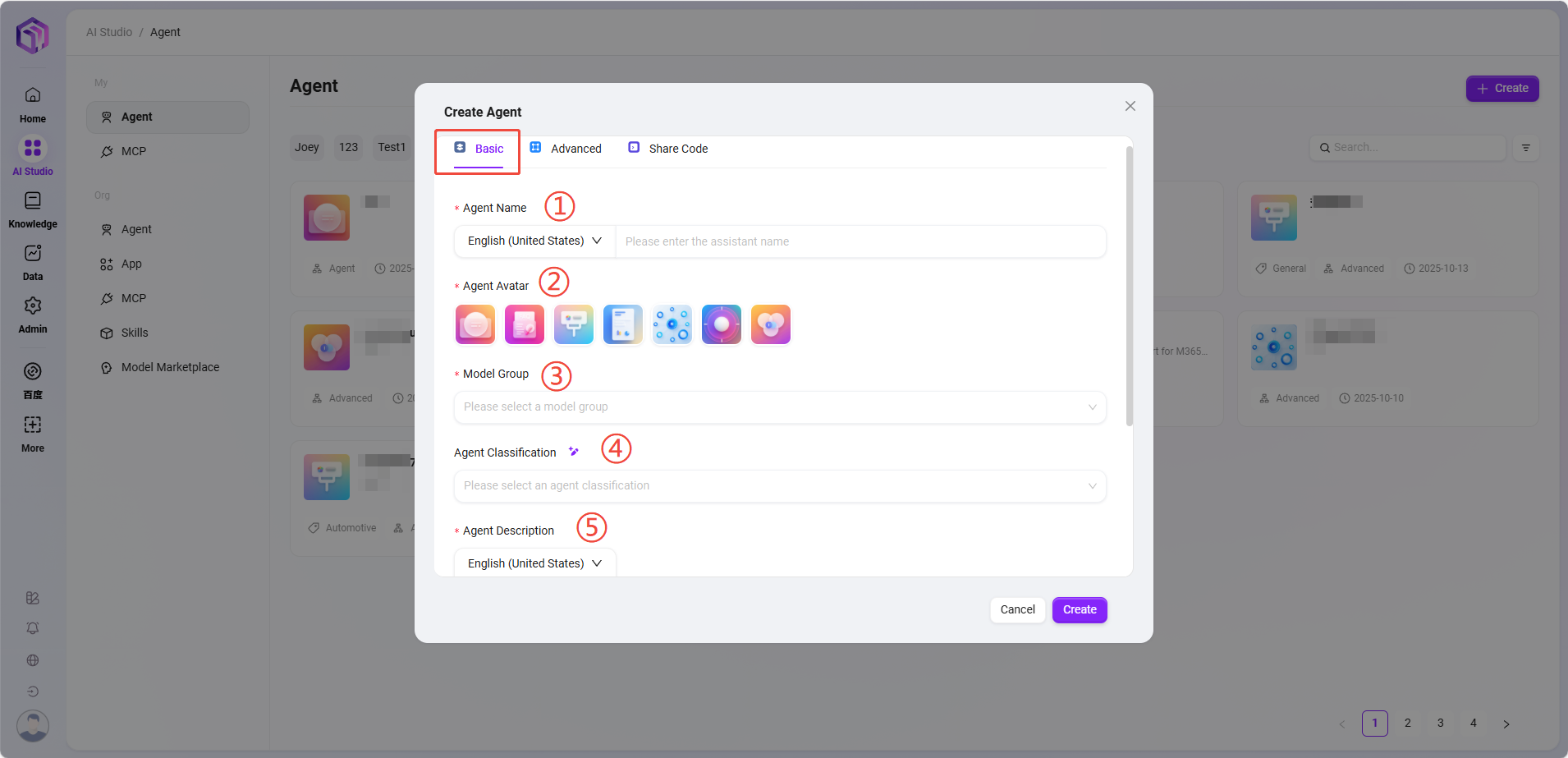
- アシスタント設定
アシスタント設定へのアクセス方法は2通りあります:
-
アシスタント作成後に直接設定ページに遷移する。
-
アシスタントカードにマウスをホバーすると「✏️」アイコンが表示され、クリックで設定ページに入る。
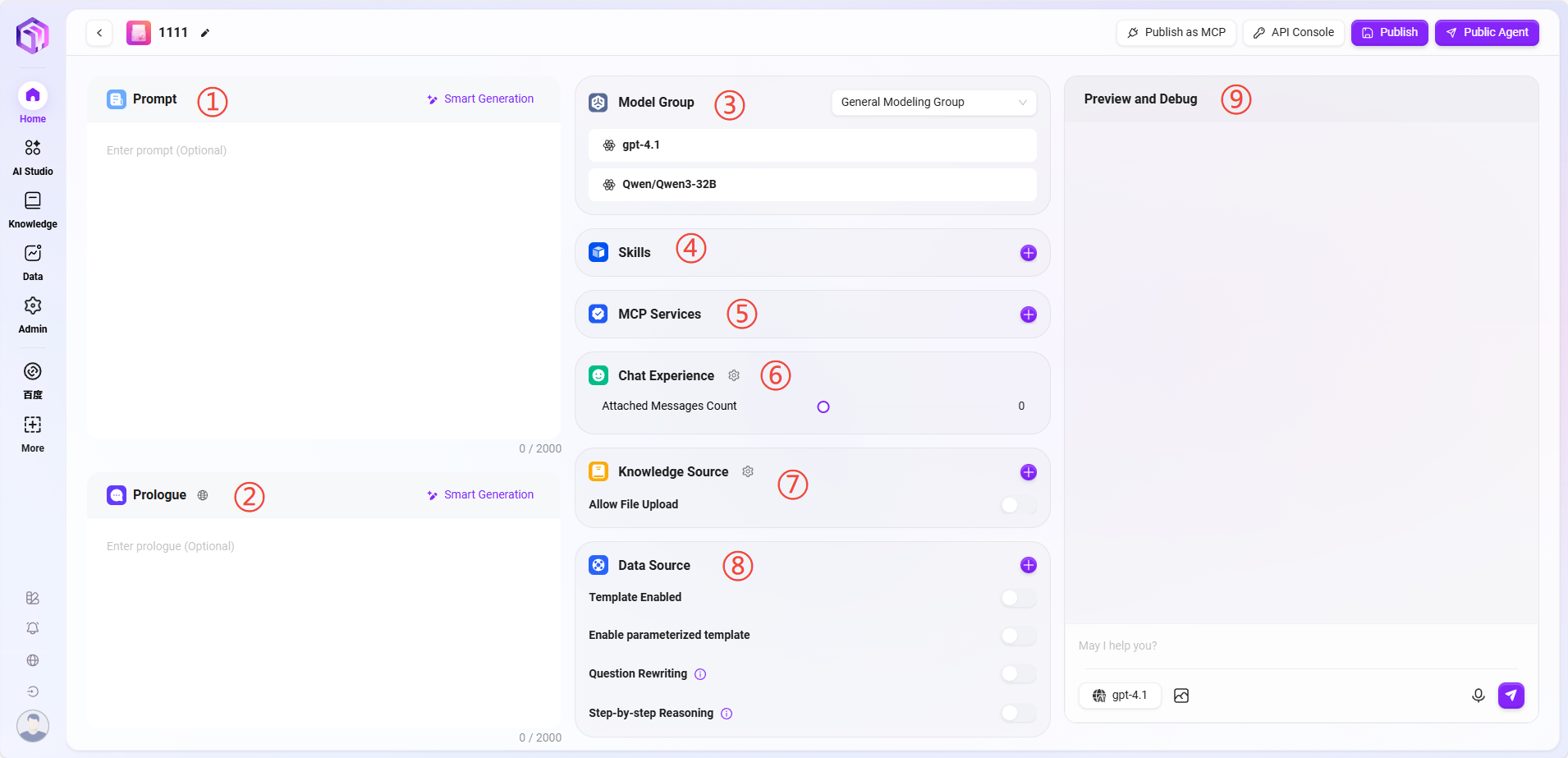
① プロンプト:アシスタントのプロンプトを入力。既存のプロンプトからのインテリジェント生成も可能。文字数制限は2000字。
② オープニングメッセージ:アシスタントの開始メッセージを入力。プロンプトや既存の開始メッセージからのインテリジェント生成も可能。文字数制限は2000字。
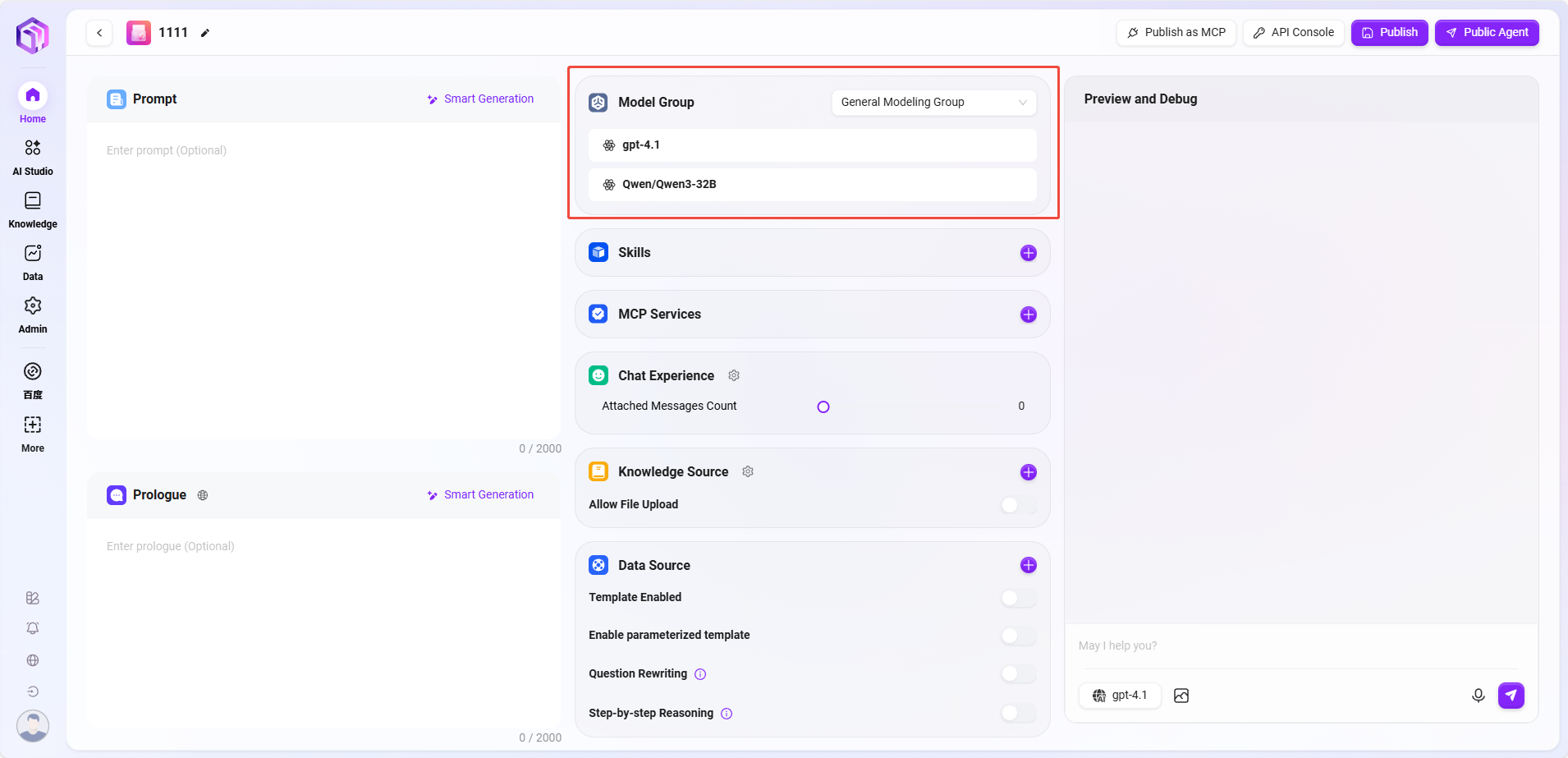
③ モデルグループ:「+」をクリックしてモデルグループを追加。複数のモデルを選択可能。
備考:モデルグループは管理者がシステム管理で先に作成し、複数の異なるモデルを同一グループにまとめてから、アシスタントに割り当てます。
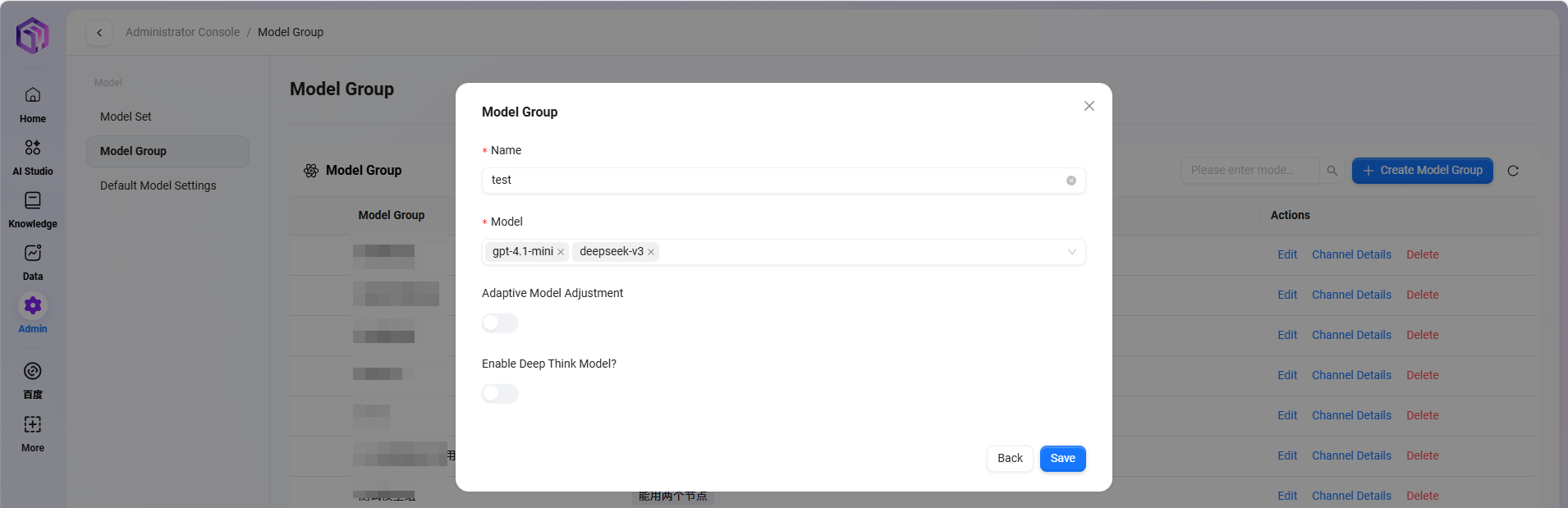
モデルグループの追加
-
パス:管理 → モデル管理 → モデルグループ → 新規モデルグループ(管理者のみ追加可能)
-
追加手順:
- 「新規モデルグループ」をクリック
- 以下を設定:
- モデルグループ名を入力
- モデルグループに追加するモデルを複数選択可能
- 自動適応モデルデプロイの有無を選択
- 深層思考モデルの有効化を選択
- 「保存」をクリック
-
自動適応モデルデプロイ:トラフィックに応じて計算リソースを自動調整し、サービスの安定性とスムーズさを確保。
-
深層思考モデル:複雑な問題に直面した際により強力なAIを呼び出し、回答品質を大幅に向上。

④ スキル:「+」をクリックして1つまたは複数のスキルを追加、推奨スキルも追加可能。

デフォルトスキルは5つ:Google検索、Tencent検索、テキストから画像生成、ニュース検索ツール、ウェブページ読み取り。
- Google検索:Google検索エンジンを通じてリアルタイムかつ正確なネット情報を取得し、世界中のウェブコンテンツを検索可能。
