创建助手
创建助手的方式
您可通过以下方式创建助手:
- 常规创建:适合新手用户,操作简单快捷。
- 工作流创建:支持配置更复杂的业务逻辑,适用于进阶使用场景。
- 分享码创建:可直接复制已有助手,快速复用配置。
💡 提示:创建前请确保您具有创建助手的权限。
创建助手的入口(两种快捷入口均可用)
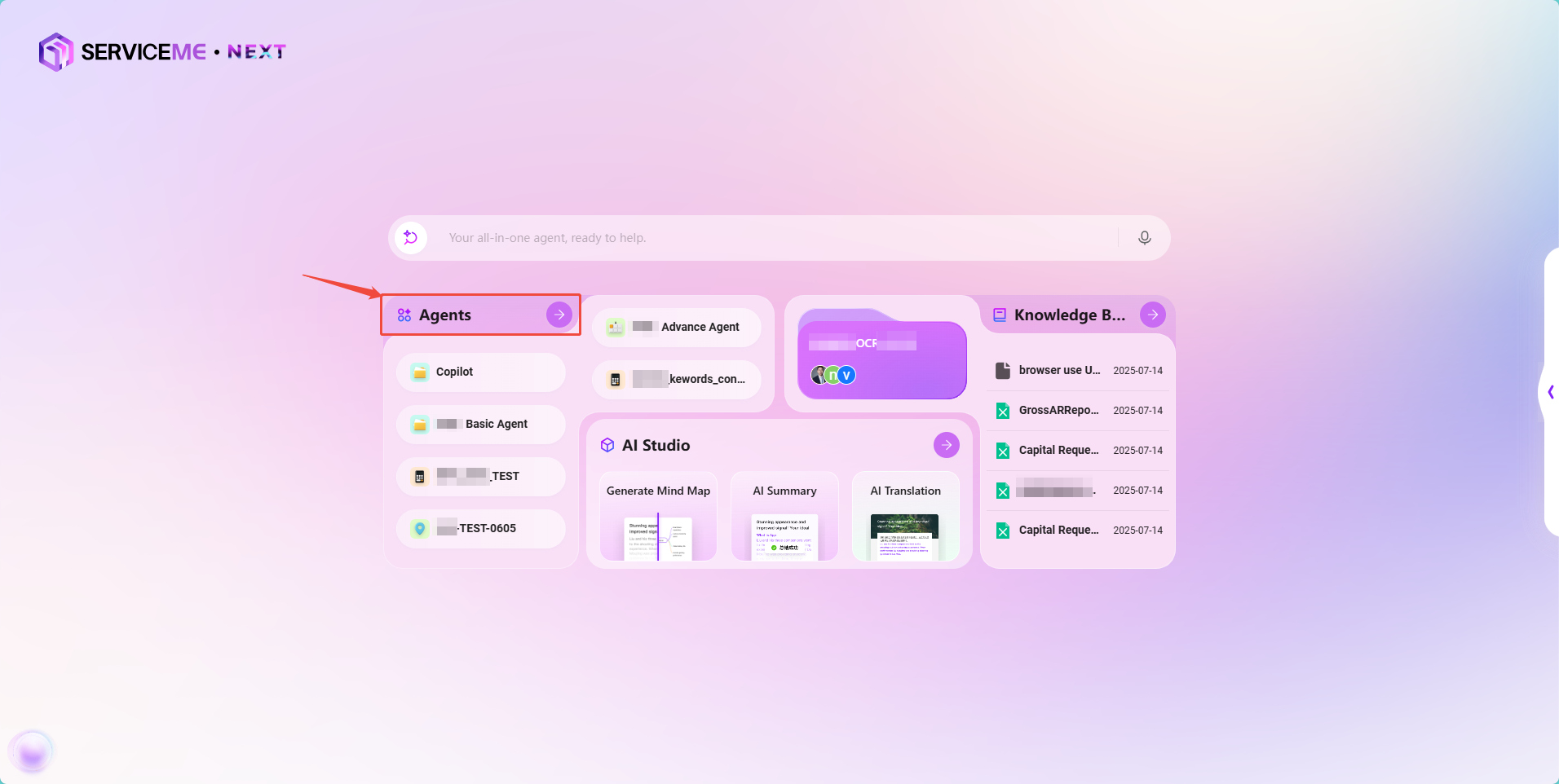
- 入口1:
智能体→创建智能体
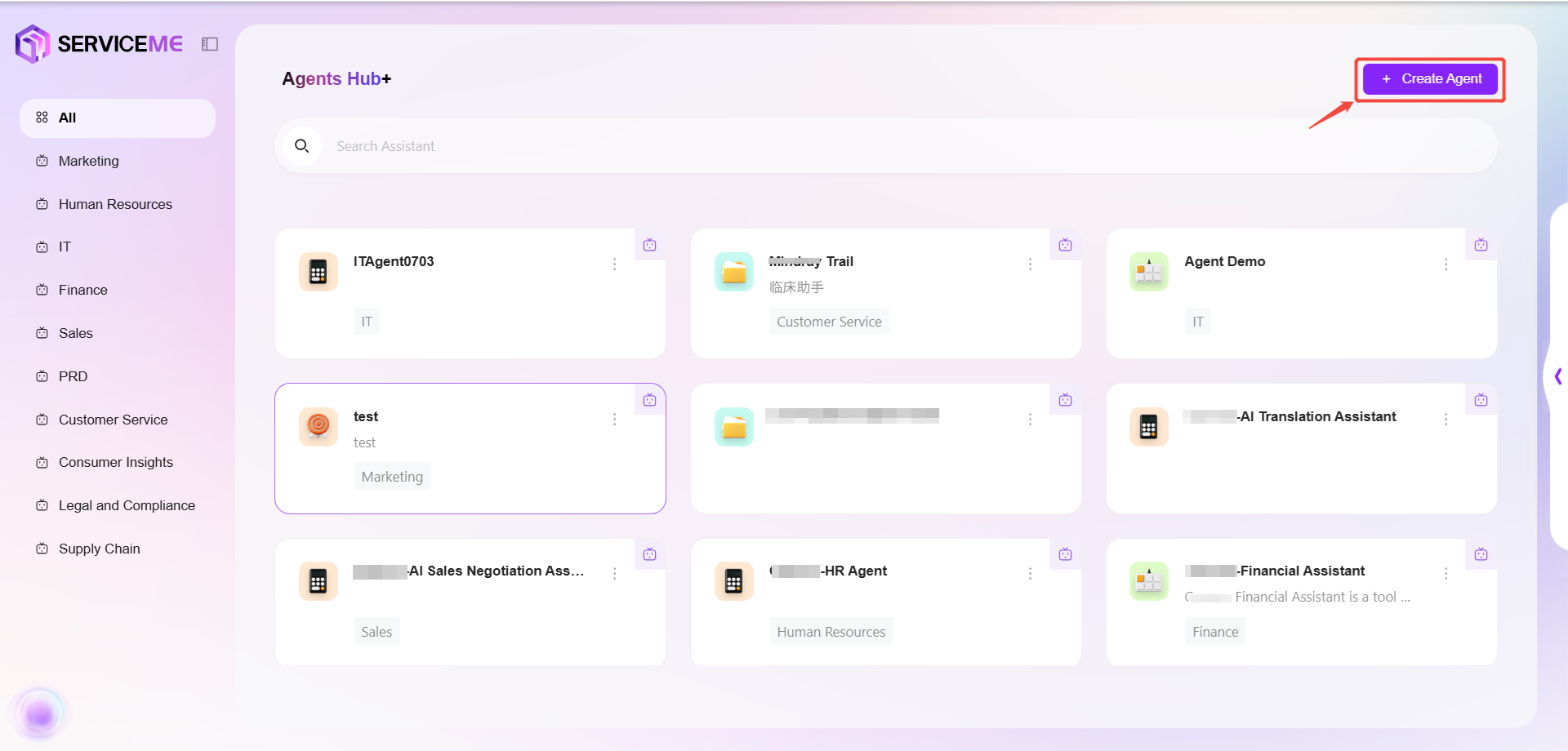
- 入口2:
设置→助手&Agent管理→创建智能体

常规创建-基本智能体
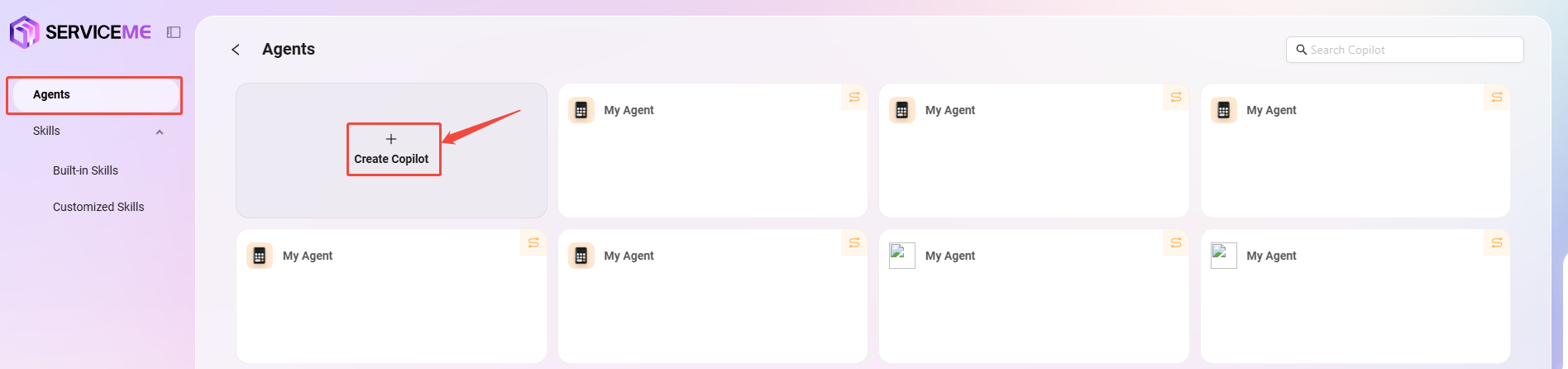
1. 选择“基本智能体”
2. 创建步骤
- 从创建助手的入口点击“创建助手”后,选择“基础编排创建”
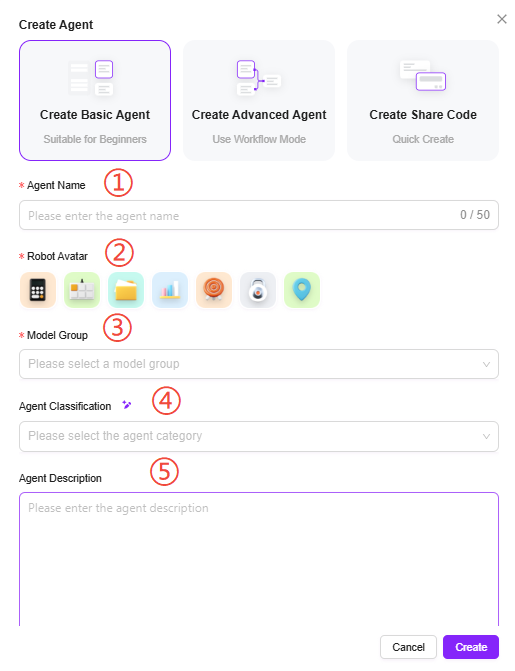
- 输入助手名称、选择助手头像、选择模型组、选择助手分类、添加助手描述:
① 助手名称:输入助手的名称,作为助手标识。
② 助手头像:选择助手默认头像,目前不支持上传头像。
③ 模型组:为助手配置合适的模型组。
④ 助手描述:输入简要描述,说明助手的功能和用途。
⑤ 助手分类:选择新建助手所在的组,可多选。 - 点击“创建”,助手创建后进入基础编排助手配置页面,配置并发布后可投入使用。
3. 助手配置
助手配置进入方式有两种:
- 创建助手后直接进入助手配置页面
- 点击助手名称右侧“...”选择“配置”
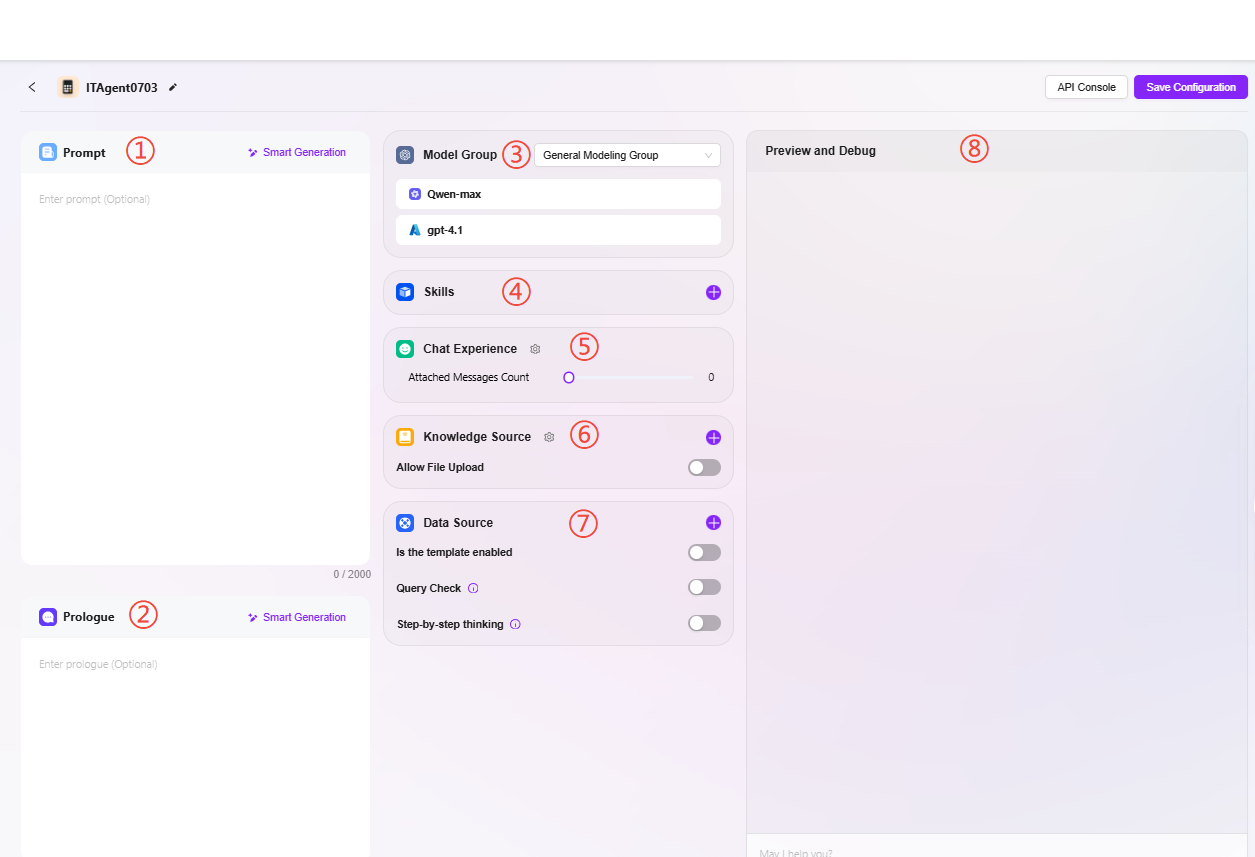
① 提示词:输入助手提示词,也支持将现有提示词进行智能生成,提示词限制字数2000字
② 开场白:输入助手开场白,也支持根据提示词或已有开场白进行智能生成,开场白限制字数2000字
③ 模型组:点击“+”添加模型组,支持多种可选模型
备注:模型组首先需要管理员在系统管理中进行添加模型组,将多个不同的模型添加到同一个模型组中,再将模型组配置到助手中。

添加模型组
-
路径:设置 → 系统管理 → 模型管理 → 模型组 → 新建模型组(仅管理员可添加模型)
-
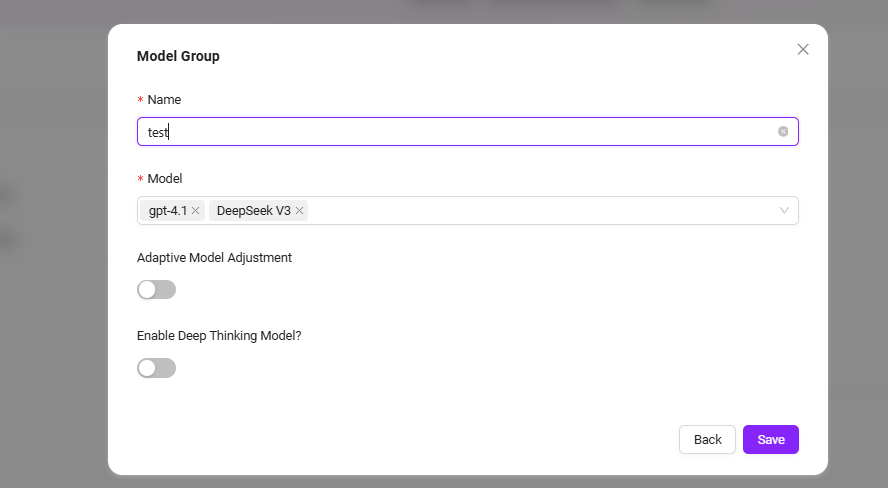
添加步骤:
- 点击“新建模型组”
- 完成以下配置:
- 输入模型组名称
- 选择要加入模型组的模型,可选择多个
- 选择是否开启自适应模型部署
- 选择是否启用深度思考模型
- 点击“保存”
④ 技能:点击“+”添加一种或多种技能,也可以添加推荐技能
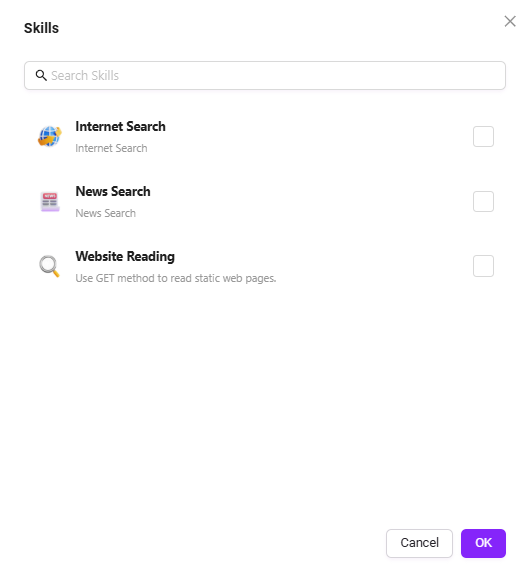
默认技能有 4 个:联网搜索、文生图、新闻查询工具、网页读取。
- 联网搜索:连接互联网,检索网络公开内容(如资讯、资料等)的功能。
- 文生图:通过输入的文本内容,生成对应主题图片的功能。
- 新闻查询工具:用于搜索、获取各类新闻资讯的专用工具。
- 网页读取:提取网页文本、数据等内容,解析网页信息的功能。
支持追加其他技能,需管理员进行操作与配置。
⑤ 对话体验:
-
