Building Complex Business Agent with Workflow
In SERVICEME NEXT, Agents created using the basic method are more suitable for simple Q&A scenarios and have relatively limited functionality. If you need to handle more complex business logic or implement multi-step operations, you can build advanced Agents through Workflow, meeting richer business requirements.
This section will demonstrate, through a concrete example, how to use Workflow to build a complex process.
Scenario Example: Sensitive Word Extraction from Contract Content
In real business scenarios, contract texts are usually lengthy and complex. Manually comparing and identifying whether they contain sensitive words is not only time-consuming and labor-intensive but also prone to omissions, especially when there are many sensitive words, making accuracy even harder to guarantee.
With Workflow capabilities, you can build an intelligent Agent that supports file upload, content parsing, sensitive word identification, and annotation, automatically completing the following operations:
- Receive contract files uploaded by users;
- Automatically parse the text content;
- Detect and extract sensitive words;
- Return results containing sensitive words and their locations.
Through this process, users can quickly understand the sensitive information in contracts without manual review, greatly improving review efficiency and accuracy.
✅ Tip: This type of Agent is especially suitable for scenarios such as legal review, content audit, and compliance management.
Preparing the Sensitive Word Data Source
Before building the workflow, you need to prepare the sensitive word data. In this case, the sensitive words are stored in a database, so you need to add the database as a data source through the Data module and complete data synchronization.
Prerequisites for Data Preparation
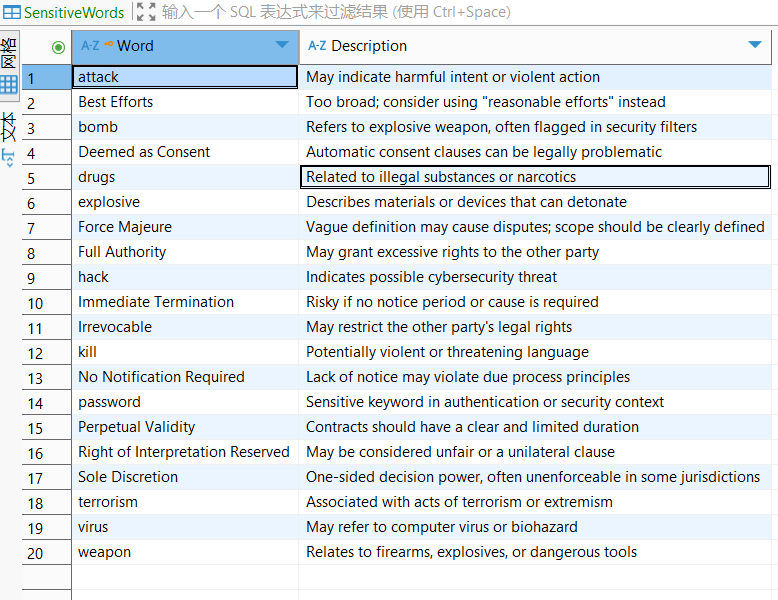
- Sensitive word data has been written into the database (table name is
SensitiveWords). - The database type is
SQLServerand is accessible via the network.
Steps to Add Data Source
- Enter the Data Module
- Open the SERVICEME platform and click "Data" in the right menu.
- Select "Data Sources" on the left to enter the data source management page.
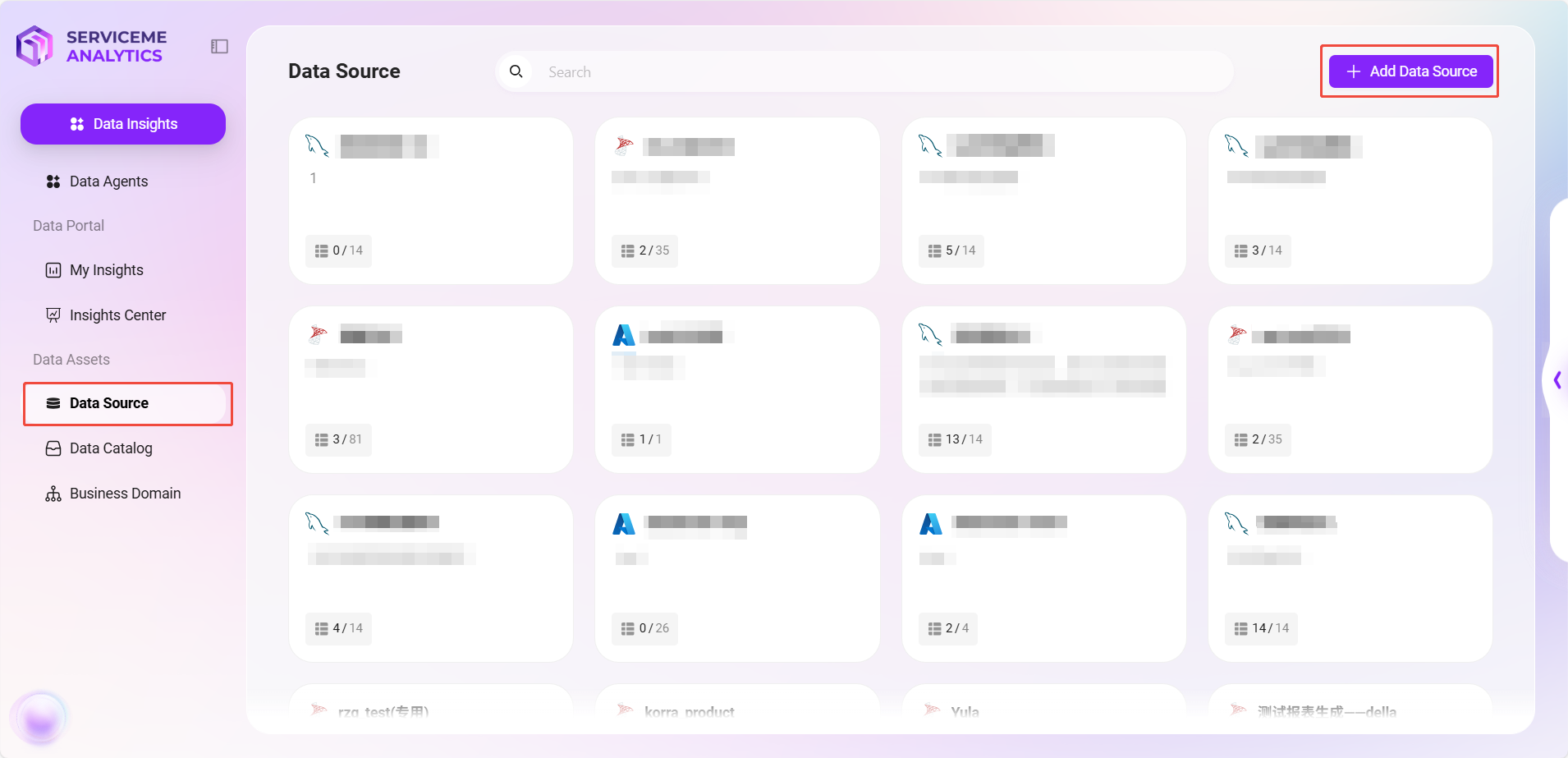
- Add Data Source
- Click the "Add Data Source" button in the upper right corner.