- Tencent検索:Tencentの検索技術に基づき、中国語インターネット環境に特化した検索サービスを提供し、中国語コンテンツの検索精度を最適化。
- ニュース検索ツール:各種ニュース情報の検索・取得に特化したツール。
- ウェブページ読み取り:ウェブページのテキストやデータを抽出し、ページ情報を解析。
- テキストから画像生成:テキスト記述に基づき対応する画像を自動生成し、文字の創造性を視覚的に表現。
備考:他のスキルの追加も可能で、管理者による操作・設定が必要。
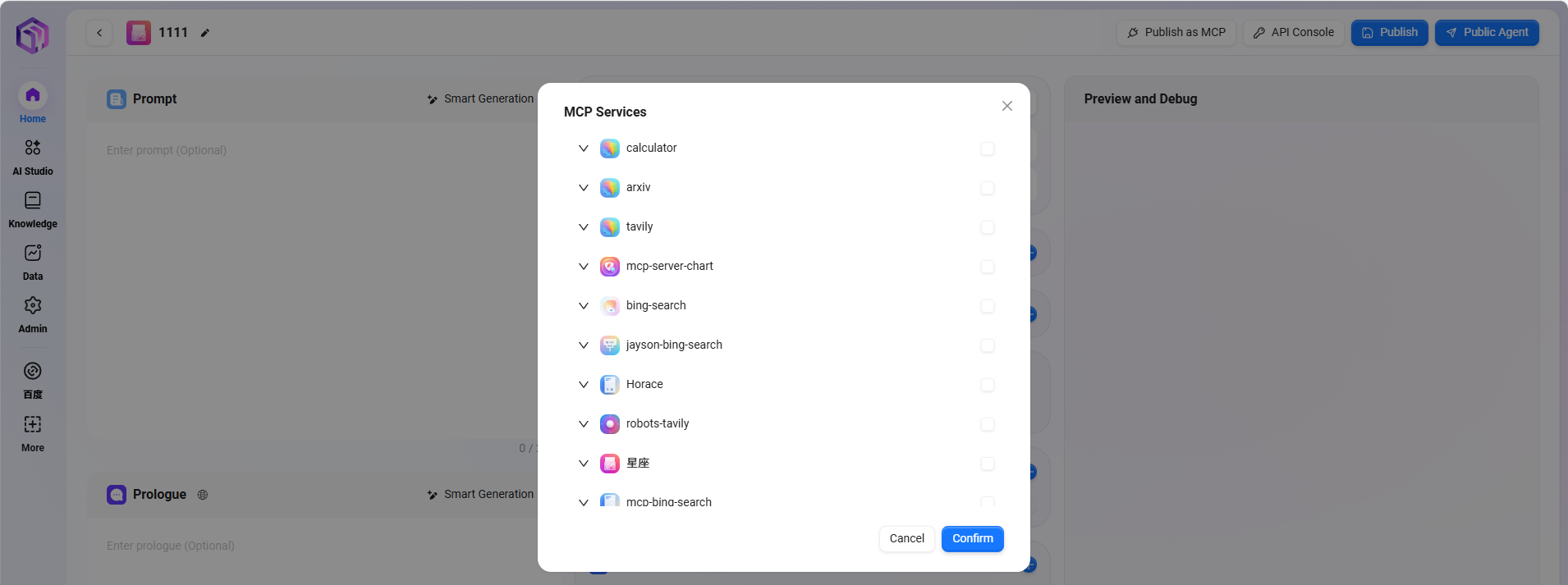
⑤ MCPサービス
-
MCPサービスはシステム内のAIアシスタントと外部ツール・データソースの接続権限を管理
- 能力拡張:AIアシスタントに検索、計算、可視化などの実用機能を付与。
- エコシステムの充実:各種ツールサービスを継続的に統合し、多様なニーズに対応。
- 標準化された接続:個人MCPを通じて内部システムリソースを統合。
⑥ 対話体験:
- 対話設定:「ユーザー質問提案、質問誘導、チャット履歴、対話フィードバック、キーワード審査」などの設定を有効化可能
- ユーザー質問提案:アシスタントの回答後、前文に基づきユーザーに質問提案を行う。
- 質問誘導:ユーザーとアシスタントの対話中に関連質問を誘導し、モデルの能力でユーザーの質問を推測・補完。
- チャット履歴:アシスタントのチャット履歴を保存するかどうか。無効にすると履歴は参照不可。
- 対話フィードバック:アシスタントの回答に対して「いいね」「よくないね」などのインタラクションを行い、回答の最適化に活用。
- キーワード審査の有効化:入力内容と出力内容のいずれか少なくとも1つを審査。オンにするとプロンプトやAIのフィードバック結果に対して敏感語検出を行い、敏感語は事前に管理可能。

⑦ ナレッジベース:
-
ナレッジベース:「+」をクリックしてナレッジベースを追加
- ファイルアップロードの許可:
- 許可をオンにすると、ナレッジベースの内容を知識ソースとして追加不可
- 許可をオフにすると、個人スペースまたは企業スペースのナレッジベースを選択的に知識ソースとして追加可能
- ファイルアップロードの許可:
-
ナレッジベース設定:「検索戦略、プライベートQA、検索方式」など詳細設定を変更可能
1)検索戦略:ハイブリッド検索、埋め込み検索、テキスト検索- ハイブリッド検索:ベクトル検索と全文検索の結果を統合し、再ランキングした結果を返す
- 埋め込み検索:類似度に基づく断片検索で、ある程度の多言語汎化能力を持つ
- テキスト検索:キーワードによる断片検索で、特定キーワードや名詞断片を含む検索に適する
2)最大リコール数:1~10の範囲。高すぎ・低すぎは推奨されず、3~5が推奨値。
3)メタデータフィルタリング:なし、フィルタリング、重み付け
4)強制プライベートファイルQA:オンにするとネット検索などのスキルを使わず、アシスタントの回答はナレッジベースの内容に限定される。
5)ドキュメントマッチング類似度:0~1の範囲。類似度が高いほどリコールされたドキュメント内容が類似。推奨値は約0.8(80%)。
6)QnAマッチング類似度:0~1の範囲。ドキュメント内容の類似度マッチに類似し、推奨値は約0.9(90%)。
7)参考文献の表示:オンにすると、アシスタントが回答時に参照した文献を列挙し、回答の信頼性を向上。
💡 ヒント:最大リコール数、ドキュメントマッチング類似度、QnAマッチング類似度は高ければ良い、低ければ良いというものではなく、実際のニーズに応じて設定してください。特に指定がなければデフォルト値を推奨します。

⑧ データソース
-
データソース:「+」をクリックしてデータソースを追加し、アシスタントのQAデータソースとする
-
テンプレートの有効化:自然言語とSQL間の事前マッピングテンプレートを有効にするかどうか。
- ユーザーが自然言語で質問(例:「
先月の売上はいくらですか?」)を入力すると、システムはまず事前設定されたテンプレートとマッチングを試みる。 - マッチするテンプレート(例:「
特定期間の売上を照会する」のような一般的な質問)が見つかれば、テンプレート内のSQL構造を参考にし、具体的なフィールド名やテーブル名を組み合わせて最終的なSQL文を生成する。
- ユーザーが自然言語で質問(例:「
-
パラメータ化テンプレートの有効化:オンにするとテンプレートに基づくパラメータ化クエリを有効化し、クエリの柔軟性と安全性を強化。
-
質問リライト:オンにするとユーザーの質問を自動的に最適化し、正確なデータクエリを保証。
- ユーザーの元の質問:
