工作流创建Agent
选择智能体类型
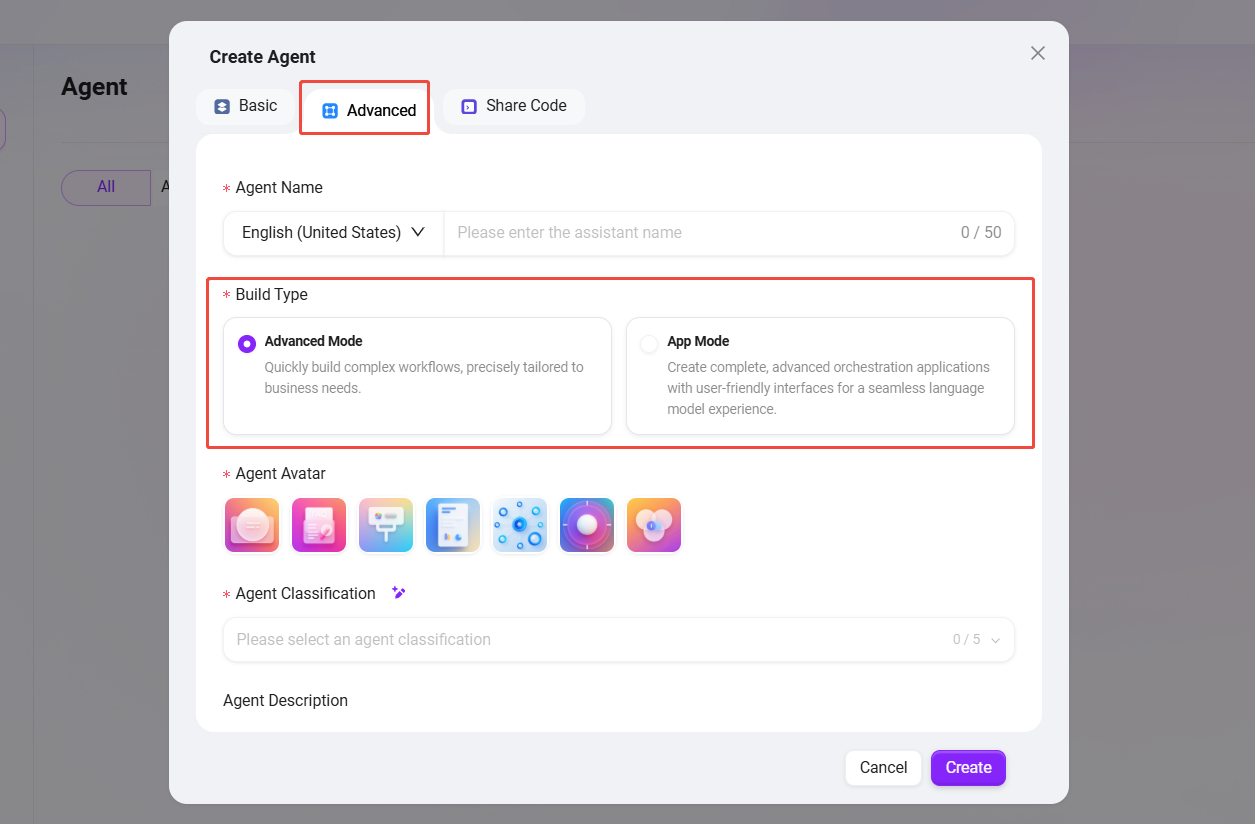
在创建智能体时,选择 “高级智能体”(初始创建步骤与普通智能体相同)。
- 构建类型:提供两种核心模式以满足不同复杂度的业务需求。
- 进阶模式:快速构建基于对话的复杂工作流程。
- 应用模式:创建具有定制化用户界面和结构化输入流程的完整编排应用程序,提供更优的用户体验。
进阶模式
在基础智能体之上增强的问答型智能体,核心能力集中于多轮对话与知识问答。
特点:
- 以自然语言对话为主要交互方式。
- 创建完成后,会显示在 智能体列表 中。
- 适合需要灵活、开放式对话交互的业务场景。
典型场景:
- 企业内部知识问答助手
- 产品FAQ与技术支持助理
- 工单处理咨询助手
应用模式
用构建一个带UI的Agent编排应用,具有特定输入结构、用于完成特定任务,不以自由对话为主,而是专注于执行既定任务流程的智能体。
特点:
- 创建后展示在 APP 页面 中。
- 具有固定、可定制的输入界面(如上传文件、填写表单字段)。
- 重点是执行某个自动化或半自动化的任务流程。
- 支持复杂的输入类型,如文件、结构化数据(Structured Data),适用于需要严格输入输出格式的业务场景。
典型场景:
- 合同审查 App(上传合同 → 自动标记风险)
- 文档分析 App(上传文档 → 自动生成关键内容)
- 数据清洗 App(上传 Excel → 自动处理数据)
配置工作流
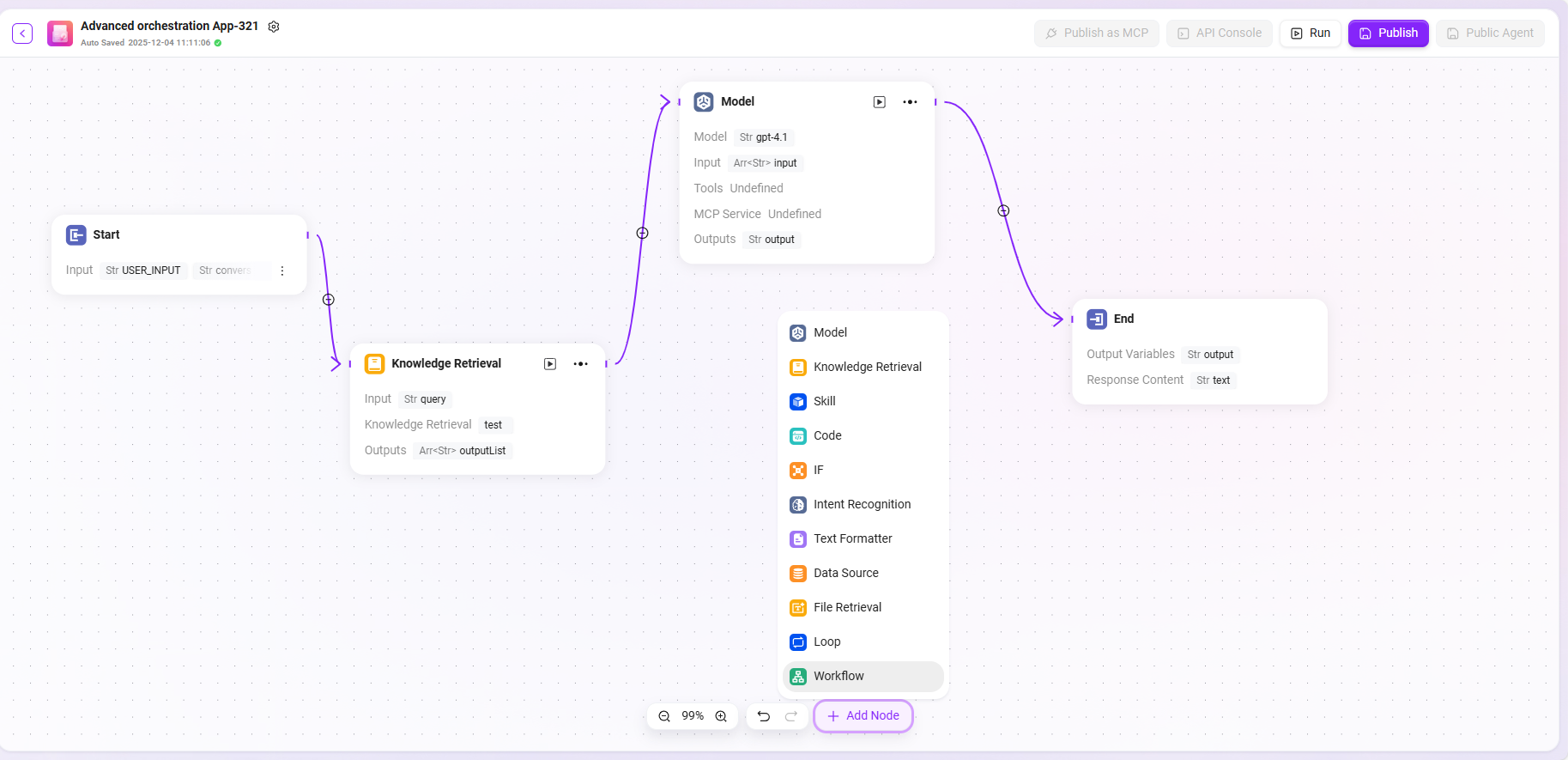
根据用户的实际业务逻辑,通过拖拽和连接以下节点来配置工作流:
- 开始、结束:自带的输入输出模块,可自定义输入输出参数与字段;
- 模型:可在此模块中选择使用的模型,输入其他模块获取的变量,并编辑提示词以及输出的消息,以变量形式保存;
- 知识库检索:在选定的知识库中,根据输入变量召回最匹配的信息,加以返回;
- 技能:选择其中一个技能,进行经过该技能的输入输出动作;
- 代码:根据其他模块中的输出变量,进行代码函数的自定义编写与创建;
- 选择器:根据设定条件判断流程分支走向,实现逻辑判断;
- 意图识别:用于用户输入的意图识别,并将其与预设意图选项进行匹配;
- 文本格式器:用于处理多个字符型变量的格式;
- 数据来源:选择数据来源以增加可引用的变量内容;
- 文件检索:在上传的文件中搜索,根据输入的问题查找相关答案;
- 循环:对列表中的每一项重复执行一组任务,并可选择并行处理。
节点详细介绍
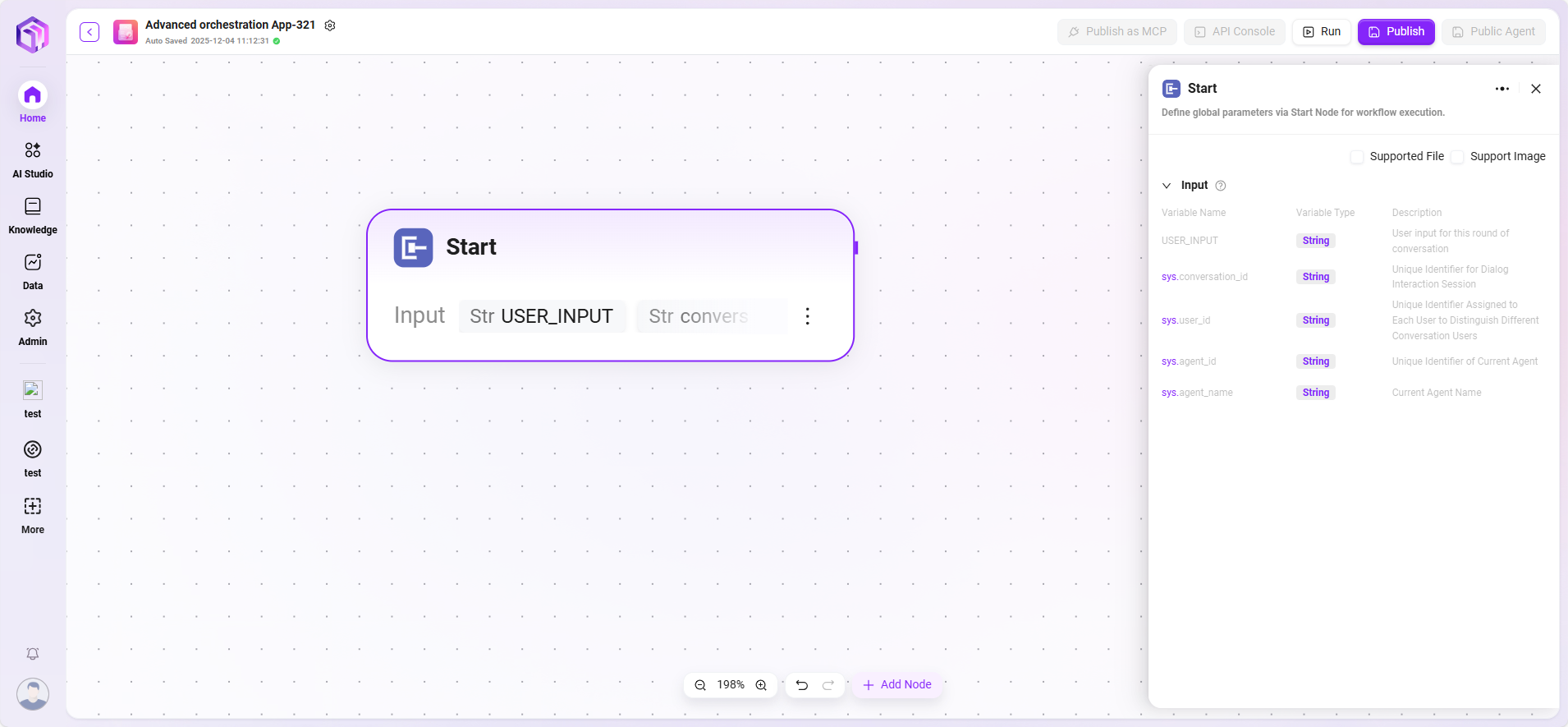
开始
开始节点是工作流的起始节点,用于设定启动工作流需要的信息。
- 功能:预设完成任务所需的基本信息(输入参数)。当满足触发条件时,系统自动收集并传递这些参数以启动流程。
- 处理逻辑:直通传递(By pass),将输入内容原样传递给后续节点。
- 输出:所有输入内容。
- 特别说明(应用模式):在此模式下,开始节点支持定义多种复杂的入参类型,包括文件上传(PDF, Excel, 图片等)和结构化数据字段,为构建专业化应用提供了高度定制化的输入界面。
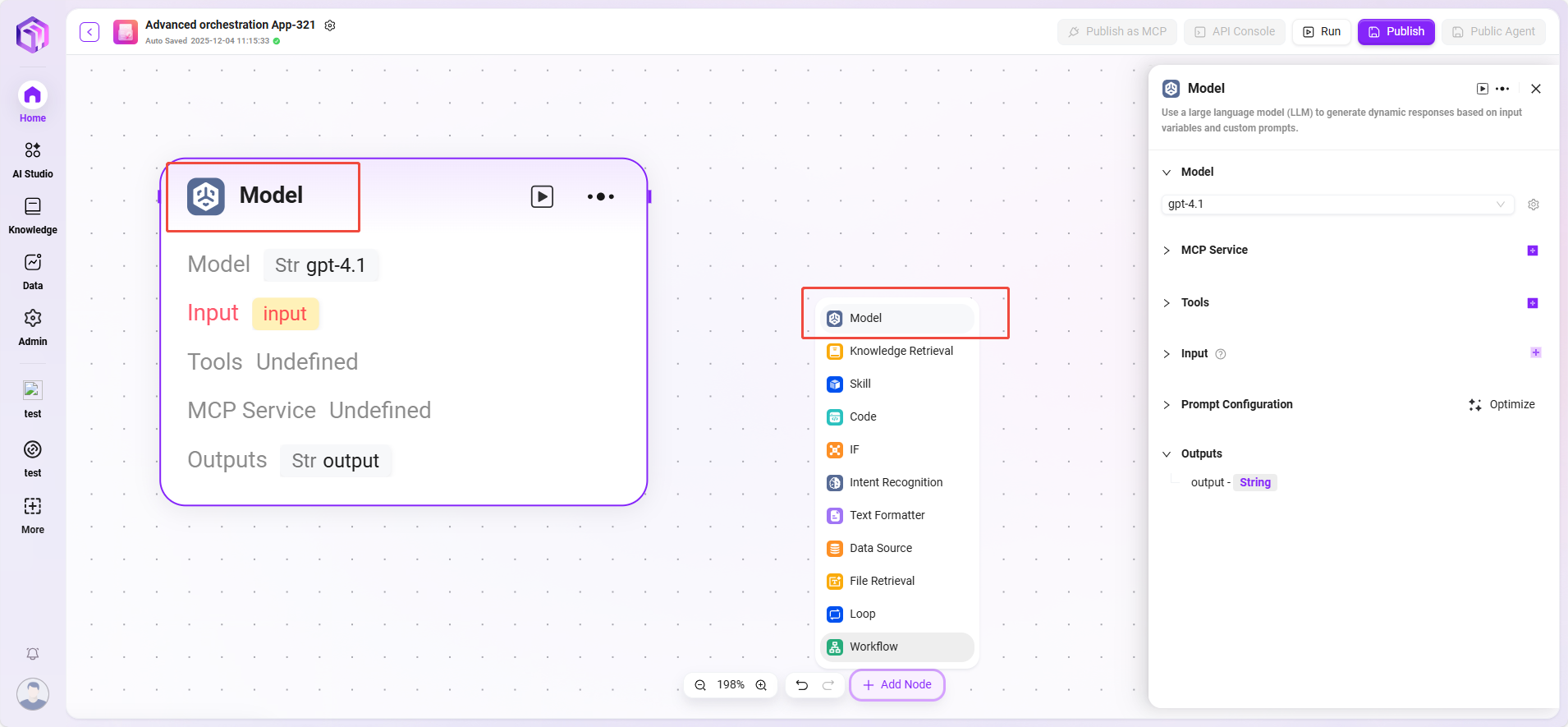
模型
调用大语言模型,使用变量和提示词生成回复。
输入:下拉选择已有的模型,选用输入变量名。 输入参数:query(String,来自上游或用户输入)。 配置参数:
- 一个或多个 Tools
- Model
- GPT(GPT 或其他模型)
- Temperature:控制创造性,数值越高,回答越有创造性和随机性。
- Top P:通过“概率阈值”限制选择的词范围,控制回答的多样性。
- Max Reply Length:限制AI一次能回复的最大字数。。
- Syatem Prompt:系统给AI的隐藏指令,用来控制整体风格
- User Prompt:用户输入的内容或问题。
- History:之前对话的轮次,用来保持上下文理解。
- 处理逻辑:把输入交给大语言模型(LLM)处理,模型根据配置生成回答。
- 输出结果:模型生成的文本内容。
💡 提示:需先连接上前置节点,才能选择其他节点的变量作为当前节点的输入。
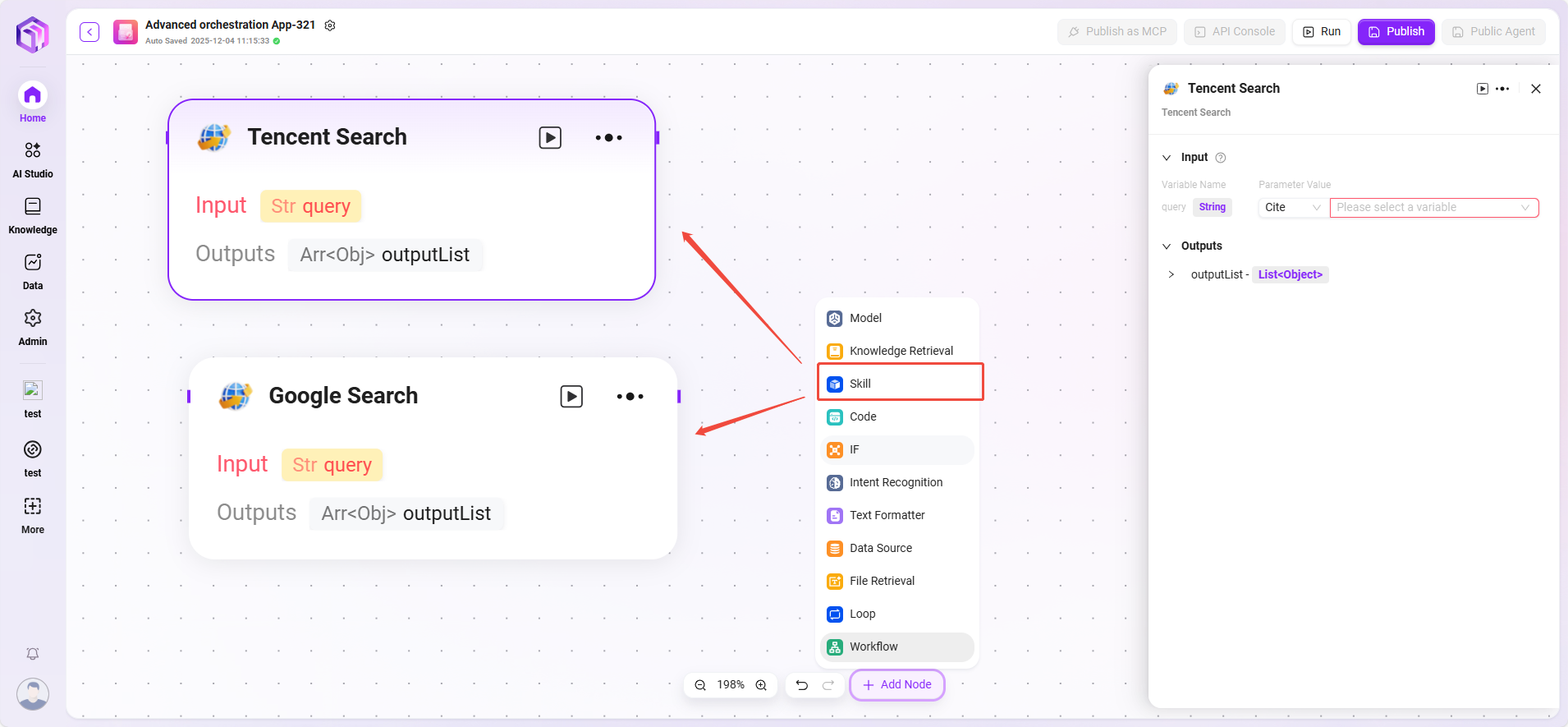
技能(示例)
- 网站读取:能读取网页上的静态文字(但看不到动态加载的内容)。
- 文本生成图片:根据描述性文本生成图像,并返回图片地址。
- 腾讯搜索:调用搜索引擎返回搜索结果。
💡 提示:高级编排模式下添加技能只允许添加内置技能,无法添加自定义技能。
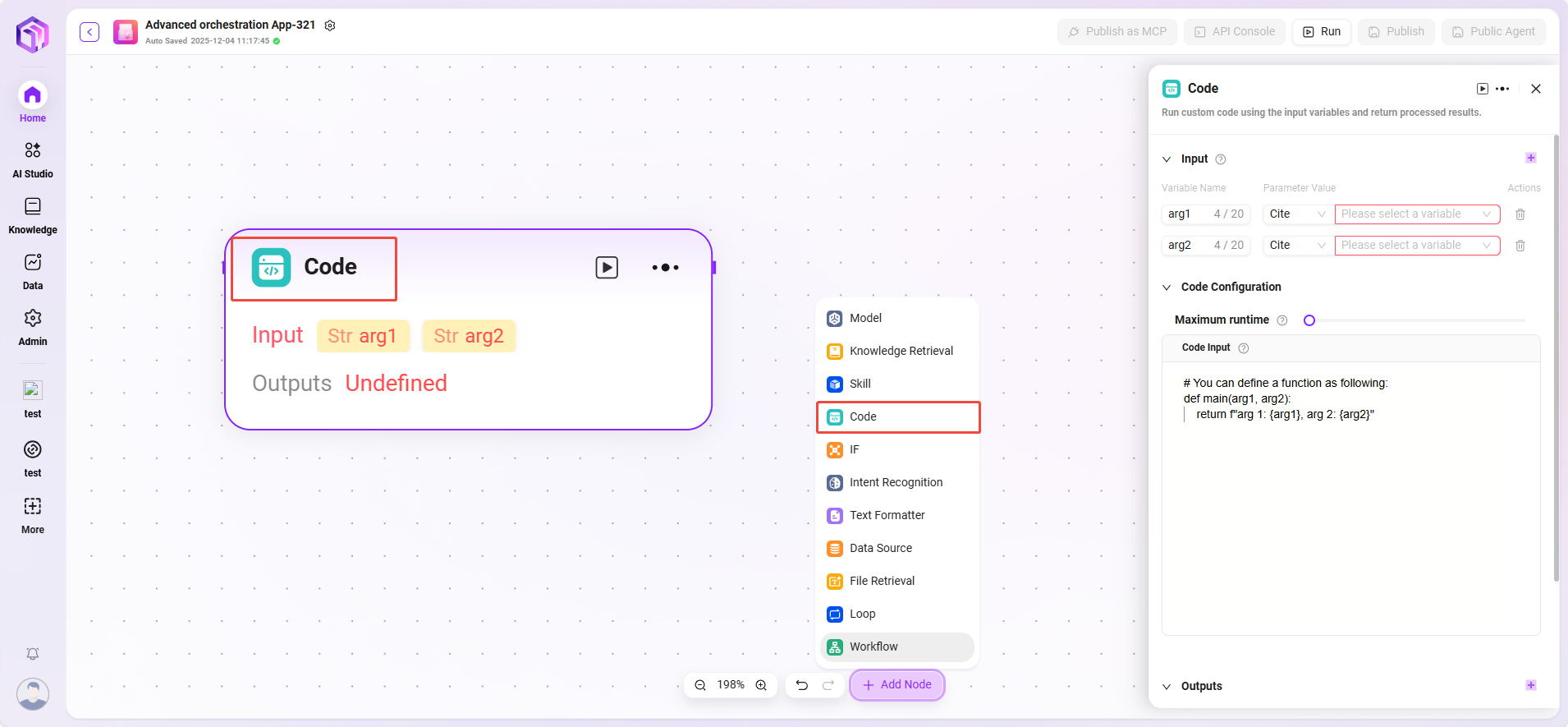
代码
编写代码,处理输入变量来生成返回值。
- 输入:用于接收外部传入的变量,是代码运行所需数据的入口,为后续代码处理提供原始数据。
- 输入参数:query(string,用户或上游传入的代码请求)。
- 配置参数:对代码运行相关参数进行设置。
- 最大运行时长(Maximum Runtime)
- 代码内容(Code Input)
- 处理逻辑:
- 在安全的沙箱环境中运行代码(基于 RestrictedPython 或指定平台)。
- 限制运行时长和访问权限,避免安全风险。
- 输出结果:代码运行处理完输入数据后,将结果以指定变量形式输出,是代码处理结果的出口。
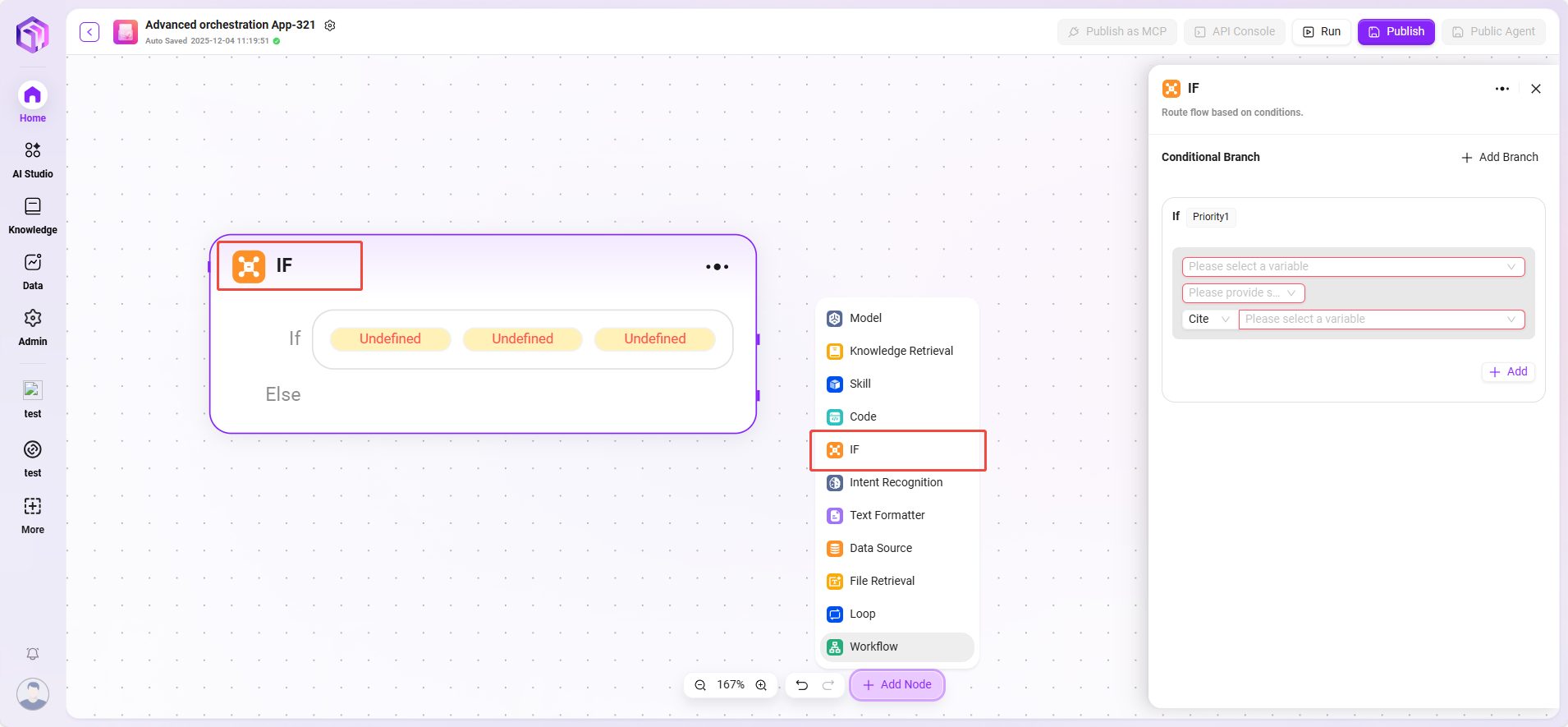
选择器
在流程编排中起条件判断作用。它连接多个下游分支,通过设定的条件来决定执行路径。
- 条件分支:可设置多个条件,如 “if - 优先级 1” 。通过配置引用变量、选择条件(如等于、大于等比较逻辑 )、比较值,来判断条件是否成立。若成立,就运行对应的分支流程。
- 处理逻辑:根据不同条件走不同路径(如果没有满足条件的,就走 Else)。
- 输出结果:没有直接输出,只决定下一个节点的走向。
意图识别
意图识别是自然语言处理中的关键环节,该模块作用是分析用户输入内容,确定其真实意图并匹配预设置选项。
- 模型:选择用于意图识别的模型,模型决定了意图识别的能力和效果。
- 意图匹配:可预先输入用户意图描述作为匹配标准,也能新增其他意图,系统据此判断用户输入符合哪种预设意图。
- 高级设置:能设置系统提示内容,可引用输入变量来优化提示效果;还可设置历史记忆条数,让模型参考过往对话信息提升识别准确性。
- 处理逻辑:判断用户的真实意图,把输入分类到对应类别。
知识库检索
- 输入:通过定义变量名及设置参数值,为知识库检索提供检索关键词等原始数据。
- 处理逻辑:根据输入和参数检索知识库,返回片段或FAQ。
- 知识库:选定特定的知识库作为检索范围,系统将在这个范围内查找匹配信息。
- 最大召回数量:可设置从知识库中最多返回匹配结果的数量,避免返回过多数据。
- 输出:将从知识库中检索到的匹配信息,以指定变量的形式输出,供后续流程使用。
文本格式器
主要用于处理字符串类型变量格式。
- 输入:可定义变量名,并通过引用方式获取参数值,为后续文本处理提供原始字符串数据。
- 处理逻辑:把文本做简单加工。
- 字符串拼接
- 字符串分割
- 字符串拼接:提供文本编辑区域,可按需求使用变量名方式引用输入变量,对多个字符串进行拼接等格式处理。
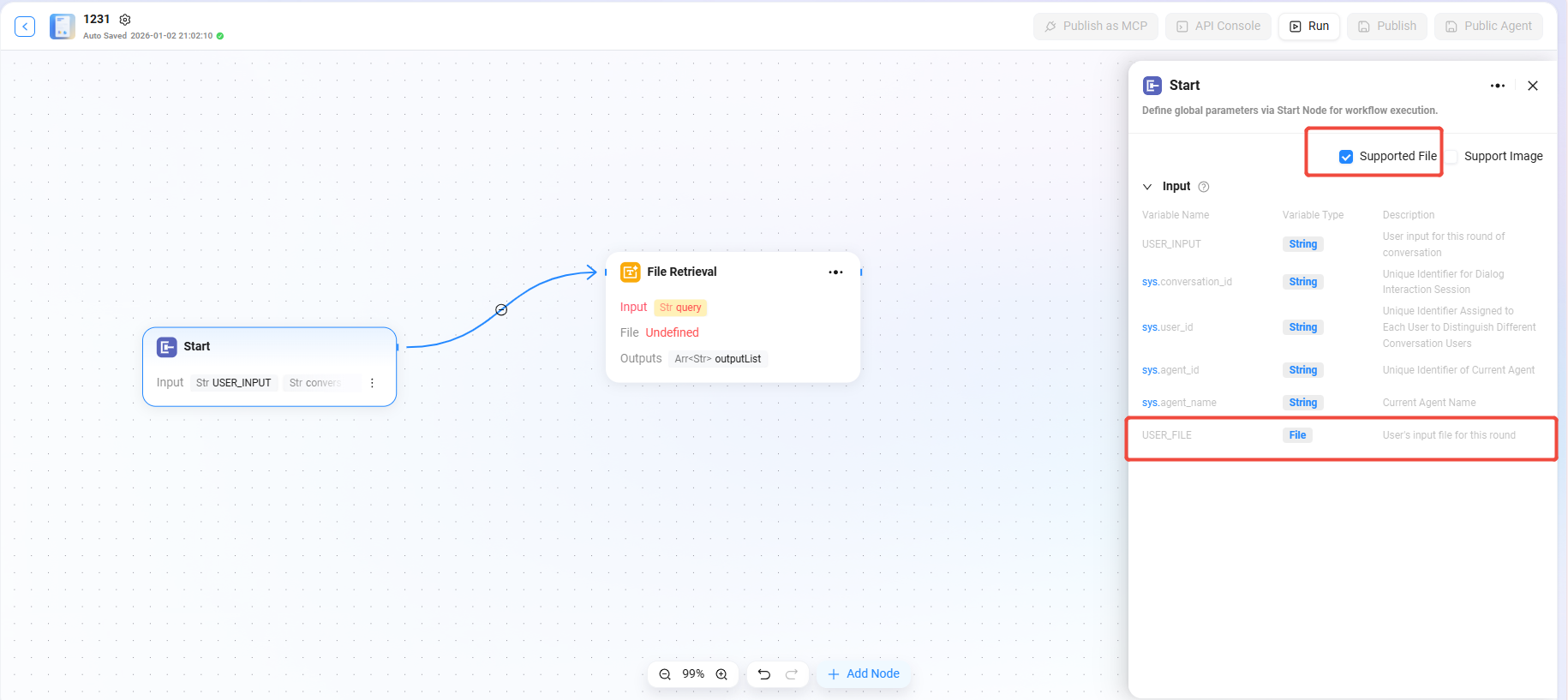
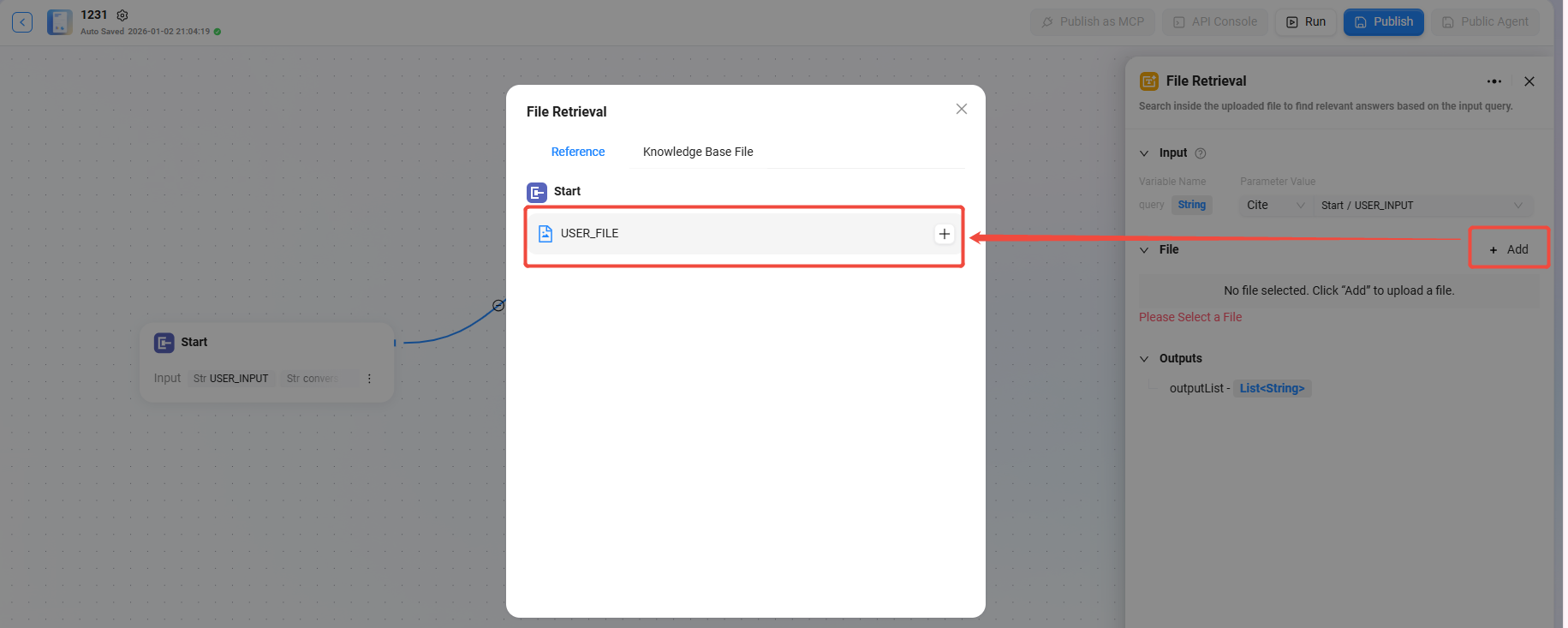
文件检索
文件检索是对文件内容进行检索等操作的功能模块。
- 输入:通过定义变量名并引用参数值来提供检索关键词等输入信息,为文件内容查找提供依据。
- 文件:可添加需要处理的文件到该节点,确定检索的文件范围。
配置文件检索
- 首先需要在“开始”节点中勾选“支持文件”
- 勾选后开始节点出现变量“USER_FILE”,指的是用户本轮输入的文件
- 再连接“开始”节点和“文件检索”节点
- 连接后,文件检索节点可添加“USER_FILE”为被检索的文件。
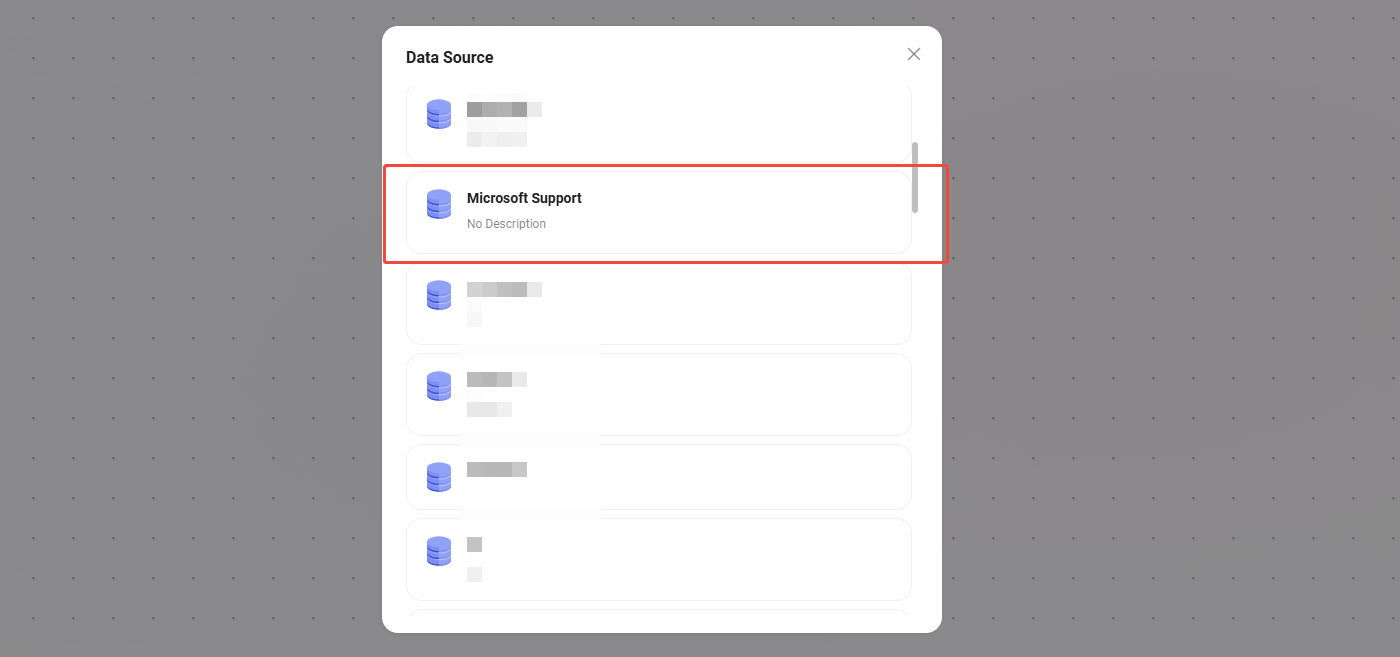
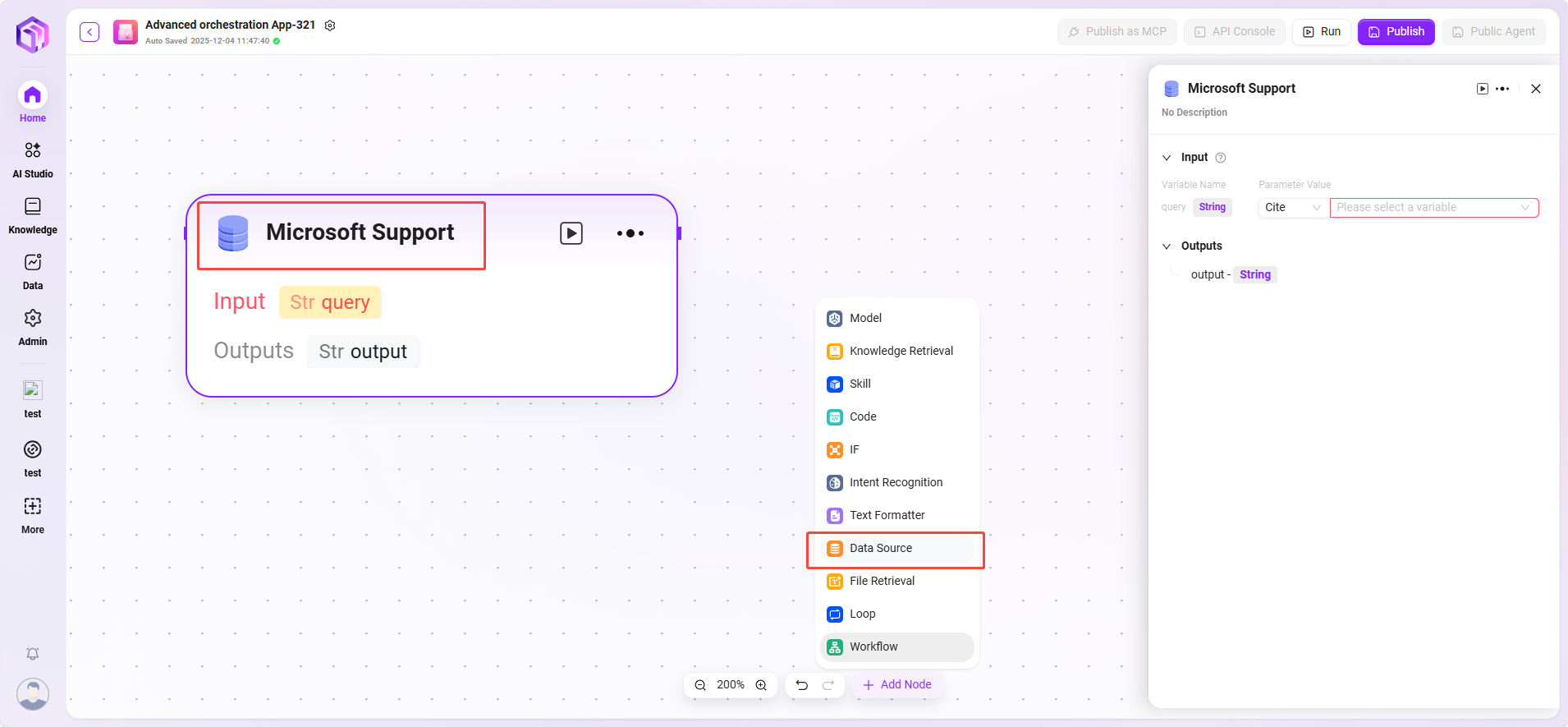
数据来源
- 数据来源:选择要接入的数据源。
- 处理逻辑:把自然语言转成SQL查询数据库,返回结果。
- 输出:将数据源的数据进行输出,输出给下一个节点。
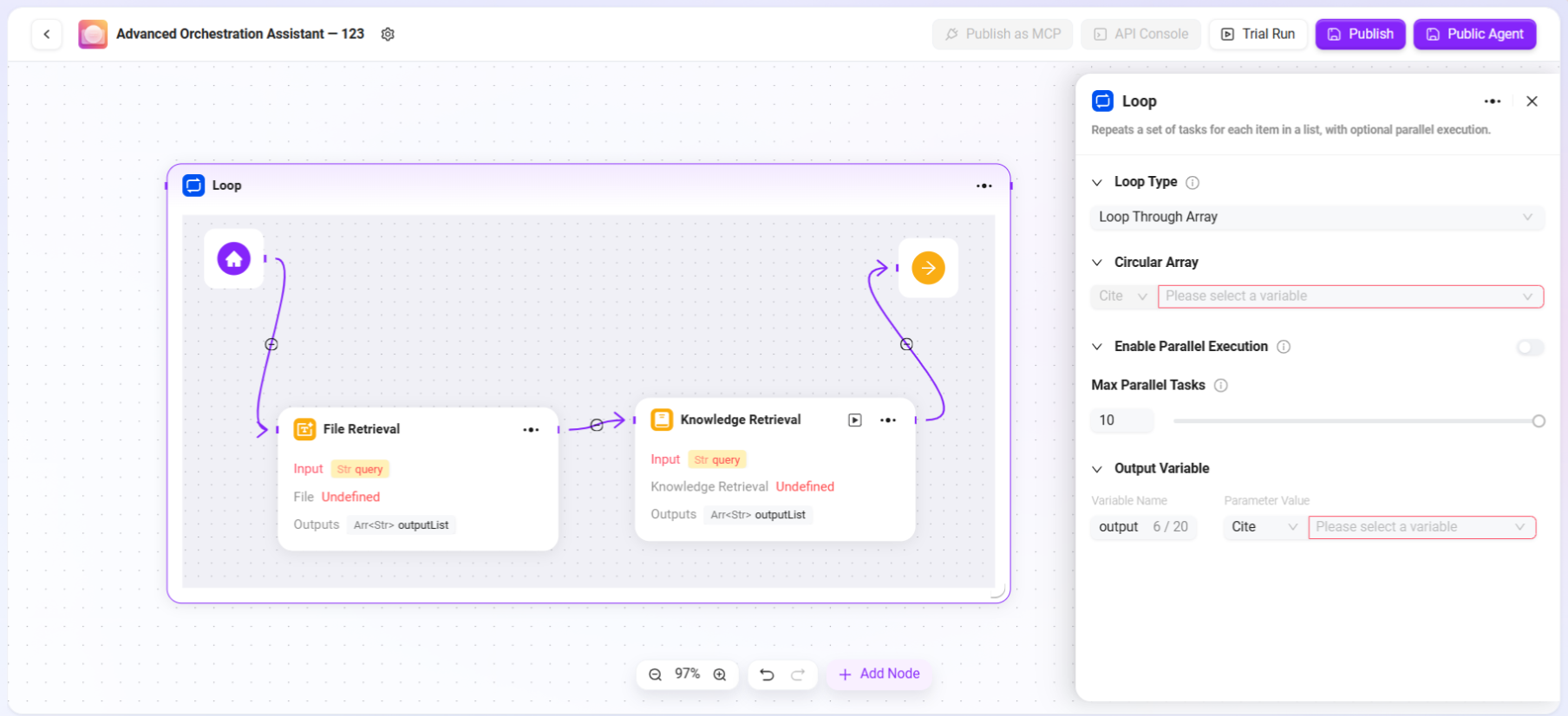
循环
用于按指定的次数或指定的数据集合,重复执行一组任务。通过配置不同的循环模式,可以灵活实现批量处理或重复操作。
- 循环类型:支持两种模式
- 使用数组循环:根据输入的数组,对数组中的每个元素依次执行任务。
- 使用数值循环:按照设定的次数,循环执行任务。
- 循环数值/数组:
- 当选择“数值循环”时,需输入一个具体的数字,例如 2,则表示任务将被执行 2 次。
- 当选择“数组循环”时,需要提供一个数组变量,系统会逐一取出数组中的元素作为输入执行任务。
- 并行执行:可选功能。如果开启,系统会同时处理多个循环任务,提升效率。用户可以设置最大并行数,以控制资源占用。
工作流示例
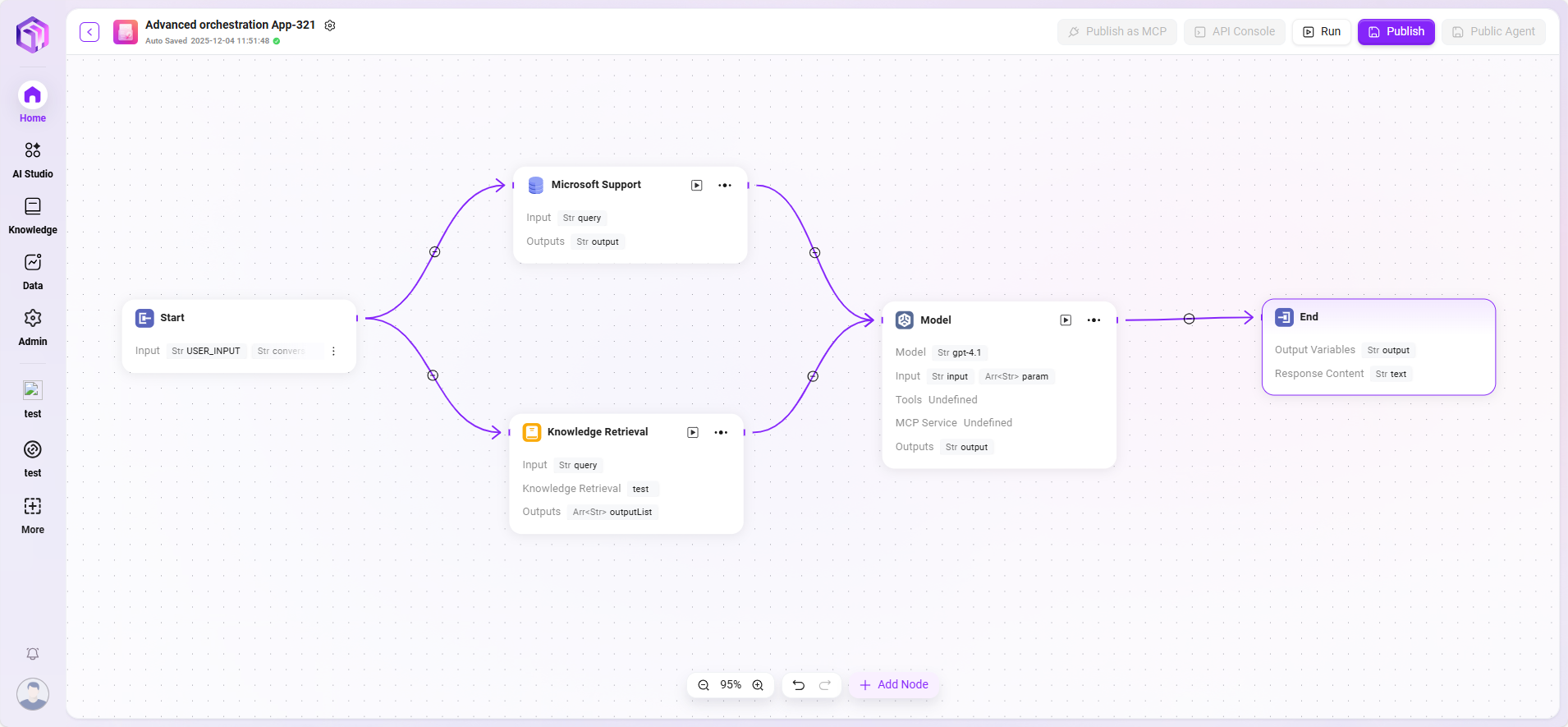
在本场景中,使用工作流功能构建一个完整的 “Microsoft Support Ticket Issue Analytics” 流程,具体流程如下:
- 开始节点
流程的起点,系统默认包含。 - 数据源节点
用于接入工单分析所需的原始数据。 - 知识库节点
接入包含分析参考资料的知识文档,作为AI分析的理论支撑。 - 模型节点
基于AI模型,将数据源与知识库内容结合,进行综合分析,生成工单问题分析结果。 - 结束节点
流程的终点,输出模型节点的分析结果。此节点系统默认包含。
数据源节点与知识库节点并列配置,模型节点则汇总处理前两者的信息,确保输出结果具备数据依据和理论支撑。
最后效果如下:
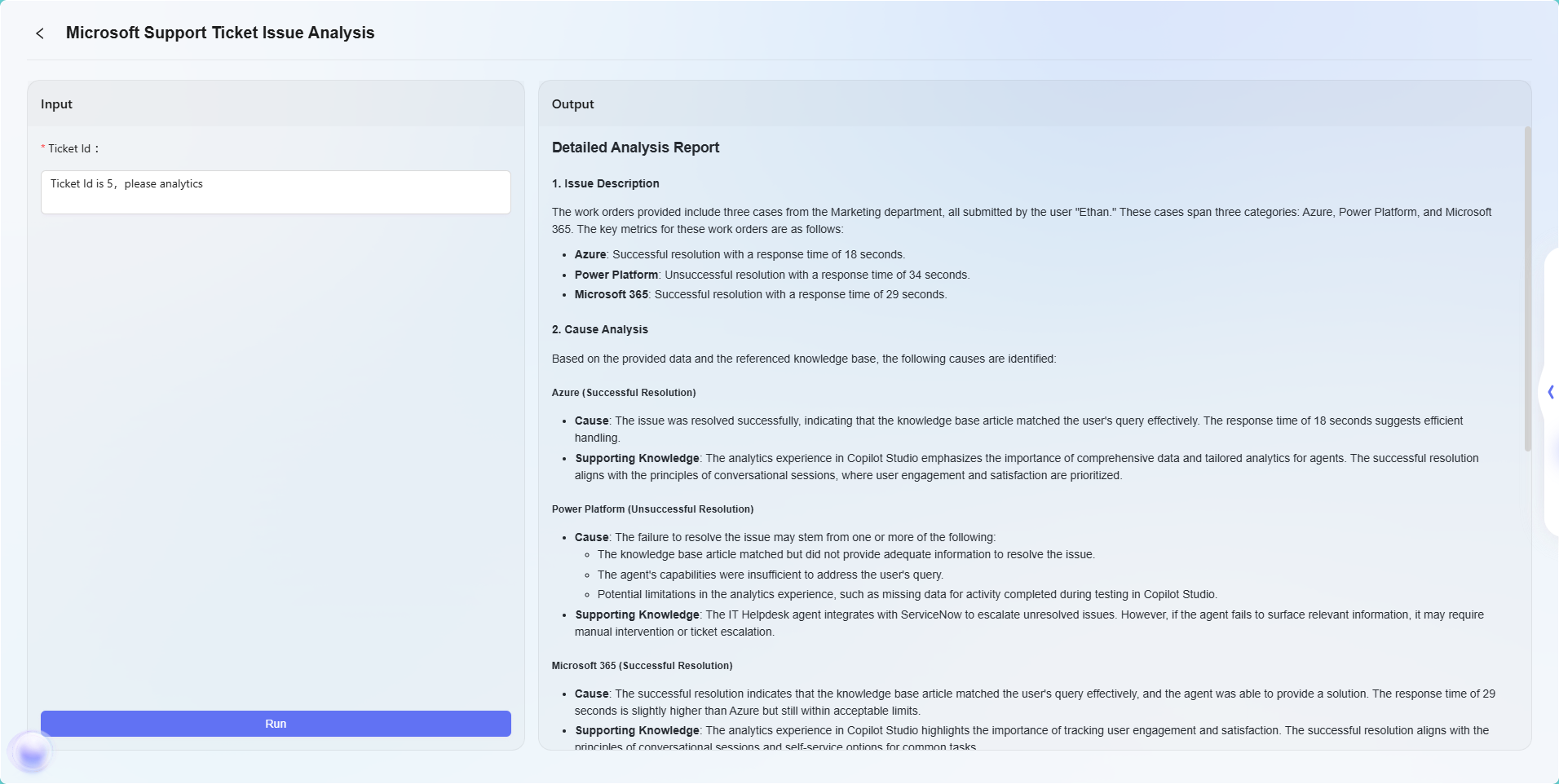
注:本示例仅为工作流功能的基础应用演示。工作流编排具备高度的灵活性与可扩展性,通过组合各类节点,能够实现极其复杂的业务逻辑与自动化流程,可适应广泛的业务场景需求。