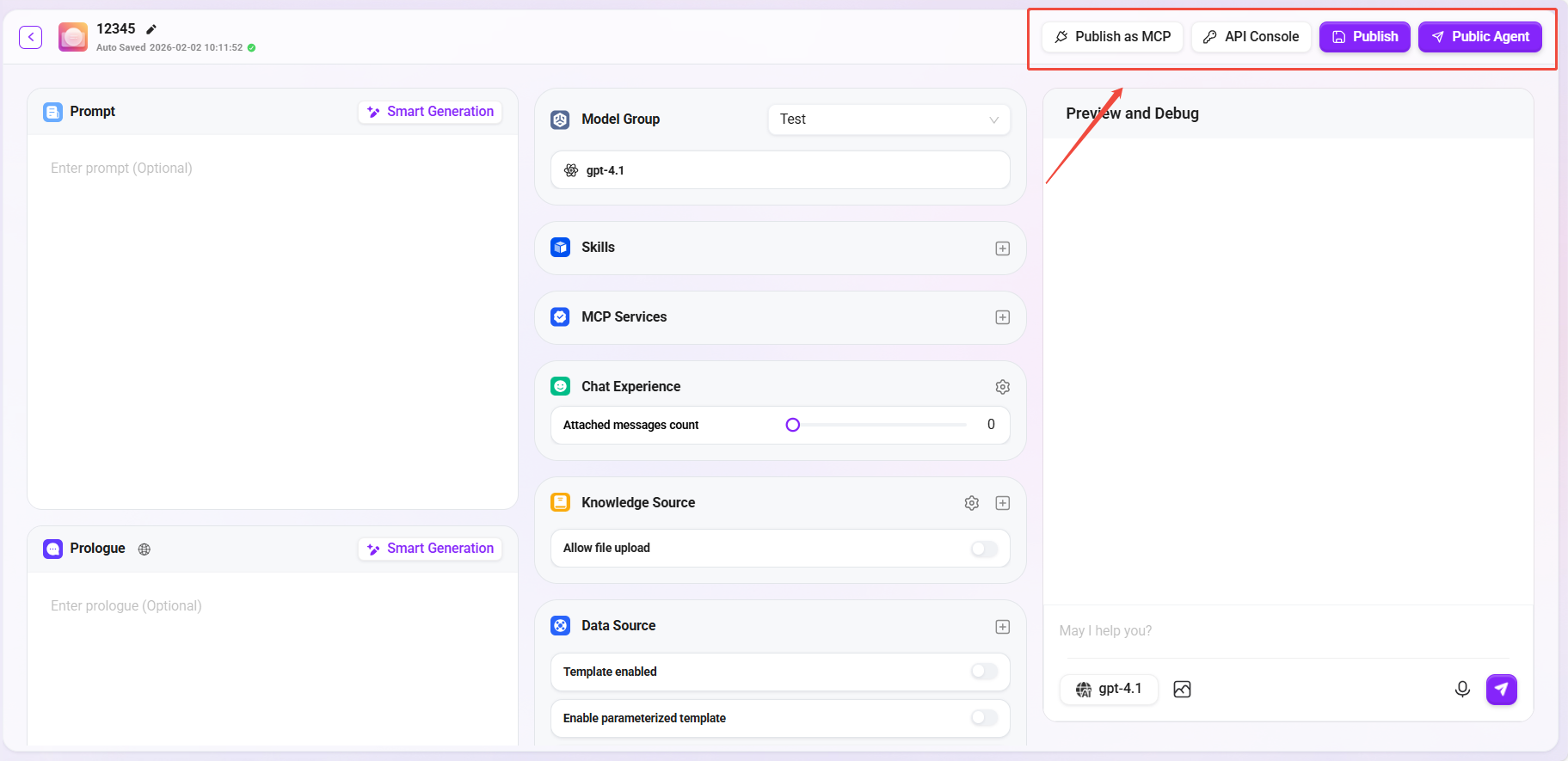
基础创建Agent
选择助手类型
在AI Studio页面的右上角,点击“创建”创建基础智能体;
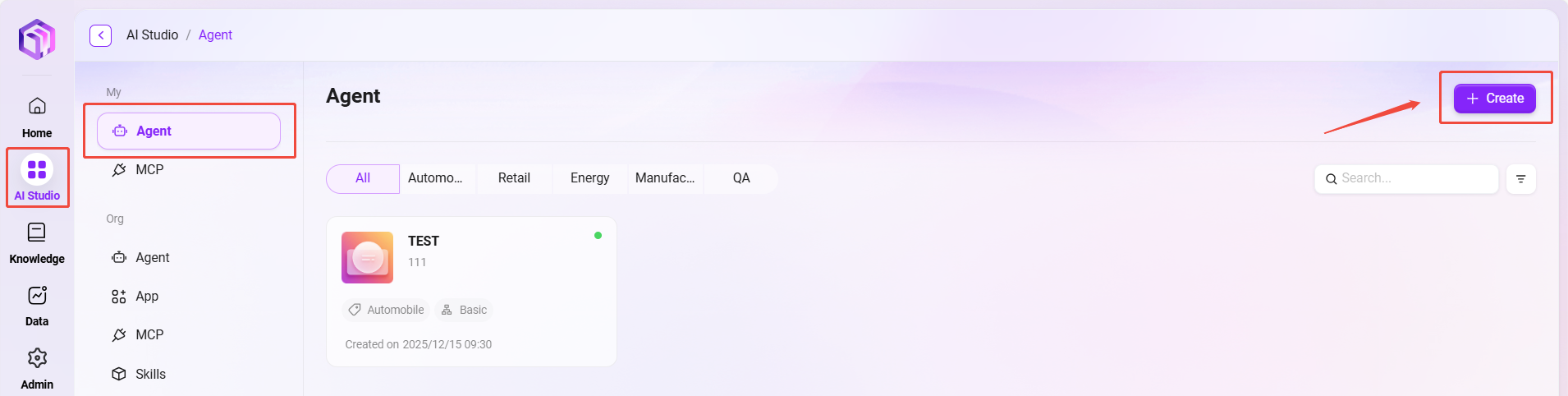
创建步骤
在创建弹窗中,填写以下基础信息:
① 助手名称:输入助手的名称,作为助手标识(50字以内)。
② 助手头像:从系统默认头像中选择一个(暂不支持上传自定义头像)。
③ 模型组:为助手配置合适的模型组。
④ 助手分类:选择新建助手所在的组(最多选择5个)。
⑤ 助手描述:输入简要描述,说明助手的功能和用途(200字以内)。
- 点击“创建”,助手创建后进入基础编排助手配置页面,配置并发布后可投入使用。
💡 提示:系统界面支持语言:中文简体、中文繁体、日语、英语。
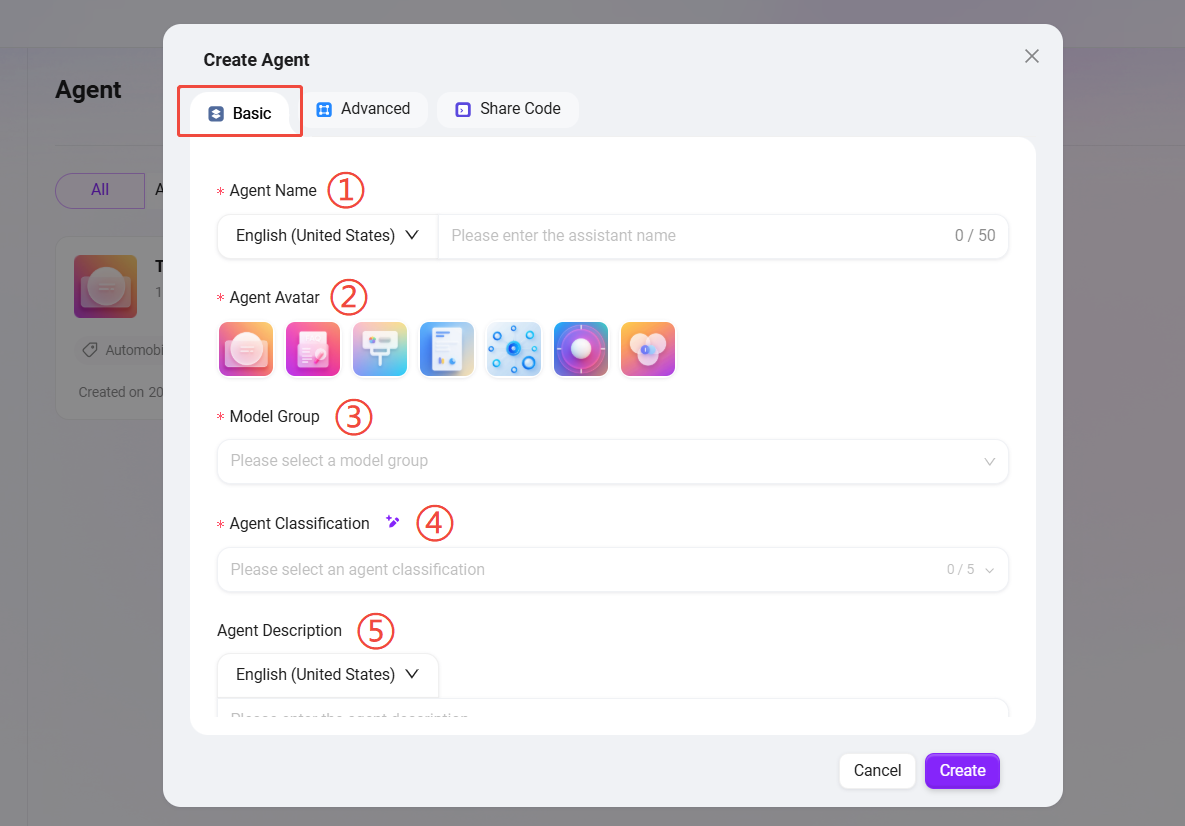
助手配置
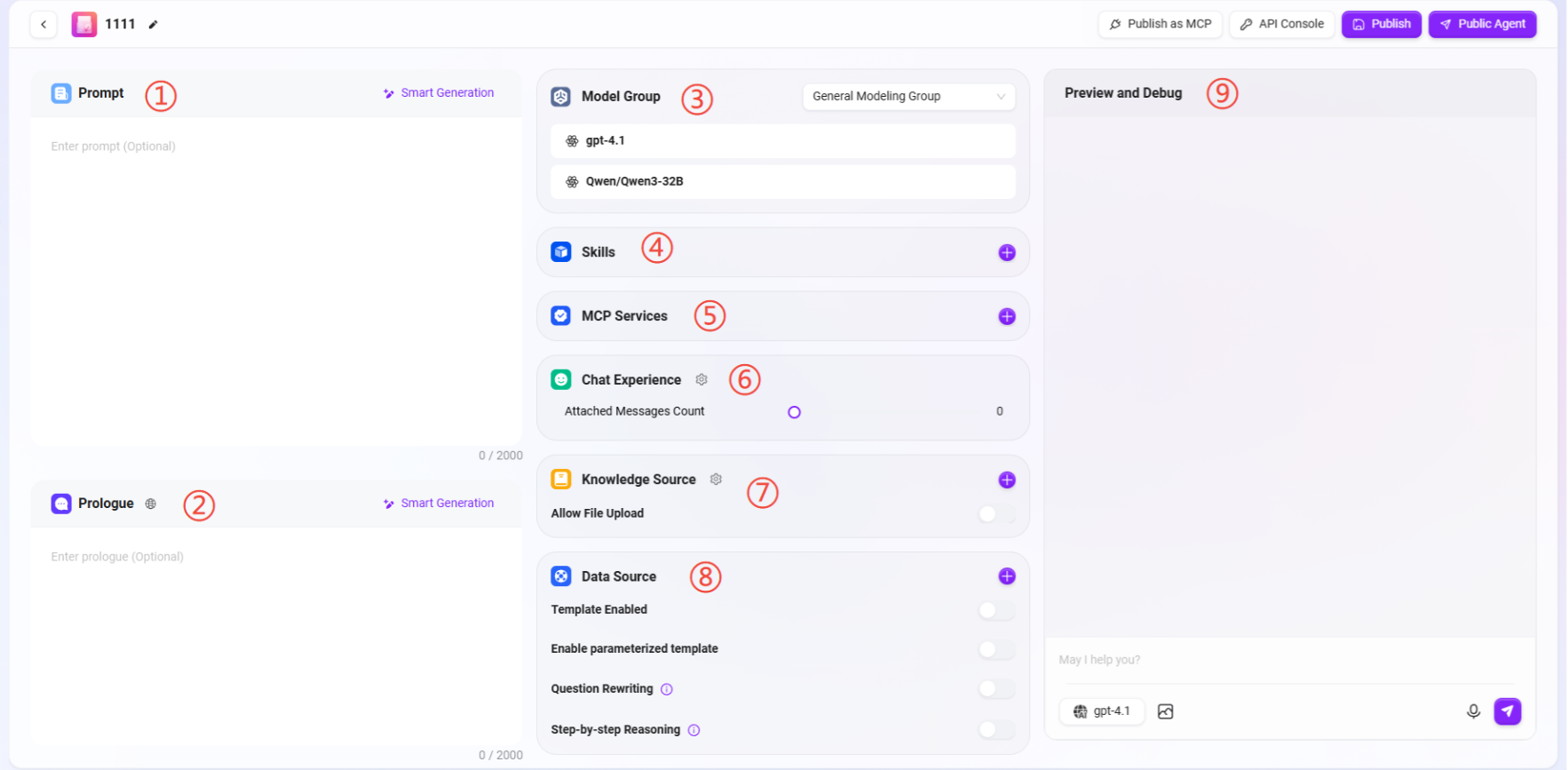
进入配置页面
可以通过以下两种方式进入智能体的详细配置页面:
- 方式一:在 AI Studio 中创建新助手后,系统将自动进入其配置页面。
- 方式二:在智能体列表,将鼠标悬停在目标助手卡片上,点击出现的“✏️”图标,即可进入配置页面。
核心配置项说明
配置页面包含以下核心模块:
① 提示词:输入助手提示词,也支持将现有提示词进行智能生成。
② 开场白:输入助手开场白,也支持根据提示词或已有开场白进行智能生成。
备注:提示词与开场白的输入超过约2000字时,系统会提示“输入内容过多,可能影响效果”,但不会阻止继续输入。建议保持内容精炼以确保最佳性能。
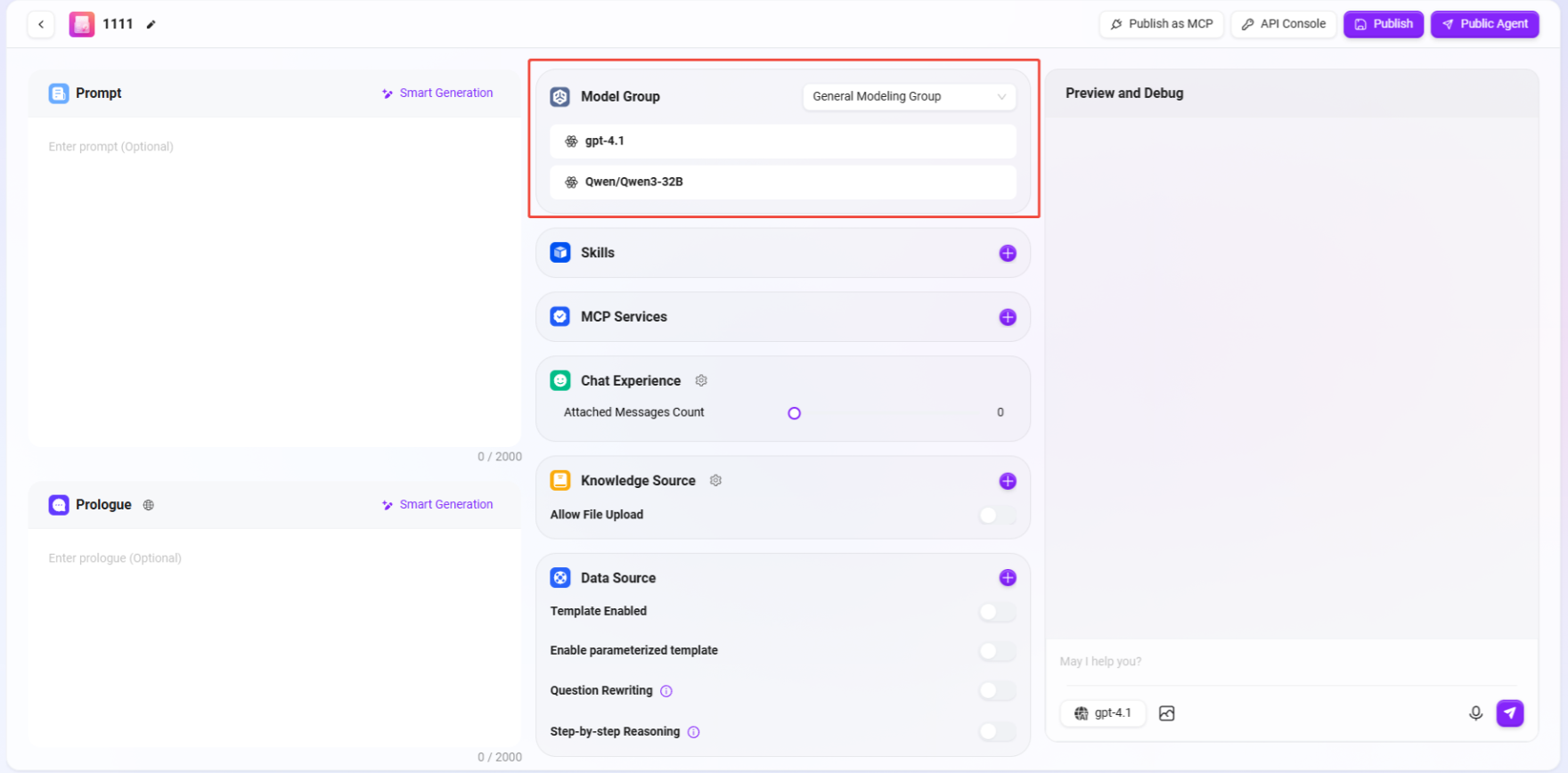
③ 模型组:点击“+”添加模型组,支持多种可选模型。
- 功能:点击 “+” 为助手添加或切换已配置的模型组。一个模型组可包含多个不同的AI模型。
- 管理说明:模型组需由管理员在 “管理 > 模型管理 > 模型组” 中先行创建与配置,将多个模型添加至同一个模型组中,方可在此处分配给助手使用。
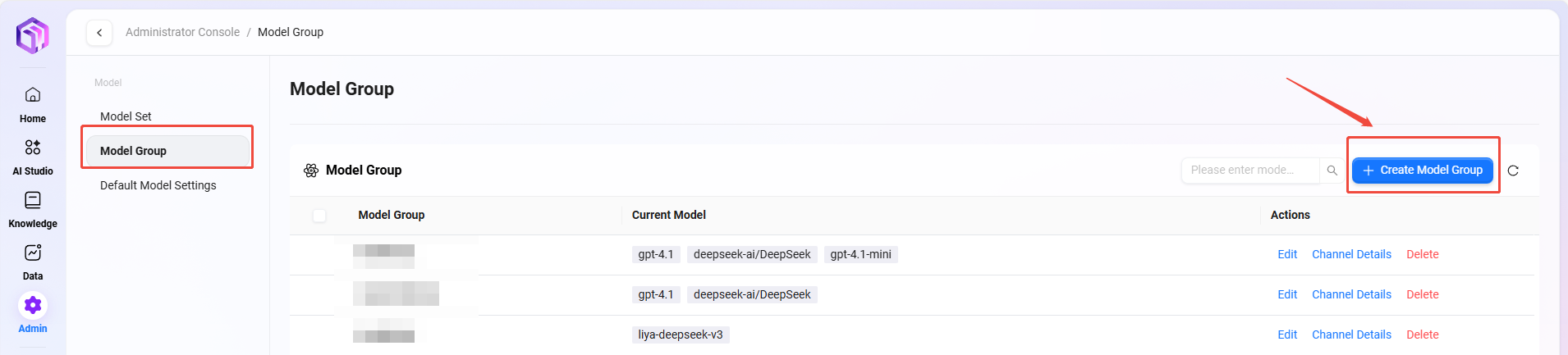
管理员添加模型组步骤:
- 进入路径:管理 → 模型管理 → 模型组。