売上を調べて(情報不足) - リライト後の質問:
2024年7月の全製品の総売上を照会(期間と範囲を補完)
- ユーザーの元の質問:
-
ステップバイステップ思考:この機能をオンにすると、最終クエリ結果生成前に詳細な思考過程を出力し、問題分析とSQL構築の過程を説明。
- ステップ1:キーワード「
2024年7月」「売上」を認識 - ステップ2:データテーブル
Orders、フィールドorder_dateとsales_amountを特定 - ステップ3:日付範囲条件
2024-07-01から2024-07-31を構築 - ステップ4:SQLを生成
- ステップ1:キーワード「

ワークフローによるAgent作成
- 「高度なエージェント」を選択(作成手順は通常のエージェントと同様)
- 構築タイプ
- 進階モード:複雑なワークフローを迅速に構築し、ビジネスニーズに正確に対応。
- アプリケーションモード:ユーザーフレンドリーなインターフェースを備えた完全で高度な編成アプリケーションを作成し、シームレスな小型言語モデル体験を提供。
- 構築タイプ

- 実際の業務に応じてワークフローを設定:
- 開始、終了:入力・出力モジュールを標準搭載し、入力・出力パラメータやフィールドをカスタマイズ可能。
- モデル:このモジュールで使用モデルを選択し、他モジュールから取得した変数を入力、プロンプトや出力メッセージを編集し、変数形式で保存。
- ナレッジベース検索:選択したナレッジベースから入力変数に基づき最適な情報を呼び出して返す。
- スキル:任意のスキルを選択し、そのスキルを介した入出力操作を実行。
- コード:他モジュールの出力変数を基にコード関数をカスタム作成。
- セレクター:複数の下流分岐を接続し、条件が成立した分岐のみを実行。条件が成立しない場合は「それ以外」分岐を実行。
- 意図認識:ユーザー入力の意図を認識し、事前設定した意図オプションとマッチング。
- テキストフォーマッター:複数の文字列型変数のフォーマット処理。
- データソース:データソースを選択し、参照可能な変数内容を増やす。
- ファイル検索:アップロードされたファイル内を検索し、入力質問に関連する回答を探す。
- ループ:リスト内の各項目に対して一連のタスクを繰り返し実行し、並列処理も選択可能。

- ノード詳細説明
- 開始
- 開始ノード:ワークフローの起点で、起動に必要な情報を設定。
- 入力:LLMにタスク完了に必要な基本情報(入力パラメータ)を事前に伝え、対話中にタスク起動のタイミングを検知すると自動的に呼び出し、対応箇所にパラメータを挿入してフローを開始。
- 処理ロジック:バイパス(By pass)で直接伝達し、ユーザー入力内容をそのまま次ノードに渡す。
- 出力結果:すべての入力内容をそのまま出力。

- モデル
- モデル:大規模言語モデルを呼び出し、変数とプロンプトを用いて応答を生成。
- 入力:既存モデルをドロップダウンから選択し、入力変数名を指定。
- 入力パラメータ:query(String、上流またはユーザー入力由来)
- 設定パラメータ:
- 1つ以上のツール
- モデル
- GPT(GPTまたは他モデル)
- Temperature:創造性を制御。数値が高いほど創造的かつランダムな回答。
- Top P:確率閾値で選択語彙範囲を制限し、多様性を制御。
- Max Reply Length:AIが一度に返信可能な最大文字数。
- System Prompt:AIに対する隠し指示で全体のスタイルを制御。
- User Prompt:ユーザーの入力内容や質問。
- History:過去の対話ラウンド数でコンテキスト理解を維持。
- 処理ロジック:入力をLLMに渡し、設定に基づき回答を生成。
- 出力結果:モデルが生成したテキスト内容。
💡 ヒント:前段ノードと接続して初めて、他ノードの変数を現在ノードの入力変数として選択可能。

-
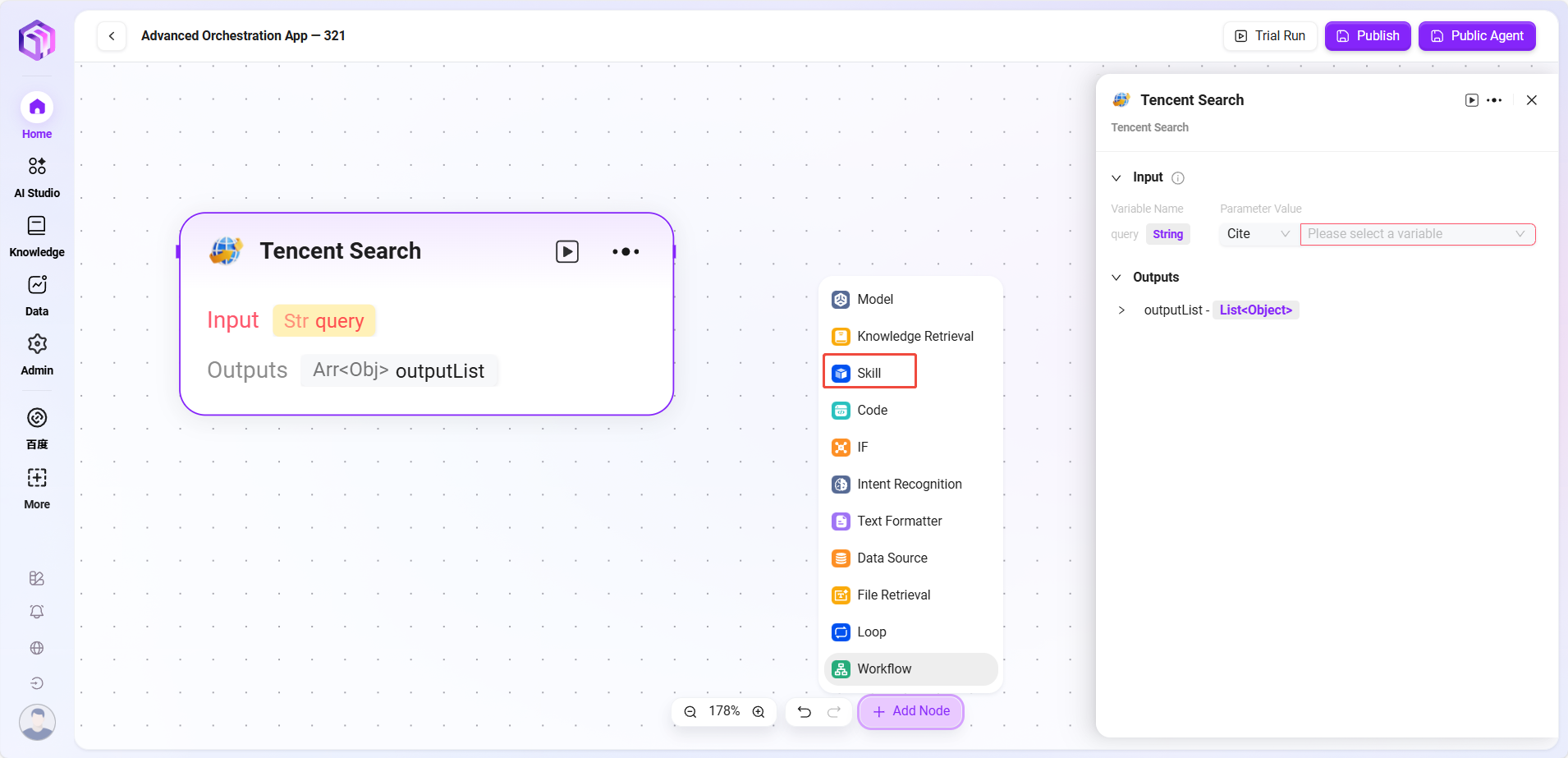
スキル(一部例)
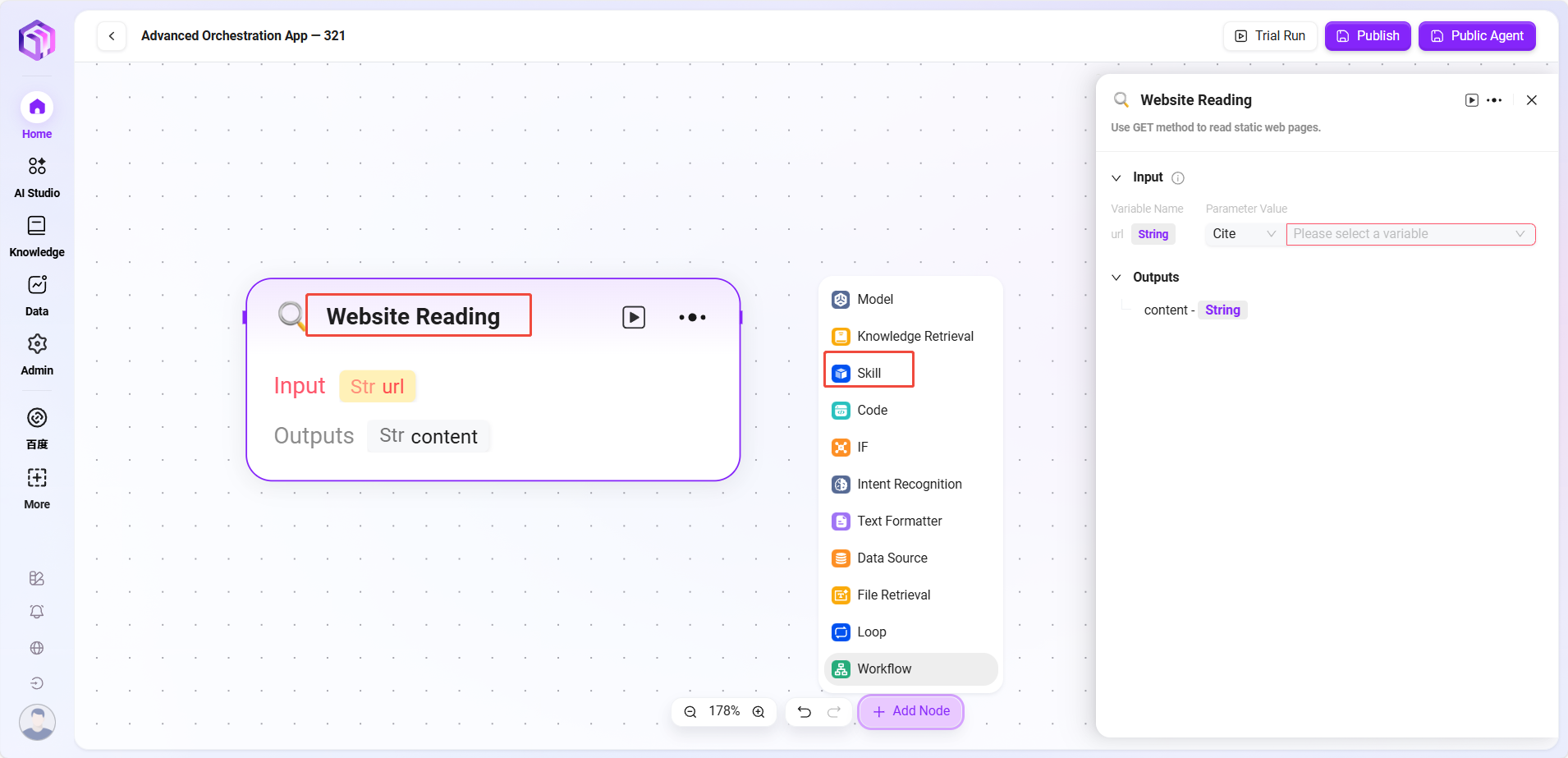
- ウェブサイト読み取り:ウェブページ上の静的テキストを読み取る(動的ロード内容は不可)。
- テキスト生成画像:テキストを画像に変換(画像URLを出力)。
- Tencent検索:検索エンジンを呼び出し、検索結果を返す。
- コード
- コード:コードを記述し、入力変数を処理して戻り値を生成。
- 入力:外部から渡される変数を受け取り、コード実行に必要なデータ入口となる。
- 入力パラメータ:query(string、ユーザーまたは上流からのコードリクエスト)
- 設定パラメータ:コード実行関連の設定
- 最大実行時間(Maximum Runtime)
- コード内容(Code Input)
- 処理ロジック:
- 安全なサンドボックス環境(RestrictedPythonまたは指定プラットフォーム)でコードを実行。
- 実行時間とアクセス権限を制限し、安全リスクを回避。
- 出力結果:コード実行後の結果を指定変数形式で出力し、コード処理結果の出口となる。

-
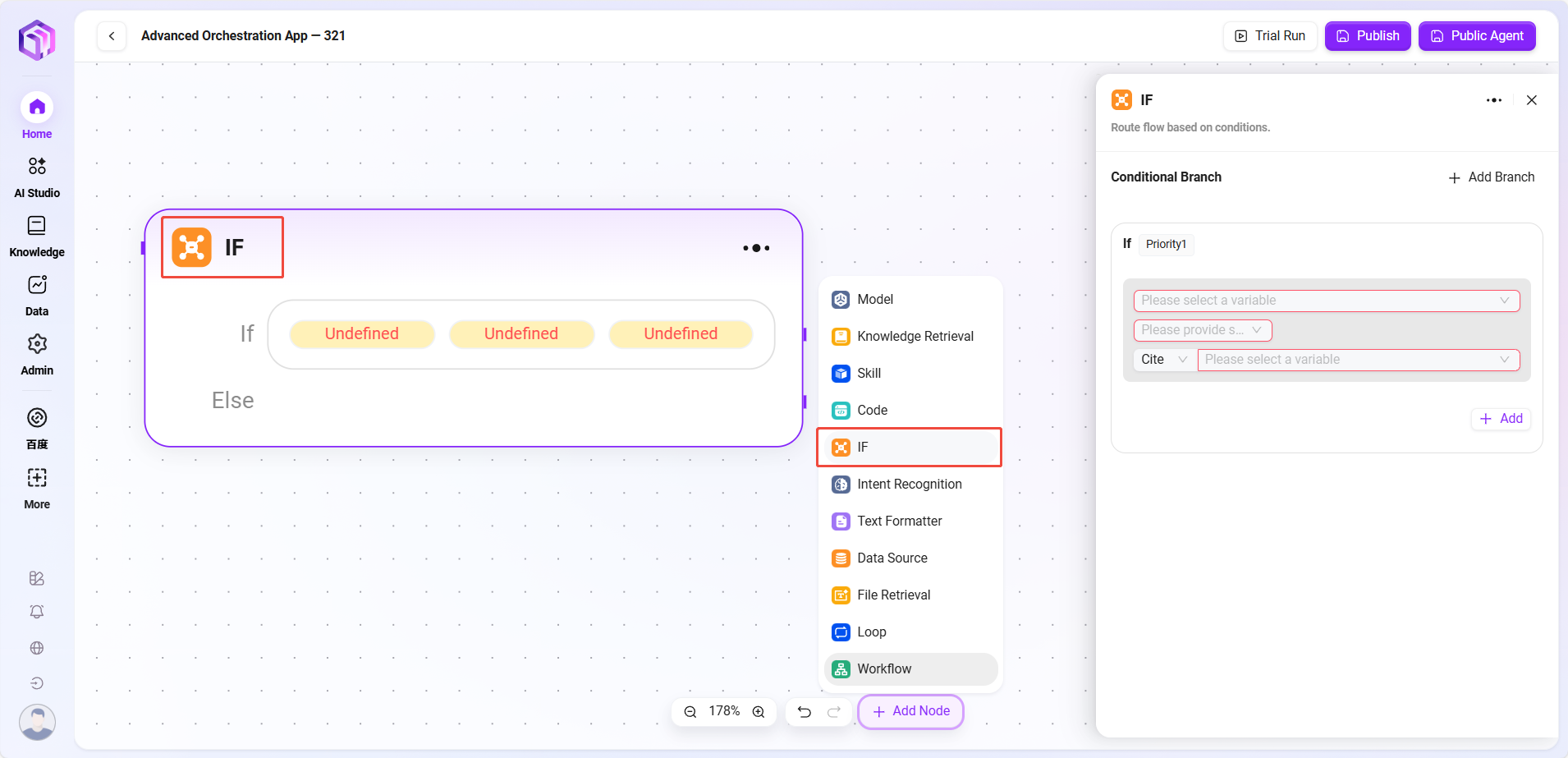
セレクター
- セレクター:フロー編成における条件判断役割。複数の下流分岐を接続し、設定した条件により実行経路を決定。
- 条件分岐:複数の条件(例:「if - 優先度1」)を設定可能。変数参照、条件選択(等しい、大きいなどの比較ロジック)、比較値を設定し、条件成立時に対応分岐を実行。
- 処理ロジック:条件に応じて異なる経路を通る(条件不成立時はElse経路)。
- 出力結果:直接の出力はなく、次ノードの進行方向を決定。
-
意図認識
- 意図認識:自然言語処理の重要な段階で、ユーザー入力の真意を分析し、事前設定した選択肢とマッチング。
- モデル:意図認識に用いるモデルを選択し、認識能力と効果を決定。
- 意図マッチング:ユーザー意図の説明を事前に入力しマッチング基準とし、他の意図も追加可能。システムはユーザー入力がどの意図に該当するか判断。
- 高度設定:システムプロンプト内容を設定可能で、入力変数を参照してプロンプト効果を最適化。履歴記憶数も設定可能で、過去対話情報を参照し認識精度を向上。
- 処理ロジック:ユーザーの真意を判定し、入力を対応カテゴリに分類。

- ナレッジベース検索
- 入力:変数名とパラメータ値を定義し、ナレッジベース検索のキーワードなどの原始データを提供。
- 処理ロジック:入力とパラメータに基づきナレッジベースを検索し、断片やFAQを返す。
- ナレッジベース:特定のナレッジベースを検索範囲として選択し、その範囲内でマッチ情報を検索。
- 最大リコール数:ナレッジベースから返す最大マッチ結果数を設定し、過剰なデータ返却を防止。
- 出力:検索したマッチ情報を指定変数形式で出力し、後続フローで利用。

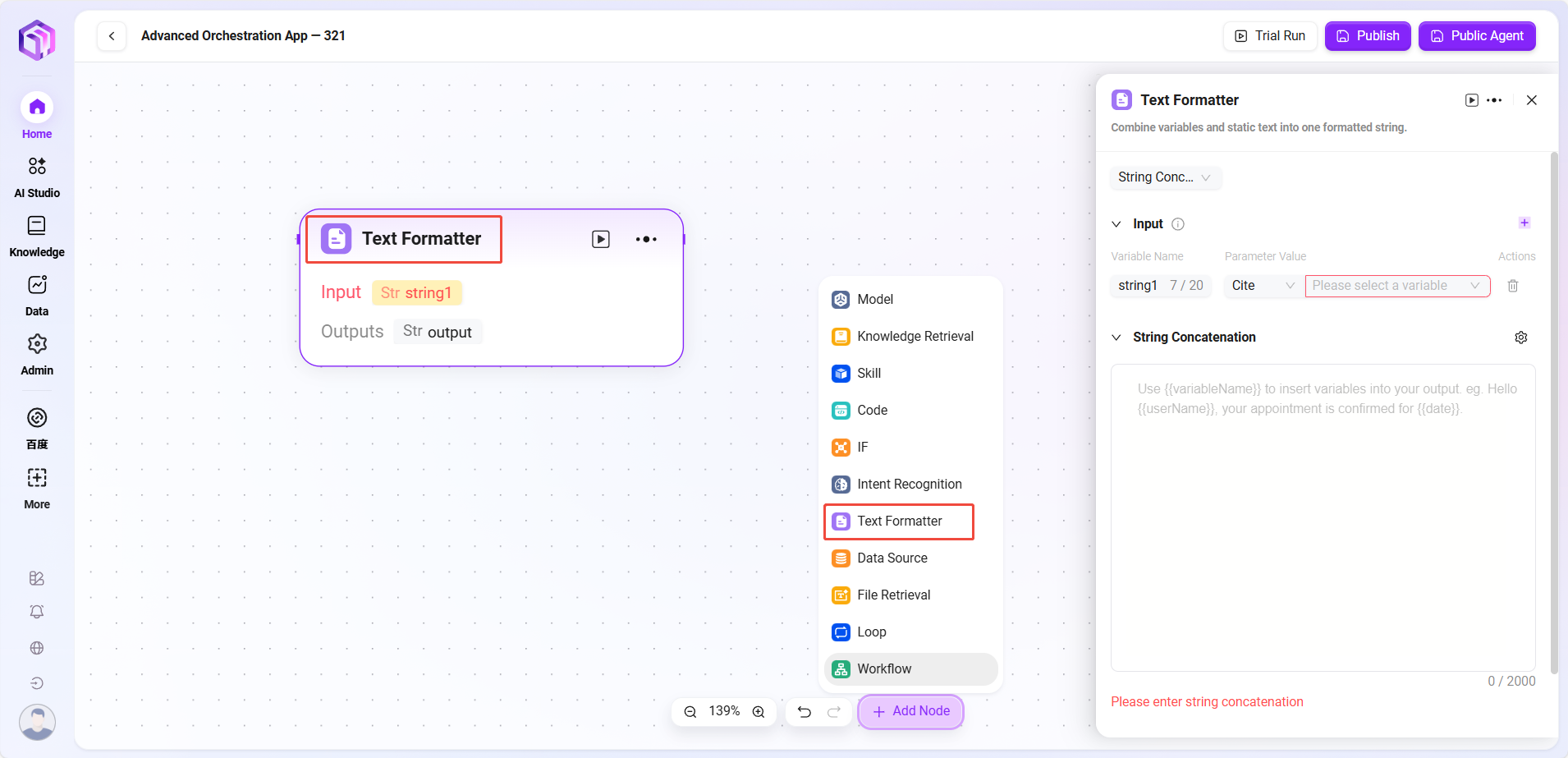
- テキストフォーマッター
- テキスト:主に文字列型変数のフォーマット処理に使用。
- 入力:変数名を定義し、参照方式でパラメータ値を取得し、後続のテキスト処理に原始文字列データを提供。
- 処理ロジック:テキストを簡単に加工
- 文字列の連結
- 文字列の分割
- 文字列連結:テキスト編集エリアを提供し、必要に応じて変数名で入力変数を参照し、複数文字列の連結などのフォーマット処理を実施。
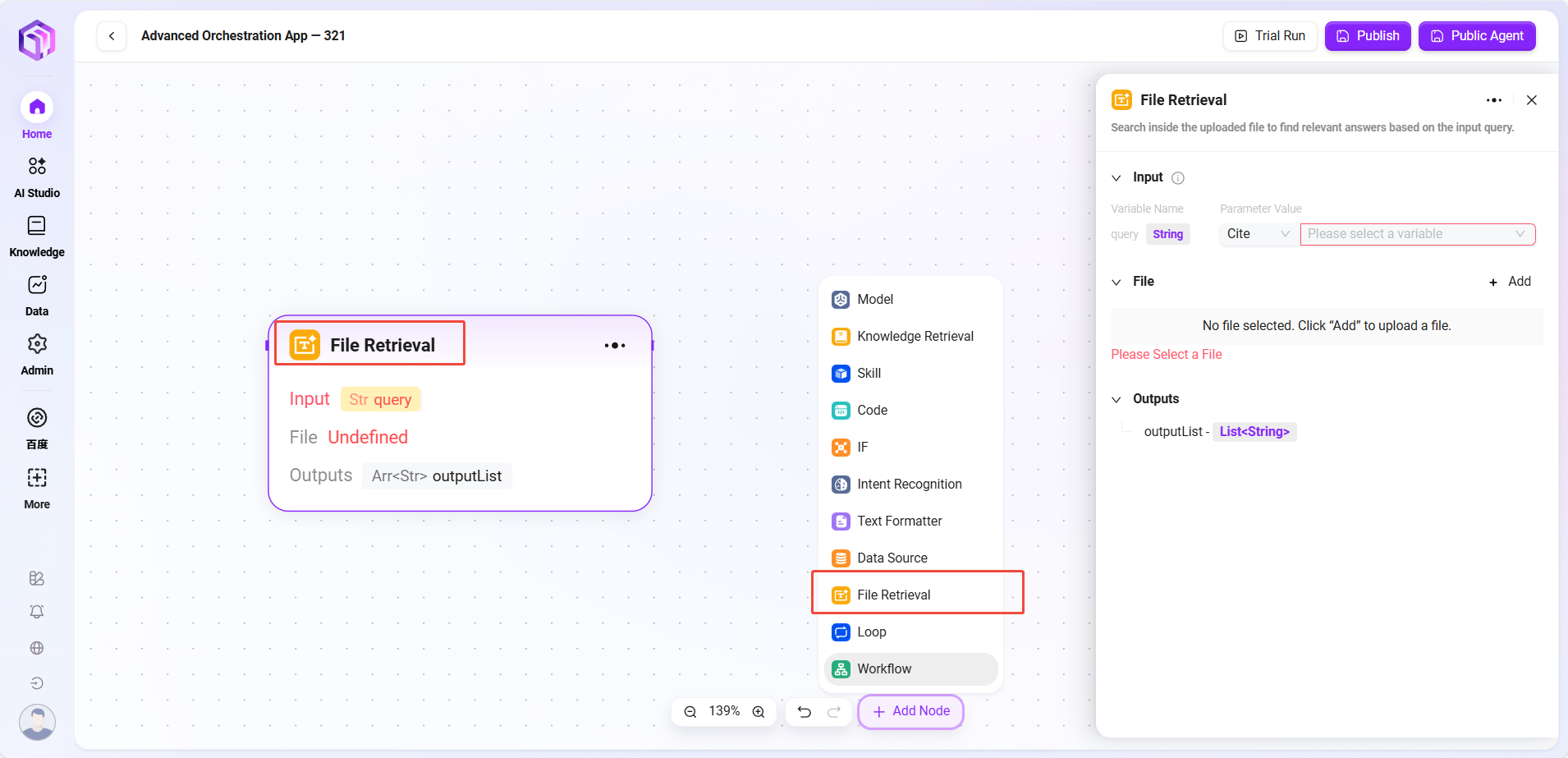
- ファイル検索
- ファイル検索:ファイル内容の検索などの操作モジュール。
- 入力:変数名を定義し、パラメータ値を参照して検索キーワードなどの入力情報を提供し、ファイル内容検索の根拠とする。
- ファイル:処理対象のファイルをこのノードに追加し、検索範囲を確定。
- データソース
- データソース:接続するデータソースを選択。
- 処理ロジック:自然言語をSQLに変換しデータベースをクエリし、結果を返す。
- 出力:データソースのデータを出力し、次ノードに渡す。

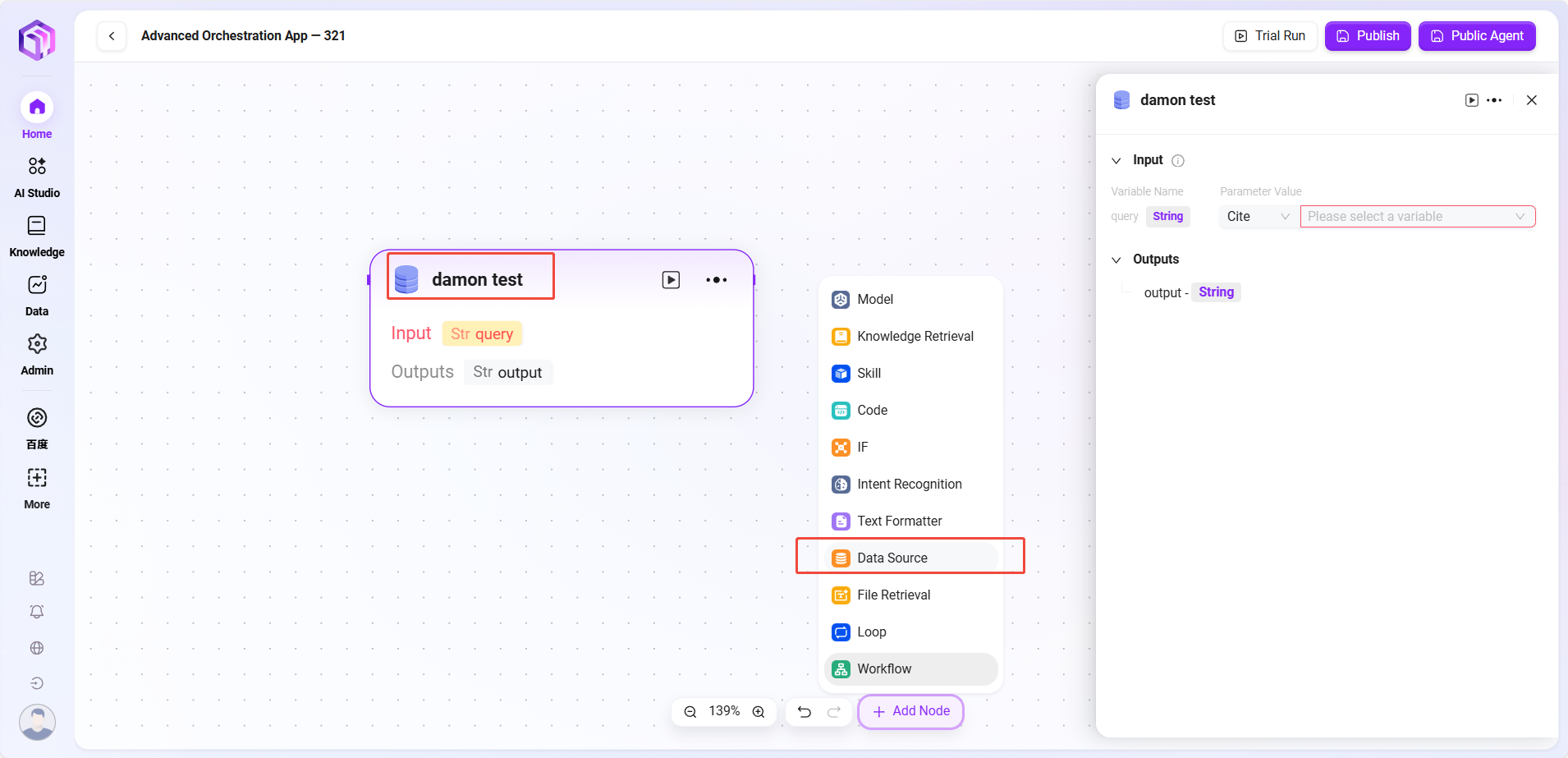
- ループ
- ループノード:指定回数または指定データ集合に基づき、一連のタスクを繰り返し実行。異なるループモードを設定し、バッチ処理や繰り返し操作を柔軟に実現。
- ループタイプ:2種類のモードをサポート
- 配列ループ:入力配列に基づき、配列内の各要素に順次タスクを実行。
- 数値ループ:設定回数に従いタスクを繰り返し実行。
- ループ数値/配列:
- 「数値ループ」選択時は具体的な数字を入力(例:2回実行)。
- 「配列ループ」選択時は配列変数を提供し、システムは配列の要素を順に取り出して入力としてタスクを実行。
- 並列実行:オプション機能。オンにすると複数のループタスクを同時処理し効率を向上。最大並列数を設定しリソース使用を制御可能。

ワークフロー例
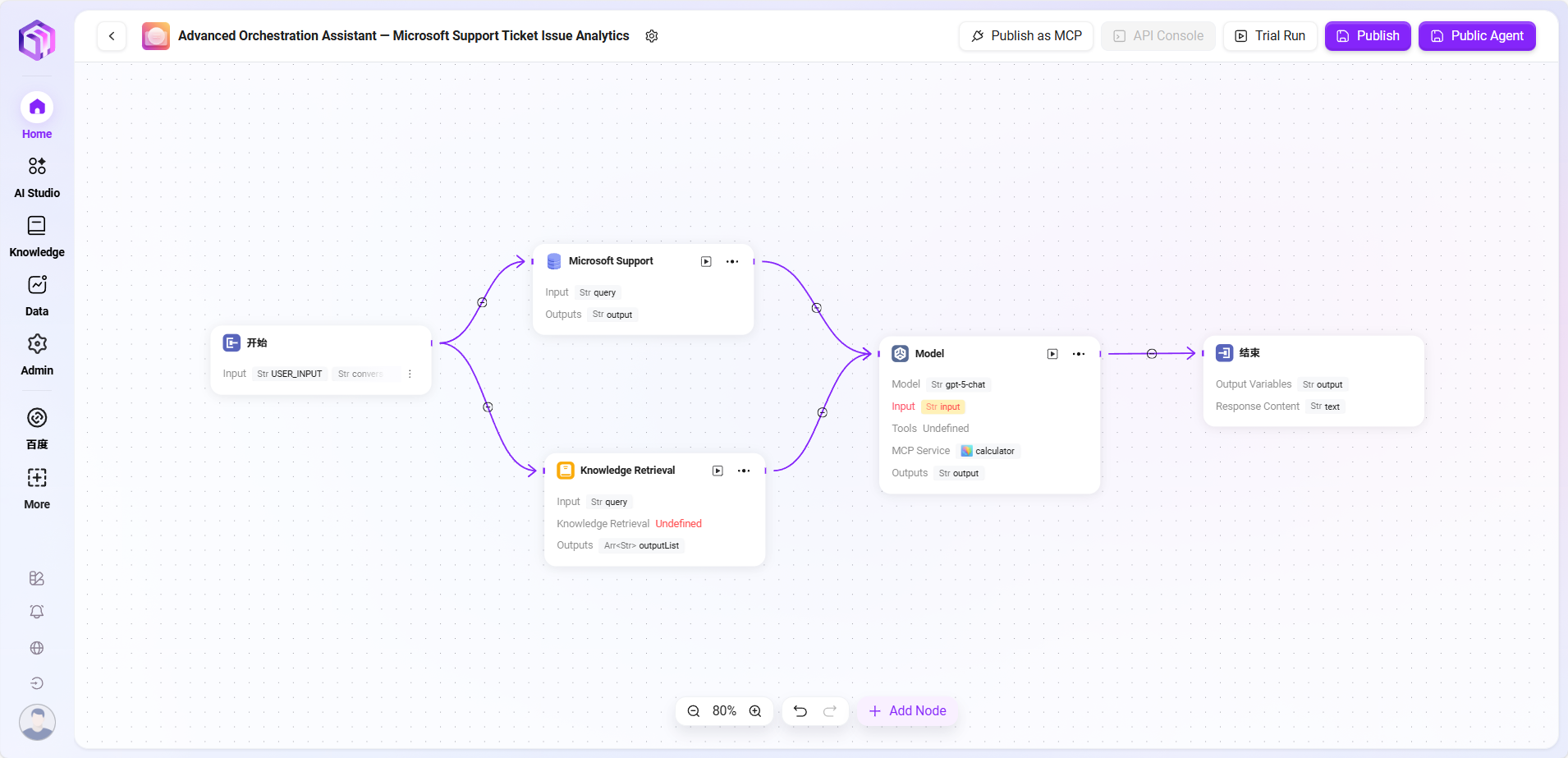
本シナリオでは、ワークフロー機能を用いて完全な「Microsoft Support Ticket Issue Analytics」プロセスを構築し、具体的な流れは以下の通り:
- 開始ノード
フローの起点で、システムによりデフォルトで含まれる。 - データソースノード
チケット分析に必要な原始データを接続。 - ナレッジベースノード
分析参考資料を含むナレッジドキュメントを接続し、AI分析の理論的支援とする。 - モデルノード
AIモデルを基に、データソースとナレッジベース内容を統合して総合分析を行い、チケット問題分析結果を生成。 - 終了ノード
フローの終点で、モデルノードの分析結果を出力。こちらもシステムによりデフォルトで含まれる。
データソースノードとナレッジベースノードは並列配置され、モデルノードが両者の情報を集約処理し、出力結果にデータ根拠と理論支援を保証。
最終結果は以下の通り:
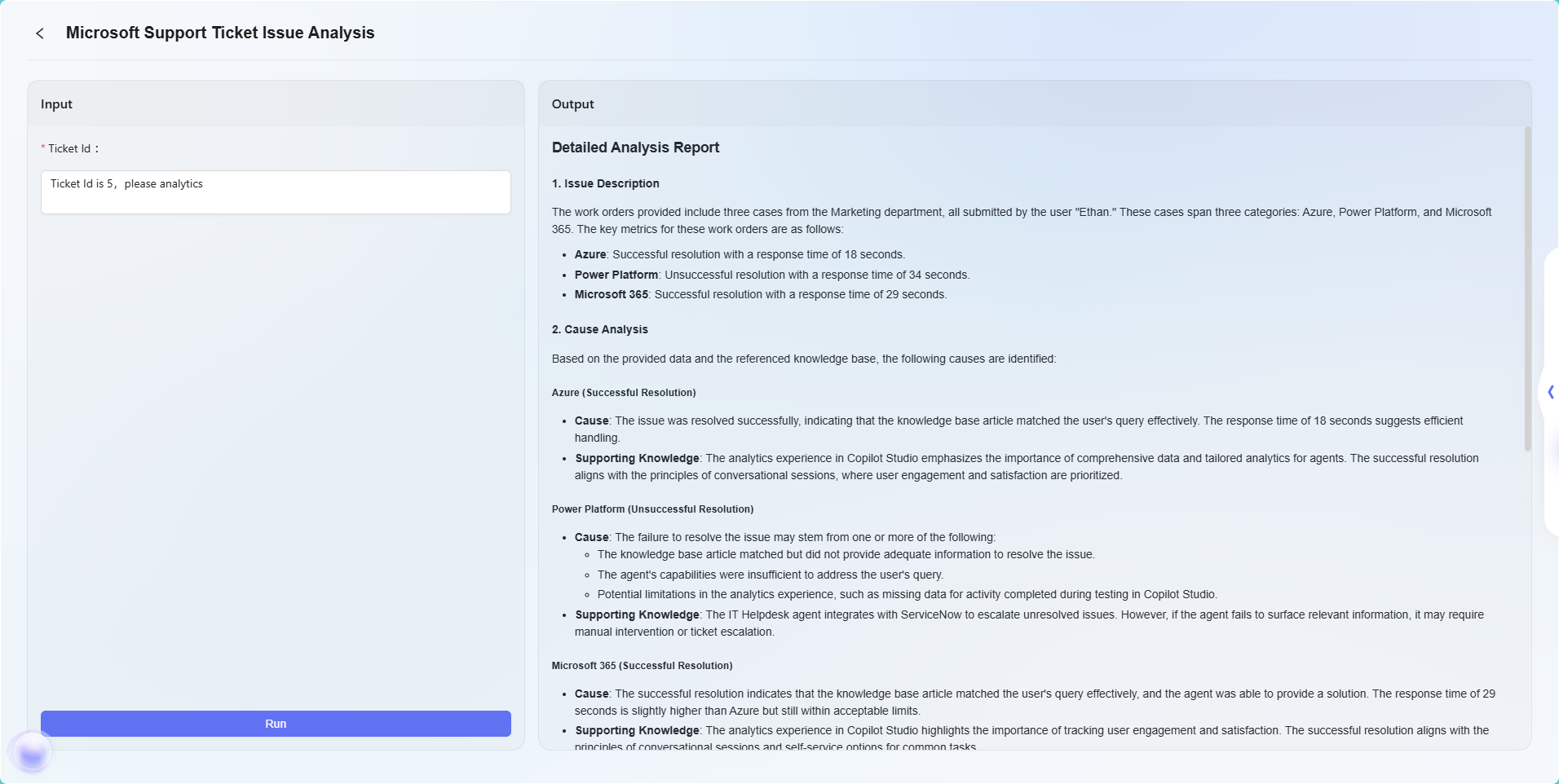
注:本例は高度編成機能の簡単な応用例であり、基本的なフロー効果を示すものです。高度編成は強力な柔軟性と拡張性を備え、多様なノードタイプを通じて複雑な業務ロジックやインテリジェントな自動化フローを実現し、多様な実業務シーンに広く適用可能です。
MCPとは
MCP(Model Context Protocol)はエージェントプラットフォームのコア拡張プロトコルであり、外部ツール、データソース、サービスと接続し、AIアシスタントに強力な能力拡張サポートを提供します。
機能モジュール
| 機能カテゴリ | 主な用途 |
|---|---|
| 計算サービス | 加算、減算、乗算、除算、剰余、平方根、べき乗計算 |
| 検索サービス | ネット検索、学術論文検索、データ抽出 |
| データ分析 | グラフ生成、分析能力 |
| ツール統合 | 地図サービス、コラボレーションツール統合 |
個人MCPの作成方法
-
AI Studioページ左側で「MCP」をクリックし、MCPページに入る。
-
MCPページで右上の「作成」ボタンをクリックし、MCP作成ページに遷移。
-
基本情報を入力
- MCP名:MCPの識別名として入力。
- MCPアイコン:デフォルトアイコンを選択。現在はアップロード不可。
- MCP説明:MCPの機能特徴と主な用途を簡潔に説明。
- MCP分類:新規MCPの所属カテゴリを選択。
- MCPサービス設定:JSONコードで外部サービスを登録し、アシスタントに新機能を付与。