对话设置:可以开启“用户问题建议、问题引导、聊天记录、对话反馈、关键词审查”等设置
- 用户问题建议:在助手回答后,根据前文为用户提供一些问题建议。
- 问题引导:在用户与助手对话时,会有相关的问题引导,利用模型能力推测用户可能提问的问题以及对用户问题的补全。
- 聊天记录:是否留存助手的聊天记录,关闭后,将无法查到助手的聊天记录。
- 对话反馈:对助手的回答可以进行点赞、点踩等交互操作,用于优化助手回答。
- 开启关键词审查:审查输入内容和审查输出内容至少启用一项。开通后将对提示词或 AI 反馈结果都进行敏感词检测,敏感词可提前进行维护,以下是维护页面。
⑥ 知识库:
-
知识库:点击“+”添加知识库
-
知识库配置:可以修改知识库的“检索策略、私域问答、检索方式”等详细设置
- 是否允许文件上传:
1)打开允许文件上传后,无法再添加知识库的内容作为知识来源
2)关闭允许文件上传后,可以选择性添加个人空间或企业空间的知识库作为知识来源

- 知识库配置:
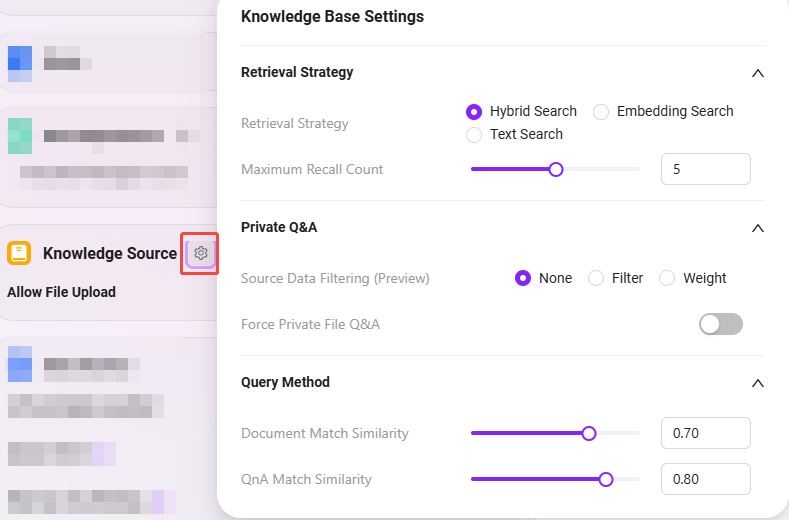
1)检索策略:混合搜索、嵌入搜索、文本搜索
- 混合检索:综合向量检索和全文检索的查询结果,返回重排后的结果
- 嵌入检索:通过相似性进行片段查找,有一定的跨语言泛化能力
- 文本检索:通过关键字进行片段查找,适用于含有特定关键字、名词片段的检索
2)最大召回数量:范围 1–8,不建议设置过高或过低,建议值为 3–5
3)元数据过滤:无、过滤、权重
4)强制私域文件问答:打开后不会使用联网搜索等技能,助手的回答只针对知识库内容
5)文档匹配近似度:范围 0–1,匹配近似度越高,说明召回文档内容越相似,建议值约为 0.8(即 80%)
6)QnA 匹配近似度:范围 0–1,类似于文档内容的近似度匹配,建议值约为 0.9(即 90%)
7)显示参考文献:打开后,助手在回答时会列出所参考的文献,提高回答可信度
- 是否允许文件上传:
💡 提示:不论是最大召回数量、文档匹配近似度,还是 QnA 匹配近似度,都不是越高越好或越低越好,建议根据实际需求进行设置。如无特殊需求,建议保持默认值。
⑦ 数据来源:点击“+”添加数据源,作为助手问答数据来源
助手数据来源可匹配已接入的数据源,将其作为助手可参考的数据来源。
添加助手数据来源步骤较为简单:点击数据来源右侧“+”,选择数据源,点击“确定”即可。
⑧ 助手预览与调试:界面右侧可预览测试助手,测试无误后保存配置
工作流创建-高级智能体
- 选择“高级智能体”(创建步骤同创建普通智能体)
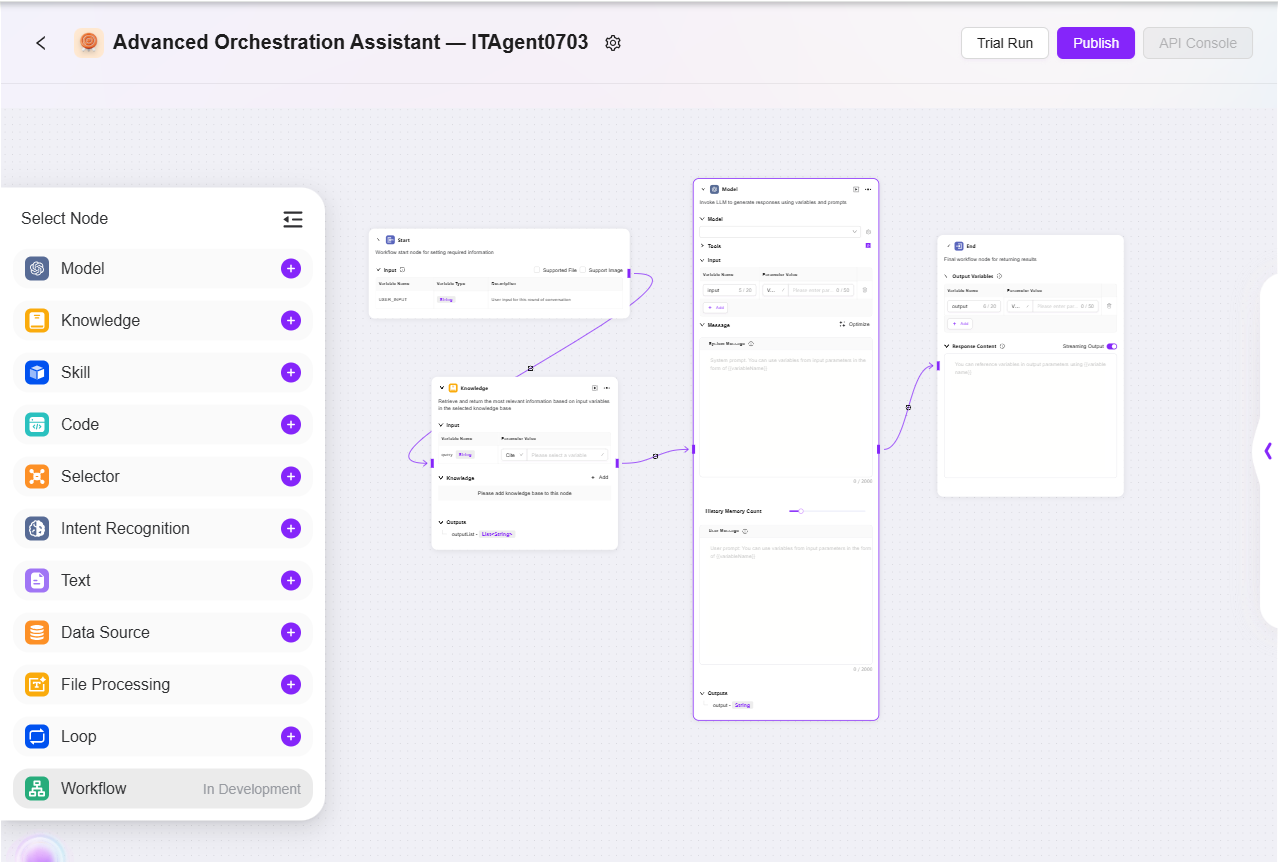
- 根据实际业务配置工作流:
- 开始、结束:自带的输入输出模块,可自定义输入输出参数与字段
- 模型:可在此模块中选择使用的模型,输入其他模块获取的变量,并编辑提示词以及输出的消息,以变量形式保存
- 技能:选择其中一个技能,进行经过该技能的输入输出动作
- 数据来源:选择数据来源以增加可引用的变量内容
- 代码:根据其他模块中的输出变量,进行代码函数的自定义编写与创建
- 知识库:在选定的知识库中,根据输入变量召回最匹配的信息,加以返回
- 选择器:连接多个下游分支,若设定的条件成立则仅运行对应的分支,若均不成立则只运行“否则”分支
- 意图识别:用于用户输入的意图识别,并将其与预设意图选项进行匹配
- 文本:用于处理多个字符型变量的格式
- 节点详细介绍
-
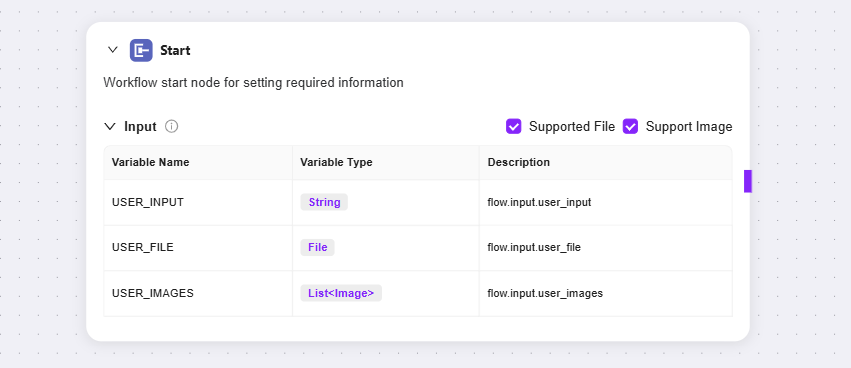
开始
-
开始节点:工作流的起始节点,用于设定启动工作流需要的信息
-
输入:简单理解为,提前告诉LLM完成一项任务需要哪些基本信息(输入参数),当进行使用时,LLM会记住这些信息要求,一旦在对话中发现需要启动任务的时机,就会自动调用这些预先设定的参数,将参数放入对应位置,从而启动整个流程。
-
-
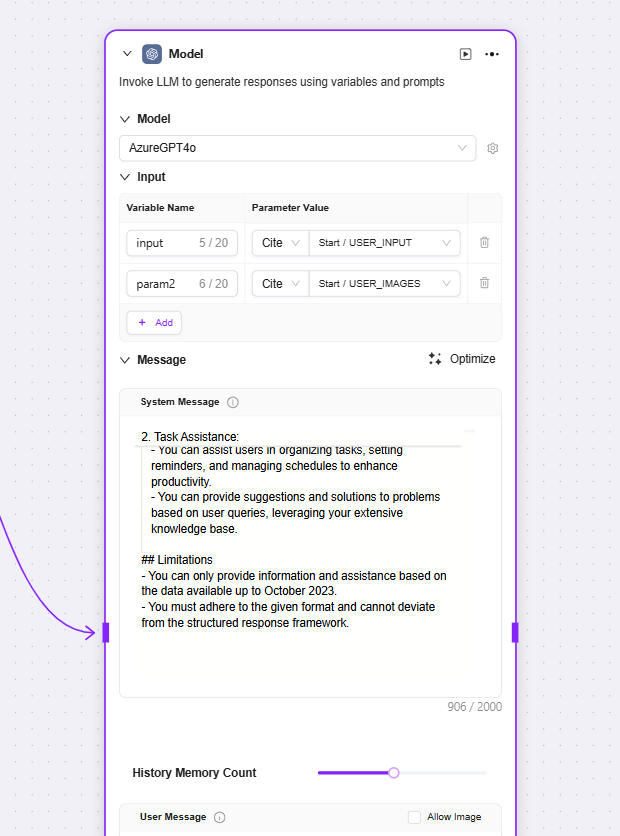
模型
-
模型:调用大语言模型,使用变量和提示词生成回复
-
输入:下拉选择已有的模型,选用输入变量名
-
消息:为对话提供高层指导
-
用户消息:向模型提供指令、查询或任何基于文本的输入
-
💡 提示:需要先连接上前置节点,才能选择其他节点的变量作为当前节点的输入变量
-
技能
-
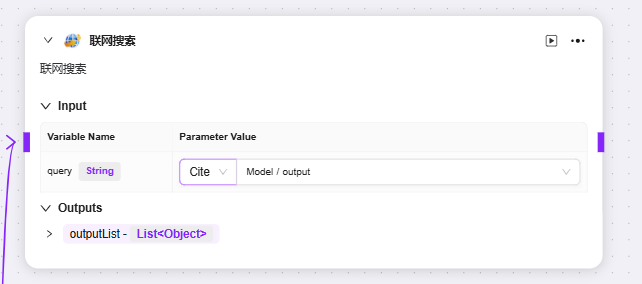
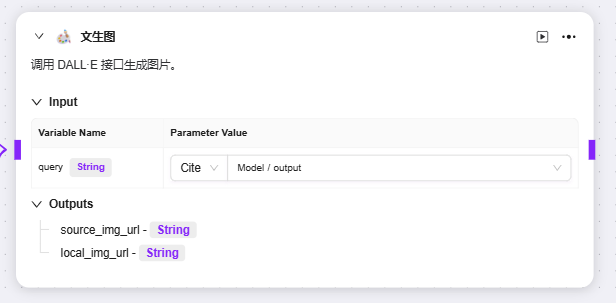
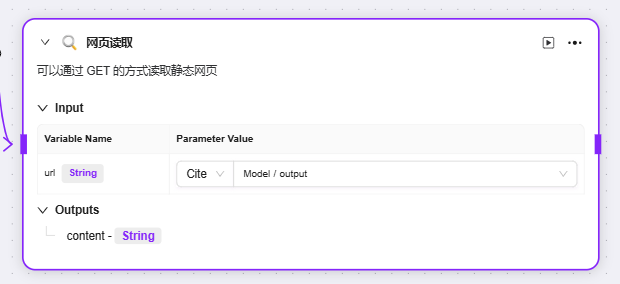
目前默认三种技能课添加至高价编排:联网搜索、文生图、网页读取
-
可以分别输入其作为query、url的前置节点变量作为其输入,并得到对应的输出变量
-
-
代码
-
代码:编写代码,处理输入变量来生成返回值
-
输入:用于接收外部传入的变量,是代码运行所需数据的入口,为后续代码处理提供原始数据
-
代码配置:对代码运行相关参数进行设置(如最大运行时间),并提供代码编写区域,在此编写逻辑来处理输入变量
-
输出:代码运行处理完输入数据后,将结果以指定变量形式输出,是代码处理结果的出口
-
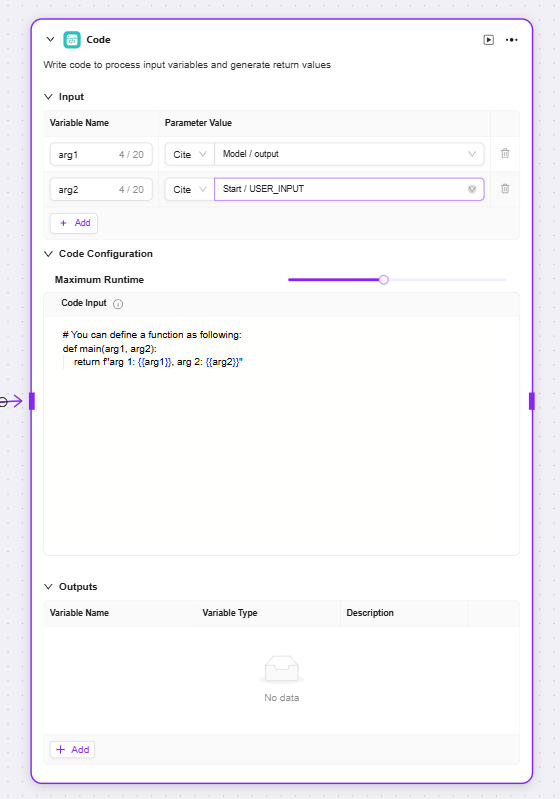
-
选择器
-
选择器:在流程编排中起条件判断作用。它连接多个下游分支,通过设定的条件来决定执行路径
-
条件分支:可设置多个条件,如 “if - 优先级 1” 。通过配置引用变量、选择条件(如等于、大于等比较逻辑 )、比较值,来判断条件是否成立。若成立,就运行对应的分支流程。
-
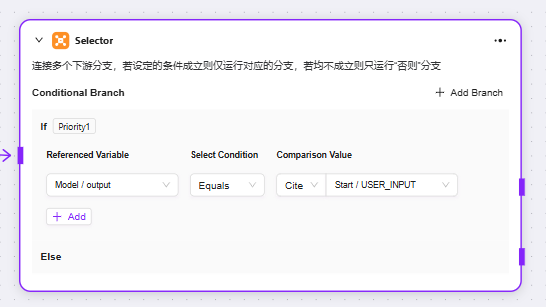
-
知识库
-
输入:通过定义变量名及设置参数值,为知识库检索提供检索关键词等原始数据
-
知识库:选定特定的知识库作为检索范围 ,系统将在这个范围内查找匹配信息
-
最大召回数量:可设置从知识库中最多返回匹配结果的数量,避免返回过多数据
-
输出:将从知识库中检索到的匹配信息,以指定变量的形式输出,供后续流程使用
-
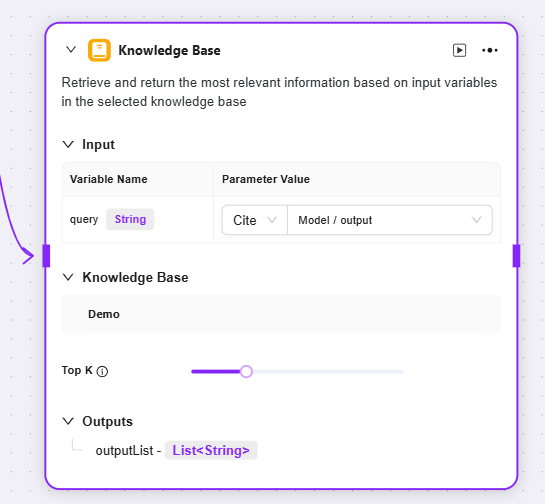
-
意图识别
-
意图识别:是自然语言处理中的关键环节,该模块作用是分析用户输入内容,确定其真实意图并匹配预设置选项
-
模型:选择用于意图识别的模型,模型决定了意图识别的能力和效果
-
意图匹配:可预先输入用户意图描述作为匹配标准,也能新增其他意图,系统据此判断用户输入符合哪种预设意图
-
高级设置:能设置系统提示内容,可引用输入变量来优化提示效果;还可设置历史记忆条数,让模型参考过往对话信息提升识别准确性
-
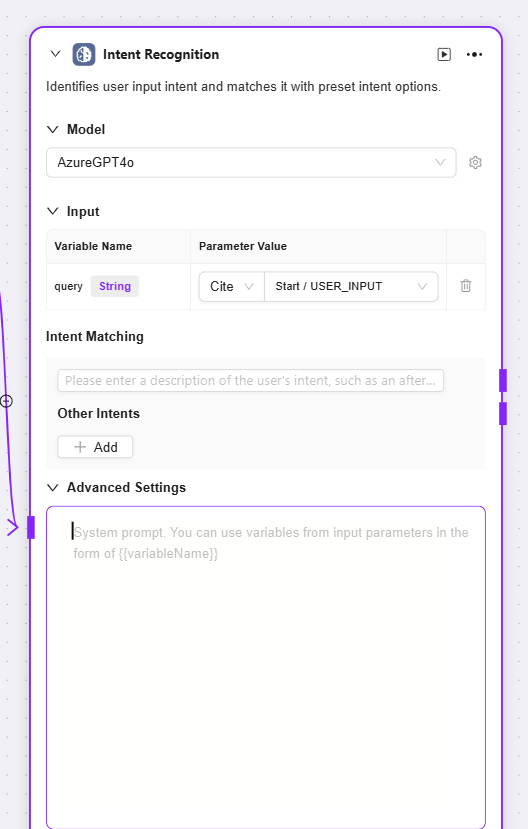
-
文本
-
文本:主要用于处理字符串类型变量格式
-
输入:可定义变量名,并通过引用方式获取参数值,为后续文本处理提供原始字符串数据
-
字符串拼接:提供文本编辑区域,可按需求使用变量名方式引用输入变量,对多个字符串进行拼接等格式处理
-
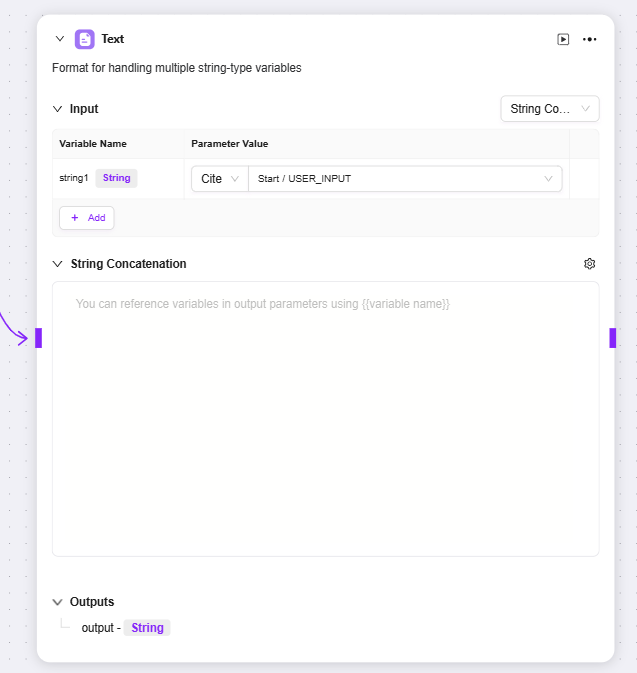
-
文件处理
-
文件处理:是对文件内容进行检索等操作的功能模块
-
输入:通过定义变量名并引用参数值来提供检索关键词等输入信息,为文件内容查找提供依据
-
文件:可添加需要处理的文件到该节点,确定检索的文件范围
-
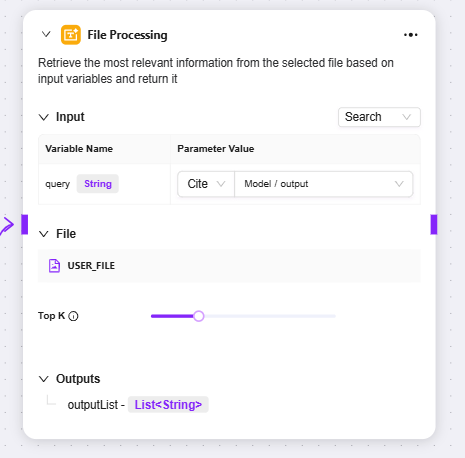
-
数据源
-
数据源:选择要接入的数据源
-
输出:将数据源的数据进行输出,输出给下一个节点。
-

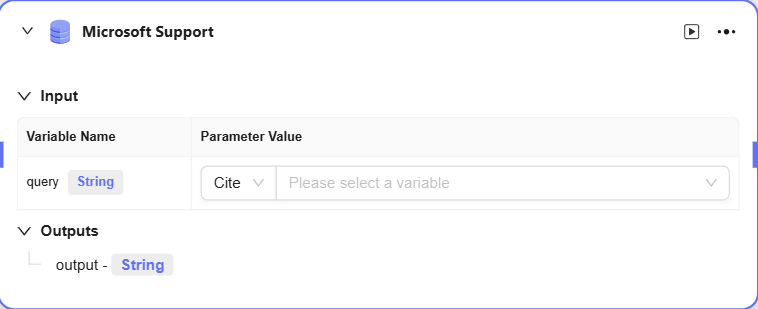
工作流示例
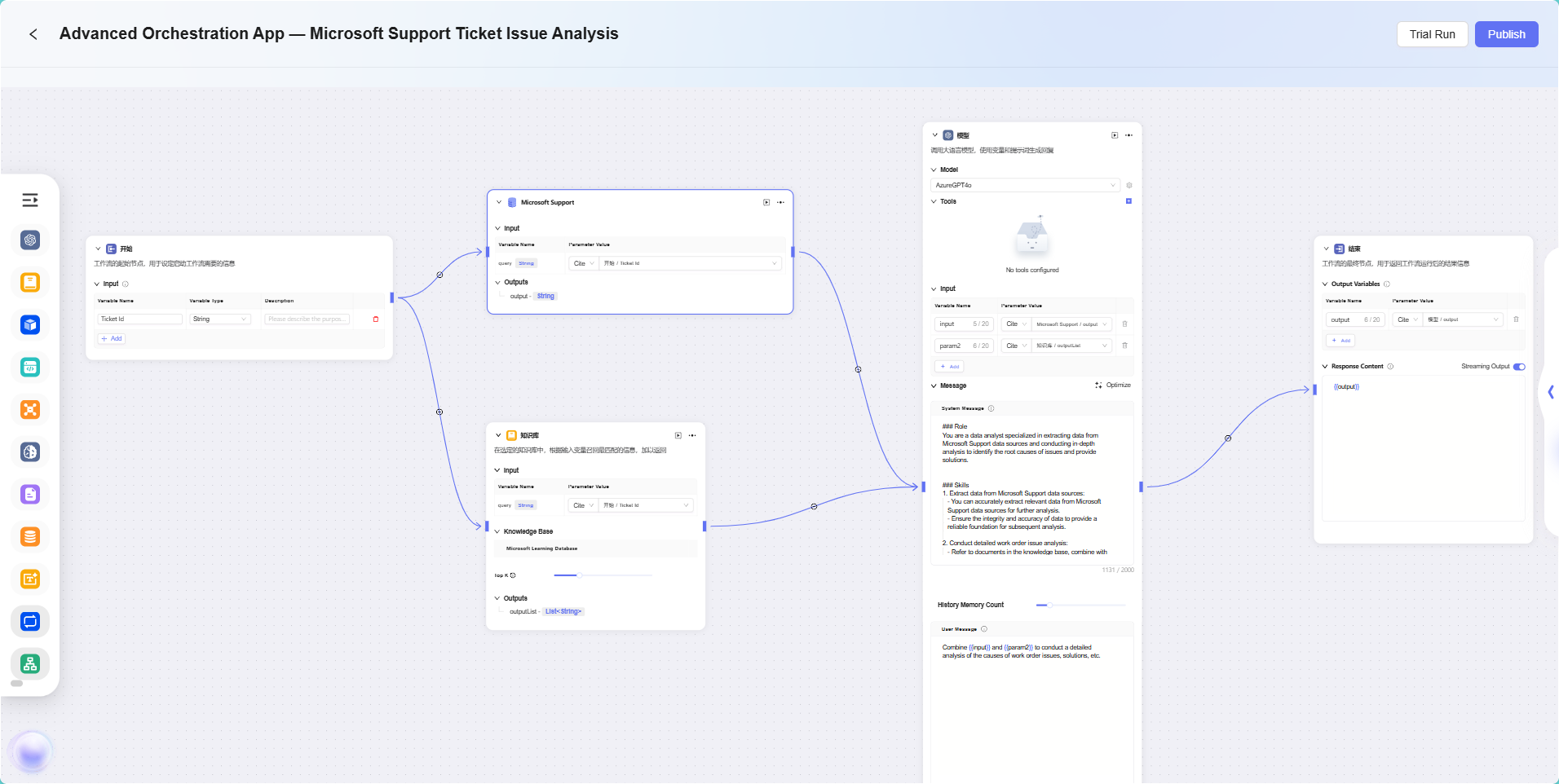
在本场景中,使用工作流功能构建一个完整的 “Microsoft Support Ticket Issue Analytics” 流程,具体流程如下:
-
开始节点
流程的起点,系统默认包含。 -
数据源节点
用于接入工单分析所需的原始数据。 -
知识库节点
接入包含分析参考资料的知识文档,作为AI分析的理论支撑。 -
模型节点
基于AI模型,将数据源与知识库内容结合,进行综合分析,生成工单问题分析结果。 -
结束节点
流程的终点,输出模型节点的分析结果。此节点系统默认包含。
数据源节点与知识库节点并列配置,模型节点则汇总处理前两者的信息,确保输出结果具备数据依据和理论支撑。
最后效果如下:
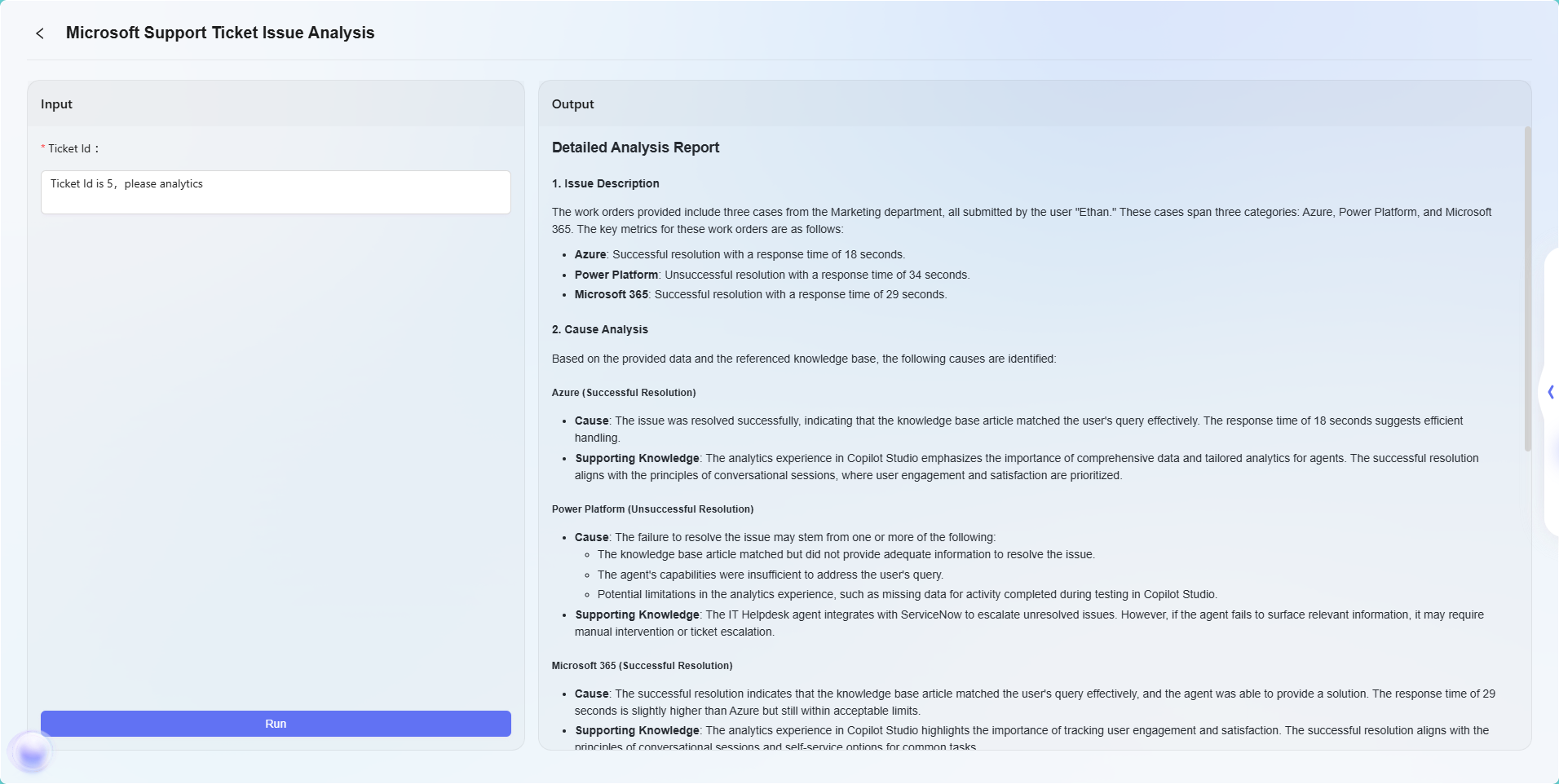
注:本示例仅为高级编排功能的简单应用,用于展示其基本流程效果。高级编排具备强大的灵活性和扩展性,支持通过多种节点类型实现复杂的业务逻辑和智能自动化流程,可广泛应用于多种实际业务场景中。
通过分享码创建智能体
分享码创建可以理解为助手的复制,其核心原理是通过已有的成熟助手生成专属分享码,用户只需获取该代码即可快速创建一个全新的助手,实现功能的无缝复制与传播。
分享码创建助手具体步骤:
- 点击助手右侧三个点,选择“分享”
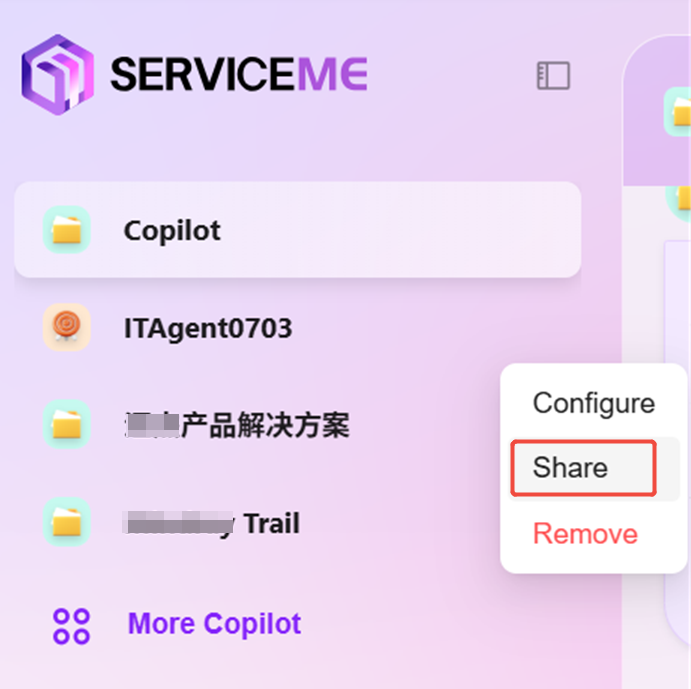
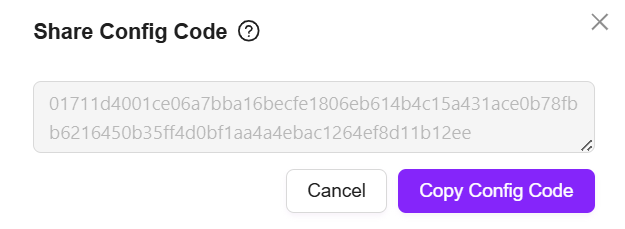
- 点击后会生成配置码,将配置码复制备用
- 点击“创建助手”,选择“分享码创建”
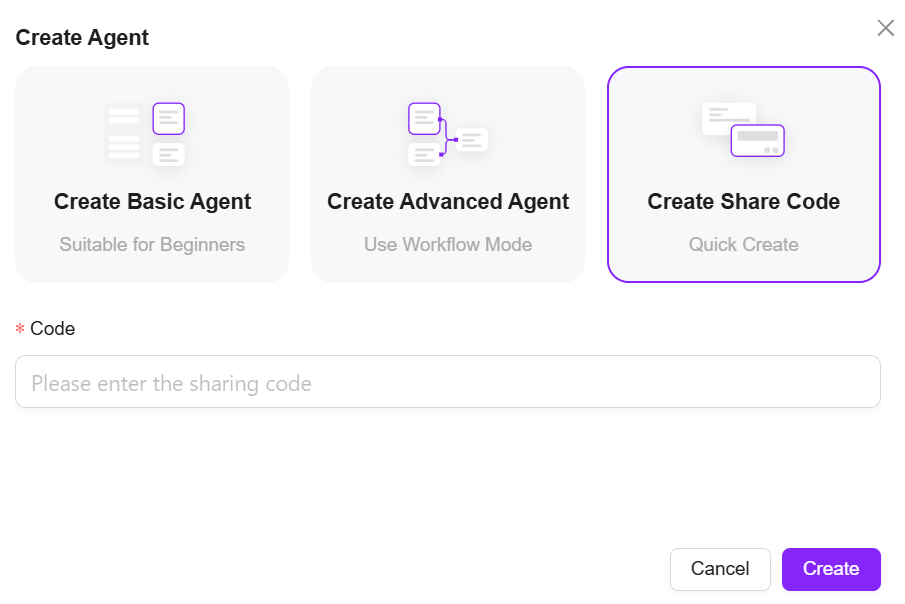
- 将复制的配置码粘贴至配置码处,点击“创建”
可在助手配置页对此分享码创建的助手进行适当的调整,以更符合场景。