个人应用中心
什么是Agent
什么是智能体(Agent)?
智能体(Agent)是指一种具备自主感知、理解、推理和执行能力的智能程序或系统。它能够根据用户提供的目标,自主制定计划、调用工具、执行任务,甚至在任务过程中根据反馈动态调整行为,最终高效达成目标。 不同于传统的软件程序依赖人工逐步操作,智能体可以代表用户“思考并行动”,从而实现“指令驱动 → 自主决策 → 自动执行”的完整任务闭环。
智能体具备的核心特征
- 目标导向:根据用户指令或上下文,明确任务目标并制定达成策略。
- 自主行为:具备一定的主动性和自治性,无需逐步指导,即可独立执行复杂任务。
- 环境感知与反馈:能够从外部系统、数据源或用户输入中获取信息,并据此动态调整执行路径。
- 工具调用能力:可灵活调用搜索引擎、数据库、API、自动化工具等外部资源,完成任务所需操作。
- 持续学习与优化:部分高级智能体具备持续学习和优化能力,可在长期使用中不断提升表现。
示例类比
- 你可以把传统软件比作“工具箱”,每个功能都需要你手动点击、操作;
- 而智能体更像是一个“熟练的助手”,你只需要告诉它“我需要完成什么”,它就能自己决定用哪些工具、按什么顺序、如何应对突发情况,最终完成目标。
应用场景
智能助手广泛应用于多个业务领域,以下是典型场景:
-
企业自动化办公
- 自动撰写日报、周报、会议纪要、邮件等内容
- 日程自动管理与会议协调
- 数据自动分析并生成图表和结论报告
-
金融服务与风险管理
- 自动生成合规或审计报表
- 风险舆情监控与异常事件识别
- 自动化客户风险评估与信用评分
如何创建个人AI Studio
基础创建Agent
-
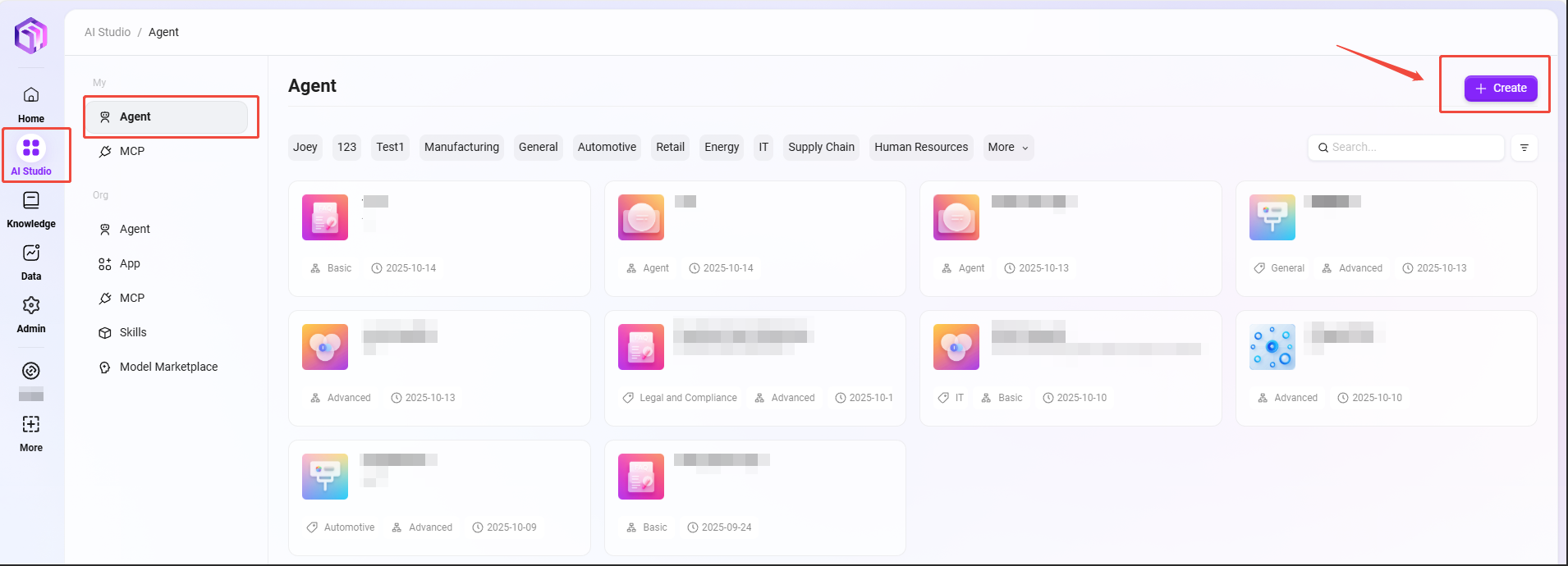
在AI Sudio页面的右上角,点击“创建”创建基础智能体
-
创建步骤
-
输入助手名称、选择助手头像、选择模型组、选择助手分类、添加助手描述:
① 助手名称:输入助手的名称,作为助手标识。
② 助手头像:选择助手默认头像,目前不支持上传头像。
③ 模型组:为助手配置合适的模型组。
④ 助手分类:选择新建助手所在的组,可多选。
⑤ 助手描述:输入简要描述,说明助手的功能和用途。 -
点击“创建”,助手创建后进入基础编排助手配置页面,配置并发布后可投入使用。
-
- 助手配置
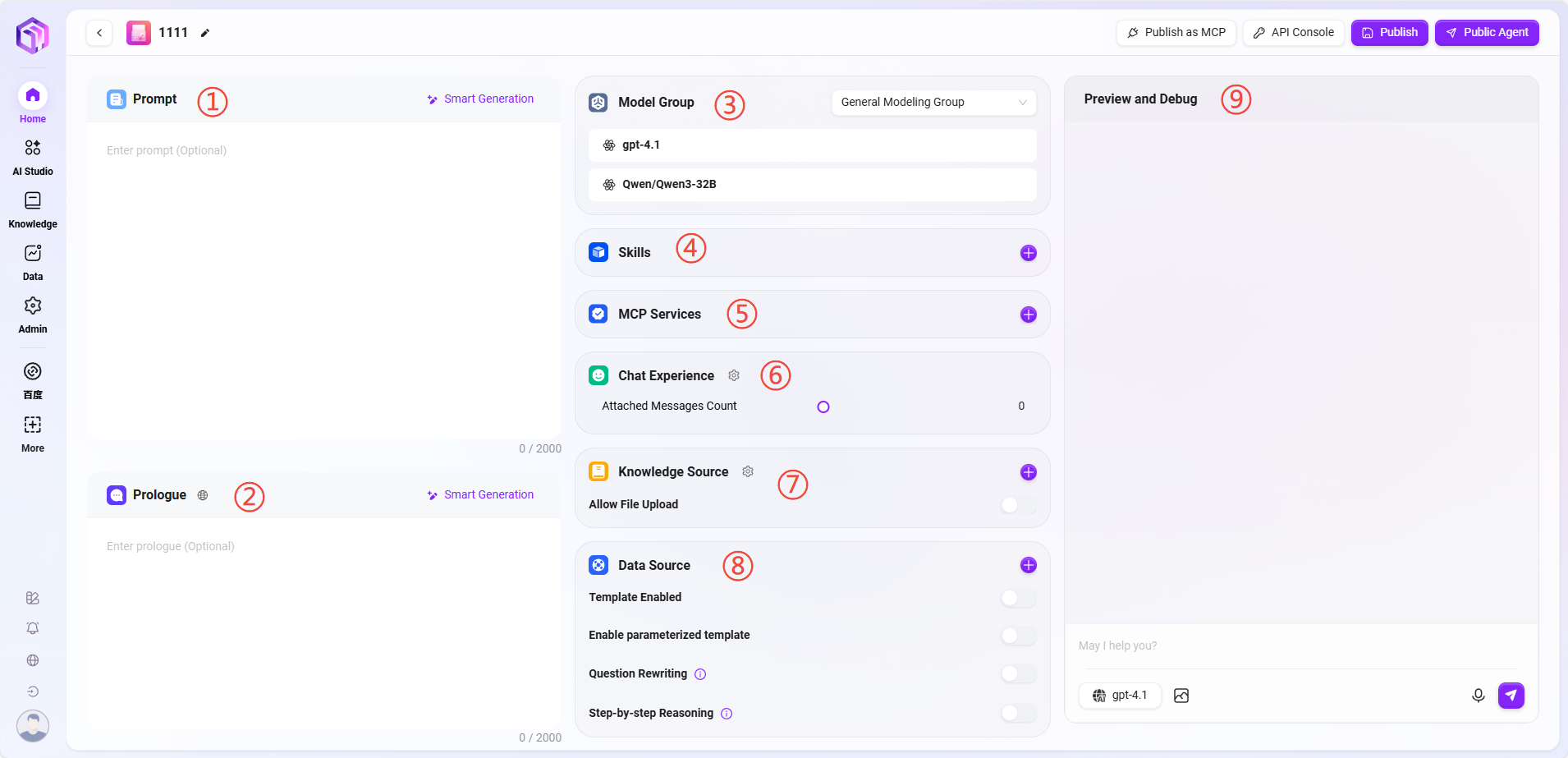
助手配置进入方式有两种:
-
创建助手后直接进入助手配置页面;
-
将鼠标悬停在助手卡片上方,即可看到“✏️”图标,点击它可进入配置页面。
① 提示词:输入助手提示词,也支持将现有提示词进行智能生成,提示词限制字数2000字。
② 开场白:输入助手开场白,也支持根据提示词或已有开场白进行智能生成,开场白限制字数2000字。
③ 模型组:点击“+”添加模型组,支持多种可选模型。
备注:模型组首先需要管理员在系统管理中进行添加模型组,将多个不同的模型添加到同一个模型组中,再将模型组配置到助手中。
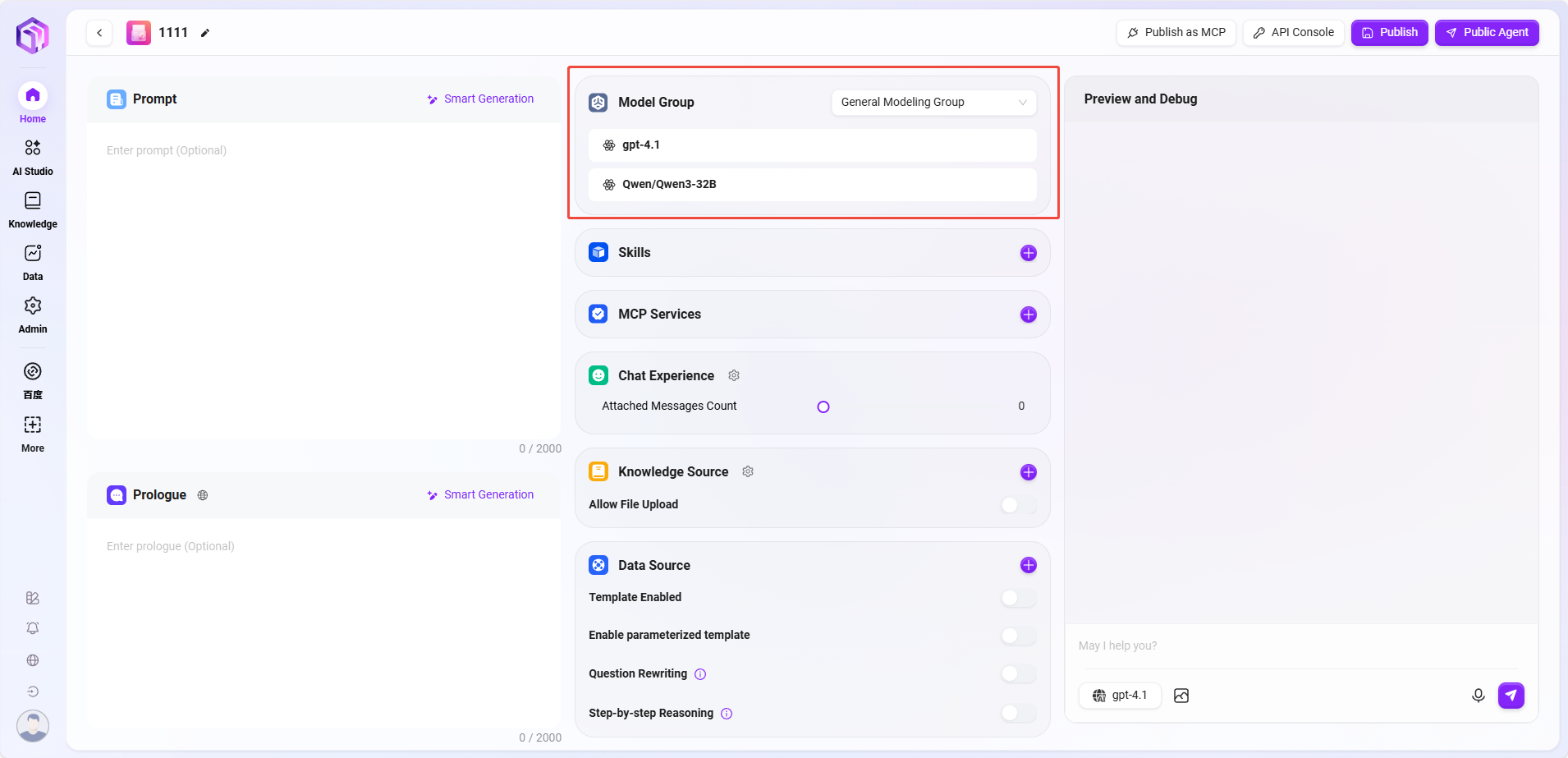
添加模型组
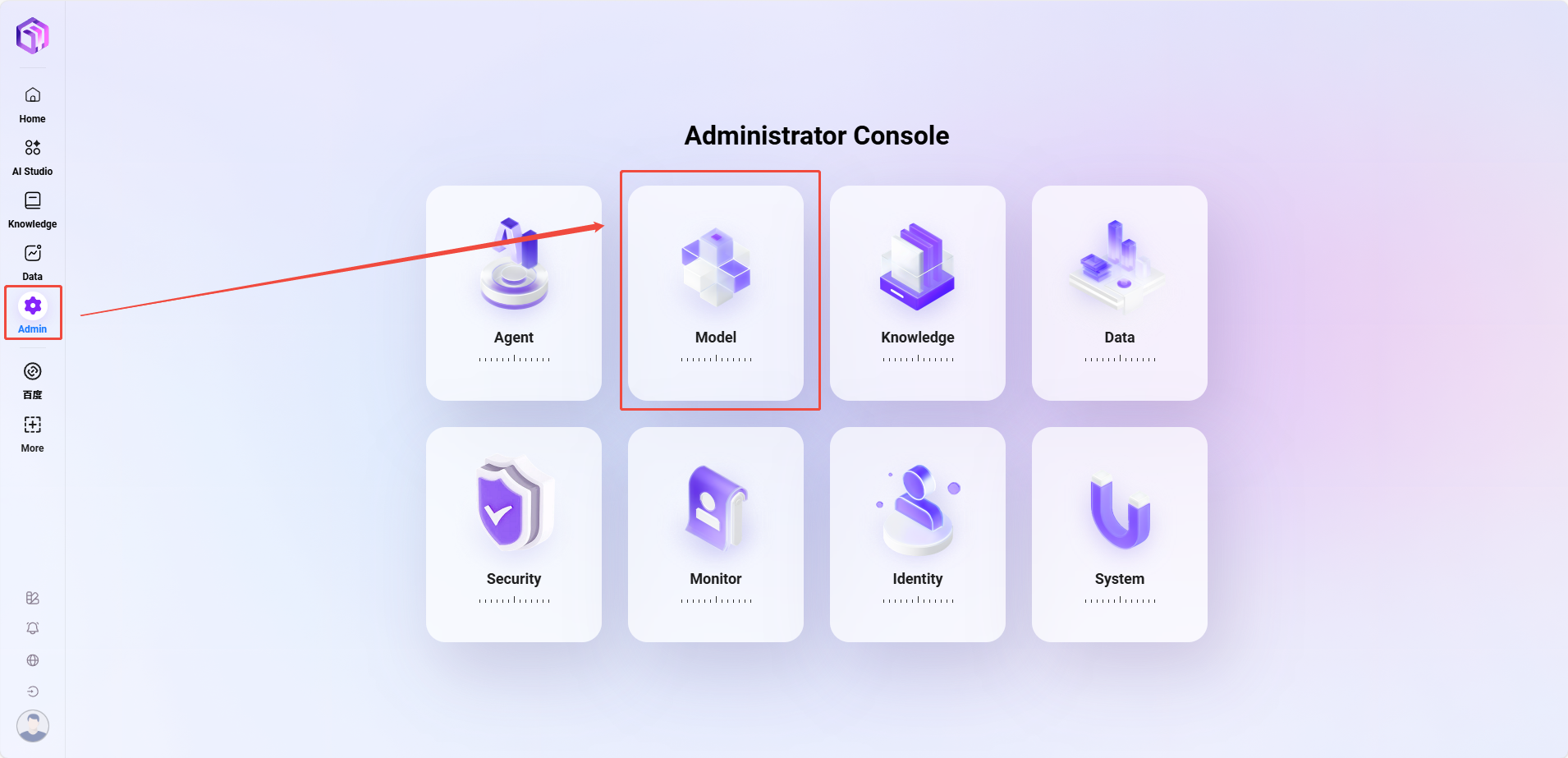
-
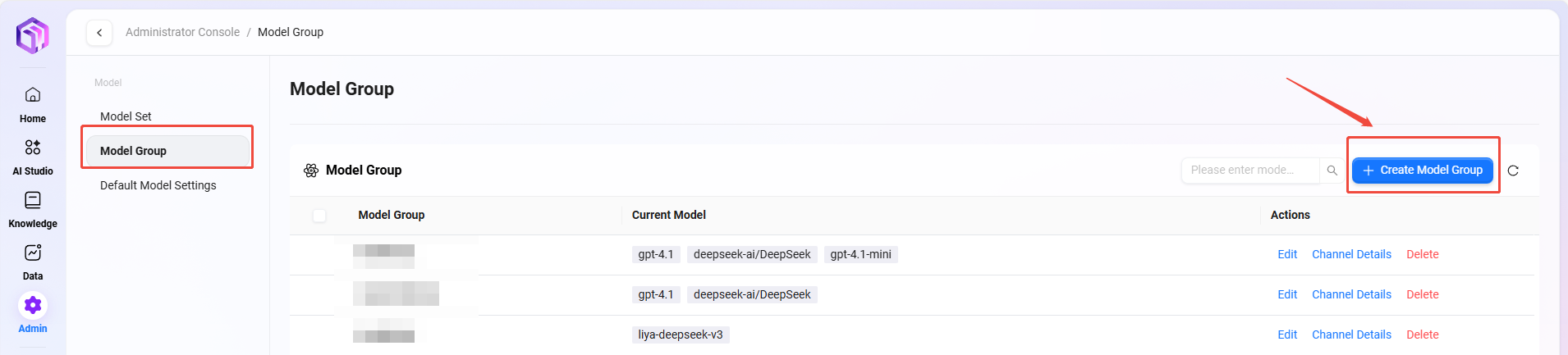
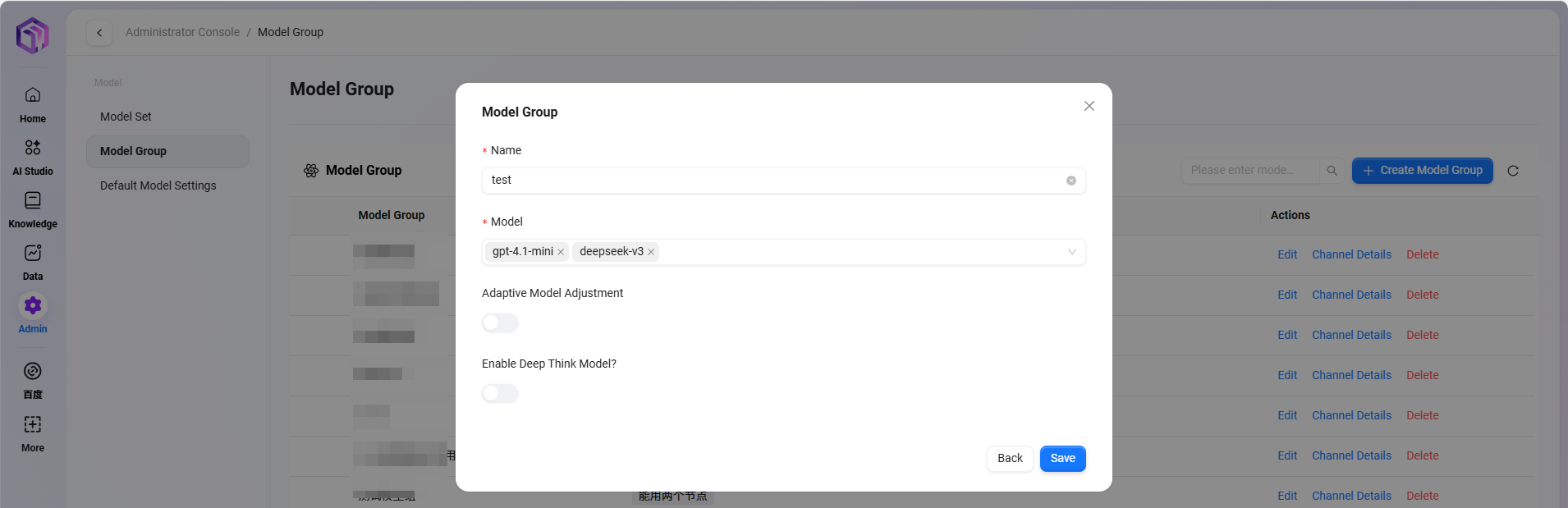
路径:管理 → 模型管理 → 模型组 → 新建模型组(仅管理员可添加模型)
-
添加步骤:
- 点击“新建模型组”
- 完成以下配置:
- 输入模型组名称
- 选择要加入模型组的模型,可选择多个
- 选择是否开启自适应模型部署
- 选择是否启用深度思考模型
- 点击“保存”
-
自适应模型部署:能根据流量自动调整计算资源,确保服务稳定流畅;
-
深度思考模型:在遇到复杂问题时智能调用更强大的AI,显著提升回答质量。
④ 技能:点击“+”添加一种或多种技能,也可以添加推荐技能
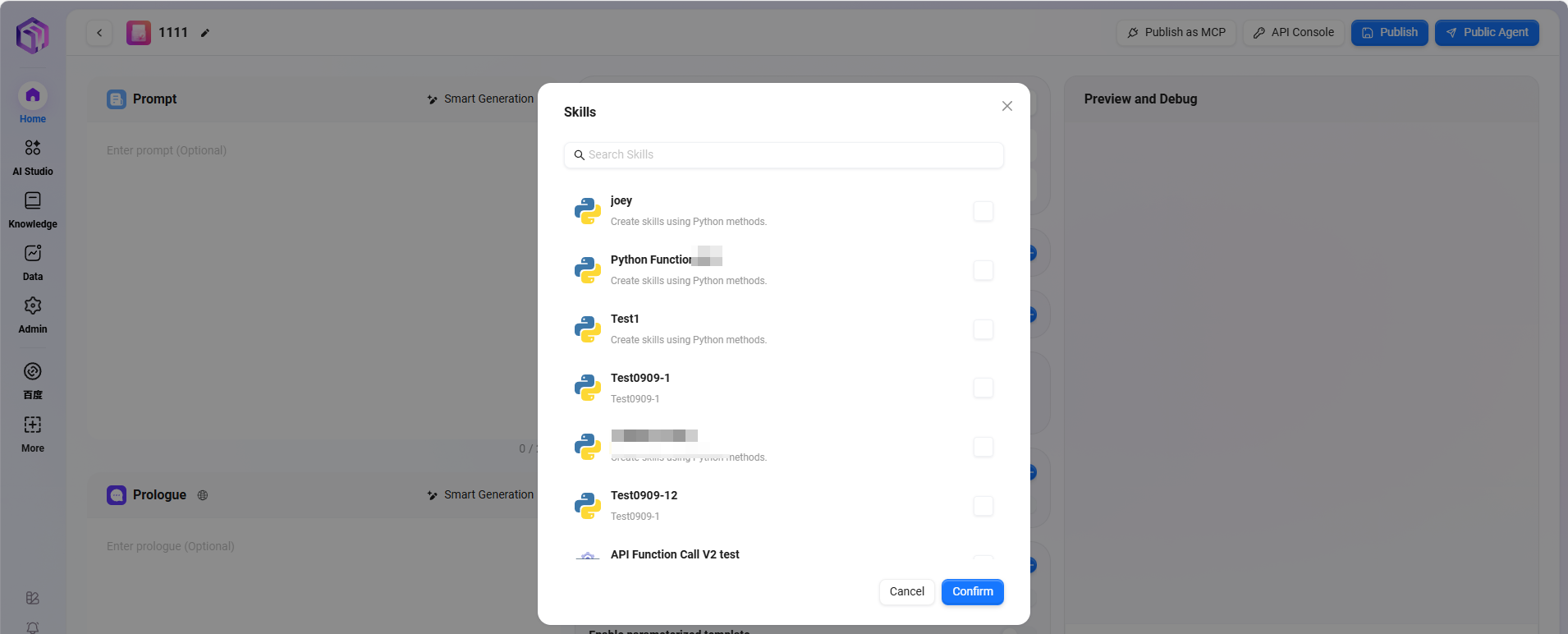
默认技能有 5 个:Google搜索、腾讯搜索、文生图、新闻查询工具、网页读取。
- Google搜索:通过Google搜索引擎获取实时、准确的网络信息,支持全球范围内的网页内容检索。
- 腾讯搜索:基于腾讯搜索技术,提供针对中文互联网环境的搜索服务,特别优化了对中文内容的检索效果。
- 新闻查询工具:用于搜索、获取各类新闻资讯的专用工具。
- 网页读取:提取网页文本、数据等内容,解析网页信息的功能。
- 文生图:基于文本描述自动生成对应的图像内容,将文字创意转化为视觉呈现。
备注:支持追加其他技能,需管理员进行操作与配置。
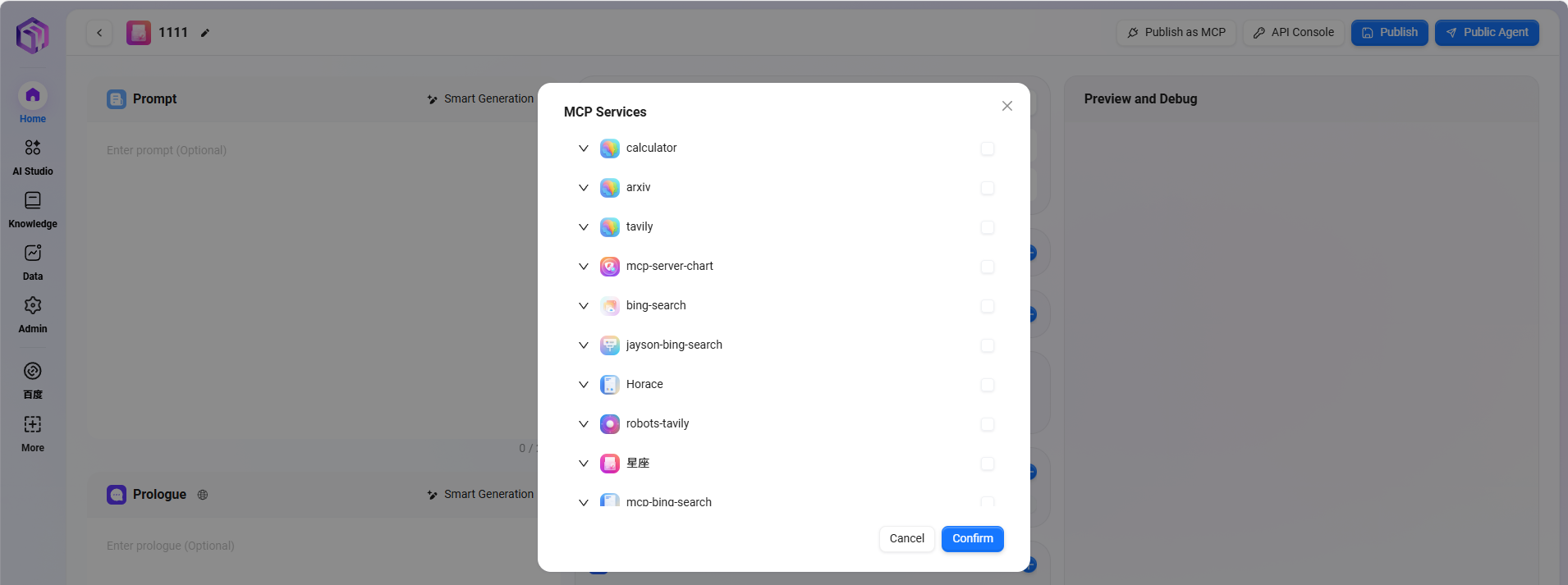
⑤ MCP服务
-
MCP服务管理系统内AI助手与外部工具、数据源的连接权限
- 能力扩展:让AI助手具备搜索、计算、可视化等实用功能。
- 生态丰富:持续集成各类工具服务,满足多元化需求。
- 标准化接入:通过个人MCP集成内部系统资源。
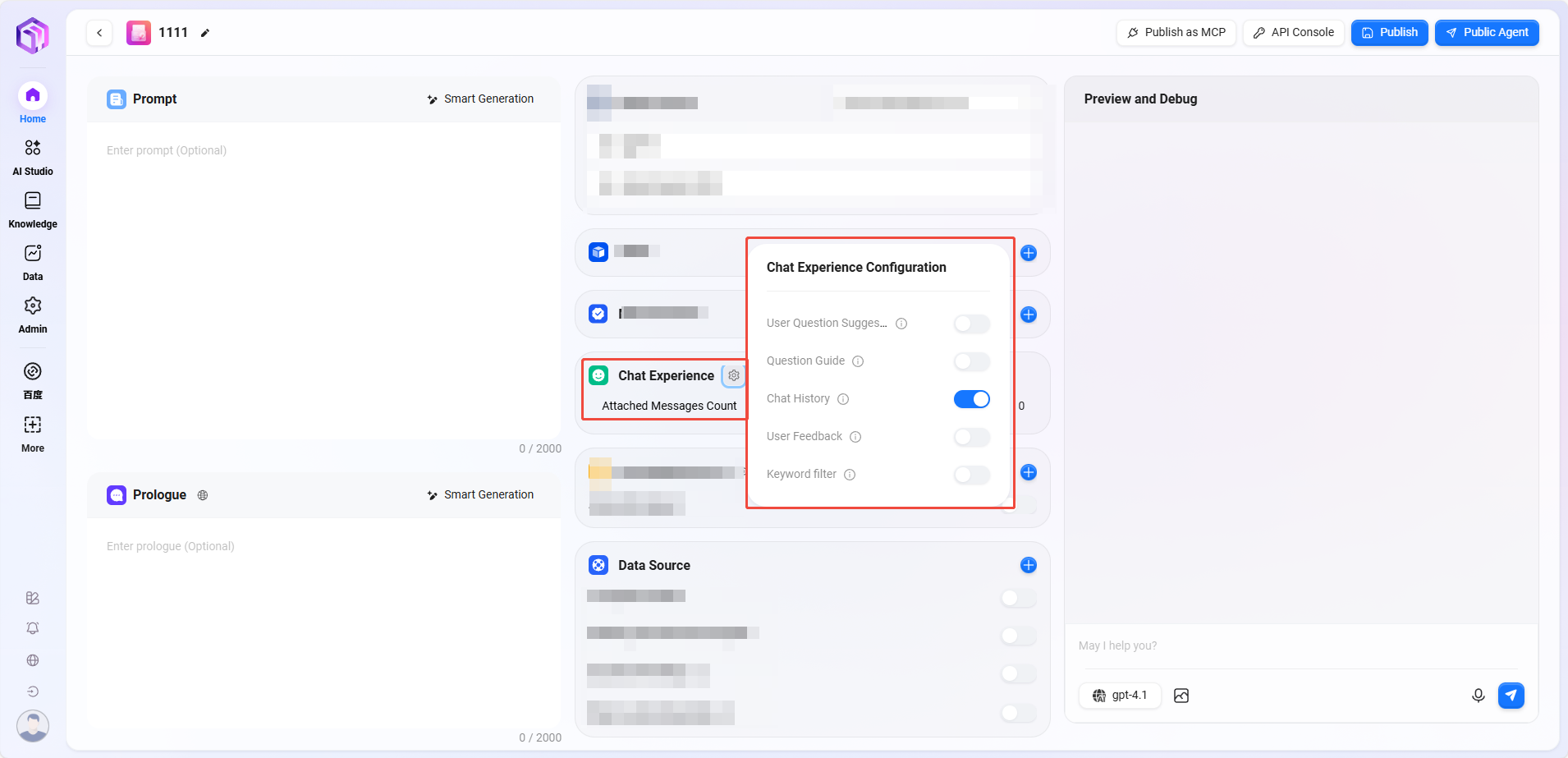
⑥ 对话体验:
- 对话设置:可以开启“用户问题建议、问题引导、聊天记录、对话反馈、关键词审查”等设置
- 用户问题建议:在助手回答后,根据前文为用户提供一些问题建议。
- 问题引导:在用户与助手对话时,会有相关的问题引导,利用模型能力推测用户可能提问的问题以及对用户问题的补全。
- 聊天记录:是否留存助手的聊天记录,关闭后,将无法查到助手的聊天记录。
- 对话反馈:对助手的回答可以进行点赞、点踩等交互操作,用于优化助手回答。
- 开启关键词审查:审查输入内容和审查输出内容至少启用一项。开通后将对提示词或 AI 反馈结果都进行敏感词检测,敏感词可提前进行维护。
⑦ 知识库:
-
知识库:点击“+”添加知识库
- 是否允许文件上传:
- 打开允许文件上传后,无法再添加知识库的内容作为知识来源
- 关闭允许文件上传后,可以选择性添加个人空间或企业空间的知识库作为知识来源
- 是否允许文件上传:
-
知识库配置:可以修改知识库的“检索策略、私域问答、检索方式”等详细设置
1)检索策略:混合搜索、嵌入搜索、文本搜索- 混合检索:综合向量检索和全文检索的查询结果,返回重排后的结果
- 嵌入检索:通过相似性进行片段查找,有一定的跨语言泛化能力
- 文本检索:通过关键字进行片段查找,适用于含有特定关键字、名词片段的检索
2)最大召回数量:范围 1–10,不建议设置过高或过低,建议值为 3–5
3)元数据过滤:无、过滤、权重
4)强制私域文件问答:打开后不会使用联网搜索等技能,助手的回答只针对知识库内容
5)文档匹配近似度:范围 0–1,匹配近似度越高,说明召回文档内容越相似,建议值约为 0.8(即 80%)
6)QnA 匹配近似度:范围 0–1,类似于文档内容的近似度匹配,建议值约为 0.9(即 90%)
7)显示参考文献:打开后,助手在回答时会列出所参考的文献,提高回答可信度
💡 提示:不论是最大召回数量、文档匹配近似度,还是 QnA 匹配近似度,都不是越高越好或越低越好,建议根据实际需求进行设置。如无特殊需求,建议保持默认值。
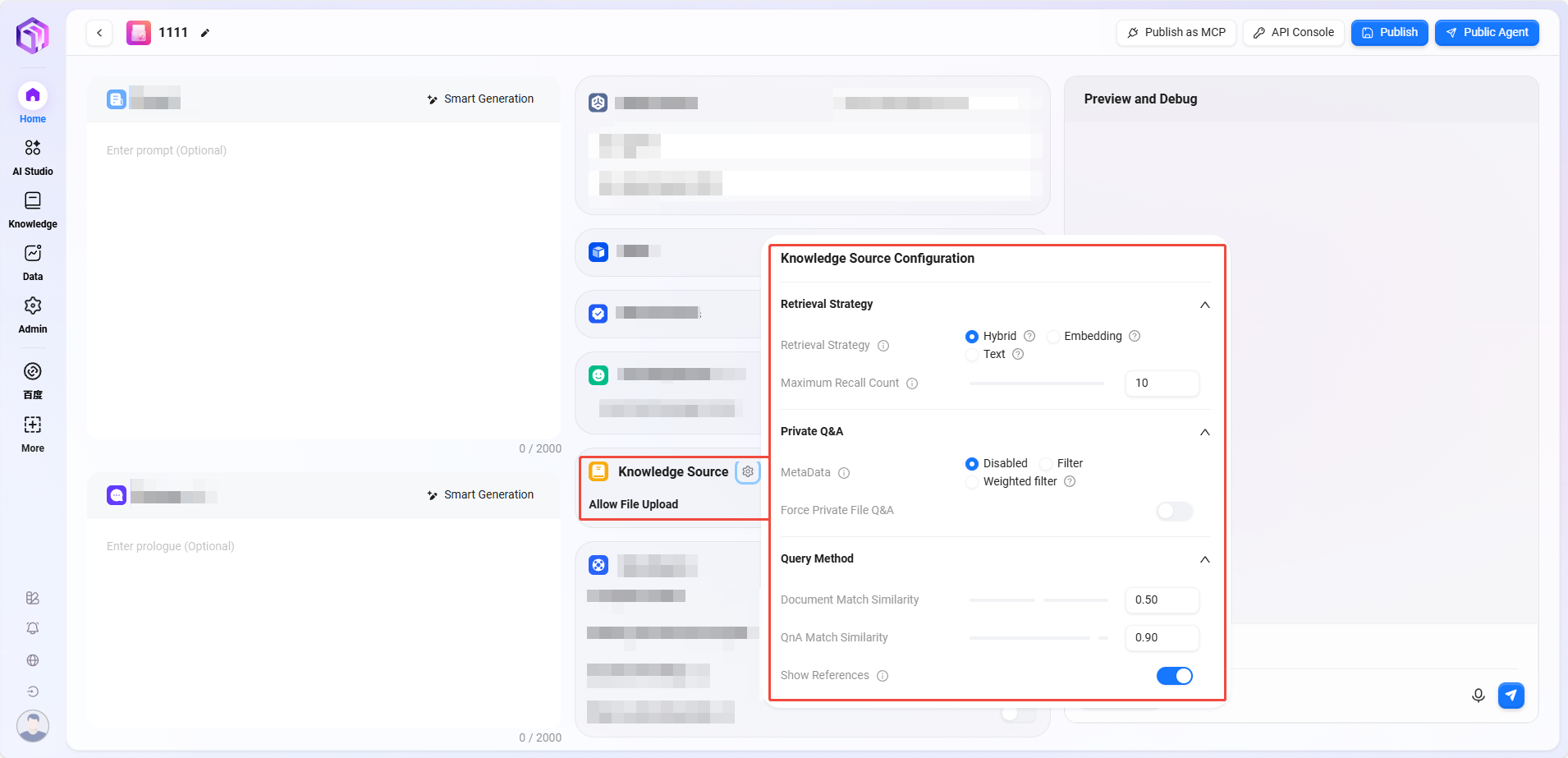
⑧ 数据来源
-
数据来源:点击“+”添加数据源,作为助手问答数据来源
-
是否启用模板:是否启用自然语言与SQL之间的预设映射模板。
- 当用户输入一个自然语言问题(比如:“
上个月销售额是多少?”),系统会先尝试 匹配一个预设好的模板。 - 如果找到匹配的模板(比如“
查询某个时间段的销售额”这种通用问题),就会使用模板中已有的 SQL 结构 作为参考,再结合具体的字段/表名等来生成最终的SQL语句。
- 当用户输入一个自然语言问题(比如:“
-
是否启用参数化模板:开启后,在模板基础上启用参数化查询,增强查询的灵活性和安全性。
-
问题改写:开启后,将自动对用户输入的问题进行优化,以确保准确地数据查询
- 用户原始提问:
查一下销售额(信息不完整) - 问题改写后:
查询2024年7月份所有产品的总销售额(补充了时间和范围)
- 用户原始提问:
-
分步思考:开启此功能后,在生成最终查询结果之前,系统会输出详细的思考步骤,解释它是如何分析问题并构造SQL查询语句。
- 步骤 1:识别关键词“
2024年7月”“销售额” - 步骤 2:确定数据表
Orders,字段order_date和sales_amount - 步骤 3:构造日期范围条件
2024-07-01到2024-07-31 - 步骤 4:生成SQL
- 步骤 1:识别关键词“
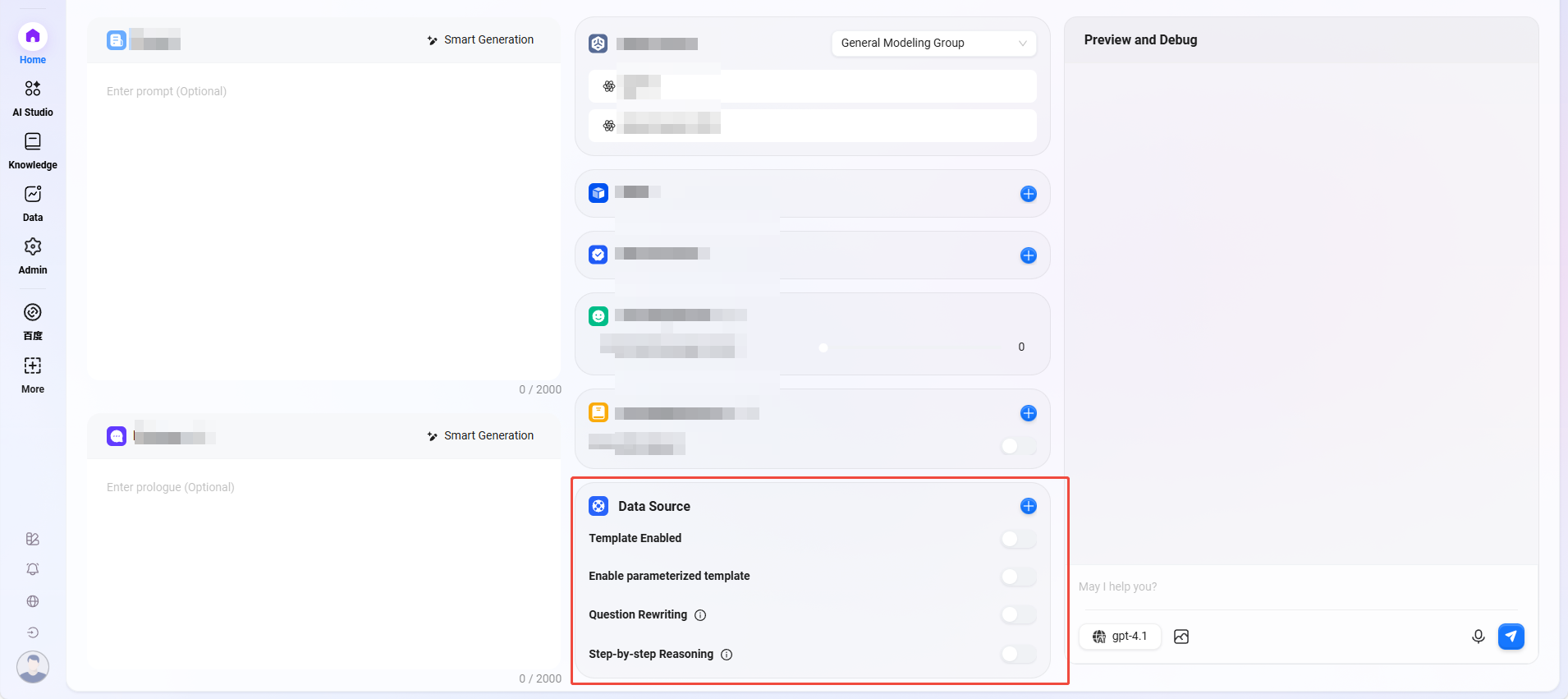
工作流创建Agent
- 选择“高级智能体”(创建步骤同创建普通智能体)
- 构建类型
- 进阶模式:快速构建复杂的工作流程,精确满足业务需求。
- 应用模式:创建完整、先进的编排应用程序,具有用户友好的界面,带来无缝的小语言模型体验。
- 构建类型
- 根据实际业务配置工作流:
- 开始、结束:自带的输入输出模块,可自定义输入输出参数与字段;
- 模型:可在此模块中选择使用的模型,输入其他模块获取的变量,并编辑提示词以及输出的消息,以变量形式保存;
- 知识库检索:在选定的知识库中,根据输入变量召回最匹配的信息,加以返回;
- 技能:选择其中一个技能,进行经过该技能的输入输出动作;
- 代码:根据其他模块中的输出变量,进行代码函数的自定义编写与创建;
- 选择器:连接多个下游分支,若设定的条件成立则仅运行对应的分支,若均不成立则只运行“否则”分支;
- 意图识别:用于用户输入的意图识别,并将其与预设意图选项进行匹配;
- 文本格式器:用于处理多个字符型变量的格式;
- 数据来源:选择数据来源以增加可引用的变量内容;
- 文件检索:在上传的文件中搜索,根据输入的问题查找相关答案;
- 循环:对列表中的每一项重复执行一组任务,并可选择并行处理。
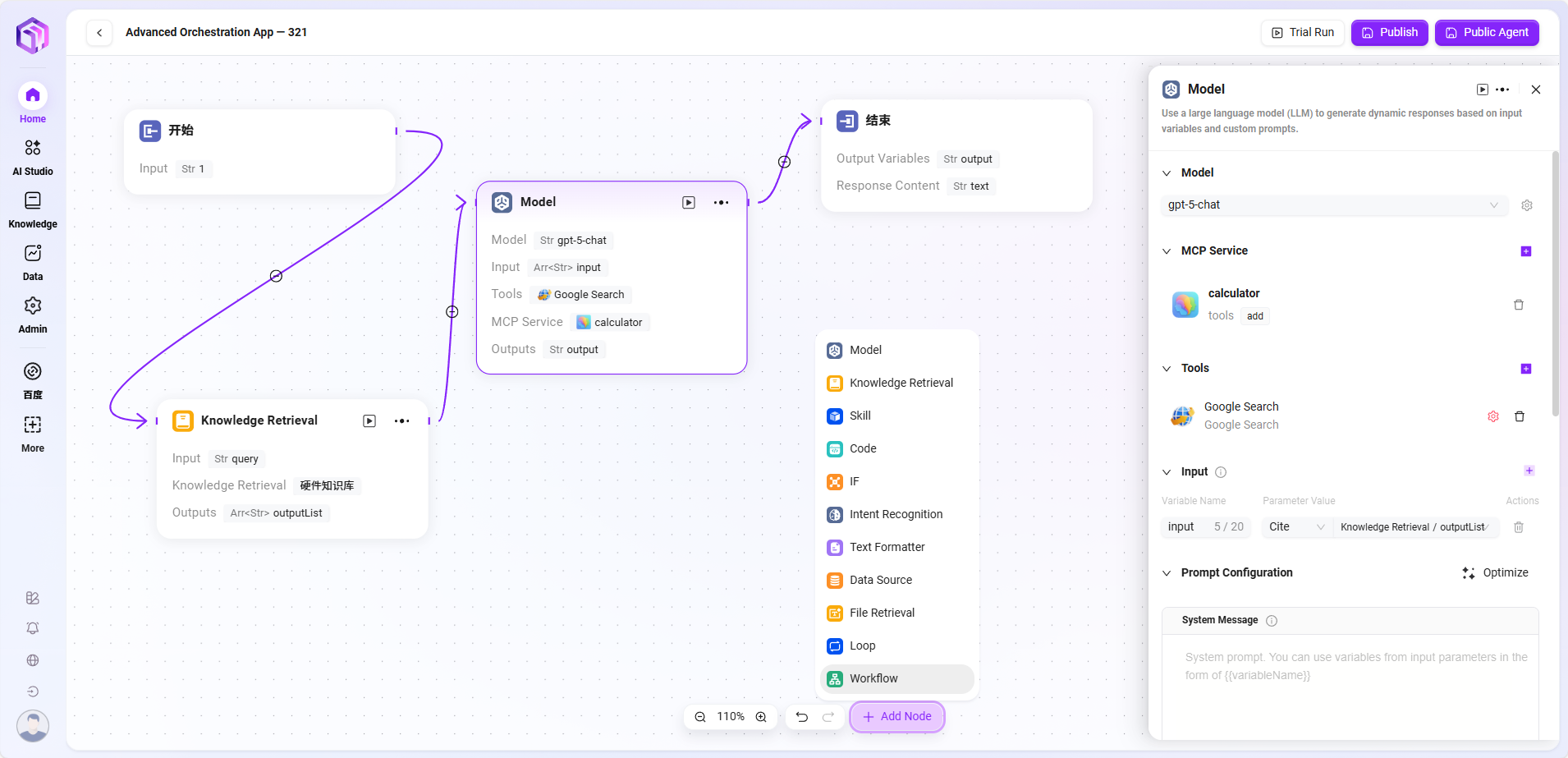
- 节点详细介绍
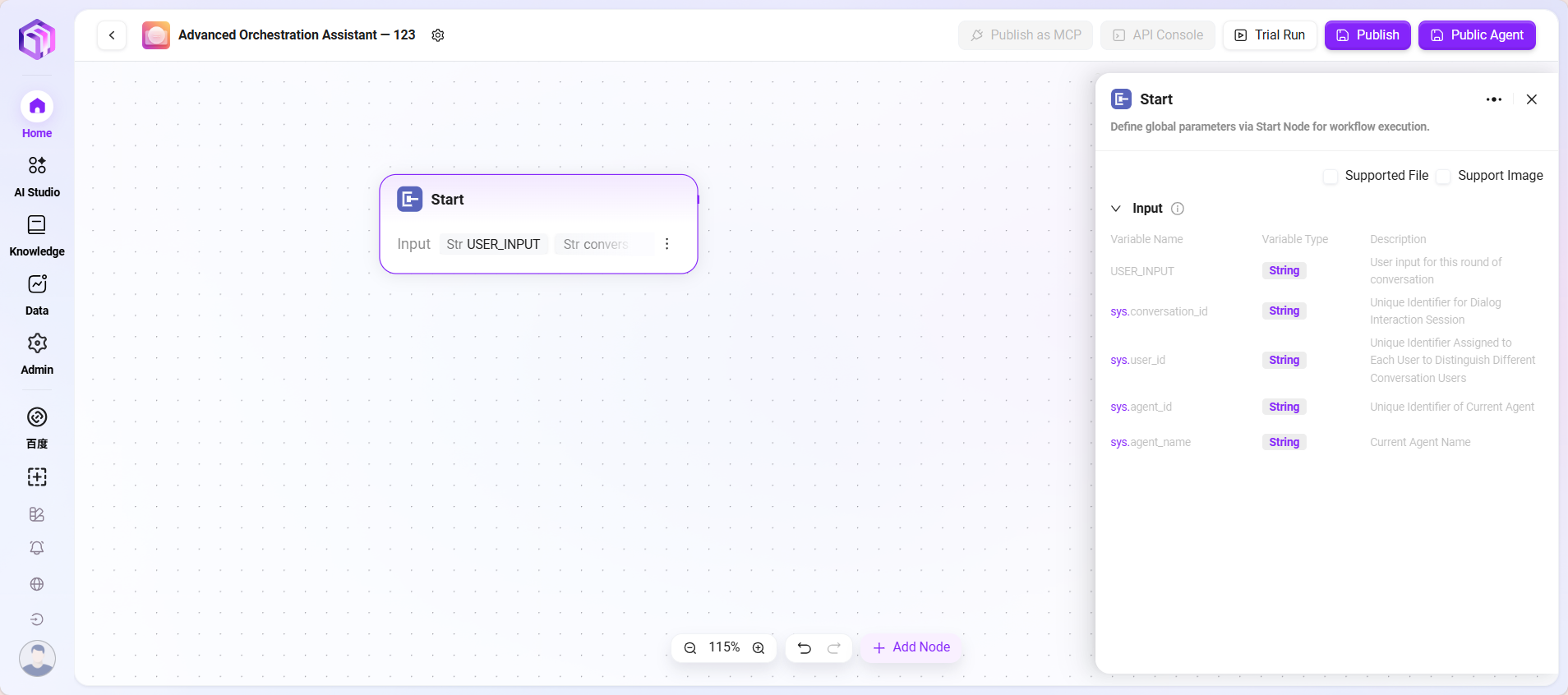
- 开始
- 开始节点:工作流的起始节点,用于设定启动工作流需要的信息
- 输入:简单理解为,提前告诉LLM完成一项任务需要哪些基本信息(输入参数),当进行使用时,LLM会记住这些信息要求,一旦在对话中发现需要启动任务的时机,就会自动调用这些预先设定的参数,将参数放入对应位置,从而启动整个流程。
- 处理逻辑:直接传递(By pass),不做任何处理,只是把用户输入的内容原封不动传递给下个节点。
- 输出结果:所有输入内容直接输出。
- 模型
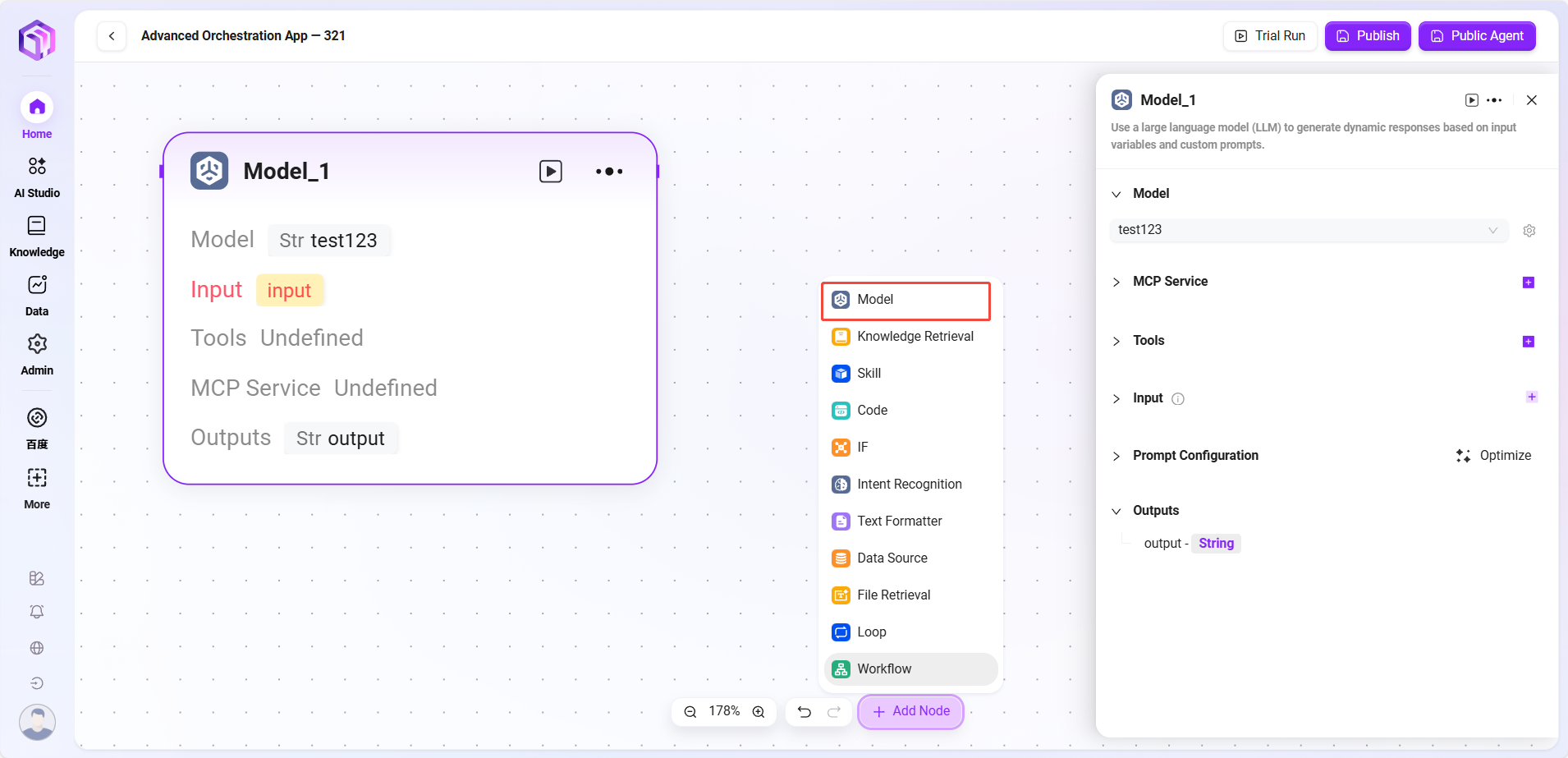
- 模型:调用大语言模型,使用变量和提示词生成回复
- 输入:下拉选择已有的模型,选用输入变量名
- 输入参数:query(String,来自上游或用户输入)
- 配置参数:
- 一个或多个 Tools
- Model
- GPT(GPT 或其他模型)
- Temperature:控制创造性,数值越高,回答越有创造性和随机性
- Top P:通过“概率阈值”限制选择的词范围,控制回答的多样性
- Max Reply Length:限制AI一次能回复的最大字数
- Syatem Prompt:系统给AI的隐藏指令,用来控制整体风格
- User Prompt:用户输入的内容或问题
- History:之前对话的轮次,用来保持上下文理解
- 处理逻辑:把输入交给大语言模型(LLM)处理,模型根据配置生成回答
- 输出结果:模型生成的文本内容
💡 提示:需要先连接上前置节点,才能选择其他节点的变量作为当前节点的输入变量
-
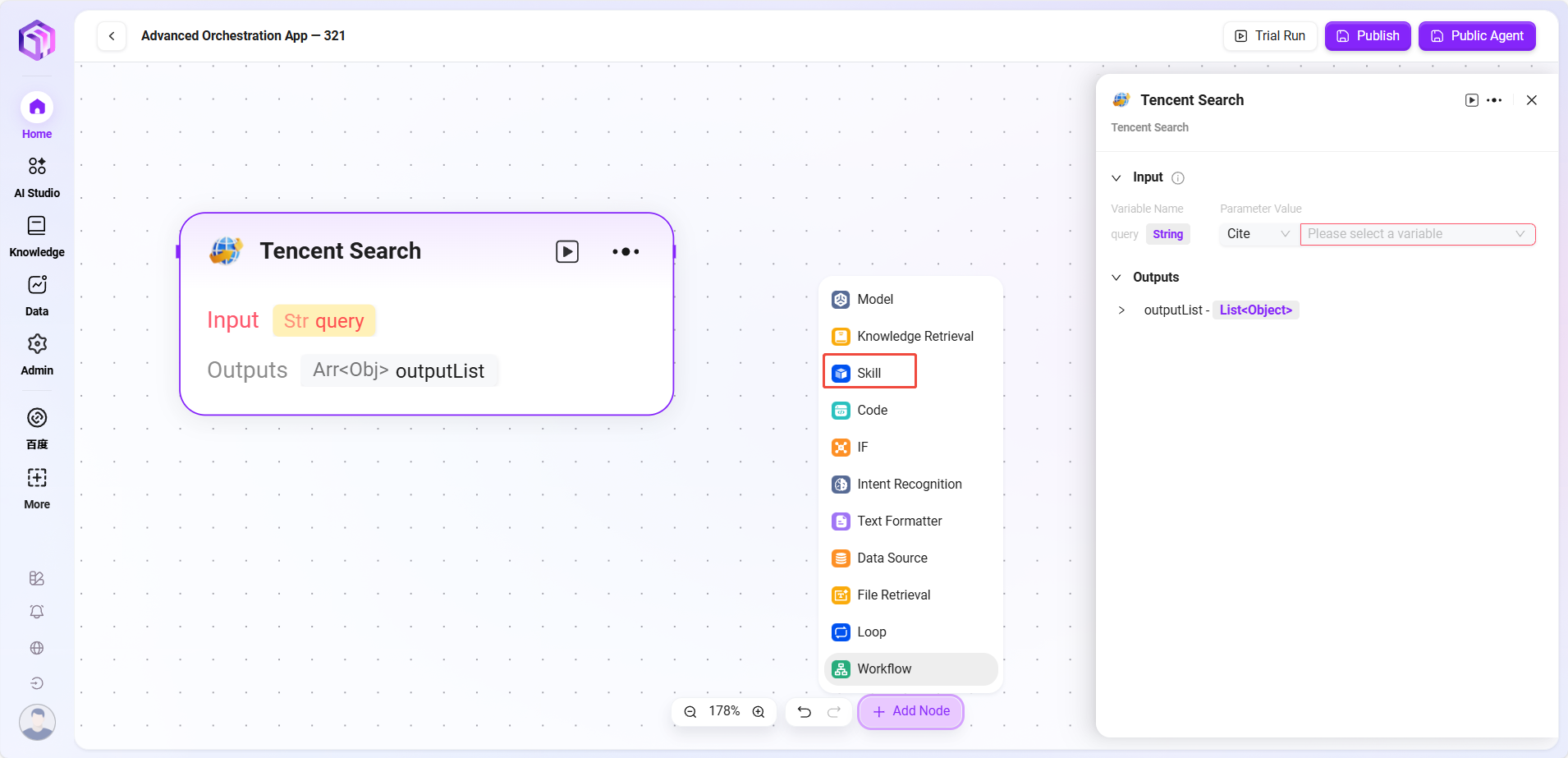
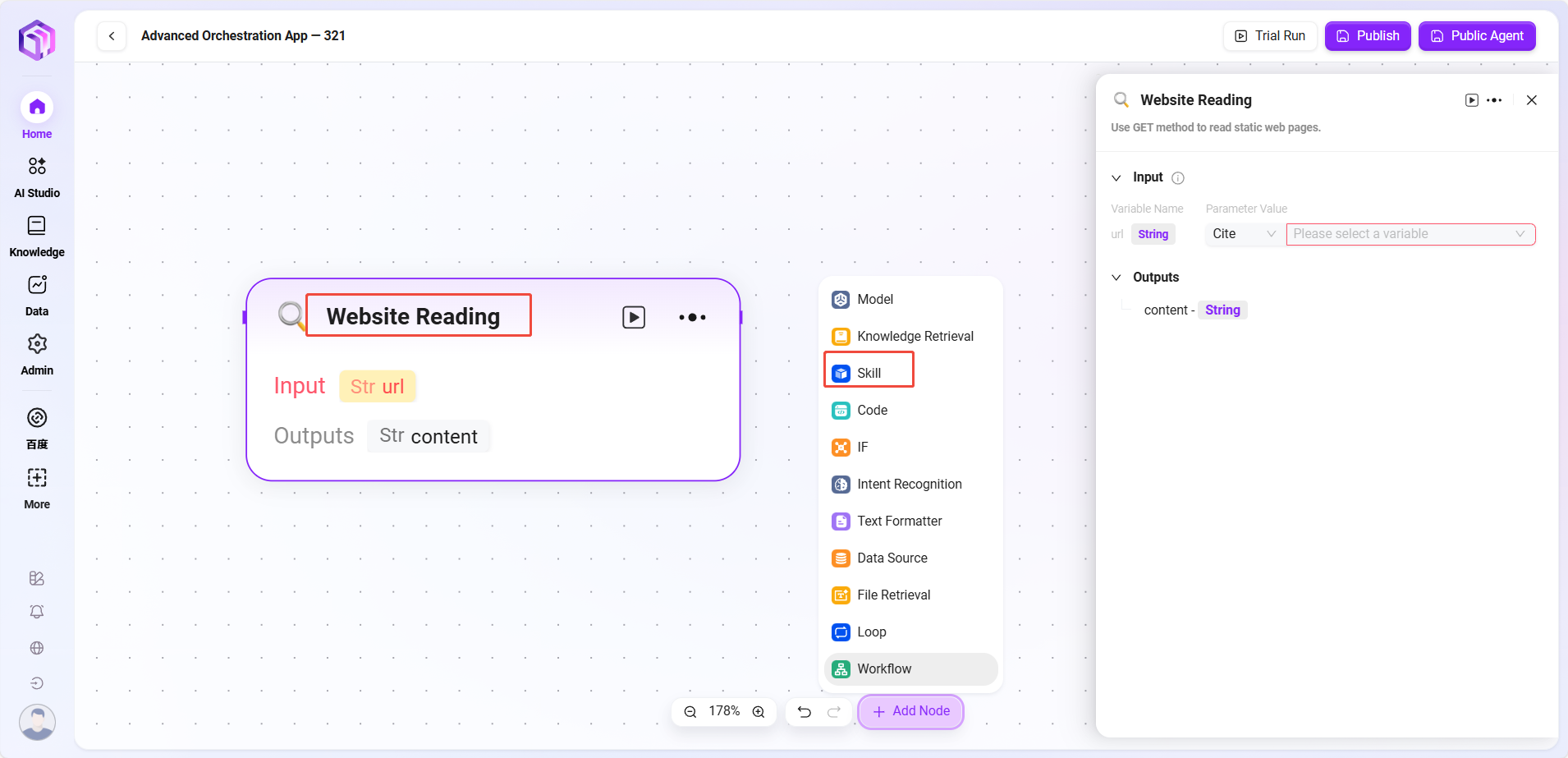
技能(部分示例)
- 网站读取:能读取网页上的静态文字(但看不到动态加载的内容)。
- 文本生成图片:把一段文字转成图片(输出图片地址)。
- 腾讯搜索:调用搜索引擎返回搜索结果。
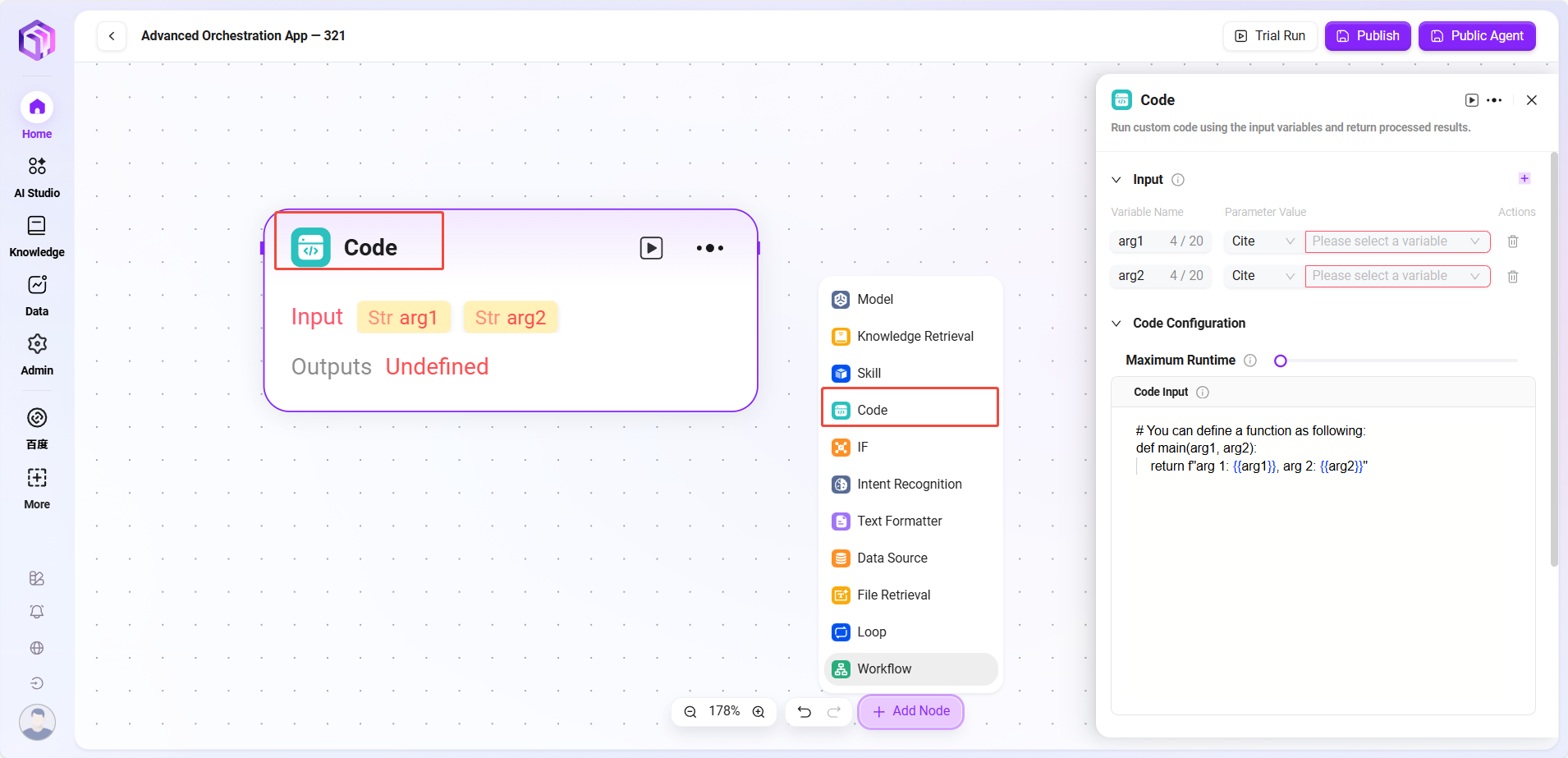
- 代码
- 代码:编写代码,处理输入变量来生成返回值
- 输入:用于接收外部传入的变量,是代码运行所需数据的入口,为后续代码处理提供原始数据
- 输入参数:query(string,用户或上游传入的代码请求)
- 配置参数:对代码运行相关参数进行设置
- 最大运行时长(Maximum Runtime)
- 代码内容(Code Input)
- 处理逻辑:
- 在安全的沙箱环境中运行代码(基于 RestrictedPython 或指定平台)
- 限制运行时长和访问权限,避免安全风险
- 输出结果:代码运行处理完输入数据后,将结果以指定变量形式输出,是代码处理结果的出口
-
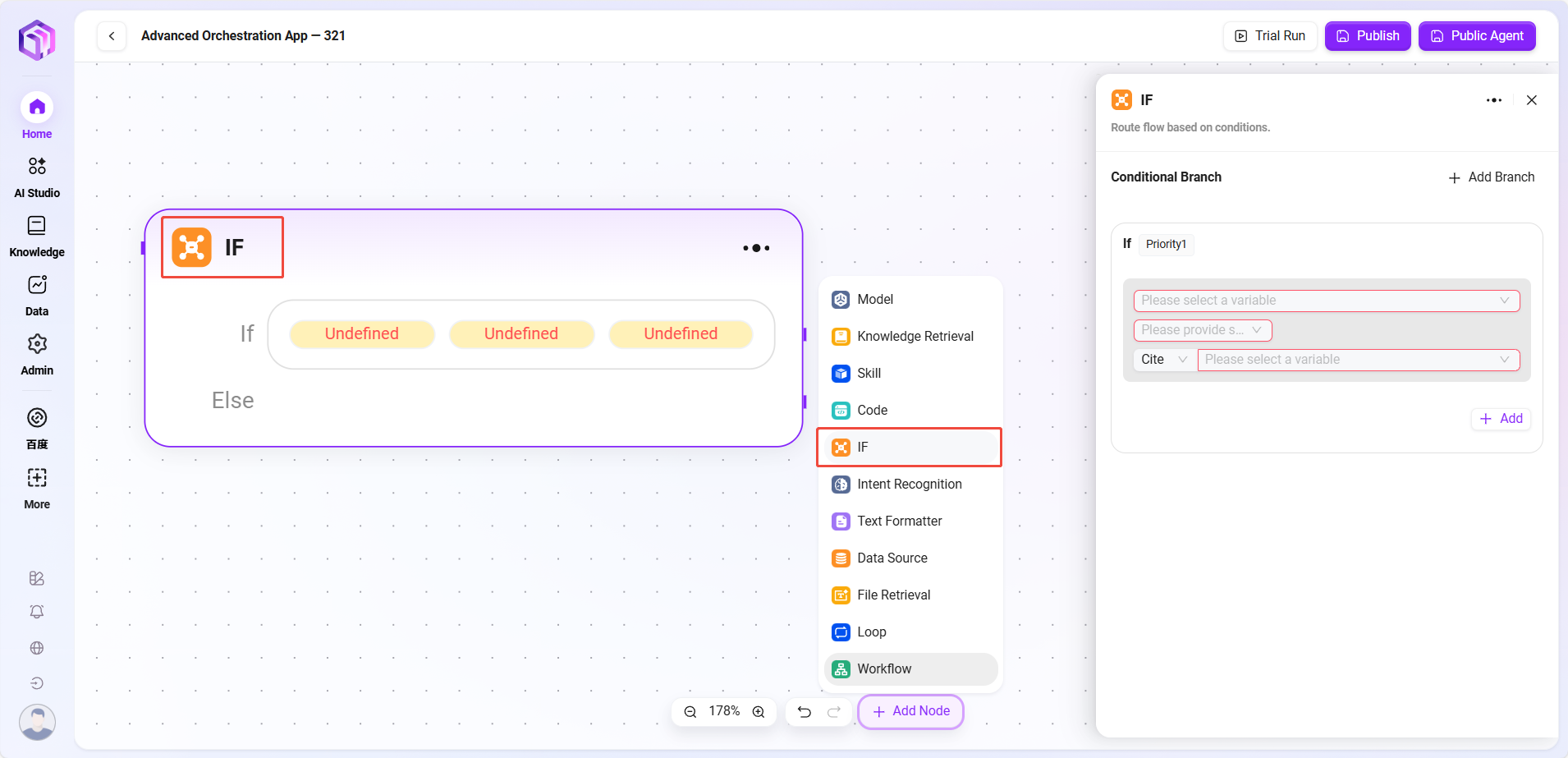
选择器
- 选择器:在流程编排中起条件判断作用。它连接多个下游分支,通过设定的条件来决定执行路径
- 条件分支:可设置多个条件,如 “if - 优先级 1” 。通过配置引用变量、选择条件(如等于、大于等比较逻辑 )、比较值,来判断条件是否成立。若成立,就运行对应的分支流程。
- 处理逻辑:根据不同条件走不同路径(如果没有满足条件的,就走 Else)
- 输出结果:没有直接输出,只决定下一个节点的走向
-
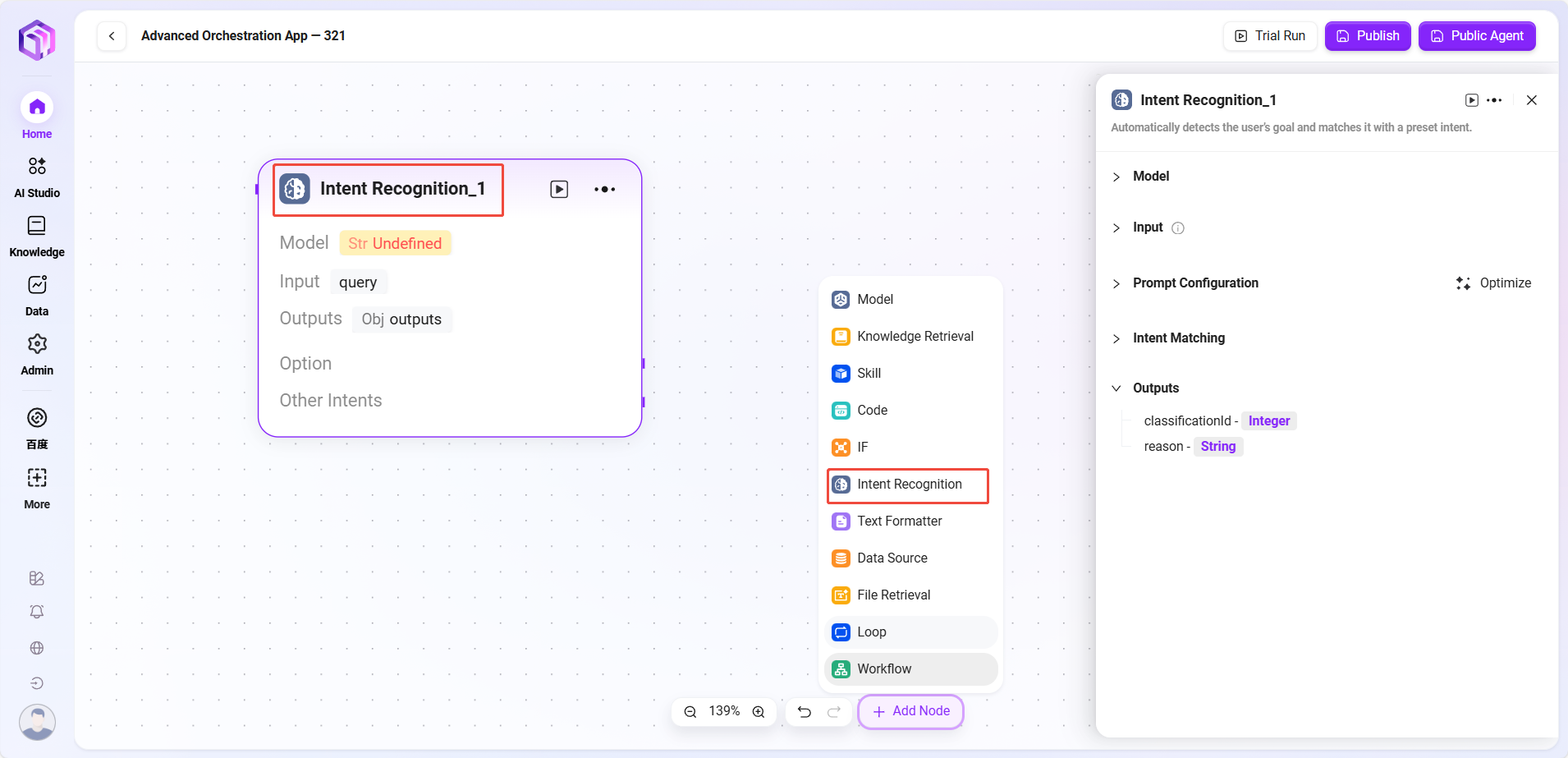
意图识别
- 意图识别:是自然语言处理中的关键环节,该模块作用是分析用户输入内容,确定其真实意图并匹配预设置选项
- 模型:选择用于意图识别的模型,模型决定了意图识别的能力和效果
- 意图匹配:可预先输入用户意图描述作为匹配标准,也能新增其他意图,系统据此判断用户输入符合哪种预设意图
- 高级设置:能设置系统提示内容,可引用输入变量来优化提示效果;还可设置历史记忆条数,让模型参考过往对话信息提升识别准确性
- 处理逻辑:判断用户的真实意图,把输入分类到对应类别
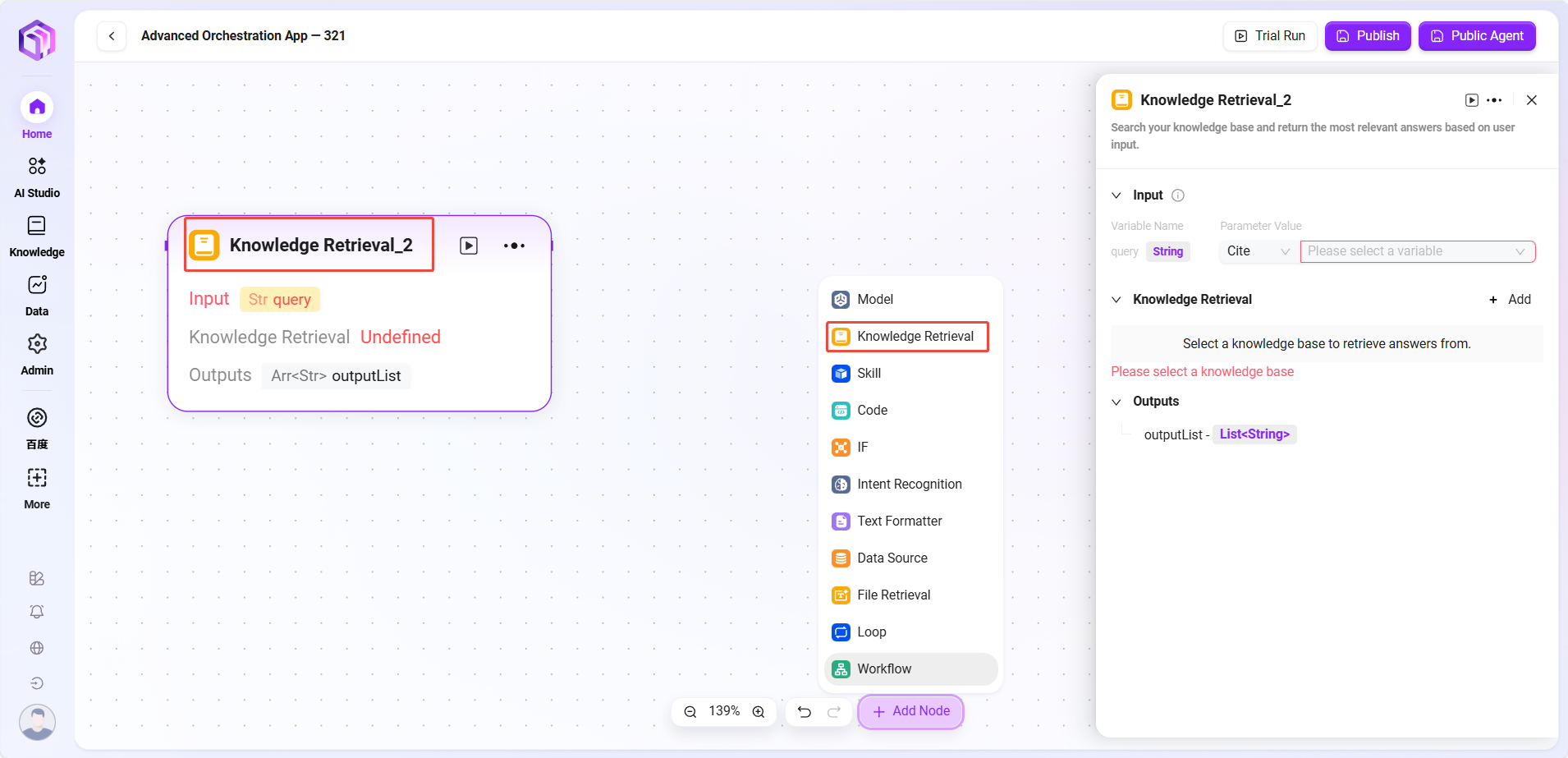
- 知识库检索
- 输入:通过定义变量名及设置参数值,为知识库检索提供检索关键词等原始数据
- 处理逻辑:根据输入和参数检索知识库,返回片段或FAQ
- 知识库:选定特定的知识库作为检索范围,系统将在这个范围内查找匹配信息
- 最大召回数量:可设置从知识库中最多返回匹配结果的数量,避免返回过多数据
- 输出:将从知识库中检索到的匹配信息,以指定变量的形式输出,供后续流程使用
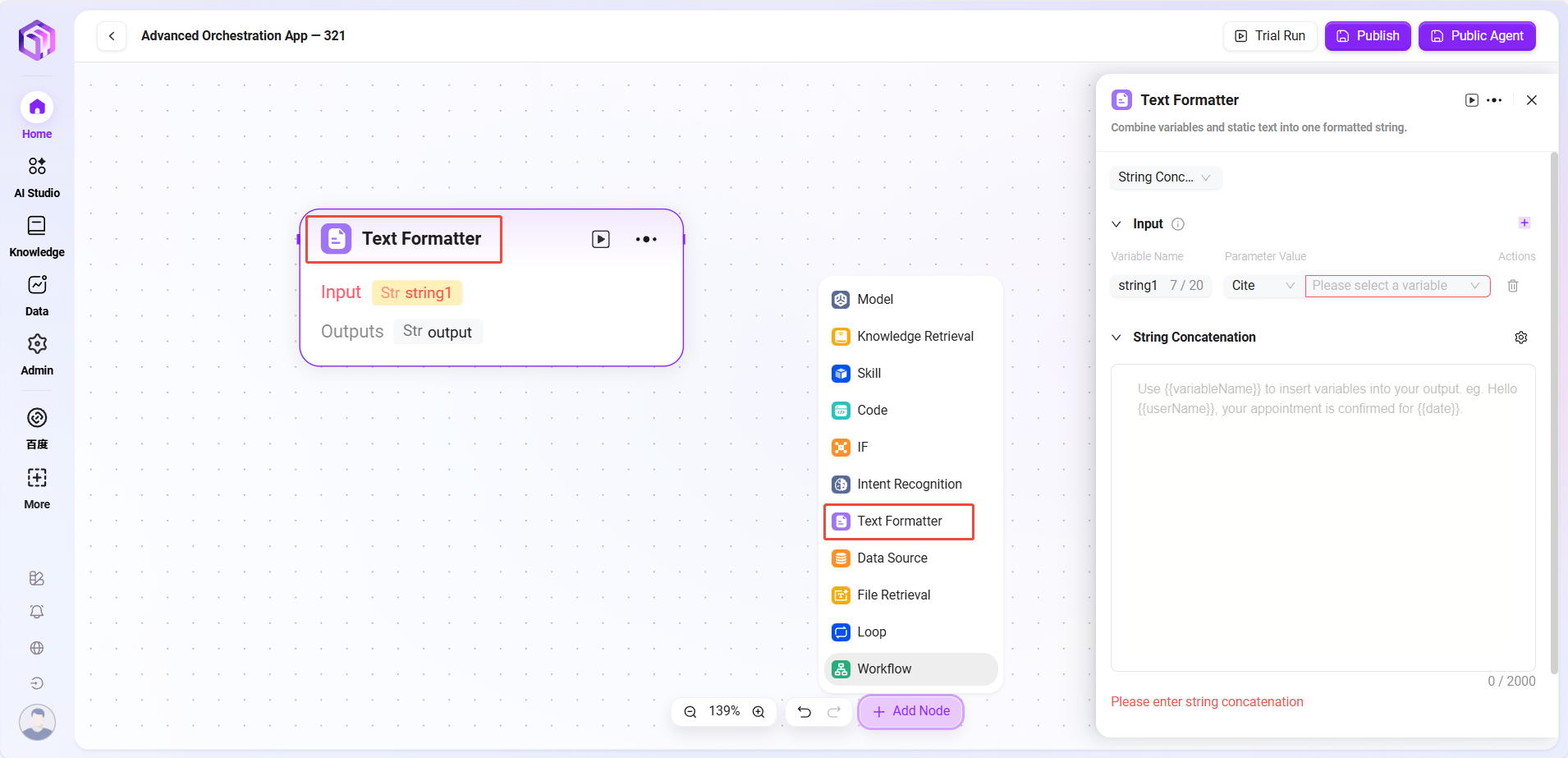
- 文本格式器
- 文本:主要用于处理字符串类型变量格式
- 输入:可定义变量名,并通过引用方式获取参数值,为后续文本处理提供原始字符串数据
- 处理逻辑:把文本做简单加工
- 字符串拼接
- 字符串分割
- 字符串拼接:提供文本编辑区域,可按需求使用变量名方式引用输入变量,对多个字符串进行拼接等格式处理
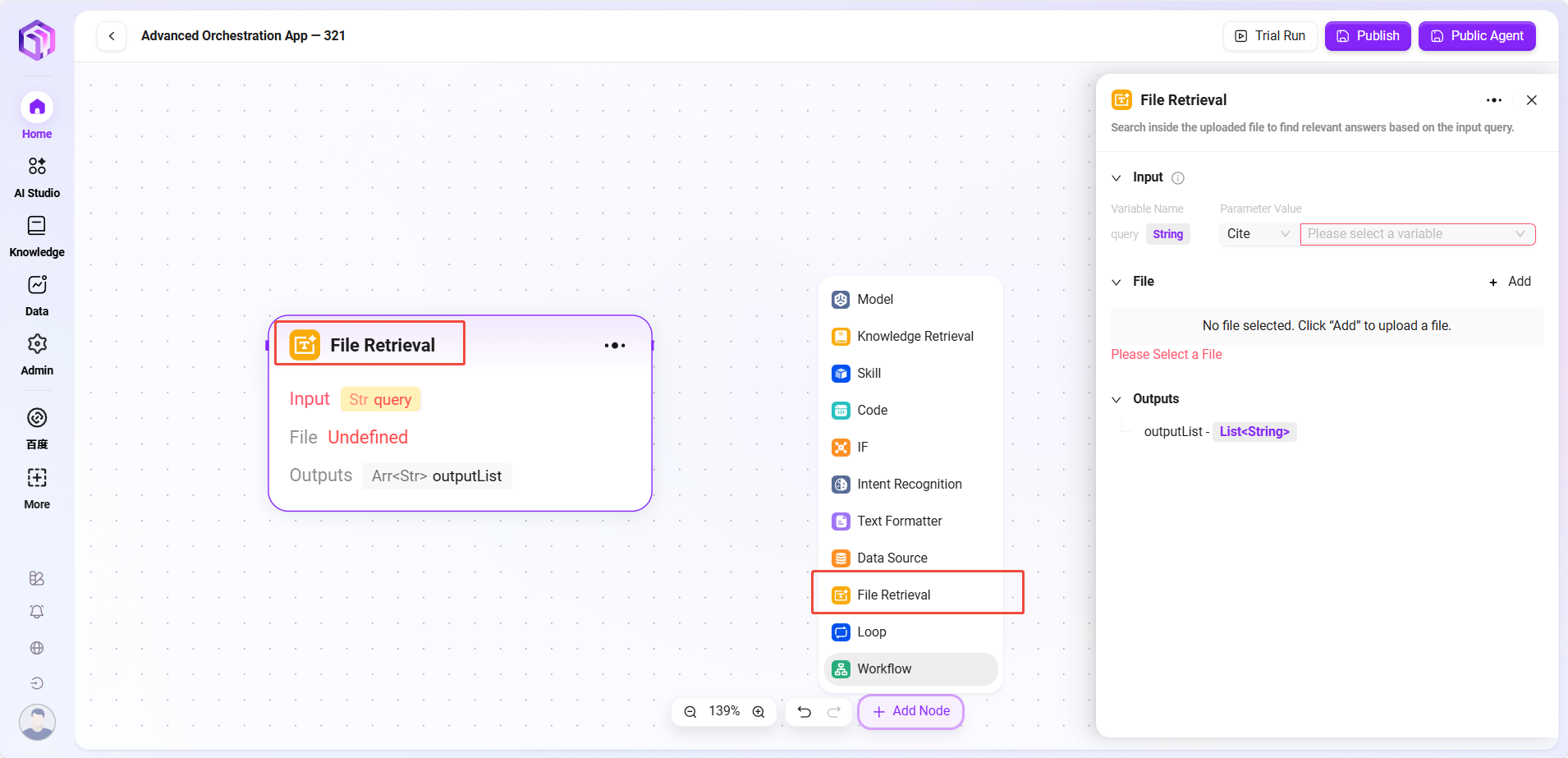
- 文件检索
- 文件检索:是对文件内容进行检索等操作的功能模块
- 输入:通过定义变量名并引用参数值来提供检索关键词等输入信息,为文件内容查找提供依据
- 文件:可添加需要处理的文件到该节点,确定检索的文件范围
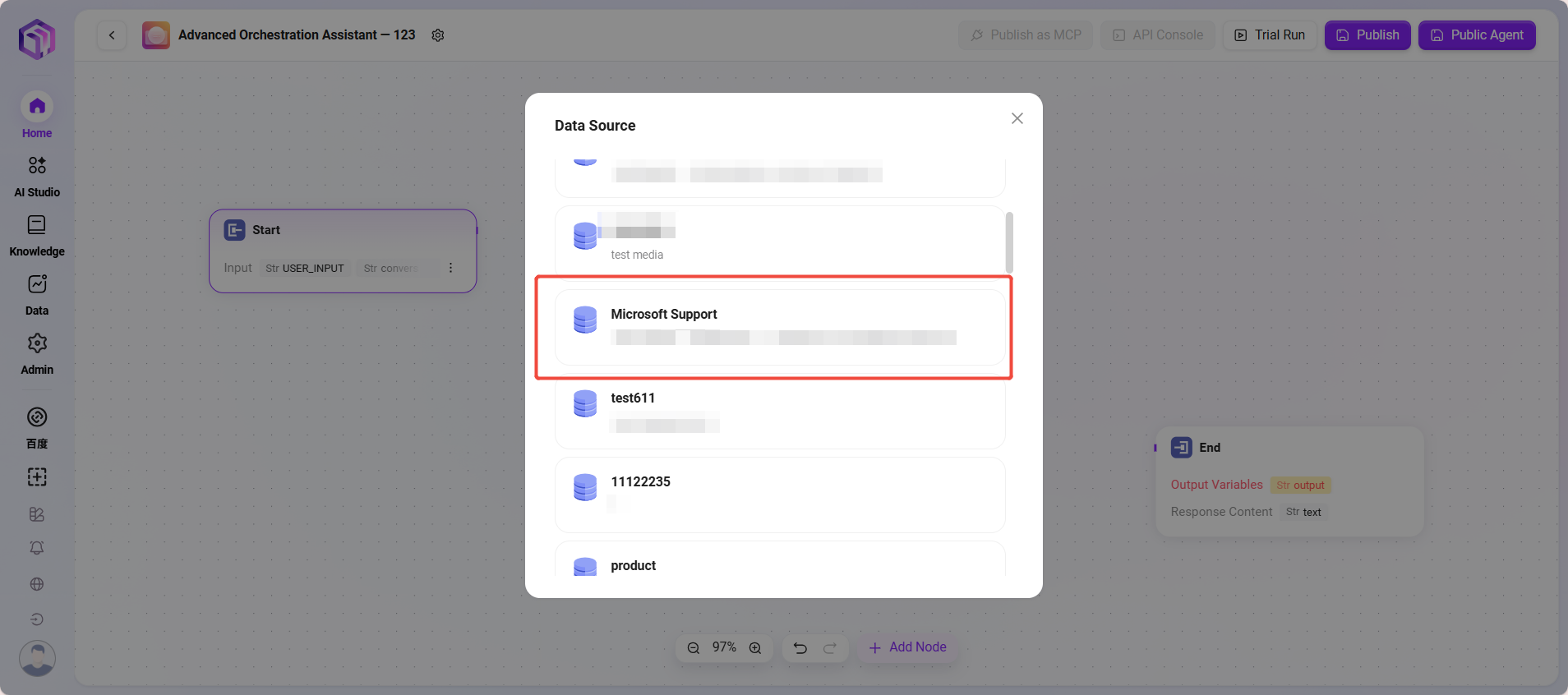
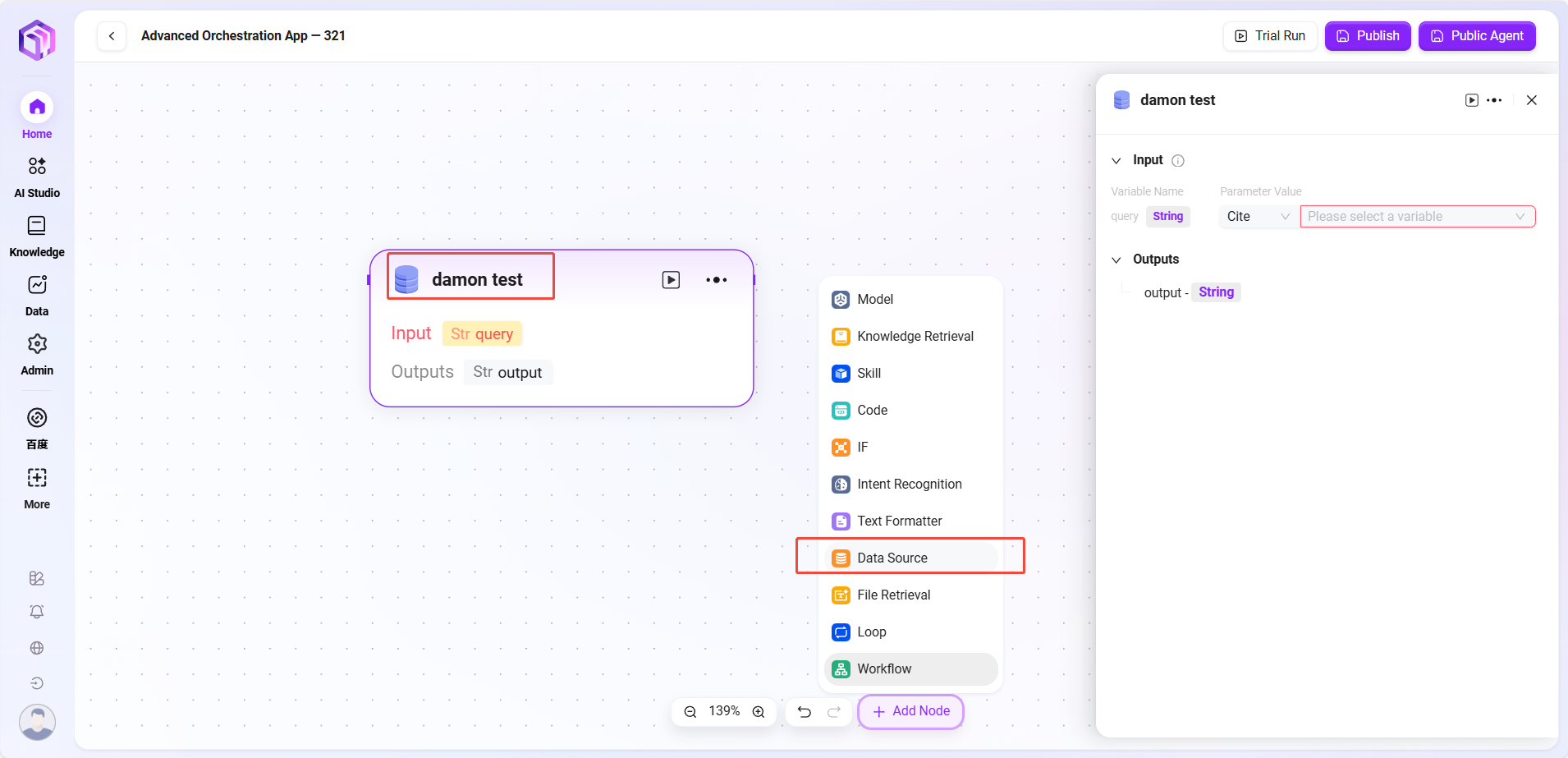
- 数据来源
- 数据来源:选择要接入的数据源
- 处理逻辑:把自然语言转成SQL查询数据库,返回结果
- 输出:将数据源的数据进行输出,输出给下一个节点。
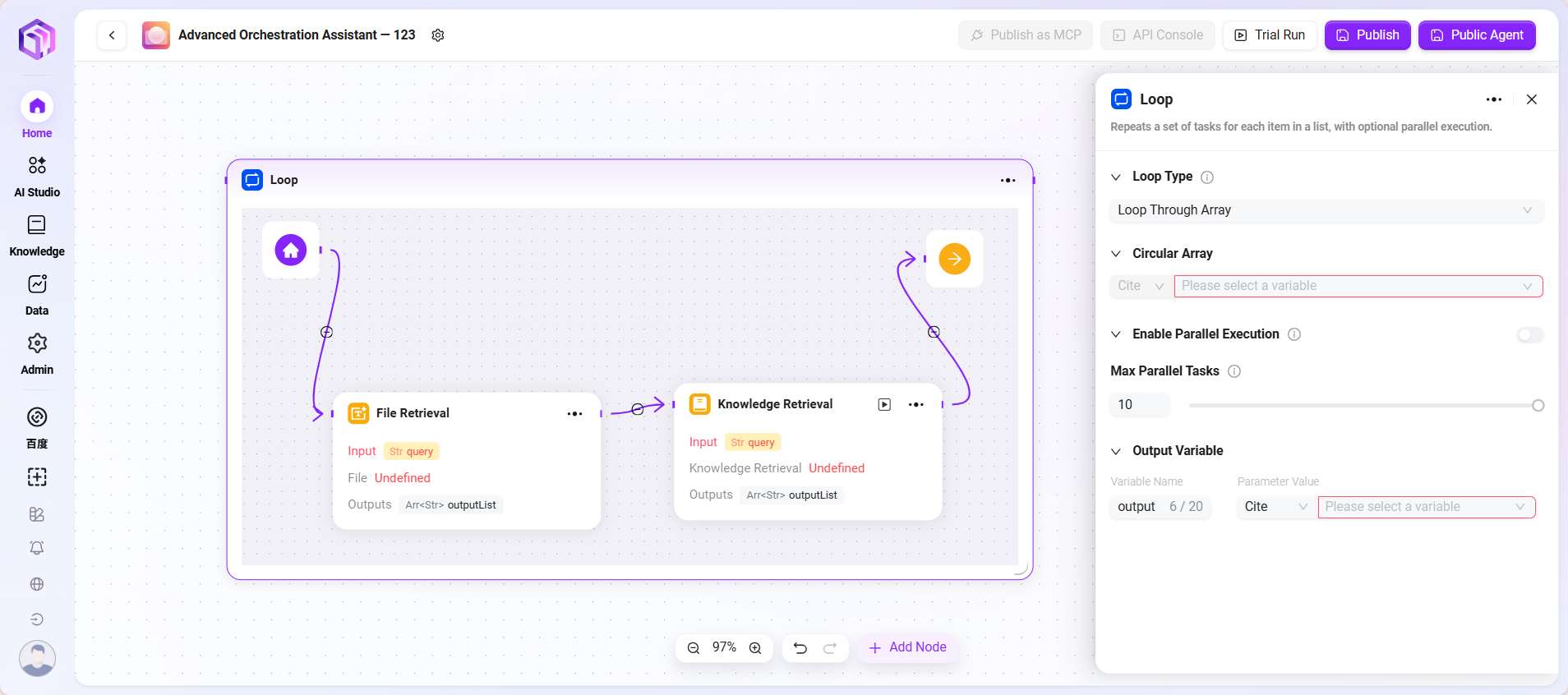
- 循环
- 循环节点:用于按指定的次数或指定的数据集合,重复执行一组任务。通过配置不同的循环模式,可以灵活实现批量处理或重复操作
- 循环类型:支持两种模式
- 使用数组循环:根据输入的数组,对数组中的每个元素依次执行任务。
- 使用数值循环:按照设定的次数,循环执行任务。
- 循环数值/数组:
- 当选择“数值循环”时,需输入一个具体的数字,例如 2,则表示任务将被执行 2 次。
- 当选择“数组循环”时,需要提供一个数组变量,系统会逐一取出数组中的元素作为输入执行任务。
- 并行执行:可选功能。如果开启,系统会同时处理多个循环任务,提升效率。用户可以设置最大并行数,以控制资源占用。
工作流示例
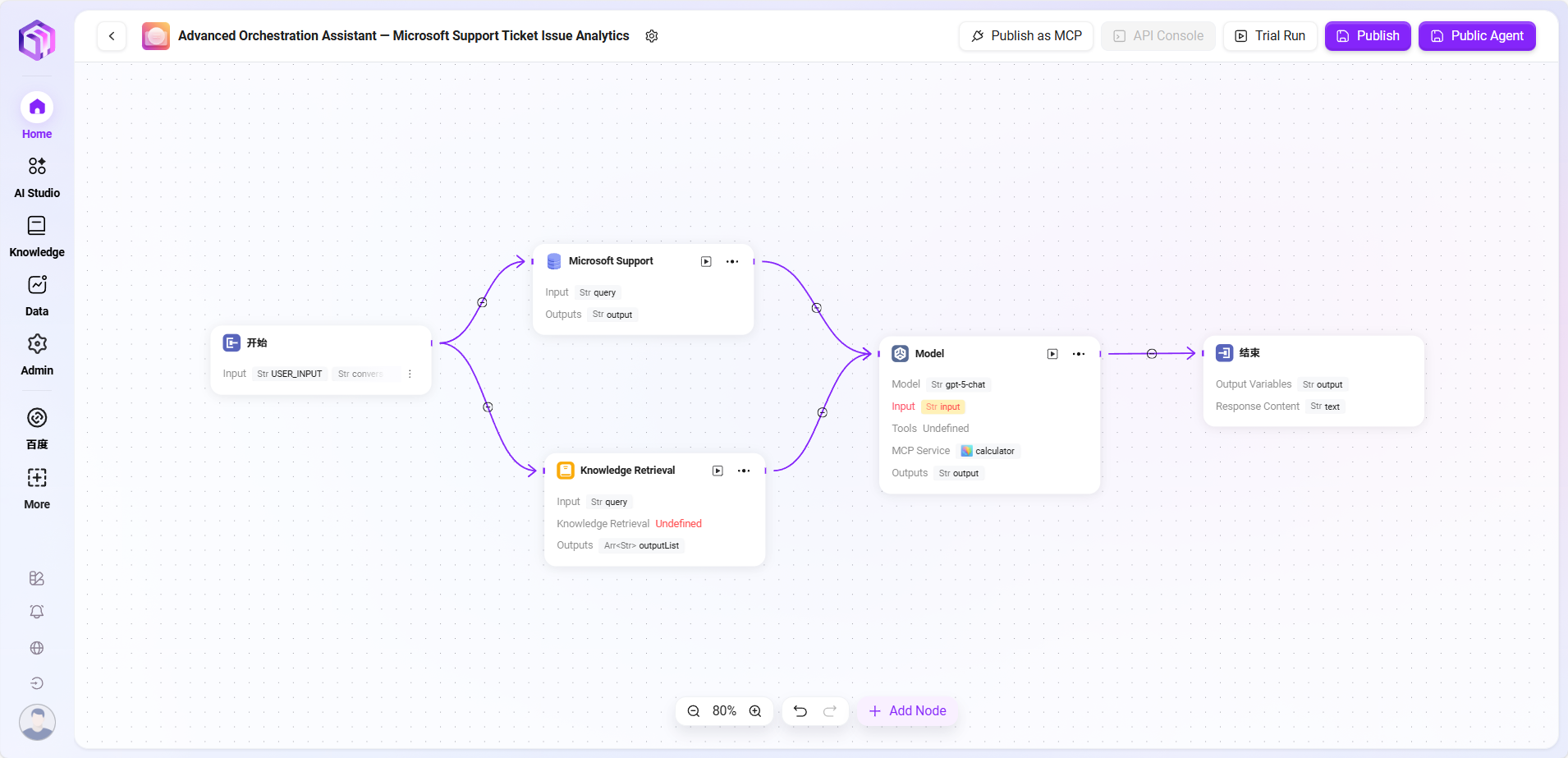
在本场景中,使用工作流功能构建一个完整的 “Microsoft Support Ticket Issue Analytics” 流程,具体流程如下:
- 开始节点
流程的起点,系统默认包含。 - 数据源节点
用于接入工单分析所需的原始数据。 - 知识库节点
接入包含分析参考资料的知识文档,作为AI分析的理论支撑。 - 模型节点
基于AI模型,将数据源与知识库内容结合,进行综合分析,生成工单问题分析结果。 - 结束节点
流程的终点,输出模型节点的分析结果。此节点系统默认包含。
数据源节点与知识库节点并列配置,模型节点则汇总处理前两者的信息,确保输出结果具备数据依据和理论支撑。
最后效果如下:
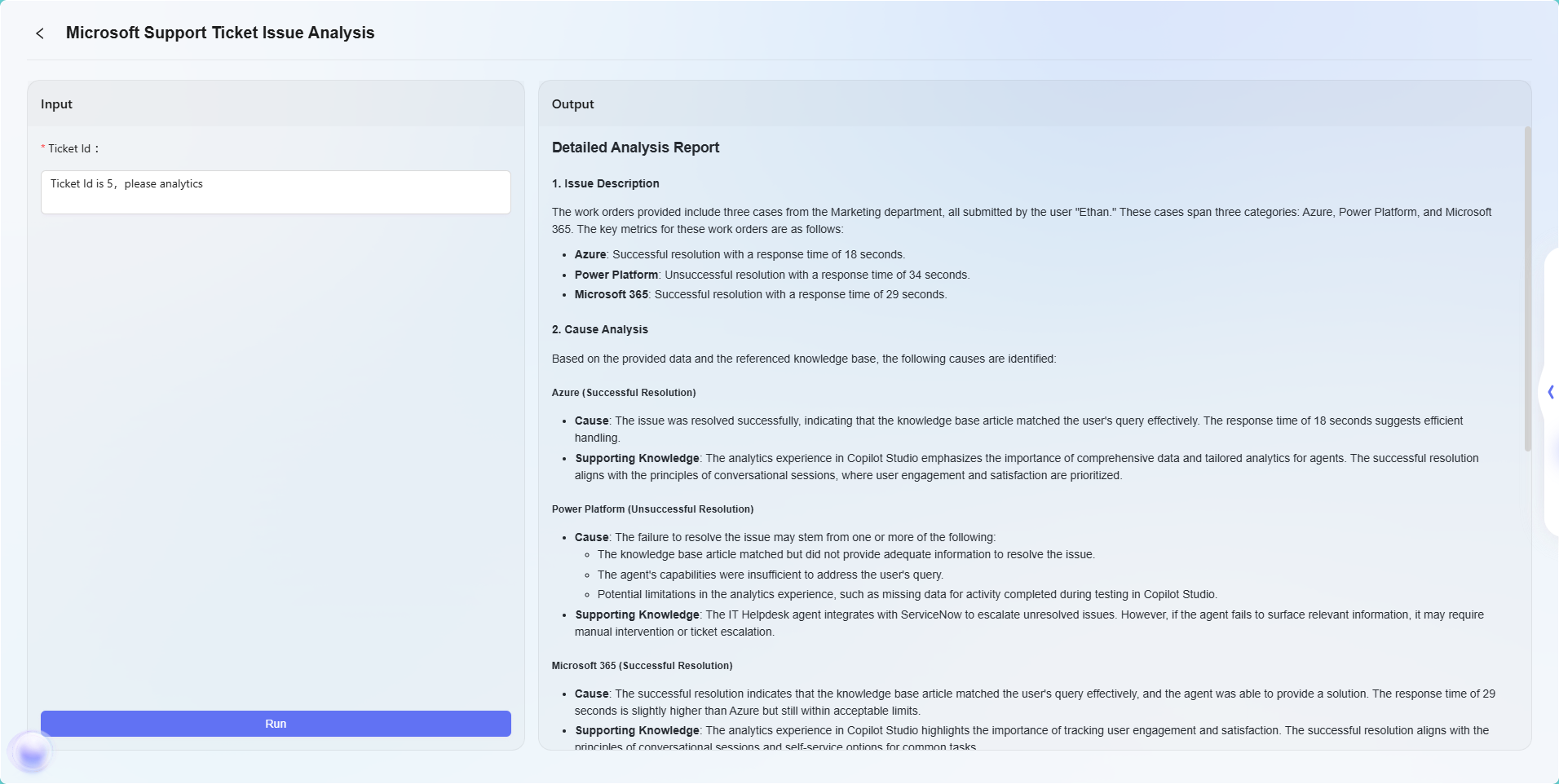
注:本示例仅为高级编排功能的简单应用,用于展示其基本流程效果。高级编排具备强大的灵活性和扩展性,支持通过多种节点类型实现复杂的业务逻辑和智能自动化流程,可广泛应用于多种实际业务场景中。
什么是MCP
MCP(Model Context Protocol)是智能体平台的核心扩展协议,负责连接外部工具、数据源和服务,为AI助手提供强大的能力扩展支持。
功能模块
| 功能类别 | 主要用途 |
|---|---|
| 计算服务 | 加、减、乘、除、取余、开方、幂运算 |
| 搜索服务 | 网络搜索、学术论文检索、数据提取 |
| 数据分析 | 图表生成、分析能力 |
| 工具集成 | 地图服务、协作工具集成 |
如何创建个人MCP
-
在 AI Studio 页面左侧,点击 "MCP" 进入 MCP 页面;
-
进入 MCP 页面后,点击右上角的 "创建" 按钮,进入 MCP 创建页面;
-
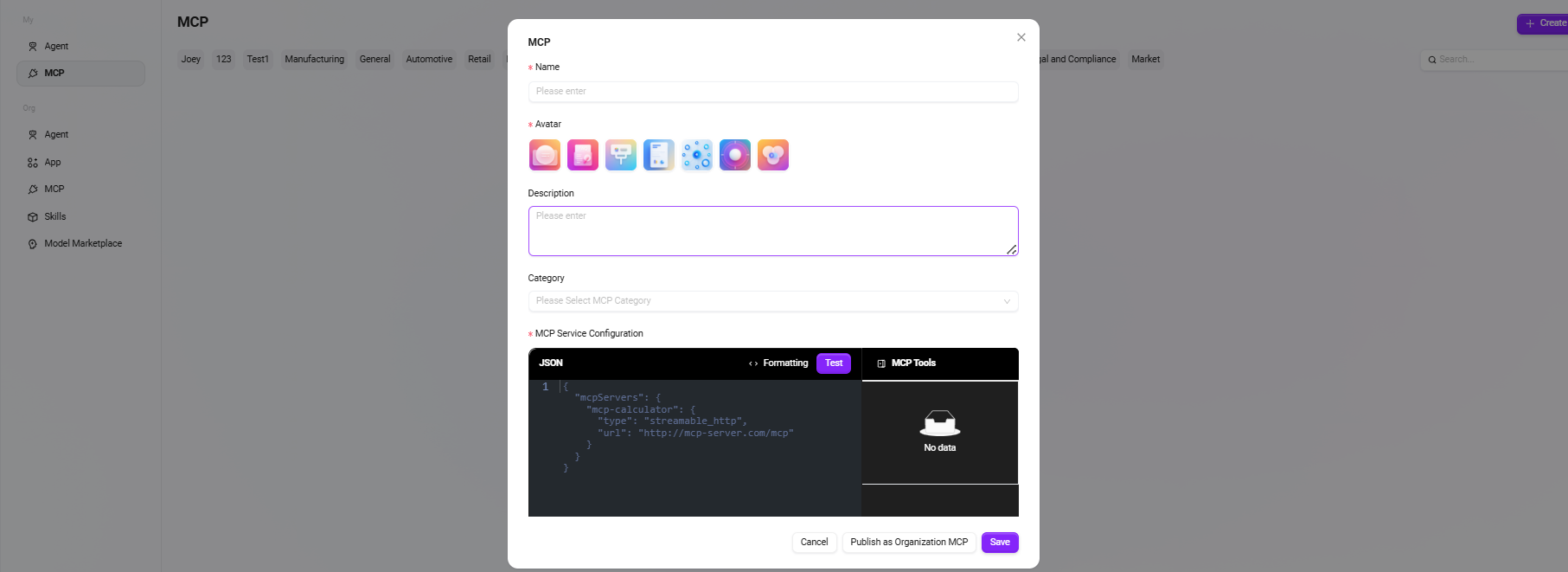
填写基础信息
- MCP名称:输入MCP的名称,作为MCP标识。
- MCP头像:选择默认头像,目前不支持上传头像。
- MCP描述:简要描述该 MCP 的功能特点和主要用途。
- MCP分类:选择新建MCP所在的类别。
- MCP服务配置:通过JSON代码注册外部服务,让助手获得新能力。