- Fill in the following information in the pop-up configuration window:
- Data Source Name: e.g.,
Sensitive Word - Database Type: Select
SQLServer - Connection Info: Includes
host,port,username,password,database name
- Data Source Name: e.g.,
- Click "Test Connection". After confirming the connection is successful, click "Confirm" to complete the addition.
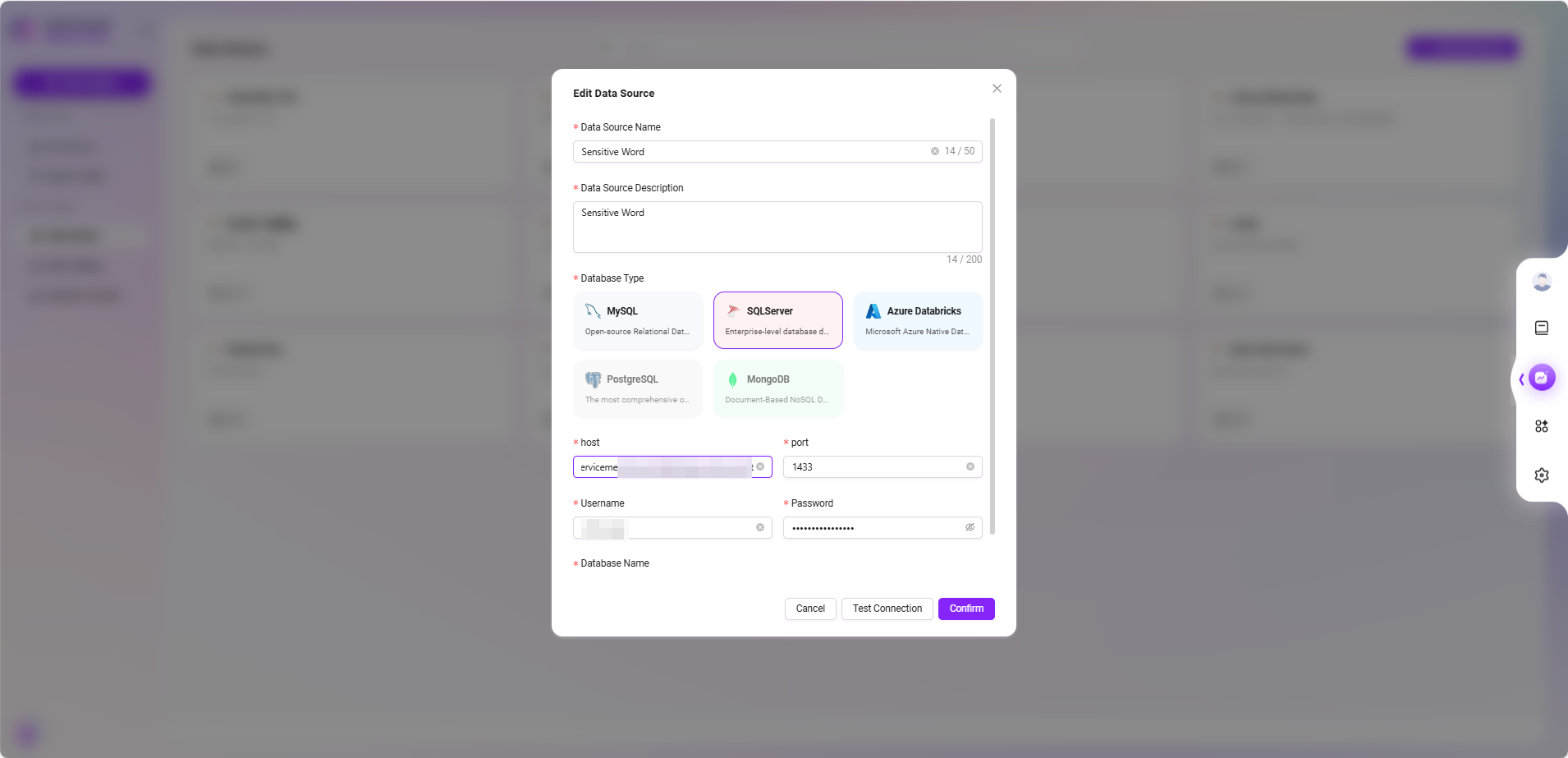
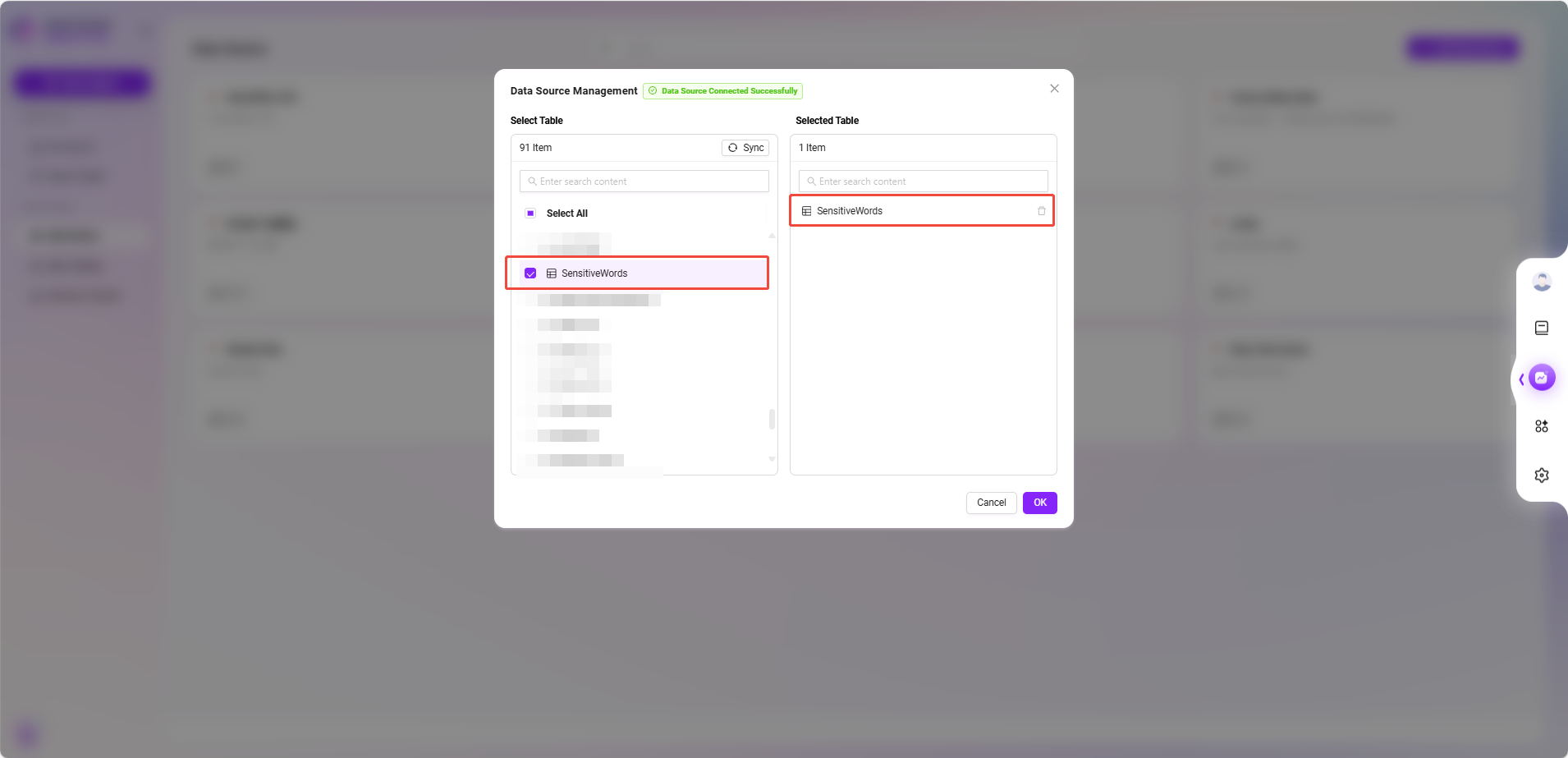
- Select Data Table
- Return to the data source list and click the newly created data source item.
- The system will display available data tables in the database. Check the table containing sensitive words (e.g.,
SensitiveWords) and click "OK" to add.
- Data Catalog Synchronization
- Select "Data Catalog" in the left menu, find and click the
Sensitive Worddata source. - Perform the "Sync" operation to ensure the platform obtains the latest data.
- Select "Data Catalog" in the left menu, find and click the
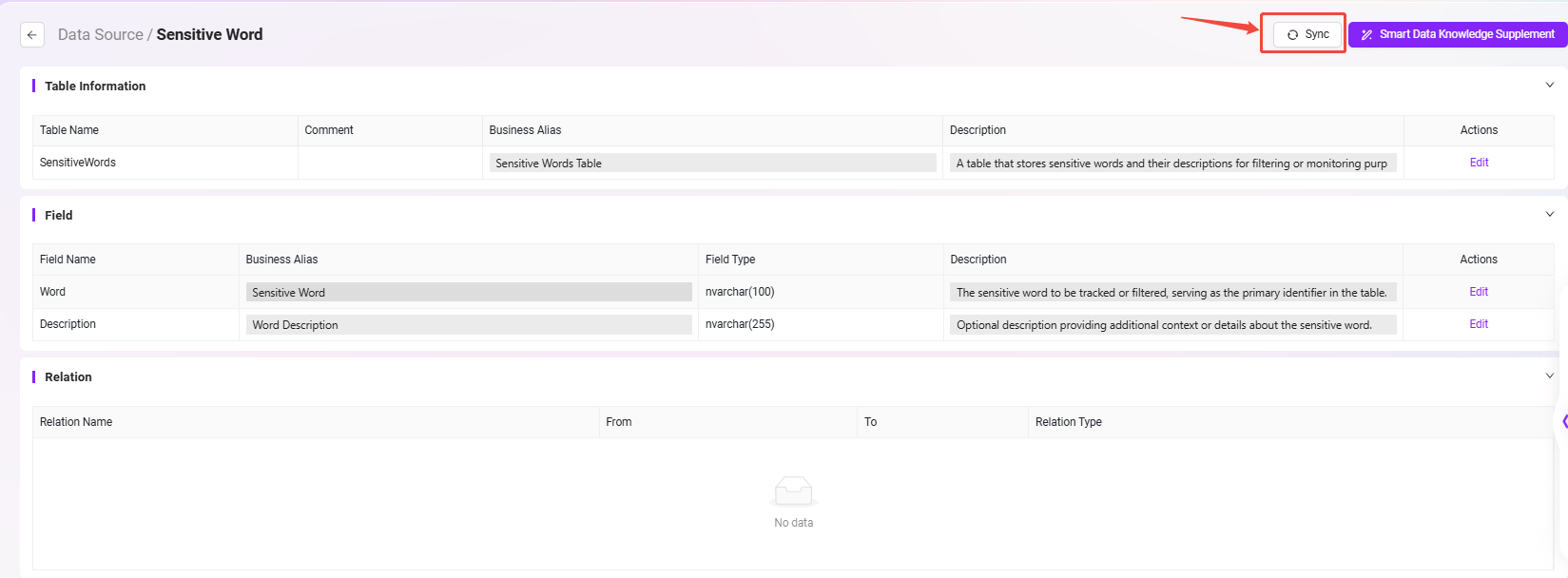
After completing the above steps, the sensitive word data source is configured. In the following workflow, you can access this data table through nodes to achieve sensitive word extraction and comparison for contract content.
Creating the “Sensitive Word Extraction” Agent via Workflow
- Go to the SERVICEME NEXT homepage, click the circular icon in the lower left corner to enter the Agent Q&A interface.
- Click "More Agents" in the left menu to enter the Agent Plaza.
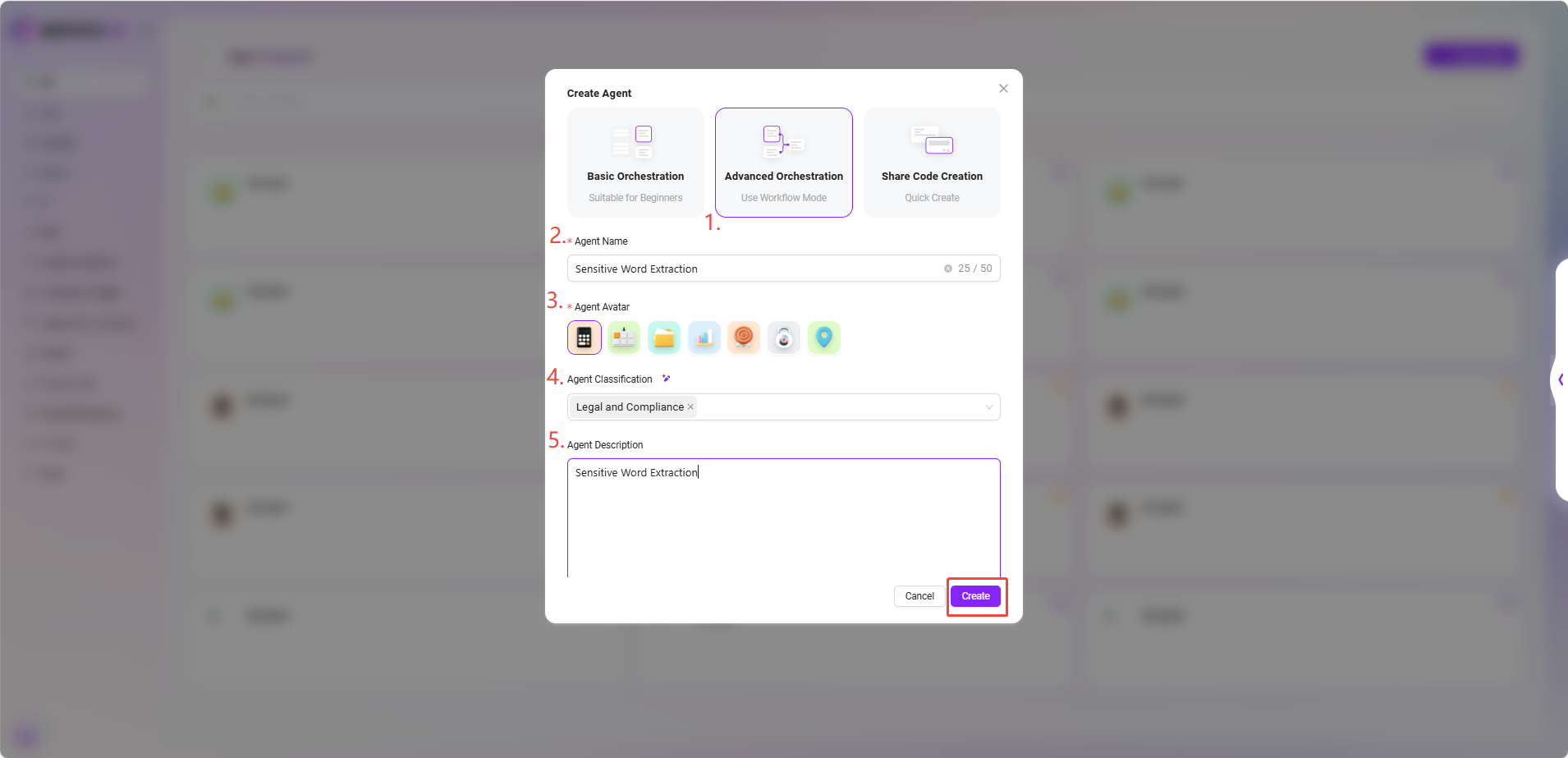
- In the upper right corner of the Agent Plaza, click "Create Agent" and select "Advanced Orchestration Creation".
- Fill in the following basic information:
- Agent Name: Enter
Sensitive Word Extraction - Agent Avatar: Select one from the built-in avatars (custom upload is not supported currently)
- Agent Classification: Select the appropriate business category, such as
Legal and Compliance - Description: For example,
Sensitive Word Extraction
- Agent Name: Enter
- After completing the information, click "Create" to successfully generate the basic Agent.
Configuring the “Sensitive Word Extraction” Agent
📌 Workflow Planning
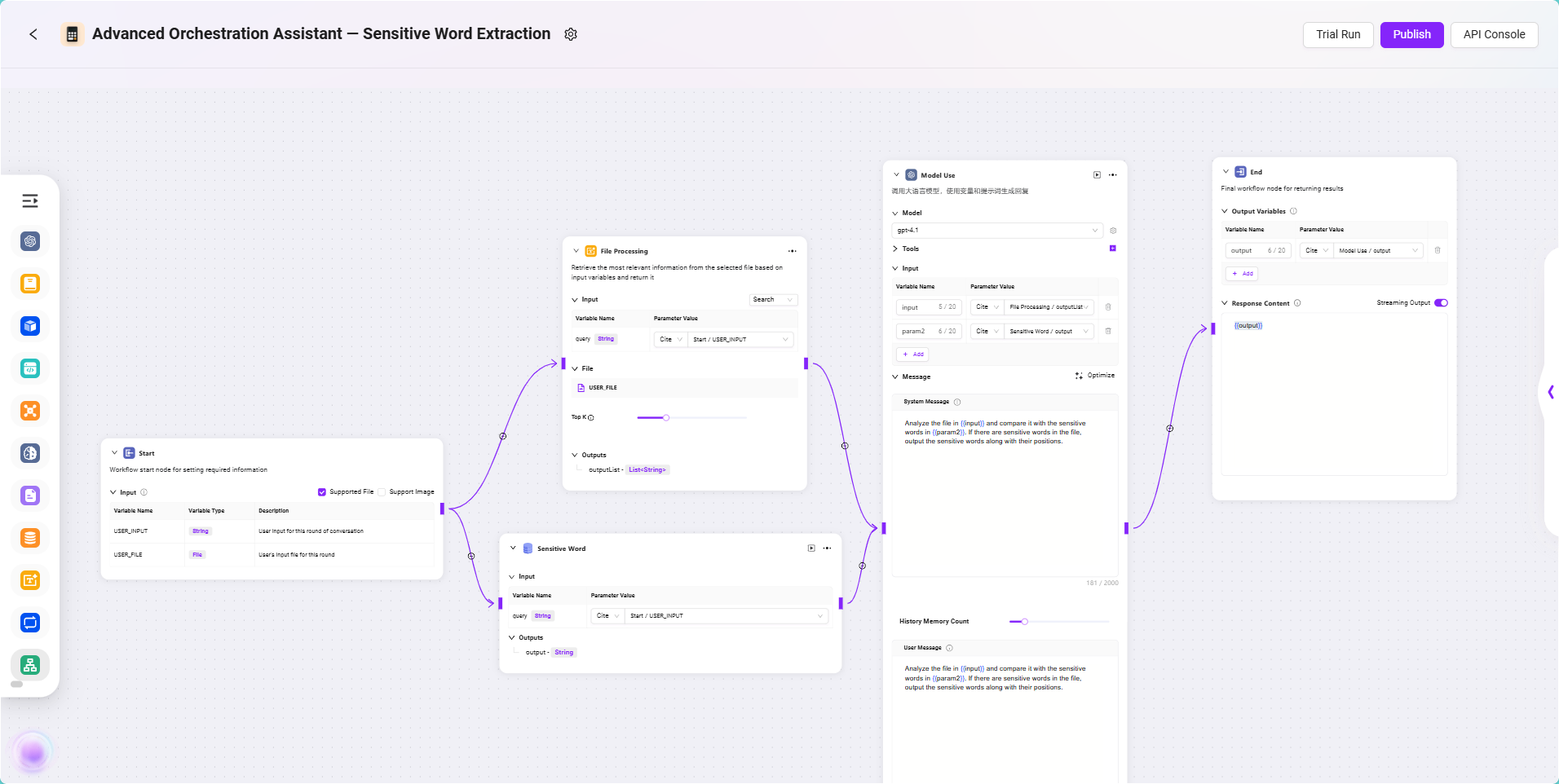
The core goal of this workflow is to enable the Agent to automatically identify sensitive words present in contract files uploaded by users. To achieve this, we need to guide users to upload contract files and parse their content into processable text; at the same time, load sensitive word data from the configured database, and use the model to intelligently compare the contract content with the sensitive words, identifying matches and their positions. Finally, the model outputs the recognition results and returns them to the user. The entire process covers key steps such as file processing, data source invocation, model recognition, and result output, suitable for automated text review business scenarios.
📌 Node Configuration and Connection Instructions
In this Workflow example, the input and output of each node are configured by referencing the results of the previous node. To achieve the goal of sensitive word extraction, the process mainly involves the following nodes: Start Node, File Processing Node, Data Source Node, Model Node, and End Node. The configuration and connection methods for each node are explained below.
Configuration Process
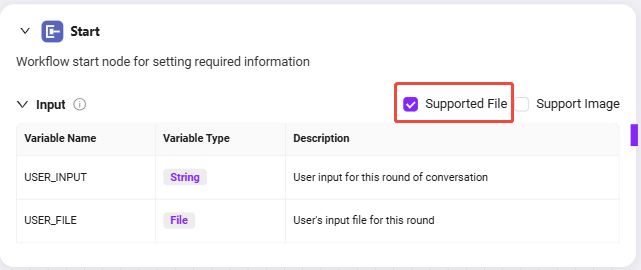
- Start Node Input Description
The Start Node includes two default inputs:
USER_INPUT: The user's natural language instruction, e.g., "Please help me check for sensitive words in the contract."USER_FILE: The contract file uploaded by the user.
These two inputs will serve as reference sources for subsequent nodes, for use in file processing and model recognition.
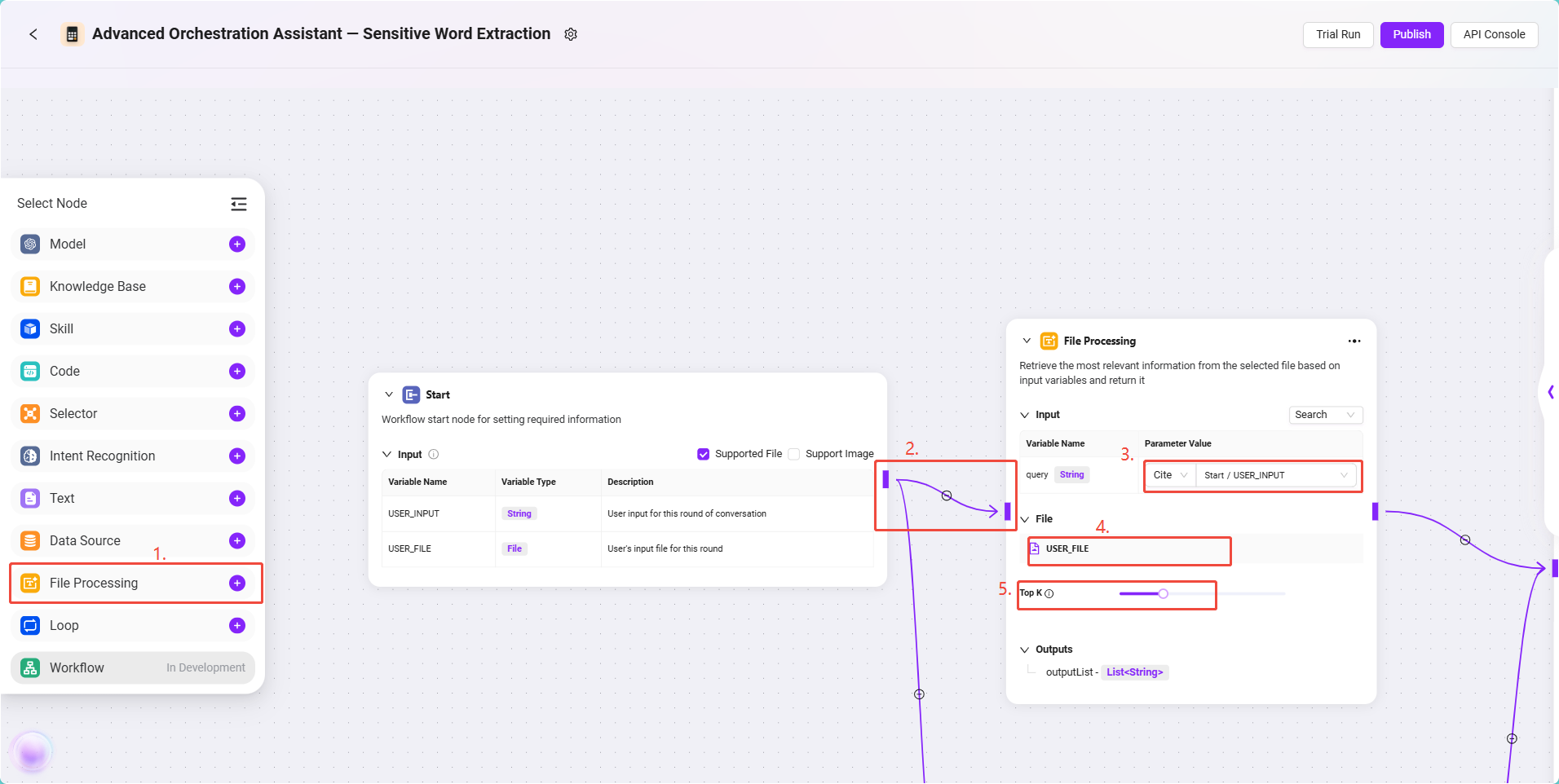
- File Processing Node Configuration
This node is responsible for processing the contract file uploaded by the user, including text extraction, slicing, and vectorization.
Configuration steps:
- Add a File Processing Node to the canvas.
- Connect the Start Node to the File Processing Node.
- Click the File Processing Node to enter the configuration interface and set the following:
- Input Reference: Set
USER_INPUTas the reference, format:
Start/USER_INPUT - File Reference: Click "Add File" and select
USER_FILE(i.e., the contract file uploaded by the user) - TopK Setting: Choose an appropriate TopK (e.g., 3~5).
- TopK indicates the maximum number of text segments returned by the model during text vector matching.
- Suggestion: If TopK is too low, key content may be missed; if too high, it may affect the model's focus.
- Input Reference: Set
- Data Source Node Configuration
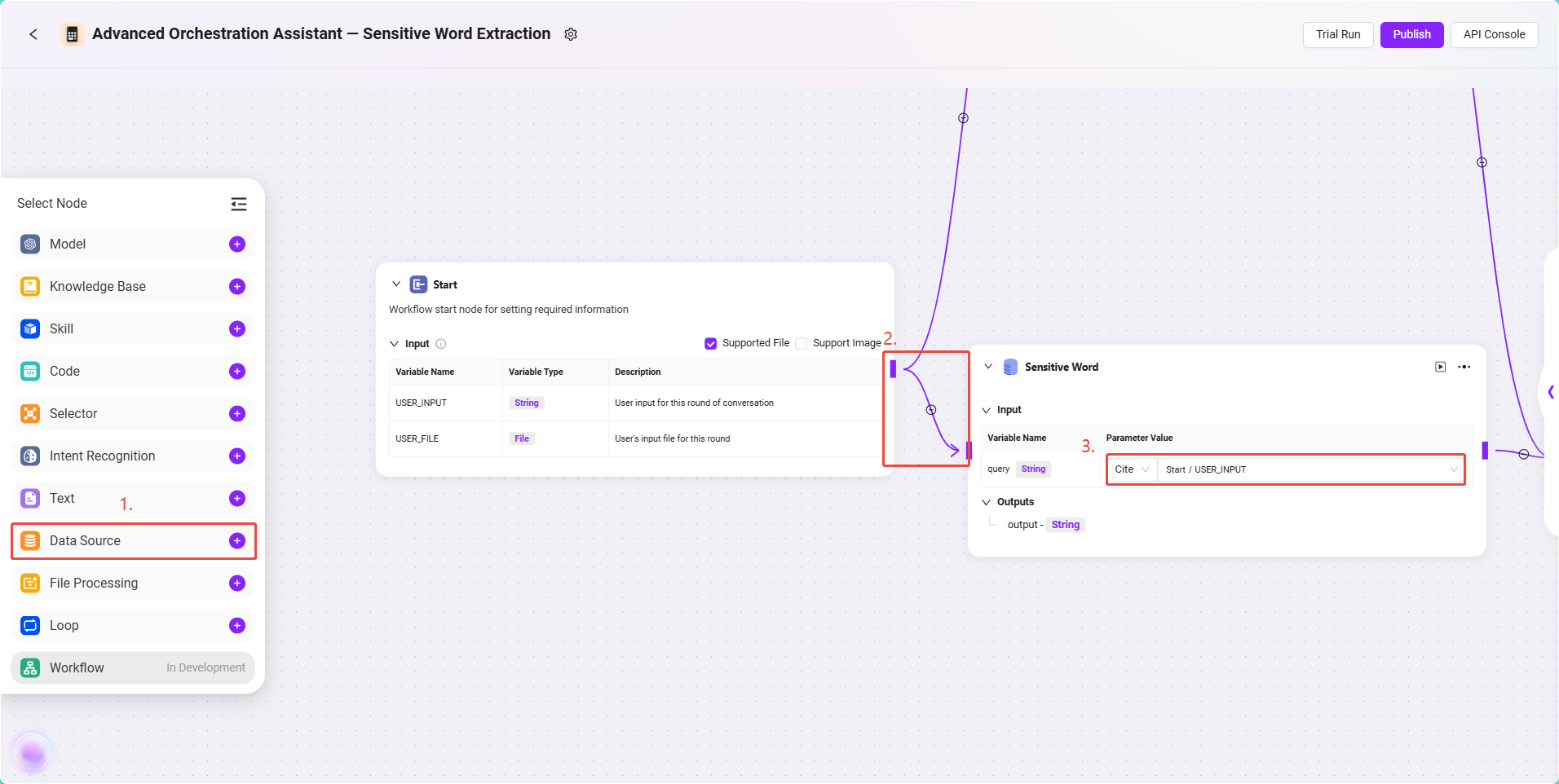
This node is used to introduce the sensitive word data table created earlier for subsequent comparison.
Configuration steps:
- Add a Data Source Node to the canvas and connect it to the Start Node.
- Click the node and configure the data source information:
- Select the data source:
Sensitive Word - Input reference configuration:
Start/USER_INPUT(user's input instruction)
- Select the data source:
The output of this node is the sensitive word list required by the model.
- Model Node Configuration
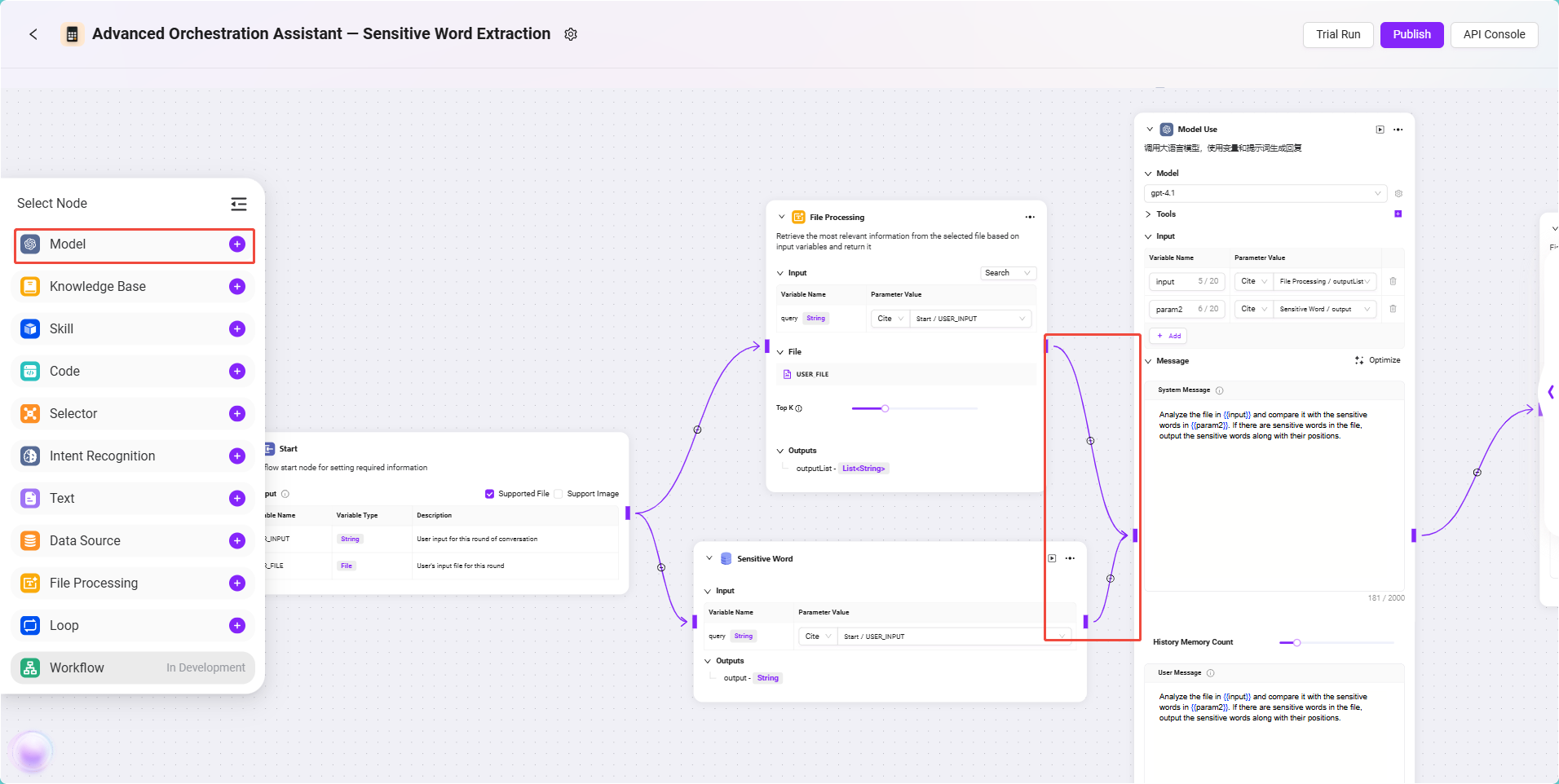
This node is the core processing module of this workflow, responsible for intelligently comparing the contract text with sensitive words and returning the results.
Configuration steps:
- Add a Model Node and connect it to both the File Processing Node and the Data Source Node.
- Model selection:
gpt-4.1 - Tool selection: No external tools are needed for this scenario, can be skipped.
- Input references:
input: Reference the output of the File Processing Node, format:
FileHandler/outputparam2: Reference the output of the Data Source Node, format:
DataSource/output
- Prompt configuration:
- System Prompt:
Analyze the file in {{input}} and compare it with the sensitive words in {{param2}}. If there are sensitive words in the file, output the sensitive words along with their positions. - User Prompt:
Analyze the file in {{input}} and compare it with the sensitive words in {{param2}}. If there are sensitive words in the file, output the sensitive words along with their positions.
- System Prompt:
✅ Tip: The system prompt is used to provide behavioral instructions to the model, and the user prompt simulates the actual user input. The content is the same here for more stable results.
- Output Node Configuration
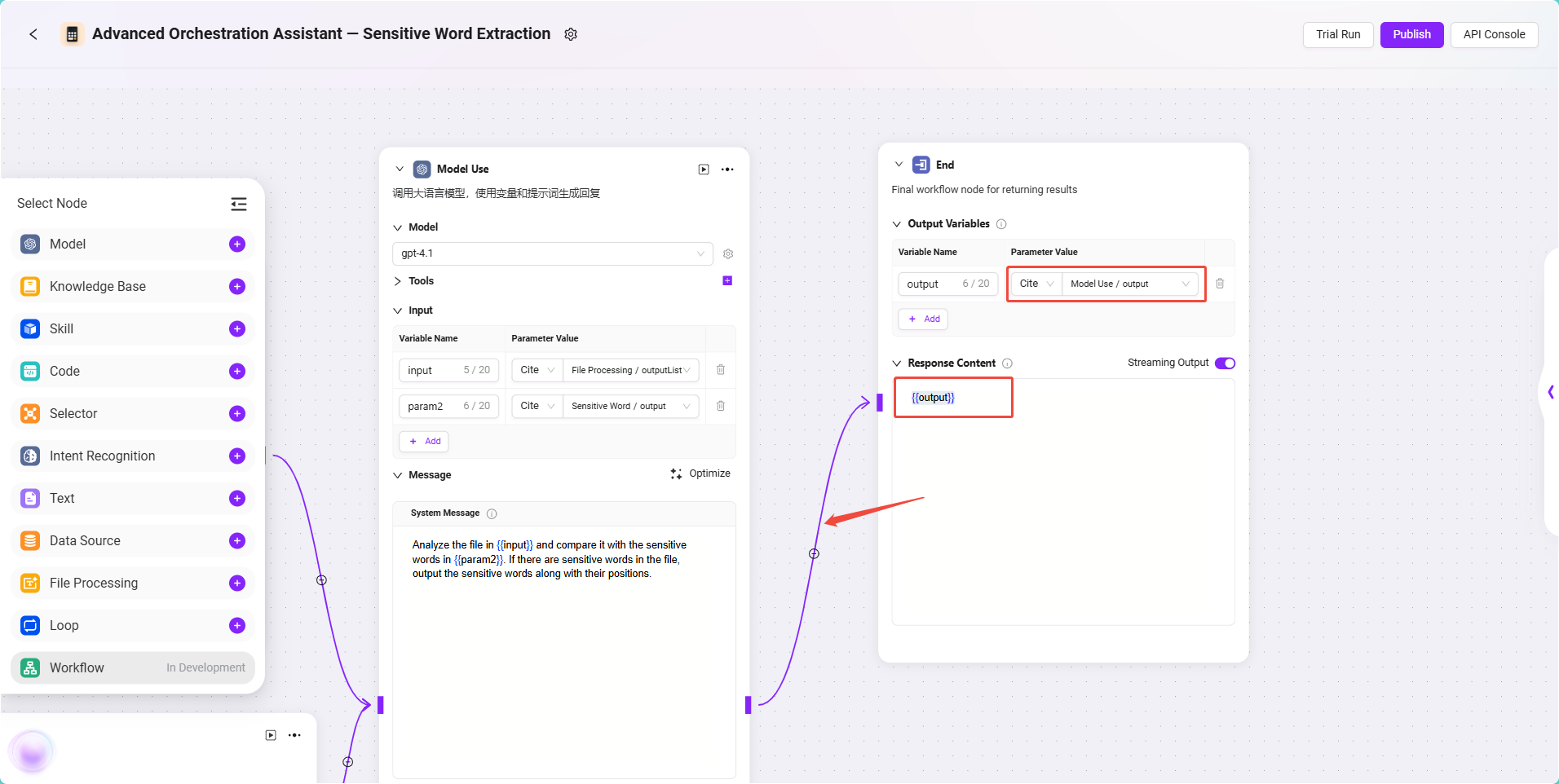
This node is used to return the model's processing results to the end user.
Configuration steps:
- Connect the Model Node to the End Node.
- Click the End Node and set the input reference:
- Input content: Reference the model node output, format:
Model/output
- Input content: Reference the model node output, format:
- Fill in the output content configuration:
{{output}}
✅ Tip: Only filling in
{{output}}as the output at the end can better preserve the model's output. If needed, you can also specify the output of specific content.
The complete configuration is as follows: