通过Workflow搭建复杂业务Agent助手
在 SERVICEME NEXT 中,基础方式创建的 Agent 更适用于简单的问答场景,功能相对有限。若需处理更复杂的业务逻辑或实现多步骤操作,可通过 Workflow(工作流) 构建高级 Agent,满足更丰富的业务需求。
本章节将通过一个具体实例,展示如何使用 Workflow 搭建复杂流程。
场景示例:合同内容敏感词提取
在实际业务中,合同文本通常篇幅较长,内容复杂。若需人工逐条比对并识别其中是否包含敏感词,不仅耗时费力,还容易遗漏,尤其当敏感词数量较多时,准确性更难保障。
借助 Workflow 能力,可以构建一个支持文件上传、内容解析、敏感词识别与标注的智能 Agent,自动完成以下操作:
- 接收用户上传的合同文件;
- 自动解析文本内容;
- 检测并提取其中的敏感词;
- 返回包含敏感词及其所在位置的结果。
通过该流程,用户无需手动查阅,即可快速了解合同中的敏感信息,大幅提升审核效率与准确性。
✅ 提示:此类 Agent 尤其适用于法务审查、内容审核、合规管理等场景。
准备敏感词数据源
在正式搭建工作流之前,需要先准备好敏感词的数据。本案例中,敏感词存储在数据库中,因此需要通过 Data 模块 添加数据库为数据源,并完成数据同步。
数据准备前置条件
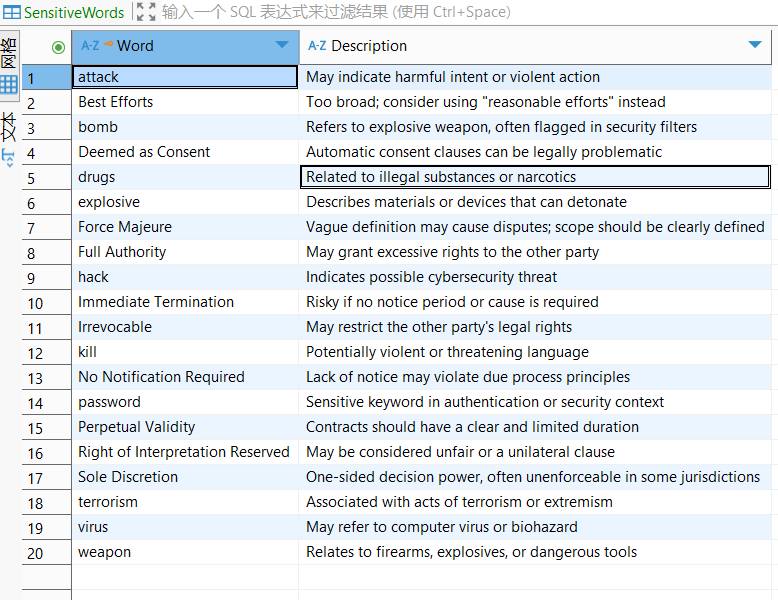
- 已将敏感词数据写入数据库(表名为
SensitiveWords)。 - 数据库类型为
SQLServer,并可通过网络访问。
添加数据源步骤
- 进入 Data 模块
- 打开 SERVICEME 平台,点击右侧菜单中的 “Data”。
- 在左侧选择 “数据源”,进入数据源管理页面。
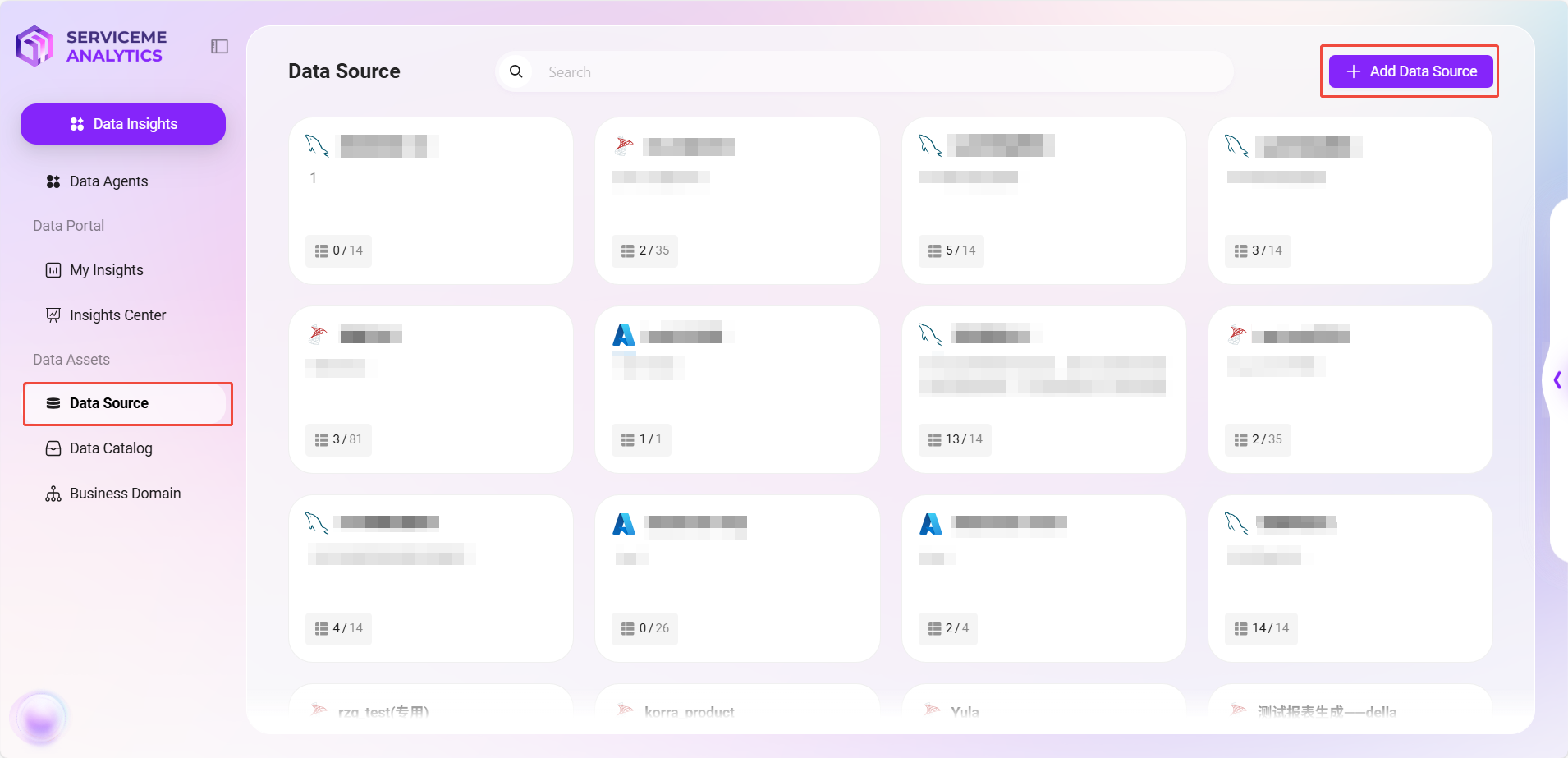
- 添加数据源
- 点击右上角 “添加数据源” 按钮。
- 在弹出的配置窗口中填写以下信息:
- 数据源名称:如
Sensitive Word - 数据库类型:选择
SQLServer - 连接信息:包括
host、port、用户名、密码、数据库名称
- 数据源名称:如
- 点击 “测试链接”,确认连接成功后点击 “确认” 完成添加。
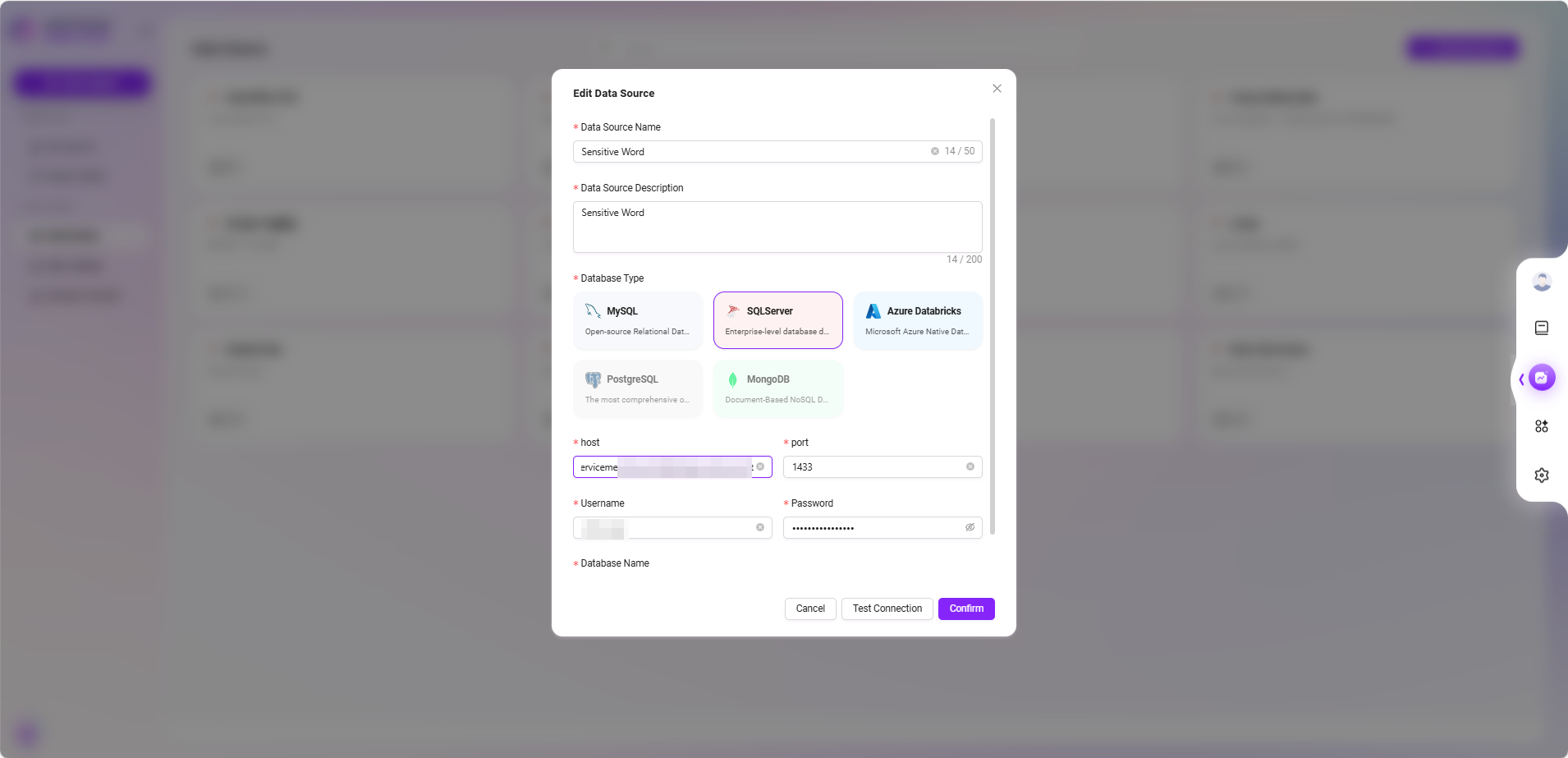
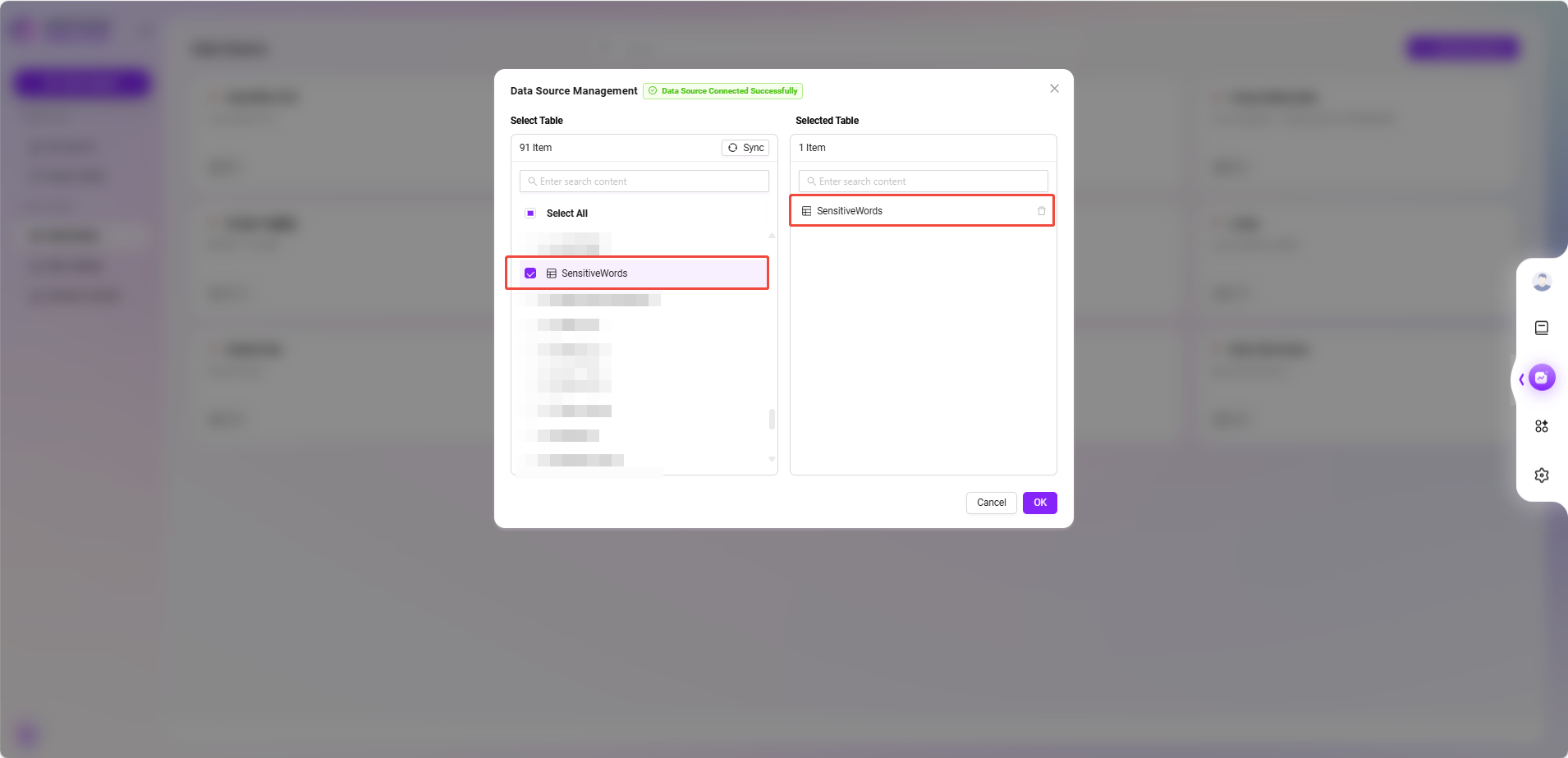
- 选择数据表
- 返回数据源列表,点击刚创建的数据源项。
- 系统会展示数据库中可用的数据表,勾选包含敏感词的表(如
SensitiveWords),点击 “确认” 添加。
- 数据目录同步
- 在左侧菜单选择 “数据目录”,找到并点击
Sensitive Word数据源。 - 执行 “同步” 操作,以确保平台获取到最新的数据。
- 在左侧菜单选择 “数据目录”,找到并点击
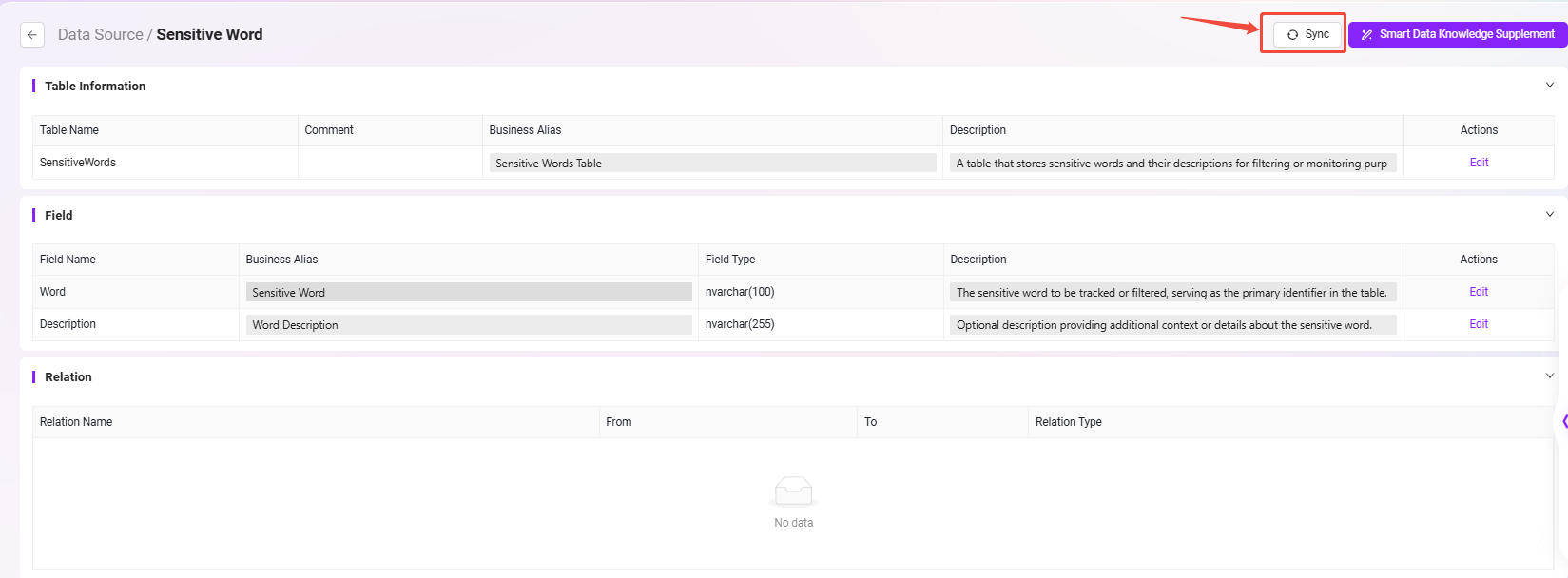
完成以上步骤后,敏感词数据源即配置完毕。在接下来的工作流中,可以通过节点方式访问该数据表,实现对合同内容的敏感词提取与比对。
通过工作流的方式创建“Sensitive Word Extraction”Agent
- 进入 SERVICEME NEXT 首页,点击左下角圆形图标,进入 Agent 问答界面。
- 点击左侧菜单中的 “更多助手”,进入助手广场。
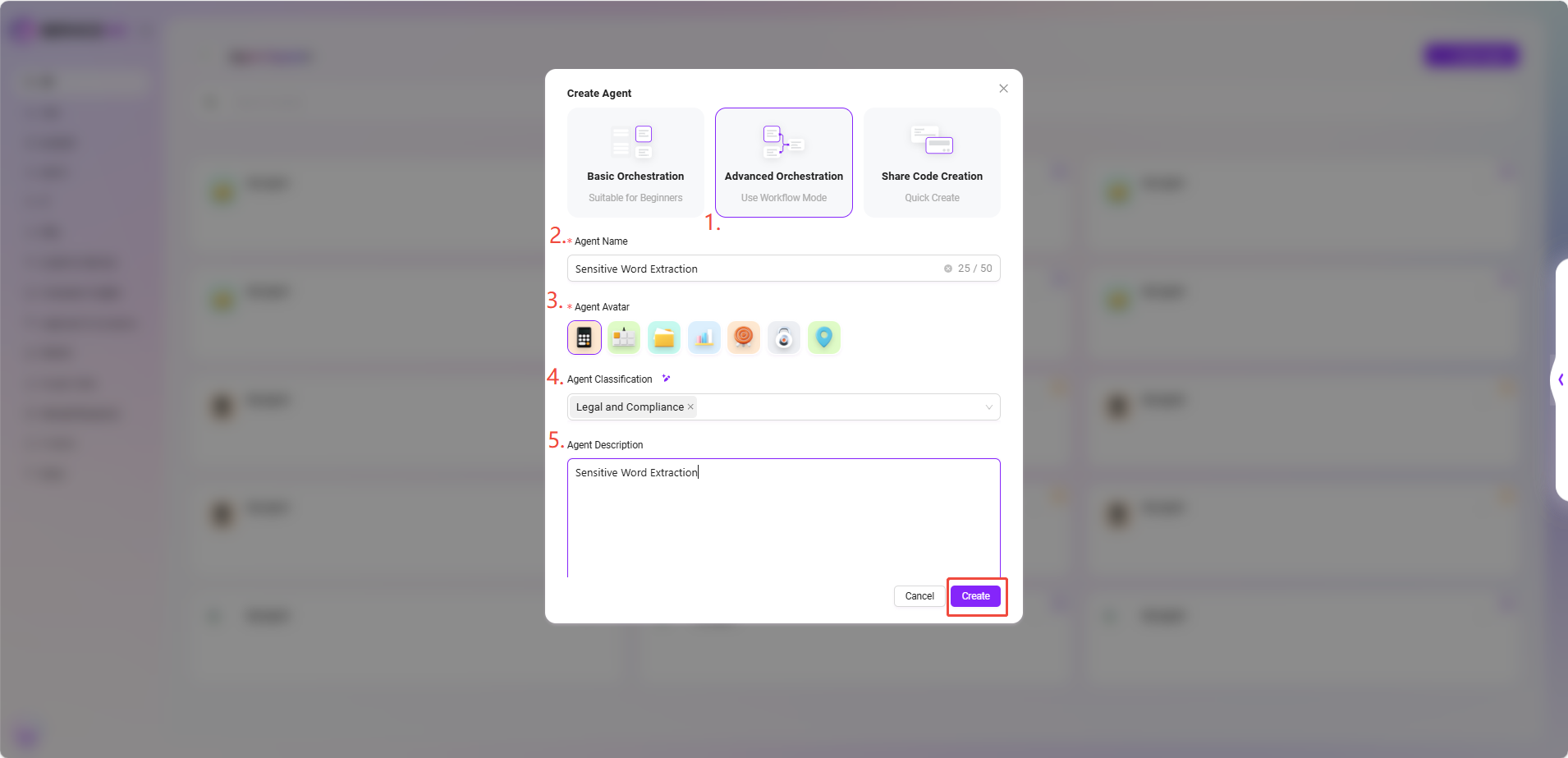
- 在助手广场右上角点击 “创建助手”,并选择 “高级编排创建” 方式。
- 填写以下基础信息:
- 助手名称:输入
Sensitive Word Extraction - 智能体头像:从系统内置头像中选择一个(当前不支持自定义上传)
- 分类:选择业务归属分类,如
Legal and Compliance - 描述:例如
Sensitive Word Extraction
- 助手名称:输入
- 填写完成后,点击 “创建”,即成功生成基础 Agent。
配置“Sensitive Word Extraction”Agent
📌 编排前思路梳理
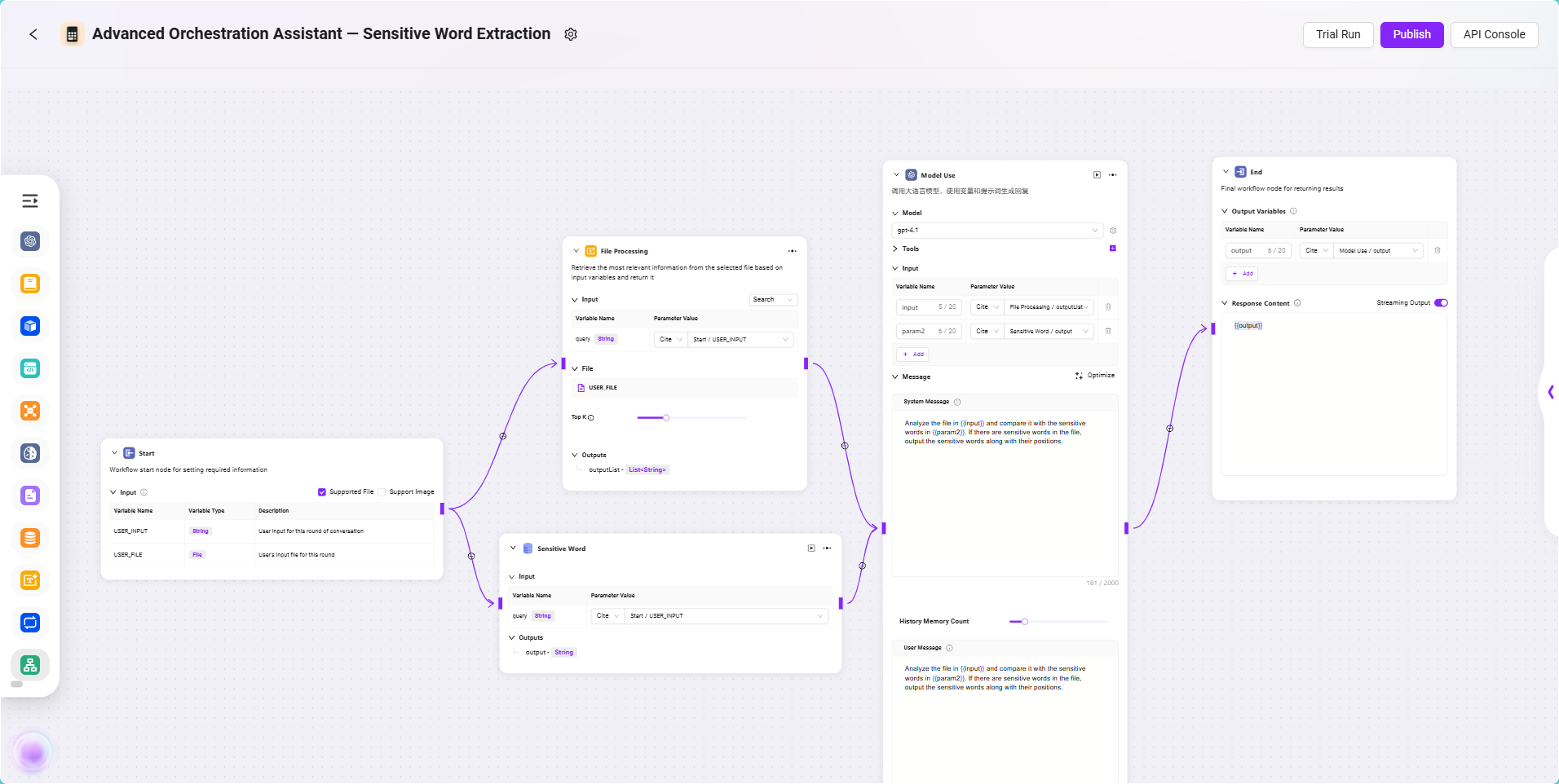
本工作流的核心目标是:让 Agent 能够从用户上传的合同文件中自动识别出存在的敏感词。为此,我们需要引导用户上传合同文件,并将其内容解析为可处理的文本;同时从已配置好的数据库中加载敏感词数据,通过模型将合同内容与敏感词进行智能比对,识别匹配项及其位置。最终,模型输出识别结果,并将结果返回给用户。整个流程涵盖了文件处理、数据源调用、模型识别与结果输出等关键环节,适用于自动化的文本审查类业务场景。
📌 节点配置与连线说明
在本例 Workflow 中,每个节点的输入输出均通过引用前一节点的结果进行配置。为了实现敏感词提取的目标,本流程主要涉及以下节点:开始节点、文件处理节点、数据源节点、模型节点和结束节点。下面将依次说明各节点的配置与连线方式。
配置过程
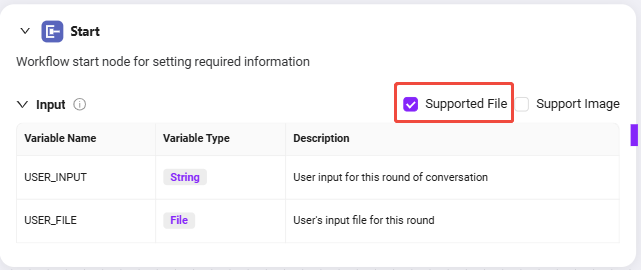
- 开始节点输入说明
开始节点默认包含两个输入:
USER_INPUT:用户输入的自然语言指令,例如:“请帮我检查合同中的敏感词。”USER_FILE:用户上传的本地合同文件。
这两个输入将作为后续节点的引用来源,供文件处理与模型识别使用。
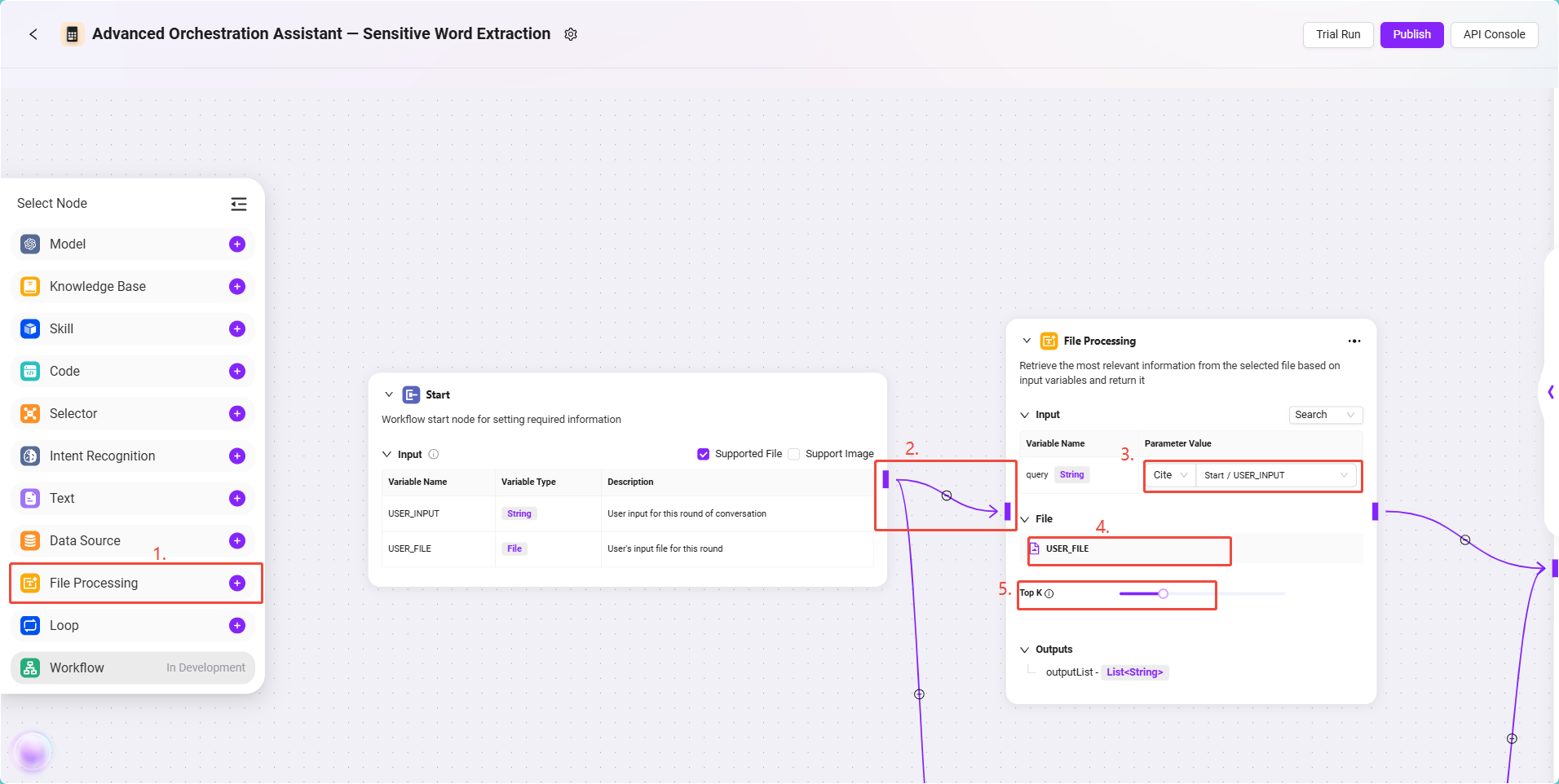
- 文件处理节点配置
该节点负责处理用户上传的合同文件,包括文本提取、切片和向量化处理。
配置步骤如下:
- 添加一个 文件处理节点 到画布中。
- 使用连线将 开始节点 与 文件处理节点 相连。
- 点击文件处理节点,进入配置界面,设置如下内容:
- 输入引用:将
USER_INPUT设置为引用,格式为:
Start/USER_INPUT - 文件引用:点击“添加文件”,选择
USER_FILE(即用户上传的合同文件) - TopK 设置:选择合适的 TopK(如 3~5)。
- TopK 表示模型在处理文本向量匹配时最多返回的文段数量。
- 建议:TopK 过低可能漏掉关键内容,过高则可能影响模型聚焦能力。
- 输入引用:将
- 数据源节点配置
该节点用于引入之前创建的敏感词数据表,供后续比对使用。
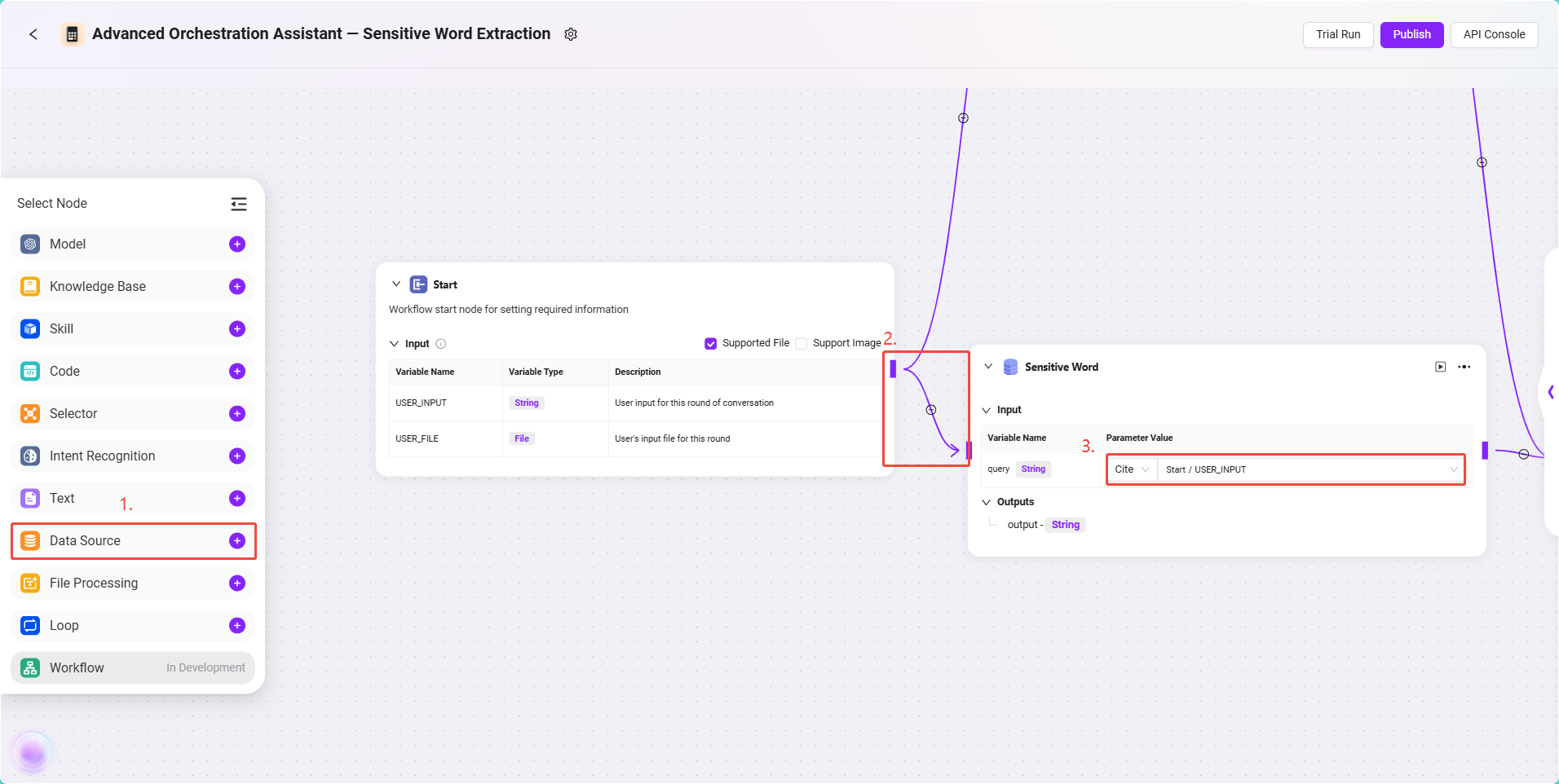
配置步骤如下:
- 添加一个 数据源节点 到画布,与 开始节点 相连。
- 点击节点,配置数据源信息:
- 选择数据源为:
Sensitive Word - 输入引用配置为:
Start/USER_INPUT(用户的输入指令)
- 选择数据源为:
此节点的输出即为模型中需要使用的敏感词列表。
- 模型节点配置
该节点是本流程的核心处理模块,负责将合同文本与敏感词进行智能比对,并返回结果。
配置步骤如下:
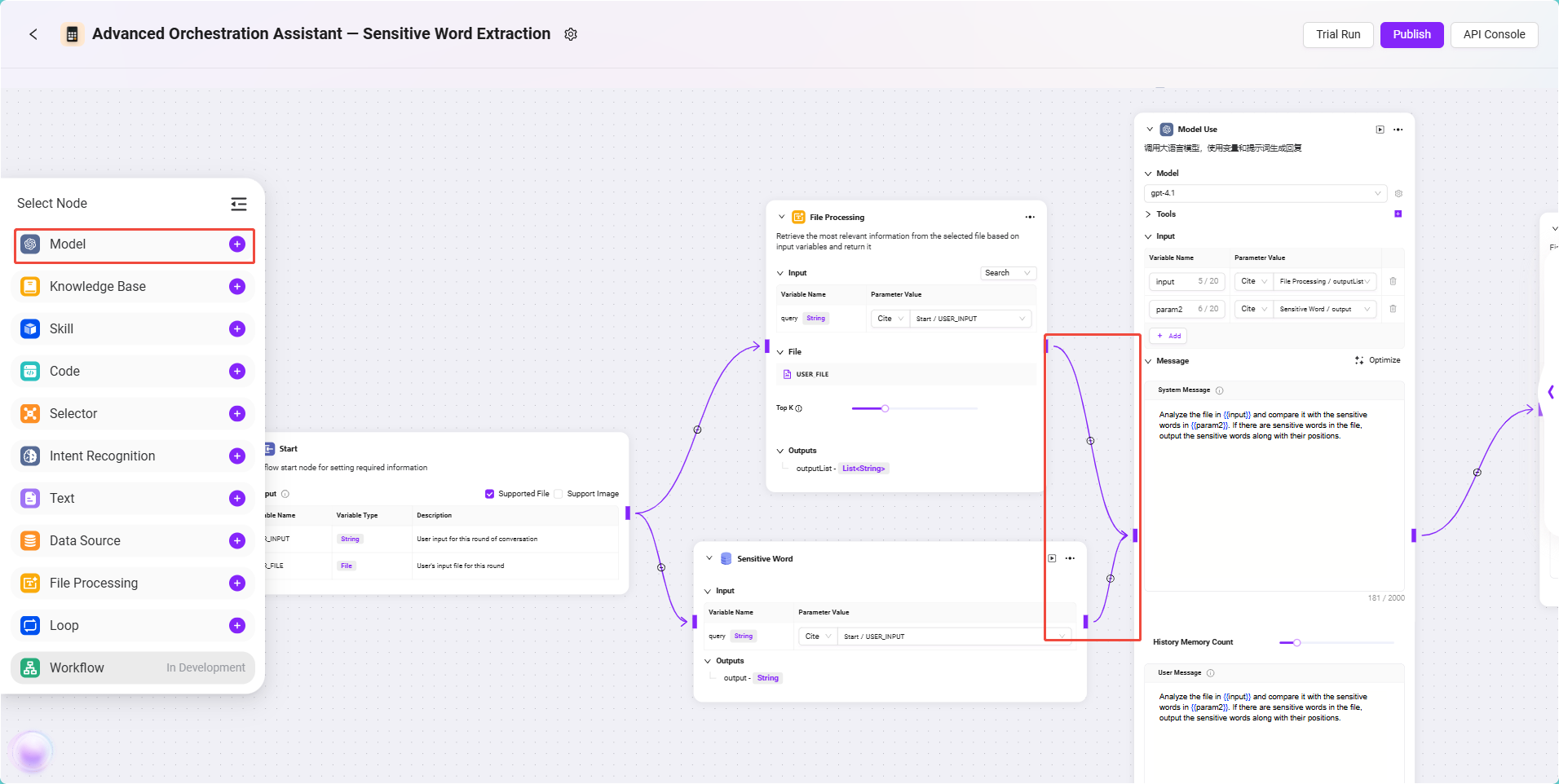
- 添加一个 模型节点,分别连接文件处理节点与数据源节点。
- 模型选择:
gpt-4.1 - 工具选择:本场景不需要调用外部工具,可跳过。
- 输入引用:
input:引用文件处理节点的输出,格式为:
FileHandler/outputparam2:引用数据源节点的输出,格式为:
DataSource/output
- 提示词配置:
- 系统消息(System Prompt):
Analyze the file in {{input}} and compare it with the sensitive words in {{param2}}. If there are sensitive words in the file, output the sensitive words along with their positions. - 用户消息(User Prompt):
Analyze the file in {{input}} and compare it with the sensitive words in {{param2}}. If there are sensitive words in the file, output the sensitive words along with their positions.
- 系统消息(System Prompt):
✅ 提示:系统消息用于给模型提供行为指令,用户消息模拟用户实际输入。此处两者内容相同,效果更稳定。
- 输出节点配置
该节点用于返回模型的处理结果给最终用户。
配置步骤如下:
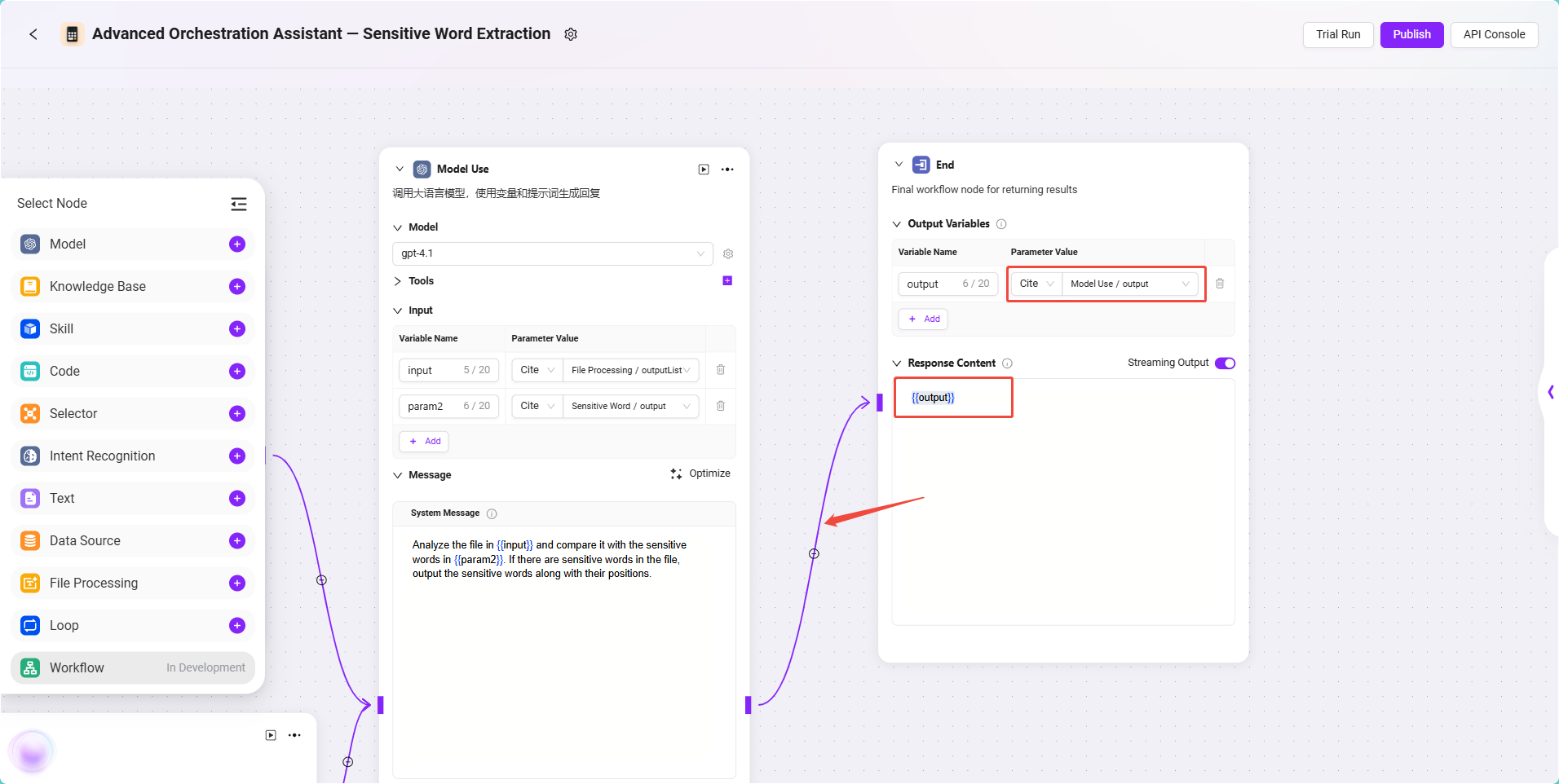
- 将 模型节点 与 结束节点 相连。
- 点击结束节点,设置输入引用:
- 输入内容:引用模型节点输出,格式为:
Model/output
- 输入内容:引用模型节点输出,格式为:
- 在输出内容配置中填写:
{{output}}
✅ 提示:最后只填写
{{output}}作为输出,可以更好的保留模型的输出,如果需要,也可指定特定内容的输出。
完整配置如下: