配置检索 Pipeline 与 Agent 问答
本教程是"企业技术文档智能问答系统"系列的第二篇,承接上一篇 配置预处理 Pipeline 与知识库入库。
在上一篇中,我们已经完成了:
- ✅ 预处理 Pipeline 编排(文本提取 → 智能分段 → 多维度摘要增强 → 向量化存储)
- ✅ 知识库创建并绑定预处理 RAG Pipeline
- ✅ 技术文档上传与入库验证
本篇将在此基础上,配置检索 Pipeline 并关联到 Agent,实现端到端的智能问答能力。
💡 前置条件:请确保已完成上一篇教程,知识库中已有处理完成的文档数据。
第一步:配置检索 Pipeline
检索 Pipeline 决定了用户提问时如何从知识库中召回最相关的内容。由于预处理阶段已生成多维度增强数据(段落摘要、图片描述、表格摘要),检索时可利用这些数据提升召回质量。
创建检索 Pipeline
- 在 知识库 页面,切换到 "检索 Pipeline" 页签。
- 点击 "+ 创建 Pipeline",填写:
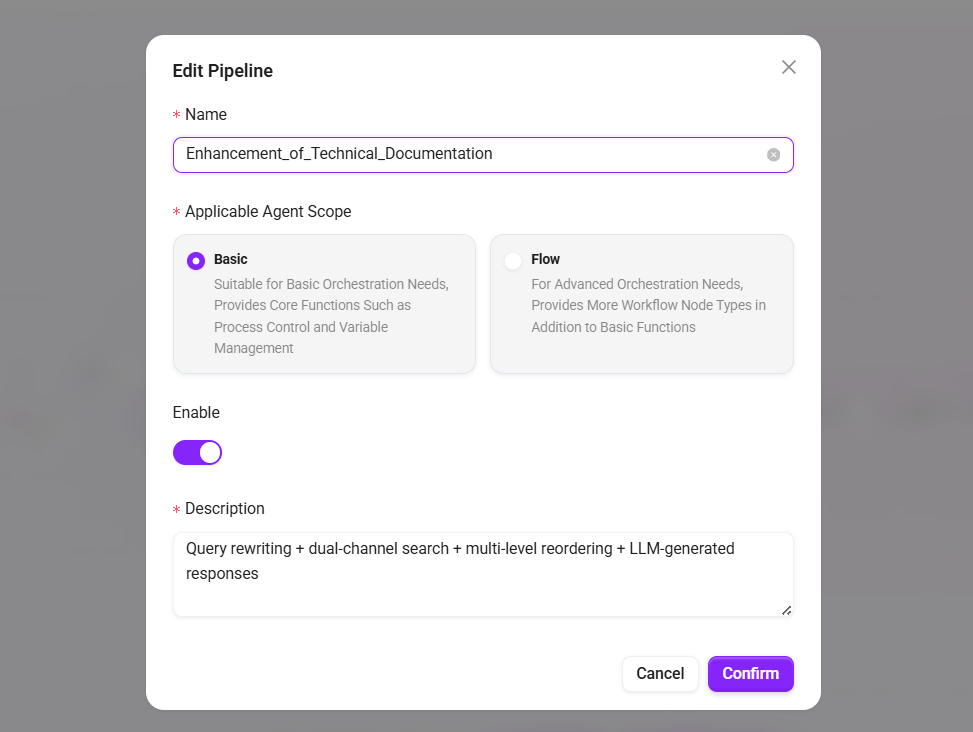
- 名称:
技术文档增强检索 - 适用Agent范围:选择
基础编排 - 描述:
查询改写 + 双通道检索 + 多级重排 + LLM 生成回答
- 名称:
- 点击 "确认" 进入编排界面。
配置检索节点
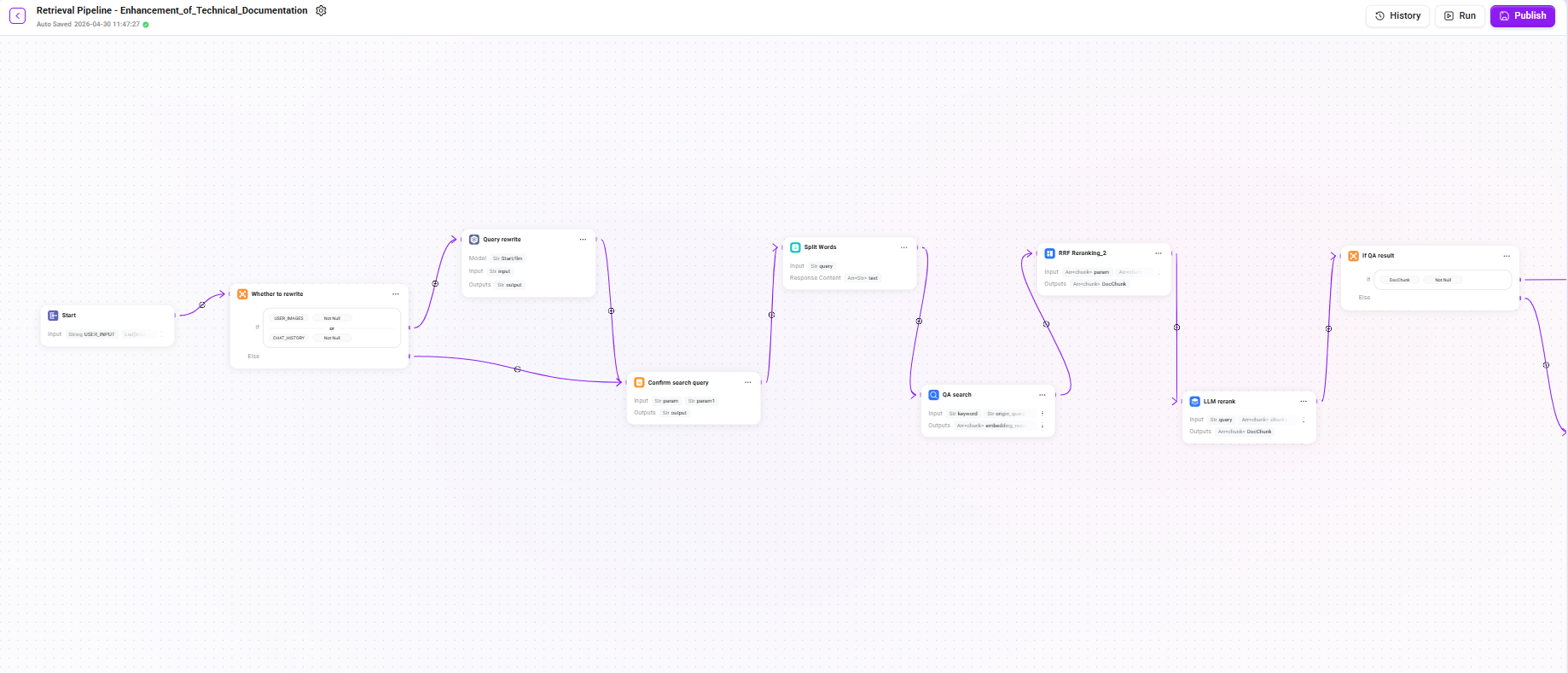
本检索 Pipeline 采用多阶段递进式架构,包含查询改写、双通道检索、多级重排、条件兜底和 LLM 生成回答等环节。由于链路较长,下面分三个阶段详细说明。
阶段一:查询理解与检索
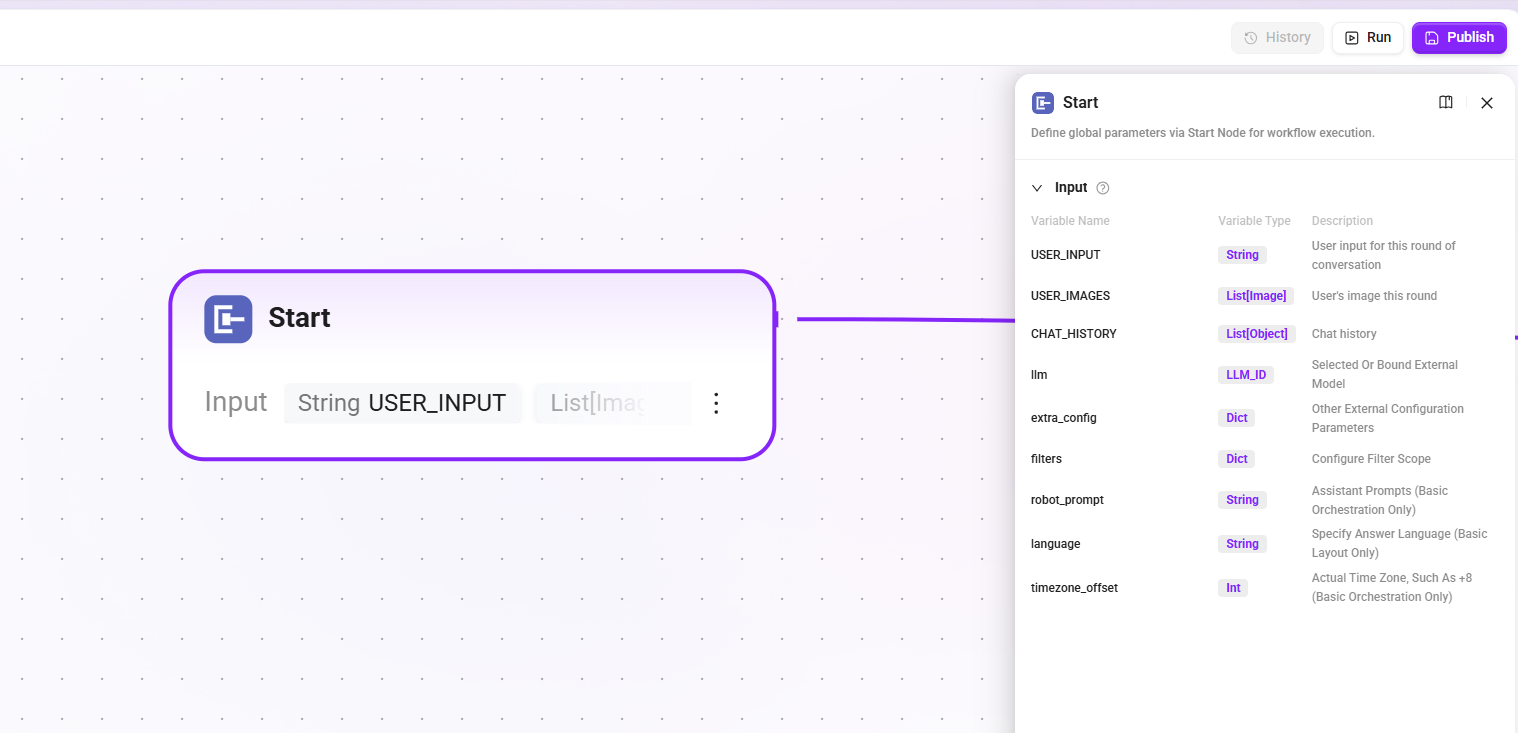
1. Start 节点
定义启动工作流需要的输入参数,这些内容将在助手对话过程中被LLM阅读,使LLM可以在合适的时候启动工作流并填入正确的信息。
- 输入:
USER_INPUT(用户本轮对话输入内容)、CHAT_HISTORY(聊天记录)、USER_IMAGES(用户本轮输入的图片)等
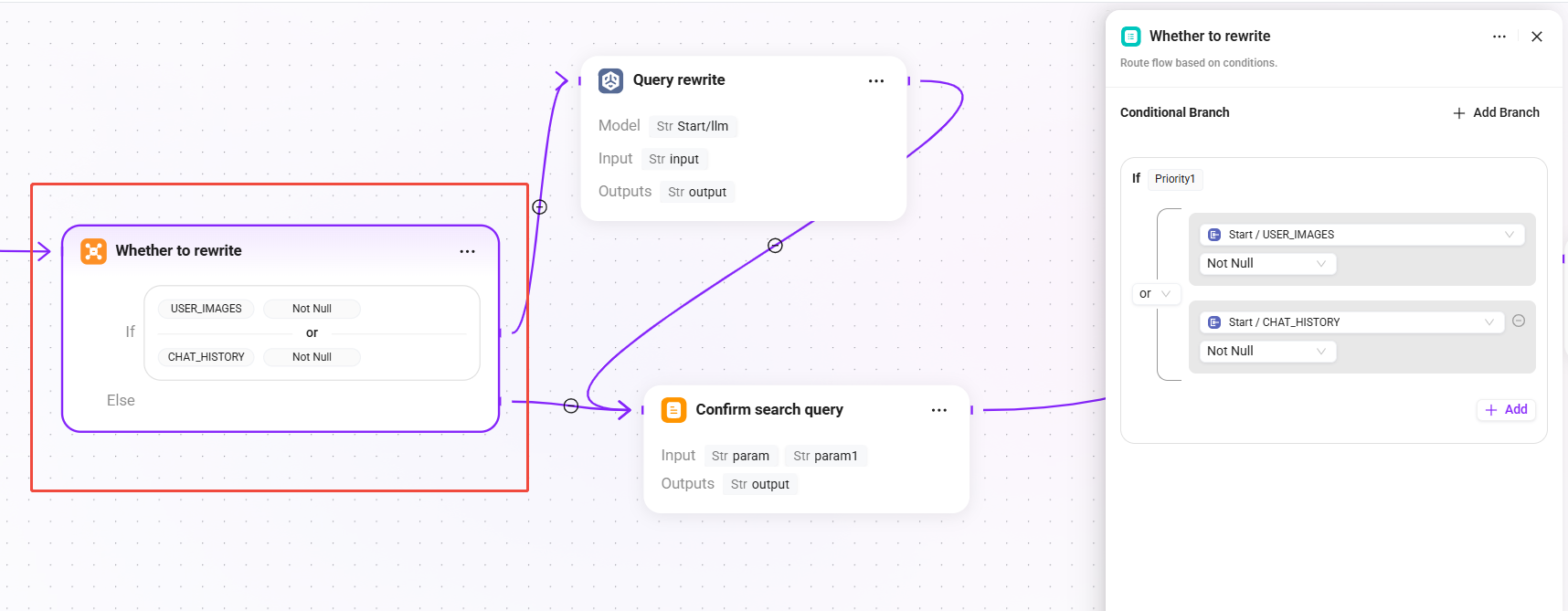
2. Whether to rewrite(条件判断)
根据当前会话上下文判断是否需要对用户查询进行改写:
- 条件:
USER_IMAGES不为空或CHAT_HISTORY不为空时,进入“查询改写”分支。 - else:跳过改写流程,直接进入“确认搜索查询”节点,将原始问题作为最终查询。
💡 当存在多轮对话历史时,用户的最新提问可能是指代性表达(如"它的参数是什么?"),此时需要改写为完整查询以提升检索效果。
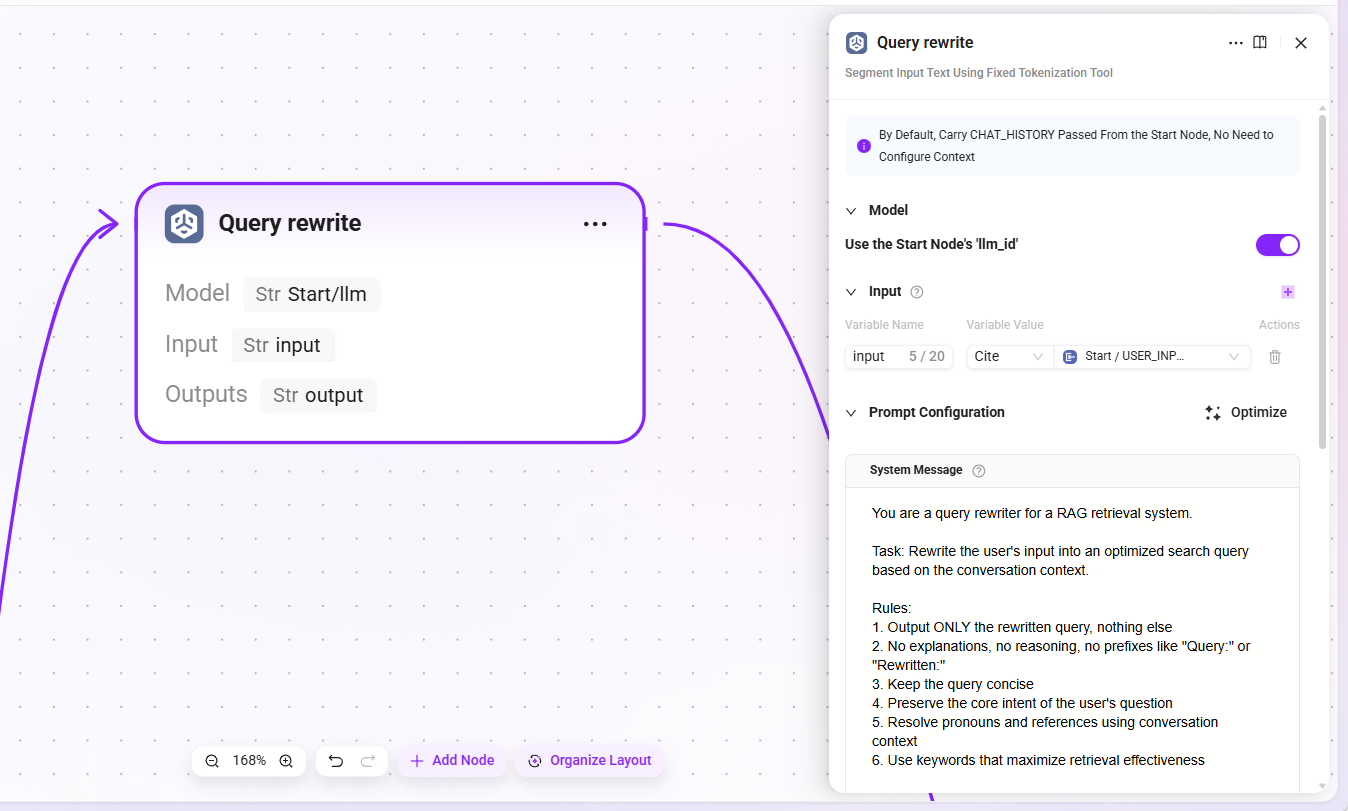
3. Query rewrite(查询改写)
- 模型:沿用开始节点所配置的 LLM(
llm_id) - 输入:
USER_INPUT(用户输入的原始问题文本) - 输出:
output(改写后的完整查询语句)
LLM 会结合上下文将模糊指代替换为明确表述,例如将"它怎么配置?"改写为"知识库的检索 Pipeline 如何配置?"。
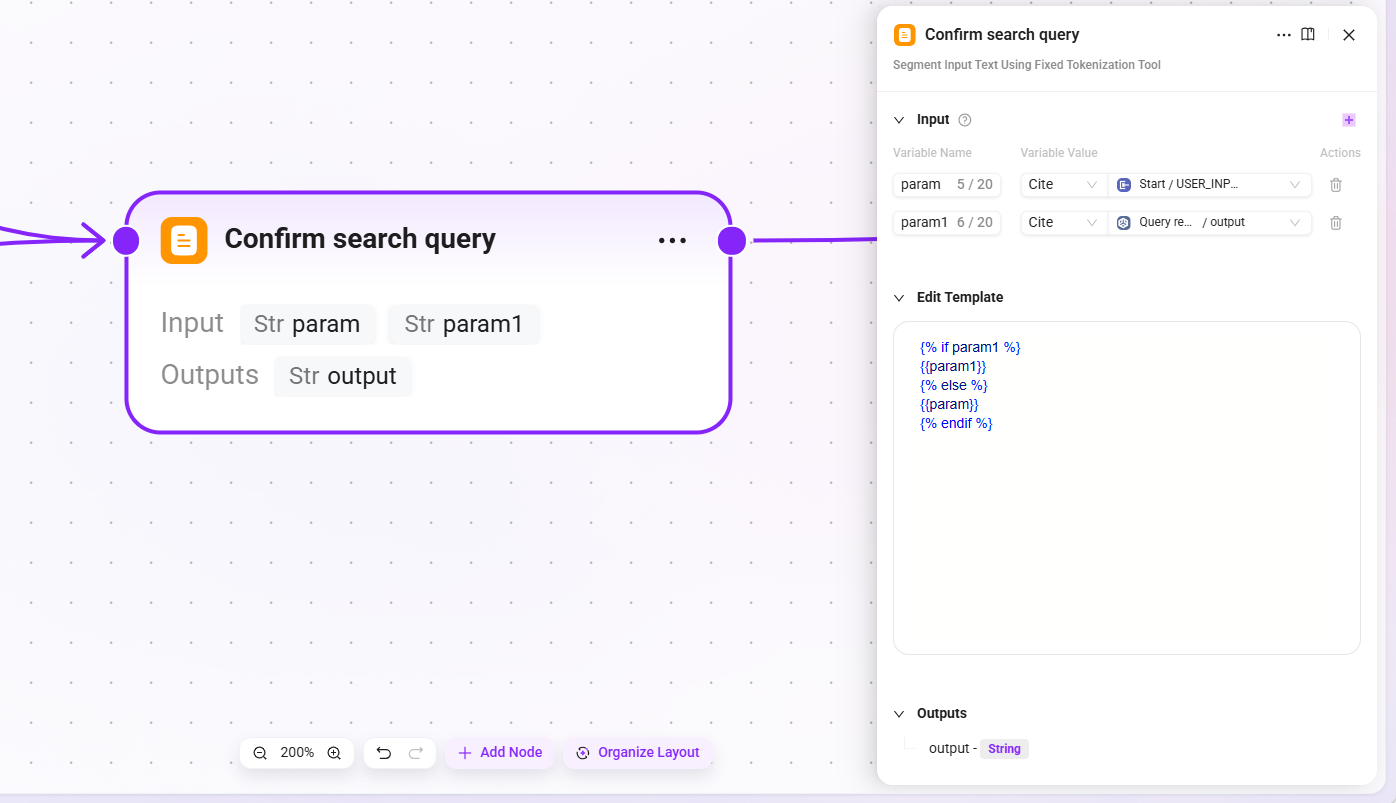
4. Confirm search query(确认搜索查询)
- 输入::
param(原始用户输入)、param1(查询改写后的结果) - 输出:
output(最终确认的搜索查询)
该节点确保无论是否经过改写,都有一个确定的查询语句传递给下游检索节点。
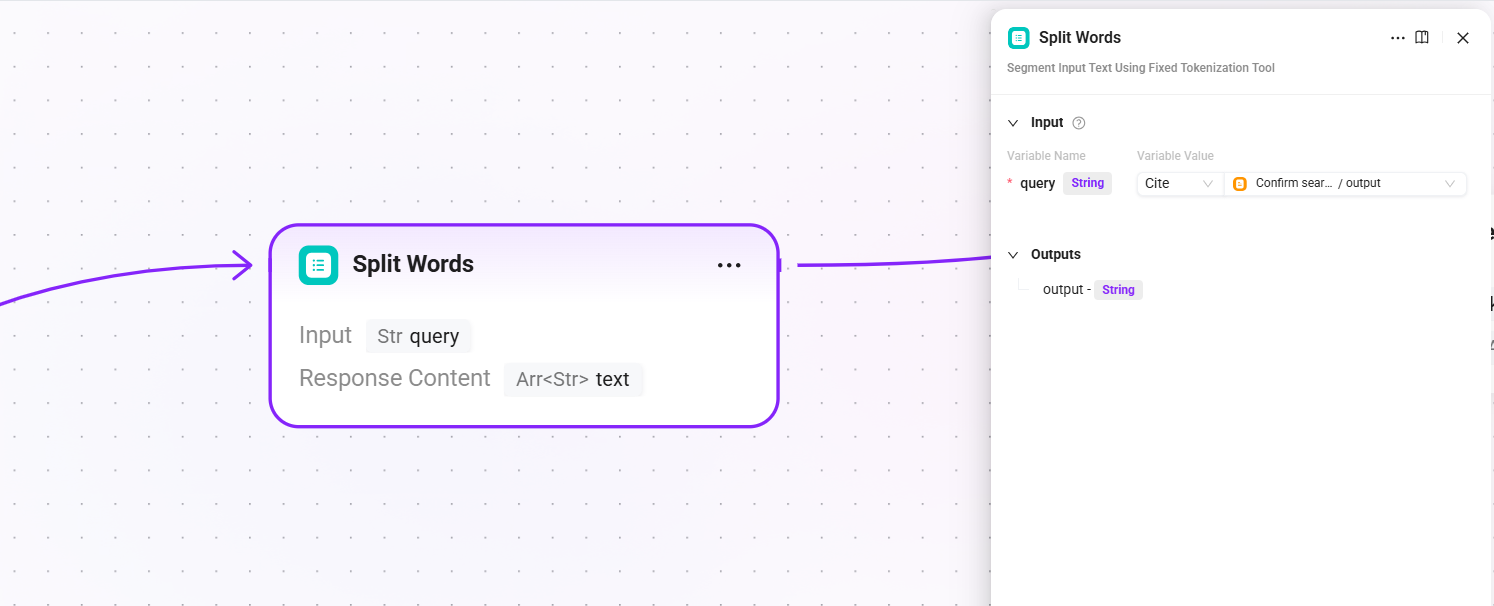
5. Split Words(分词)
- 输入:
query(搜索查询后的最终查询文本) - 输出:
text(分词结果,用于全文检索的关键词)
对查询进行分词处理,提取关键词供后续 QA 检索和文档检索的全文匹配通道使用。
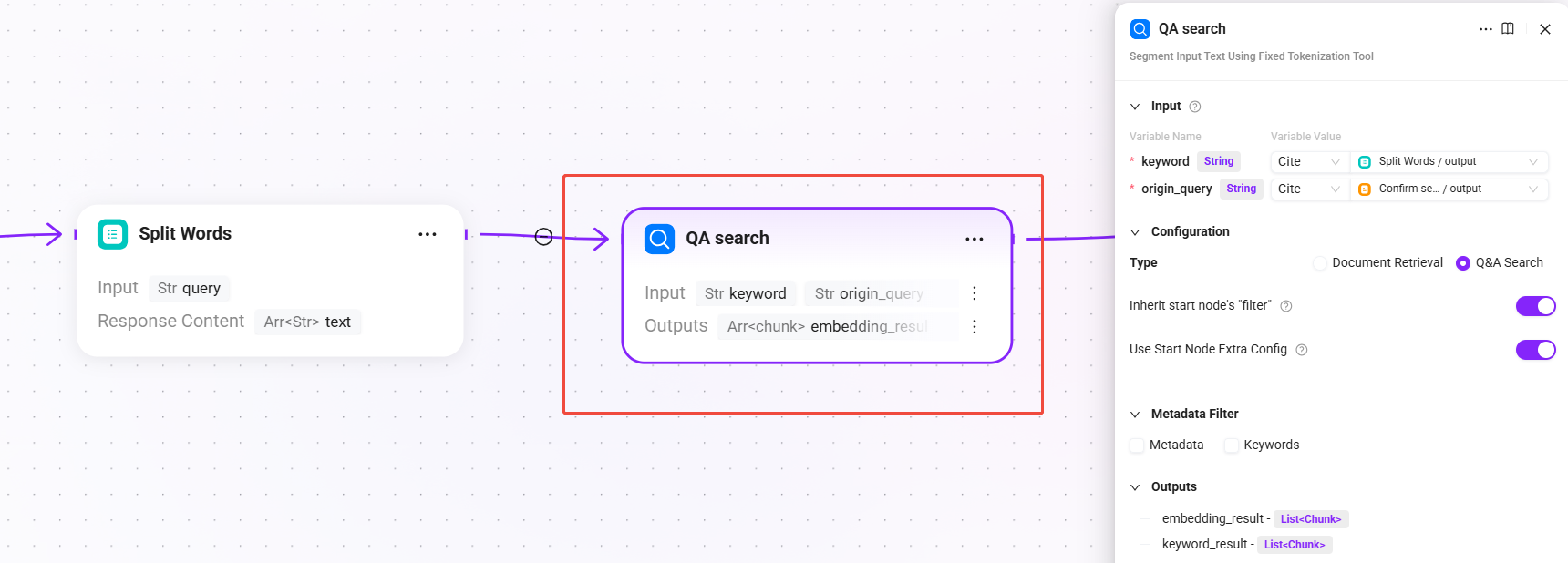
6. QA search(QA 知识检索)
- 输入:
keyword(分词后的关键词)、origin_query(搜索查询后的最终查询文本) - 配置:选择
Q&A 检索,默认开启沿用开始节点 filters和沿用开始节点 extra_config - 输出:
embedding_result(QA 知识库的检索结果)、keyword_result(基于关键词全文检索的 QA 匹配结果)
优先从 QA 问答对知识库中检索,QA 知识库通常包含已整理好的标准问答对,命中率高、回答质量稳定。
阶段二:多级重排与条件兜底
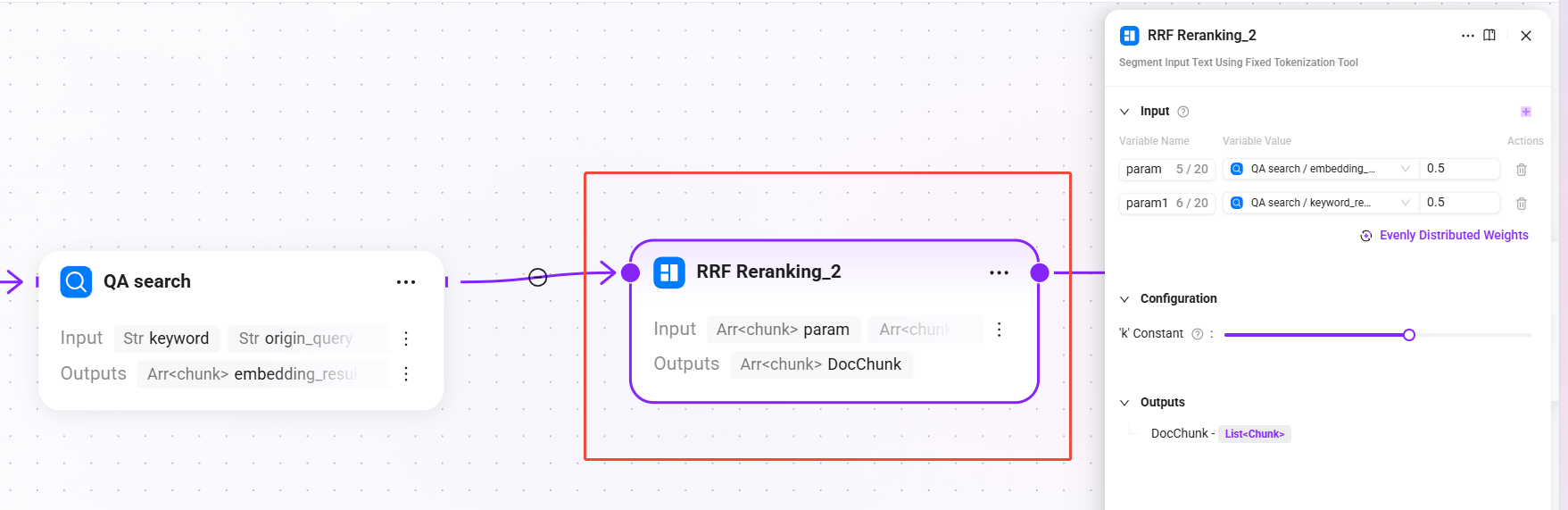
7. RRF Reranking_2(RRF 融合重排)
将输入文本通过固定的分词工具进行分词处理
- 输入:
param(QA 检索的语义向量召回结果)、param1(QA 检索的关键词全文匹配召回结果)- 两路输入权重均分,各为 0.5
- 配置:
-
- k 常数:
60(0-100,用于控制排名对最终得分的衰减速度,值越大,排名靠后的结果权重衰减越平缓)
- k 常数:
-
- 输出:
DocChunk(重排后的文档片段)
使用 RRF(Reciprocal Rank Fusion)算法对 QA 检索结果进行融合排序,综合多路召回的排名信息,生成统一的相关度排序。
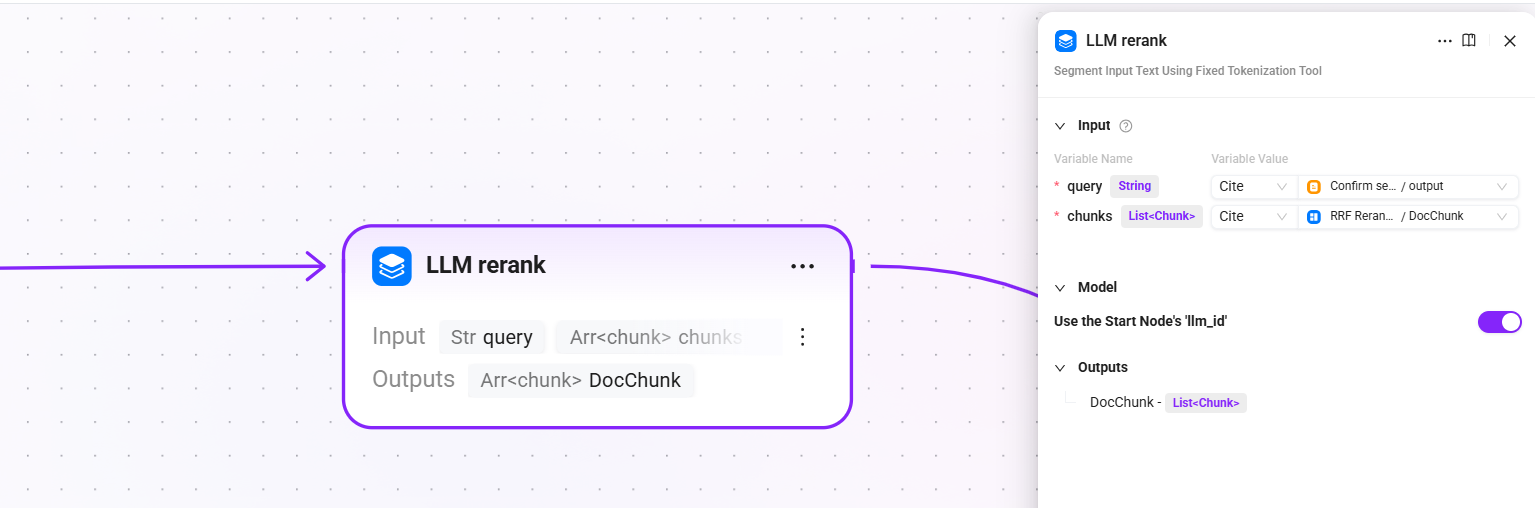
8. LLM rerank(LLM 精排)
- 输入:
query(搜索查询后的最终查询文本)、chunk(重排后的文档片段) - 配置:沿用开始节点所配置的 LLM(
llm_id) - 输出:
DocChunk(精排后的片段)
调用 LLM 对候选片段进行语义级精排,逐一判断每个片段与用户问题的相关程度,比传统 Reranker 模型具有更强的语义理解能力。
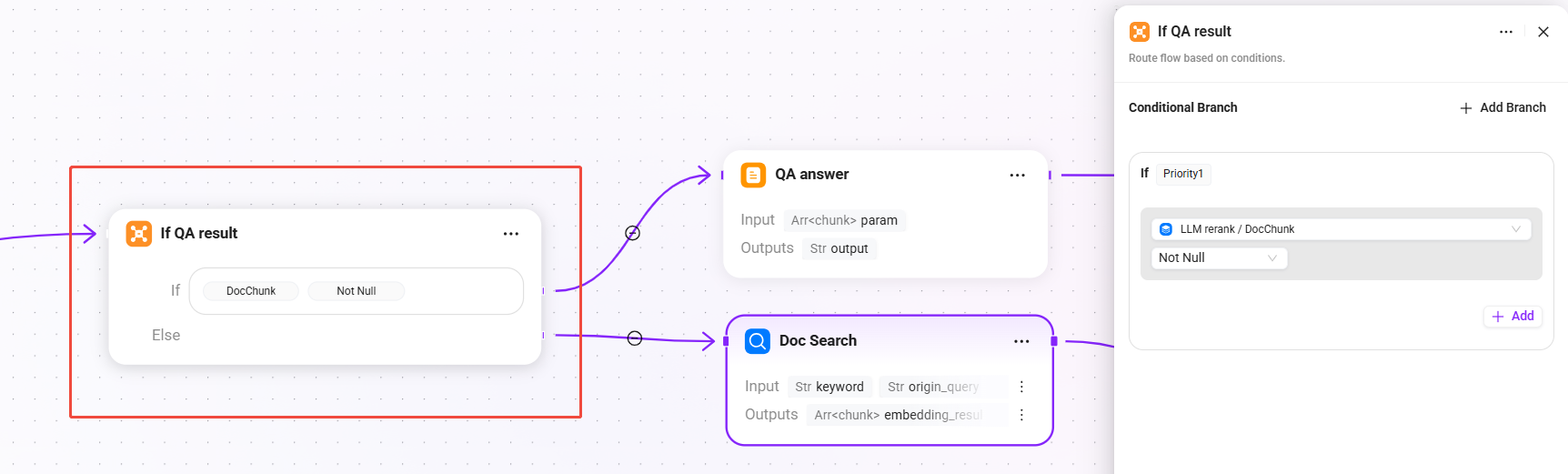
9. If QA result(条件判断 - QA 结果是否有效)
- 条件:
DocChunk不为空时,直接使用 QA 检索 + 重排的结果 - else:QA 结果为空,触发文档兜底检索
这是本 Pipeline 的关键设计:优先使用 QA 知识库的高质量回答,仅当 QA 无法命中时才回退到文档片段检索,兼顾回答质量与召回覆盖率。
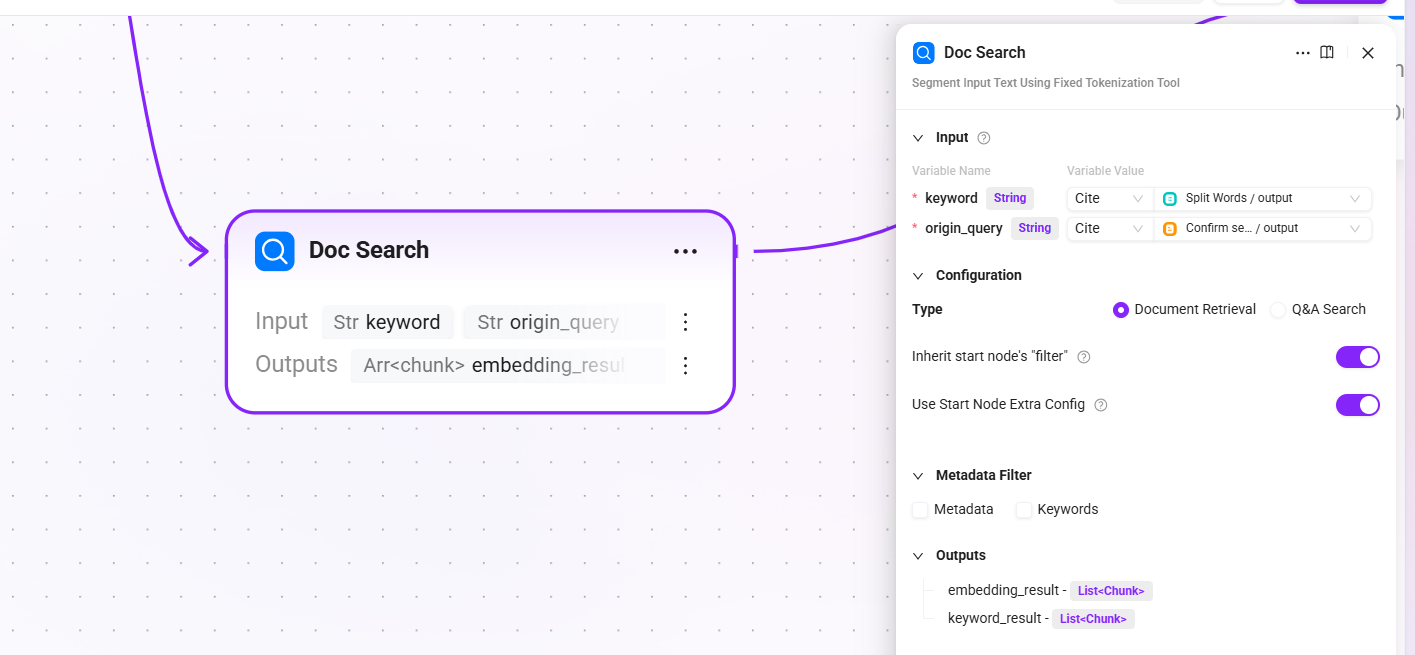
10. Doc Search(文档检索 - 兜底通道)
- 输入:
keyword(分词后的关键词)、origin_query(确认后的最终查询文本) - 配置:选择
文档检索,默认开启沿用开始节点 filters和沿用开始节点 extra_config - 输出:
embedding_result(语义向量检索命中的文档片段列表)和keyword_result(关键词全文匹配命中的文档片段列表)
当 QA 检索无结果时,从预处理阶段存入的文档片段中进行向量 + 全文融合检索,确保用户问题不会无回答。
11. RRF Reranking_1(文档检索重排)
- 输入:
param(文档检索的语义向量召回结果)、param1(文档检索的关键词全文匹配召回结果) - 配置:
k常数:60(与 QA 检索重排使用相同的衰减控制值,保证排序策略一致)
- 输出:
DocChunk(重排后的文档片段)
对文档兜底检索的结果同样进行 RRF 融合重排,保证返回结果的相关度排序质量。
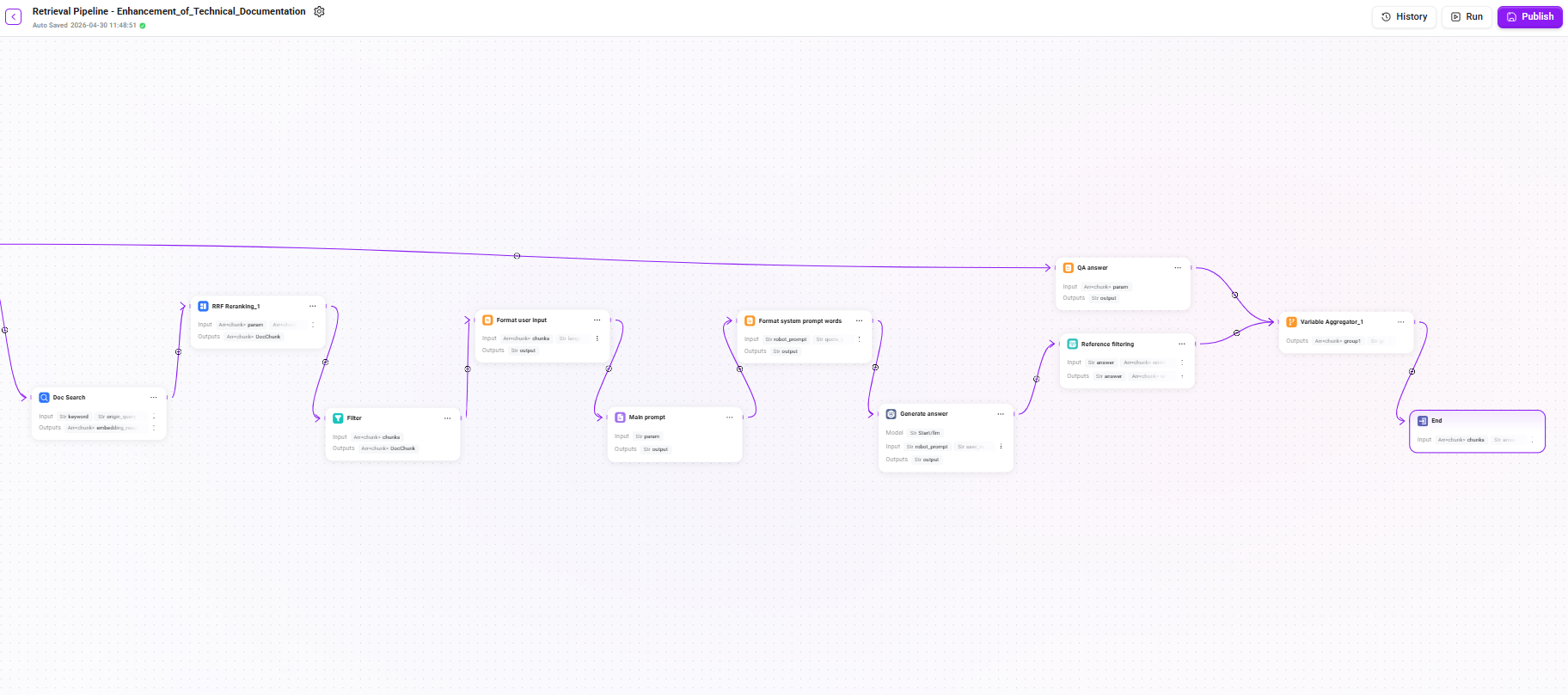
阶段三:回答生成与输出
12. Filter(过滤)
- 输入:
chunks(来自文档检索重排后的候选片段列表) - 模型:沿用开始节点所配置的 LLM(
llm_id) - 输出:
DocChunk(经过 LLM 筛选后保留的高相关片段,去除噪音或弱相关内容)
对最终召回的片段进行过滤,移除低相关度或重复片段,确保传给 LLM 的上下文精简有效。
13. Format user input(格式化用户输入)
- 输入:
chunks(经过过滤后的高相关文档片段列表)、language(用户输入的语言)、user_input(用户输入的内容) - 输出:
output(格式化后的用户上下文)
将召回的文档片段与用户问题按指定模板格式拼接,构成 LLM 的用户侧输入。
14. Main prompt(主提示词组装)
- 模式:字符串拼接
- 输入:
param(格式化后的用户上下文) - 输出:
output(组装后的主提示词内容)
15. Format system prompt words(格式化系统提示词)
- 输入:
robot_prompt(助手提示词)、quote_prompt(组装后的主提示词内容)、time_diff_hour(实际时区) - 输出:
output(完整的 System Prompt,作为 LLM 的系统级指令)
将 Agent 的人设描述、行为约束与检索上下文模板整合为完整的 System Prompt。
16. Generate answer(生成回答)
- 模型:沿用开始节点所配置的 LLM(
llm_id) - 输入:
robot_prompt(完整的系统提示词)、user_input(格式化后的用户上下文) - 输出:
output(LLM 生成的最终回答文本)
核心生成节点,LLM 基于检索到的文档片段和系统提示词,为用户生成最终回答。
17. Reference filtering(引用过滤)
- 输入:
answer(LLM 生成的最终回答文本)、retrival_docs(经过过滤后的高相关文档片段列表) - 输出:
answer(回答)、reference(从“retrieval_docs”中筛选出的、回答中实际引用或依据的片段列表)
从候选片段中筛选出实际被回答引用的片段,作为参考来源展示给用户,增强回答的可追溯性。
18. QA answer(QA 回答处理)
- 输入:
param(精排后的片段) - 输出:
output(处理后的回答结构)
对 QA 通道产出的标准答案进行格式化处理。
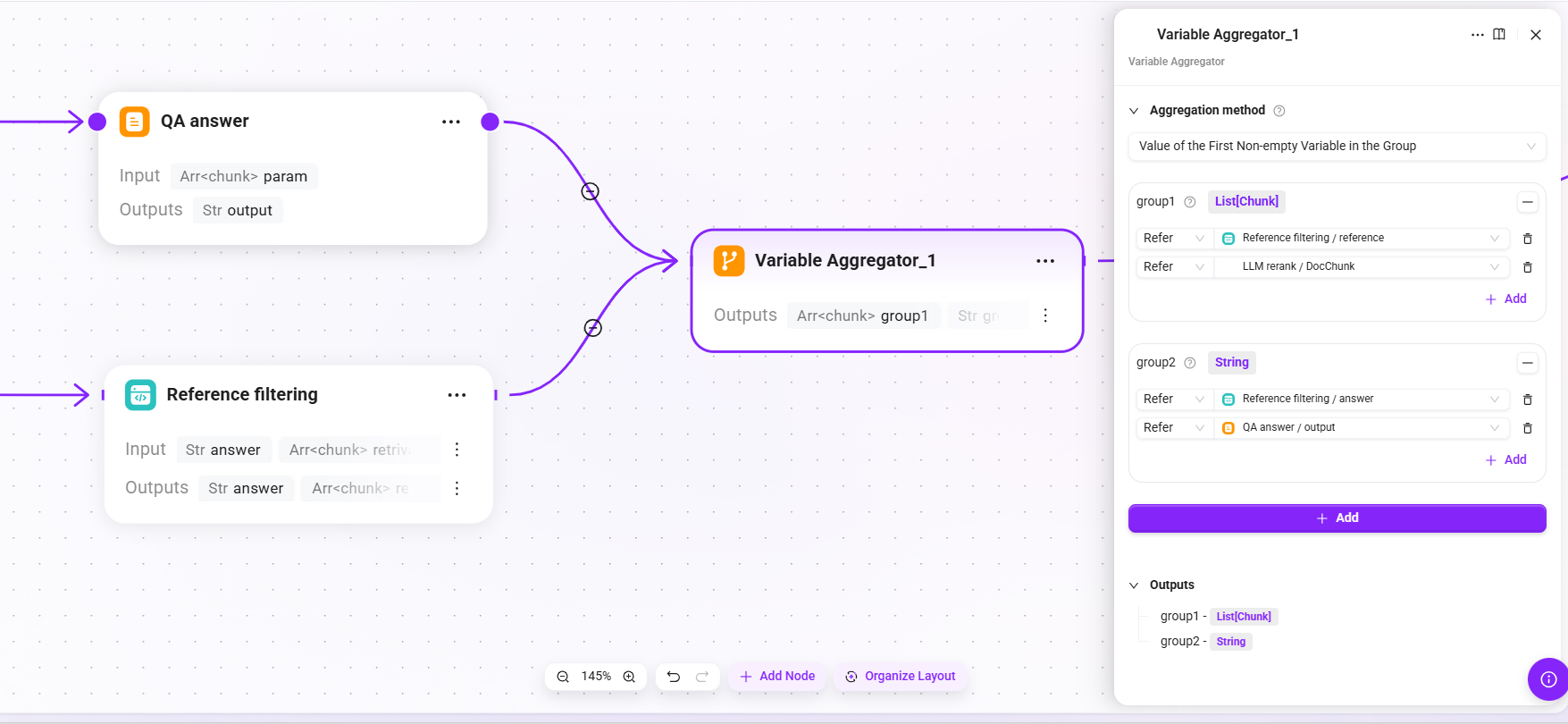
19. Variable Aggregator_1(结果聚合)
- 聚合策略:分组首个非空变量的值
- 输入:
- group1:
- Reference filtering 输出的
reference列表。 - LLM Rerank 精排后的片段
- Reference filtering 输出的
- group2:
- Reference filtering 输出的
answer文本。 - QA answer 输出的
output。
- Reference filtering 输出的
- group1:
- 输出:
group1(最终使用的引用来源列表)、group2(最终返回给用户的回答文本)
将 QA 回答和引用过滤的输出统一聚合,形成最终返回结构。
20. End(流程结束)
- 输出:
chunks(聚合后的group1,即最终确认的参考引用列表)、answer(聚合后的group2,即最终返回给用户的回答文本)
输出最终结果给调用方(Agent),包含回答内容和参考引用。
完整检索链路总结
检索测试与发布
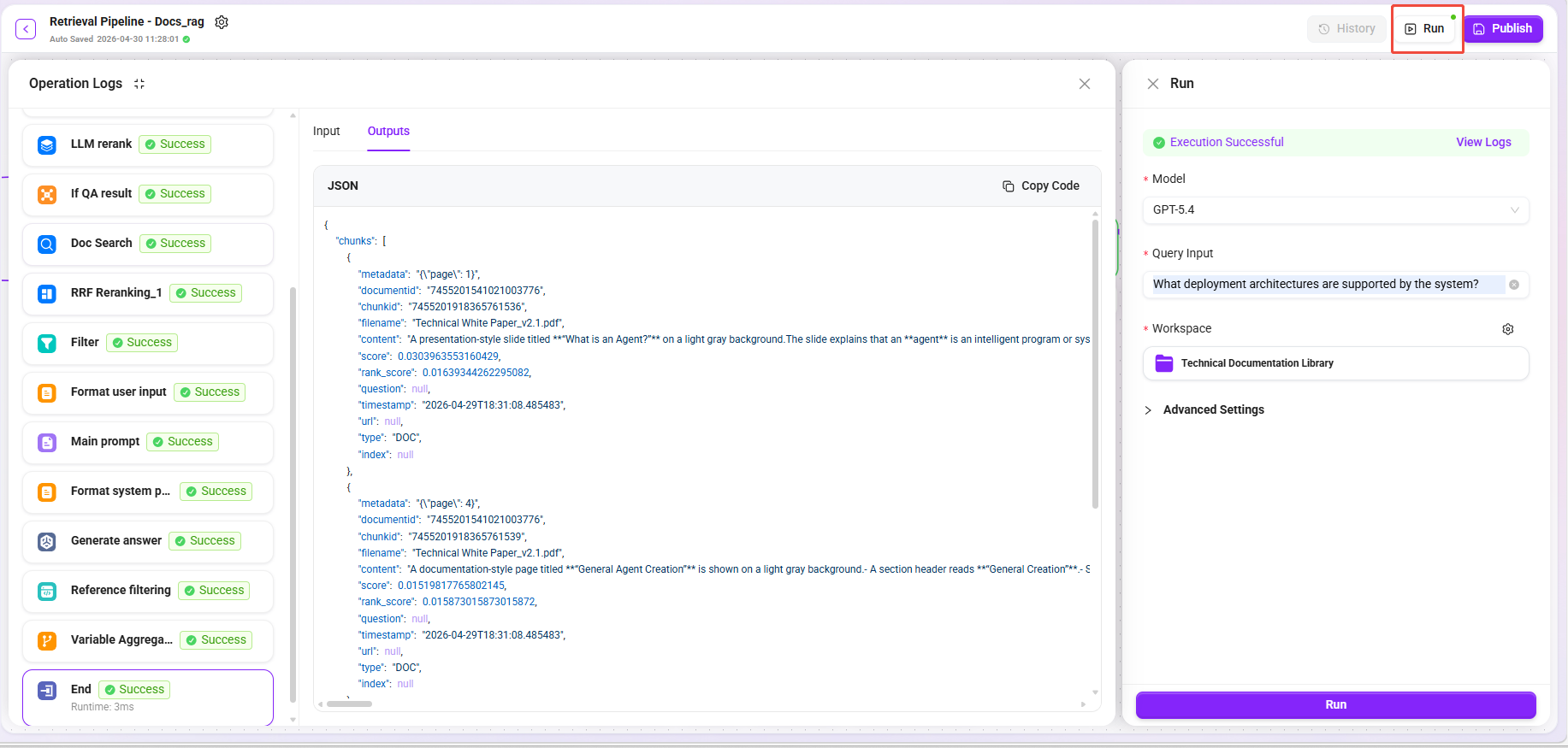
- 点击 "试运行" 按钮。 2,选择模型:GPT-5.4
- 输入不同类型的问题:
| 测试问题 | 预期召回类型 |
|---|---|
系统支持的部署架构有哪些? | 文字段落 + 架构图描述 |
各模块的性能指标对比 | 表格摘要相关片段 |
数据处理流程是怎样的? | 流程图描述 + 相关文字段落 |
- 选择知识库:Technical Documentation Library
- 确认召回结果涵盖多维度数据(原文 + 摘要 + 图片描述 + 表格摘要)。
- 确认测试结果满足预期后,点击 "发布"。
第二步:创建 Agent 并应用检索 RAG Pipeline
将配置好的检索 Pipeline 关联到 Agent,完成端到端的智能问答验证。
创建或配置 Agent
- 进入 AI Asset 模块 → Agent 管理。
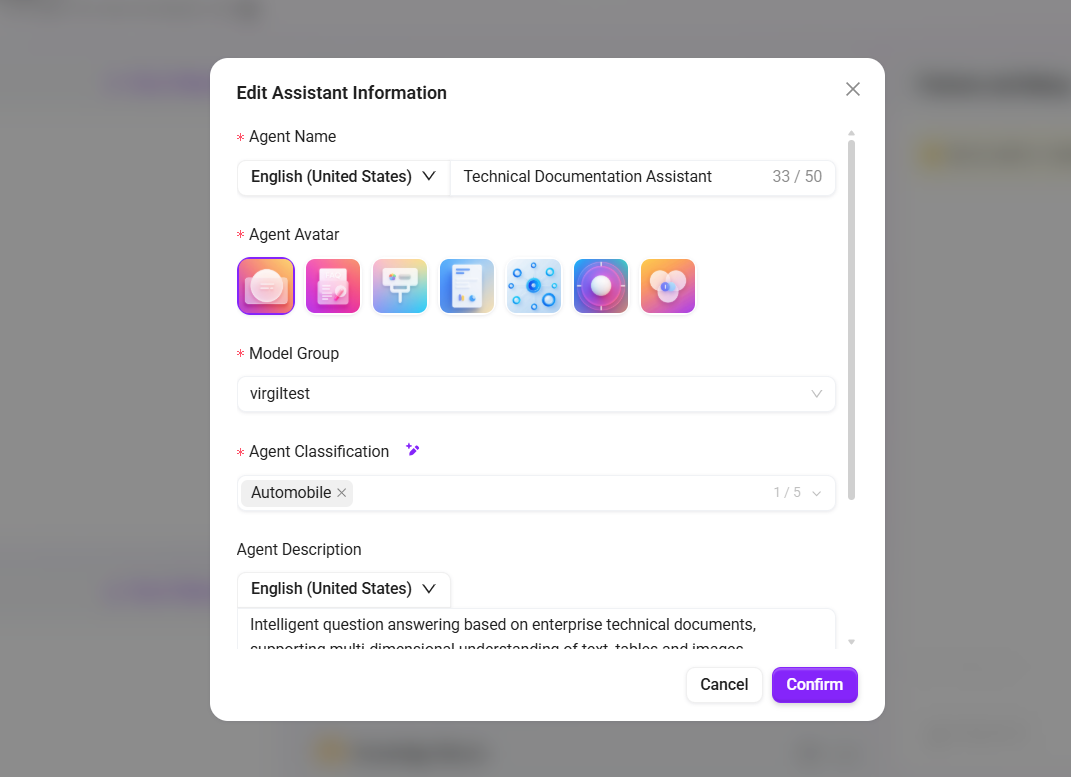
- 创建基础Agent 或选择已有 Agent,填写:
- 名称:
技术文档助手 - 描述:
基于企业技术文档的智能问答,支持文字、表格、图片多维度理解
- 名称:
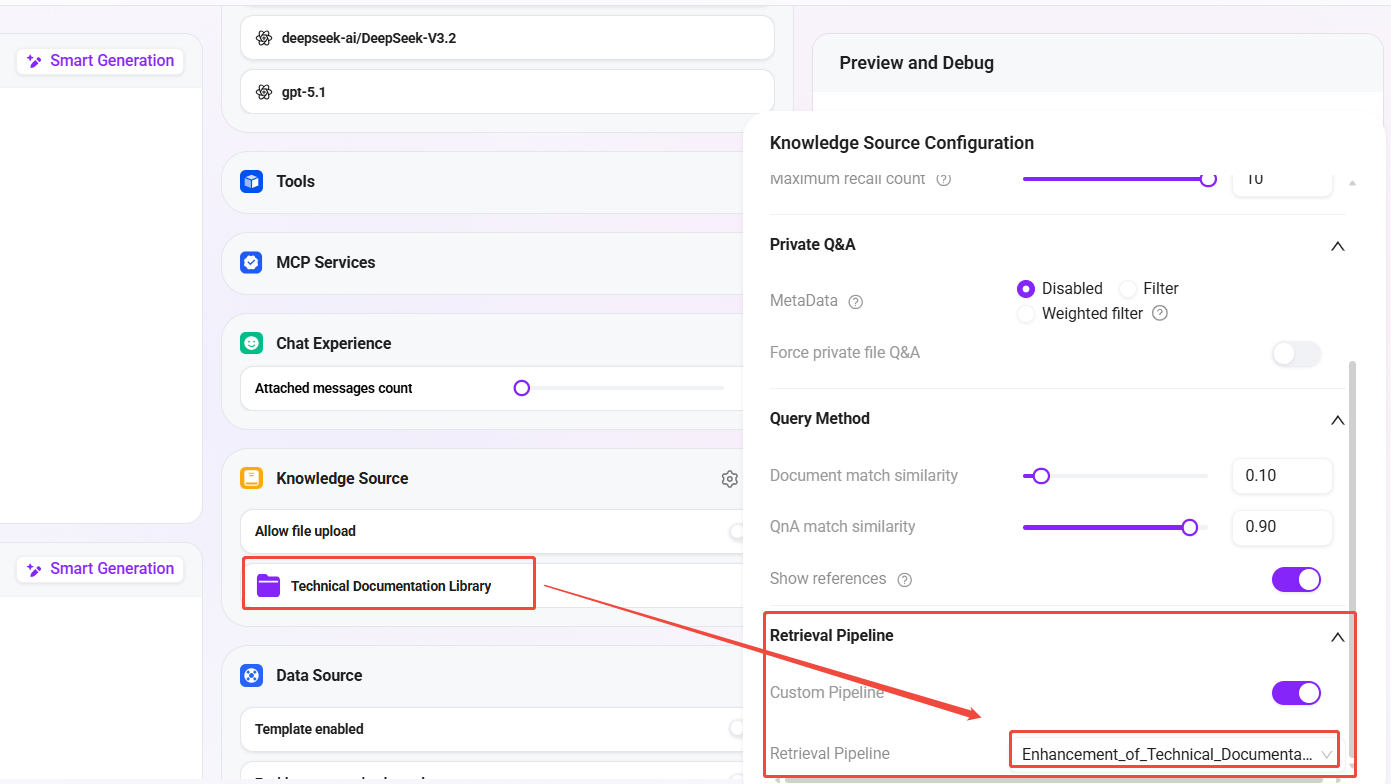
- 在 Agent 的 知识库配置 中:
- 关联知识库:
技术文档库(上一篇创建的知识库) - 检索 Pipeline:选择
技术文档增强检索
- 关联知识库:
- 保存 Agent 配置。
验证智能问答效果
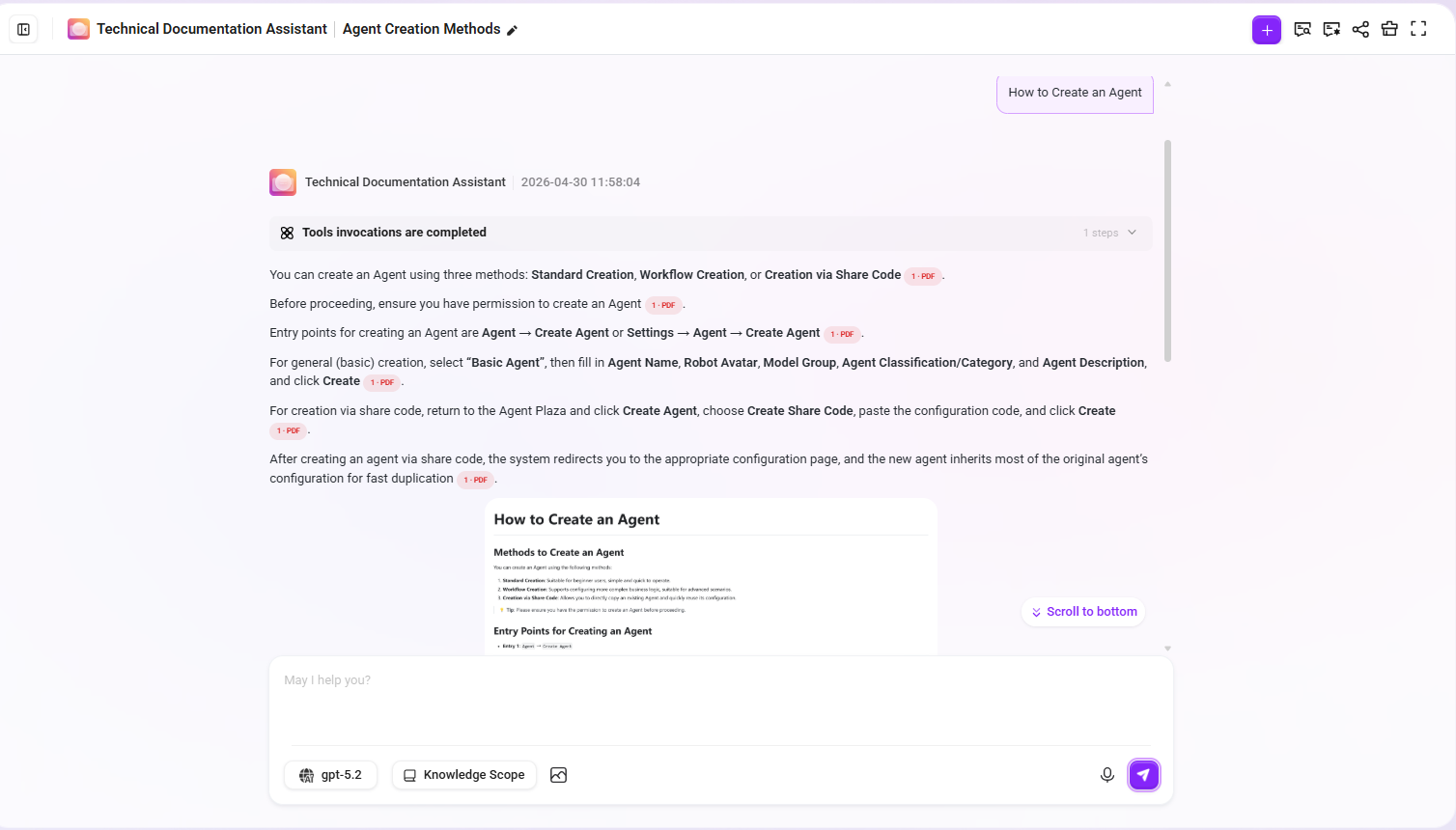
进入 Agent 对话界面,进行以下测试:
提问:如何创建Agent?
预期效果:
- 回答内容来自文档中关于创建Agent的段落
- 引用的片段包含段落原文及摘要增强信息
- 文档中有相关步骤图,其图片也参与召回
效果总结
结合上一篇(预处理 Pipeline + 知识库)和本篇(检索 Pipeline + Agent),我们完成了一个具备深度文档理解能力的端到端智能问答系统:
| 环节 | 配置内容 | 效果 |
|---|---|---|
| 预处理 Pipeline | 文本提取 → 智能分段 → 多维度增强 → 存储 | 文档被充分理解和索引,文字/图片/表格均可检索 |
| 知识库 RAG Pipeline 模式 | 创建知识库时直接绑定预处理 RAG Pipeline | 上传即处理,自动执行全链路预处理 |
| 检索 Pipeline | 查询改写 → 双通道检索 → 多级重排 → LLM 生成 | 理解用户意图,精准召回,智能生成回答 |
| Agent 关联 | 知识库 + 检索 Pipeline 绑定 | 端到端智能问答可用 |
检索 Pipeline 设计亮点
- 查询改写:基于对话历史自动补全指代性问题,提升多轮对话检索精度
- QA 优先 + 文档兜底:双通道策略兼顾回答质量与覆盖率
- 多级重排:RRF 融合排序 + LLM 语义精排,逐步提升 Top-K 质量
- 端到端生成:检索 Pipeline 内置 LLM 生成环节,一条链路完成从检索到回答的全流程
- 引用溯源:Reference filtering 自动标注回答引用的文档片段
进一步优化建议
- 优化查询改写 Prompt:根据业务领域定制改写提示词,提升改写质量
- 调整 RRF 参数:根据实际召回效果调整 RRF 的 k 值参数
- LLM rerank 成本控制:如调用量大,可考虑用轻量 Reranker 模型替代 LLM 精排
- 扩展 QA 知识库:持续补充高频问答对,提升 QA 通道命中率
- 监控检索日志:通过 Pipeline 运行历史定位召回质量问题和响应时间瓶颈