- 点击 “新建模型组”。
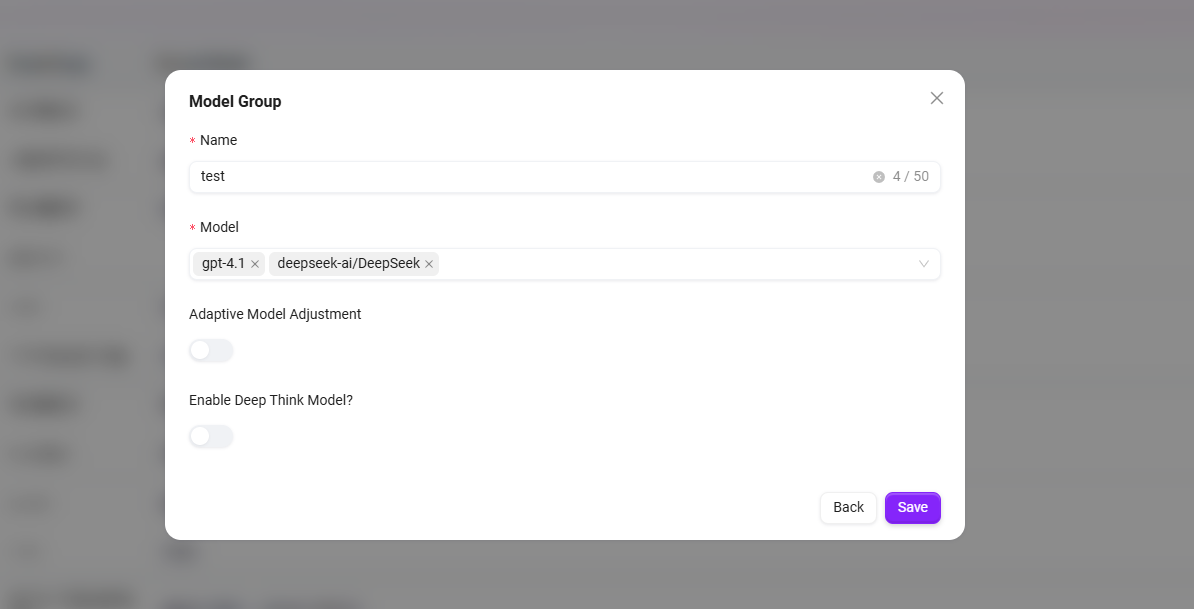
- 完成以下配置:
- 输入模型组名称。
- 勾选需要加入该组的模型(可多选)。
- 选择是否开启 “自适应模型部署”,能根据流量自动调整计算资源,确保服务稳定流畅。
- 选择是否启用 “深度思考模型”,在遇到复杂问题时智能调用更强大的AI,显著提升回答质量。
- 点击 “保存”。
④ 技能
点击“+”添加一种或多种技能,也可以添加推荐技能(最多可添加20个技能)
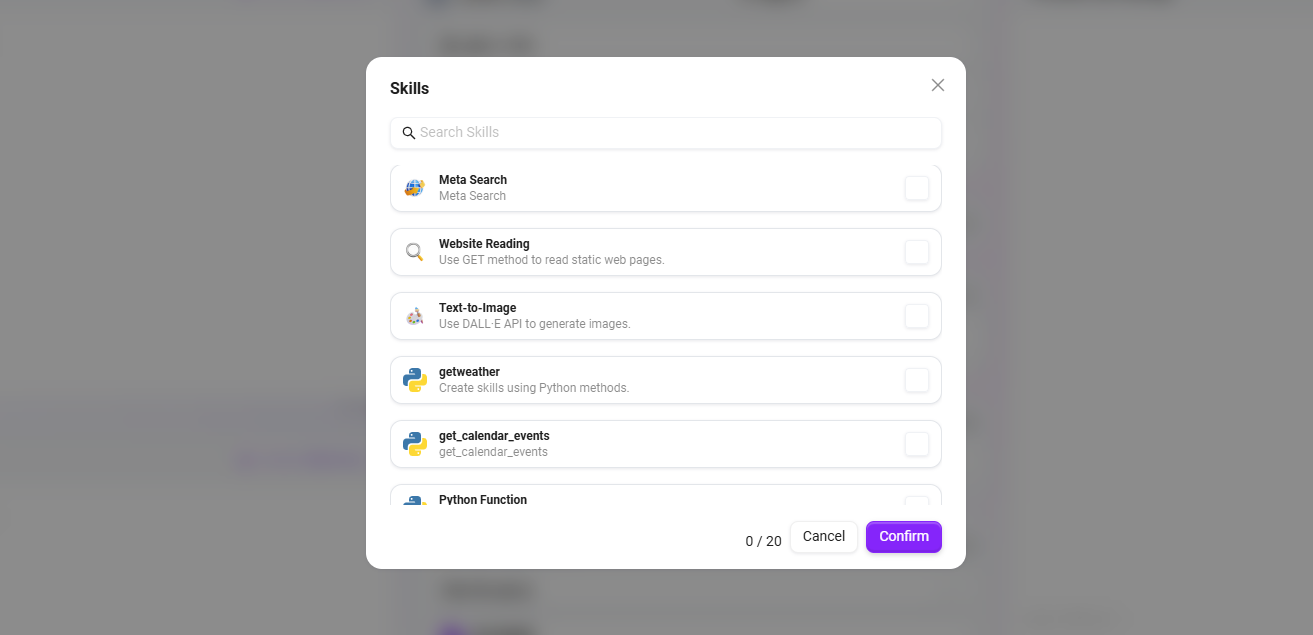
系统提供 7 项默认技能:Google搜索、腾讯搜索、G-Bing搜索、秘塔搜索、文生图、新闻查询工具、网页读取。
- Google搜索:通过Google搜索引擎获取实时、准确的网络信息,支持全球范围内的网页内容检索。
- 腾讯搜索:基于腾讯搜索技术,提供针对中文互联网环境的搜索服务,特别优化了对中文内容的检索效果。
- G-Bing搜索:提供综合性的网络搜索能力,平衡检索的广泛性与结果的精准度。
- 秘塔搜索:提供高效、精准的搜索服务,能快速定位并返回用户所需的关键信息。
- 文生图:基于文本描述自动生成对应的图像内容,将文字创意转化为视觉呈现。
- 新闻查询工具:用于搜索、获取各类新闻资讯的专用工具。
- 网页读取:提取网页文本、数据等内容,解析网页信息的功能。
备注:支持追加其他技能,需由管理员在后台进行操作与配置。
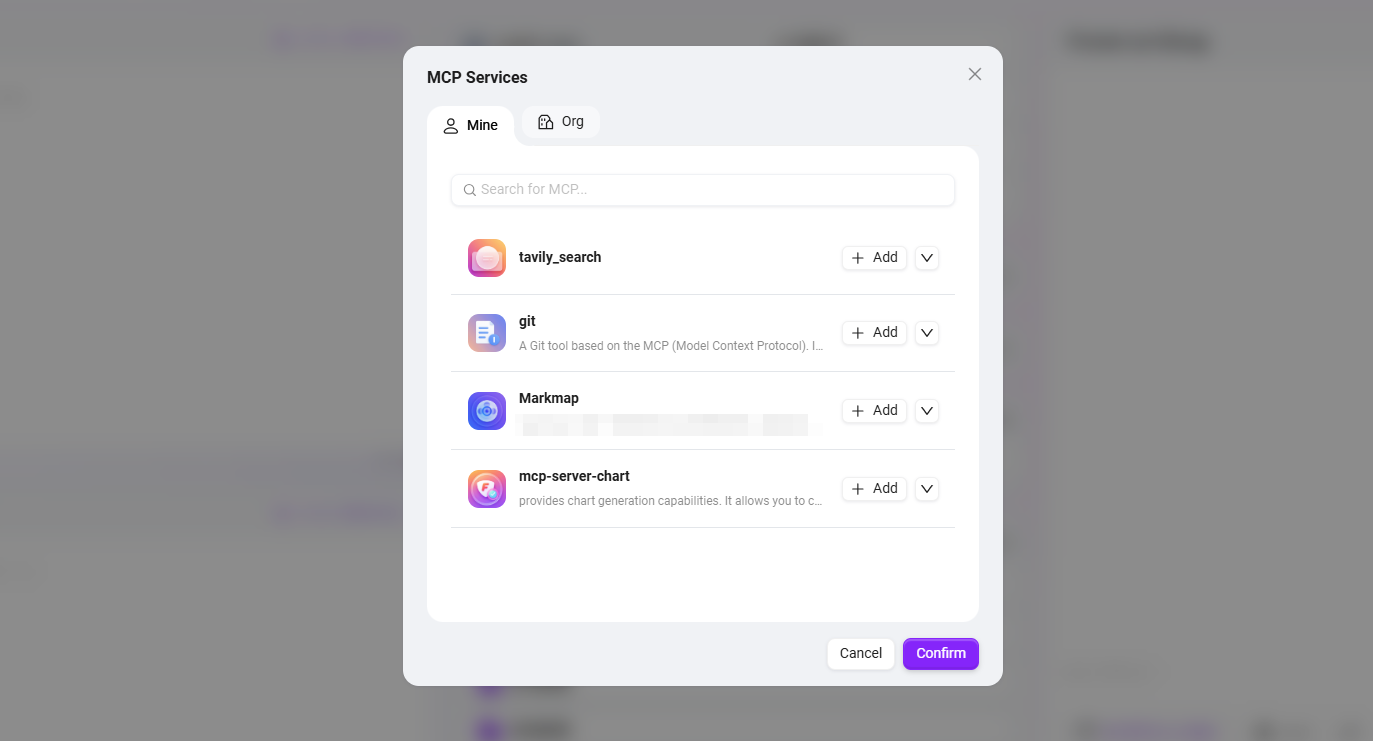
⑤ MCP服务
MCP服务管理系统内AI助手与外部工具、数据源的连接权限。
- 作用:
- 能力扩展:赋予助手搜索、计算、可视化等外部能力。
- 生态集成:持续集成各类工具与服务,满足多元化需求。
- 内部集成:通过个人MCP集成内部系统资源。
- 配置建议:当配置的MCP工具数量达到或超过5个时,系统会发出提示。过多的工具可能导致提示词过长,超出模型上下文限制,影响性能。
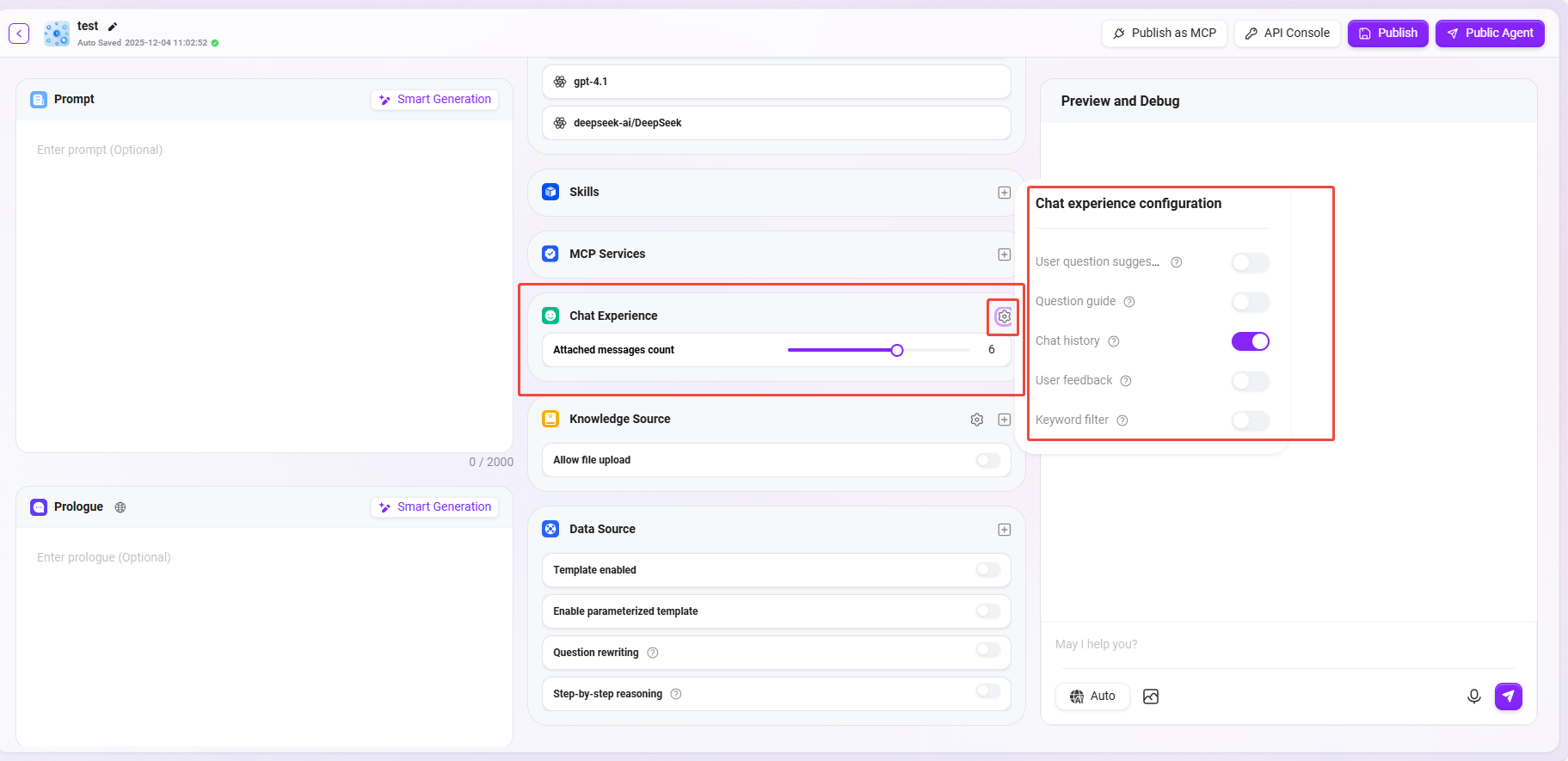
⑥ 对话体验
-
上下记忆条数: 设置助手可记忆的历史对话轮数 1-10条,建议设置为5条以平衡对话连贯性与性能。
-
对话设置:可以开启“用户问题建议、问题引导、聊天记录、对话反馈、关键词审查”等设置。
- 用户问题建议:在助手回答后,根据前文为用户提供一些问题建议。
- 问题引导:在用户与助手对话时,会有相关的问题引导,利用模型能力推测用户可能提问的问题以及对用户问题的补全。
- 聊天记录:是否留存助手的聊天记录,关闭后,将无法查到助手的聊天记录。
- 对话反馈:对助手的回答可以进行点赞、点踩等交互操作,用于优化助手回答。
- 开启关键词审查:审查输入内容和审查输出内容至少启用一项。开通后将对提示词或 AI 反馈结果都进行敏感词检测,敏感词可提前进行维护。
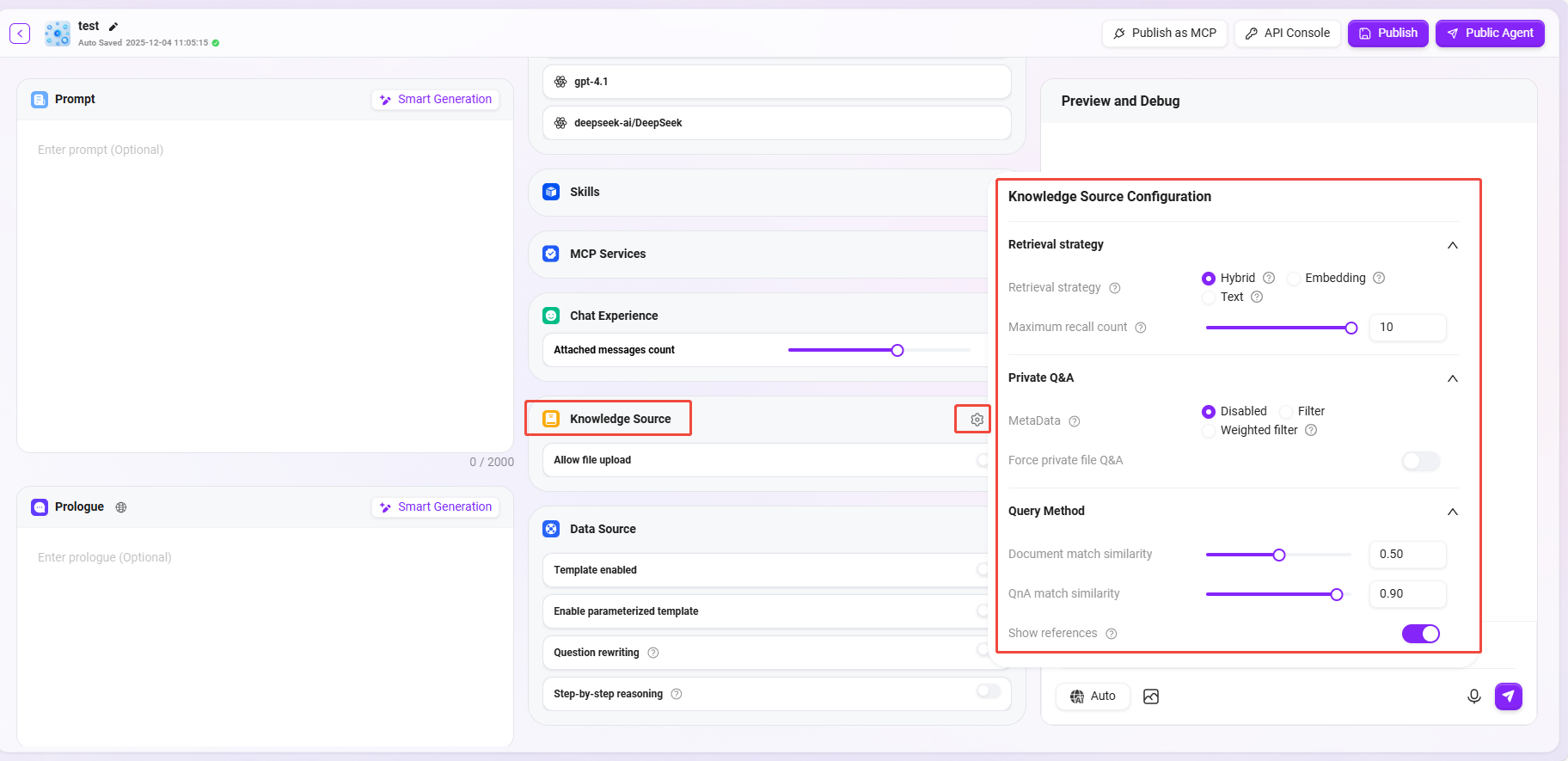
⑦ 知识库
-
知识库:点击“+”添加知识库(最多可添加5个知识库作为知识来源)。
-
是否允许文件上传:
- 打开允许文件上传后,无法再添加知识库的内容作为知识来源。
- 关闭允许文件上传后,可以选择性添加个人空间或企业空间的知识库作为知识来源。
-
知识库配置:可以修改知识库的“检索策略、私域问答、检索方式”等详细设置。
1)检索策略:混合搜索、嵌入搜索、文本搜索。
- 混合检索:综合向量检索和全文检索的查询结果,返回重排后的结果。
- 嵌入检索:通过相似性进行片段查找,有一定的跨语言泛化能力。
- 文本检索:通过关键字进行片段查找,适用于含有特定关键字、名词片段的检索。
2)最大召回数量:范围 1–10,不建议设置过高或过低,建议值为 3–5。
3)元数据过滤:无、过滤、权重。
4)强制私域文件问答:打开后不会使用联网搜索等技能,助手的回答只针对知识库内容。
5)文档匹配近似度:范围 0–1,匹配近似度越高,说明召回文档内容越相似,建议值约为 0.8(即 80%)。
6)QnA 匹配近似度:范围 0–1,类似于文档内容的近似度匹配,建议值约为 0.9(即 90%)。
7)显示参考文献:打开后,助手在回答时会列出所参考的文献,提高回答可信度。
💡 提示:不论是最大召回数量、文档匹配近似度,还是 QnA 匹配近似度,都不是越高越好或越低越好,建议根据实际需求进行设置。如无特殊需求,建议保持默认值。
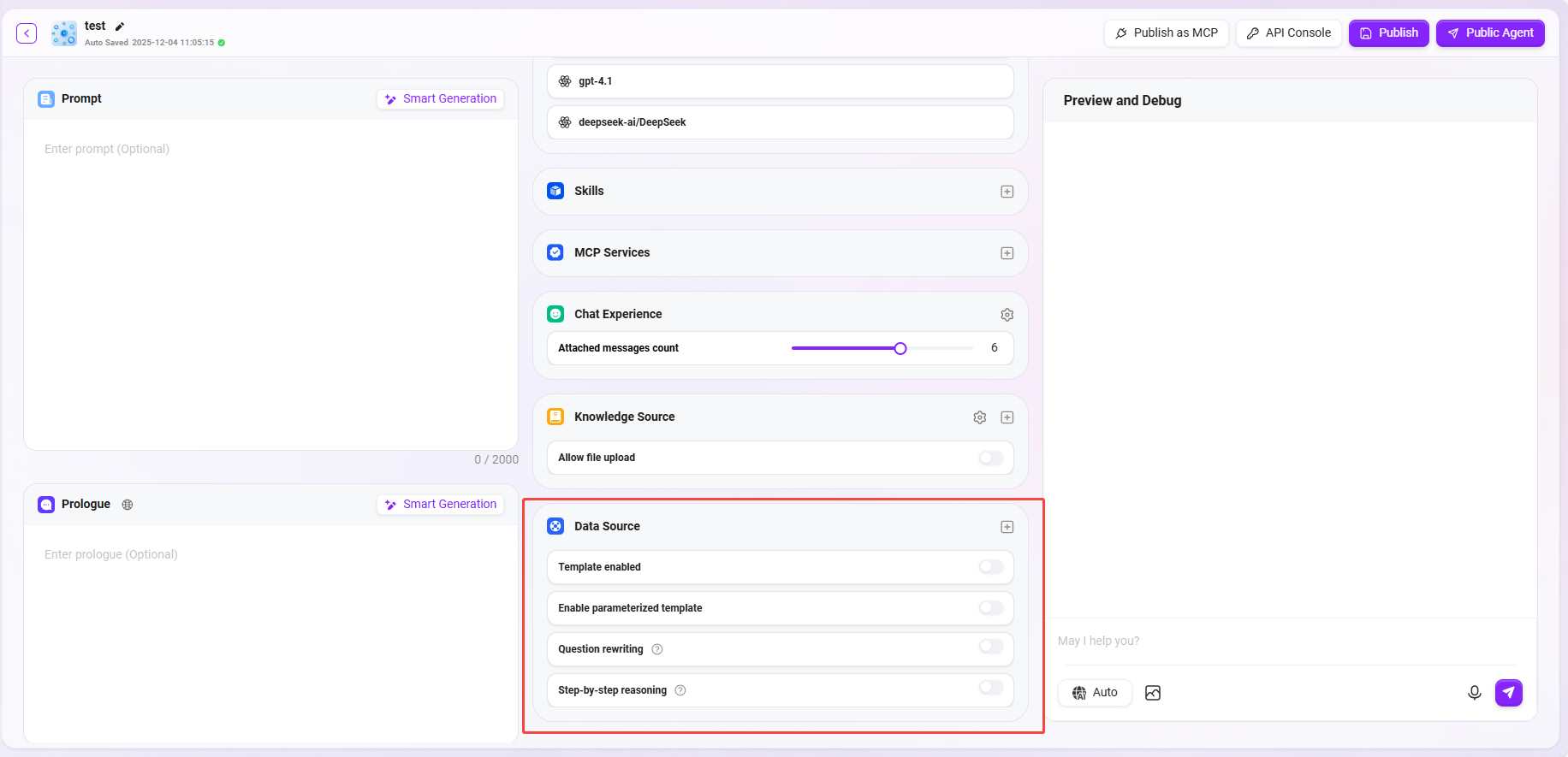
⑧ 数据来源
-
数据来源:点击“+”添加数据源,作为助手问答数据来源(最多可添加5个数据来源)。
-
是否启用模板:是否启用自然语言与SQL之间的预设映射模板。
- 当用户输入一个自然语言问题(比如:“
上个月销售额是多少?”),系统会先尝试 匹配一个预设好的模板。 - 如果找到匹配的模板(比如“
查询某个时间段的销售额”这种通用问题),就会使用模板中已有的 SQL 结构 作为参考,再结合具体的字段/表名等来生成最终的SQL语句。
- 当用户输入一个自然语言问题(比如:“
-
是否启用参数化模板:开启后,在模板基础上启用参数化查询,增强查询的灵活性和安全性。
-
问题改写:开启后,将自动对用户输入的问题进行优化,以确保准确地数据查询。
- 用户原始提问:
查一下销售额(信息不完整)。 - 问题改写后:
查询2024年7月份所有产品的总销售额(补充了时间和范围)。
- 用户原始提问:
-
分步思考:开启此功能后,在生成最终查询结果之前,系统会输出详细的思考步骤,解释它是如何分析问题并构造SQL查询语句。
- 步骤 1:识别关键词“
2024年7月”“销售额”。 - 步骤 2:确定数据表
Orders,字段order_date和sales_amount。 - 步骤 3:构造日期范围条件
2024-07-01到2024-07-31。 - 步骤 4:生成SQL。
- 步骤 1:识别关键词“
-
二次确认:开启后,由模型对生成的SQL进行准确性检验,暂不适配claude系模型。
⑨ 预览与调试
- 功能:在发布前,在此可对智能体进行对话测试。
- 操作:用户可以直接在预览对话窗中输入问题,与配置中的智能体进行实时交互,验证其提示词、知识库、技能等配置是否符合预期。
- 目的:确保智能体行为准确无误,再进行发布,避免配置错误影响用户体验。
发布与使用
配置完成后可选择发布完成智能体的创建。选择公开至Agent,是指发布至组织智能体。还可以选择发布至MCP,作为MCP可接入另外一个Agent。API控制台可查看已有的API渠道名称和API Key 数量,还可以新增渠道
完成所有配置并通过预览调试后,即可发布智能体:
- 发布为MCP:可将智能体作为MCP服务发布,以便被其他智能体接入和调用。
- API控制台:在“API控制台”可以查看已有的API渠道名称和API Key数量,并可进行新增渠道等管理操作。
- 发布:配置、预览无误后,点击发布保存配置,智能体即可正式投入使用。
- 公开Agent:可将智能体发布至组织智能体库,供团队成员使用。