配置预处理 Pipeline 与知识库入库
本教程是"企业技术文档智能问答系统"系列的第一篇,介绍如何通过 RAG Pipeline 的预处理能力,将 PDF 技术文档进行深度解析、多维度增强并入库。
企业内部技术文档(如产品白皮书、API 文档、架构设计文档等)通常包含大量文字、表格和流程图。本篇将带你完成文档预处理 Pipeline 的编排与知识库创建,为后续检索问答打好数据基础。
💡 提示:本教程需要 SERVICEME V4.2 及以上版本,且操作用户需具备管理员权限。
场景说明
业务背景
某科技公司拥有一套核心产品的技术文档(PDF 格式,约 80 页),文档内容包含:
- 大量文字段落:功能说明、技术原理、配置指南等
- 数据表格:参数对照表、兼容性矩阵、性能指标等
- 流程图与架构图:系统架构、数据流转、部署拓扑等
公司希望构建智能问答系统,让工程师和产品经理能快速获取文档中的信息,且:
- 对纯文字内容能精准召回相关段落
- 对表格内容能理解表格结构并给出结构化回答
- 对图片/流程图能基于图片描述进行语义检索
- 支持全文检索与向量检索双通道,提升召回率
实现方案概览
本案例使用的预处理 Pipeline 包含以下核心环节:
| 阶段 | 节点 | 说明 |
|---|---|---|
| 文本提取 | PDF File Text | 从 PDF 提取原始文本与页面结构 |
| 智能分段 | Page Segmentation | 按页面内容智能切分为语义段落 |
| 摘要增强 | Segment Summary Generation | LLM 为每个段落生成摘要,增强检索语义 |
| 图片理解 | Image Description Generation | LLM 为文档中的图片生成文字描述 |
| 表格理解 | Table Advanced Summary Gen. | LLM 为表格生成结构化摘要 |
| 数据聚合 | Variable Aggregator | 合并多维度增强数据 |
| 文档摘要 | Document Summary Generation | 生成整篇文档的全局摘要 |
| 分词索引 | Spacy Tokenizer | 对段落进行分词,支持全文检索 |
| 持久化存储 | 多个存储节点 | 分别存储原始文本、段落、增强数据、分词和向量 |
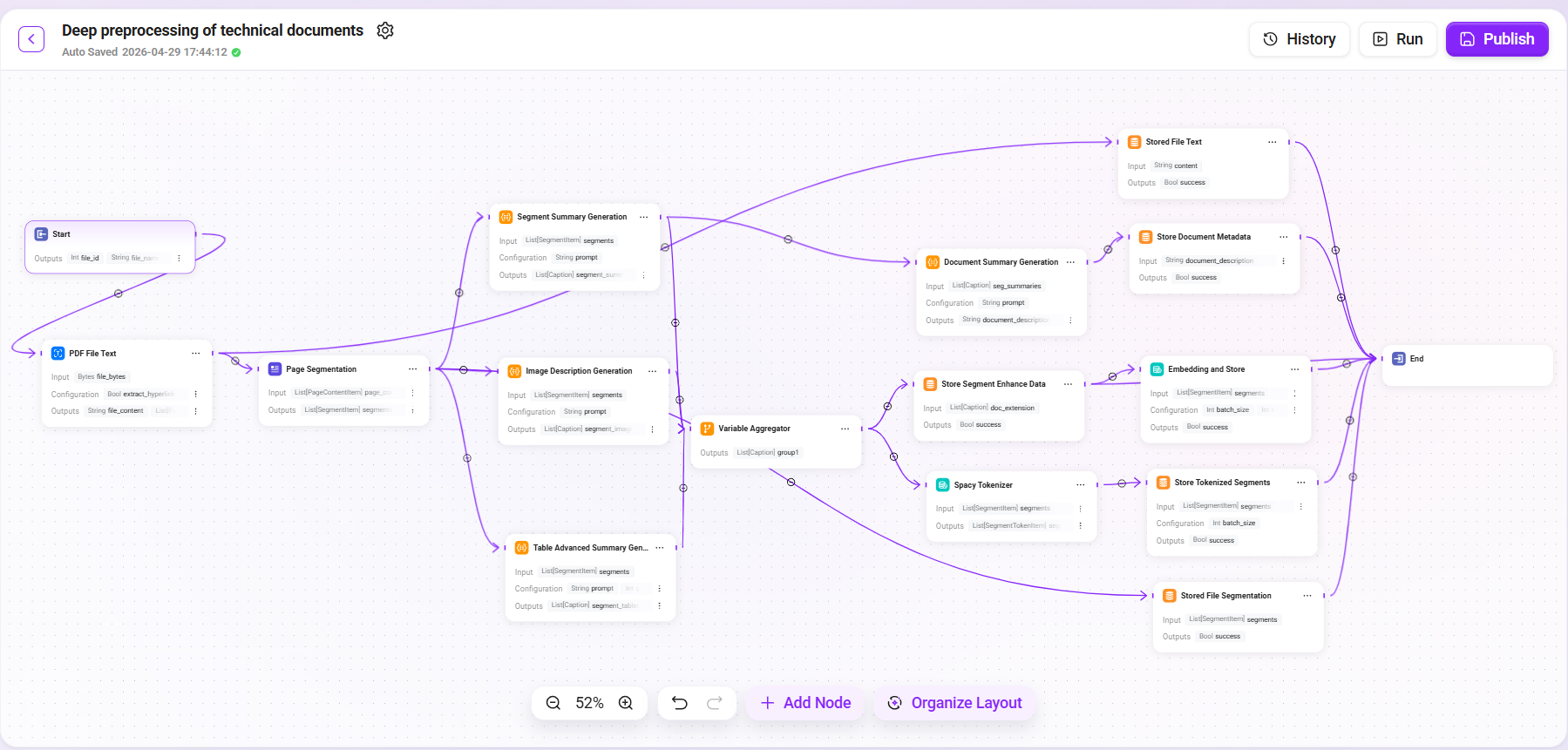
第一步:配置预处理 Pipeline
预处理 Pipeline 决定了文档如何被解析、理解和存储,直接影响后续检索质量。本案例将构建一条多分支并行处理的 Pipeline,充分挖掘文档中的文字、图片和表格信息。
文件准备要求
- 技术文档:PDF 格式,如
技术白皮书_v2.1.pdf - 文档中应包含标题结构、表格和图片,以充分发挥 Pipeline 各节点能力
- 建议文件大小不超过 50MB,页数不超过 200 页
创建预处理 Pipeline
- 进入 Knowledge 模块 → 左侧菜单栏点击 "RAG Pipeline"。
- 切换到 "预处理 Pipeline" 页签。
- 点击 "+ 创建 Pipeline",填写:
- 名称:
技术文档深度预处理 - 描述:
多维度增强处理技术文档,含摘要、图片描述、表格解析、分词与向量化
- 名称:
- 点击 "确认" 进入编排界面。
编排预处理流程
在编排界面中,按以下架构添加节点并连线。本 Pipeline 采用先提取后分支并行的设计模式:
1. PDF 文件文本提取
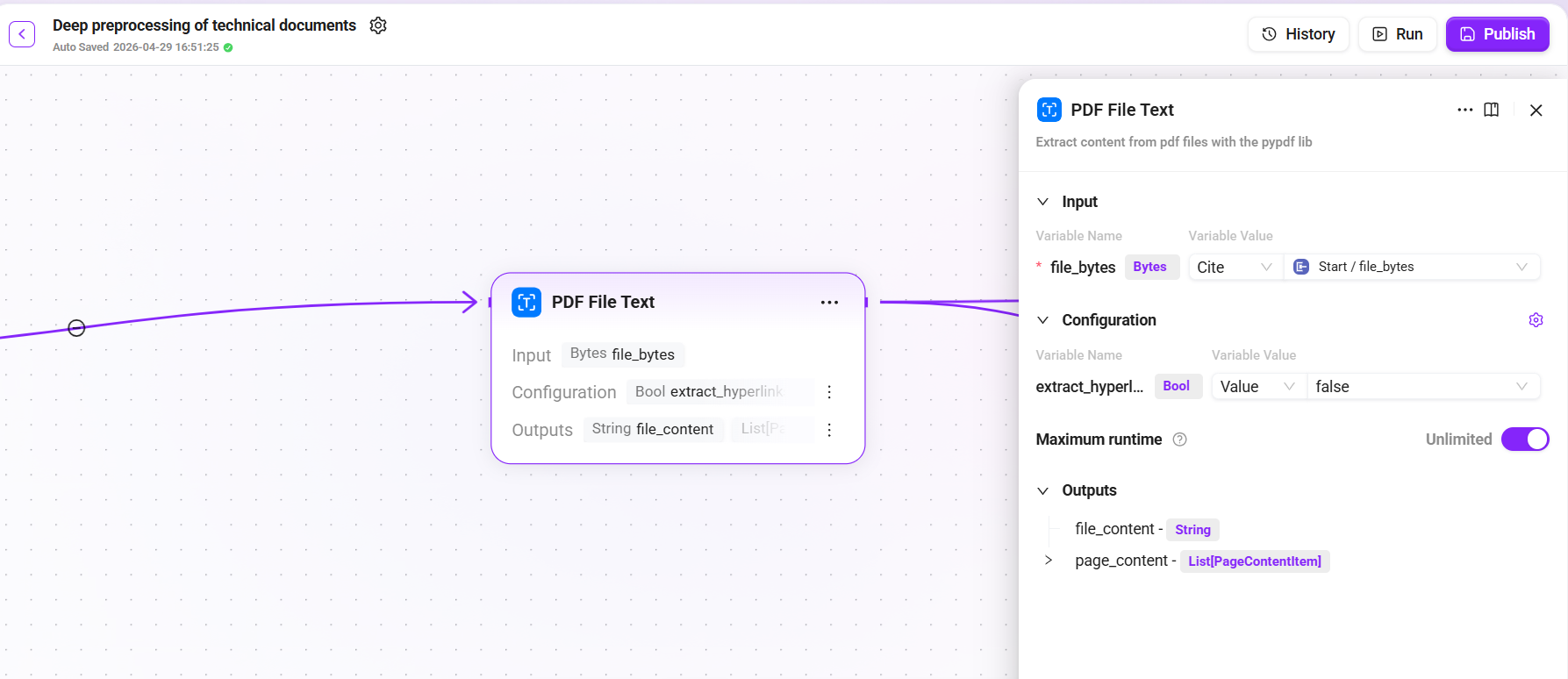
添加 "PDF File Text" 节点作为流程入口:
- 输入:
file_bytes(上传的 PDF 文件字节流) - 配置:
extract_hyperlinks设为true(提取超链接信息) - 输出:
file_content(提取的文本内容)与页面内容列表
该节点将 PDF 中的文字、图片占位、表格结构等信息提取为可处理的结构化数据。
2. 页面分段(Page Segmentation)
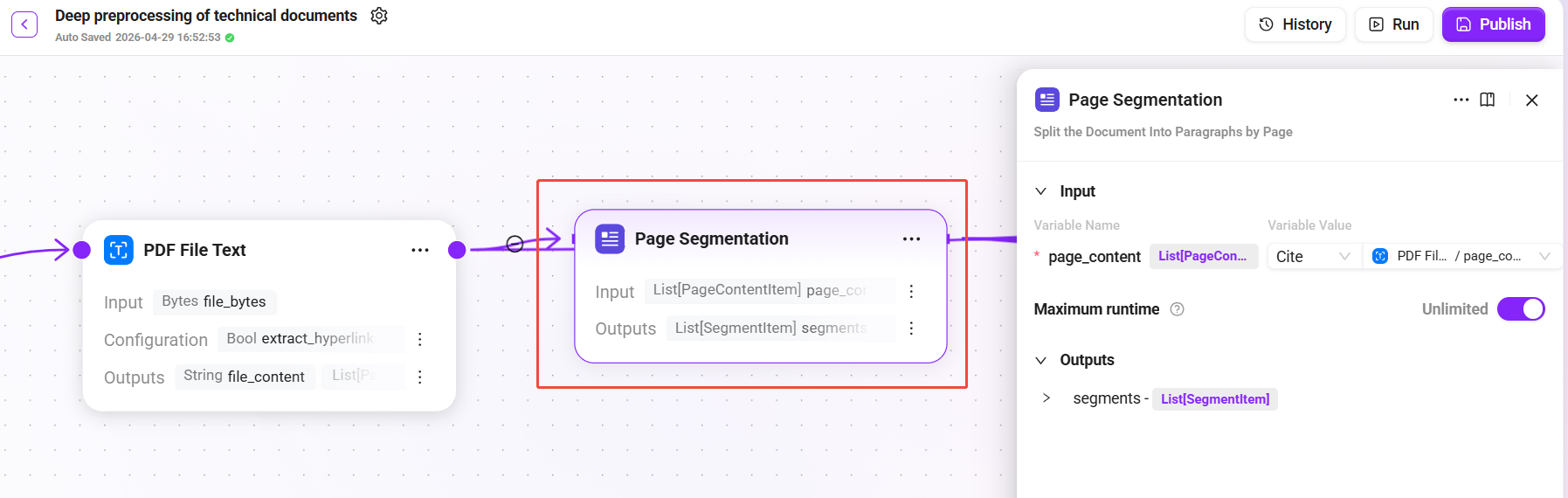
添加 "Page Segmentation" 节点:
- 输入:上一步输出的页面内容列表
page_content_items - 输出:
segments(语义段落列表)
系统会基于页面布局和内容结构,将文档智能切分为独立的语义段落。每个段落保持上下文完整性,避免跨主题切割。
3. 多维度摘要增强(并行分支)
页面分段完成后,Pipeline 分为三条并行分支,分别处理不同类型的内容:
分支 A:段落摘要生成(Segment Summary Generation)
- 输入:
segments - 配置:
prompt(摘要提示词,可自定义) - 输出:
segment_summaries(每个段落的摘要)和sensitive_segments(识别出的敏感段落列表,用于合规审查或过滤)
通过 LLM 为每个文本段落生成简洁摘要,增强检索时的语义匹配能力。即使用户提问用词与原文不同,摘要也能提供额外的语义桥梁。
分支 B:图片描述生成(Image Description Generation)
- 输入:
segments(包含图片引用的段落) - 配置:
prompt(图片描述提示词) - 输出:
segment_images(图片的文字描述)
LLM 会基于多模态能力分析文档中的图片(如架构图、流程图、截图),生成结构化的文字描述。这使得图片内容也能参与语义检索。
分支 C:表格高级摘要生成(Table Advanced Summary Generation)
- 输入:
segments(包含表格的段落) - 配置:
prompt:表格摘要提示词group_size:分组大小max_columns:最大列数sample_rows:抽样行数group_summary_prompt:分组摘要合并时的提示词large_table_threshold:判定为大表的最小行列阈值small_table_threshold:判定为小表的最大行列阈值
- 输出:
segment_tables(表格的结构化摘要)
对文档中的表格内容进行深度解析,生成易于理解和检索的文字摘要。例如将参数对照表转化为"该表列出了 X 功能支持的 Y 个参数及其默认值"等描述。
4. 数据聚合(Variable Aggregator)
添加 "Variable Aggregator" 节点:
- 输入:三条分支的输出:
segment_summaries(段落摘要)、segment_images(图片描述)、segment_tables(表格摘要) - 输出:
group1(聚合后的增强数据)
将段落摘要、图片描述、表格摘要合并为统一的数据结构,供后续节点使用。
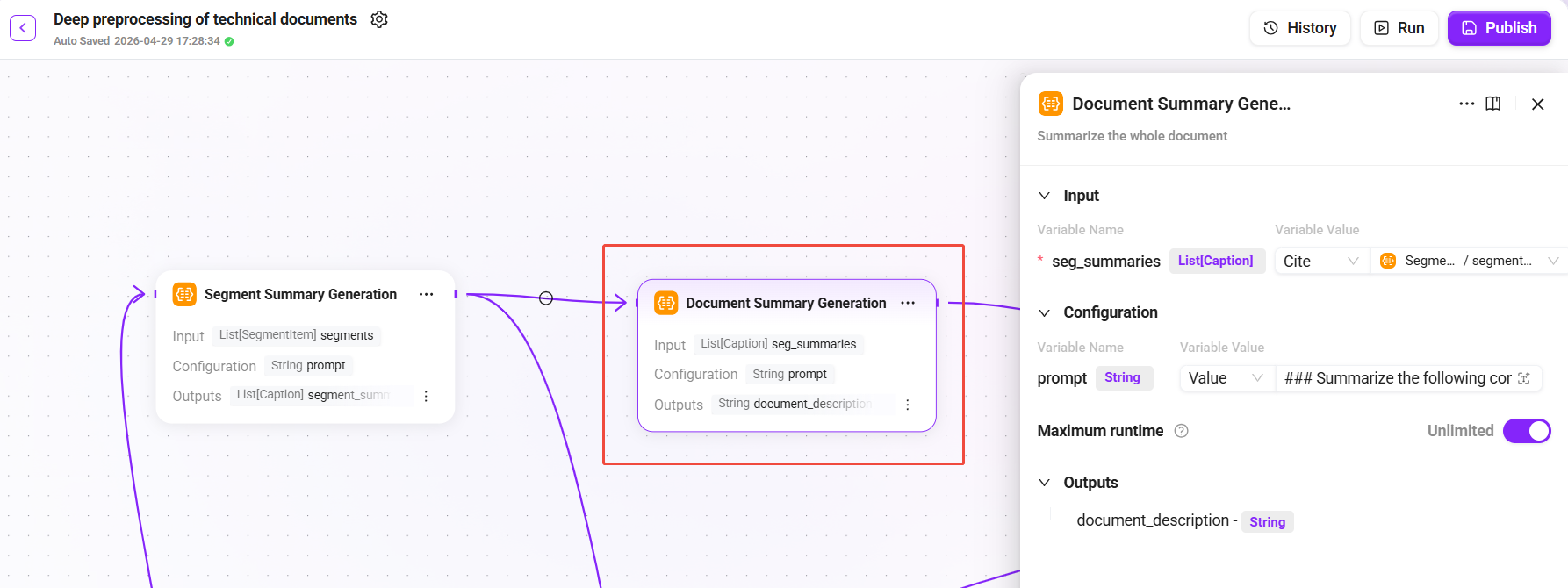
5. 文档级摘要生成(Document Summary Generation)
添加 "Document Summary Generation" 节点:
- 输入:
seg_summaries(来自“段落摘要生成”节点的所有段落摘要列表) - 配置:
prompt(文档摘要提示词) - 输出:
document_description(整篇文档的全局摘要)
基于所有段落摘要生成文档级别的总结描述,用于文档元数据存储和粗粒度检索。
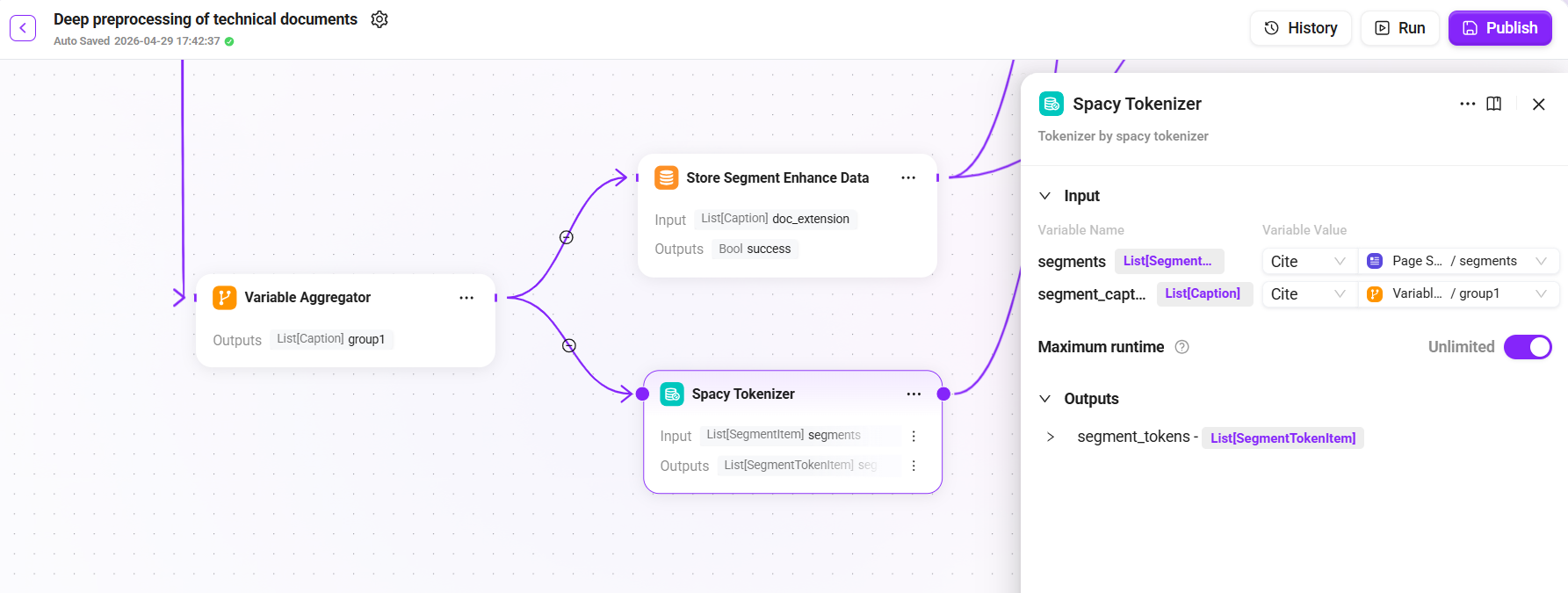
6. 分词处理(Spacy Tokenizer)
添加 "Spacy Tokenizer" 节点(与存储段落增强数据并行):
- 输入:
group1(聚合后的段落数据)及原始页面分段的segments(用于补充原始信息) - 输出:分词后的
segments_tokenized
使用 Spacy 对段落进行分词处理,生成倒排索引所需的 Token 序列,支撑全文检索能力。
7. 持久化存储(多个存储节点)
Pipeline 末端包含以下存储节点,将各类处理结果持久化:
| 存储节点 | 输入 | 说明 |
|---|---|---|
| Stored File Text | content | 存储原始文档的完整文本 |
| Store Document Metadata | document_description | 存储文档级摘要作为元数据 |
| Store Segment Enhance Data | doc_extension | 存储段落的增强数据(摘要、图片描述、表格摘要) |
| Embedding and Store | segments、batch_size、rehire_size | 对段落进行向量化(Embedding)并存入向量数据库 |
| Store Tokenized Segments | segments、batch_size | 存储分词结果,支持全文检索 |
| Stored File Segmentation | segments | 存储原始分段结果 |
所有存储节点完成后,流程汇聚到 End 节点,Pipeline 执行结束。
完整流程连线示意
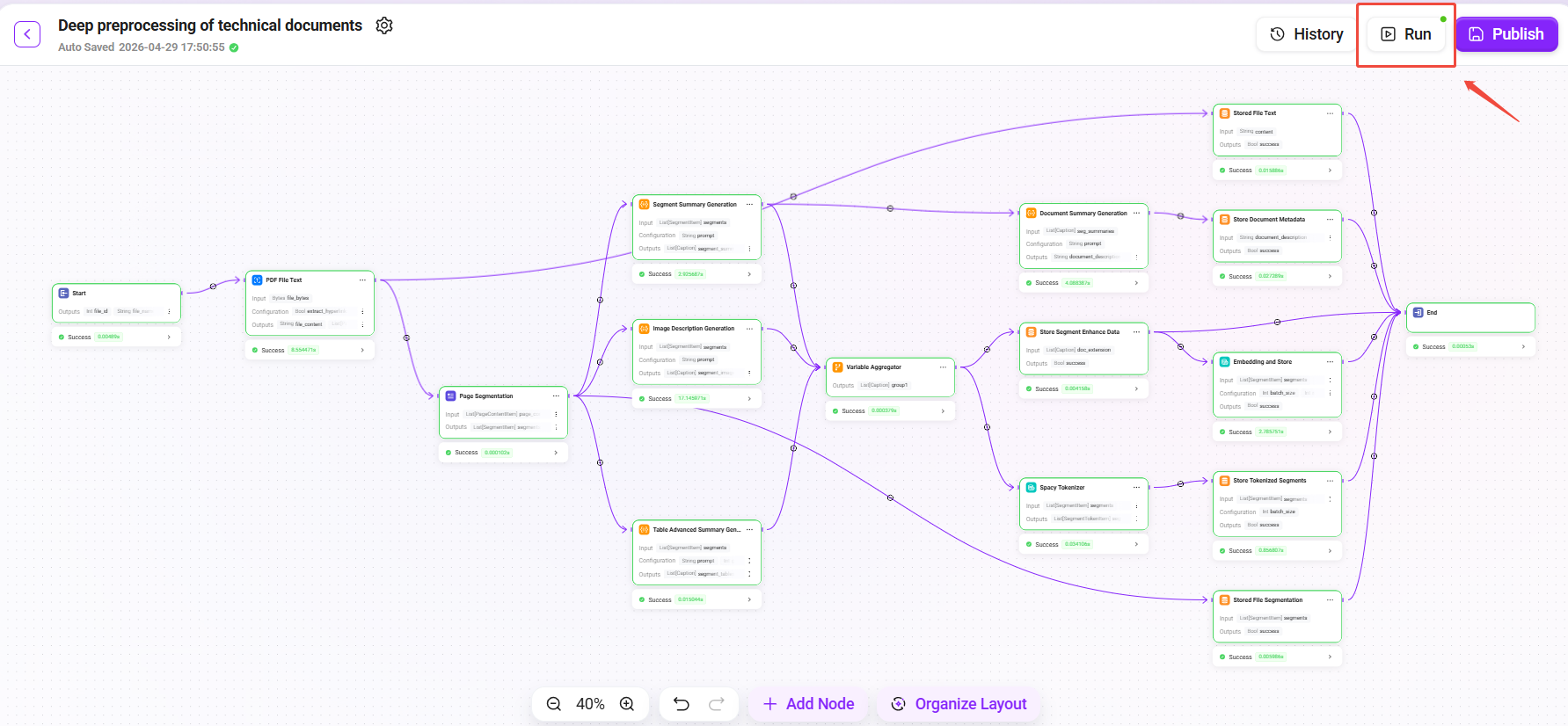
试运行并发布
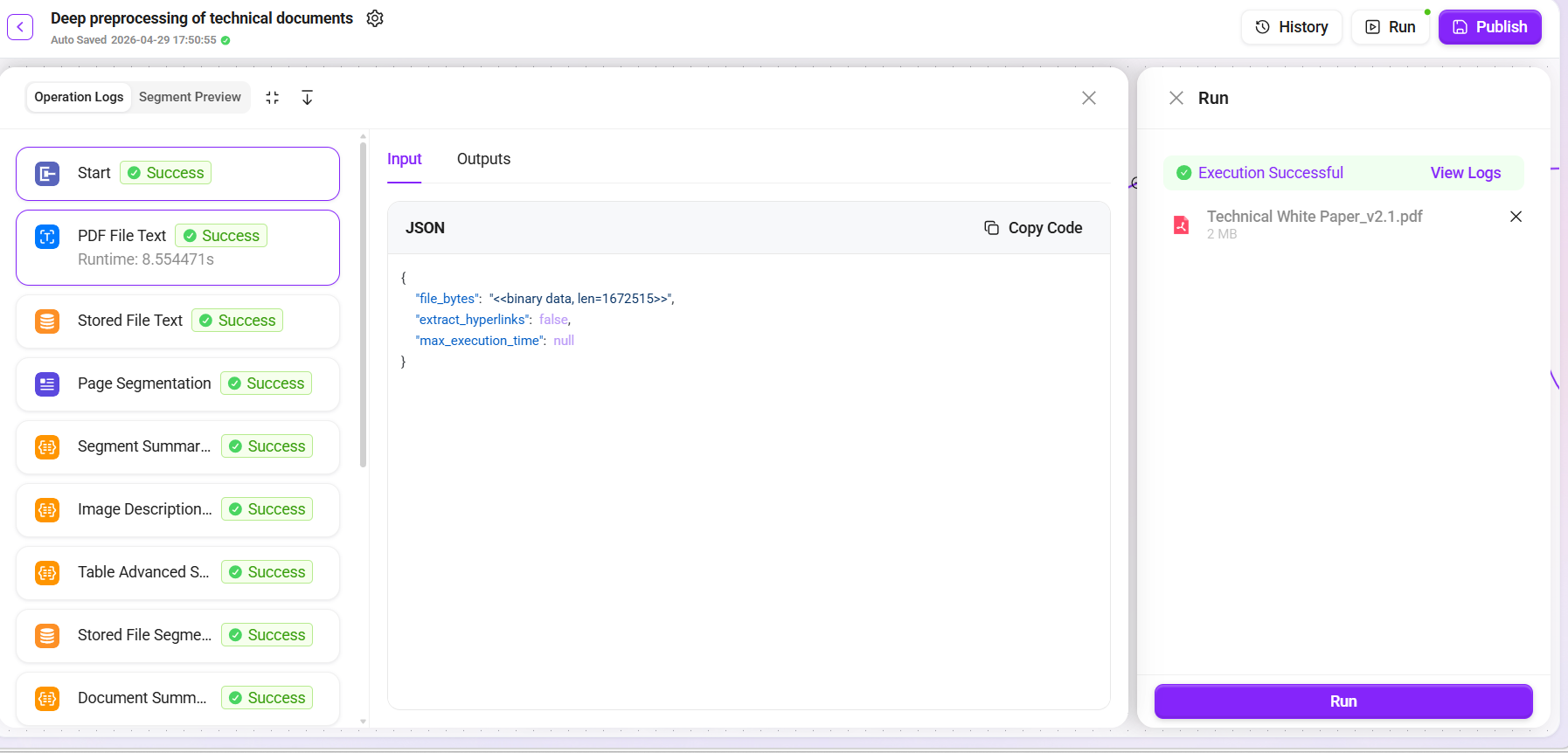
- 点击右上角 "试运行" 按钮。
- 选择准备好的
技术白皮书_v2.1.pdf作为测试文件。 - 查看运行结果,逐一验证:
- ✅ 文本提取:确认 PDF 内容完整提取,无乱码
- ✅ 页面分段:确认段落切分合理,无跨主题混切
- ✅ 段落摘要:确认摘要能准确概括段落核心内容
- ✅ 图片描述:确认图片描述与实际图片内容一致
- ✅ 表格摘要:确认表格数据被正确解读
- ✅ 向量化存储:确认 Embedding 生成成功
- 确认试运行结果无误后,点击 "发布"。
注意:为保证测试运行效率,建议先用不超过5MB、20页以内的小样本文件测试运行逻辑。
第二步:创建知识库并选择 RP 模式上传文档
完成预处理 Pipeline 配置后,接下来创建知识库,并在知识库中启用 RP 模式,让文档入库时自动按已发布的预处理 Pipeline 执行。
创建知识库并绑定预处理 RP
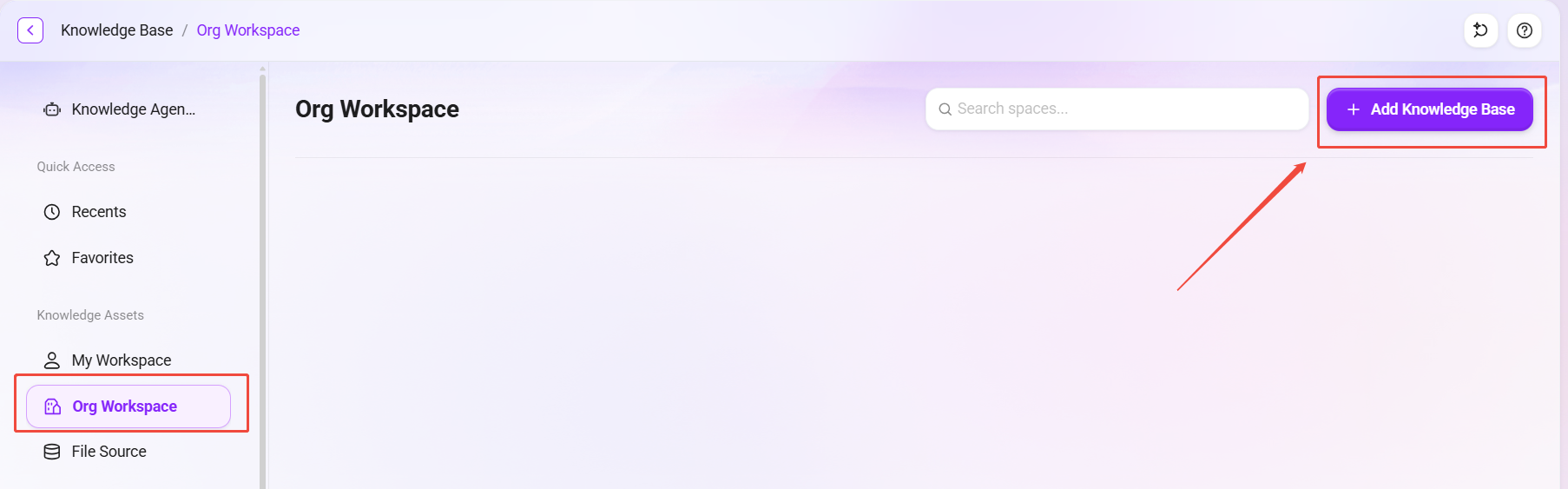
- 进入系统的 Knowledge 模块。
- 点击左侧菜单栏中的 "企业空间",进入知识库管理界面。
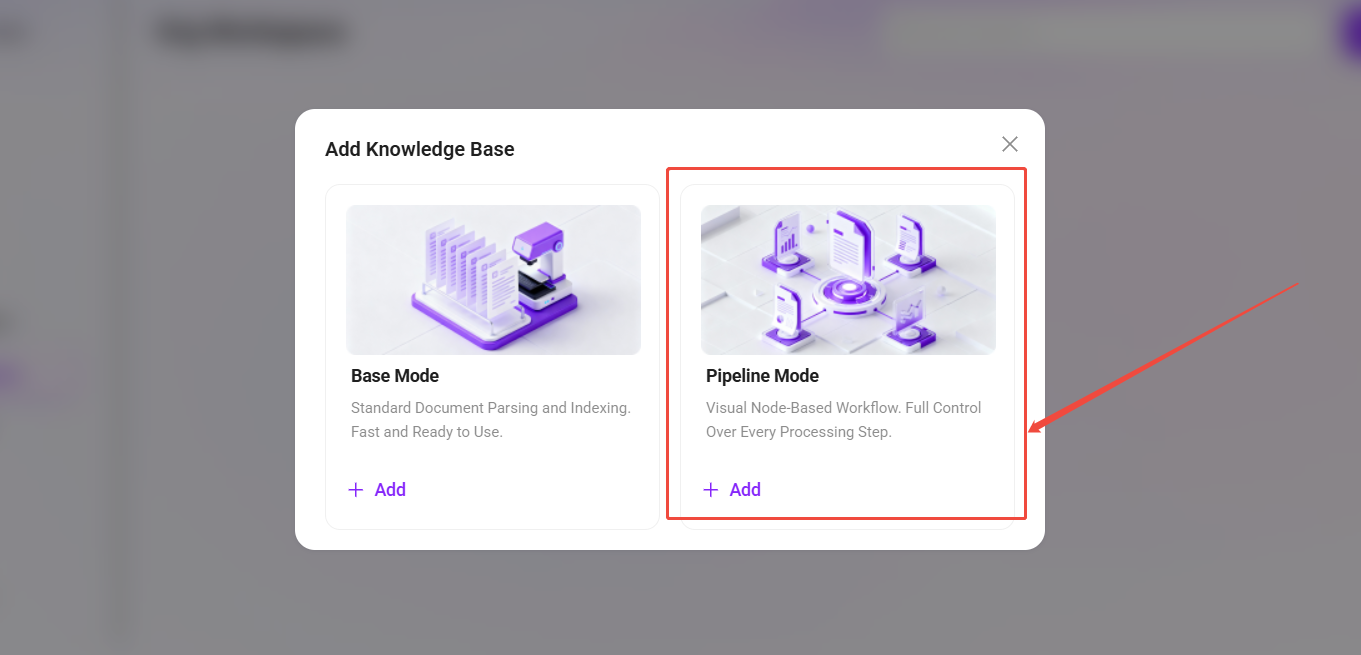
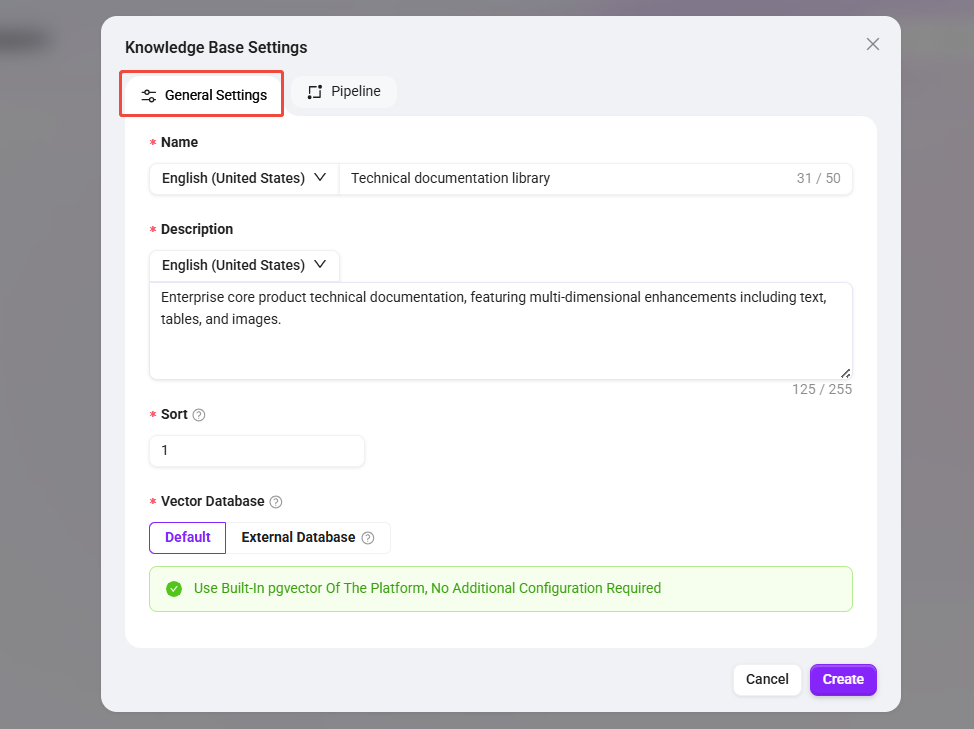
- 点击 "+ 创建知识库",选择“Pipeline Mode”模式,填写以下基础信息:
- 知识库名称:
技术文档库 - 知识库描述:
企业核心产品技术文档,含文字、表格、图片多维度增强 - 排序:
1 - 向量数据库:保持默认,使用平台内置的
pgvector - 向量模型:选择平台默认的
AzureEmbedding模型,用于生成段落与查询的向量表示
- 知识库名称:
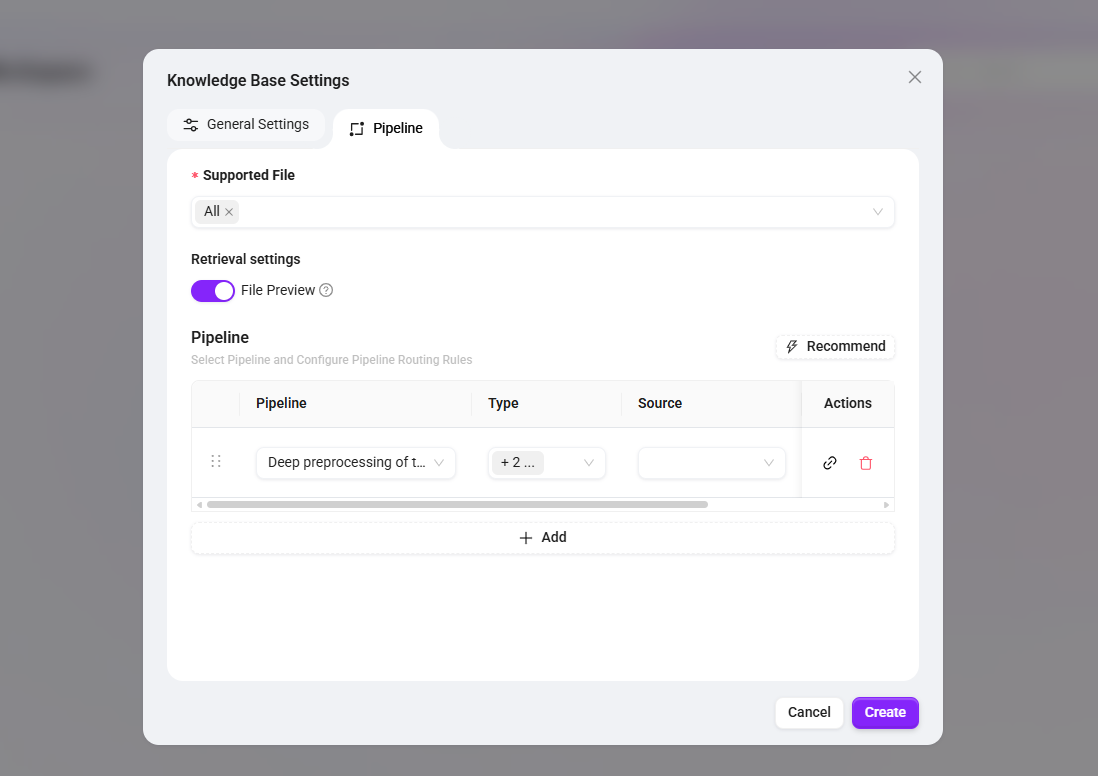
- 在 Pipeline 配置页中,,关联已发布的预处理 Pipeline Mode:
- 文件支持格式:勾选“全部”,以便后续能处理多种格式的文档
- 检索设置:开启“文件预览”功能,允许在检索结果中直接预览原文片段
- Pipeline选择:选择已发布的
技术文档深度预处理,并将文件类型指定为PDF(如需支持其他格式,可添加对应类型的 Pipeline )
- 确认配置无误后,点击 “创建”,完成知识库的建立与 RP 模式的绑定。
创建完成后,当用户向该知识库上传PDF格式的文件时,系统会自动调用“技术文档深度预处理”对PDF文件进行文本提取、分段、多维度摘要增强、分词及向量化等一系列处理。
上传技术文档
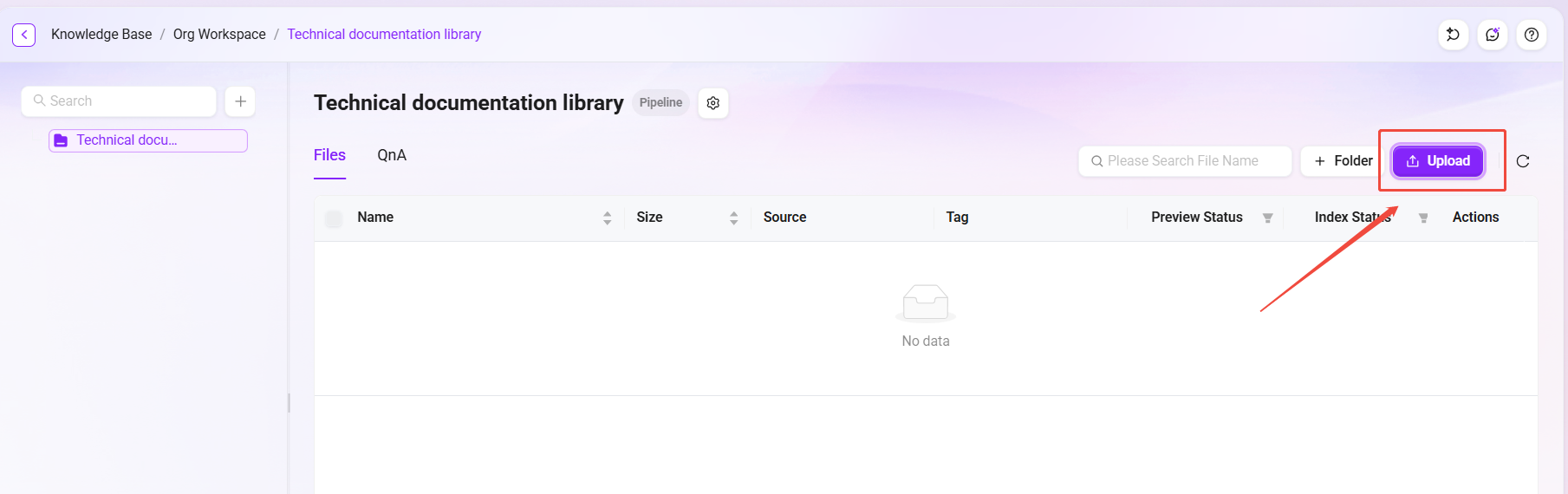
- 进入刚创建的知识库
技术文档库。 - 点击 "上传文件",上传
技术白皮书_v2.1.pdf。 - 系统将按 RP 模式自动调用
技术文档深度预处理Pipeline 对文档进行全链路处理。 - 上传完成后,可在文件列表中查看处理状态和进度。
💡 由于本 Pipeline 包含多个 LLM 调用节点(摘要生成、图片描述、表格解析),处理时间会比简单 Pipeline 更长,请耐心等待。
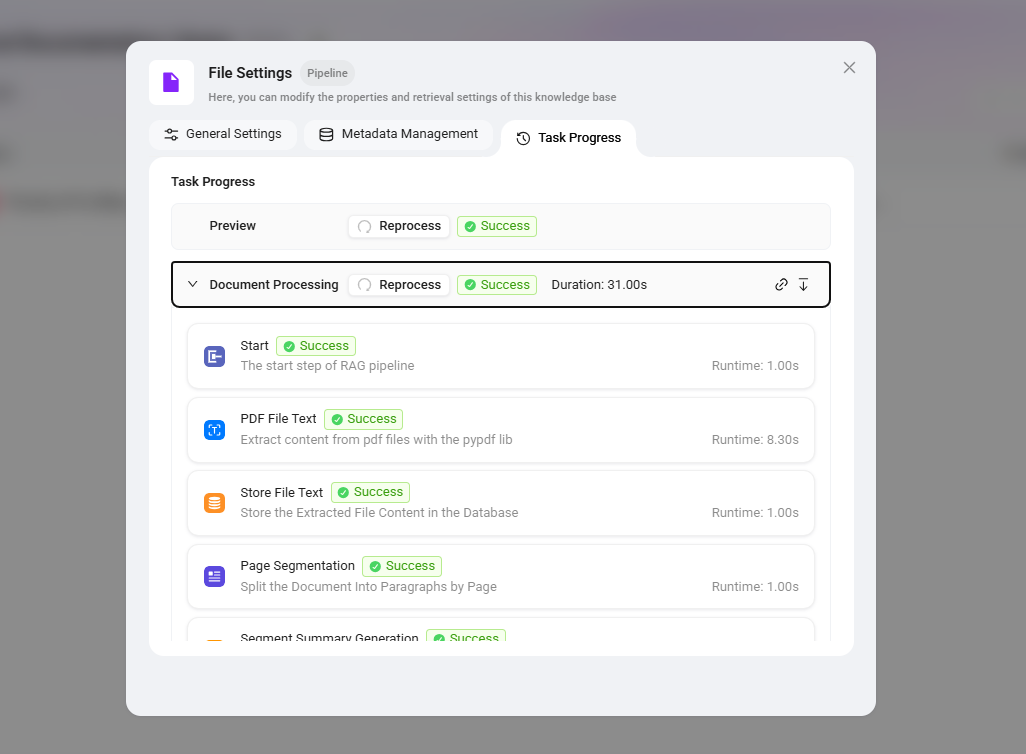
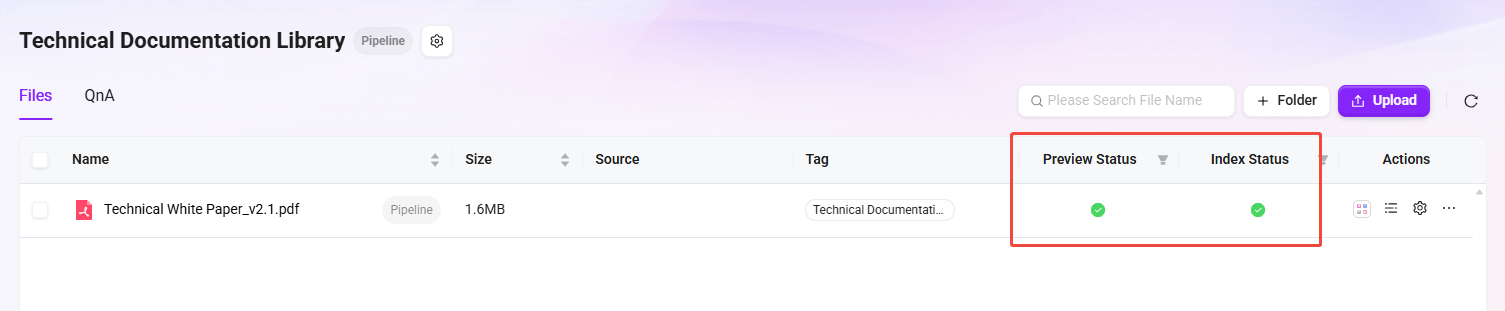
验证知识库入库结果
- 进入知识库文档详情页面。
- 验证以下内容:
- ✅ 文档片段列表正确展示
- ✅ 每个片段包含增强数据(摘要、图片描述等)
- ✅ 文档元数据中包含全局摘要描述
- ✅ 向量数据与分词索引均已生成
下一步
预处理 Pipeline 和知识库已就绪,接下来请阅读 配置检索 Pipeline 与 Agent 问答,完成检索链路编排和端到端问答验证。